Paraformer分角色语音识别-中文-通用 FunASR demo测试与训练
文章目录
- 0 资料
- 1 Paraformer分角色语音识别-中文-通用
- 1 模型下载
- 2 音频识别测试
- 3 FunASR安装 (训练用)
- 4 数据集制作
- 4 训练
- 5 使用训练的模型进行测试
0 资料
https://github.com/modelscope/FunASR/blob/main/README_zh.md
https://github.com/modelscope/FunASR/blob/main/model_zoo/readme_zh.md
训练实时语音识别Paraformer模型
b站视频:
https://www.bilibili.com/video/BV1QzTMzVEDr/
https://www.bilibili.com/video/BV1UhM7zeERU/
PyTorch / 2.3.0 / 3.12(ubuntu22.04) / 12.1
1 Paraformer分角色语音识别-中文-通用
https://www.modelscope.cn/models/iic/speech_paraformer-large-vad-punc-spk_asr_nat-zh-cn
安装ffmpeg
source /etc/network_turboconda install x264 ffmpeg -c conda-forge -y# 或者conda install -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/ x264 ffmpeg -ysource /etc/network_turbopip install torchaudiopip install -U funasrpython -c \"import torchaudio; print(torchaudio.__version__)\"python -c \"import funasr; print(funasr.__version__)\"1 模型下载
模型下载:https://modelscope.cn/models/iic/speech_paraformer-large-vad-punc-spk_asr_nat-zh-cn/files
使用SDK下载下载:
开始前安装
source /etc/network_turbopip install modelscope脚本下载
# source /etc/network_turbofrom modelscope import snapshot_download# 指定模型的下载路径cache_dir = \'/root/autodl-tmp\'# 调用 snapshot_download 函数下载模型model_dir = snapshot_download(\'iic/speech_paraformer-large-vad-punc-spk_asr_nat-zh-cn\', cache_dir=cache_dir)print(f\"模型已下载到: {model_dir}\")2 音频识别测试
音频下载
wget https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/vad_example.wavfrom funasr import AutoModel# paraformer-zh is a multi-functional asr model# use vad, punc, spk or not as you need# model = AutoModel(model=\"paraformer-zh\", model_revision=\"v2.0.4\",model = AutoModel(model=\"/root/autodl-tmp/iic/speech_paraformer-large-vad-punc-spk_asr_nat-zh-cn\", model_revision=\"v2.0.4\", vad_model=\"fsmn-vad\", vad_model_revision=\"v2.0.4\", punc_model=\"ct-punc-c\", punc_model_revision=\"v2.0.4\", # spk_model=\"cam++\", spk_model_revision=\"v2.0.2\", )# res = model.generate(input=f\"{model.model_path}/example/asr_example.wav\", res = model.generate(input=f\"vad_example.wav\", batch_size_s=300, hotword=\'魔搭\')print(res)结果如下:
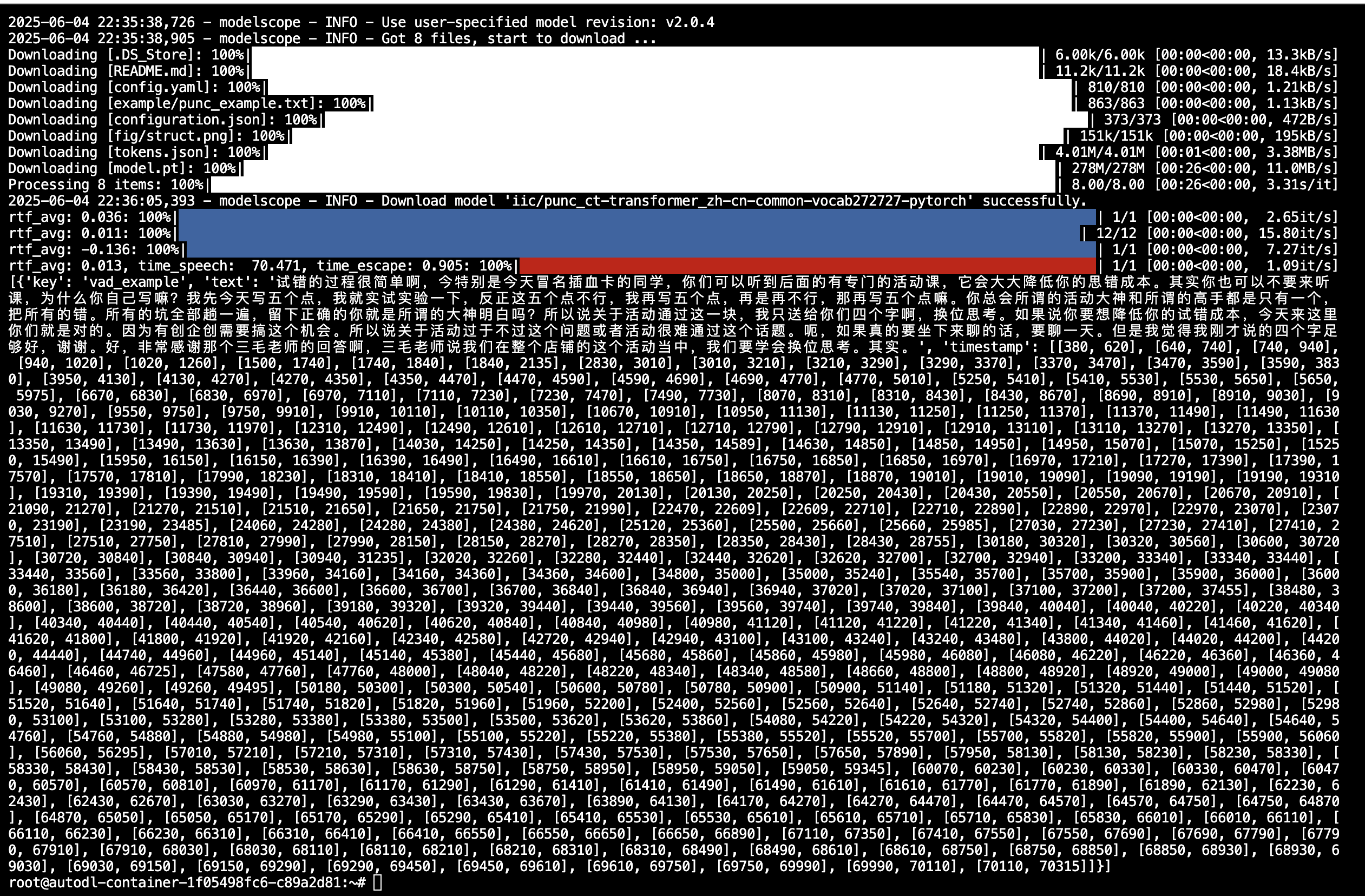
[{‘key’: ‘vad_example’, ‘text’:
‘试错的过程很简单啊,今特别是今天冒名插血卡的同学,你们可以听到后面的有专门的活动课,它会大大降低你的思错成本。其实你也可以不要来听课,为什么你自己写嘛?我先今天写五个点,我就实试实验一下,反正这五个点不行,我再写五个点,再是再不行,那再写五个点嘛。你总会所谓的活动大神和所谓的高手都是只有一个,把所有的错。所有的坑全部趟一遍,留下正确的你就是所谓的大神明白吗?所以说关于活动通过这一块,我只送给你们四个字啊,换位思考。如果说你要想降低你的试错成本,今天来这里你们就是对的。因为有创企创需要搞这个机会。所以说关于活动过于不过这个问题或者活动很难通过这个话题。呃,如果真的要坐下来聊的话,要聊一天。但是我觉得我刚才说的四个字足够好,谢谢。好,非常感谢那个三毛老师的回答啊,三毛老师说我们在整个店铺的这个活动当中,我们要学会换位思考。其实。’,
‘timestamp’: [[380, 620], [640, 740], [740, 940], [940, 1020], [1020,
1260], [1500, 1740], [1740, 1840], [1840, 2135], [2830, 3010], [3010,
3210], [3210, 3290], [3290, 3370], [3370, 3470], [3470, 3590], [3590,
3830], [3950, 4130], [4130, 4270], [4270, 4350], [4350, 4470], [4470,
4590], [4590, 4690], [4690, 4770], [4770, 5010], [5250, 5410], [5410,
5530], [5530, 5650], [5650, 5975], [6670, 6830], [6830, 6970], [6970,
7110], [7110, 7230], [7230, 7470], [7490, 7730], [8070, 8310], [8310,
8430], [8430, 8670], [8690, 8910], [8910, 9030], [9030, 9270], [9550,
9750], [9750, 9910], [9910, 10110], [10110, 10350], [10670, 10910],
[10950, 11130], [11130, 11250], [11250, 11370], [11370, 11490],
[11490, 11630], [11630, 11730], [11730, 11970], [12310, 12490],
[12490, 12610], [12610, 12710], [12710, 12790], [12790, 12910],
[12910, 13110], [13110, 13270], [13270, 13350], [13350, 13490],
[13490, 13630], [13630, 13870], [14030, 14250], [14250, 14350],
[14350, 14589], [14630, 14850], [14850, 14950], [14950, 15070],
[15070, 15250], [15250, 15490], [15950, 16150], [16150, 16390],
[16390, 16490], [16490, 16610], [16610, 16750], [16750, 16850],
[16850, 16970], [16970, 17210], [17270, 17390], [17390, 17570],
[17570, 17810], [17990, 18230], [18310, 18410], [18410, 18550],
[18550, 18650], [18650, 18870], [18870, 19010], [19010, 19090],
[19090, 19190], [19190, 19310], [19310, 19390], [19390, 19490],
[19490, 19590], [19590, 19830], [19970, 20130], [20130, 20250],
[20250, 20430], [20430, 20550], [20550, 20670], [20670, 20910],
[21090, 21270], [21270, 21510], [21510, 21650], [21650, 21750],
[21750, 21990], [22470, 22609], [22609, 22710], [22710, 22890],
[22890, 22970], [22970, 23070], [23070, 23190], [23190, 23485],
[24060, 24280], [24280, 24380], [24380, 24620], [25120, 25360],
[25500, 25660], [25660, 25985], [27030, 27230], [27230, 27410],
[27410, 27510], [27510, 27750], [27810, 27990], [27990, 28150],
[28150, 28270], [28270, 28350], [28350, 28430], [28430, 28755],
[30180, 30320], [30320, 30560], [30600, 30720], [30720, 30840],
[30840, 30940], [30940, 31235], [32020, 32260], [32280, 32440],
[32440, 32620], [32620, 32700], [32700, 32940], [33200, 33340],
[33340, 33440], [33440, 33560], [33560, 33800], [33960, 34160],
[34160, 34360], [34360, 34600], [34800, 35000], [35000, 35240],
[35540, 35700], [35700, 35900], [35900, 36000], [36000, 36180],
[36180, 36420], [36440, 36600], [36600, 36700], [36700, 36840],
[36840, 36940], [36940, 37020], [37020, 37100], [37100, 37200],
[37200, 37455], [38480, 38600], [38600, 38720], [38720, 38960],
[39180, 39320], [39320, 39440], [39440, 39560], [39560, 39740],
[39740, 39840], [39840, 40040], [40040, 40220], [40220, 40340],
[40340, 40440], [40440, 40540], [40540, 40620], [40620, 40840],
[40840, 40980], [40980, 41120], [41120, 41220], [41220, 41340],
[41340, 41460], [41460, 41620], [41620, 41800], [41800, 41920],
[41920, 42160], [42340, 42580], [42720, 42940], [42940, 43100],
[43100, 43240], [43240, 43480], [43800, 44020], [44020, 44200],
[44200, 44440], [44740, 44960], [44960, 45140], [45140, 45380],
[45440, 45680], [45680, 45860], [45860, 45980], [45980, 46080],
[46080, 46220], [46220, 46360], [46360, 46460], [46460, 46725],
[47580, 47760], [47760, 48000], [48040, 48220], [48220, 48340],
[48340, 48580], [48660, 48800], [48800, 48920], [48920, 49000],
[49000, 49080], [49080, 49260], [49260, 49495], [50180, 50300],
[50300, 50540], [50600, 50780], [50780, 50900], [50900, 51140],
[51180, 51320], [51320, 51440], [51440, 51520], [51520, 51640],
[51640, 51740], [51740, 51820], [51820, 51960], [51960, 52200],
[52400, 52560], [52560, 52640], [52640, 52740], [52740, 52860],
[52860, 52980], [52980, 53100], [53100, 53280], [53280, 53380],
[53380, 53500], [53500, 53620], [53620, 53860], [54080, 54220],
[54220, 54320], [54320, 54400], [54400, 54640], [54640, 54760],
[54760, 54880], [54880, 54980], [54980, 55100], [55100, 55220],
[55220, 55380], [55380, 55520], [55520, 55700], [55700, 55820],
[55820, 55900], [55900, 56060], [56060, 56295], [57010, 57210],
[57210, 57310], [57310, 57430], [57430, 57530], [57530, 57650],
[57650, 57890], [57950, 58130], [58130, 58230], [58230, 58330],
[58330, 58430], [58430, 58530], [58530, 58630], [58630, 58750],
[58750, 58950], [58950, 59050], [59050, 59345], [60070, 60230],
[60230, 60330], [60330, 60470], [60470, 60570], [60570, 60810],
[60970, 61170], [61170, 61290], [61290, 61410], [61410, 61490],
[61490, 61610], [61610, 61770], [61770, 61890], [61890, 62130],
[62230, 62430], [62430, 62670], [63030, 63270], [63290, 63430],
[63430, 63670], [63890, 64130], [64170, 64270], [64270, 64470],
[64470, 64570], [64570, 64750], [64750, 64870], [64870, 65050],
[65050, 65170], [65170, 65290], [65290, 65410], [65410, 65530],
[65530, 65610], [65610, 65710], [65710, 65830], [65830, 66010],
[66010, 66110], [66110, 66230], [66230, 66310], [66310, 66410],
[66410, 66550], [66550, 66650], [66650, 66890], [67110, 67350],
[67410, 67550], [67550, 67690], [67690, 67790], [67790, 67910],
[67910, 68030], [68030, 68110], [68110, 68210], [68210, 68310],
[68310, 68490], [68490, 68610], [68610, 68750], [68750, 68850],
[68850, 68930], [68930, 69030], [69030, 69150], [69150, 69290],
[69290, 69450], [69450, 69610], [69610, 69750], [69750, 69990],
[69990, 70110], [70110, 70315]]}]
3 FunASR安装 (训练用)
source /etc/network_turbogit clone https://github.com/alibaba/FunASR.git && cd FunASR进入到:FunASR/examples/industrial_data_pretraining/paraformer
4 数据集制作
数据集标注,请看下面的资料:
ASR(语音识别)语音/字幕标注 通过via(via_subtitle_annotator)
我准备了一个组很小的标注及转化为ASR Paraformer 可训练数据:
https://download.csdn.net/download/WhiffeYF/90975948
标注网站:https://whiffe.github.io/VIA/via_subtitle_annotator.html
标注教程:https://blog.csdn.net/WhiffeYF/article/details/148530647
0001.mp4 视频,标注用
0001.json 标注后保存的json
json2ASR.py 将json转化为ASR训练格式文件
train_text.txt train_wav.scp 训练格式文件,json2ASR生成
wav 文件夹,里面是抽取的wav音频,训练用,json2ASR生成
extract_audio.py 从0001.mp4中抽取3分钟wav音频文件的脚本,用于测试
0001.wav 从0001.mp4中抽取3分钟的wav音频,测试用
list2.zip 是直接放在 ./funasr/data/ 中。这里是整理好的训练数据,可以直接用。
4 训练
训练目录:FunASR/examples/industrial_data_pretraining/paraformer
训练文件:finetune.sh
修改如下内容:
export CUDA_VISIBLE_DEVICES=\"0,1\"改为export CUDA_VISIBLE_DEVICES=\"0\"data_dir=\"../../../data/list\"改为data_dir=\"../../../data/list2\"++scp_file_list=\'[\"../../../data/list/train_wav.scp\", \"../../../data/list/train_text.txt\"]\' \\++scp_file_list=\'[\"../../../data/list/val_wav.scp\", \"../../../data/list/val_text.txt\"]\' \\改为++scp_file_list=\'[\"../../../data/list2/train_wav.scp\", \"../../../data/list2/train_text.txt\"]\' \\++scp_file_list=\'[\"../../../data/list2/val_wav.scp\", \"../../../data/list2/val_text.txt\"]\' \\output_dir=\"./outputs\"改为output_dir=\"/root/autodl-tmp/outputs\"++train_conf.max_epoch=50 \\改为++train_conf.max_epoch=10 \\++train_conf.keep_nbest_models=20 \\++train_conf.avg_nbest_model=10 \\改为++train_conf.keep_nbest_models=10 \\++train_conf.avg_nbest_model=5 \\官方参数说明:
funasr/bin/train.py \\++model=\"${model_name_or_model_dir}\" \\++train_data_set_list=\"${train_data}\" \\++valid_data_set_list=\"${val_data}\" \\++dataset_conf.batch_size=20000 \\++dataset_conf.batch_type=\"token\" \\++dataset_conf.num_workers=4 \\++train_conf.max_epoch=50 \\++train_conf.log_interval=1 \\++train_conf.resume=false \\++train_conf.validate_interval=2000 \\++train_conf.save_checkpoint_interval=2000 \\++train_conf.keep_nbest_models=20 \\++train_conf.avg_nbest_model=10 \\++optim_conf.lr=0.0002 \\++output_dir=\"${output_dir}\" &> ${log_file}model(str):模型名字(模型仓库中的ID),此时脚本会自动下载模型到本读;或者本地已经下载好的模型路径。train_data_set_list(str):训练数据路径,默认为jsonl格式,具体参考(例子)。valid_data_set_list(str):验证数据路径,默认为jsonl格式,具体参考(例子)。dataset_conf.batch_type(str):example(默认),batch的类型。example表示按照固定数目batch_size个样本组batch;lengthortoken表示动态组batch,batch总长度或者token数为batch_size。dataset_conf.batch_size(int):与batch_type搭配使用,当batch_type=example时,表示样本个数;当batch_type=length时,表示样本中长度,单位为fbank帧数(1帧10ms)或者文字token个数。train_conf.max_epoch(int):100(默认),训练总epoch数。train_conf.log_interval(int):50(默认),打印日志间隔step数。train_conf.resume(int):True(默认),是否开启断点重训。train_conf.validate_interval(int):5000(默认),训练中做验证测试的间隔step数。train_conf.save_checkpoint_interval(int):5000(默认),训练中模型保存间隔step数。train_conf.avg_keep_nbest_models_type(str):acc(默认),保留nbest的标准为acc(越大越好)。loss表示,保留nbest的标准为loss(越小越好)。train_conf.keep_nbest_models(int):500(默认),保留最大多少个模型参数,配合avg_keep_nbest_models_type按照验证集 acc/loss 保留最佳的n个模型,其他删除,节约存储空间。train_conf.avg_nbest_model(int):10(默认),保留最大多少个模型参数,配合avg_keep_nbest_models_type按照验证集 acc/loss 对最佳的n个模型平均。train_conf.accum_grad(int):1(默认),梯度累积功能。train_conf.grad_clip(float):10.0(默认),梯度截断功能。train_conf.use_fp16(bool):False(默认),开启fp16训练,加快训练速度。optim_conf.lr(float):学习率。output_dir(str):模型保存路径。**kwargs(dict): 所有在config.yaml中参数,均可以直接在此处指定,例如,过滤20s以上长音频:dataset_conf.max_token_length=2000,单位为音频fbank帧数(1帧10ms)或者文字token个数。
其它网络博客参数解释
# 商业转载请联系作者获得授权,非商业转载请注明出处。# For commercial use, please contact the author for authorization. For non-commercial use, please indicate the source.# 协议(License):署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)# 作者(Author):lukeewin# 链接(URL):https://blog.lukeewin.top/archives/train-asr-model-paraformer# 来源(Source):lukeewin的博客../../../funasr/bin/train.py 表示实际运行的训练脚本++model=\"${model_name_or_model_dir}\" 指定原模型++train_data_set_list=\"${train_data}\" 指定训练数据集++valid_data_set_list=\"${val_data}\" 指定验证数据集++dataset_conf.batch_size=20000 指定批处理数量++dataset_conf.batch_type=\"token\" 指定批处理类型++dataset_conf.num_workers=4 指定工作线程数,这里可以根据你机器有多少个内核来设定++train_conf.max_epoch=50 设定最大训练轮次,一般设置在 200 以内,如果设置的过小,会导致训练的不充分,还未到拟合点就提前结束训练,如果设置的过大,会导致过拟合++train_conf.log_interval=1 设定打印日志的间隔++train_conf.resume=false++train_conf.validate_interval=2000 设置多少步验证一下++train_conf.save_checkpoint_interval=2000 设置多少步保存一次 checkpoint++train_conf.keep_nbest_models=20 设定保存多少个最好的模型,如果你硬盘空间不足,那么可以设置小一些++optim_conf.lr=0.0002 设定学习率++output_dir=\"${output_dir}\" &> ${log_file} 指定保存模型路径启动训练:
bash finetune.sh结果如下:
log.txt部分结果如下:
[2025-06-10 18:00:24,452][root][INFO] - download models from model hub: msDownloading Model from https://www.modelscope.cn to directory: /root/.cache/modelscope/hub/models/iic/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch2025-06-10 18:00:25,249 - modelscope - WARNING - Using branch: master as version is unstable, use with cautiontables: ----------- ** dataset_classes ** --------------| register name | class name | class location || AudioDataset | AudioDataset | funasr/datasets/audio_datasets/datasets.py:9 || AudioDatasetHotword | AudioDatasetHotword | funasr/datasets/audio_datasets/datasets.py:121 || AudioLLMARDataset | AudioLLMARDataset | funasr/datasets/llm_datasets/datasets.py:302 || AudioLLMDataset | AudioLLMDataset | funasr/datasets/llm_datasets/datasets.py:167 || AudioLLMNARDataset | AudioLLMNARDataset | funasr/datasets/llm_datasets/datasets.py:8 || AudioLLMQwenAudioDataset | AudioLLMQwenAudioDataset | funasr/datasets/llm_datasets_qwenaudio/datasets.py:8 || AudioLLMVicunaDataset | AudioLLMVicunaDataset | funasr/datasets/llm_datasets_vicuna/datasets.py:8 || KwsMTDataset | KwsMTDataset | funasr/datasets/kws_datasets/datasets.py:9 || OpenAIDataset | OpenAIDataset | funasr/datasets/openai_datasets/datasets.py:10 || OpenAIDatasetMultiTurn | OpenAIDatasetMultiTurn | funasr/datasets/openai_datasets/datasets.py:232 || SenseVoiceCTCDataset | SenseVoiceCTCDataset | funasr/datasets/sense_voice_datasets/datasets.py:234 || SenseVoiceDataset | SenseVoiceDataset | funasr/datasets/sense_voice_datasets/datasets.py:11 |...[2025-06-10 18:05:23,540][root][INFO] - val, rank: 0, epoch: 10/10, data_slice: 0/1, step_in_slice: 57/62, step_in_epoch: 57, total step: 57, (loss_avg_rank: 0.214), (loss_avg_slice: 0.313), (ppl_avg_slice: 1.368e+00), (acc_avg_slice: 0.876), (lr: 0.000e+00), [(\'loss_att\', 0.214), (\'acc\', 0.889), (\'loss_pre\', 0.0), (\'loss\', 0.214), (\'batch_size\', 1)], {\'data_load\': \'0.002\', \'forward_time\': \'0.067\', \'total_time\': \'0.071\'}, GPU, memory: usage: 2.507 GB, peak: 4.168 GB, cache: 2.576 GB, cache_peak: 4.361 GB[2025-06-10 18:05:23,607][root][INFO] - val, rank: 0, epoch: 10/10, data_slice: 0/1, step_in_slice: 58/62, step_in_epoch: 58, total step: 58, (loss_avg_rank: 0.031), (loss_avg_slice: 0.311), (ppl_avg_slice: 1.365e+00), (acc_avg_slice: 0.877), (lr: 0.000e+00), [(\'loss_att\', 0.031), (\'acc\', 1.0), (\'loss_pre\', 0.0), (\'loss\', 0.031), (\'batch_size\', 1)], {\'data_load\': \'0.001\', \'forward_time\': \'0.064\', \'total_time\': \'0.068\'}, GPU, memory: usage: 2.507 GB, peak: 4.168 GB, cache: 2.576 GB, cache_peak: 4.361 GB[2025-06-10 18:05:23,678][root][INFO] - val, rank: 0, epoch: 10/10, data_slice: 0/1, step_in_slice: 59/62, step_in_epoch: 59, total step: 59, (loss_avg_rank: 0.085), (loss_avg_slice: 0.307), (ppl_avg_slice: 1.359e+00), (acc_avg_slice: 0.879), (lr: 0.000e+00), [(\'loss_att\', 0.085), (\'acc\', 1.0), (\'loss_pre\', 0.0), (\'loss\', 0.085), (\'batch_size\', 1)], {\'data_load\': \'0.001\', \'forward_time\': \'0.067\', \'total_time\': \'0.071\'}, GPU, memory: usage: 2.507 GB, peak: 4.168 GB, cache: 2.576 GB, cache_peak: 4.361 GB[2025-06-10 18:05:23,748][root][INFO] - val, rank: 0, epoch: 10/10, data_slice: 0/1, step_in_slice: 60/62, step_in_epoch: 60, total step: 60, (loss_avg_rank: 0.009), (loss_avg_slice: 0.303), (ppl_avg_slice: 1.354e+00), (acc_avg_slice: 0.881), (lr: 0.000e+00), [(\'loss_att\', 0.009), (\'acc\', 1.0), (\'loss_pre\', 0.0), (\'loss\', 0.009), (\'batch_size\', 1)], {\'data_load\': \'0.001\', \'forward_time\': \'0.066\', \'total_time\': \'0.070\'}, GPU, memory: usage: 2.507 GB, peak: 4.168 GB, cache: 2.576 GB, cache_peak: 4.361 GB[2025-06-10 18:05:23,817][root][INFO] - val, rank: 0, epoch: 10/10, data_slice: 0/1, step_in_slice: 61/62, step_in_epoch: 61, total step: 61, (loss_avg_rank: 0.028), (loss_avg_slice: 0.298), (ppl_avg_slice: 1.347e+00), (acc_avg_slice: 0.883), (lr: 0.000e+00), [(\'loss_att\', 0.028), (\'acc\', 1.0), (\'loss_pre\', 0.0), (\'loss\', 0.028), (\'batch_size\', 1)], {\'data_load\': \'0.001\', \'forward_time\': \'0.064\', \'total_time\': \'0.068\'}, GPU, memory: usage: 2.507 GB, peak: 4.168 GB, cache: 2.576 GB, cache_peak: 4.361 GB[2025-06-10 18:05:23,884][root][INFO] - val, rank: 0, epoch: 10/10, data_slice: 0/1, step_in_slice: 62/62, step_in_epoch: 62, total step: 62, (loss_avg_rank: 0.016), (loss_avg_slice: 0.294), (ppl_avg_slice: 1.341e+00), (acc_avg_slice: 0.885), (lr: 0.000e+00), [(\'loss_att\', 0.016), (\'acc\', 1.0), (\'loss_pre\', 0.0), (\'loss\', 0.016), (\'batch_size\', 1)], {\'data_load\': \'0.001\', \'forward_time\': \'0.063\', \'total_time\': \'0.068\'}, GPU, memory: usage: 2.507 GB, peak: 4.168 GB, cache: 2.576 GB, cache_peak: 4.361 GB[2025-06-10 18:05:23,976][root][INFO] - Save checkpoint: 10, rank: 0, local_rank: 0[2025-06-10 18:05:26,540][root][INFO] - Checkpoint saved to /root/autodl-tmp/outputs/model.pt.ep10[2025-06-10 18:05:33,502][root][INFO] - Update best acc: 0.8866, /root/autodl-tmp/outputs/model.pt.best[2025-06-10 18:05:33,503][root][INFO] - rank: 0, time_escaped_epoch: 0.008 hours, estimated to finish 10 epoch: 0.008 hoursaverage_checkpoints: [\'/root/autodl-tmp/outputs/model.pt.ep10\', \'/root/autodl-tmp/outputs/model.pt.ep7\', \'/root/autodl-tmp/outputs/model.pt.ep8\', \'/root/autodl-tmp/outputs/model.pt.ep9\', \'/root/autodl-tmp/outputs/model.pt.ep6\']5 使用训练的模型进行测试
脚本如下:
import osimport jsonfrom funasr import AutoModel# 配置FunASR模型model = AutoModel( model=\"/root/autodl-tmp/outputs\", model_revision=\"v2.0.4\", vad_model=\"fsmn-vad\", vad_model_revision=\"v2.0.4\", punc_model=\"ct-punc-c\", punc_model_revision=\"v2.0.4\",)def process_audio_folder(audio_dir, output_json, hotword=None, batch_size_s=300): \"\"\" 处理指定目录下的所有wav文件并保存识别结果到JSON 参数: audio_dir (str): 包含wav文件的目录路径 output_json (str): 输出JSON文件路径 hotword (str): 热词,提高特定词汇的识别准确率 batch_size_s (int): 处理音频的批大小(秒) \"\"\" # 存储所有音频文件的识别结果 results = [] # 遍历目录中的所有文件 for root, _, files in os.walk(audio_dir): for file in files: if file.lower().endswith(\'.wav\'): file_path = os.path.join(root, file) try: # 相对路径作为标识 relative_path = os.path.relpath(file_path, audio_dir) # 进行音频识别 print(f\"正在处理: {relative_path}\") res = model.generate( input=file_path, batch_size_s=batch_size_s, hotword=hotword ) # 构建结果条目 result_entry = { \"audio_file\": relative_path, \"transcription\": res, \"status\": \"success\" } results.append(result_entry) print(f\"处理完成: {relative_path}\") except Exception as e: print(f\"处理失败: {file_path}, 错误: {str(e)}\") results.append({ \"audio_file\": relative_path, \"error\": str(e), \"status\": \"error\" }) # 保存结果到JSON文件 with open(output_json, \'w\', encoding=\'utf-8\') as f: json.dump(results, f, ensure_ascii=False, indent=2) print(f\"所有音频处理完成,结果已保存到: {output_json}\")if __name__ == \"__main__\": # 配置参数 # AUDIO_DIR = \"/root/FunASR/data/list2/wav\" # 替换为你的音频文件夹路径 AUDIO_DIR = \"./temp\" # 替换为你的音频文件夹路径 OUTPUT_JSON = \"./asr_results_new.json\" # 输出JSON文件路径 HOTWORD = \"魔搭\" # 热词 # 处理音频文件夹 process_audio_folder(AUDIO_DIR, OUTPUT_JSON, hotword=HOTWORD)结果如下:
[ { \"audio_file\": \"0001.wav\", \"transcription\": [ { \"key\": \"0001\", \"text\": \"上课起立好,同学们好,请坐今天在上课之前呀,老师先请同学们听一个故事。嘿嘿。战国时期,当楚国最强盛的时候,北方的人们都害怕楚宣王手下的大将朝夕去楚宣王感到很奇怪,就问朝中的大臣,这是为什么?当时有一位名叫江里的大臣,向他说起了一段故事,将你说的故事请听虎求百兽而食之得狐。胡曰子无敢食,我也。天帝使我长百兽,今子使我是逆天帝命也。子以我为不信,吾为子先行子随我后观,百兽之见我而敢不走乎虎以为然,故遂与之,行手见之皆走虎不知兽畏己而走也。以为未狐听懂了吗?听懂听懂了哦,你听懂了,他讲的是什么?他讲的没听懂哦,你说你听懂了,你说讲的是什么?是狐假虎威。哎,这个故事讲的是狐假虎威没听懂没关系,因为这个故事是两千多年前战国策里边记载的狐假虎威。我们今天也学习狐假虎威,它是一个成语故事,刚说过,距现在已经多少年了?两千两千多年了,这个题目有四个字,这四个字就把狐假虎威讲的什么,告诉他课文里边呀也有一句话,还有也有一句话也是讲狐假虎威讲的是什么?请打开你的语文书,九十九天,他现在找一找哪句话,告诉了我们狐假虎威讲的是什么呢?已经了好几个同学。\" } ], \"status\": \"success\" }]

