langchain+本地embedding模型+milvus实现RAG
继上一篇langchain+免费大模型api快速部署服务_langchain 免费模型-CSDN博客
环境
centos7、docker26、python310
部署本地embedding大模型
1、从魔塔社区拉取模型文件
ModelScope - 模型列表页
注意:git下载需要安装git-lfs才能下载大文件,步骤如下
添加Git LFS软件仓库curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.rpm.sh | sudo bash安装Git LFS包sudo yum install git-lfs初始化Git LFSgit lfs install安装完成后会显示\"Git LFS initialized\"提示2、模型应用
from langchain.embeddings import HuggingFaceBgeEmbeddings# 加载本地模型(替换为你的实际路径)model_path = \"/modelscope/hub/bge-large-zh-v1.5\"model_kwargs = {\'device\': \'cpu\'}encode_kwargs = {\'normalize_embeddings\': True} # set True to compute cosine similarityembedding_model = HuggingFaceBgeEmbeddings( model_name=model_path, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs,)# print(embedding_model.embed_query(\'你好\'))部署向量数据库milvus
参考文档
Run Milvus in Docker (Linux) | Milvus Documentation
python调用
from pymilvus import connectionsfrom langchain_community.vectorstores import Milvus# 建立Milvus连接milvus_host = \"localhost\"milvus_port = \"19530\"conn = connections.connect(\"default\", host=milvus_host, port=milvus_port)# 初始化一个Milvus向量数据库collection_name=\"text_splits\"metric_type=\"COSINE\"#默认是L2vector_db = Milvus( embedding_function=embedding_model, collection_name=collection_name, connection_args={\"host\": milvus_host, \"port\": milvus_port}, index_params={\"metric_type\": metric_type}, text_field=\"text\", auto_id=True,)注意:Milvus中可以通过设置index_params的metric_type来控制相似度的计算方式,默认是L2;并不是设置了\'normalize_embeddings\': True,相似度计算就会采用cosine,需要显示指明
相关报错如下
pymilvus.exceptions.MilvusException: 输出文档相似度分数
参考文档
如何为检索结果添加分数 | LangChain中文网
代码实现
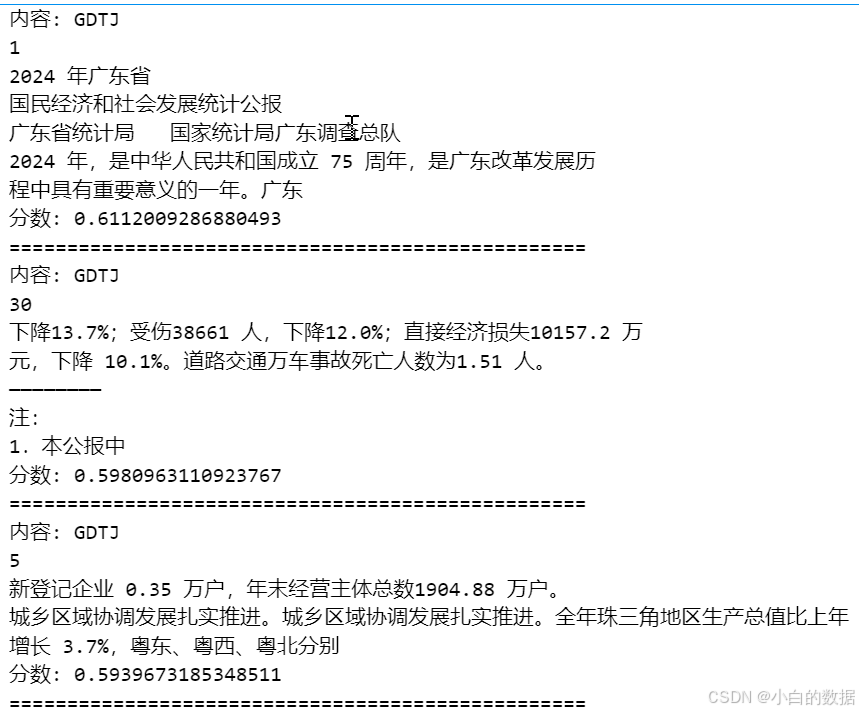
# 创建RAG链search_params = { \"metric_type\": \"COSINE\", # 使用余弦相似度(适用于归一化向量) \"params\": {\"nprobe\": 10} # 调整nprobe值以平衡速度和精度}@chaindef retriever(query: str) -> List[Document]: docs, scores = zip(*vector_db.similarity_search_with_score(query, k=3, param=search_params)) # 将分数添加到文档的元数据中 for doc, score in zip(docs, scores): doc.metadata[\"score\"] = score return docsqa_chain = ( {\"context\": retriever, \"question\": RunnablePassthrough()} | PROMPT | chat_model)# 获取检索结果retrieved_docs = retriever.invoke(\"分析2024年广东三次产业分别的情况怎么样?\")# 打印文档内容和分数for doc in retrieved_docs: print(f\"内容: {doc.page_content[:100]}\\n分数: {doc.metadata[\'score\']}\\n{\'=\'*50}\")结果打印