华为云Flexus+DeepSeek征文|华为云CCE高可用部署与性能监控:构建稳健云架构的最佳实践


前引: 容器化部署已经成为许多企业实现高效、灵活应用的关键技术之一。作为华为云的核心云服务之一,容器引擎(CCE)为用户提供了强大的容器编排与管理能力。然而,随着应用规模的扩大以及服务复杂度的增加,如何确保CCE环境的高可用性,并持续监控其性能,成为了所有使用该平台的企业面临的重要挑战!
本文将详细介绍如何在华为云上部署CCE高可用架构,确保系统的高稳定性和抗故障能力。通过结合华为云的监控与告警服务,您将学会如何实时监控系统性能,及时发现潜在的瓶颈与故障风险,从而提高云端应用的整体可靠性和可扩展性!
目录
【一】华为云CCE简介与应用场景
(1)什么是华为云CCE
(2)CCE的核心功能与优势
功能:
优势:
【二】CCE高可用架构设计
(1)高可用性概念与重要性
(2)CCE高可用部署的设计原则
(3)CCE高可用性架构部署步骤
【三】CCE高可用“一键部署”教学
获取桶名称:
创建秘钥:
配置委托:
委托授权:
教学步骤:
【四】监测CCE性能的工具与方法:Linux插件+集群
(1)华为云监控服务概述
(2)核心功能
(3)使用Linux命令安装插件监控
(4)使用集群监控
(5)监控数据如何分析
分析步骤:
分析工具
(6)优化建议
【五】常见问题与故障排查
(1)常见的CCE高可用性问题
(2)性能瓶颈排查
【一】华为云CCE简介与应用场景
(1)什么是华为云CCE
华为云CCE(Cloud Container Engine)是一种:
CCE集群介绍
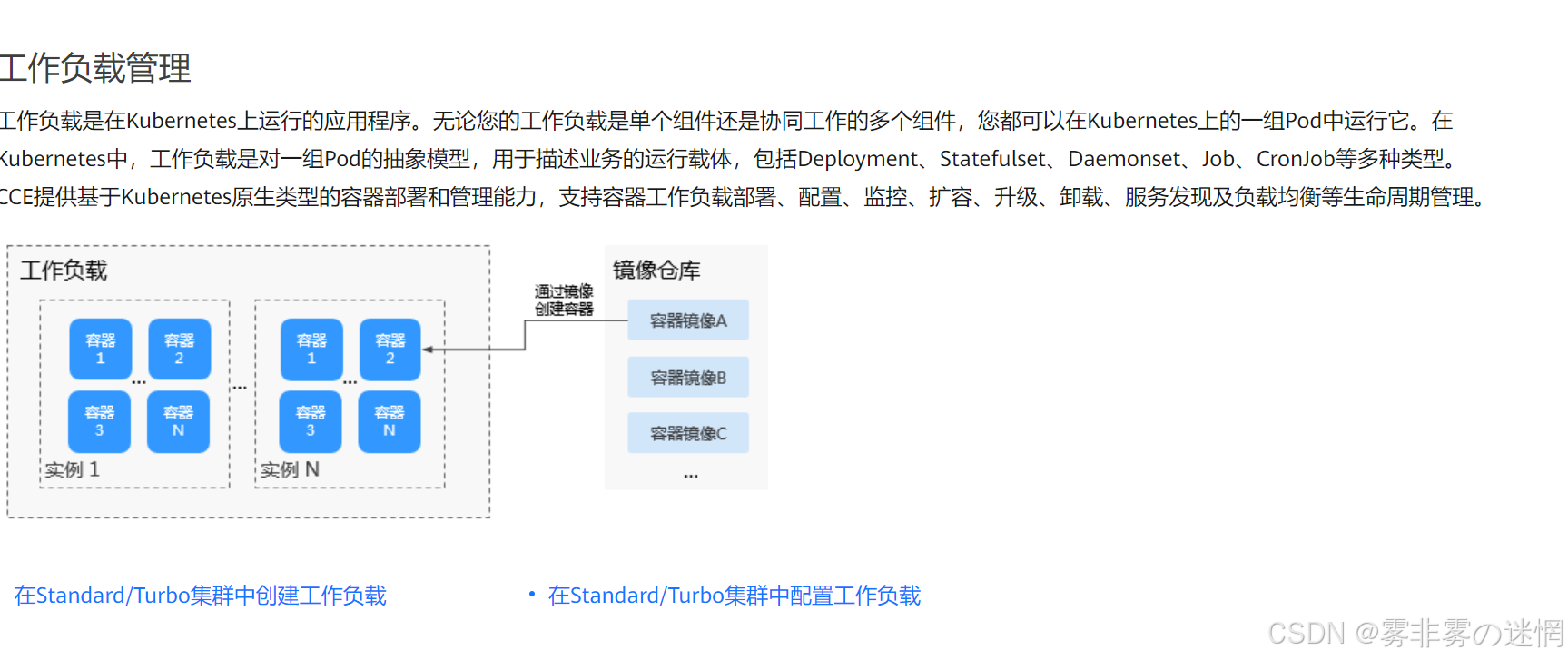
容器技术的云原生服务平台,主要用于管理和部署容器化应用程序。它基于Kubernetes和Docker技术,提供高效的容器编排、管理和自动化运维能力,帮助企业快速构建、部署和管理高可用、弹性的云原生应用。CCE支持多种场景,包括Web应用、微服务架构、AI开发平台等,通过与华为云其他服务的无缝集成(如负载均衡、云存储等),为用户提供一站式的容器化解决方案!
(2)CCE的核心功能与优势
功能:
比如:容器编排与管理、弹性伸缩、高可用性与容灾、集成式CI/CDd等等,例如表格总结
功能 描述 容器编排与管理 基于Kubernetes,支持Pod、Service、Deployment等资源的自动化管理! 弹性伸缩 根据负载自动调整容器集群规模,确保资源高效利用 高可用性与容灾 支持多可用区部署,结合负载均衡和故障转移机制,确保服务稳定性 集成式CI/CD 支持持续集成与持续交付,简化开发、测试和上线流程 安全性保障 提供网络隔离、身份认证、访问控制等功能,确保应用和数据安全 监控与告警 集成Cloud Eye,实时监控集群性能,支持告警和自动化响应 服务集成 与华为云EIP、OBS、Redis等服务无缝对接,构建复杂云原生架构
优势:
它的优势也是很有竞争力的,比如:
优势 描述 灵活性 支持多种计算资源类型,满足不同应用场景需求 高效性 自动化运维和弹性伸缩功能,减少手动操作,提升资源利用率 易于集成 与华为云生态深度集成,简化复杂应用的开发与部署 成本优化 按需计费和资源优化功能,降低运维成本 高可用性 多可用区部署和负载均衡技术,确保服务稳定运行 安全可靠 多层次安全防护机制,保障应用和数据安全

【二】CCE高可用架构设计
(1)高可用性概念与重要性
概念:
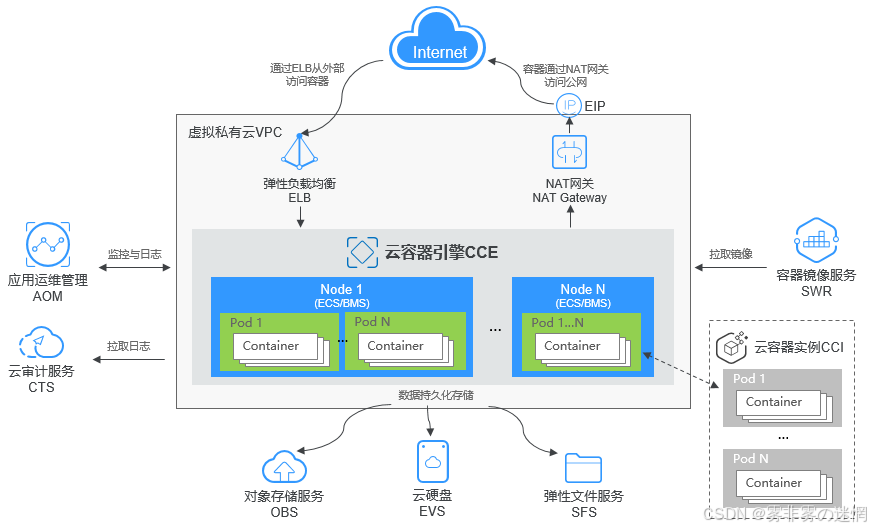
高可用性(High Availability, HA)是指通过系统设计和技术手段,确保服务在面对硬件故障、软件错误或网络中断等异常情况时,仍能持续提供稳定、可靠的服务,最大程度减少宕机时间。华为云CCE通过多节点、多可用区(AZ)和负载均衡等技术实现高可用性,确保容器化应用的稳定运行
重要性:
业务连续性:
高可用架构能够确保核心业务在故障情况下仍能正常运行,避免因服务中断导致的经济损失或声誉损害
提升用户体验:
通过减少服务中断时间,保证用户能够持续、流畅地访问应用,提升客户满意度
风险规避:
高可用性架构通过冗余设计和自动故障转移,降低单点故障(Single Point of Failure, SPOF)带来的风险
支持大规模应用:
对于需要处理高并发请求的场景(如Web服务、微服务架构等),高可用性是确保系统稳定性和可扩展性的关键
(2)CCE高可用部署的设计原则
基于华为云CCE的特点和实战学习,以下是CCE高可用部署的核心设计原则:
冗余性设计:
(1)部署多个节点(虚拟机或裸金属服务器)运行容器化应用,避免单一节点故障导致整个服务不可用
(2)数据层面通过分布式存储(如华为云OBS或分布式数据库)实现多副本存储,确保数据的高可用性
负载均衡:
(1)使用华为云的弹性负载均衡(ELB)服务,将用户请求均匀分配到不同的CCE节点,防止单一节点过载
(2)支持动态调整流量分配策略(如轮询、最少连接等),优化资源利用率
多可用区(AZ)部署:
(1)在多个可用区部署CCE集群,确保即使某一可用区发生故障(如电力或网络中断),其他可用区的服务仍可正常运行
(2)结合跨区域容灾机制,提升系统的全局可用性
自动化故障转移:
(1)配置自动检测和故障转移机制,当某个节点或Pod出现故障时,系统自动将流量切换到健康的节点或Pod
(2)利用Kubernetes的健康检查(Liveness Probe和Readiness Probe)确保服务始终运行在健康状态
可扩展性:
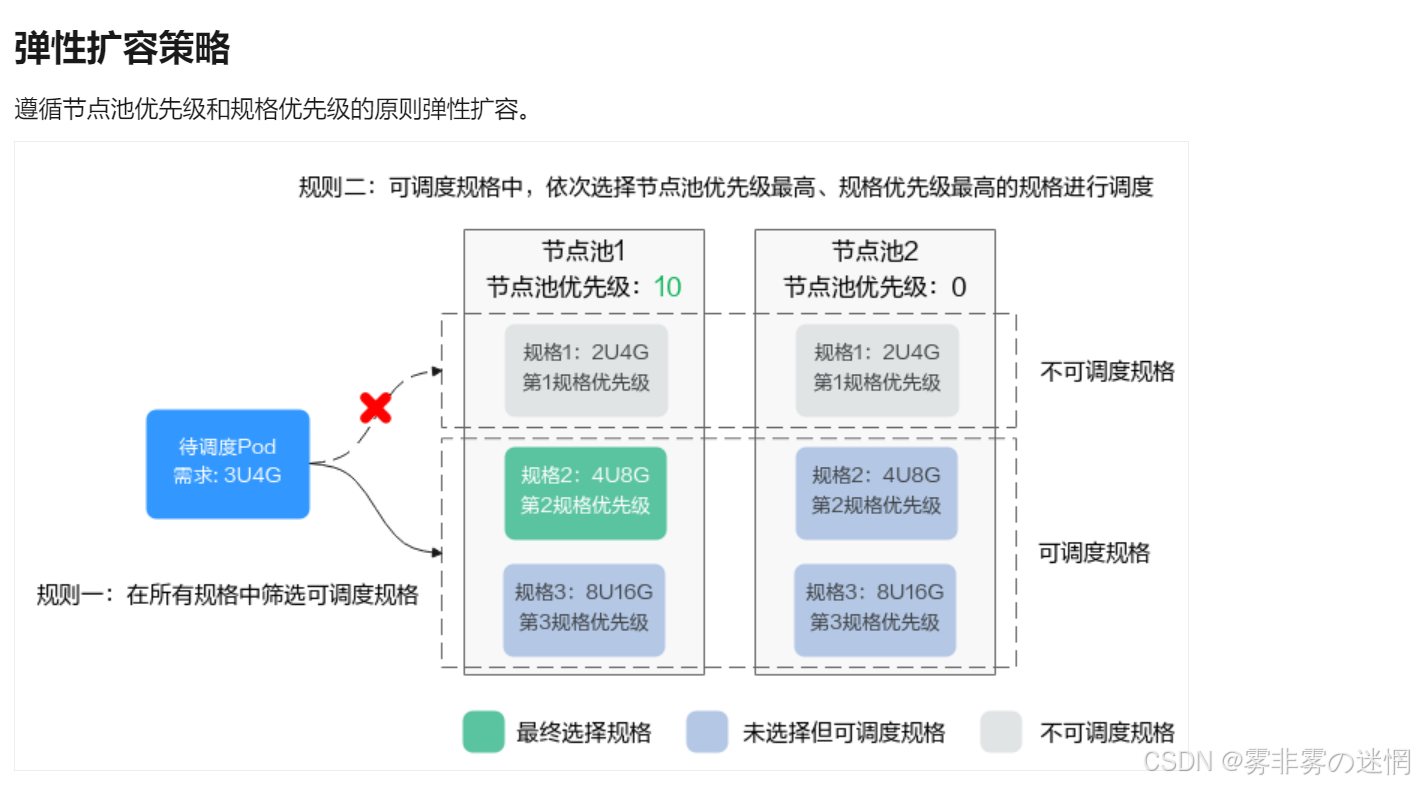
(1)支持水平扩展(Horizontal Pod Autoscaling, HPA)和垂直扩展(Vertical Pod Autoscaling, VPA),根据负载动态调整节点或Pod数量
(2)结合华为云的弹性伸缩服务(AS),实现资源的动态分配和优化
安全性与隔离:
(1)通过VPC(虚拟私有云)和子网隔离,确保网络层面的安全性和高可用性
(2)实施细粒度的访问控制(如RBAC)和安全策略,防止未经授权的访问影响服务可用性
(3)CCE高可用性架构部署步骤

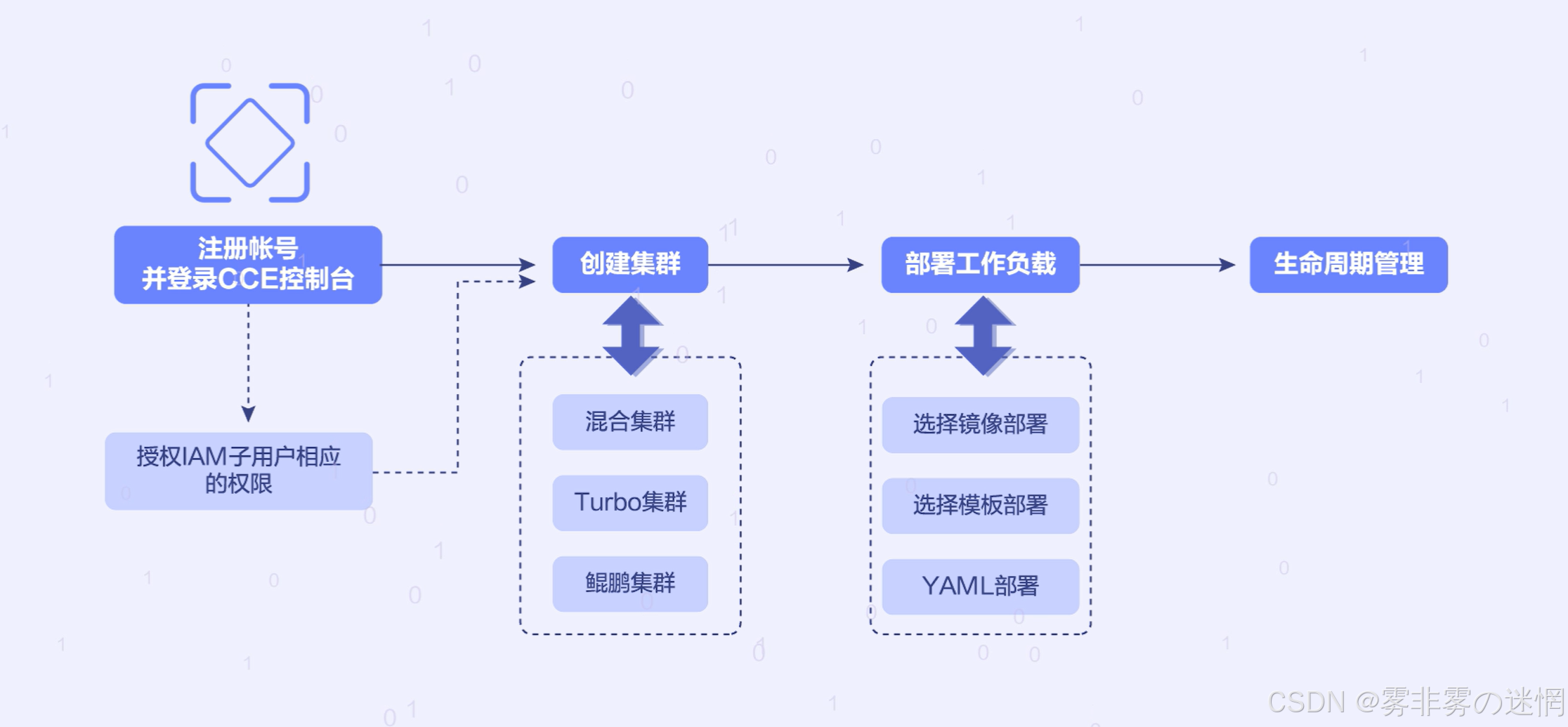
环境规划与准备
选择合适的VPC和子网:
(1)在华为云控制台创建VPC,并划分多个子网以实现网络隔离
(2)根据业务需求选择适当的可用区(AZ),建议至少跨两个可用区部署以确保容灾能力
确定计算资源:
(1)选择合适的云服务器类型(如ECS虚拟机或BMS裸金属服务器)作为CCE集群的节点
(2)根据应用负载需求,配置节点的CPU、内存和存储资源
创建CCE集群
在华为云CCE控制台创建Kubernetes集群,选择“高可用集群”模式
配置集群参数:
节点数量:建议至少3个主节点(Master Node)以实现控制平面的高可用性
工作节点(Worker Node):根据应用规模配置多个工作节点,确保Pod分布在不同节点上
网络模式:选择VPC网络或CCE Turbo(支持高性能网络)以优化通信效率
配置负载均衡
(1)创建华为云弹性负载均衡(ELB)实例,绑定到CCE集群的Service资源
(2)配置负载均衡策略(如轮询或最少连接),将用户请求分发到多个Pod或节点
(3)设置健康检查规则,确保只有健康的Pod接收流量
部署应用程序
(1)使用Kubernetes的Deployment或StatefulSet资源部署容器化应用
(2)配置Pod副本数(Replicas),确保同一应用的多个实例运行在不同节点上
(3)利用Affinity和Anti-Affinity规则,优化Pod的调度分布,避免单点故障
设置自动故障转移与恢复
(1)配置Kubernetes的健康检查(Liveness Probe和Readiness Probe),监控Pod的运行状态
(2)启用节点自动修复功能,当检测到节点故障时,CCE自动替换故障节点
(3)配置DNS或ELB的故障转移策略,确保流量快速切换到健康的可用区或节点
集成监控与告警
(1)使用华为云Cloud Eye服务监控CCE集群的性能指标(如CPU使用率、内存占用、网络流量等)
(2)配置告警规则,当资源使用率超过阈值或节点故障时,触发通知(如短信或邮件)
(3)结合Prometheus和Grafana(可通过CCE的扩展插件安装),实现更细粒度的监控仪表盘
实现弹性伸缩
(1)配置HPA(Horizontal Pod Autoscaling),根据CPU或内存使用率动态调整Pod数量
(2)配置集群自动伸缩(Cluster Autoscaler),根据负载自动增减工作节点
(3)结合华为云的AS(Auto Scaling)服务,实现更灵活的资源管理
测试与验证
(1)模拟节点故障或网络中断,验证故障转移机制是否生效
(2)进行压力测试,检查负载均衡和弹性伸缩是否满足高并发需求
(3)定期检查监控数据,确保系统运行在健康状态
【三】CCE高可用“一键部署”教学
获取桶名称:
创建秘钥:
配置委托:
委托授权:
教学步骤:
(1)选择高可用部署,打开
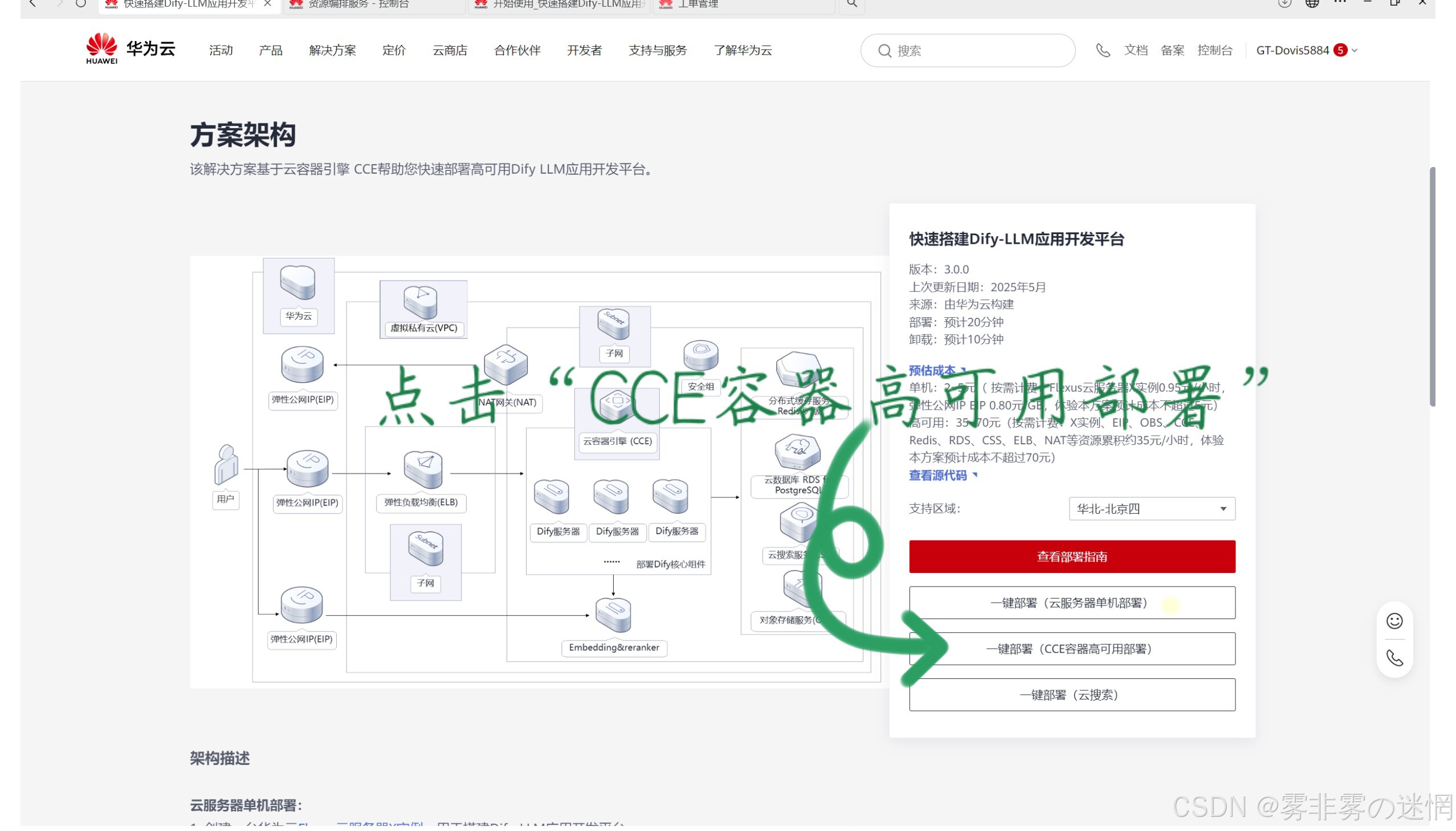
(2)这个默认配置我们可以不管,直接点击下一步!
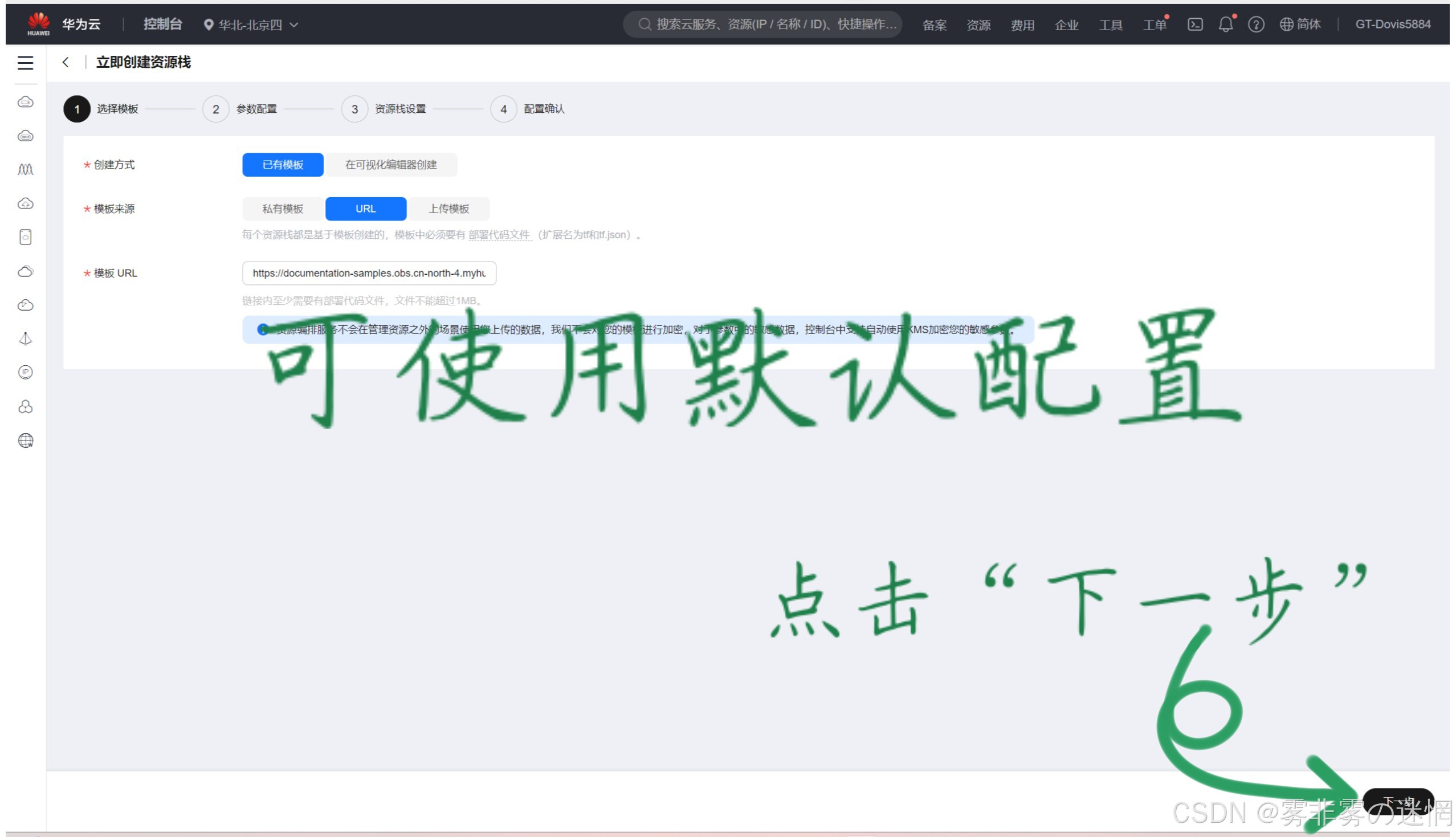
(3)这里的任何密码都需要严格按照规定设置,否则很容易部署失败
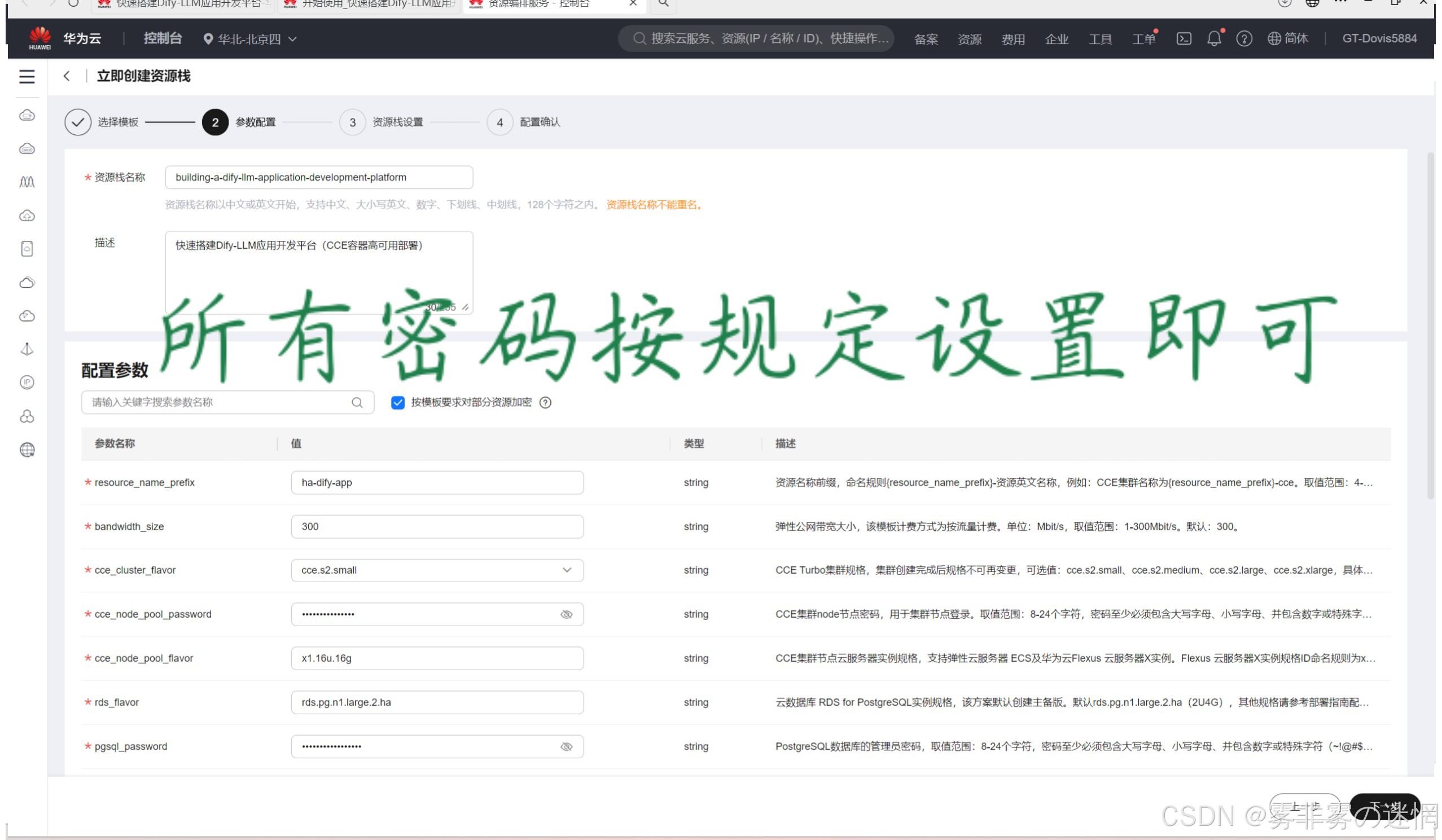
(4)现在我们看到这个页面的下面,有三个需要特别特别注意,它们一般就是部署失败的原因,参考上面的步骤分别获取:桶名称、秘钥ID、秘钥
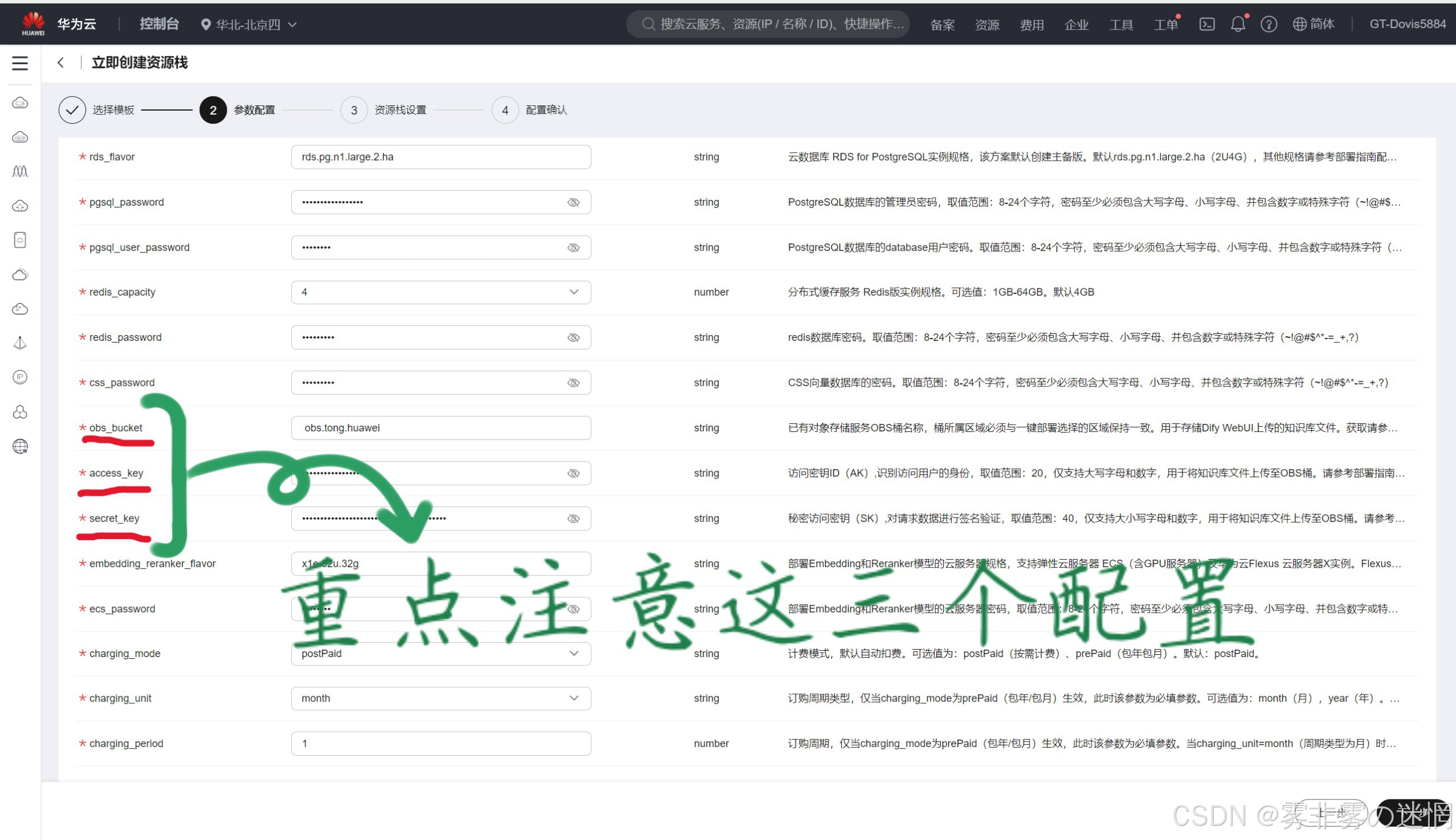
(5)配置栏配置好之后,我们可以看见这里有个委托,这是必须设置的
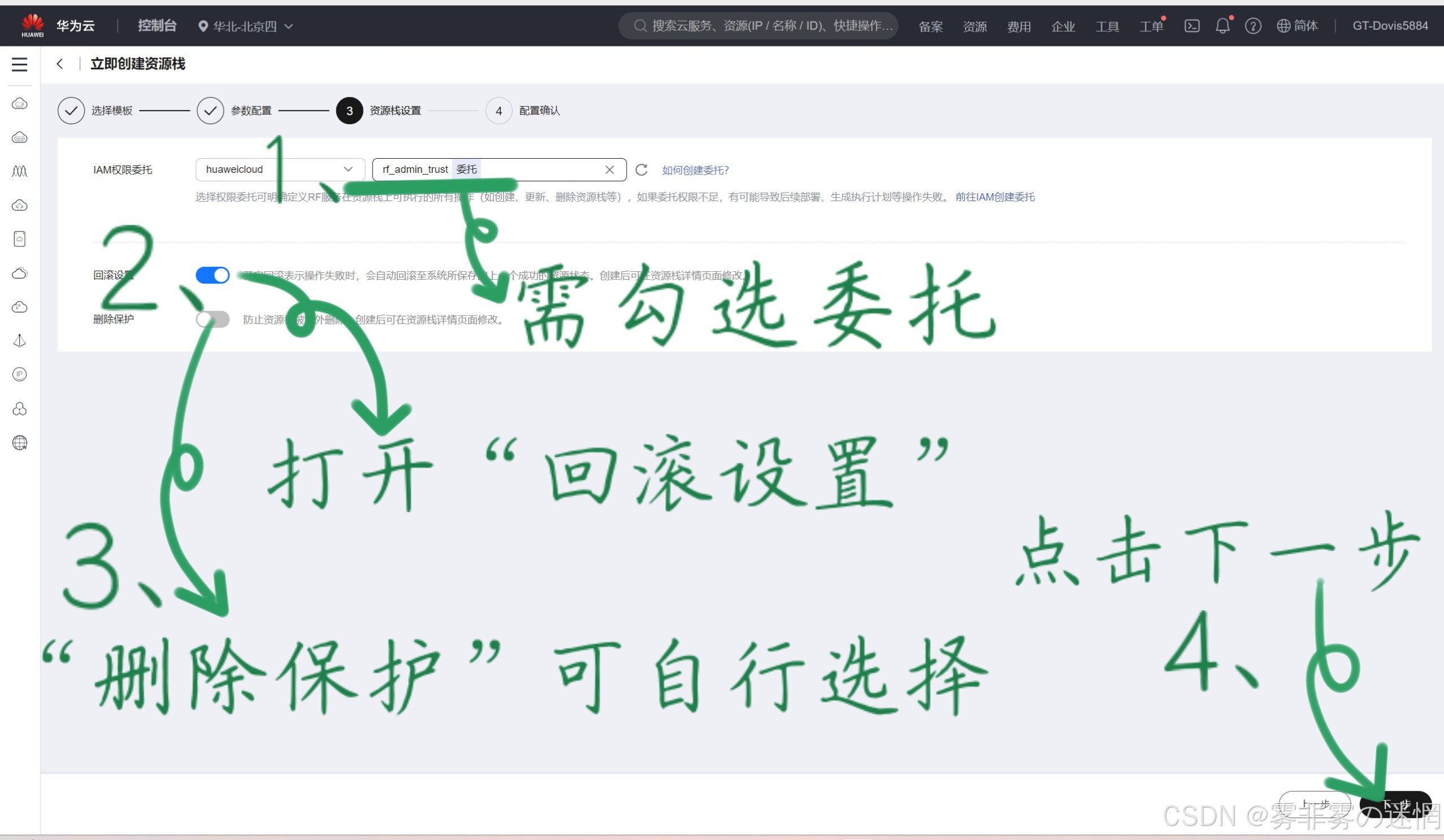
(6)点击创建执行计划
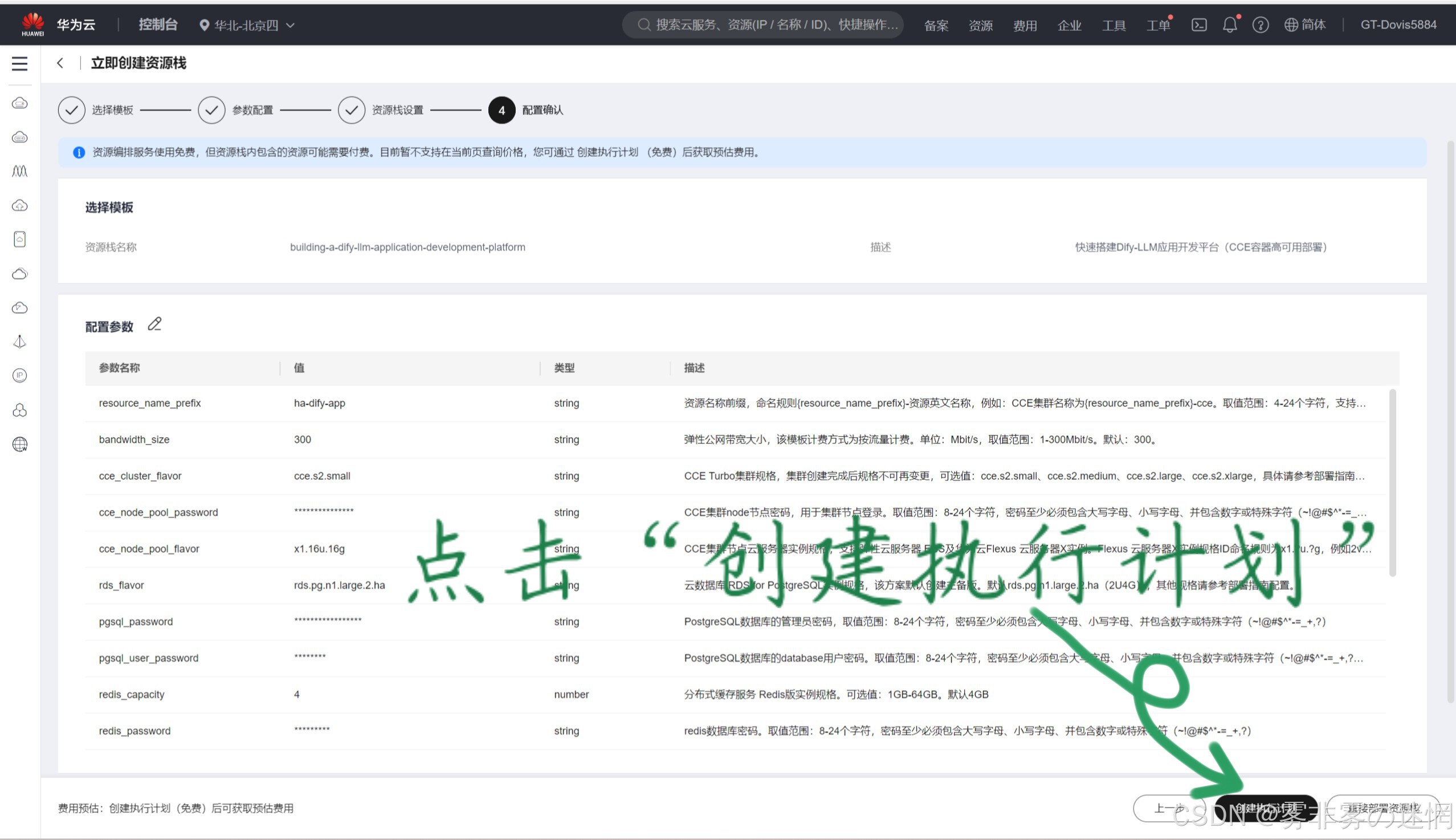
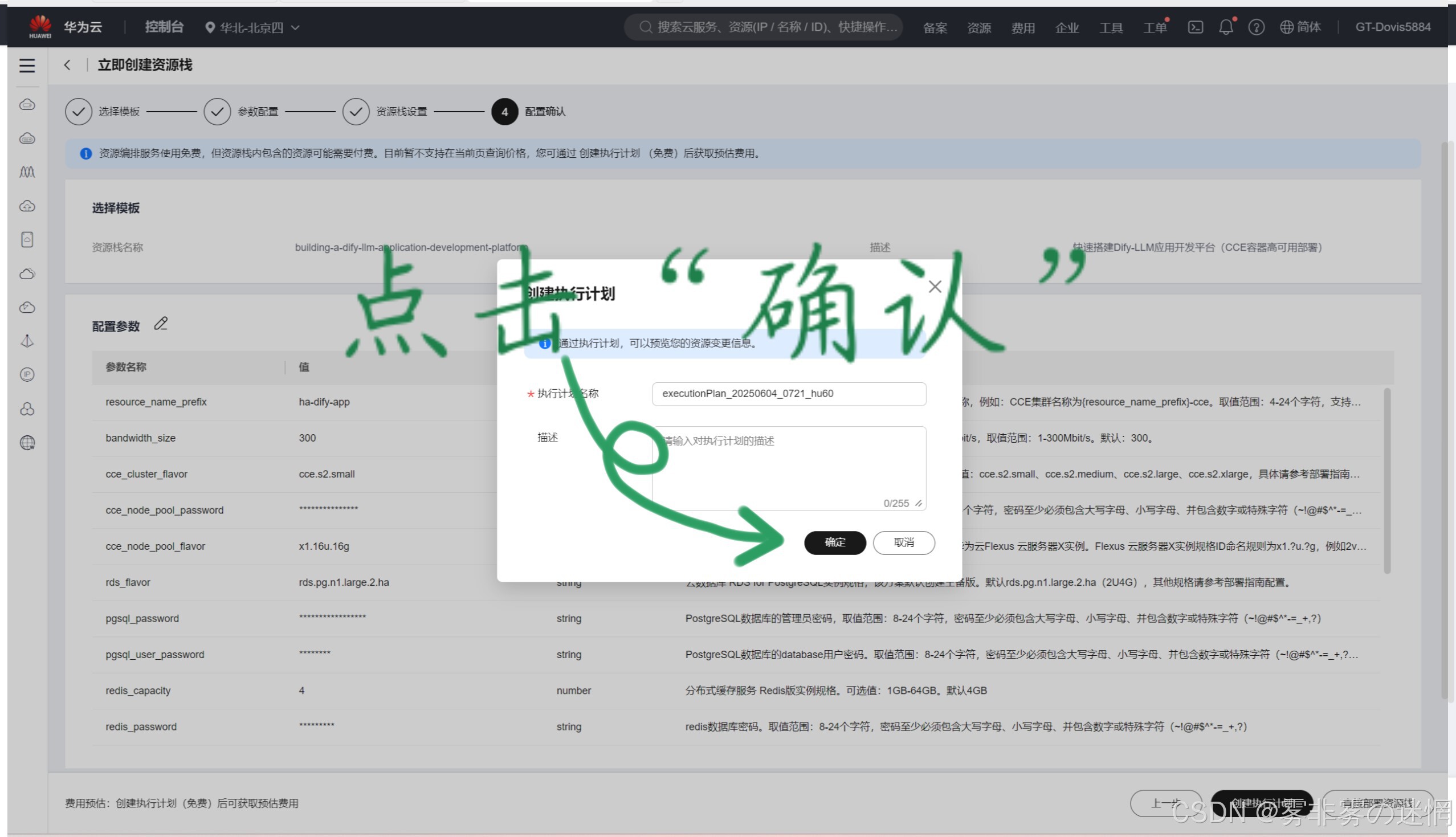
(7)完成配置确认
(8)待创建成功之后,开始部署获得DIfy平台的IP
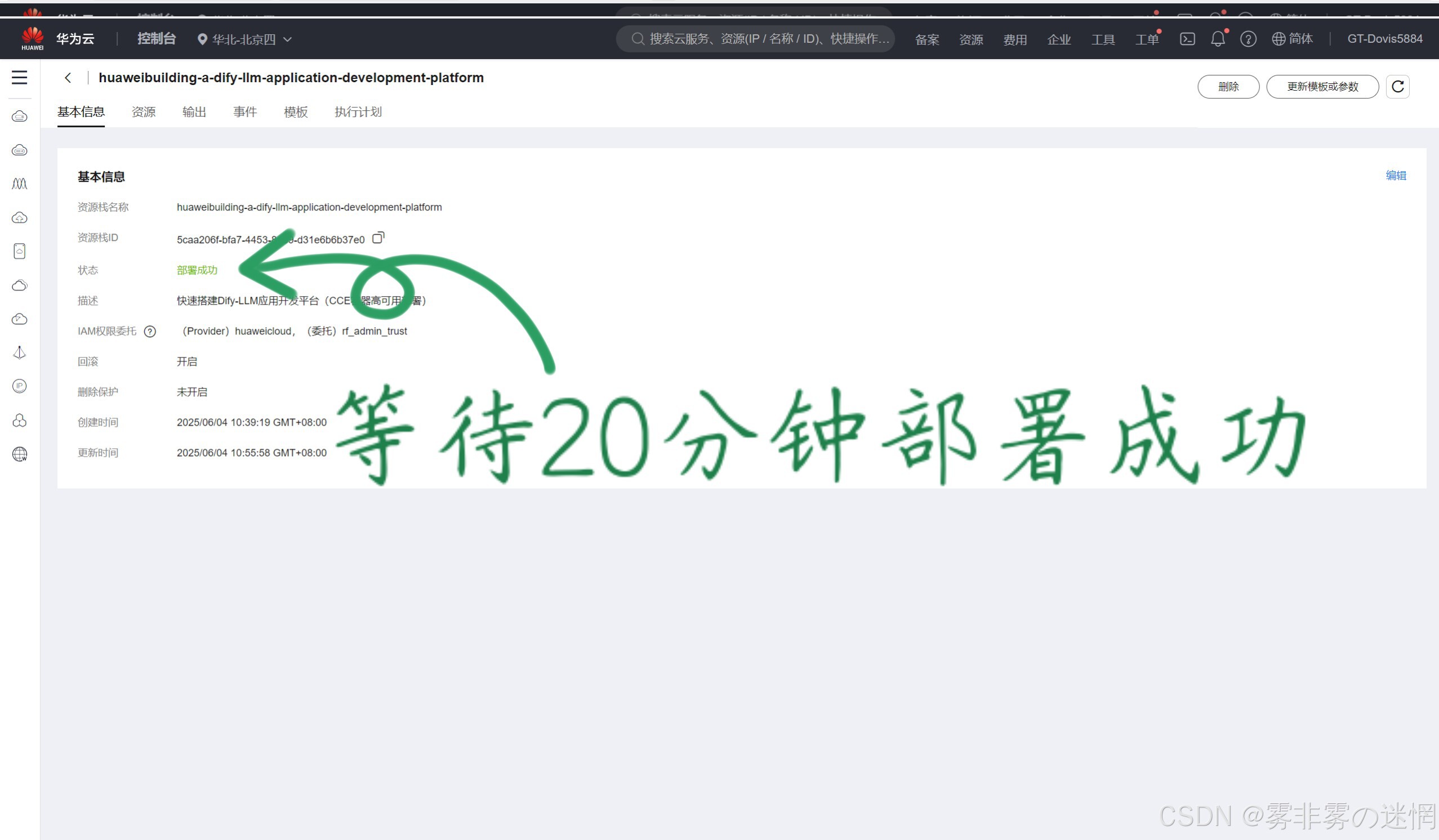
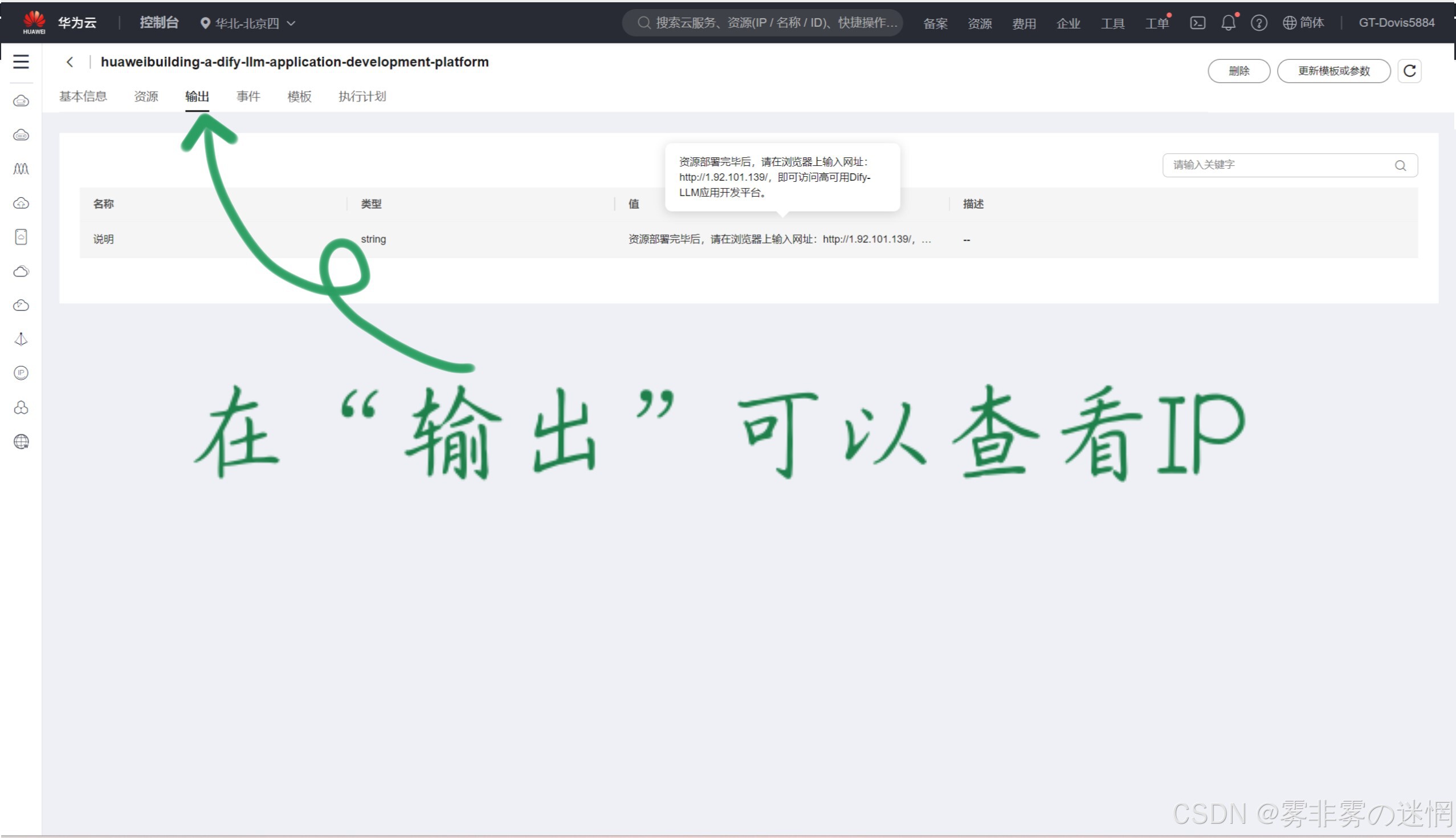
【四】监测CCE性能的工具与方法:Linux插件+集群
(1)华为云监控服务概述
华为云提供多种监控服务,其中与CCE高可用部署和性能监控最相关的是 Cloud Eye(云监控服务),以及与第三方工具(如Prometheus和Grafana)的集成能力!下面我们开始学习哈!
(2)核心功能
实时监控:
监控CCE集群的健康状态、节点资源使用情况(如CPU、内存、磁盘I/O)和网络性能(如吞吐量、延迟)
支持对Pod级别的指标(如容器CPU使用率、内存占用、请求响应时间)进行细粒度监控
告警机制:
支持用户自定义告警规则(如CPU使用率超过80%时触发告警)
提供多种通知方式(如短信、邮件、Webhook),便于及时响应异常
可视化仪表盘:
通过图形化界面展示监控数据,支持多维度分析(如按集群、节点、Pod或时间段)
可集成Prometheus和Grafana,提供更丰富的自定义仪表盘
自动化运维:
支持与华为云其他服务(如AOM、AS)联动,实现异常自动处理和资源弹性伸缩
多服务集成:
支持监控华为云其他资源(如ELB、OBS、Redis),实现全栈式监控
(3)使用Linux命令安装插件监控
(1)Flexus X服务点击远程登录
(2)点击立刻登录
(3)先输入“root”回车。再输入密码(部署时设置的),再回车,就可以看到下面这个界面
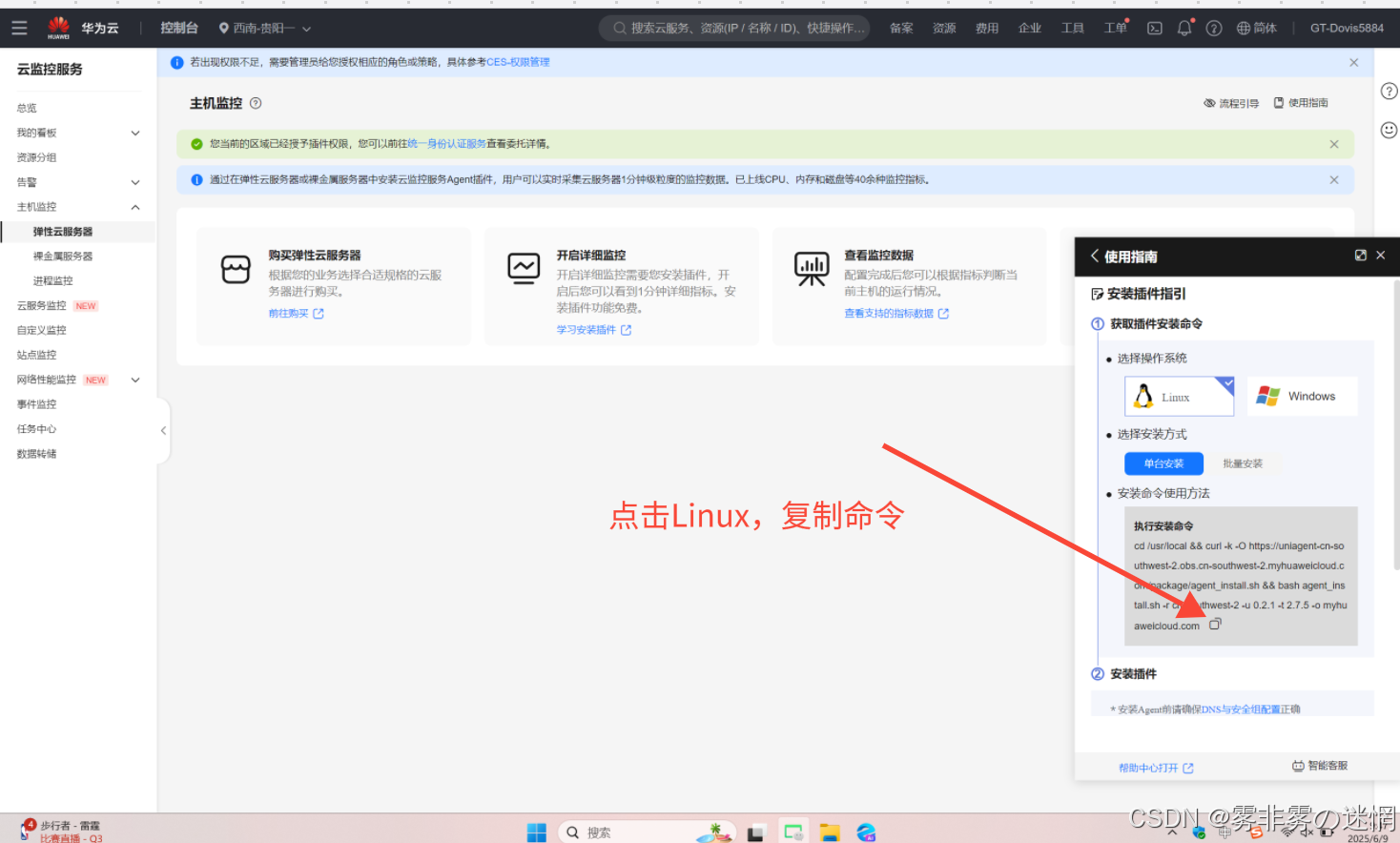
(4)点击弹性云云服务器,点击“开始详细监控”,点击 Linux,复制下面的执行命名
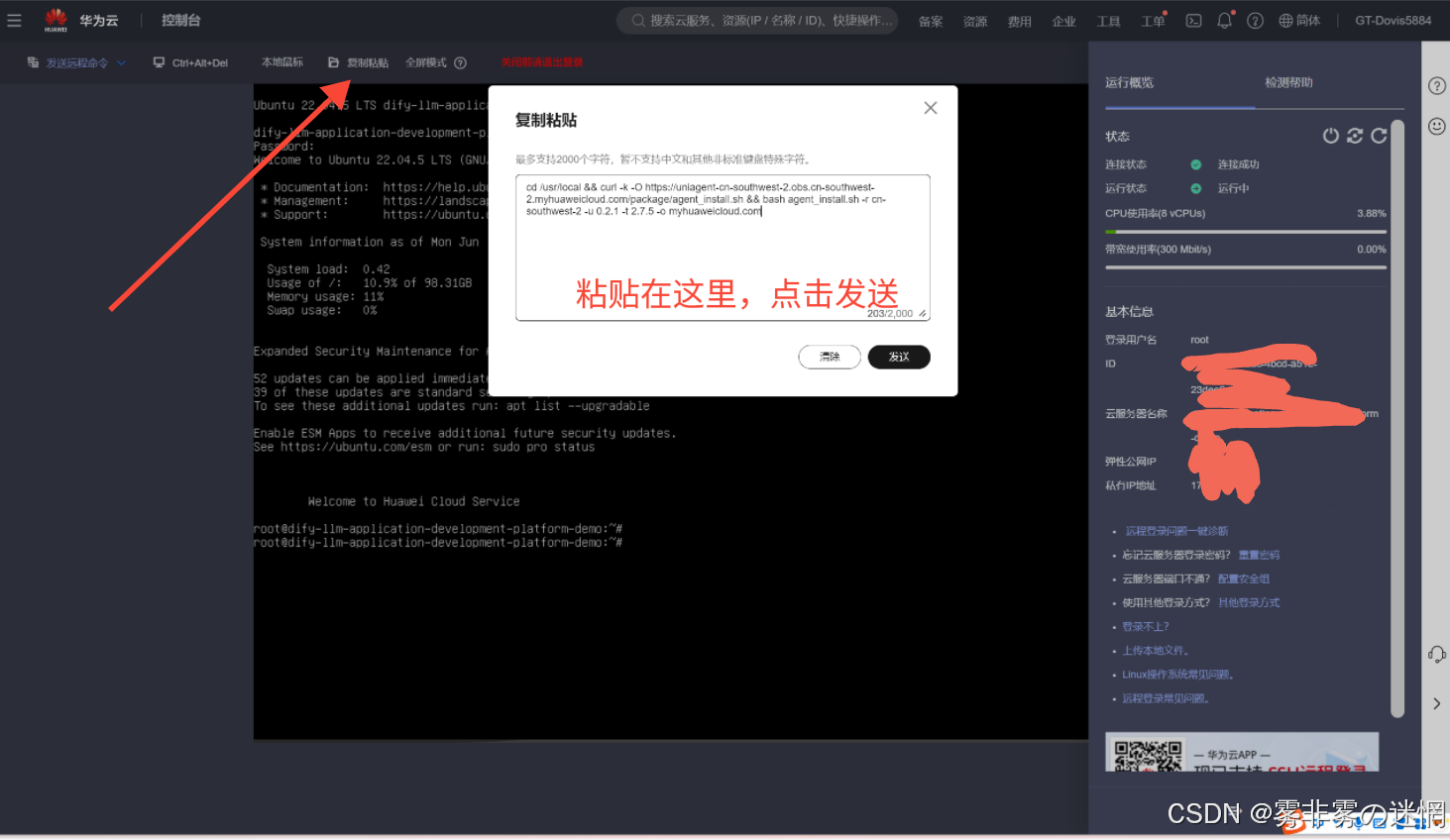
(5)然后回到登录界面,点击左上角的复制粘贴,粘贴命名然后发送
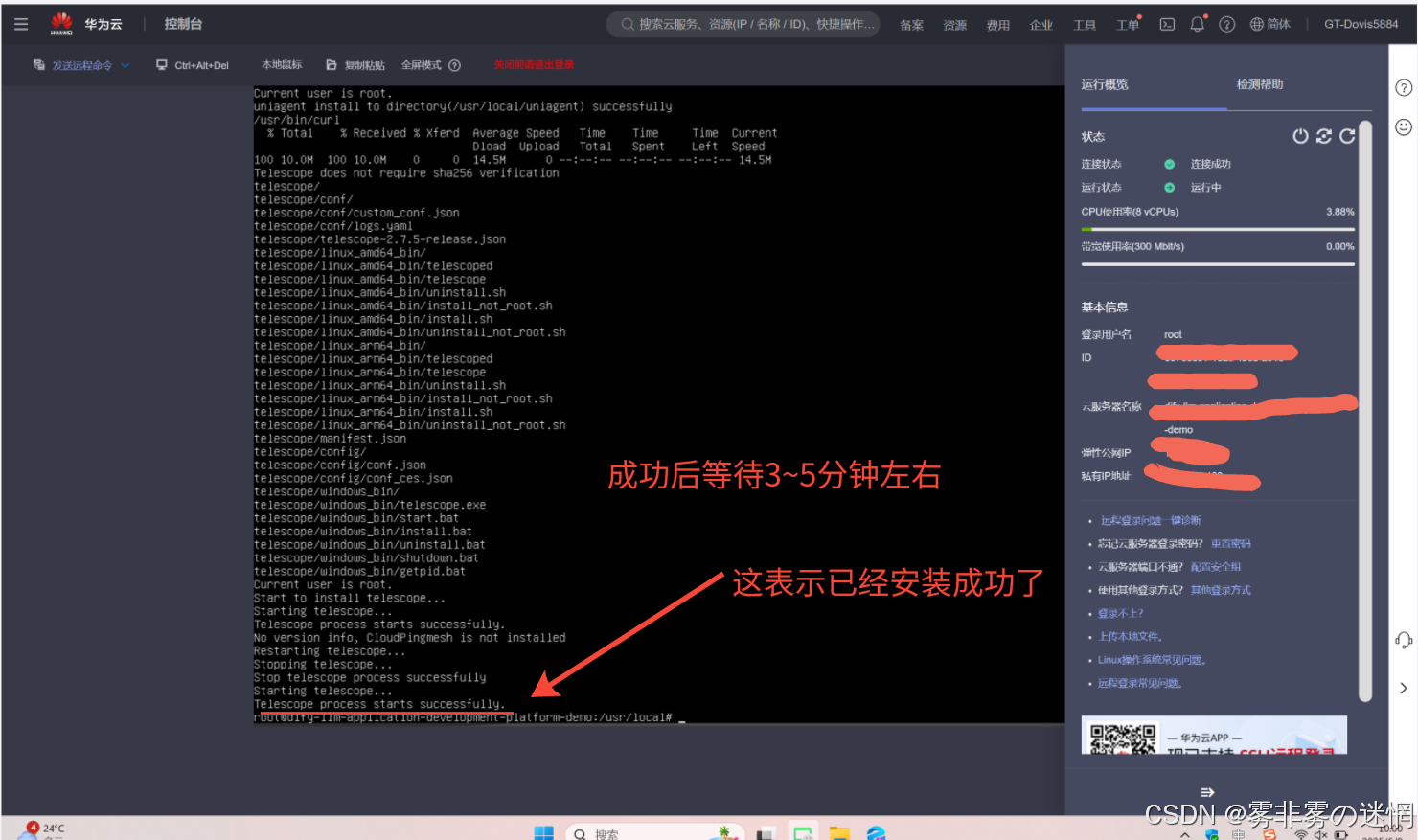
(6)这样就表示成功了,然后等待3~5分钟,就可以开始我们的“操作步骤”查看部署性能了
(4)使用集群监控
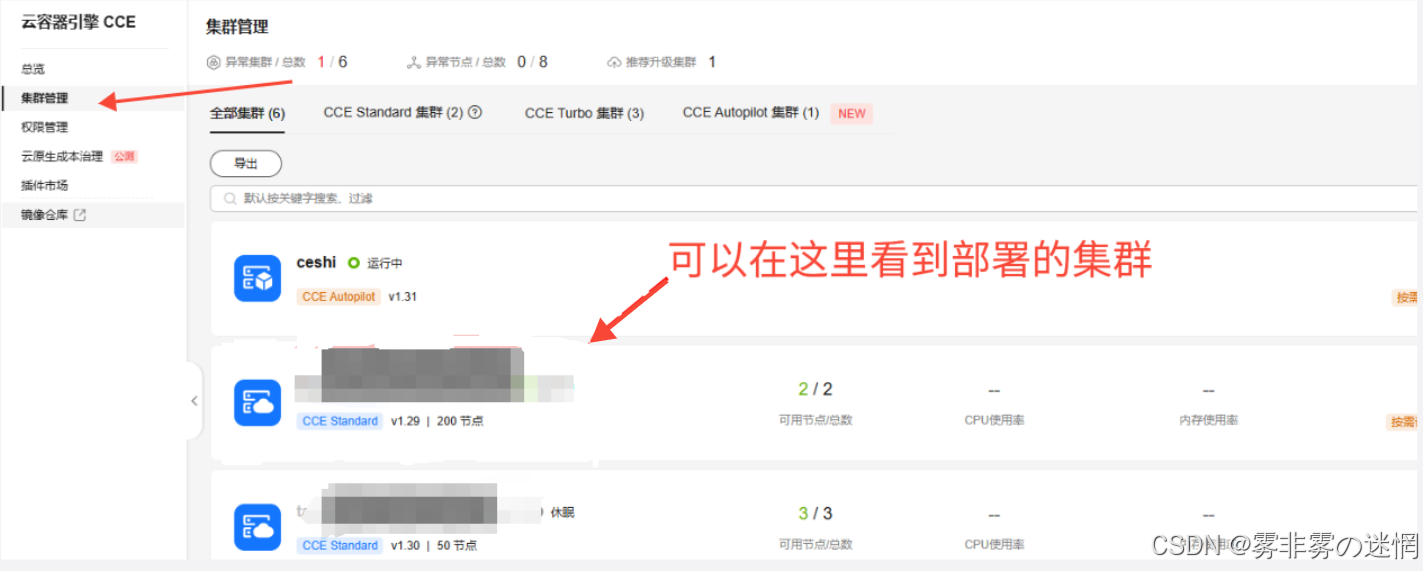
(1)进入云服务引擎CCE,找到集群管理。注意:这个方法适用于CCE部署的

(2)点击集群管理,可以看见已经部署的集群,这样可以查看单个集群的性能
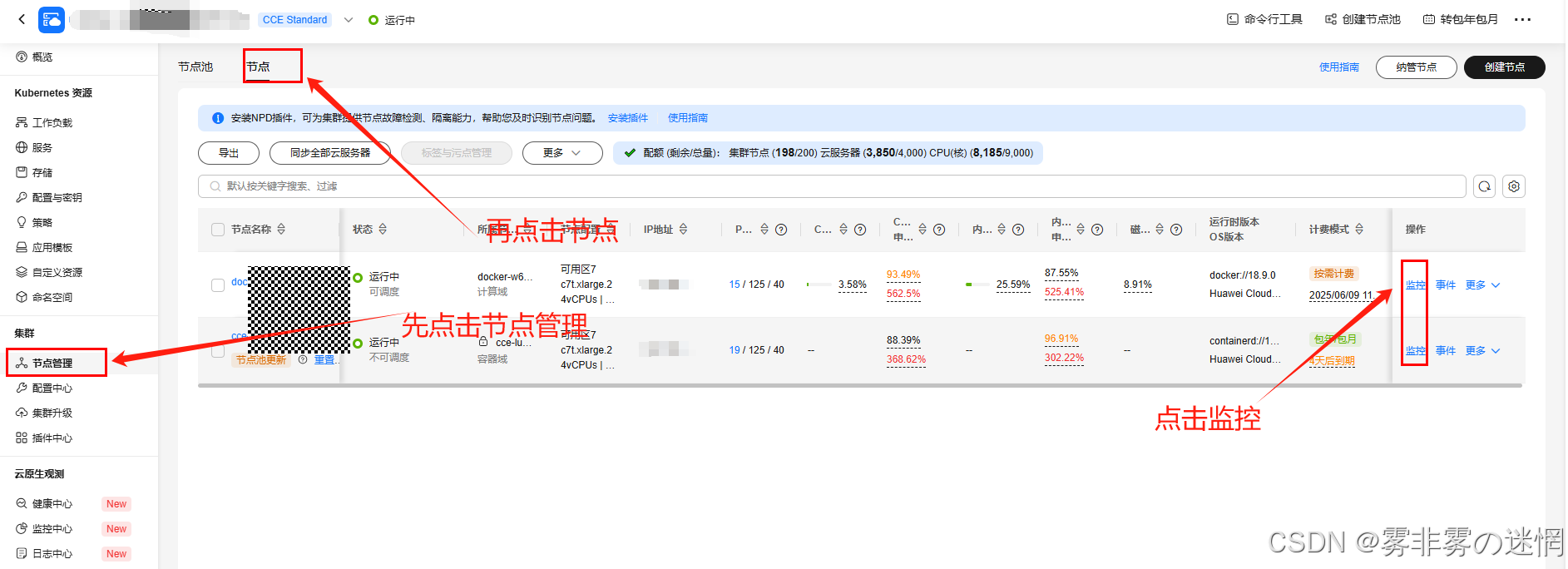
(3)左边工作栏找到“节点管理”,再点击“节点”->“监控”,查看更多监控,就OK了!
(5)监控数据如何分析
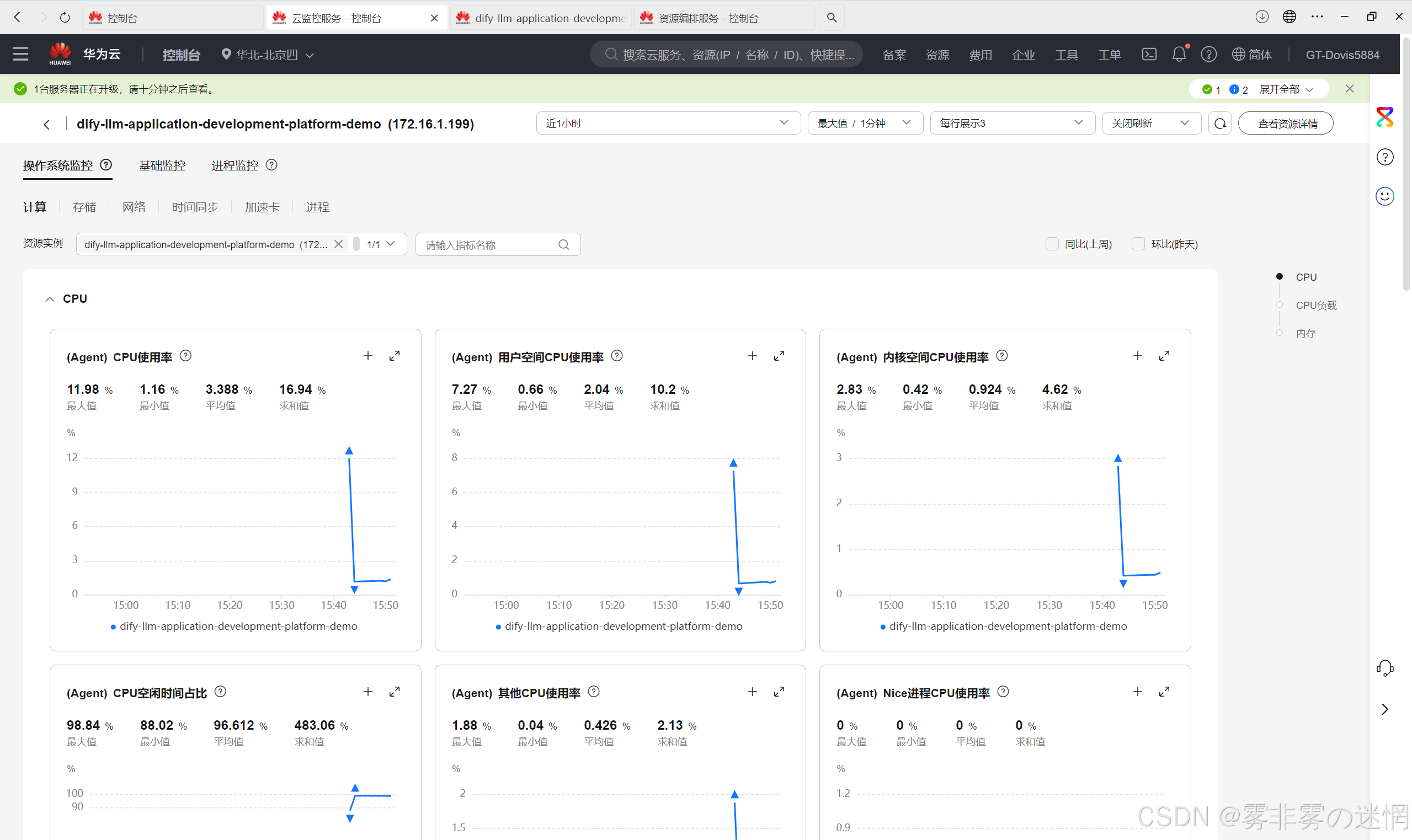
分析步骤:
数据收集:
通过Cloud Eye自动采集CCE集群的指标,或通过Prometheus抓取自定义指标
配置采集频率(如每5秒、1分钟)以平衡数据精度和性能开销
数据可视化:
使用Cloud Eye仪表盘或Grafana绘制时间序列图、饼图、热力图等,直观展示指标趋势
按时间、地域、节点或Pod进行分维度分析,定位问题根源
异常检测:
设置阈值告警(如CPU使用率>85%持续5分钟),快速发现异常
使用统计分析工具(如Cloud Eye的异常检测功能)识别潜在性能瓶颈
关联分析:
结合日志服务(如AOM)分析异常事件的上下文,如Pod重启与节点资源不足的关联性
检查网络指标与应用程序性能的关系,定位网络瓶颈
趋势预测:
利用Cloud Eye的预测功能,基于历史数据预测资源使用趋势,提前规划扩容或优化
分析工具
Cloud Eye:提供基础的指标分析和告警功能,适合快速部署和简单场景
·
Prometheus+Grafana:通过CCE插件市场安装,支持复杂查询(PromQL)和自定义仪表盘,适合高级用户
·
AOM(应用运维管理):结合日志、指标和事件分析,提供全链路监控能力
·
第三方工具:可集成ELK Stack、Zabbix等,满足企业级运维需求
(6)优化建议
高可用性增强
多可用区部署:确保CCE集群跨多个可用区部署,结合ELB实现流量自动切换
故障自动恢复:配置Kubernetes的健康检查(Liveness/Readiness Probe),确保故障Pod快速重启或替换
备份与容灾:定期备份关键数据到OBS,配置跨区域容灾机制,应对大规模故障
监控与告警优化
细化告警规则:根据业务优先级设置分级告警(如关键服务CPU>90%为紧急告警,非关键服务>80%为警告)
自定义监控:通过Prometheus exporter收集应用程序自定义指标(如业务API的错误率),提高监控针对性
自动化响应:结合华为云AOM或FunctionGraph,配置自动化脚本处理常见异常(如自动重启故障Pod)
成本优化
按需计费:监控资源使用率,释放闲置节点或Pod,采用按需计费模式降低成本
资源预测:利用Cloud Eye的趋势预测功能,提前规划资源扩展,避免临时扩容导致的高成本
安全优化
网络隔离:通过VPC和子网隔离CCE集群,降低网络攻击风险
权限管理:使用RBAC(基于角色的访问控制)限制对CCE资源的访问,防止误操作影响可用性
【五】常见问题与故障排查
(1)常见的CCE高可用性问题
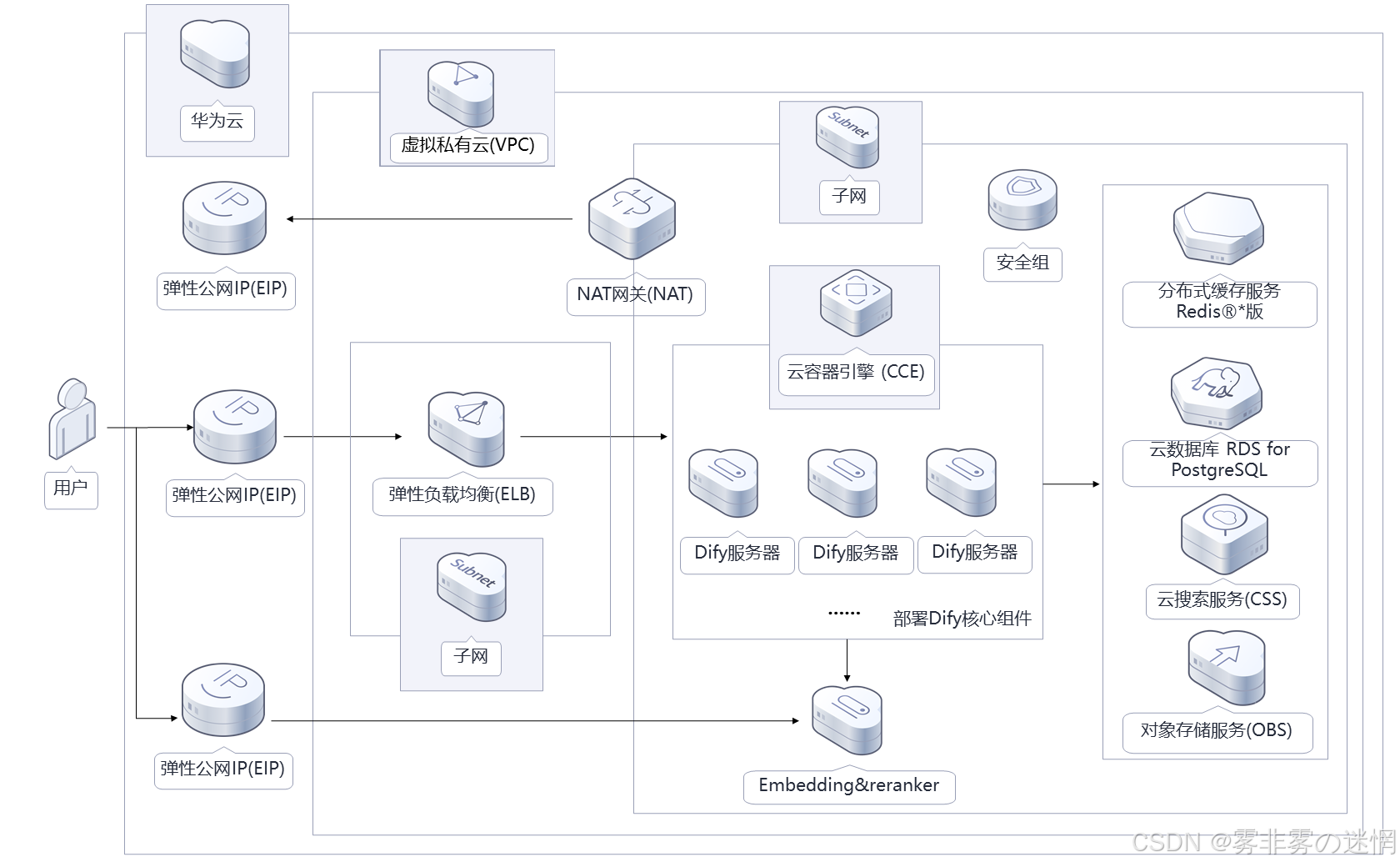
网络问题:网络延迟、丢包或连接中断可能导致容器间通信失败或外部访问受阻。架构显示,流量通过负载均衡器(ELB)和NAT网关进入CCE集群,若网络配置不当(如子网隔离不正确或带宽不足),可能引发问题
容器服务化过载:当CCE集群中的节点或Pod处理请求量超过其容量时,可能导致服务响应缓慢或不可用。Dify服务涉及大规模机器学习任务(如Embedding & Re-ranker),对资源需求较高,易引发过载
资源分配不均:架构显示CCE集群可能跨多可用区(AZ)部署,若资源分配不均(如某些节点负载过高而其他节点空闲),可能导致局部瓶颈,影响高可用性
(2)性能瓶颈排查
CPU和内存使用率:
使用Cloud Eye查看集群、节点和Pod的CPU/内存使用率,定位高负载的组件
检查Pod的资源限制(Request/Limit)是否过低,导致资源不足
分析应用程序日志(如Dify服务日志),确认是否存在代码或算法导致的资源消耗过高
网络带宽限制:
使用Cloud Eye监控ELB的网络流量、4xx/5xx错误率和响应时间
检查VPC内子网的带宽分配和NAT网关的流量限制
分析Pod间的网络通信延迟,确认是否存在跨可用区通信瓶颈
数据库性能:
使用Cloud Eye监控Redis的QPS、响应时间和连接数
检查数据库的慢查询日志,定位低效查询语句
分析Redis的内存使用情况,确认是否存在内存不足或数据淘汰问题
磁盘IO性能:
监控节点的磁盘IO指标(如IOPS、吞吐量、读写延迟)
检查是否使用了低性能的存储类型(如普通磁盘而非SSD)
分析应用程序的IO模式,确认是否存在频繁的小文件读写

828 B2B企业节已经开幕,汇聚千余款华为云旗下热门数智产品,更带来满额赠、专属礼包、储值返券等重磅权益玩法,是中小企业和开发者上云的好时机,建议密切关注官方渠道,及时获取最新活动信息,采购最实惠的云产品和最新的大模型服务!


