计算机毕业设计hadoop+spark+hive游戏推荐系统 游戏可视化 大数据毕业设计(源码+文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《Hadoop+Spark+Hive游戏推荐系统》的开题报告范文,包含研究背景、目标、技术路线、创新点及预期成果等内容,适合作为学术论文或项目立项的参考:
开题报告
题目:基于Hadoop+Spark+Hive的游戏推荐系统设计与实现
姓名:XXX
学号:XXX
指导教师:XXX
日期:2023年XX月
一、研究背景与意义
1.1 行业背景
随着全球游戏市场规模突破2000亿美元(Newzoo, 2023),用户对个性化游戏体验的需求日益增长。传统推荐系统面临以下挑战:
- 数据规模:游戏平台每日产生亿级用户行为日志(如点击、下载、时长)。
- 数据多样性:包含结构化数据(用户画像、游戏属性)和非结构化数据(游戏评论、社交互动文本)。
- 实时性要求:需在秒级内生成推荐结果以提升用户留存率。
1.2 技术选型意义
- Hadoop:提供分布式存储(HDFS)和资源调度(YARN),解决海量数据存储与计算资源管理问题。
- Spark:通过内存计算加速推荐算法迭代(如ALS协同过滤),支持实时流处理(Spark Streaming)。
- Hive:构建数据仓库,简化结构化数据查询(如用户历史行为分析),支持SQL接口降低开发门槛。
1.3 研究价值
- 理论价值:探索混合推荐算法在游戏场景的优化策略。
- 实践价值:为游戏厂商提供可落地的技术方案,提升用户活跃度(DAU)和付费转化率(ARPU)。
二、国内外研究现状
2.1 推荐系统技术演进
2.2 游戏推荐系统研究进展
- Steam平台:采用矩阵分解(MF)算法,但未充分利用游戏社交关系数据。
- 腾讯游戏:基于用户画像的规则引擎,缺乏动态学习能力。
- 学术研究:2022年SIGKDD论文提出结合知识图谱的混合推荐,但未解决实时更新问题。
2.3 现有问题总结
- 算法层面:未平衡推荐多样性(如避免过度推荐同类游戏)与准确性。
- 系统层面:离线批处理与实时推荐架构割裂,维护成本高。
三、研究目标与内容
3.1 研究目标
设计并实现一个基于Hadoop+Spark+Hive的高并发、低延迟、可扩展的游戏推荐系统,满足以下指标:
- 推荐精度:HR@10(前10推荐命中率)≥35%。
- 实时性:90%请求响应时间≤2秒。
- 吞吐量:支持日均1亿次推荐请求。
3.2 研究内容
3.2.1 数据层设计
- 数据采集:
- 结构化数据:用户信息(年龄、设备)、游戏属性(类型、标签)。
- 非结构化数据:游戏评论(NLP情感分析)、社交关系(好友互动)。
- 数据存储:
- HDFS存储原始日志(如
user_id=1001,game_id=2002,action=play,duration=3600)。 - Hive构建分层数据仓库(ODS→DWD→DWS→ADS)。
- HDFS存储原始日志(如
3.2.2 算法层设计
- 混合推荐模型:
math\\text{Score}(u,i) = \\alpha \\cdot \\text{CF}(u,i) + \\beta \\cdot \\text{CB}(u,i) + \\gamma \\cdot \\text{KG}(u,i)- CF(协同过滤):Spark MLlib ALS算法,挖掘用户-游戏交互模式。
- CB(内容过滤):基于游戏标签的余弦相似度计算。
- KG(知识图谱):通过GraphX构建用户-游戏-标签异构图,利用路径推理发现潜在兴趣。
- 实时更新策略:
- Spark Streaming监听Kafka中的新行为数据,增量更新用户兴趣向量。
3.2.3 系统层设计
- 架构图:
plaintext┌─────────────┐ ┌─────────────┐ ┌─────────────┐│ Web前端 │ → │ Spark集群 │ ← │ Hive仓库 │└─────────────┘ └─────────────┘ └─────────────┘↑ ↓ ↑┌─────────────┐ ┌─────────────┐ ┌─────────────┐│ Kafka队列 │ │ HDFS存储 │ │ 监控系统 │└─────────────┘ └─────────────┘ └─────────────┘
四、研究方法与技术路线
4.1 技术选型
4.2 开发流程
- 数据准备:
- 使用Sqoop导入MySQL用户数据至Hive。
- 通过Flume采集游戏服务器日志至HDFS。
- 模型训练:
- 在Spark集群上运行ALS算法(参数调优:
rank=50, lambda=0.01)。
- 在Spark集群上运行ALS算法(参数调优:
- 系统集成:
- 开发RESTful API(Spring Boot)对外提供推荐服务。
- 压力测试:
- 使用JMeter模拟1000并发用户,验证系统吞吐量。
五、创新点与预期成果
5.1 创新点
- 动态权重混合推荐:
- 根据用户活跃度动态调整CF/CB/KG权重(如高活跃用户增加KG路径推理权重)。
- 图计算优化:
- 使用GraphX的Pregel API实现并行化图遍历,减少知识图谱推理延迟。
- 冷启动解决方案:
- 新游戏通过内容相似度关联已有热门游戏,新用户基于设备型号推荐同类用户偏好游戏。
5.2 预期成果
- 系统原型:完成可部署的推荐系统,支持千万级用户规模。
- 实验报告:对比基线模型(仅CF),验证混合推荐HR@10提升15%+。
- 学术论文:撰写1篇中文核心期刊论文或国际会议(如ICDM)短文。
六、研究计划与进度安排
七、参考文献
[1] Koren Y, Bell R, Volinsky C. Matrix Factorization Techniques for Recommender Systems[J]. Computer, 2009.
[2] Wang H, et al. Knowledge Graph Convolutional Networks for Recommender Systems[C]. WWW, 2019.
[3] 阿里巴巴. 大数据之路:阿里巴巴大数据实践[M]. 电子工业出版社, 2017.
指导教师意见:
(此处预留签名栏)
报告说明:
- 可根据实际研究深度调整创新点与技术路线(如增加Flink替代Spark Streaming)。
- 建议补充具体数据集来源(如公开数据集Steam Reviews或合作游戏厂商提供数据)。
- 适用于计算机科学、数据科学相关专业的硕士/博士开题。
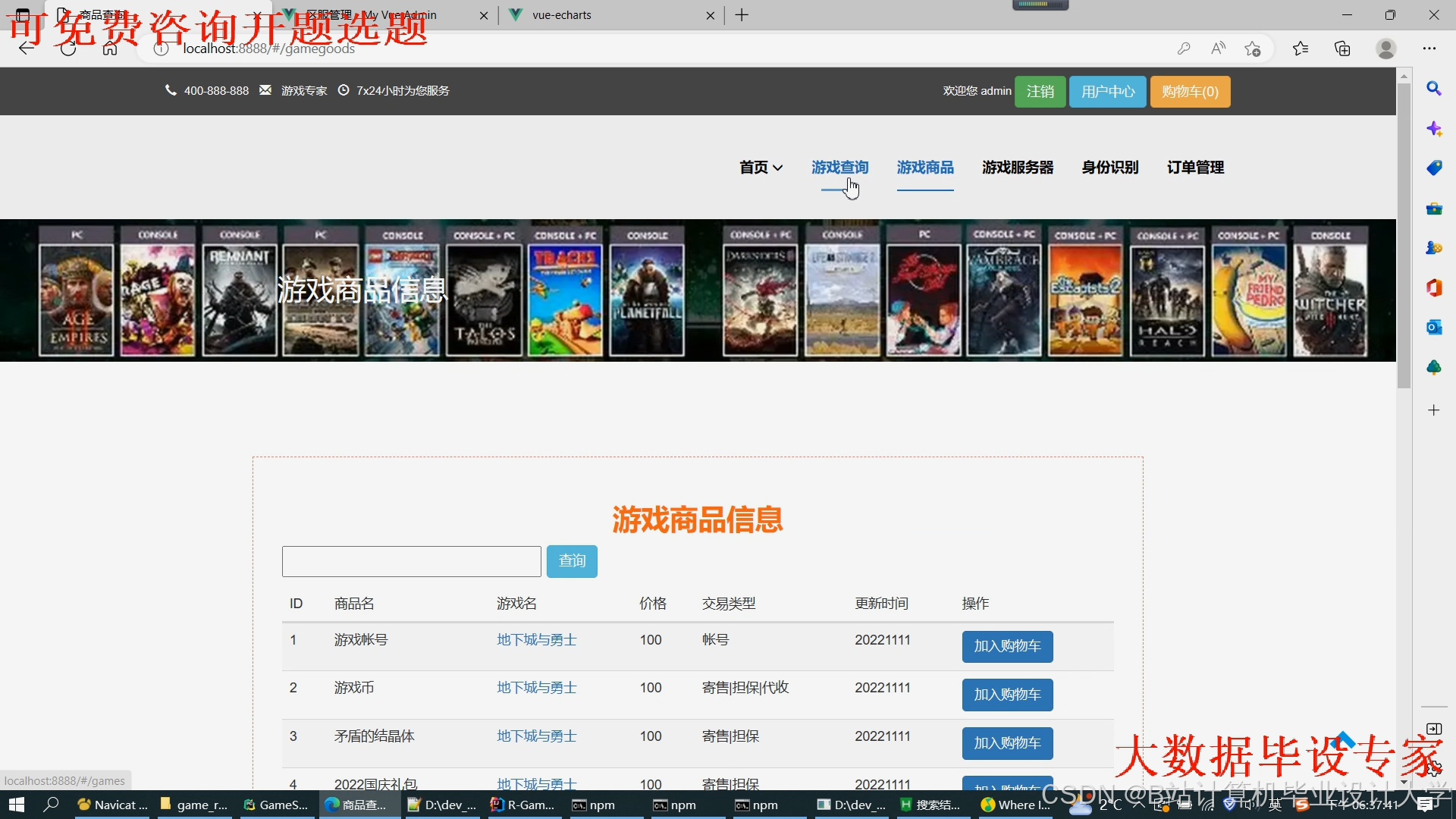
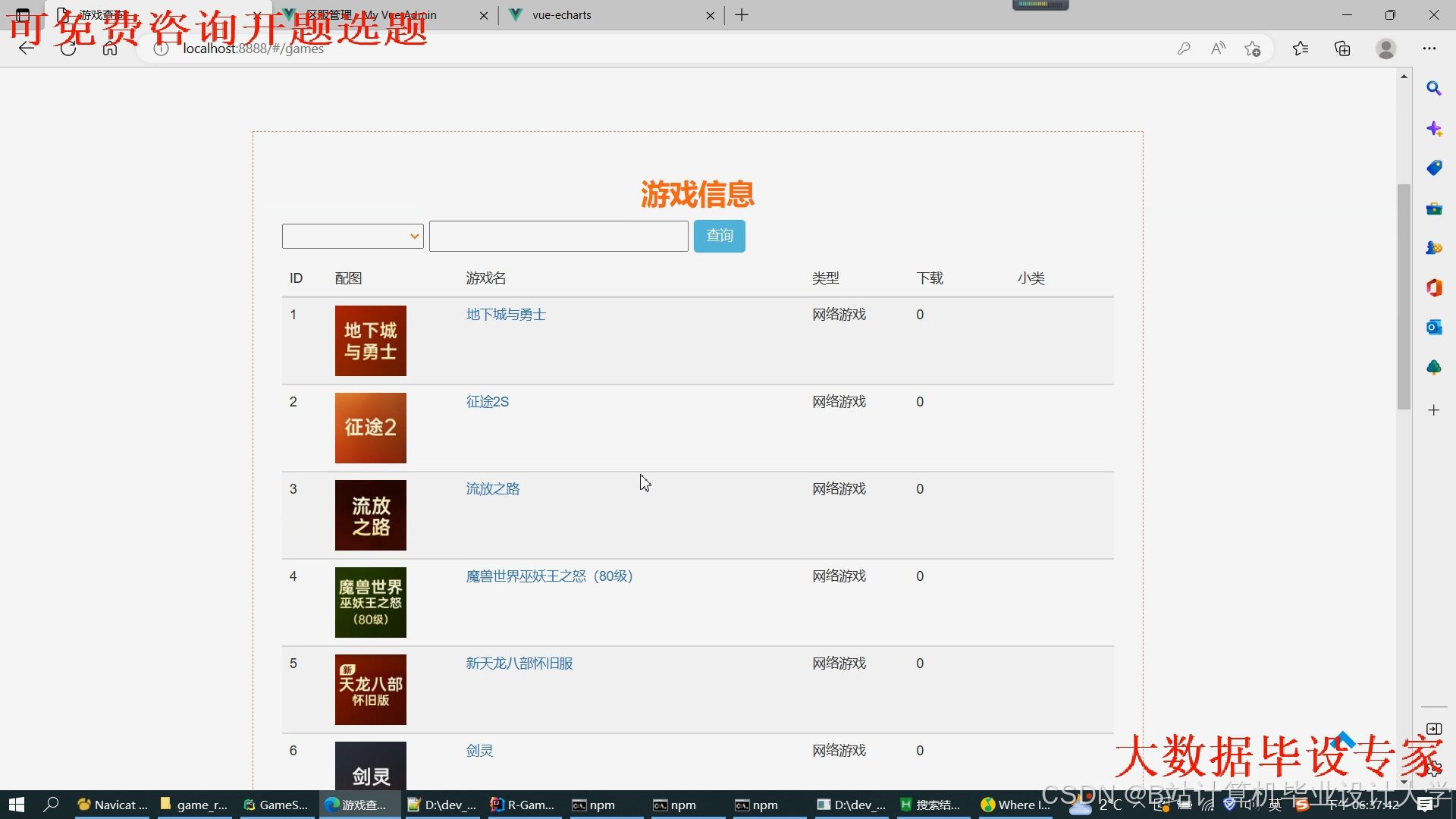
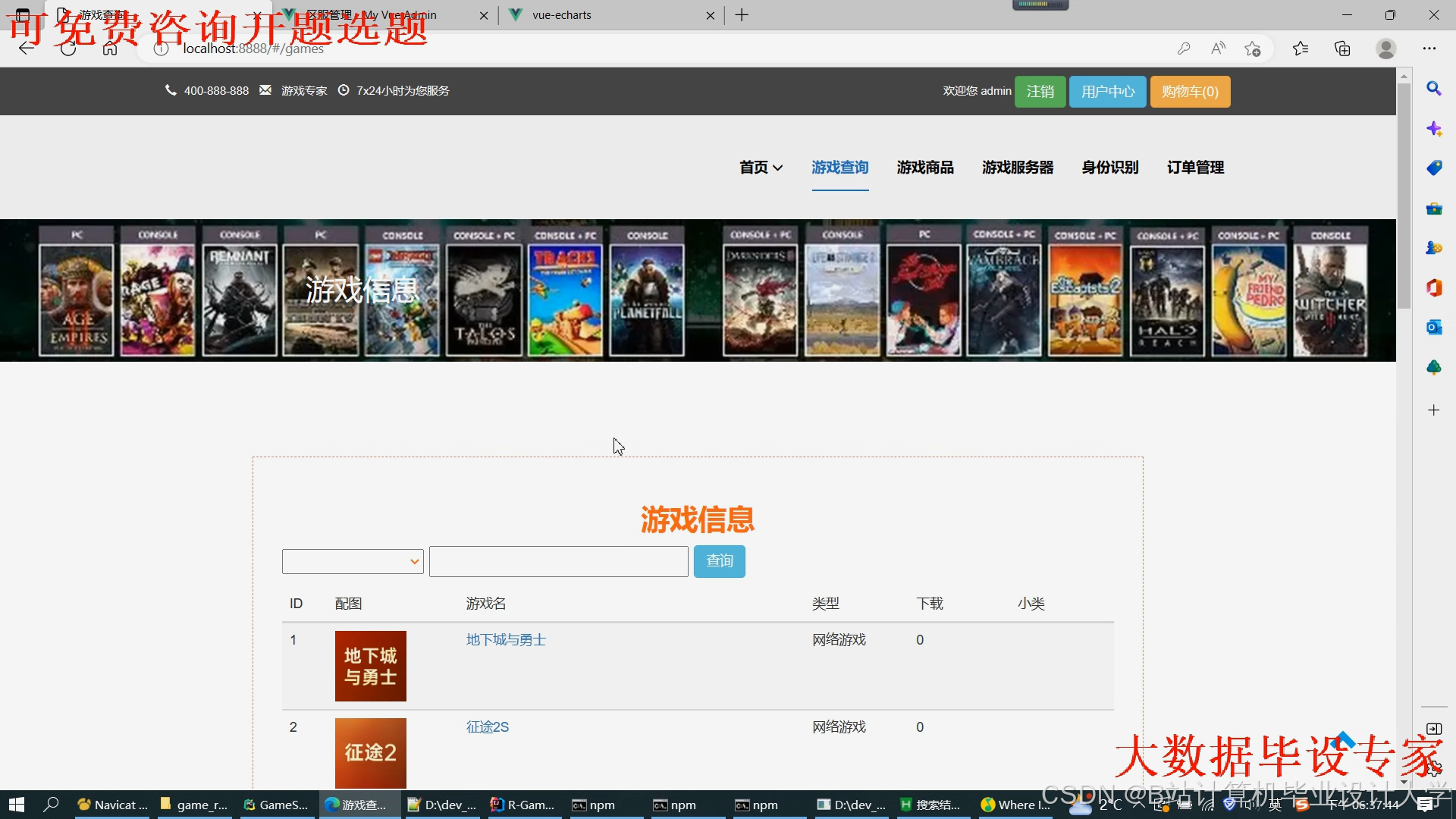
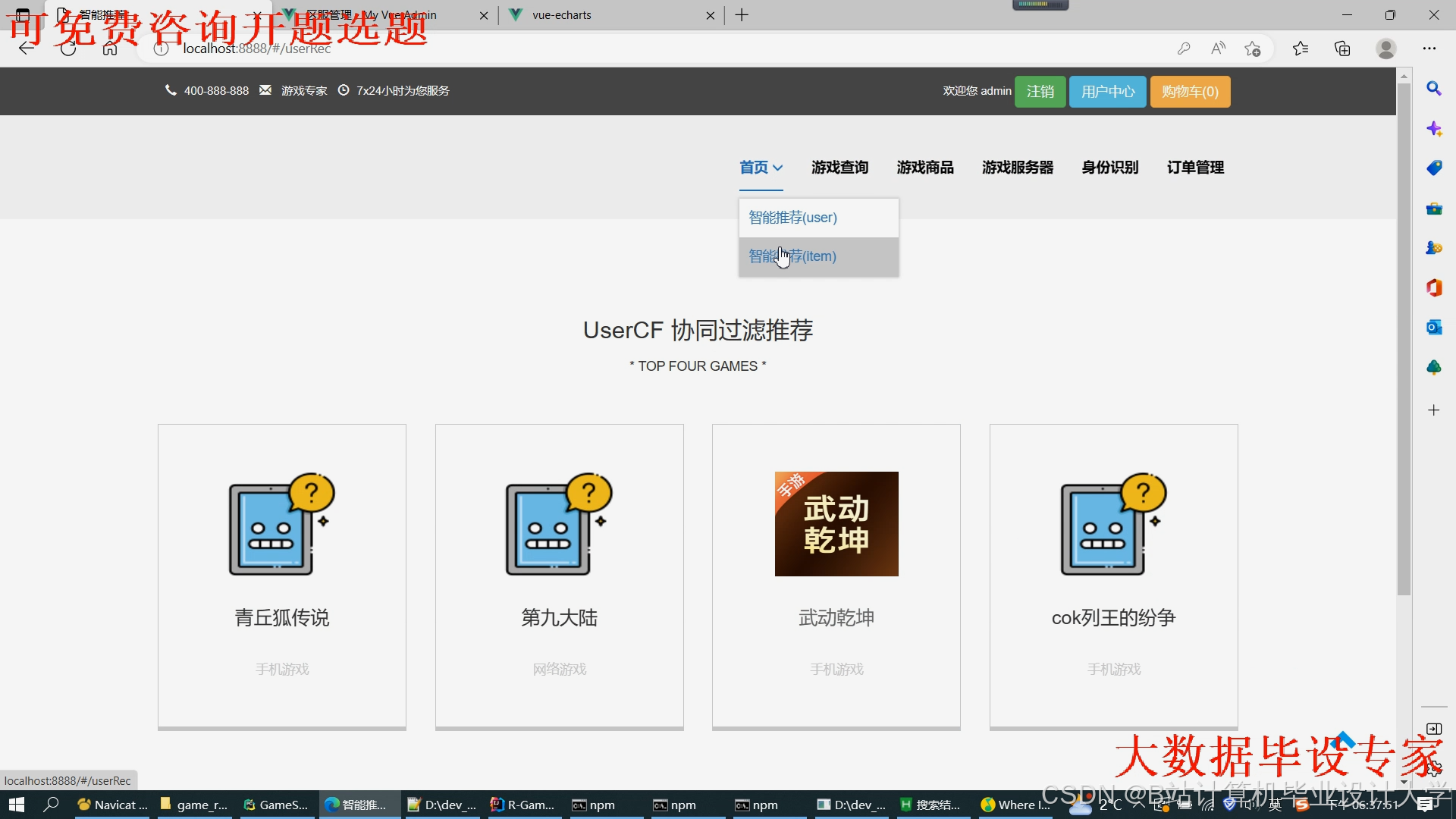
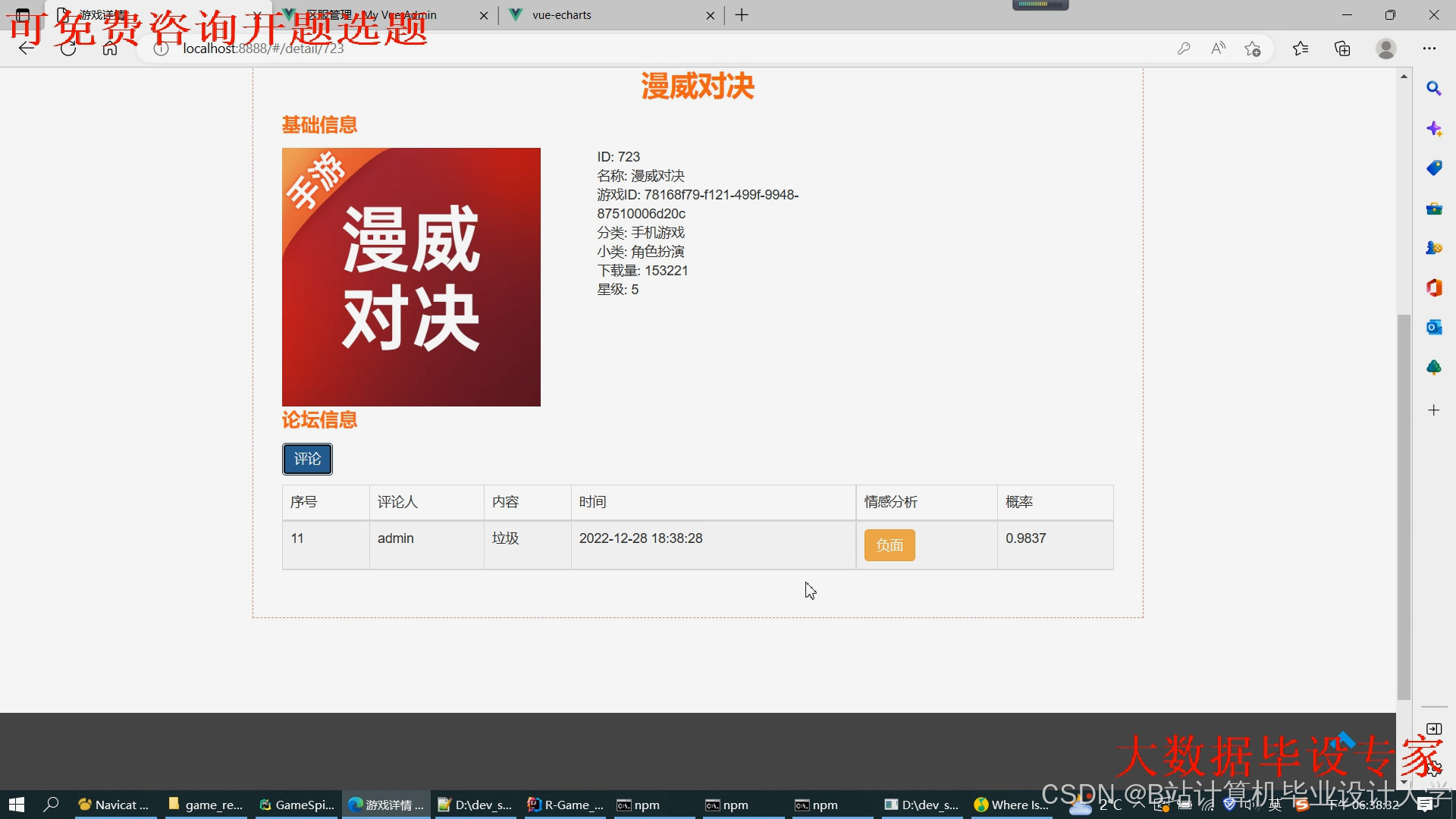
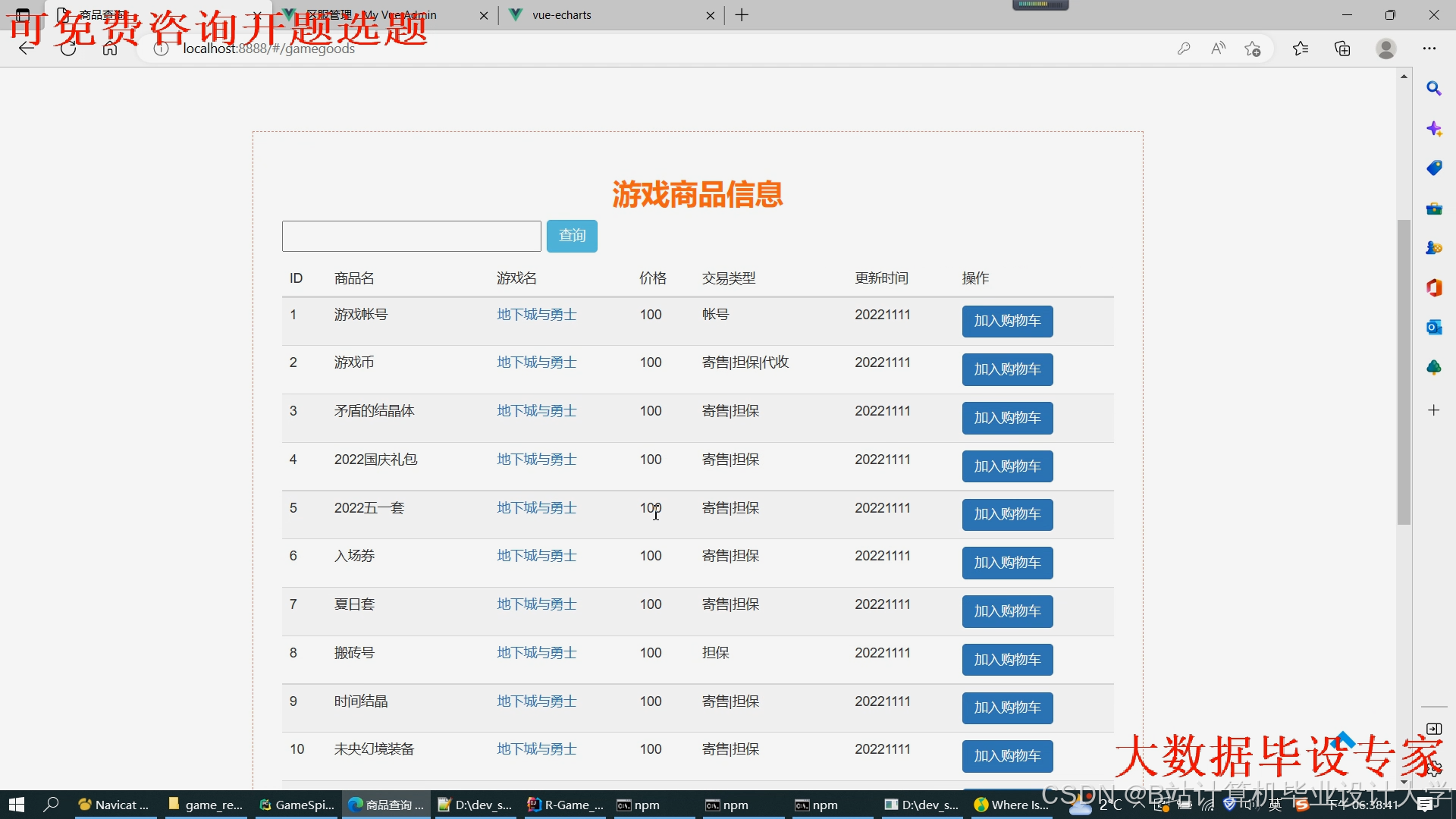
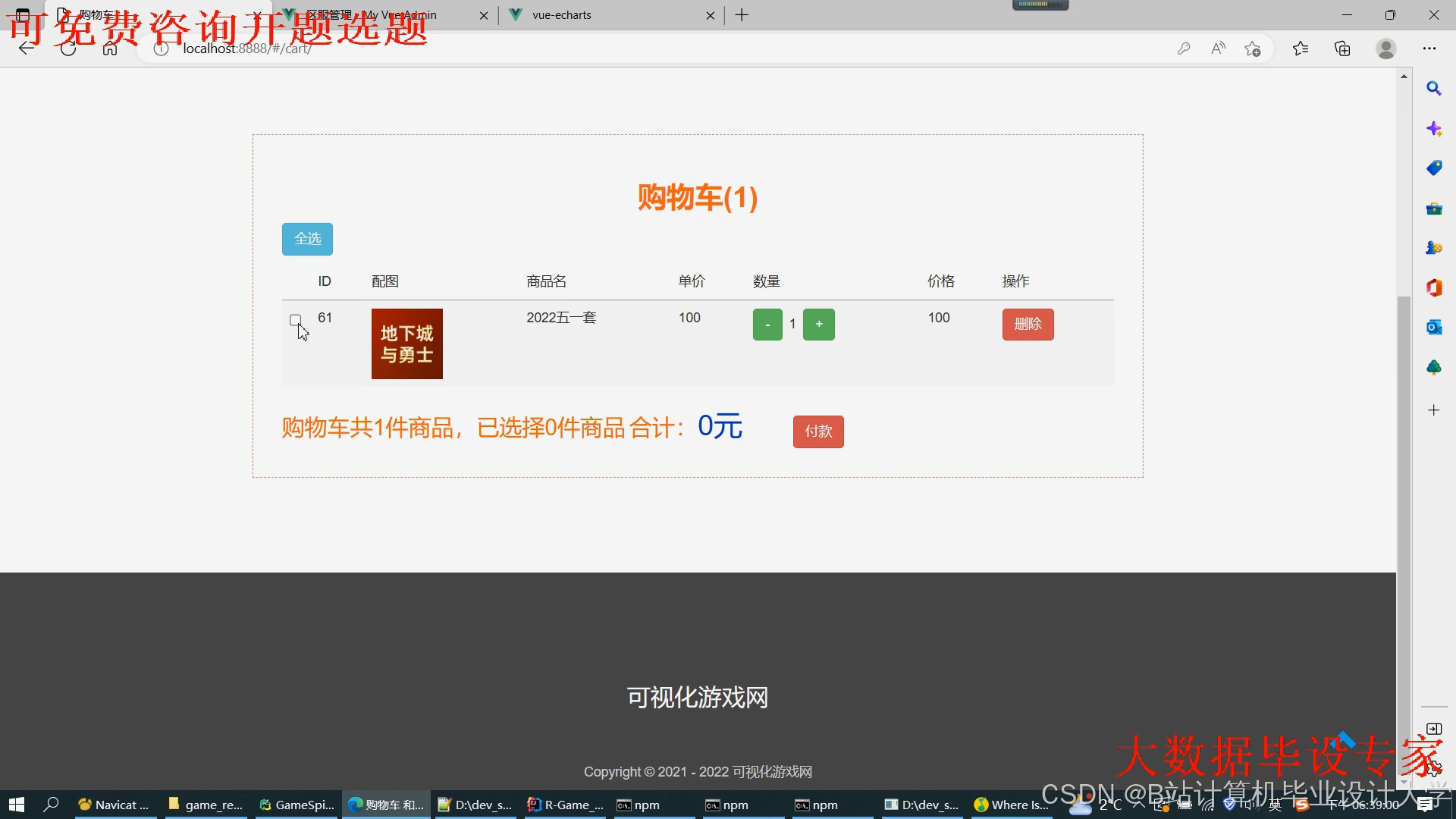
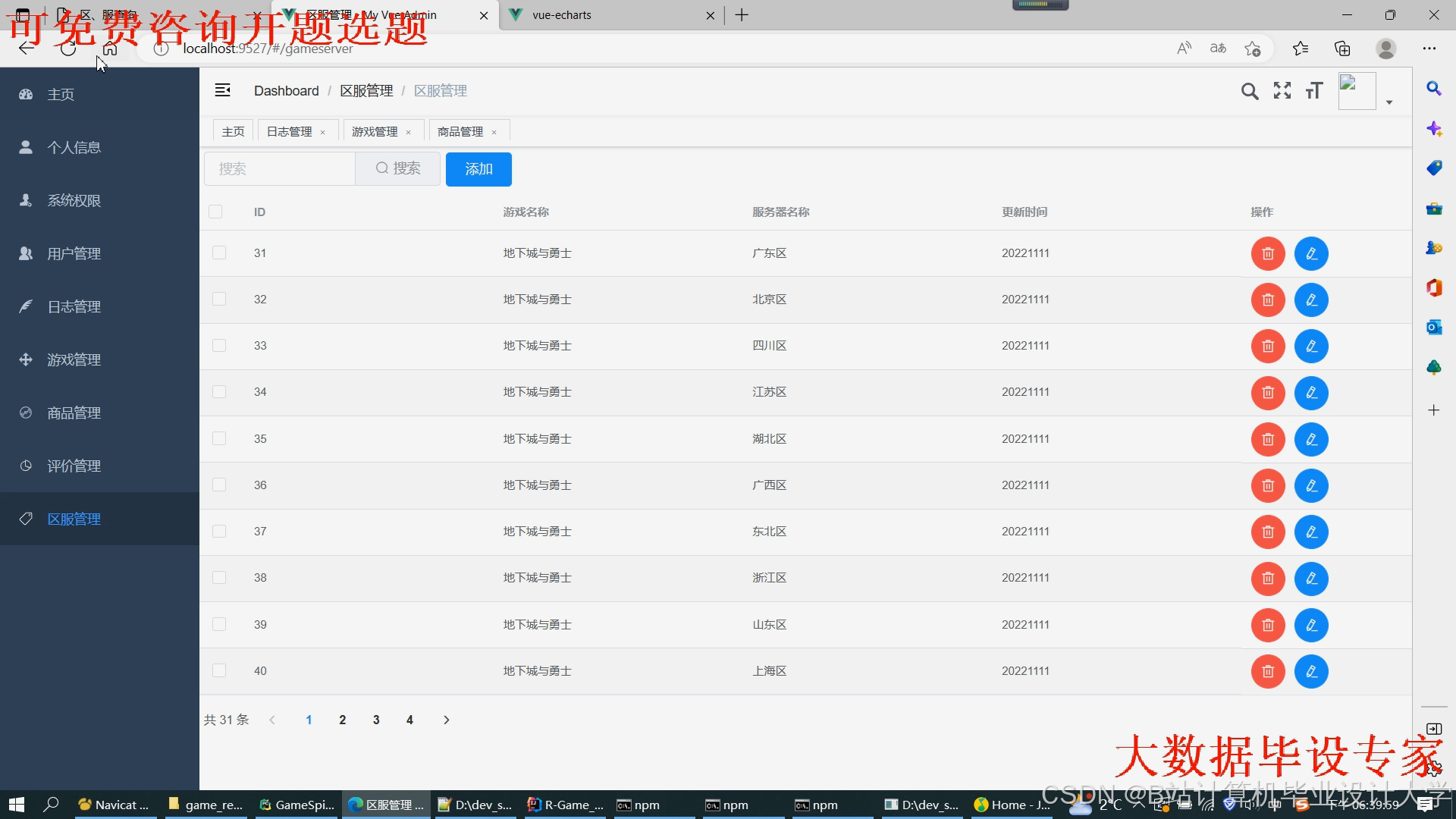
运行截图
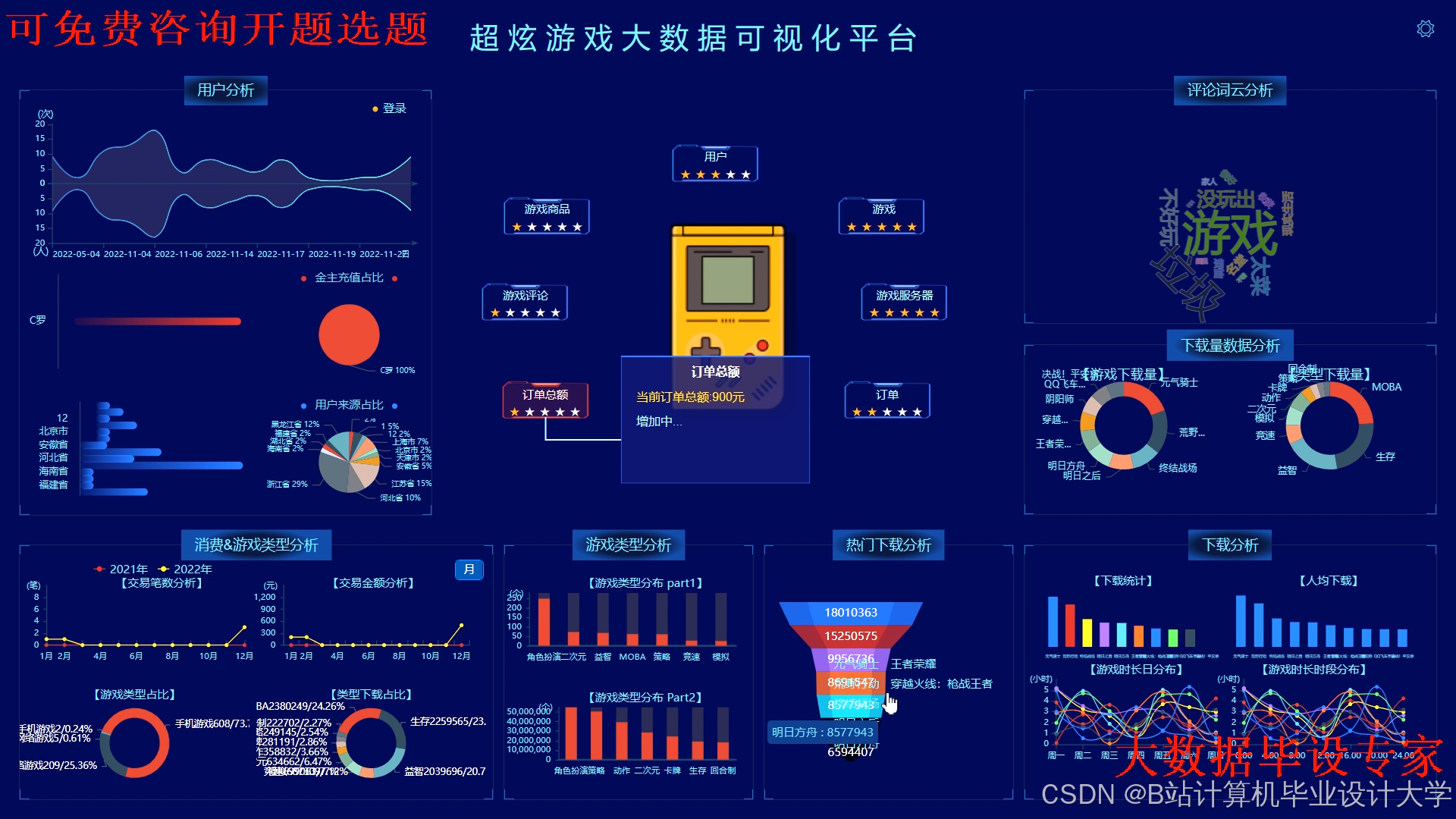
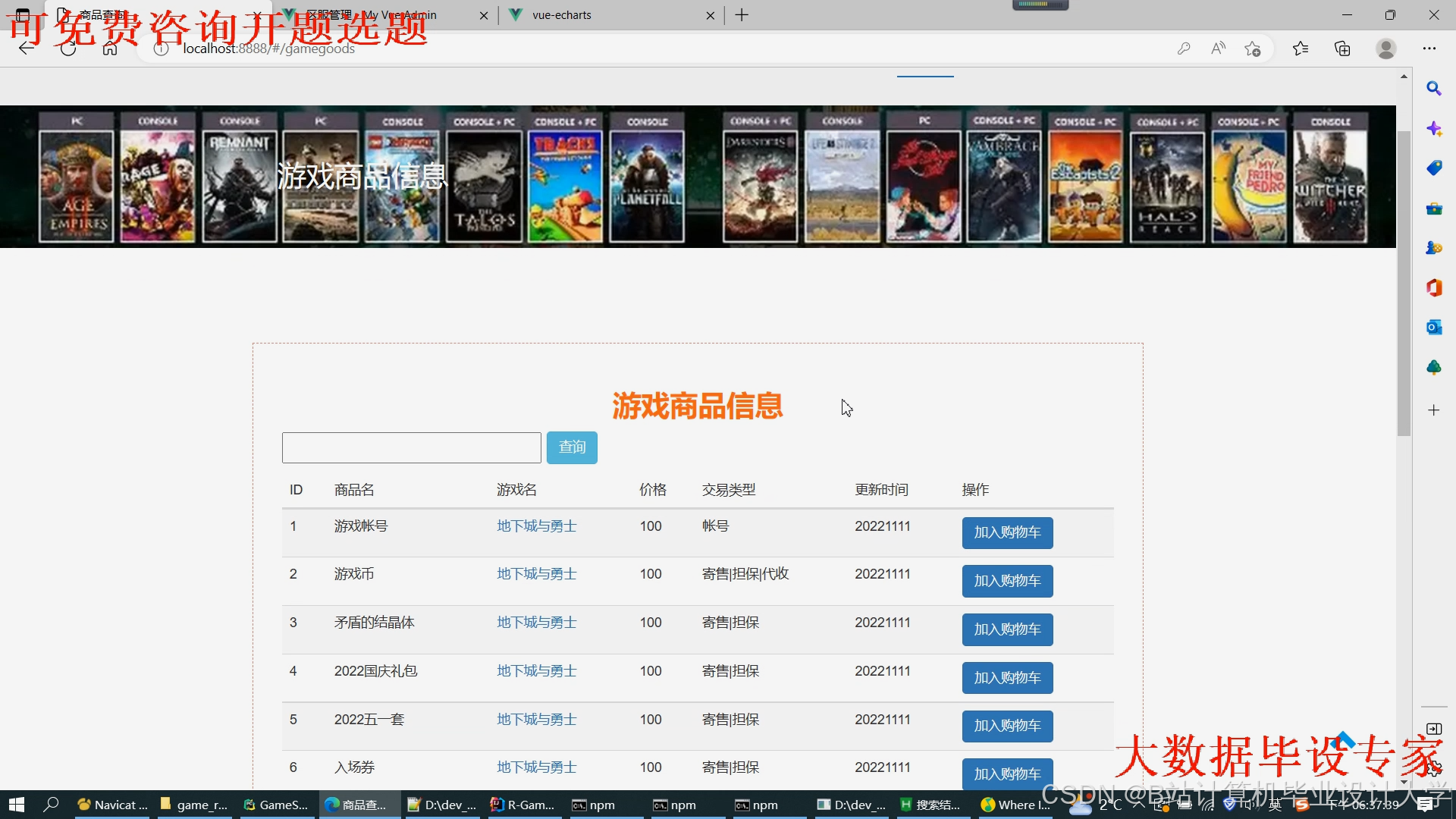

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻

