卡夫卡(Kafka)从入门到实践:超详细学习指南_kafka实践
在当今数据爆炸的时代,高效的消息传递和数据流转成为企业级系统的核心需求。卡夫卡(Kafka)作为一款高吞吐量、高可用的分布式消息系统,已成为大数据生态的关键组件,被广泛应用于日志收集、实时数据管道、事件驱动架构等场景。本文将从基础概念到实战操作,带你全面掌握 Kafka 的核心知识与应用技巧。
一、卡夫卡核心概念:从 “是什么” 开始
1.1 什么是 Kafka?
卡夫卡是由 Apache 软件基金会开发的分布式流处理平台,最初由 LinkedIn 公司设计,用于解决大规模日志收集与传输问题。它的核心定位是 “高吞吐量的分布式发布 - 订阅消息系统”,具有高吞吐、低延迟、持久化、可扩展、容错性强等特点。
简单来说,Kafka 就像一个 “分布式数据管道”,能在不同系统间高效传递海量数据。例如:电商平台的订单数据可通过 Kafka 实时同步到库存系统、支付系统和数据分析平台;日志系统可将应用日志集中收集到 Kafka,再分发给 ELK 栈进行分析。
1.2 核心架构组件
Kafka 的架构设计是其高性能的关键,理解以下核心组件是入门的基础:
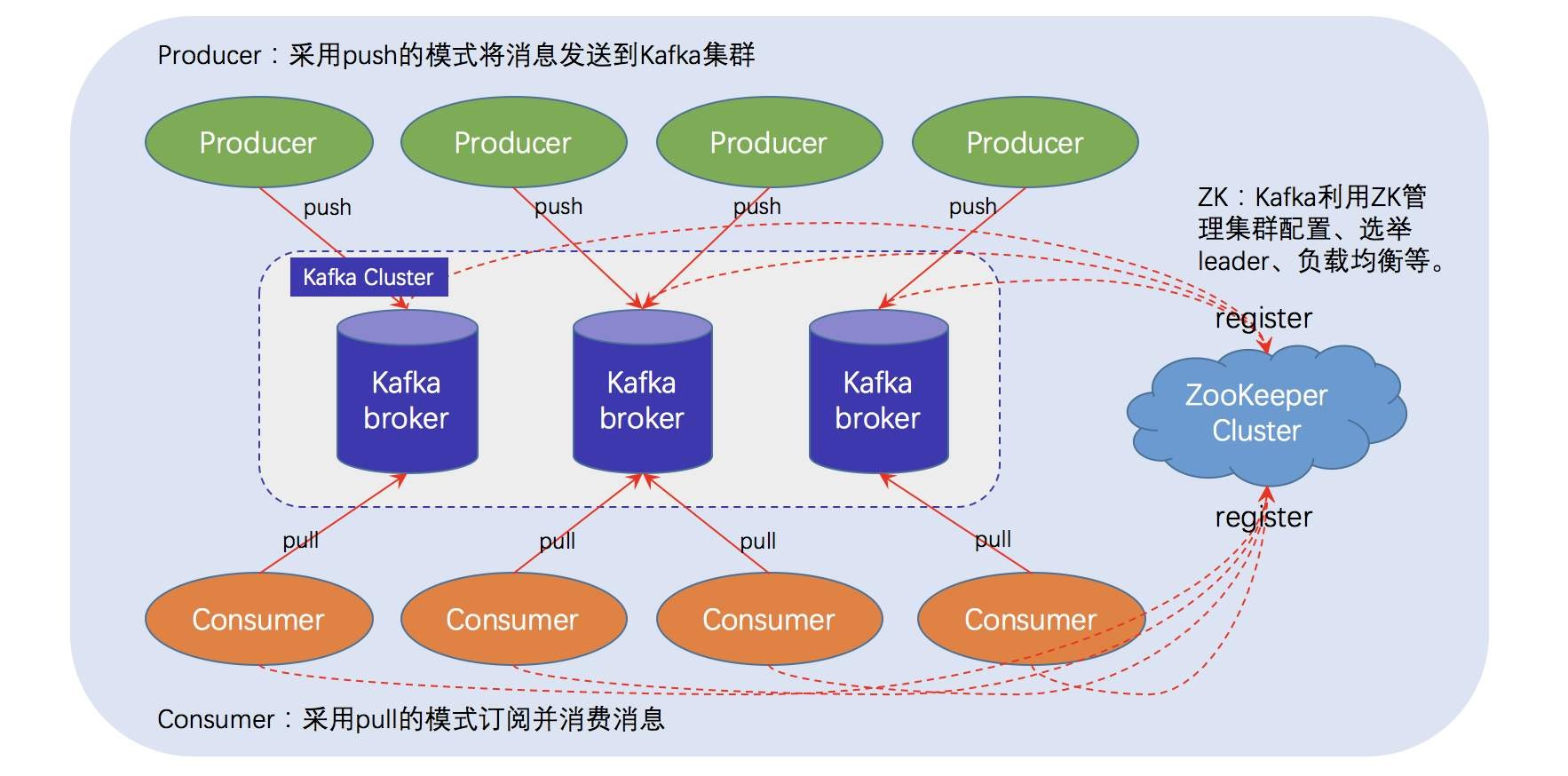
- 生产者(Producer):数据的发送方,负责将消息写入 Kafka 集群。生产者可指定消息发送到哪个主题(Topic),并支持通过分区策略决定消息存储的具体分区。
- 消费者(Consumer):数据的接收方,从 Kafka 集群读取消息。消费者通过 “消费者组(Consumer Group)” 机制实现负载均衡和消息共享。
- Broker:Kafka 集群中的服务器节点,负责存储消息、处理生产者和消费者的请求。一个 Kafka 集群由多个 Broker 组成,Broker 数量越多,集群的吞吐量和容错能力越强。
- 主题(Topic):消息的分类容器,类似数据库中的 “表” 或文件系统中的 “文件夹”。所有消息必须属于某个主题,生产者向主题写入消息,消费者从主题读取消息。
- 分区(Partition):主题的最小存储单元,每个主题可划分为多个分区,分区内的消息按写入顺序存储(类似日志文件)。分区是 Kafka 并行处理的核心,通过多分区实现读写操作的并行化。
- 副本(Replica):为保证数据可靠性,每个分区可配置多个副本。副本分为 Leader 和 Follower,生产者和消费者仅与 Leader 交互,Follower 负责同步 Leader 数据,Leader 故障时自动选举新 Leader。
- 偏移量(Offset):分区内每条消息的唯一序号(从 0 开始递增),消费者通过记录偏移量确定已消费的位置,支持消息的重复消费和断点续传。
二、卡夫卡工作原理:为何能实现高吞吐?
2.1 分区与并行机制
分区是 Kafka 实现高吞吐的核心设计:
- 分区的作用:每个分区独立存储消息,可分布在不同 Broker 上,实现读写操作的并行化。例如:一个包含 8 个分区的主题,可同时支持 8 个消费者并行读取。
- 消息存储:分区内的消息按写入顺序存储为 “日志段(Log Segment)” 文件,每个文件大小固定(默认 1GB),满后自动创建新文件。这种结构让消息写入操作简化为 “追加写入”,避免随机 IO,提升性能。
2.2 副本机制与高可用
Kafka 通过副本机制确保数据不丢失:
- 副本配置:每个分区可设置 N 个副本(通常 3 个),其中 1 个为 Leader 副本,其余为 Follower 副本。Leader 负责处理读写请求,Follower 实时同步 Leader 数据。
- 故障转移:当 Leader 所在 Broker 故障时,Kafka 会从 Follower 中选举新 Leader(通过 ISR 机制确保数据一致性),整个过程自动完成,对生产者和消费者透明。
2.3 消费者组与负载均衡
消费者组是 Kafka 消费消息的核心机制:
- 消费者组定义:多个消费者组成一个消费者组,共同消费一个主题的消息。组内每个消费者负责消费部分分区,同一分区的消息只会被组内一个消费者消费(避免重复消费)。
- 重平衡(Rebalance):当消费者组内消费者数量变化(如新增 / 下线)或分区数量变化时,Kafka 会重新分配分区与消费者的对应关系,确保负载均衡。
三、安装与部署:从 0 搭建 Kafka 环境
3.1 环境准备
- 依赖:Kafka 基于 Java 开发,需安装 JDK 1.8+(推荐 JDK 11),并配置 JAVA_HOME 环境变量。
- 操作系统:支持 Linux、Windows、macOS,生产环境推荐 Linux(如 CentOS 7/8、Ubuntu 20.04)。
- 网络:Broker 之间、生产者 / 消费者与 Broker 之间需开放默认端口(9092 用于客户端通信,2181 用于 Zookeeper,若使用 KRaft 模式则无需 Zookeeper)。
3.2 单机部署(快速入门)
步骤 1:下载安装包
从 Apache Kafka 官网 下载稳定版本(如 3.6.1),通过 wget 命令下载:
wget https://mirrors.aliyun.com/apache/kafka/3.7.2/kafka_2.12-3.7.2.tgz解压到指定目录:
tar -zxvf kafka_2.12-3.7.2.tgz -C /opt/cd /opt/kafka_2.12-3.7.2/步骤 2:配置修改
Kafka 支持两种运行模式:传统 Zookeeper 模式和 KRaft 模式(无 Zookeeper)。新手推荐先使用 Zookeeper 模式:
- Zookeeper 配置:无需修改默认配置,默认端口 2181,数据存储在 tmp/zookeeper。
- Kafka 配置:编辑 config/server.properties,关键配置如下:
# Broker 唯一标识(集群模式需不同)broker.id=0# 监听地址(默认 localhost,远程访问需改为服务器 IP)listeners=PLAINTEXT://localhost:9092# 日志存储路径log.dirs=/tmp/kafka-logs# Zookeeper 连接地址zookeeper.connect=localhost:2181步骤 3:启动服务
先启动 Zookeeper(内置简易版,生产环境需独立部署 Zookeeper 集群):
# 后台启动 Zookeeperbin/zookeeper-server-start.sh -daemon config/zookeeper.properties再启动 Kafka Broker:
# 后台启动 Kafkabin/kafka-server-start.sh -daemon config/server.properties步骤 4:验证部署
检查进程是否启动:
jps | grep -E \"Kafka|QuorumPeerMain\"
若输出 QuorumPeerMain(Zookeeper)和 Kafka 进程,则部署成功。
3.3 集群部署(生产环境)
集群部署需多台服务器,核心步骤如下:
- 在 3 台服务器上分别安装 Kafka,修改 server.properties:
- broker.id 分别设为 0、1、2
- listeners 设为服务器实际 IP(如 PLAINTEXT://192.168.1.101:9092)
- zookeeper.connect 设为所有 Zookeeper 节点地址(如 192.168.1.101:2181,192.168.1.102:2181,192.168.1.103:2181)
- 依次启动所有 Zookeeper 和 Kafka 节点。
四、核心操作:用命令行玩转 Kafka
4.1 主题管理
创建主题
创建一个名为 test-topic 的主题,指定 3 个分区、2 个副本:
bin/kafka-topics.sh --bootstrap-server localhost:9092 \\--create --topic test-topic \\--partitions 3 --replication-factor 2- --partitions:分区数量,建议根据业务吞吐量设置(如每分区承载 1000-5000 TPS)。
- --replication-factor:副本数量,建议设为 2-3(需 ≤ Broker 数量)。
查看主题列表
bin/kafka-topics.sh --bootstrap-server localhost:9092 --list查看主题详情
bin/kafka-topics.sh --bootstrap-server localhost:9092 \\--describe --topic test-topic输出将显示分区分布、副本状态、Leader 节点等信息。
4.2 消息生产与消费
发送消息(生产者)
通过命令行启动生产者,向 test-topic 发送消息:
bin/kafka-console-producer.sh --bootstrap-server localhost:9092 \\--topic test-topic输入消息并回车发送,例如:
Hello Kafka!This is my first message.消费消息(消费者)
启动消费者,从开头消费 test-topic 的消息:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \\--topic test-topic --from-beginning若消费者与生产者在同一台机器,可看到刚才发送的消息。
消费者组操作
指定消费者组消费消息:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \\--topic test-topic --group my-group查看消费者组详情:
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 \\--describe --group my-group4.3 可视化工具:Kafka Manager
命令行操作较繁琐,推荐使用 Kafka Manager(由 Yahoo 开发)进行可视化管理:
- 从 GitHub 下载安装,修改配置文件指定 Kafka 集群地址。
- 启动后通过浏览器访问(默认端口 9000),可直观查看主题、分区、消费者组状态,支持创建主题、调整分区等操作。
五、进阶实践:客户端开发与集成
5.1 Java 客户端开发(生产者)
依赖配置(Maven)
org.apache.kafka kafka-clients 3.6.1生产者示例代码
import org.apache.kafka.clients.producer.*;import java.util.Properties; // 2. 创建生产者实例 Producer producer = new KafkaProducer(props); // 3. 发送消息 for (int i = 0; i < 10; i++) { String message = \"Message \" + i; // 发送消息并添加回调 producer.send(new ProducerRecord(\"test-topic\", message), (metadata, exception) -> { if (exception == null) { System.out.println(\"发送成功:\" + metadata.topic() + \" - 分区:\" + metadata.partition() + \" - 偏移量:\" + metadata.offset()); } else { exception.printStackTrace(); } }); } // 4. 关闭生产者 producer.close(); }}5.2 Java 客户端开发(消费者)
import org.apache.kafka.clients.consumer.*;import java.time.Duration; props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, \"1000\"); // 消费起始位置:earliest(从头)、latest(最新) props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, \"earliest\"); // 2. 创建消费者实例 KafkaConsumer consumer = new KafkaConsumer(props); // 3. 订阅主题 consumer.subscribe(Collections.singletonList(\"test-topic\")); // 4. 循环消费消息 while (true) { ConsumerRecords records = consumer.poll(Duration.ofMillis(100)); for (ConsumerRecord record : records) { System.out.println(\"接收消息:\" + record.value() + \" - 分区:\" + record.partition() + \" - 偏移量:\" + record.offset()); } } }}5.3 监控与告警
Kafka 集群需实时监控以确保稳定运行,推荐方案:
- 监控指标:通过 Kafka 内置的 JMX 暴露指标(如消息吞吐量、分区滞后量、副本同步状态)。
- 工具链:使用 Prometheus 采集指标,Grafana 可视化监控面板,Alertmanager 配置告警规则(如分区不可用、消费滞后量超过阈值)。
- 部署步骤:
- 在 server.properties 中开启 JMX:export JMX_PORT=9999
- 部署 Prometheus 并配置 Kafka 指标采集
- 导入 Kafka 监控模板(Grafana ID:7589)
六、调优与最佳实践
6.1 主题与分区规划
- 分区数量:根据业务吞吐量和消费者数量规划,建议每个 Broker 承载 100-200 个分区。分区过多会增加集群负担,过少则无法充分利用并行性。
- 分区键(Key):生产者发送消息时指定 Key,Kafka 会根据 Key 的哈希值分配分区,确保相同 Key 的消息进入同一分区(保证顺序性)。
6.2 生产者调优
- 批量发送:设置 batch.size(默认 16KB)和 linger.ms(默认 0ms),累积到一定大小或时间后批量发送,减少网络请求。
- 压缩消息:开启 compression.type=gzip 或 snappy,降低网络传输和存储开销(适合文本类消息)。
- 重试机制:设置 retries 和 retry.backoff.ms,应对临时网络故障。
6.3 消费者调优
- 手动提交偏移量:关闭 enable.auto.commit,在消息处理完成后手动调用 commitSync() 或 commitAsync(),避免消息丢失。
- 消费线程数:消费者数量建议 ≤ 分区数量,多余的消费者会空闲。可通过多线程处理消息,但需注意线程安全。
- ** fetch 参数 **:调整 fetch.min.bytes(最小拉取字节数)和 fetch.max.wait.ms(最长等待时间),平衡延迟和吞吐量。
6.4 存储与安全
- 日志清理策略:通过 log.retention.hours(默认 168h)设置消息保留时间,或 log.retention.bytes 设置存储上限,避免磁盘占满。
- 安全配置:生产环境需开启 SSL 加密传输、SASL 认证(如 Kerberos 或 PLAIN 机制),限制生产者 / 消费者的操作权限。
七、常见问题排查
7.1 启动失败
- Zookeeper 连接超时:检查 Zookeeper 是否启动,zookeeper.connect 配置是否正确,防火墙是否开放 2181 端口。
- 端口占用:使用 netstat -tulpn | grep 9092 查看端口是否被占用,修改 listeners 配置更换端口。
7.2 消息丢失
- 检查生产者 acks 配置是否为 all(关键业务建议设置),消费者是否在消息处理前提交了偏移量。
- 查看 Broker 日志(logs/server.log),是否存在副本同步失败或磁盘错误。
7.3 消费延迟
- 通过 kafka-consumer-groups.sh 查看消费滞后量(LAG),若滞后过大,增加消费者数量或优化消费逻辑。
- 检查消费者处理消息的耗时,避免在消费线程中执行 heavy 操作。
八、总结
Kafka 凭借高吞吐、高可用的特性,已成为分布式系统中不可或缺的数据流转中枢。本文从基础概念、架构原理到实战操作,覆盖了 Kafka 入门到实践的核心知识,包括安装部署、命令行操作、客户端开发、调优最佳实践等。
学习 Kafka 的关键在于理解 “分区并行” 和 “副本容错” 的设计思想,在实际应用中需结合业务场景规划主题、调优参数,并建立完善的监控告警体系。未来,Kafka 将继续向无 Zookeeper 架构(KRaft)演进,进一步提升性能和稳定性,同时与流处理框架(如 Kafka Streams、Flink)的集成会更加紧密。
希望本文能帮助各位快速掌握 Kafka 的使用,在实际项目中充分发挥其威力!如需深入学习,建议阅读官方文档、参与社区讨论,并通过实际项目积累经验。

