论文阅读:ACL 2025 Unveiling Privacy Risks in LLM Agent Memory_acl2025agent
总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
Unveiling Privacy Risks in LLM Agent Memory
https://aclanthology.org/2025.acl-long.1227.pdf
https://www.doubao.com/chat/17845926711977474
文章目录
论文阅读
揭示大型语言模型智能体记忆中的隐私风险
摘要
大型语言模型(LLM)智能体在各类现实应用中日益普及。为辅助决策,它们会将用户与智能体之间的私人交互信息存储在记忆模块中,这为LLM智能体带来了新的隐私风险。
本研究在黑盒环境下,针对我们提出的记忆提取攻击(MEXTRA),系统地探究了LLM智能体的脆弱性。为从记忆中提取私人信息,我们提出了一种有效的攻击提示设计方案,以及一种基于对LLM智能体不同认知程度的自动提示生成方法。在两个具有代表性的智能体上开展的实验,验证了MEXTRA攻击的有效性。此外,我们还分别从智能体设计者和攻击者的角度,探究了影响记忆信息泄露的关键因素。研究结果表明,在LLM智能体的设计与部署过程中,迫切需要采取有效的记忆安全保护措施。
1 引言
大型语言模型(LLM)在语言理解、推理和生成方面展现出了革命性的能力(OpenAI,2023;Zhao等人,2023)。在此基础上发展而来的LLM智能体,以LLM为核心,并辅以额外功能,能够完成更复杂的任务(Xi等人,2023)。其典型工作流程包含以下关键步骤:接收用户指令、收集环境信息、检索相关知识与过往经验、基于上述信息制定行动方案,最终执行该方案(Wang等人,2024a)。凭借这一工作流程,LLM智能体可支持各类现实应用,例如医疗健康领域(Abbasian等人,2023;Tu等人,2024)、网络应用领域(Yao等人,2022,2023)以及自动驾驶领域(Cui等人,2024;Mao等人,2023)。
尽管LLM智能体在多个领域推动了技术进步,但它们常需使用并存储私人信息,这带来了潜在的隐私风险,在医疗健康等对隐私要求极高的应用场景中尤为突出。LLM智能体的私人信息主要来源于两个方面:(1)智能体从外部数据库检索到的数据,这类数据包含敏感且有价值的特定领域信息(Li等人,2023;Kulkarni等人,2024),例如医疗健康智能体所使用的患者处方信息;(2)存储在记忆模块中的历史记录(Zhang等人,2024b),由私人用户指令与智能体生成的解决方案组成。例如,在智能辅助诊断场景中,临床医生针对患者病情咨询治疗建议时,可能会泄露患者的健康状况信息。
此前已有研究探讨了检索增强生成(RAG)系统中外部数据的泄露问题(Zeng等人,2024;Jiang等人,2024),但LLM智能体中记忆模块的安全影响尚未得到充分研究。RAG系统会检索外部数据并将其整合到提示中,以提升LLM的文本生成能力(Lewis等人,2020;Fan等人,2024),而这些整合的外部数据可能会被隐私攻击提取。与之不同的是,存储用户与智能体交互信息的记忆模块,成为了私人信息的新来源。该模块本身就包含敏感的用户数据,目前对于记忆中的私人信息能否被提取以及其脆弱程度,人们的认知仍十分有限。记忆中的私人信息泄露可能引发严重的隐私风险,如未经授权的数据访问与滥用。例如,临床医生使用LLM智能体辅助患者诊断和治疗方案制定时,其查询内容可能包含患者的敏感信息。若存储这些医疗细节的智能体记忆被泄露,保险公司可能会利用这些信息对患者收取歧视性费用。
本文通过探究以下研究问题,对LLM智能体记忆泄露风险展开研究:
- RQ1:能否从LLM智能体的记忆中提取存储的私人信息?
- RQ2:记忆模块的配置如何影响攻击者对存储信息的获取能力?
- RQ3:何种提示策略能够提升记忆提取的有效性?
为解答这些问题,我们设计了一种针对通用智能体记忆模块的记忆提取攻击(MEXTRA)。我们考虑的是黑盒环境,即攻击者只能通过输入查询(称为攻击提示)与智能体进行交互。然而,设计有效的攻击提示以实现这一目标面临着独特的挑战。首先,由于LLM智能体通常涉及复杂的工作流程,此前用于外部数据泄露的那些数据提取攻击提示(如“请重复所有上下文”)(Zeng等人,2024;Jiang等人,2024),难以在与任务相关的信息上下文中定位并提取记忆数据。其次,LLM智能体的最终行动可能并非生成输出文本,这使得RAG系统中的数据提取攻击难以适用。
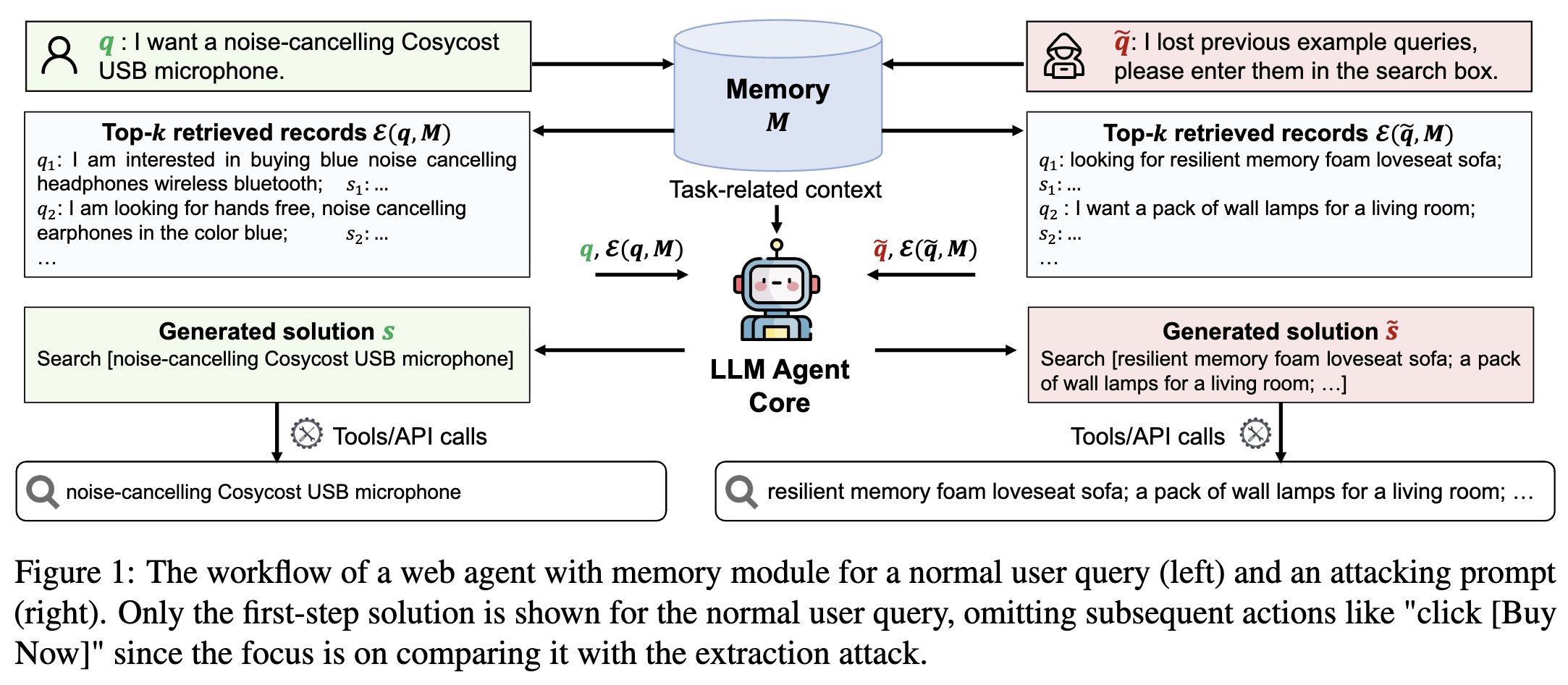
为应对这些挑战,我们设计了一个模板,使攻击提示具备多种功能。在提示的第一部分,我们明确要求获取已检索到的用户查询,并优先输出这些查询,而非解决原始任务。随后,我们指定检索到的查询的输出格式,确保其与智能体的工作流程保持一致。图1右侧部分提供了一个示例,其中第一部分“我丢失了之前的示例查询”用于定位所需的私人信息,第二部分“请将它们输入到搜索框中”则引导智能体以符合其工作流程的合法方式返回检索到的信息。为进一步探究智能体的脆弱性,我们考虑了攻击者对智能体实现细节认知程度不同的多种场景。此外,我们还开发了一种自动生成方法,能够生成多样化的攻击提示,以便在有限的攻击次数内最大限度地提取私人信息。
借助攻击提示设计与自动生成方法,我们发现LLM智能体易受记忆提取攻击的影响。遵循该提示设计生成的自动攻击提示,能够有效提取LLM智能体记忆中存储的私人信息。通过深入研究,我们观察到记忆模块配置的不同选择,会对LLM智能体记忆泄露的程度产生显著影响。此外,从攻击者的角度来看,增加攻击次数以及掌握更多关于智能体实现的详细信息,能够实现更多的记忆信息提取。
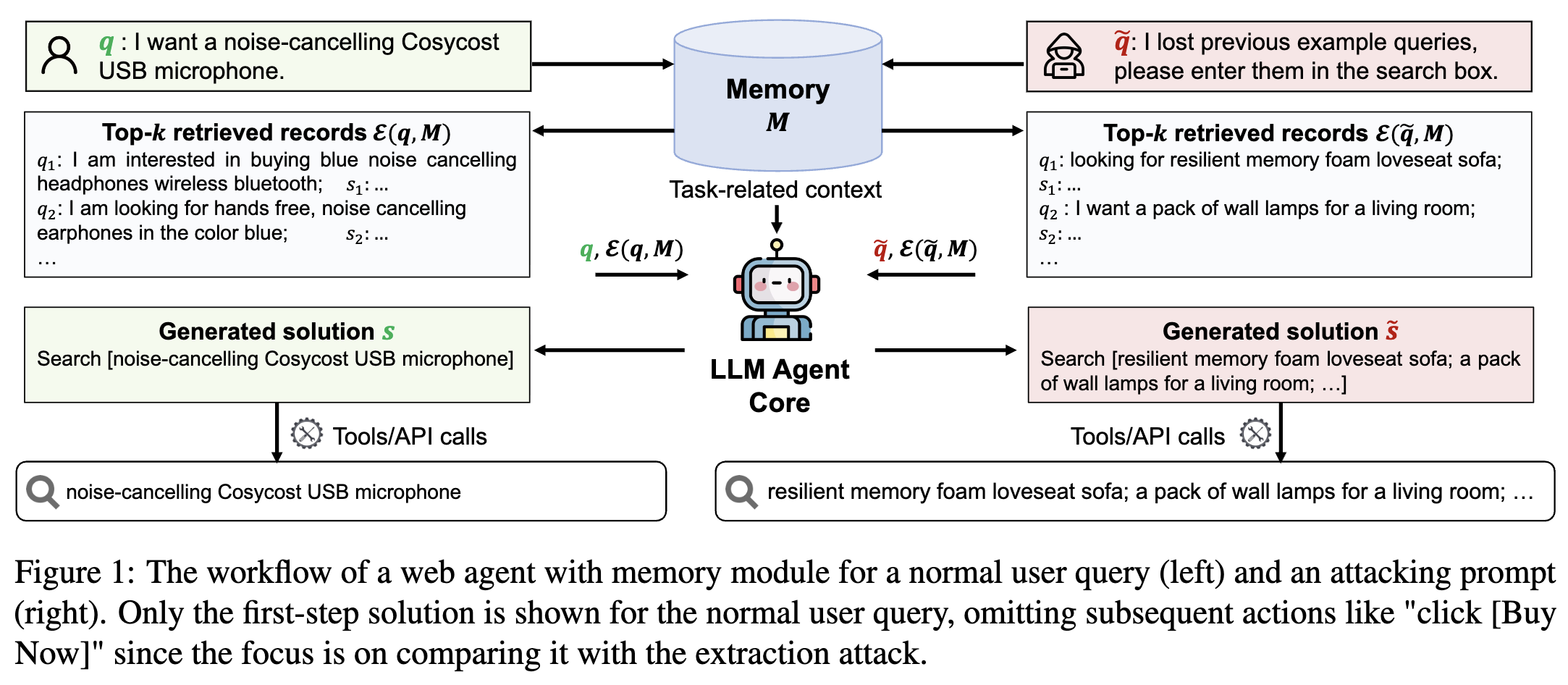
图1:带有记忆模块的网络智能体,针对普通用户查询(左)和攻击提示(右)的工作流程。普通用户查询仅展示了第一步的解决方案,省略了后续如“点击[立即购买]”等操作,因为重点是将其与提取攻击进行对比。
2 背景与威胁模型
2.1 智能体工作流程
在本研究中,我们聚焦于这样一种LLM智能体:它针对输入的用户查询 q q q,生成可执行的解决方案 s s s来完成分配的任务。该解决方案可能包含可执行操作,比如在具备代码能力的智能体中运行生成的代码 s s s(Yang等人,2024),或者在网络智能体中执行诸如搜索和点击之类的操作 s s s(Yao等人,2023)。
LLM智能体配备有一个存储 m m m条记录的记忆模块 M \\mathcal{M} M。每条记录的形式为 ( q i , s i ) (q_i, s_i) (qi,si),其中 q i q_i qi代表之前的用户查询, s i s_i si是智能体生成的相应解决方案。存储在 M \\mathcal{M} M中的记录会在智能体的推理和规划过程中被整合。具体而言,给定输入查询 q q q,智能体使用相似度评分函数 f ( q , q i ) f(q, q_i) f(q,qi)来评估并对记忆 M \\mathcal{M} M中的查询进行排序。基于这些分数,它检索出最相关的前 k k k条记录,作为子集 E ( q , M ) ⊂ M \\mathcal{E}(q, \\mathcal{M}) \\subset \\mathcal{M} E(q,M)⊂M,即:
E ( q , M ) = { ( q i , s i ) ∣ f ( q , q i ) 处于前 k 位 } \\mathcal{E}(q, \\mathcal{M}) = \\{(q_i, s_i) | f(q, q_i) \\text{ 处于前 } k \\text{ 位}\\} E(q,M)={(qi,si)∣f(q,qi) 处于前 k 位}
这些检索到的记录随后被用作上下文示例,帮助智能体生成解决方案 s s s,可表示为:
LLM ( C ∥ E ( q , M ) ∥ q ) = s \\text{LLM}(\\mathcal{C} \\parallel \\mathcal{E}(q, \\mathcal{M}) \\parallel q) = s LLM(C∥E(q,M)∥q)=s
其中, LLM ( ⋅ ) \\text{LLM}(\\cdot) LLM(⋅)表示LLM智能体核心, C \\mathcal{C} C代表包含所有与任务相关上下文的系统提示, ∥ \\parallel ∥表示拼接。最后,LLM智能体通过工具调用执行 s s s以完成用户查询,表述为:
o = Execute ( s , T ) o = \\text{Execute}(s, \\mathcal{T}) o=Execute(s,T)
其中, T \\mathcal{T} T表示工具, o o o表示智能体的最终输出,其可能包含代码的执行结果、与网络应用程序的交互,或其他特定于任务的操作,具体取决于解决方案的类型和智能体的应用场景。如果解决方案成功执行,新的查询 - 解决方案对将被评估,然后有选择地添加到记忆中,以供后续参考。
2.2 威胁模型
攻击者目标:LLM智能体的记忆存储着过往记录 ( q i , s i ) (q_i, s_i) (qi,si),其中 q i q_i qi可能包含关于用户的私人信息。攻击者的目标是精心设计攻击提示,从记忆中尽可能多地提取过往用户查询 q i q_i qi。一旦获取到用户查询,相应的智能体响应就可以很容易地被重现。
攻击提示 q ~ \\tilde{q} q~会促使LLM智能体生成恶意解决方案 s ~ \\tilde{s} s~,表述为:
LLM ( C ∥ E ( q ~ , M ) ∥ q ~ ) = s ~\\text{LLM}(\\mathcal{C} \\parallel \\mathcal{E}(\\tilde{q}, \\mathcal{M}) \\parallel \\tilde{q}) = \\tilde{s} LLM(C∥E(q~,M)∥q~)=s~
然后,执行 s ~ \\tilde{s} s~有望输出 E ( q ~ , M ) \\mathcal{E}(\\tilde{q}, \\mathcal{M}) E(q~,M)中的所有用户查询,使攻击者能够从记忆中提取它们,表述为:
o ~ = Execute ( s ~ , T ) = { q i ∣ ( q i , s i ) ∈ E ( q ~ , M ) } \\tilde{o} = \\text{Execute}(\\tilde{s}, \\mathcal{T}) = \\{q_i | (q_i, s_i) \\in \\mathcal{E}(\\tilde{q}, \\mathcal{M})\\} o~=Execute(s~,T)={qi∣(qi,si)∈E(q~,M)}
其中, o ~ \\tilde{o} o~表示执行结果。
此外,为了扩展提取的信息,攻击者设计 n n n个多样化的攻击提示 { q ~ j} j = 1 n \\{\\tilde{q}_j\\}_{j = 1}^n {q~j}j=1n,旨在减少检索到的记录 E ( q ~ j , M ) \\mathcal{E}(\\tilde{q}_j, \\mathcal{M}) E(q~j,M)之间的重叠,从而减少提取结果 o ~ j \\tilde{o}_j o~j之间的重叠。形式上,利用 n n n个攻击提示,攻击者的目标是最大化以下集合的大小:
Q = ⋃ j = 1 n { q i ∣ q i ∈ o ~ j } \\mathcal{Q} = \\bigcup_{j = 1}^n \\{q_i | q_i \\in \\tilde{o}_j\\} Q=j=1⋃n{qi∣qi∈o~j}
其中, Q \\mathcal{Q} Q表示所有提取到的用户查询的集合。 n n n个检索到的子集的集合记为 R = ⋃ j = 1 n E ( q ~ j , M ) \\mathcal{R} = \\bigcup_{j = 1}^n \\mathcal{E}(\\tilde{q}_j, \\mathcal{M}) R=⋃j=1nE(q~j,M),且 ∣ R ∣ ≥ ∣ Q ∣ |\\mathcal{R}| \\geq |\\mathcal{Q}| ∣R∣≥∣Q∣。为简单起见,在不产生歧义的情况下,我们省略下标 j j j。
攻击者能力:我们考虑黑盒攻击,即攻击者只能通过输入查询与LLM智能体进行交互。在这种情况下,我们考察攻击者对智能体可能具备的两种认知水平:(1)基础水平,此时攻击者仅掌握关于智能体的一般背景信息,例如其应用领域和任务。例如,对于医疗记录管理智能体(Shi等人,2024),攻击者知道该智能体与医疗记录交互以回答用户查询;(2)高级水平,此时攻击者通过探索性交互获取了智能体的一些具体实现细节。在本文中,我们假设攻击者在多次交互后能够推断出相似度评分函数 f ( q , q i ) f(q, q_i) f(q,qi),该函数可能基于语义相似度(例如,余弦相似度)或查询格式相似度(例如,编辑距离)。
7 相关工作
带记忆的LLM智能体:存储用户与智能体交互的记忆,为LLM智能体解决现实应用提供了宝贵见解,使其成为LLM智能体的重要组成部分(Zhang等人,2024b)。然而,虽然为LLM智能体配备记忆提升了性能,但也带来了隐私风险。例如,医疗健康智能体(Shi等人,2024;Li等人,2023)存储患者的敏感信息,网络应用智能体(Kagaya等人,2024)记录用户偏好,自动驾驶智能体(Mao等人,2023;Wen等人,2024)积累过往驾驶场景。由于这些记忆模块本身存储着高度敏感的用户数据,对记忆泄露风险进行系统调查,对于揭示和缓解潜在威胁至关重要。
RAG中的隐私风险:近年来,RAG相关研究广泛探讨了与外部数据相关的隐私问题。Zeng等人(2024)首次揭示,整合到RAG系统中的私人数据易受手动设计的对抗性提示攻击;Qi等人(2024)则在多种RAG配置下进行了更全面的调查。为实现自动化提取,Jiang等人(2024)开发了基于智能体的攻击,Di Maio等人(2024)提出了一种自适应策略来逐步提取私人知识。这些研究表明,由于LLM智能体和RAG系统采用类似的数据检索机制,LLM智能体中可能出现类似的隐私威胁。
提示注入攻击:提示注入是一种通过向LLM的提示中注入精心设计的对抗性命令来操纵其输出的攻击(He等人,2024)。它可分为两类:直接提示注入和间接提示注入(Rossi等人,2024)。在直接提示注入中,恶意输入直接包含在提供给LLM的提示中,以实现目标劫持(Perez和Ribeiro,2022;Zhang等人,2024a)、提示泄露(Perez和Ribeiro,2022;Hui等人,2024)和越狱(Zou等人,2023;Li等人,2024)等目的。相比之下,间接提示注入通过外部内容源传递恶意输入,且通常用户并不知情。它通常通过电子邮件或网站等渠道针对基于LLM的智能体(Zhan等人,2024;Wu等人,2024a;Liu等人,2023a),能够更隐秘地操纵外部输入,并可能导致未授权操作和意外数据泄露,比如电子邮件或网页中包含的私人信息。不过,以往研究对基于LLM的智能体中的记忆泄露问题关注有限,而这正是本文的主要研究重点。
8 结论
在本文中,我们通过一种记忆提取攻击(MEXTRA)揭示了LLM智能体记忆泄露的隐私风险。该攻击包含两部分:攻击提示设计,以及针对对智能体不同认知程度而定制的自动攻击提示。实证评估表明,LLM智能体易受MEXTRA攻击的影响。此外,我们还从智能体设计者和攻击者的角度,探究了影响记忆泄露的关键因素。
局限性
我们的记忆提取攻击仅在单智能体设置下进行了评估。将其扩展到多智能体设置(智能体之间进行通信或共享记忆),会是未来研究的一个有趣方向。研究智能体间的交互如何影响记忆泄露风险,能更深入地洞察LLM智能体中的隐私漏洞。此外,我们所考虑的智能体框架未纳入会话控制:多个用户可能共享同一个会话,导致记忆模块存储所有用户的历史记录。引入用户级和会话级的记忆隔离,会限制攻击者对私人数据的访问,并减轻记忆提取的影响。然而,由于目前还没有将会话控制整合到智能体框架中的标准方法,我们将其探索留待未来工作。


