DeepSeek本地部署与LLaMA Factory微调_ollama factory
一、Ollama本地部署deepseek
1.根据情况选择合适的模型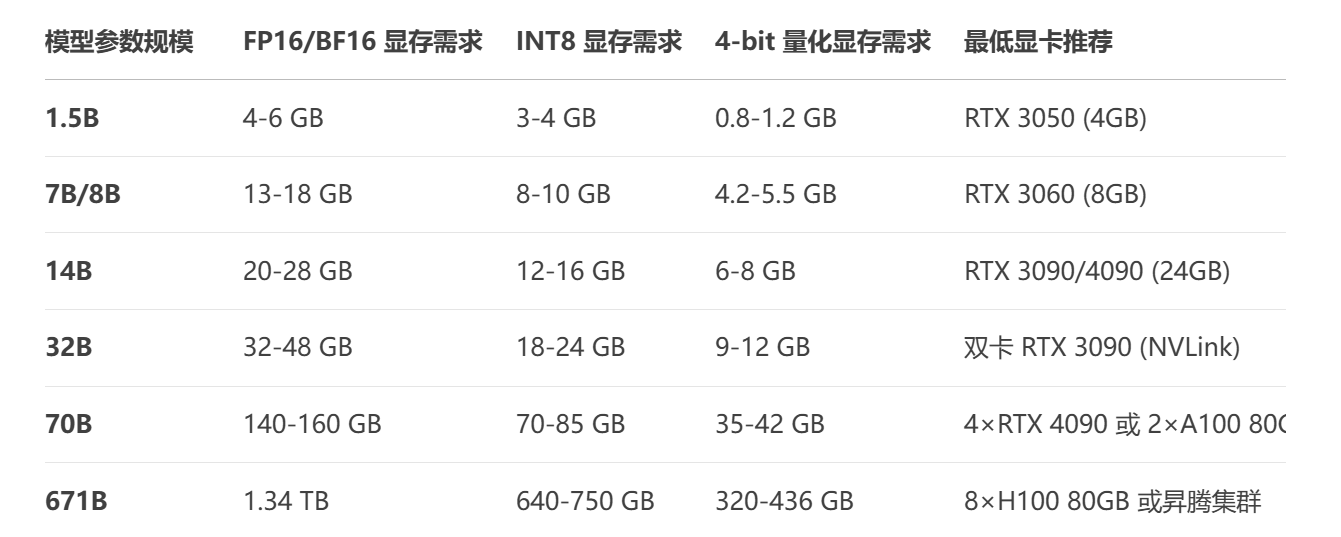
2.下载ollama
下载地址 https://ollama.com/download
下载完成后运行自己选择的模型

二、LLaMA Factory微调
安装部署LLaMA Factory
1.环境准备
# 更新系统sudo apt update && sudo apt upgrade -y# 安装基础依赖sudo apt install -y git python3-pip python3-venv build-essential# 安装CUDA工具包 (Ubuntu)wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pinsudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/3bf863cc.pubsudo add-apt-repository \"deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/ /\"sudo apt install -y cuda-12-22.创建虚拟环境
python3 -m venv llama-envsource llama-env/bin/activate3.安装PyTorch
# 选择与CUDA版本匹配的PyTorchpip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu1214.安装LLaMA Factory
# 克隆仓库git clone https://github.com/hiyouga/LLaMA-Factory.gitcd LLaMA-Factory# 安装核心依赖pip install -e .[deepspeed,metrics]# 安装可选加速组件pip install flash-attn --no-build-isolation # GPU加速pip install bitsandbytes # 量化支持5.验证安装
# 检查CUDA可用性python -c \"import torch; print(torch.cuda.is_available())\"# 测试命令行工具llamafactory-cli --version# 启动Web UI测试python src/train_web.py访问 http://localhost:7860 应看到Web界面
- 详细步骤可以参考链接: 官方文档
- 或者 参考https://blog.csdn.net/python12345_/article/details/148426568
LLaMA Factory的使用
1.总体预览
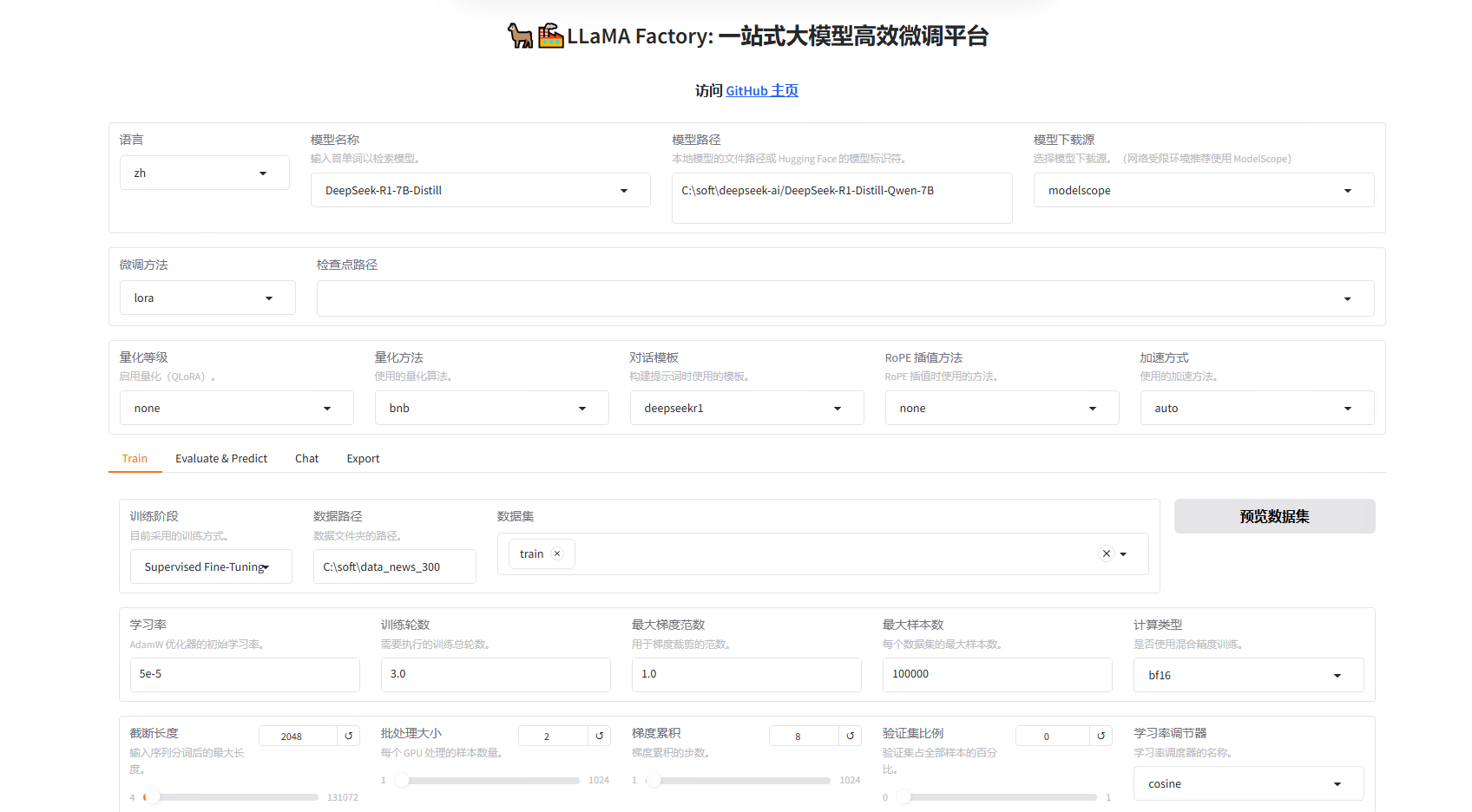
该页面展示了控制台的总体布局。上半部分可视为总体设置区域,涵盖了语言设置、模型选择、微调方法、量化参数、对话模板以及加速方式等内容。
在总体设置中,用户通常需要指定模型名称、路径以及所采用的微调方法。这里我选择的是DeepSeek-R1-7B-Distill,模型下载源是modelscope,训练方式选择的lora,下面对三种训练方式分别做出解释。
Full 是全参数微调,意思是把模型所有的权重都放开,用新数据从头到尾训练一遍。这种方法训练效果好,但是所需资源量非常大。
Freeze 是冻结微调,意思是冻结模型的大部分底层参数,比如前 80% 的层,只训练顶部的几层。这种方法使用的数据量比较少,适合微调简单的任务,比如简单的文本分类等等。
LoLoRA 中文叫低秩自适应,其原理是不修改原模型参数,而是插入低秩矩阵(理解为轻量级的适配层),只训练这些新增的小参数。优点是超级省资源,且效果很好,解决 Full 微调太耗费资源的问题。但对于用户的要求较高,需要充分理解每个参数的含义和效果。
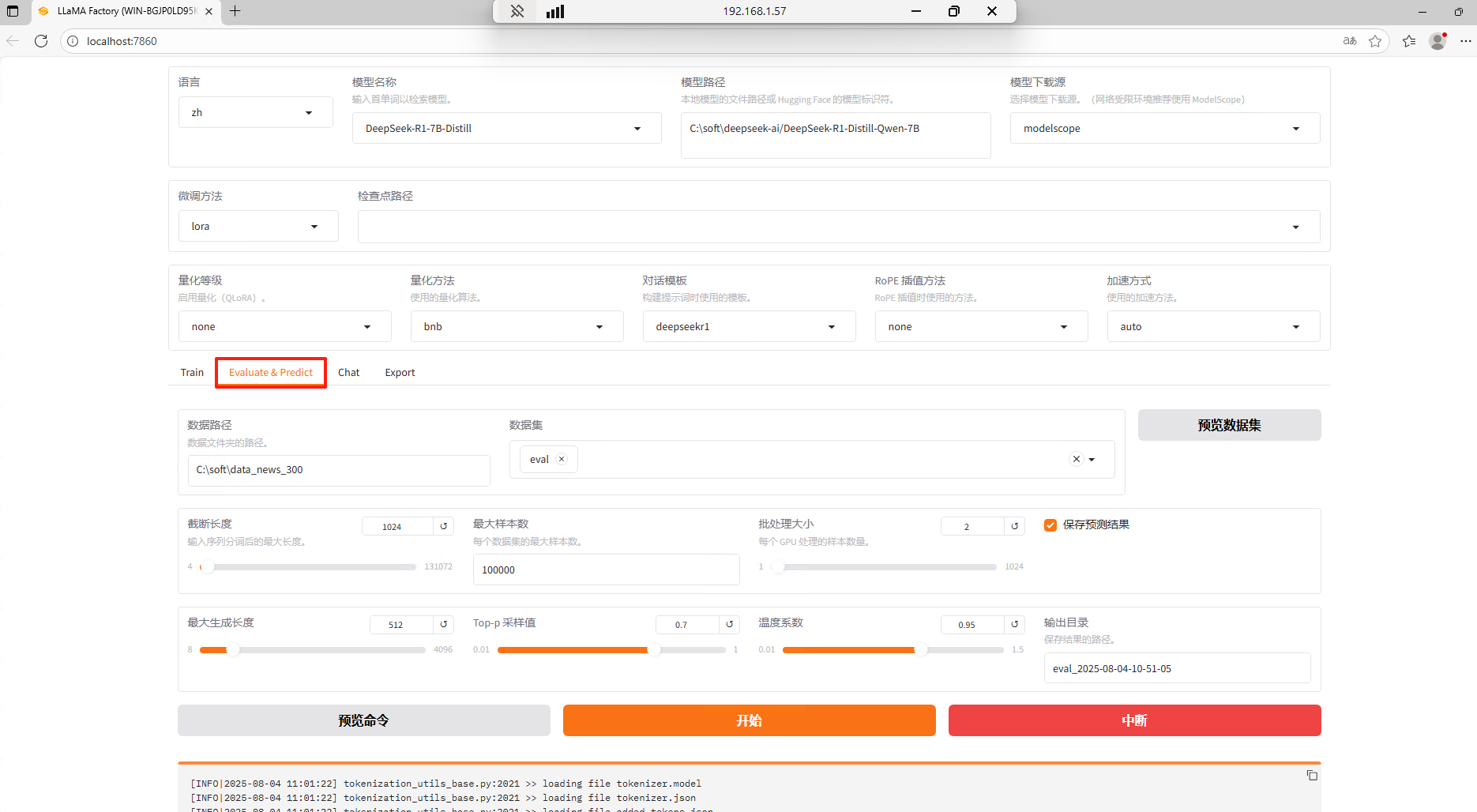
下半部分则由具体的功能菜单组成,分别为:训练(Train)、评估与预测(Evaluate & Predict)、对话(Chat)及导出(Export)四个功能模块。
2.数据集
需要准备三个数据集,分别是dataset_info.json,train.json,eval.json。
dataset_info的作用是建立数据集文件与预处理格式之间的映射关系,让框架知道如何处理不同的数据集文件。
train.json的作用是模型学习的\"教科书\",包含最大量样本(如 10,000+ 条),覆盖所有需要学习的知识领域。
eval.json的作用是模型能力的\"考场\",独立于训练集(无重叠样本),反映真实场景数据分布。
#train.json文件示例[ { \"conversations\": [ { \"from\": \"human\", \"value\": \"华中科技大学博士生培养目标中,对学术能力和专业能力分别提出哪些具体要求?\" }, { \"from\": \"gpt\", \"value\": \"\\n华中科技大学博士生培养目标中对学术能力和专业能力的具体要求如下:\\n\\n**学术能力要求**:\\n- 掌握本学科或专业领域坚实宽广的基础理论和系统深入的专门知识;\\n- 具有独立从事科学研究的能力;\\n- 具备良好的写作和国际学术交流能力;\\n- 能够在科学研究领域作出创新性研究。\\n\\n**专业能力要求**:\\n- 具有独立承担专业工作的能力;\\n- 对于专业学位博士生,重点培养其通过专业实践掌握独立承担专业工作的能力。\" } ] }, { \"conversations\": [ { \"from\": \"human\", \"value\": \"华中科技大学博士生的学习年限依据哪项具体规定执行?\" }, { \"from\": \"gpt\", \"value\": \"\\n华中科技大学博士生的学习年限依据《华中科技大学研究生学籍管理规定》执行。\" } ] }, ... ]对应的dataset_info文件为
{ \"dataset_info\": { \"file_name\": \"dataste_info\", \"formatting\": \"sharegpt\" }}然后将存放dataset_info.json,train.json,eval.json的文件夹地址放在数据路径中,数据集选择train。
训练过程中会显示显存的占用
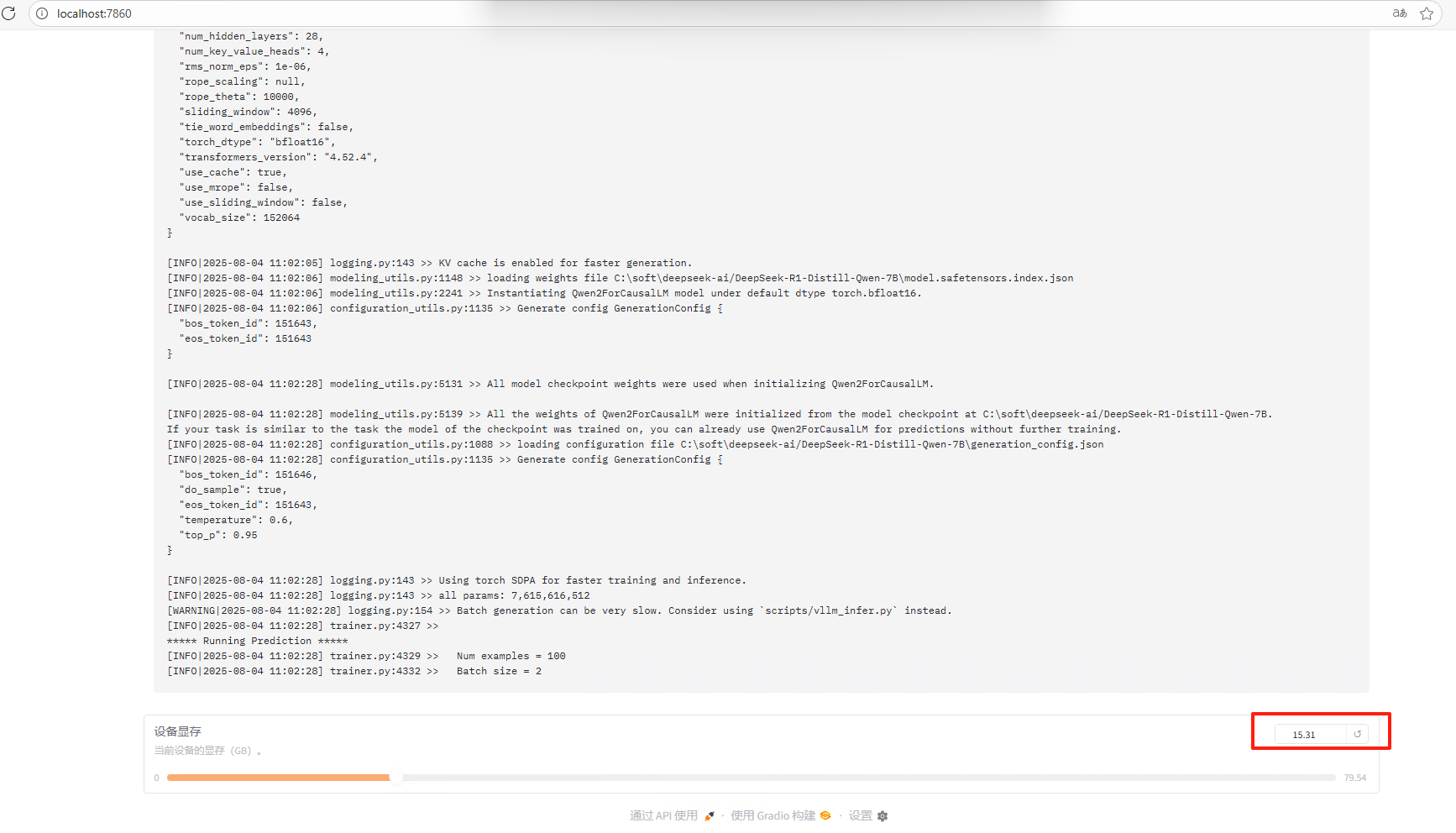
训练完成后进入eval模块,选择eval数据集进行评估,看看训练的结果如何
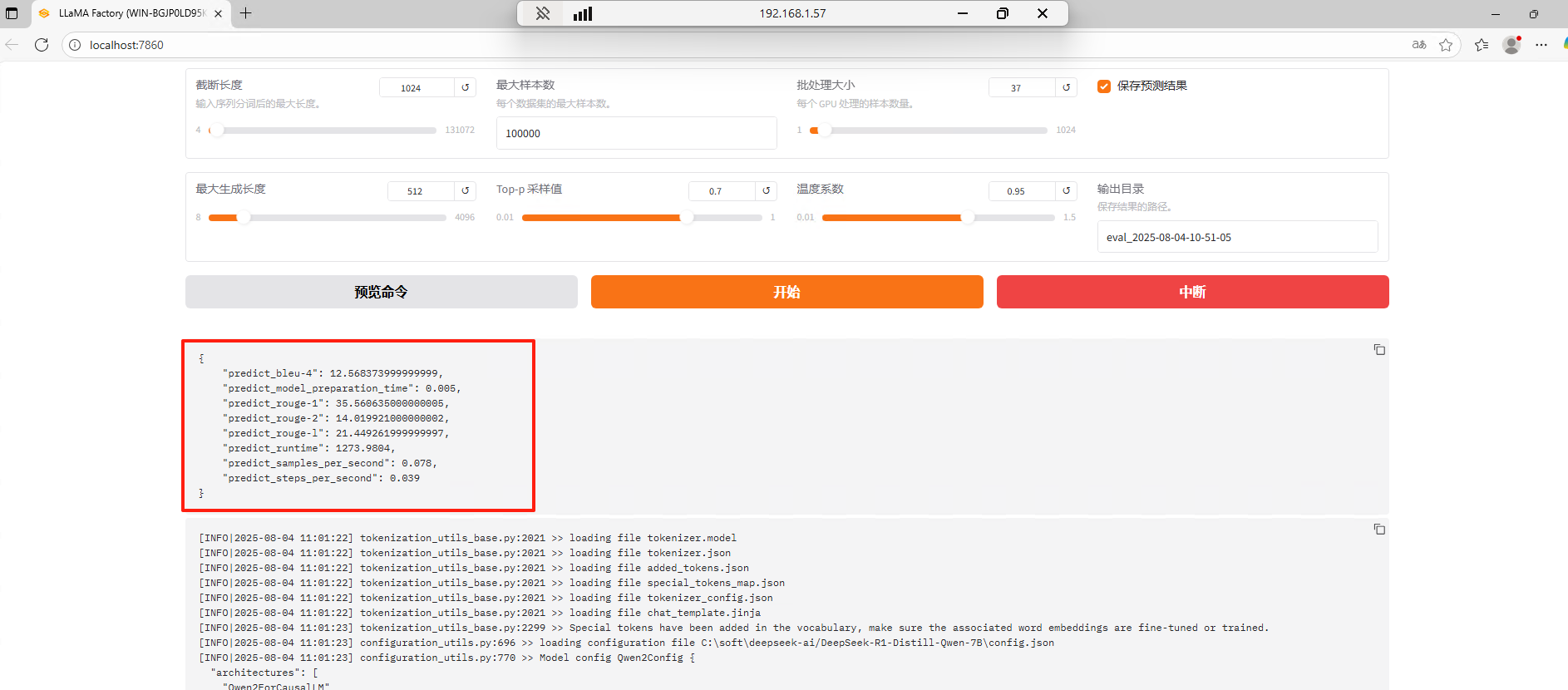
-
- predict_bleu-4: 12.568
BLEU-4:机器翻译/文本生成的标准评估指标
计算原理:比较模型生成文本与参考答案的4-gram重叠度
解读:
范围0-100,越高越好
12.57 属于中等偏低水平(专业模型通常在20-40之间)
表示生成内容与参考答案的词语匹配度一般
- predict_bleu-4: 12.568
-
- predict_rouge-1: 35.56
ROUGE-1:评估生成文本与参考答案的unigram(单字)相似度
解读:
35.56 表示约35.6%的关键词匹配
反映基础信息覆盖能力
- predict_rouge-1: 35.56
-
- predict_rouge-2: 14.02
ROUGE-2:评估bigram(双字组合)相似度
解读:
14.02 显著低于ROUGE-1
表明短语级表达能力较弱(如专业术语组合不准确)
- predict_rouge-2: 14.02
-
- predict_rouge-l: 21.45
ROUGE-L:基于最长公共子序列的流畅度评估
解读:
21.45 是核心指标
反映生成文本的连贯性和逻辑性
低于25说明存在语句断裂或逻辑跳跃问题
- predict_rouge-l: 21.45
最后可以进入chat模块,看看最终训练出来的模型使用起来怎么样,你可以问一些,数据集中的问题,看看他的回答与数据集中的答案差别大不大。
3.参数说明
-
学习率
是什么:模型权重在每次优化步骤中更新的步长大小。它是优化算法(如AdamW)中最重要的超参数之一。
作用:
控制更新幅度:学习率决定了模型根据计算出的梯度(误差的反向传播)调整自身权重的幅度。
影响收敛速度和稳定性:
过大: 可能导致优化过程在最优解附近震荡甚至发散,无法收敛,训练损失剧烈波动。
过小: 导致训练过程非常缓慢,需要更多epoch才能收敛,甚至可能陷入局部极小值。
典型值范围: 对于微调大模型(尤其是使用LoRA时),通常使用较小的学习率,例如 1e-4, 5e-5, 2e-5, 1e-5。LoRA模块的学习率有时可以比基础模型的学习率稍大。 -
最大梯度范围
是什么:梯度裁剪的阈值。在反向传播计算出每个参数的梯度后,如果梯度的范数(L2 norm)超过这个阈值,则将所有梯度按比例缩放到该范数等于阈值。
作用:
防止梯度爆炸: 这是训练深度神经网络(尤其是RNN/LSTM/Transformer)时的常见技术。当网络层数很深或某些层的激活值很大时,反向传播计算的梯度可能会变得极其巨大(爆炸),导致优化过程不稳定甚至数值溢出。梯度裁剪通过限制梯度的最大幅度来有效缓解这个问题,提高训练的稳定性。
通常不影响性能: 只要阈值设置得不是过于严格(如非常小),它主要起到稳定训练的作用,对最终模型性能影响不大。
典型值: 常用值如 1.0, 0.5, 2.0。这是一个相对鲁棒的超参数。 -
梯度累积
是什么: 在更新模型权重之前,连续进行多个前向传播和反向传播步骤(accumulation_steps),并将这些步骤计算出的梯度累加起来。
作用:模拟更大的批大小: 假设实际批大小是 micro_batch_size,梯度累积步数是 accumulation_steps,那么等效的批大小就是 micro_batch_size * accumulation_steps。
解决显存限制: 这是梯度累积最主要的目的。当GPU显存不足以容纳所需的大批量数据时,可以通过使用较小的 micro_batch_size 并设置 accumulation_steps > 1 来累积梯度,达到与大批次训练相似的优化效果(梯度噪声更小),同时降低单步显存需求。
影响优化稳定性: 累积后的梯度相当于在更大的批次上计算出来的,因此噪声更小,优化方向更准确,通常能带来更稳定的训练和可能更好的泛化性能。但这也会使每次权重更新的间隔变长。
如何工作:
前向传播一个小批次(micro batch),计算损失。
反向传播计算该小批次的梯度(但不立即更新权重!)。
将梯度累加到总梯度中。
重复步骤1-3 accumulation_steps 次。
用累积的总梯度进行一次权重更新(优化器step)。
清零累积的梯度,开始下一个累积循环。 -
LoRA+ 学习率比例
是什么:这是LoRA+技术引入的一个特定超参数。在标准的LoRA微调中,通常对所有LoRA模块使用同一个学习率。LoRA+的核心思想是:对LoRA的 A 矩阵使用一个(通常更小的)学习率,对 B 矩阵使用另一个(通常更大的)学习率。lr_ratio 通常指的就是 lr_B / lr_A 这个比例。
作用:
更优的参数更新策略: 论文研究发现,在LoRA分解 W = W0 + BA 中,对低秩矩阵 B 使用比 A 更大的学习率,可以显著提升微调效果和稳定性。
理论依据: 这源于对优化过程的理论分析,表明 B 的梯度范数通常远小于 A 的梯度范数。对 B 使用更大的学习率有助于平衡两者的有效更新步长。
提升性能: 相比所有LoRA参数使用单一学习率,LoRA+通常能获得更好的下游任务性能。
典型设置: 论文建议 lr_B = lr_A * lr_ratio,其中 lr_ratio 通常设置为一个较大的值,例如 16 或 32。例如,设置 lr_A = 1e-5, lr_ratio = 32,则 lr_B = 3.2e-4。
微调的核心目标是通过调整模型参数使损失函数最小化


