【算法】一文看懂快速排序!!!

一文看懂快速排序
✨前言:在各种排序算法中,快速排序(Quick Sort)几乎是“算法界的明星”。它由 Tony Hoare 在 1962 年提出,凭借着分治思想与高效的平均性能,成为众多编程语言和标准库中的默认排序算法。
相比于冒泡排序、选择排序这样的“基础选手”,快速排序更像是一位善于策略分配的“指挥官”:它先选出一个基准值(key),再通过一趟划分,把比基准小的元素放在左边,比基准大的元素放在右边,然后递归处理子区间,直到整个序列有序。
得益于这种巧妙的思路,快速排序在大多数情况下能以 O(N log N) 的时间复杂度完成任务,且只需较少的额外空间,几乎成为了“高效排序”的代名词。不过,快速排序并非完美无缺,它在极端情况下可能退化为 O(N²),同时也不是一个稳定的排序算法。
在这篇文章中,我们将从原理到实现、从优化到应用,全面剖析快速排序,帮助你既能在面试中“手撕快排”,也能在工程实践中理解为何它依然是排序算法的首选之一。
📖专栏:【算法】
目录
- 一文看懂快速排序
-
- 一、快速排序简介
-
- 1.1 快排的提出与背景
- 1.2 基本思想
- 二、快速排序的实现
-
- 三种划分方式
- 三、快速排序的优化
-
- 3.1三数取中法选择基准值
- 3.2 小区间转插入排序
- 3.3 其他优化方法简介
- 四、非递归实现
- 五、快速排序的性能分析
-
- 5.1 时间复杂度
- 5.2 空间复杂度
- 5.3 稳定性
- 六、总结
一、快速排序简介
1.1 快排的提出与背景
- 1962 年,Tony Hoare 提出快速排序,并凭借这一成果获得了图灵奖。
- 快速排序利用 分治思想,通过“划分—递归”的方式实现排序。
1.2 基本思想
1. 在数组中选择一个基准值(key);
2. 将数组划分为两部分:左边比 key 小,右边比 key 大;
3. 递归排序左右两部分;
4. 最终合并得到有序序列。
二、快速排序的实现
在这里,最重要的就是将数组划分为两部分:左边比 key 小,右边比 key 大。
对于将数组划分为两部分的方法有三种,本质思想都是一样的,但实现的方法却有点不同,我们来看一下:
三种划分方式
以下面一组数据为例,我们假设key的值是最左边的值。
*** 2.2.1 Hoare版本**
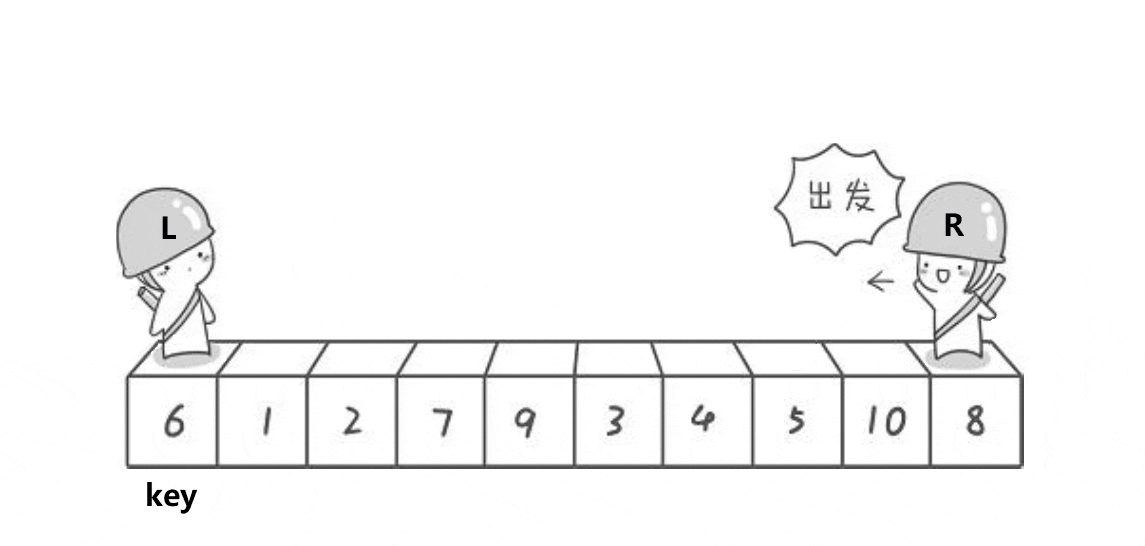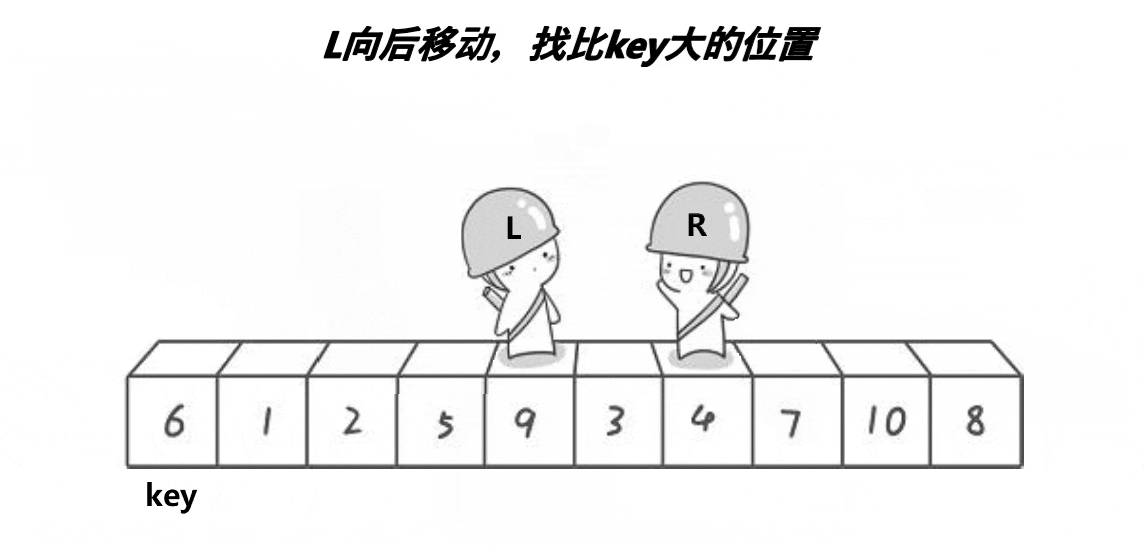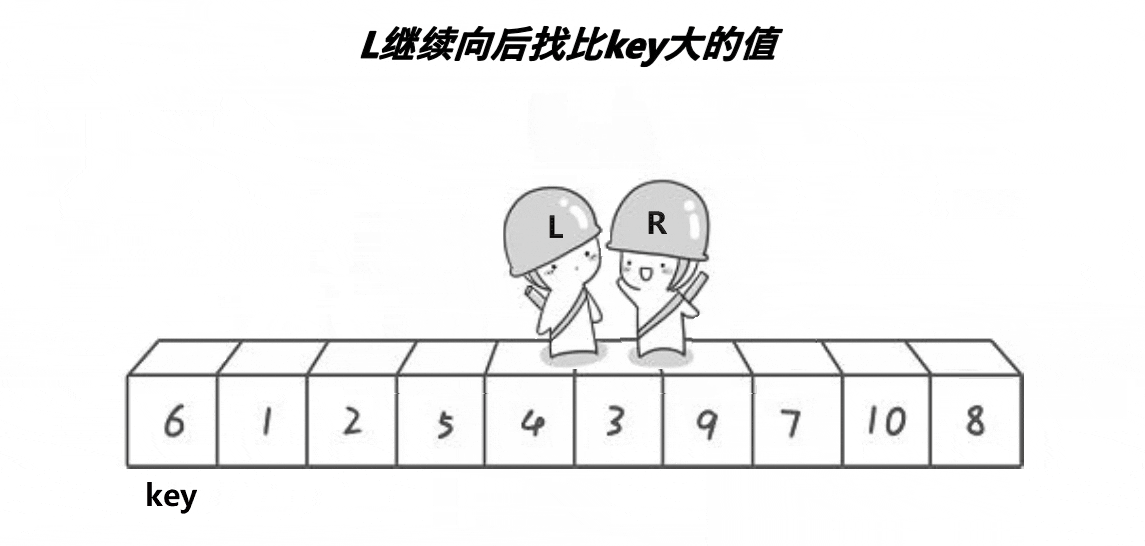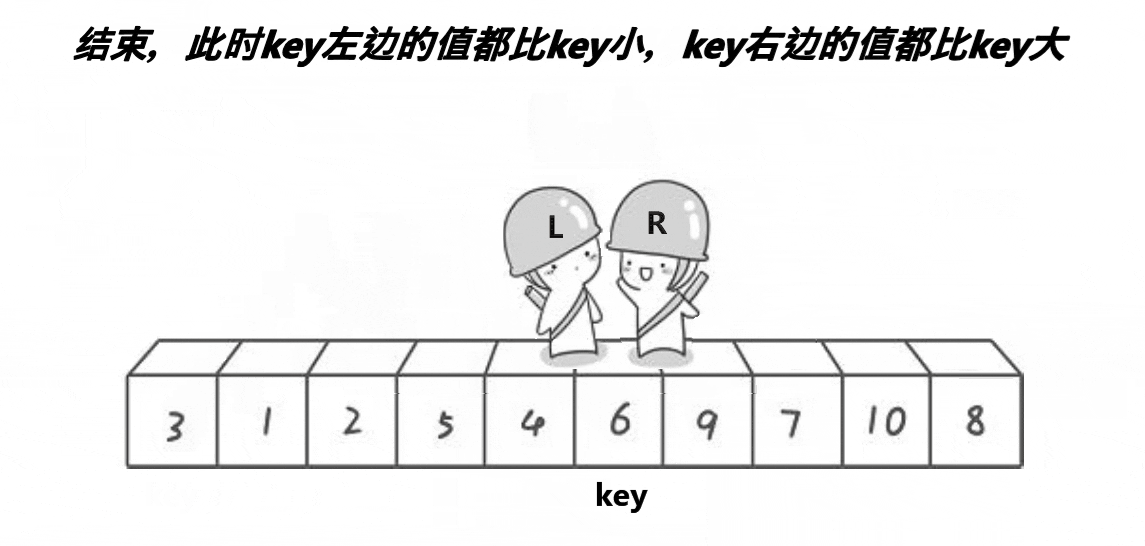
看了这个动图之后,可知,它是定义了两个下标(L与R),分别从两侧开始找,R先走,找到比key小的值,停下来;L开始走,找到比key大的值,停下来,交换对应的值即可,然后继续重复,直到两者相遇,交换相遇点与key的值即可,这就是Hoare的思想。还是很好理解的,但是这个方法会导致很多人有疑问?我也重点标记了。
答疑解惑:
- 为什么两者相遇,交换相遇点与key的值?那万一此时的值比key大呢?
在这里我们就要明白一个点,两者会以什么方式相遇,简单,要么L在移动的时候遇到了R,要么R在移动的时候遇到了L。
L在移动的时候遇到了R的情况:
由于是R先走的缘故,所以R此时指向的是比key小的值,此时L遇到了R,相遇点即为比key小的值
R在移动的时候遇到了L的情况:
此时L停留在上次交换的位置,上次交换的是比key小的值,即相遇点为比key小的值,也有可能L停留在key的位置。结果都是一样。- 为什么R先走?
其实,上面的解释已经有了答案。我们也可以看看如果L先走的话,会发生什么情况:
我们会发现,当L先走时,可以把key设在右边。

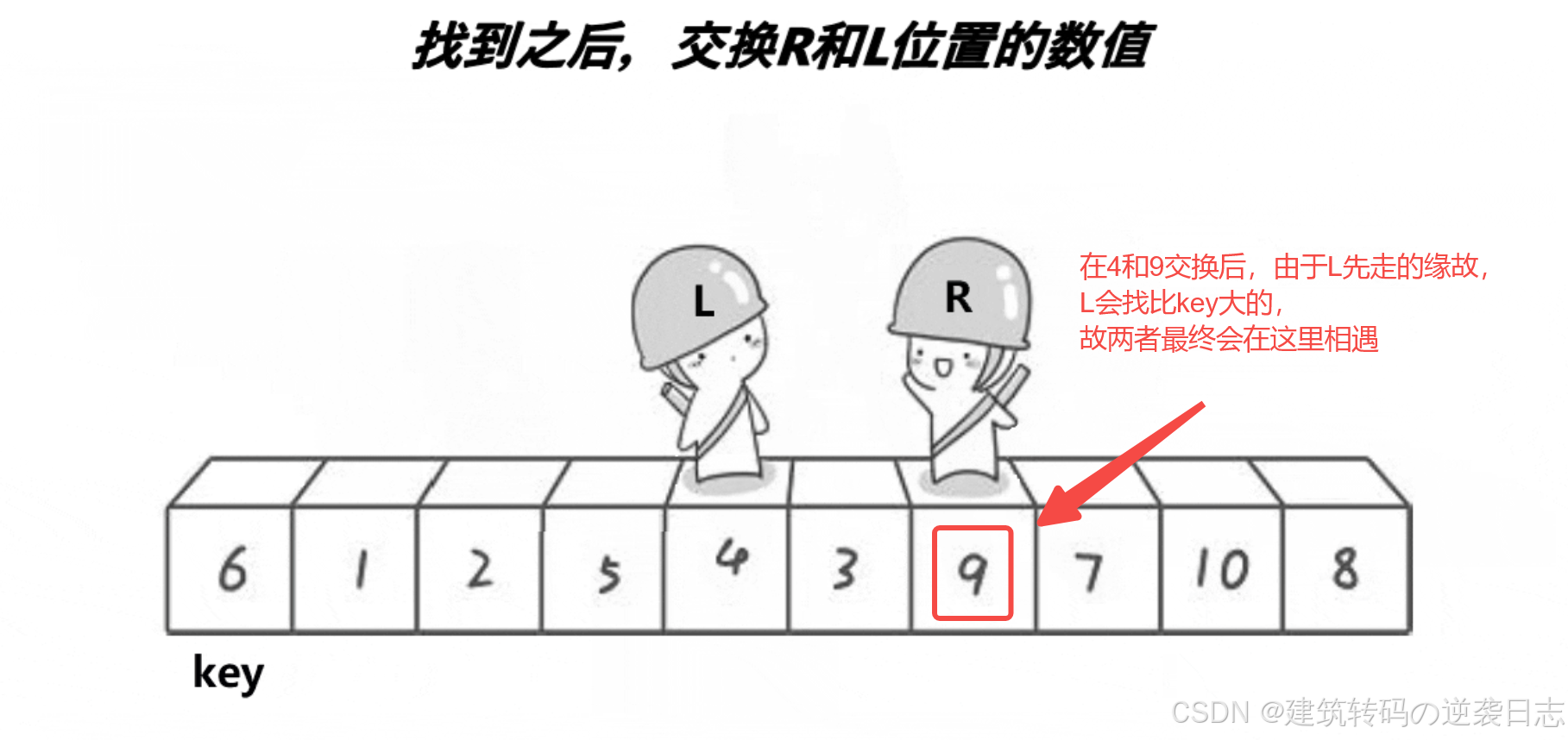
那现在我们来进行代码的完成。
int _QuickSort(int* a, int left, int right){int key = left;// 选择最左边为基准while (left < right){while (left < right && a[right] >= a[key])//只找比key位置小的right--;while (left < right && a[left] <= a[key])left++;Swap(&a[right], &a[left]);}Swap(&a[left], &a[key]);// 将基准值放到正确位置return left;// 返回基准值最终位置}现在我们完成了快速排序中的单次划分,上面我们说过,递归排序左右两部分,怎么完成呢,来分析:
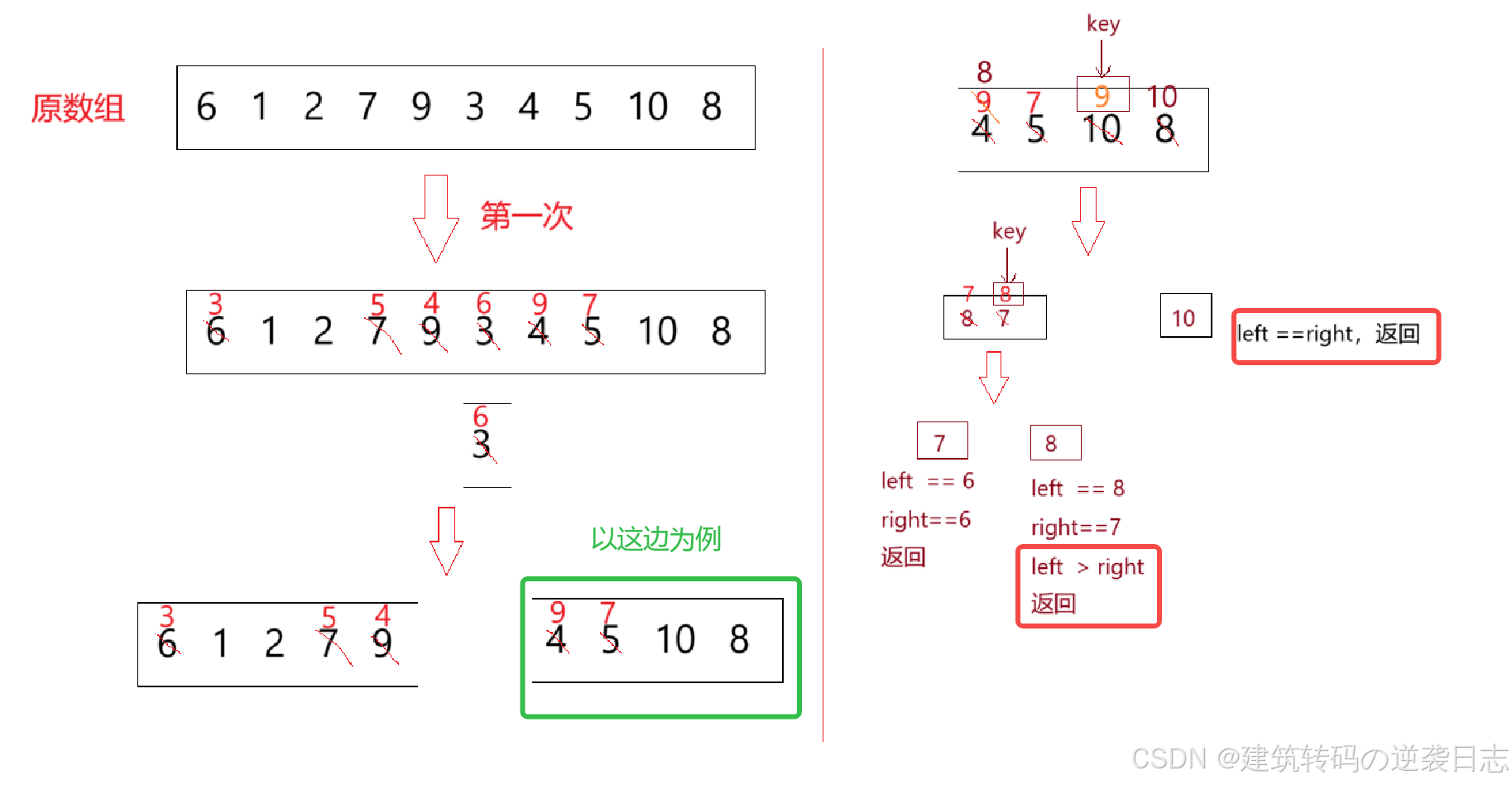
也就是说,左右两部分和首次排序的思想是一样的,然后,左右两部分的左右两部分又相同,所以对于递归已经发现清楚了,下面来完成代码吧:
void QuickSort(int* a, int left, int right){ if (left >= right) // 递归终止条件:区间只有一个元素或为空 return; int mid = _QuickSort(a, left, right); // 划分操作,返回基准值的最终位置 QuickSort(a, left, mid - 1); // 递归排序左半部分 QuickSort(a, mid + 1, right); // 递归排序右半部分}至此,快排的基本框架完成,为什么说基本框架,因为快排后序会有多种优化,后面会说。下面这两种方法我们可以来看一下思想,代码很简单。
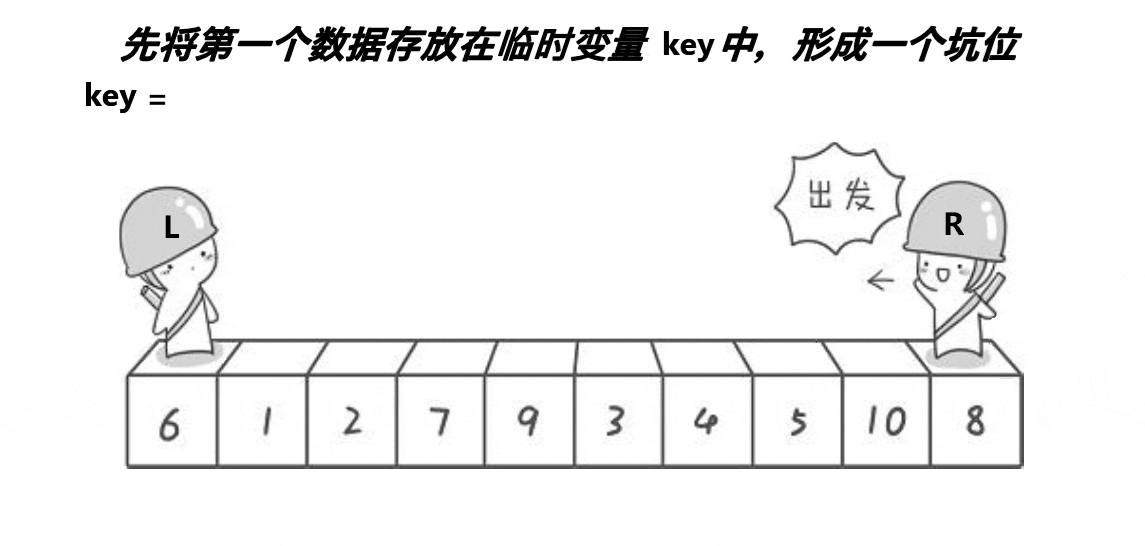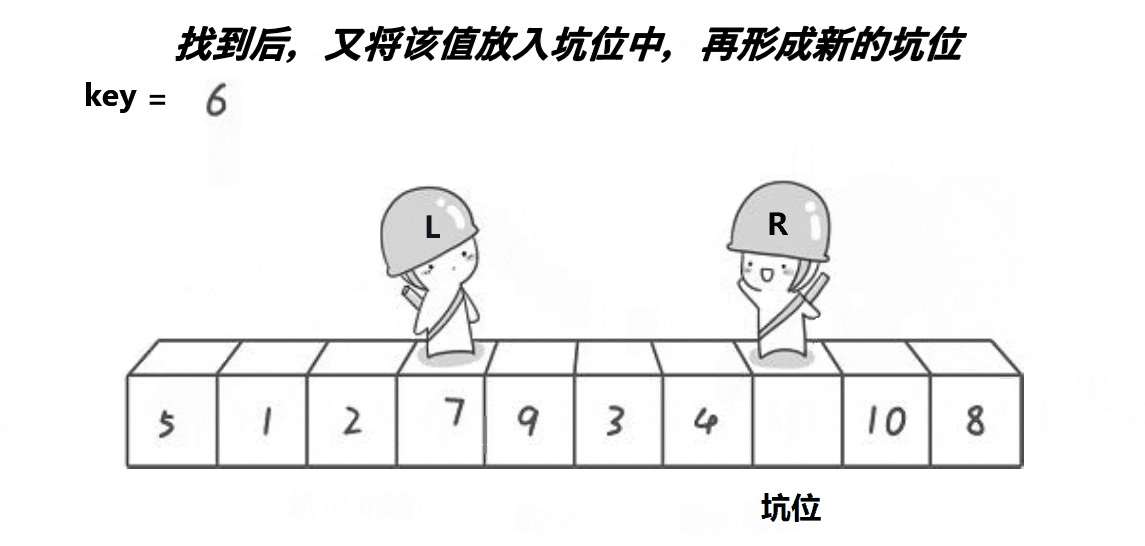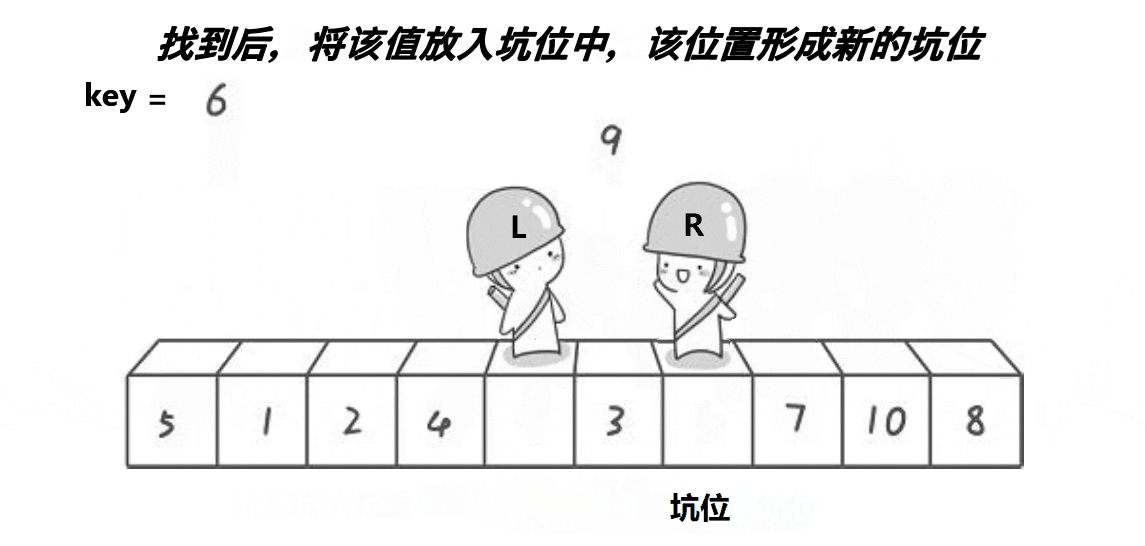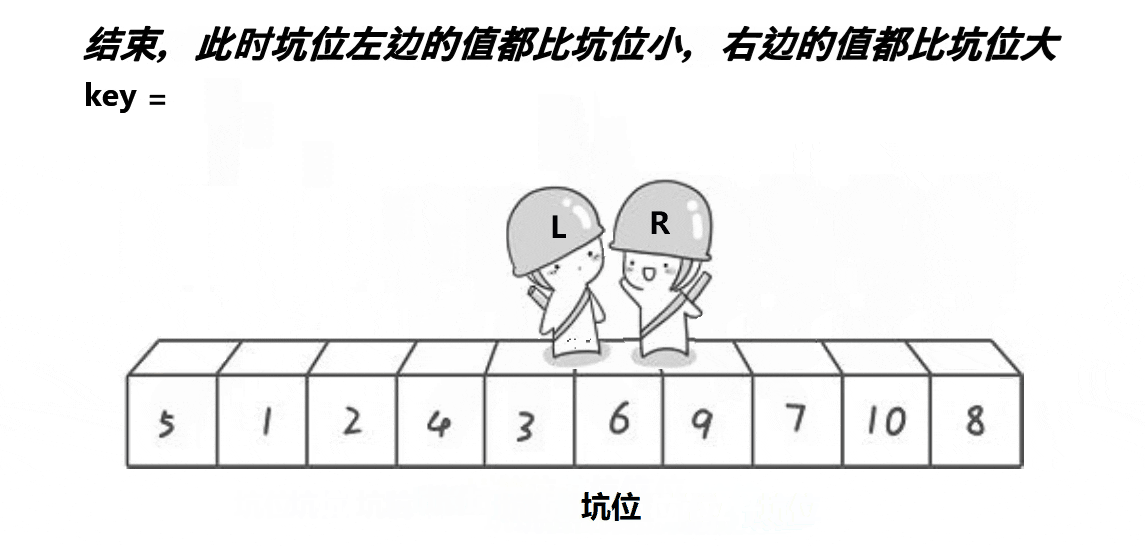
- 2.2.2 挖坑法
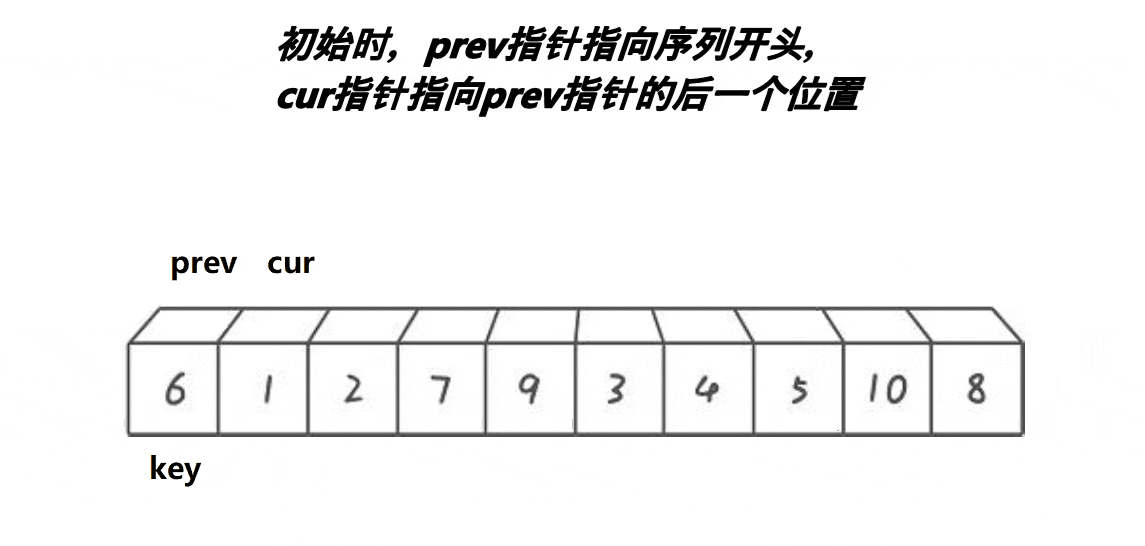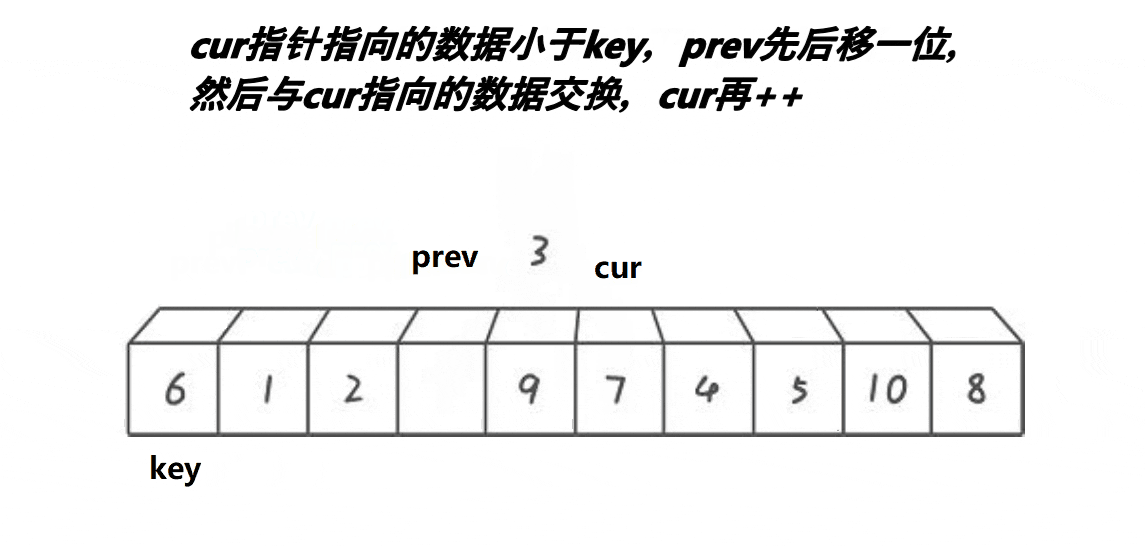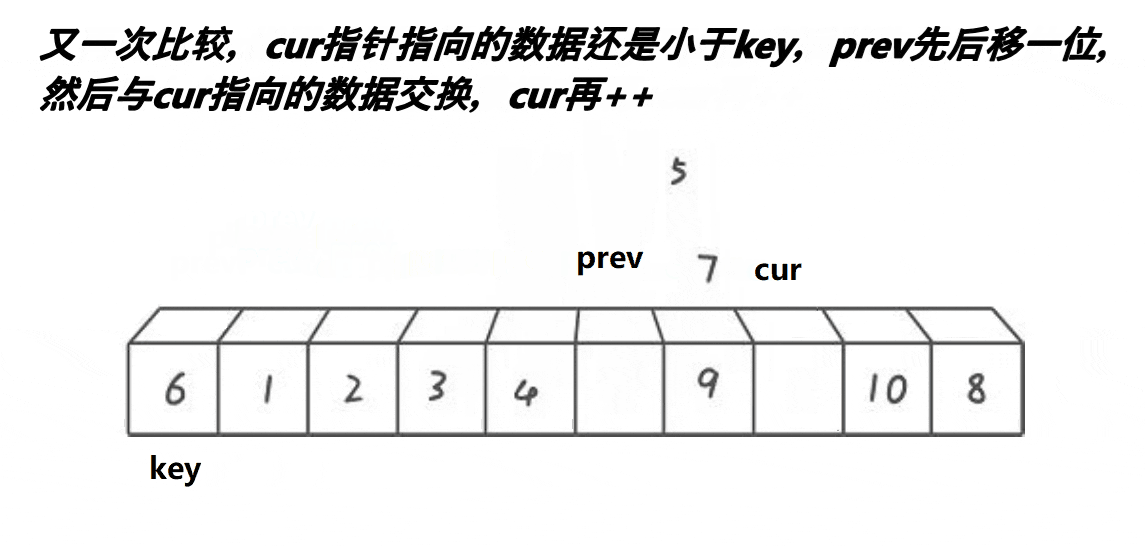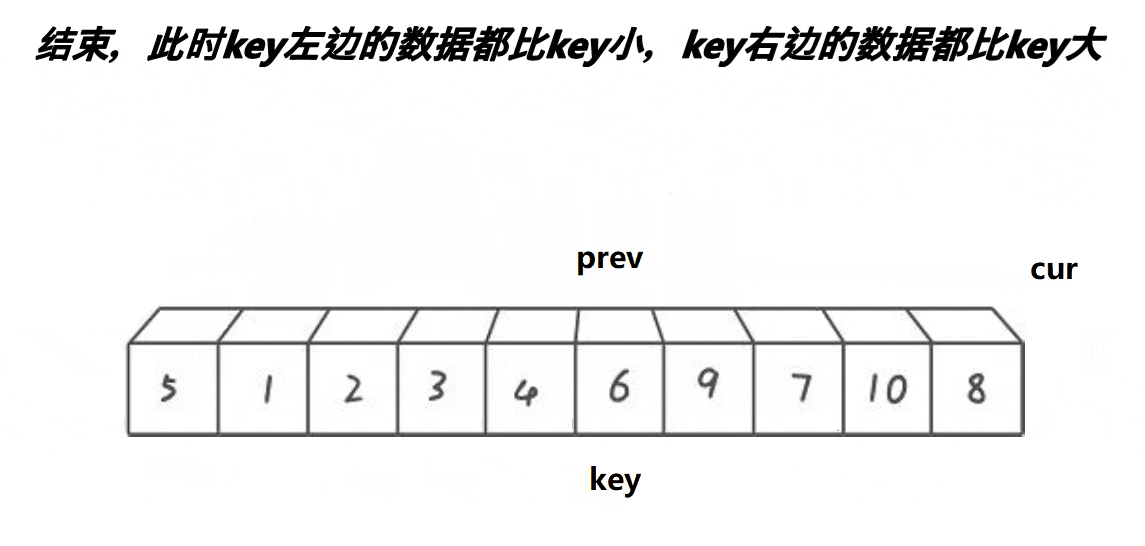
- 2.2.3 前后指针法
这两个我们了解一下思想即可。霍尔法虽然在实现上稍复杂,但其优异的性能表现使其成为大多数标准库实现的选择。
三、快速排序的优化
对于我们实现的快排,问题在于key的取值,如果key的取值大多数接近数组最小值,极端一点,就会导致:
所以我们使得key的取值尽量靠近中间值。便有了三数取中法选择基准值。
3.1三数取中法选择基准值
三数取中法,顾名思义,选择三个数的中间值,看代码
int GetMidi(int* a, int left, int right){int midi = right + (left - right) / 2;if (a[midi] > a[left]){if (a[midi] < a[right])return midi;else if (a[left] < a[right])//a[midi] >= a[right]return right;elsereturn left;}else//a[midi] <= a[left]{if (a[left] < a[right])return left;else if (a[midi] < a[right])//a[left] >= a[right]return right;elsereturn midi;}}3.2 小区间转插入排序
对于快排来说,在数据量较小时,就没有使用的必要了,所以在数据量较小时选择插入排序即可。代码实现
void QuickSort(int* a, int left, int right){ if (left >= right) // 递归终止条件:区间只有一个元素或为空 return; if (right - left + 1 <= 10)//数据量较小时用插入排序{InsertSort(a + left, right - left + 1);return;} int mid = _QuickSort(a, left, right); // 划分操作,返回基准值的最终位置 QuickSort(a, left, mid - 1); // 递归排序左半部分 QuickSort(a, mid + 1, right); // 递归排序右半部分}3.3 其他优化方法简介
- 对于快排的优化远不止于此,我们会发现,在每次划分的时候,对于与key相等的值,我们选择是不动的,这样也会使得效率较低,由此便产生了三路划分,即在找比key小的值和大的值的同时,找与key相等的值。但是,三路划分又对于重复数值不多的情况,效率有所减少。
- 前面我们说过的三数取中法有时还会导致key的值不理想,递归的层次较大,所以,有大佬便想到了,当递归层次较大时,选择堆排,在数据量较小时,选择插入排序,这种又称为自省排序。
四、非递归实现
对于快排,我们还需要会用非递归实现。
这个时候,思想还是递归的思想,只是,我们要用到栈了:对于快排的递归来说,每次转入的都是left和right。那我们对于非递归来说,每次把left和right都传入栈中,每次当left和right出栈进行操作后,把划分后的区间又入栈,即可。
停止条件:“递归终止条件:区间只有一个元素或为空”,那我们非递归对于left >= right是不入栈即可或者出栈后不进行操作即可。
代码完成:
void QuickSortNonR(int* a, int left, int right){Stack st;StackInit(&st);StackPush(&st, left);StackPush(&st, right);while (StackEmpty(&st) != 0){right = StackTop(&st);StackPop(&st);left = StackTop(&st);StackPop(&st);if (right <= left )continue;int mid = _QuickSort(a, left, right);// 以基准值为分割点,形成左右两部分:[left, mid-1 ] 和 [mid+1, right]StackPush(&st, mid + 1);StackPush(&st, right);StackPush(&st, left);StackPush(&st, mid - 1);}StackDestroy(&st);}对于栈的实现,详见【栈】
五、快速排序的性能分析
5.1 时间复杂度
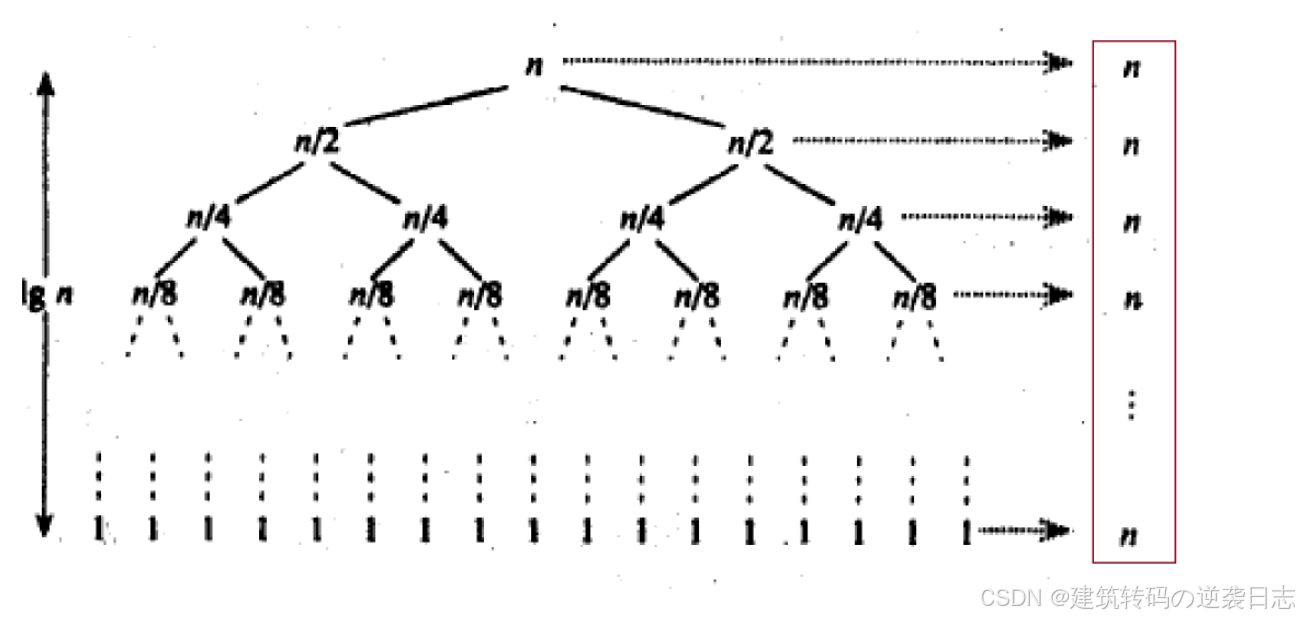
对于快排的时间复杂度一般为O(N*logN),看下图递归树。假设基准值每次都可以取到中间。
**但是快排最坏能到O(N^2),当数组完全有序(正序或逆序),每次选择的基准值都是最小或最大元素。但是一般少发生且可以避免。**毕竟快排还有很多优化。
5.2 空间复杂度
如上图,递归为O(logN),非递归也为O(logN),非递归我们可以看做二叉树的前序遍历,一直从上图的左边下去。简单点,就是,出一个,带两个,持续logN次。
5.3 稳定性
不稳定,相同元素的相对顺序可能改变。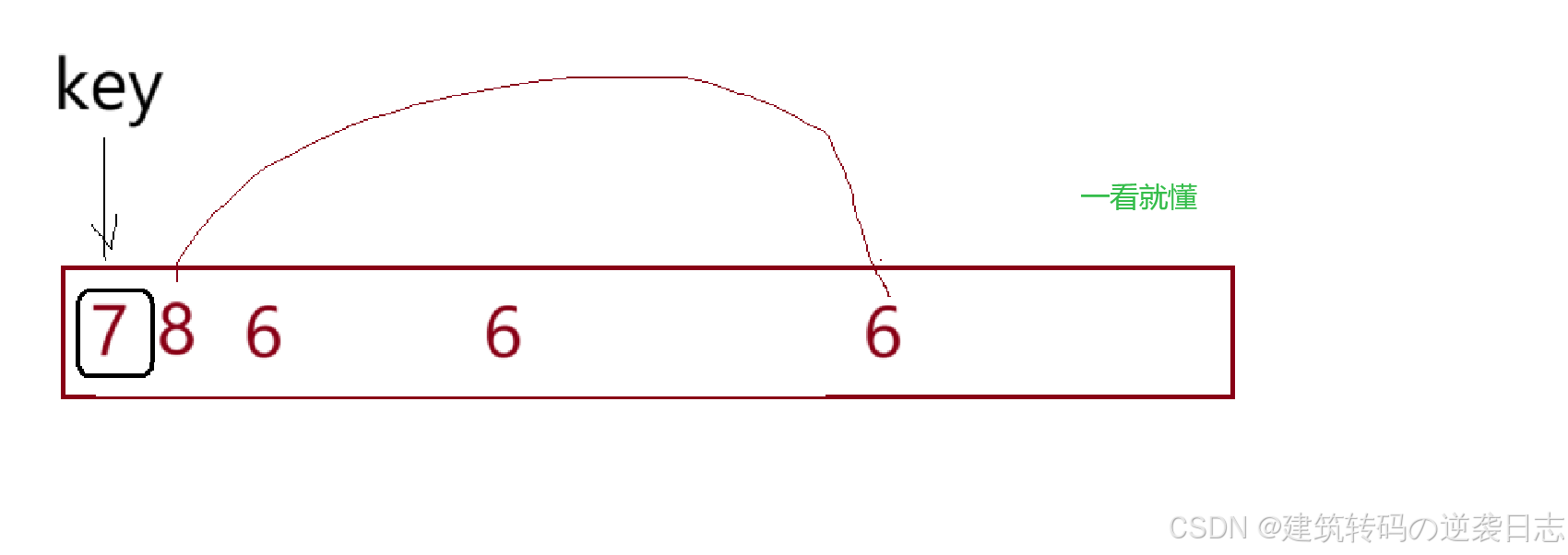
六、总结
快速排序通过“选基准、分区间、递归处理”的分治思想,实现了高效的排序。它的核心优势是平均时间复杂度接近O(N log N),并且额外空间开销较小,因此被广泛应用于标准库中。虽然在极端情况下可能退化为 O(N²),而且本身不稳定,但通过三数取中、小区间转插排、三路划分等优化手段,可以在实际场景中保持优秀表现。递归和非递归两种实现方式各有应用,递归更直观,非递归更适合工程。总体来看,快速排序因高效与实用,成为排序算法中的“明星”。
如果本文对您有启发:
✅ 点赞 - 让更多人看到这篇硬核技术解析 !
✅ 收藏 - 实战代码随时复现
✅ 关注 - 获取数据结构系列深度更新
您的每一个[三连]都是我们持续创作的动力!✨



