全面探索Kafka可视化客户端:管理与监控Kafka集群
本文还有配套的精品资源,点击获取 
简介:Kafka可视化客户端是一款提供图形用户界面的强大工具,旨在帮助用户轻松管理和监控Apache Kafka集群。作为大数据实时处理、日志收集和消息传递的分布式流处理平台,Kafka以其高吞吐量、持久化存储、分区与复制和容错性著称。该客户端支持主题管理、消费者监控、生产者监控、集群健康检查、安全配置、实时监控、日志查看、导入导出、定制化视图和报警设置。跨平台支持使得它可以在不同操作系统上运行,极大地简化了Kafka的日常管理任务,并为初学者提供了一个理解Kafka集群运作机制的直观工具。
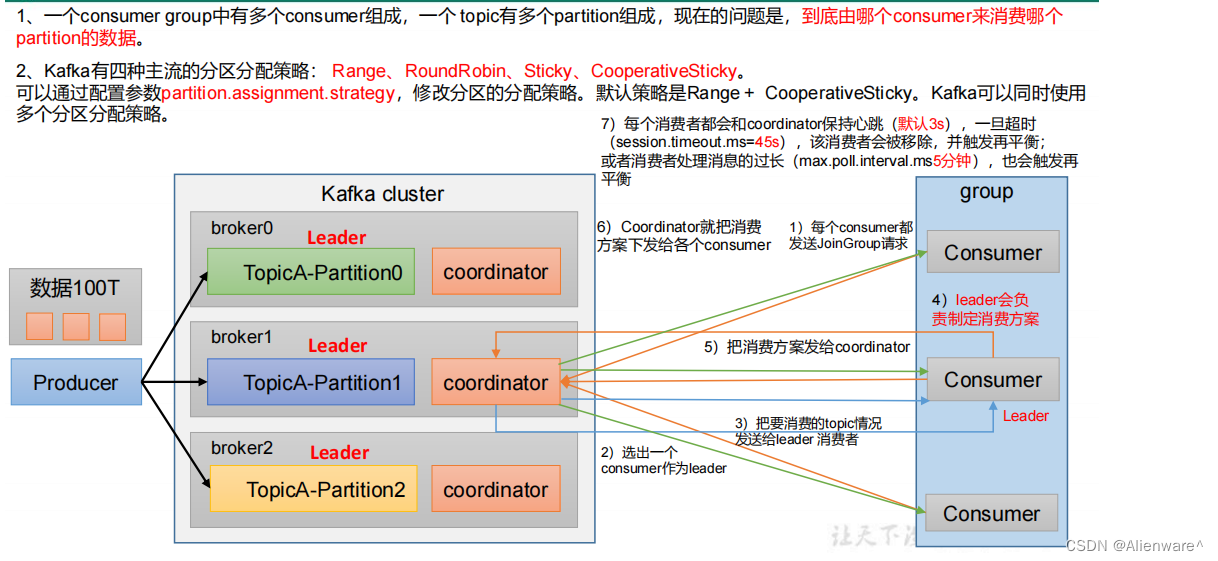
1. Kafka的分布式流处理特性
Apache Kafka是一个分布式流处理平台,它具备高性能、可扩展性和可靠性等优点。在企业级应用中,Kafka常被用于构建实时数据管道和流应用程序。它允许发布和订阅记录流,这些记录流通常被称作主题(Topics)。Kafka分布式处理的核心在于它能够横向扩展,同时在多个系统之间高效地传输大量数据。
分布式流处理意味着Kafka可以在多个服务器上并行处理数据,提供容错性和高可用性。Kafka集群中包含多个代理(Brokers),生产者(Producers)将数据发送到代理,消费者(Consumers)从代理读取数据。通过分区(Partitions),Kafka能够在多个消费者之间分配负载,提高处理能力。
Kafka不仅保证了消息的顺序性,还提供了强大的消息持久性保障。消息在被消费前会持久化存储,即使在系统故障之后也能够保证消息不会丢失。这一切使得Kafka成为处理实时数据流的理想选择,支持复杂的数据处理任务,比如数据集成、日志聚合、事件源等场景。
2. Kafka可视化客户端的图形用户界面
在分布式系统中,复杂的数据流和处理逻辑需要通过直观的方式呈现,以便用户更好地理解和操作。Kafka可视化客户端的图形用户界面(GUI)就是为此目的而设计。它提供了图形化的操作界面,不仅让主题管理、生产者与消费者的监控变得更简单,而且对于集群状态的检查也更加直观易懂。
2.1 用户界面设计原则
在开发任何类型的GUI时,设计原则至关重要。良好的用户界面设计可以提升用户体验,使得操作更为直观,降低用户的学习成本。
2.1.1 界面布局与交互逻辑
Kafka可视化客户端的界面布局应当遵循直观、清晰的原则。用户能够快速找到他们需要的功能模块,并且在进行操作时,界面的反馈迅速且准确。布局应优先考虑内容的重要性,常用功能应放在显眼的位置,而较少使用的功能可以置于二级界面或隐藏起来。
界面的交互逻辑应该是符合直觉的。比如,创建一个新主题的按钮就应该在用户处理的主题列表旁边,而删除操作可以通过右键快捷菜单触发。这样可以让用户在不需要额外学习的情况下,理解并使用这些功能。
2.1.2 界面美观与用户体验
在界面美观方面,设计应该简洁而不简单,既不显得过于单调,也不应该过分花哨。颜色、字体和图标都应该协调一致,确保用户在长时间使用过程中不会感到视觉疲劳。
用户体验是界面设计中的核心。优化用户体验要求设计师站在用户的角度思考,通过持续的用户反馈来改进界面。例如,加载时间的优化、操作的简化和提示信息的准确性都是提升用户体验的关键点。
2.2 功能模块的可视化呈现
为了有效管理Kafka集群,可视化客户端会将功能模块划分开来,以便用户可以轻松地访问。
2.2.1 主题管理的可视化
主题是Kafka消息传递中的核心概念,它们的管理和维护对于整个系统的健康运行至关重要。
操作流程与注意事项:
可视化客户端会提供一个主题列表,用户可以在这个列表上进行操作。创建新主题时,用户可以选择分区数、副本数以及键值对的数据格式等参数。在删除主题时,需要提供额外的确认步骤,避免意外删除重要主题。
批量管理与命名规则:
除了单独管理每个主题之外,还应该提供批量操作的功能,例如批量删除或修改主题配置。命名规则方面,客户端应该对用户输入的主题名称进行校验,确保它们符合Kafka的命名约定,并且在尝试创建一个已存在主题时提供适当的反馈。
2.2.2 监控数据的图表展示
监控数据的图表展示是可视化客户端中极具价值的功能。它可以实时显示消息流量、延迟和系统负载等信息,使用户能够快速诊断问题所在。
实现该功能的示例代码块:
// Java code snippet for a simple Kafka consumer monitoring tool using JFreeChart for data visualization// Note: This is a simplified example for illustration purposes onlyimport org.jfree.chart.ChartFactory;import org.jfree.chart.ChartPanel;import org.jfree.chart.JFreeChart;import org.jfree.data.time.TimeSeriesCollection;import org.jfree.data.time.TimeSeries;// Assuming we have data collection logic that fetches data from Kafka and stores it in a TimeSeries object.TimeSeriesCollection dataset = new TimeSeriesCollection();TimeSeries topicDataSeries = new TimeSeries(\"Topic Data\");dataset.addSeries(topicDataSeries);// Populate the series with data fetched from Kafka, e.g., messages processed per second// ...// Now create a chart based on the datasetJFreeChart chart = ChartFactory.createTimeSeriesChart( \"Kafka Consumer Performance\", // Title \"Time\", // X-Axis Label \"Messages Per Second\", // Y-Axis Label dataset, // Dataset true, // Legend true, // Tooltips false // URLs);ChartPanel chartPanel = new ChartPanel(chart);// Add the chartPanel to a JFrame or a JPanel to display the chart in a GUI图表展示的扩展性说明:
以上代码示例展示了如何使用JFreeChart库在Java应用程序中创建一个时间序列图表。该图表能够展示从Kafka获取的性能监控数据,例如每秒处理的消息数量。通过这种方式,我们可以将数据可视化,帮助用户直观地理解生产者和消费者的行为。
图表中的关键点在于:
- 数据收集 :监控数据需要通过程序代码从Kafka集群中定期收集。
- 数据表示 :图表需要正确地反映数据的变化,例如使用不同的颜色或标记来表示不同的监控指标。
- 交互性 :高级的可视化工具可能还包括交互性功能,如缩放、点击图表中的点来查看详细信息等。
以上是Kafka可视化客户端功能的一个缩影。接下来的章节将深入探讨如何通过图形化界面更有效地管理Kafka主题,以及如何监控生产者和消费者,确保集群的健康运行。
3. 主题管理功能详解
Apache Kafka作为一个分布式流处理平台,提供了一套完整的主题管理机制,允许用户灵活地创建、维护和删除主题。主题是Kafka用于分离消息流的顶级容器,是构建流处理应用程序的基础。本章节将详细介绍如何在Kafka中有效地管理主题,包括创建、删除、分区和复制等操作,以及相应的操作流程、注意事项和优化策略。
3.1 主题的创建与删除
3.1.1 操作流程与注意事项
创建Kafka主题是一项基础任务,可以通过命令行工具 kafka-topics.sh 来完成。以下是创建主题的典型命令格式:
kafka-topics.sh --create --topic --partitions --replication-factor --zookeeper 在执行创建主题的操作时,有几个重要的参数需要考虑:
-
-
-
-
创建主题时,需要考虑以下注意事项:
- 分区数 : 分区数一旦设定,就无法在不停机的情况下修改。因此,选择合适的分区数非常重要,需要根据当前和预期的生产者和消费者数量来决定。
- 副本因子 : 确保副本因子不超过集群中可用的brokers数量。副本因子为1意味着没有数据冗余,任何broker的失败都会导致数据丢失。
- 配置一致性 : 使用相同的参数创建所有主题,以确保整个集群的配置一致性,避免产生管理上的混乱。
- 幂等性与事务 : 考虑是否需要启用幂等性和事务支持,这将影响主题的创建参数。
3.1.2 批量管理与命名规则
批量管理主题能够提高管理效率,特别是在拥有大量主题的生产环境中。Kafka提供了一些工具和脚本来支持批量操作,比如使用 kafka-configs.sh 来批量更改配置,或者利用JMX接口通过编程方式来管理主题。
在命名主题时,应遵循一定的命名规则以保持命名的清晰和一致性。命名规则应考虑到以下几个方面:
- 目的性 : 主题名称应直观地反映其用途或承载的数据类型。
- 唯一性 : 主题名称在整个Kafka集群中必须是唯一的。
- 可读性 : 命名应易于理解和记忆,避免使用过长或不明确的字符串。
- 自动化 : 如果可能,命名规则应能适用于自动化脚本,以减少人为错误和提高效率。
# 示例:使用脚本批量创建主题for i in {1..10}; do kafka-topics.sh --create --topic topic-$i --partitions 3 --replication-factor 2 --zookeeper localhost:2181done3.2 主题的分区和复制
3.2.1 分区策略与优化
分区是Kafka高吞吐量的关键,它们将消息分配到不同的分区中,从而允许并行处理。分区策略的优劣直接影响到生产者和消费者的性能。
Kafka默认使用轮询策略分配消息到分区,但是也可以根据消息的key进行哈希来分配,以保证具有相同key的消息总是被发送到同一个分区。分区策略的选择应根据消息的使用模式来决定。
分区优化主要关注以下几点:
- 负载均衡 : 确保每个分区都有均衡的消息流量,避免某些分区的负载过重而影响整体性能。
- 数据大小 : 考虑到分区过多可能导致管理上的复杂性,分区的数量应与消息大小相匹配,以避免创建过大的分区。
3.2.2 复制因子的作用与调整
复制因子表示一个主题的分区在不同brokers上的副本数量。复制因子对于确保数据的可靠性和高可用性至关重要。
设置合适的复制因子需要权衡数据的安全性和系统的性能。高复制因子意味着更高的数据可靠性,但也会增加存储空间的使用并影响写入性能。通常情况下,复制因子设置为3是一个比较常见的选择,因为它既可以容忍单个节点的失败,也能够保证数据的高可用性。
在运行时,复制因子可以通过Kafka管理工具动态调整:
# 增加主题的副本因子kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file increase-replication-factor.json --execute调整复制因子的操作会涉及到数据的重新复制,因此在进行此操作时需要谨慎,并确保集群有足够的资源来处理额外的负载。
通过本章节的介绍,我们深入理解了Kafka主题管理的基本操作及其背后的原理,包括创建和删除主题、分区和复制的相关策略与优化技巧。在下一章节,我们将继续探讨如何对消费者和生产者进行有效的监控,以确保Kafka集群的高效运转。
4. 消费者与生产者监控功能
在构建和维护高可用的Kafka集群时,监控生产者和消费者的行为至关重要。通过监控可以保证数据流的顺畅,及时发现和解决性能瓶颈,以及确保集群的稳定运行。本章将深入探讨消费者与生产者的监控功能,包括性能监控、负载均衡分析以及状态检查等方面。
4.1 生产者性能监控
生产者是Kafka中用于发送消息到主题的客户端。有效的监控生产者的性能,可以帮助我们了解消息发送的速率,并确保消息可以被快速而可靠地发送到Kafka集群。
4.1.1 消息发送速率监控
生产者的性能监控中,消息发送速率是一个核心指标。速率的监控可以帮助我们了解生产者是否能够满足业务负载的要求,以及是否存在潜在的性能瓶颈。
graph TD; A[开始监控生产者性能] --> B{消息发送速率}; B --> |速率过低| C[分析网络延迟]; B --> |速率不稳定| D[检查生产者配置]; B --> |速率过高| E[监控系统资源使用情况];kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group producer-group该命令将提供当前生产者组的详细信息,包括当前的消费偏移量和滞后信息。通过查看滞后信息,我们可以判断生产者是否能够及时地发送消息到Kafka。
4.1.2 生产者负载均衡分析
除了监控消息发送速率之外,生产者负载均衡分析也非常重要。理想的生产者应该是均匀地向Kafka集群的所有分区发送消息,以充分利用集群的资源并防止某些分区过载。
kafka-producer-perf-test.sh --topic test-topic --num-records 100000 --record-size 1024 --throughput 10000 --producer.config producer.properties通过上述命令,我们可以对生产者发送消息的吞吐量进行测试。测试结果能够帮助我们评估生产者是否在合理地利用集群资源。
4.2 消费者性能监控
消费者在Kafka中负责从主题中读取消息。监控消费者性能,可以帮助我们确保消息能够被及时且均衡地消费。
4.2.1 消费速率与滞后分析
消费者的性能监控中,消费速率与滞后是两个重要的指标。消费速率可以告诉我们消费者是否能够跟上生产者的发送速率,而滞后分析则可以反映消费者处理消息的效率。
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group consumer-group通过此命令,我们可以获取消费者组的消费进度和滞后情况。滞后数据可以帮助我们判断消费者是否能够及时处理消息。
4.2.2 消费者组的状态检查
消费者组的状态检查是消费者性能监控的另一个重要方面。消费者组的状态可能会经历 Stable , Empty , Dead 等状态,这些状态信息对于诊断消费者问题至关重要。
graph LR; A[开始检查消费者组状态] --> B{查询消费者组列表}; B --> C[获取活跃消费者列表]; C --> D[检查消费者状态]; D --> |活跃| E[监控消费速率]; D --> |空闲| F[分析消费者任务分配]; D --> |死亡| G[重新启动消费者进程];通过上述流程,我们可以确保消费者组保持在健康的状态,并且能够高效地完成消费任务。
在本章节中,我们详细讨论了如何通过Kafka提供的工具和命令来监控消费者与生产者的性能。我们分析了消息发送速率、负载均衡、消费速率与滞后以及消费者组状态等方面的内容,并提供了实际操作中使用的关键命令。通过这些监控实践,我们能够及时识别和解决潜在的性能问题,确保Kafka集群的高效与稳定。
5. Kafka集群健康状态的可视化检查
5.1 集群状态概览
5.1.1 节点存活与角色分布
Kafka集群健康状态的可视化检查是确保消息队列稳定性的重要组成部分。在可视化工具中,集群状态概览通常是第一个展示的信息面板。节点存活信息提供了一个实时的集群健康视图,通常通过一个彩色的环状图或者列状图来展示每个节点的存活状态。绿色代表正常,红色代表宕机或无法连接,黄色则可能是警告状态,表示可能存在性能问题或即将宕机。
角色分布对于理解Kafka集群的工作方式至关重要。一个典型的Kafka集群可能包括以下角色:Broker、Zookeeper、Controller等。通过可视化工具,可以清晰地看到每个节点扮演的角色,以及它们之间的交互关系。例如,Broker数量和它们的分区分配情况,以及Zookeeper集群的状态和网络分布图。
5.1.2 磁盘空间与流量监控
磁盘空间是确保消息持久化的基础。在Kafka集群中,一旦磁盘空间不足,可能会导致消息丢失或者集群不可用。可视化检查工具能够实时监控磁盘使用情况,并通过图表直观显示磁盘空间的使用率。这通常涉及两个重要的指标:总体磁盘空间使用率和分区级别的磁盘空间使用率。
流量监控是检查集群负载情况的重要手段。通过可视化工具,可以监控到流入和流出集群的网络流量。这通常以实时图表的形式展现,如折线图或柱状图,实时反映数据的传输速率。这有助于及时发现网络瓶颈和异常流量,从而做出调整。
5.2 集群性能分析
5.2.1 端到端延迟分析
端到端的延迟是指从生产者发送消息到消费者接收消息的整个时间周期。这一指标对于了解整个消息处理的效率至关重要。性能分析工具中,通常会有一个专门的端到端延迟视图,以图形的方式展示延迟的统计信息。这个图表可能是动态更新的,能即时反映出延迟的变化情况,并且可以通过设置阈值来标识异常延迟情况。
此外,延迟分析不仅关注总体延迟,还可以深入到各个主题、分区乃至特定的消息级别,这有助于定位问题的具体范围。例如,如果发现某个主题的延迟异常,进一步的检查可以聚焦在该主题的特定分区,甚至具体到某些消息批次上。
5.2.2 网络流量与I/O吞吐量
网络流量和I/O吞吐量是衡量Kafka集群性能的关键指标。网络流量可以反映出集群内部和外部数据流动的速率和量级。可视化工具通常会提供实时的网络流量监控视图,展示流入和流出集群的数据量。这种监控对于分析网络拥塞、预测可能的瓶颈以及进行性能优化都非常重要。
I/O吞吐量直接关联到磁盘的读写速度,影响消息处理的效率。一个高效的可视化工具会提供一个实时的I/O吞吐量视图,展示读写操作的次数以及每秒处理的数据量。通过这个视图,运维人员能够及时发现I/O性能瓶颈,进而进行硬件升级或者配置调整。
接下来,我们将深入分析Kafka集群健康状态检查的实践操作,以及如何通过可视化工具监控和优化Kafka集群的性能。
graph LR A[集群状态概览] -->|节点存活| B[节点存活检查] A -->|角色分布| C[角色分布监控] D[集群性能分析] -->|端到端延迟| E[延迟分析图表] D -->|网络流量| F[流量监控视图] D -->|I/O吞吐量| G[I/O吞吐量视图]在上述流程图中,展示了集群状态概览和集群性能分析两个主要部分,以及它们各自关注的关键指标和相关视图。通过这样的布局,管理员可以快速定位并分析集群的状态和性能。
下面的代码块显示了一个简单的Kafka集群状态查询命令及其输出。这个命令会查询集群的状态信息,包括每个节点的ID、主机名、端口号、状态以及所承载的分区数量。
$ kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group example-groupGROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-IDexample-group topic1 0 3 3 0 consumer-1 /127.0.0.1 consumer-1example-group topic1 1 2 2 0 consumer-2 /127.0.0.1 consumer-2 输出结果解释:
- GROUP 是消费者组的名称。
- TOPIC 是消费者组订阅的主题。
- PARTITION 是主题的分区号。
- CURRENT-OFFSET 是消费者组在该分区上的当前消费位置。
- LOG-END-OFFSET 是该分区上的最新消息位置。
- LAG 是消费者组与分区末尾消息的差距。
- CONSUMER-ID 是消费者的唯一ID。
- HOST 是消费者运行的主机。
- CLIENT-ID 是消费者的客户端ID。
通过这些信息,管理员可以了解消费者的消费进度以及可能存在的滞后问题,从而采取相应的措施。
在下一节中,我们将探讨如何进一步深入到Kafka集群的内部工作原理,以及如何利用这些指标优化集群的性能和稳定性。
6. Kafka安全配置支持
在分布式消息系统中,保障数据的安全性是至关重要的环节。Apache Kafka提供了一系列安全配置支持,以确保数据传输和存储过程中的安全性。这包括了认证与授权机制的实施,以及通过安全审计来确保系统满足合规要求。
6.1 认证与授权机制
Kafka支持多种认证与授权机制,如SASL/SSL,来加强客户端与服务端之间通信的安全性,并实施细粒度的权限控制,以保证不同用户只能访问其被授权的数据资源。
6.1.1 SASL/SSL安全协议应用
- SASL (Simple Authentication and Security Layer) : Kafka通过SASL支持多种认证方式,如GSSAPI,PLAIN,SCRAM-SHA-256等。通过配置相应的认证方法,系统可以实现用户身份的验证。
- SSL (Secure Sockets Layer) : 为了数据传输的安全,Kafka支持使用SSL/TLS协议加密客户端与服务端之间的通信。配置SSL需要生成密钥和证书,这可以通过使用Java的keytool工具来完成。证书可以是自签名的,也可以是从证书颁发机构(CA)获取的。
下面是一个为Kafka生成自签名证书的keytool命令示例:
shell keytool -genkey -alias kafka-server -keyalg RSA -keysize 2048 -dname \"CN=Kafka Server,O=My Company,L=San Francisco,ST=California,C=US\" -keystore kafka.server.keystore.jks -validity 365
在Kafka配置文件 server.properties 中,以下参数用于配置SSL:
properties ssl.key.password=yourpassword ssl.keystore.location=kafka.server.keystore.jks ssl.keystore.password=yourpassword ssl.truststore.location=kafka.server.truststore.jks ssl.truststore.password=yourpassword
6.1.2 权限控制与访问策略
在Kafka中,可以使用ACL (Access Control Lists) 来进行细粒度的权限控制。管理员可以定义哪些用户可以执行哪些操作,比如发布、订阅消息。
ACL的配置包括主题、操作类型(如READ,WRITE),以及用户或用户组。通过以下命令可以设置ACL:
# 设置用户alice可以读取名为\"my-topic\"的主题kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --add --allow-principal User:alice --operation Read --topic my-topic 在配置文件 server.properties 中,可以设置一些默认的ACL策略:
super.users=User:admin6.2 安全审计与合规性
Kafka集群的运行日志、通信记录等信息对于审计和故障排查至关重要。此外,实现系统安全合规性是许多组织的法律义务。
6.2.1 审计日志的作用与管理
-
审计日志 : Kafka支持生成审计日志,以记录集群中发生的所有关键事件。这对于跟踪数据访问、验证系统安全策略的遵守情况以及进行问题排查非常有用。
-
日志管理 : 为了保证审计日志不被未授权访问,需要实施相应的访问控制策略。此外,日志的归档和管理策略也应考虑在内,比如定期清理旧日志。
6.2.2 遵循的行业安全标准
在不同的行业中,对于数据安全与隐私保护有着严格的规范和标准。如GDPR (欧盟通用数据保护条例)、HIPAA (美国健康保险流通与责任法案)等。
Kafka的设计允许符合这些标准的实现,比如通过SASL/SSL实现数据传输的安全,通过细粒度的权限控制来保证数据访问的合规性。管理员需要根据所在行业和组织的特定需求,配置相应的安全措施。
通过实施这些安全配置,Kafka集群能够更加安全地处理关键业务数据,同时也让组织能够更好地遵循相关法律法规,降低合规风险。
以上便是关于Kafka安全配置支持的内容,下一章将探讨如何在实际环境中对Kafka进行性能调优。
本文还有配套的精品资源,点击获取
简介:Kafka可视化客户端是一款提供图形用户界面的强大工具,旨在帮助用户轻松管理和监控Apache Kafka集群。作为大数据实时处理、日志收集和消息传递的分布式流处理平台,Kafka以其高吞吐量、持久化存储、分区与复制和容错性著称。该客户端支持主题管理、消费者监控、生产者监控、集群健康检查、安全配置、实时监控、日志查看、导入导出、定制化视图和报警设置。跨平台支持使得它可以在不同操作系统上运行,极大地简化了Kafka的日常管理任务,并为初学者提供了一个理解Kafka集群运作机制的直观工具。
本文还有配套的精品资源,点击获取


