面向边缘计算的AI Agent模型蒸馏与部署优化技术研究【附代码】
面向边缘计算的AI Agent模型蒸馏与部署优化技术研究【附代码】
一、引言
随着人工智能(AI)模型的规模不断扩大,AI Agent 在自然语言处理、智能决策和多模态推理等场景中展现出了强大的能力。然而,大规模模型往往伴随着 庞大的参数量、推理延迟和高昂的计算成本。如何在保证性能的同时,实现 模型压缩与加速,成为AI Agent落地的关键问题。
模型蒸馏(Knowledge Distillation, KD) 作为一种经典的模型压缩技术,能够在保持模型精度的同时,大幅度减少计算开销,为AI Agent提供轻量化的推理能力。
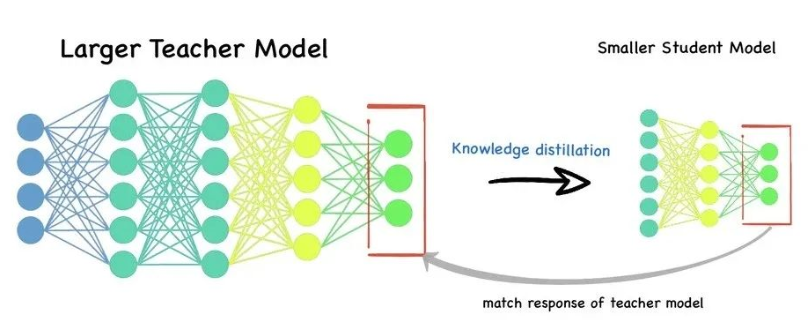
二、模型蒸馏的基本原理
模型蒸馏的核心思想是:
- 教师模型(Teacher Model):通常为性能优越的大模型,拥有强大的表达能力。
- 学生模型(Student Model):轻量化的小模型,目标是学习教师模型的知识。
通过蒸馏过程,学生模型不仅学习真实标签(Hard Label),还学习教师模型的 输出分布(Soft Label),从而获得更强的泛化能

