基于Fluentd和Elasticsearch的容器化应用日志聚合与实时分析优化策略_fluentd elasticsearch配置
💓 博客主页:借口的CSDN主页
⏩ 文章专栏:《热点资讯》
基于 Fluentd 和 Elasticsearch 的容器化应用日志聚合与实时分析优化策略
目录
- 基于 Fluentd 和 Elasticsearch 的容器化应用日志聚合与实时分析优化策略
-
- 1. 引言
- 2. 技术架构设计
-
- 2.1 核心组件
- 2.2 架构图示
- 3. 日志收集优化
-
- 3.1 Fluentd 配置示例
-
- 优化点:
- 3.2 容器日志采集策略
- 4. Elasticsearch 存储与索引优化
-
- 4.1 分片与副本配置
-
- 优化建议:
- 4.2 数据生命周期管理
- 5. 实时分析与聚合优化
-
- 5.1 聚合性能提升策略
-
- 5.1.1 使用 `execution_hint: map`
- 5.1.2 广度优先聚合
- 优化效果对比
- 5.2 查询性能优化
- 6. 安全与高可用性
-
- 6.1 权限控制
- 6.2 高可用性设计
- 7. 未来趋势与展望
-
- 7.1 云原生日志管理
- 7.2 AI 驱动的日志分析
- 8. 结论
1. 引言
在容器化环境中,日志聚合和实时分析是保障系统稳定性与可观测性的关键。随着微服务架构的普及,日志数据量呈指数级增长,传统的日志管理方案难以满足高并发、低延迟的需求。本文将探讨如何通过 Fluentd 和 Elasticsearch 构建高效的日志聚合与分析体系,并结合性能优化策略,实现大规模日志数据的实时处理与分析。
2. 技术架构设计
2.1 核心组件
- Fluentd:轻量级日志收集器,支持多语言插件,适合 Kubernetes 等容器化环境。
- Elasticsearch:分布式搜索引擎,提供高效的全文检索和聚合分析能力。
- Kafka(可选):作为日志缓冲中间件,解耦日志采集与存储。
2.2 架构图示
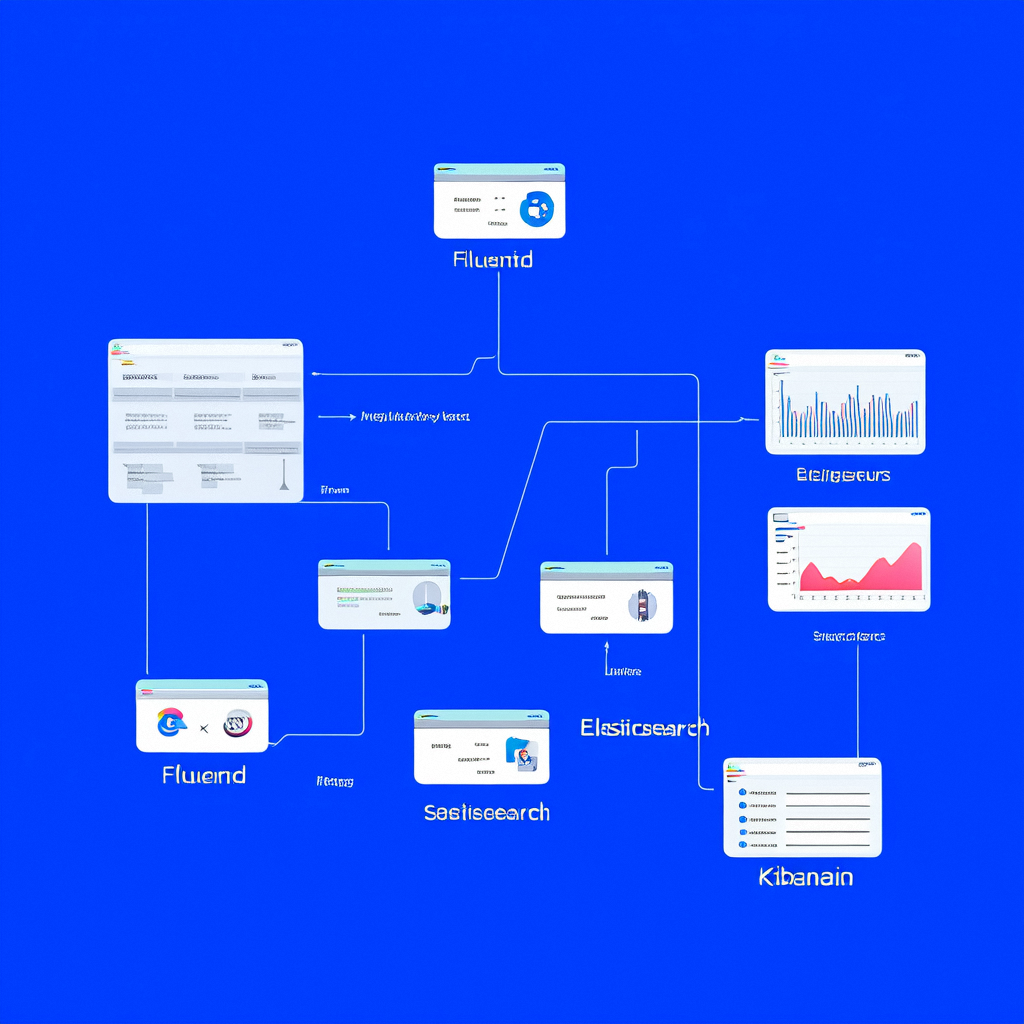
3. 日志收集优化
3.1 Fluentd 配置示例
Fluentd 的灵活性使其成为容器日志收集的首选工具。以下是一个典型的 Kubernetes 环境配置:
@type elasticsearch host elasticsearch port 9200 logstash_format true flush_interval 10s @type memory chunk_limit_size 256m queue_limit_length 32 优化点:
- 内存缓冲:通过
配置减少磁盘 I/O 开销。 - 批量写入:设置
chunk_limit_size和flush_interval平衡吞吐量与延迟。
3.2 容器日志采集策略
- DaemonSet 模式:在 Kubernetes 中部署 Fluentd 为 DaemonSet,确保每个节点运行一个实例,避免单点故障。
- 日志结构化:通过
format插件将日志解析为 JSON 格式,便于后续分析。
4. Elasticsearch 存储与索引优化
4.1 分片与副本配置
Elasticsearch 的分片策略直接影响性能与可靠性:
{ \"settings\": { \"number_of_shards\": 3, \"number_of_replicas\": 1 }, \"mappings\": { \"dynamic\": \"strict\", \"properties\": { \"@timestamp\": { \"type\": \"date\" }, \"message\": { \"type\": \"text\" } } }}优化建议:
- 分片数:根据数据量和节点数合理分配分片,避免过多或过少。
- 动态映射限制:通过
dynamic: strict禁止未定义字段的自动创建,防止字段爆炸。
4.2 数据生命周期管理
- 冷热分层:将近期高频访问的日志存储在热节点,历史数据迁移到冷节点。
- 索引模板:为不同业务模块定义独立的索引模板,优化查询性能。
5. 实时分析与聚合优化
5.1 聚合性能提升策略
Elasticsearch 的聚合操作在海量数据场景下可能成为瓶颈。以下优化方案可显著提升性能:
5.1.1 使用 `execution_hint: map`
{ \"aggs\": { \"count_over_sin\": { \"terms\": { \"field\": \"sin_id\", \"execution_hint\": \"map\", \"size\": 1000 } } }}5.1.2 广度优先聚合
{ \"aggs\": { \"count_over_sin\": { \"terms\": { \"collect_mode\": \"breadth_first\" } } }}优化效果对比
5.2 查询性能优化
- 过滤器缓存:优先使用
filter替代query,利用布尔查询的缓存机制。 - 字段选择:避免返回不必要的字段,减少序列化开销。
{ \"query\": { \"bool\": { \"filter\": [ { \"range\": { \"@timestamp\": { \"gte\": \"now-1d\" } } }, { \"term\": { \"level\": \"ERROR\" } } ] } }, \"_source\": { \"includes\": [\"@timestamp\", \"message\"] }}6. 安全与高可用性
6.1 权限控制
- Kubernetes 节点调度:允许 Fluentd 在 Master 节点运行,确保系统日志收集完整性。
- 容器能力提升:授予
SYS_ADMIN权限,使 Fluentd 能访问宿主机文件系统。
securityContext: capabilities: add: - SYS_ADMIN6.2 高可用性设计
- Elasticsearch 集群冗余:通过副本分片和跨节点部署提高容错能力。
- 日志备份:定期将冷数据备份到对象存储(如 S3、OSS),避免数据丢失。
7. 未来趋势与展望
7.1 云原生日志管理
- Loki 与 Fluentd 对比:Loki 更适合云原生环境,但 Fluentd 的灵活性使其在复杂场景中更具优势。
- 服务网格集成:通过 Istio 或 Linkerd 收集服务网格日志,实现更细粒度的监控。
7.2 AI 驱动的日志分析
- 异常检测:利用机器学习模型自动识别日志中的异常模式。
- 根因分析:结合 APM 工具(如 Jaeger)进行日志与链路追踪的关联分析。

8. 结论
通过合理配置 Fluentd 与 Elasticsearch,结合分片优化、聚合加速和数据分层策略,可以构建高效、稳定的容器化日志聚合与分析系统。未来,随着云原生和 AI 技术的发展,日志管理将进一步向智能化、自动化方向演进。

