猫头虎AI分享|智谱直播开源其最新视觉模型:GLM-4.5V,多模态,支持图像、视频输入
猫头虎AI分享|智谱直播开源其最新视觉模型:GLM-4.5V,多模态,支持图像、视频输入
在人工智能的不断演化中,视觉语言模型(VLM)已经成为智能系统的核心组成部分。随着现实世界任务的复杂性不断增加,VLMs不仅需要增强基础的多模态感知能力,还要在推理、准确性、全面性以及智能化方面实现突破。最近,智谱AI发布了其最新的开源多模态视觉模型——GLM-4.5V,该模型基于GLM-4.5-Air底座,继续了GLM-4.1V-Thinking的技术路线,并在多个标准基准测试中取得了同规模模型的最先进性能。GLM-4.5V能够处理图像、视频、文档理解等常见任务,还支持GUI代理操作,是一款多功能、适应性强的视觉语言模型。

文章目录
- 猫头虎AI分享|智谱直播开源其最新视觉模型:GLM-4.5V,多模态,支持图像、视频输入
-
- GLM-4.5V概述
-
- 核心能力
- 性能表现
- 模型实现与训练
-
- 预训练、SFT与RL三阶段训练
- 价格与速度
- 训练方式
- GitHub与开源资源
- 体验截图
- 性能对比与基准测试
- 快速开始
-
- 1. 环境安装
- 2. 启动推理
- 3. 使用SGLang
- 模型微调
- 总结
GLM-4.5V概述
GLM-4.5V 是基于智谱AI的下一代旗舰文本基础模型GLM-4.5-Air(106B参数,12B活跃参数)的多模态版本。该模型通过引入混合训练方法,不仅能够处理图像和视频输入,还能够进行复杂的场景理解、事件识别以及GUI任务等。GLM-4.5V的技术亮点包括:
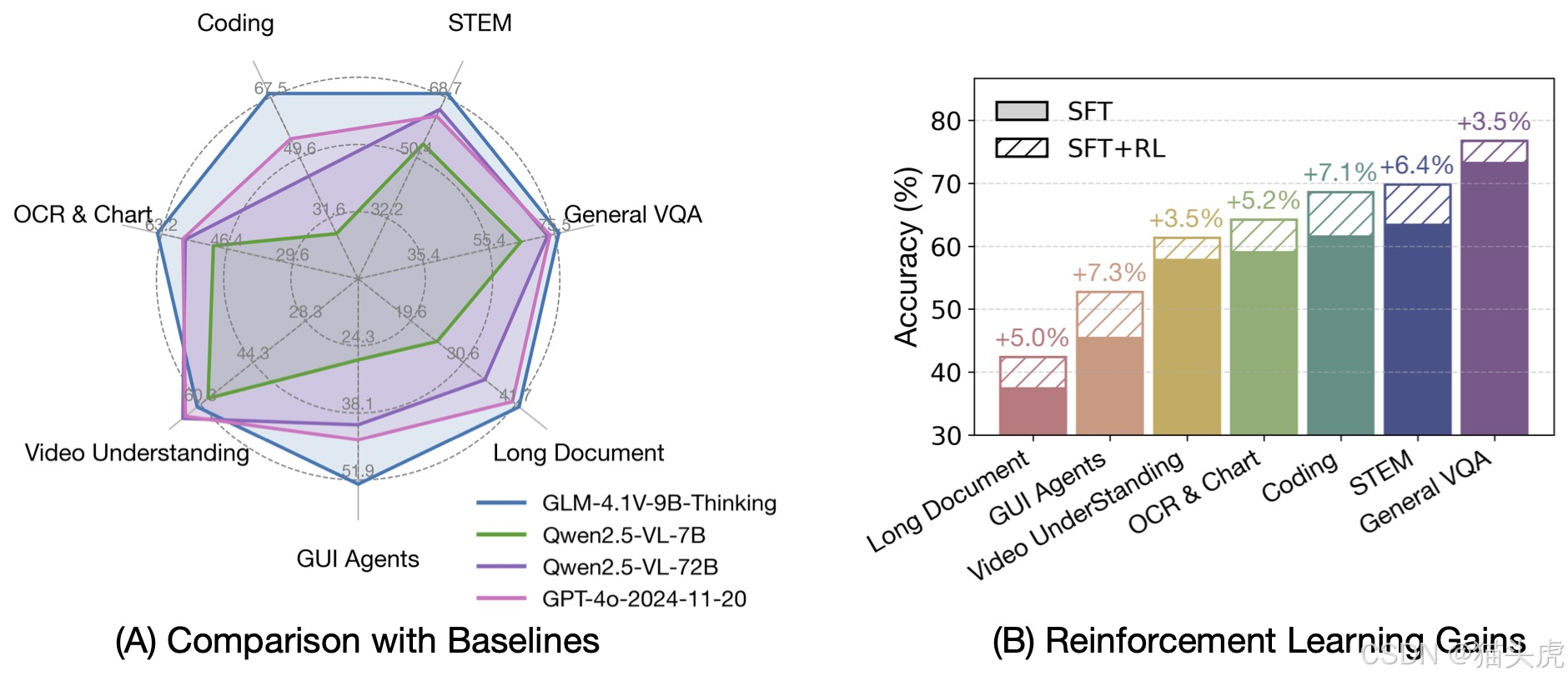
- 图像推理:场景理解、复杂多图像分析、空间识别。
- 视频理解:长视频分割、事件识别。
- GUI任务:屏幕阅读、图标识别、桌面操作协助。
- 复杂图表和长文档解析:研究报告分析、信息提取。
- 精确的视觉元素定位:包括图像中物体的精确定位与识别。
GLM-4.5V在42个公开的视觉语言基准测试中表现出色,继续推动了视觉推理和长文本理解的技术进步。
核心能力
- 图像推理:GLM-4.5V可以理解复杂的图像,处理场景分析、多个图像的整合分析,以及进行空间关系识别。
- 视频理解:它能够处理长视频的分割和事件识别,支持对视频内容的深入分析。
- GUI任务:在GUI任务中,GLM-4.5V能够有效进行屏幕阅读、图标识别和桌面操作协助,大大提高了计算机与用户的交互能力。
- 长文档解析:GLM-4.5V能够解析复杂的研究报告和文档,提取关键信息,适用于大量信息的理解与分析。
- 精准的视觉元素定位:该模型能够精确地识别和定位图像中的各类元素,确保视觉任务的高精度执行。
性能表现
GLM-4.5V的技术优化包括显式的COT(Chain-of-Thought)引入和强化学习阶段结合RLVR与RLHF(强化学习与人类反馈)。这使得它不仅在标准的视觉语言任务上表现优异,还在复杂的推理任务和多模态任务上有显著优势。以下是一些典型的功能实现:
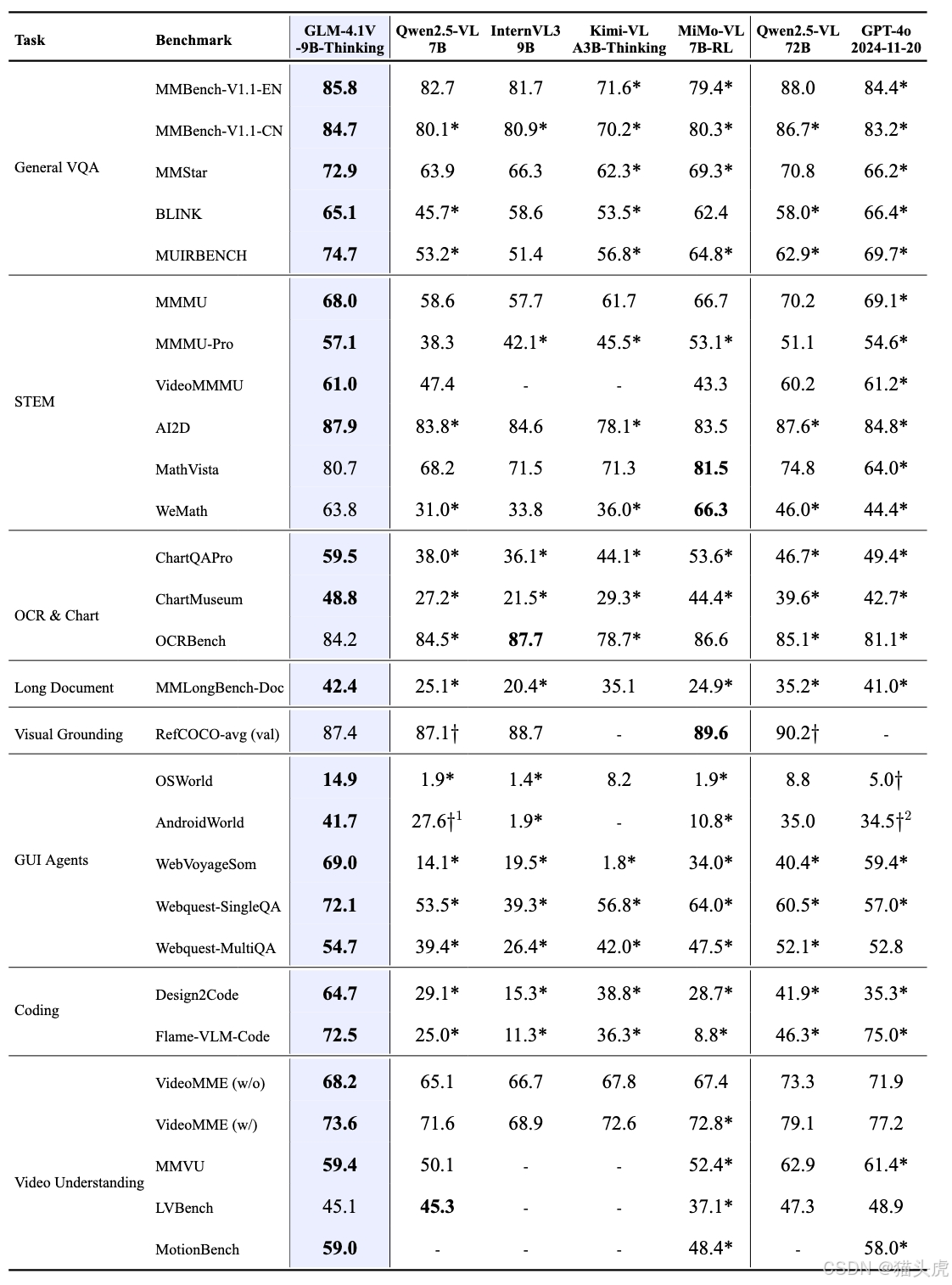
- 长视频分割与事件识别:对多小时长的视频内容进行分割,识别其中的关键事件,为智能监控、内容分析等应用提供支持。
- GUI代理操作:可以识别屏幕中的图标,理解桌面操作,帮助用户进行桌面自动化操作,提升工作效率。
- 复杂文档解析:能够处理结构复杂的长文档,帮助用户快速提取关键信息,应用于学术研究和企业数据分析等场景。
模型实现与训练
预训练、SFT与RL三阶段训练
GLM-4.5V的训练分为三个阶段:预训练、SFT(监督微调)、强化学习阶段(RL)。在SFT阶段,显式的COT(Chain-of-Thought)被引入,强化学习阶段结合RLVR和RLHF来优化模型,使其具备更强的多模态推理和任务处理能力。
价格与速度
- API输入:2元/百万tokens
- API输出:6元/百万tokens
- 速度:60-80 tokens/s
训练方式
- SFT阶段:引入显式COT,使得模型在推理过程中能够自我纠正,提升推理的准确性与可信度。
- 强化学习阶段:结合RLVR(Visual Reasoning)与RLHF(Human Feedback)来优化模型的多模态理解能力。
GitHub与开源资源
GLM-4.5V已开源,开发者可以通过以下链接访问源代码,并进行二次开发:
- GitHub:GLM-4.5V GitHub Repository
- 魔搭社区:GLM-4.5V魔搭社区链接
- 体验链接:GLM-4.5V体验(选择GLM-4.5V模型即可使用)
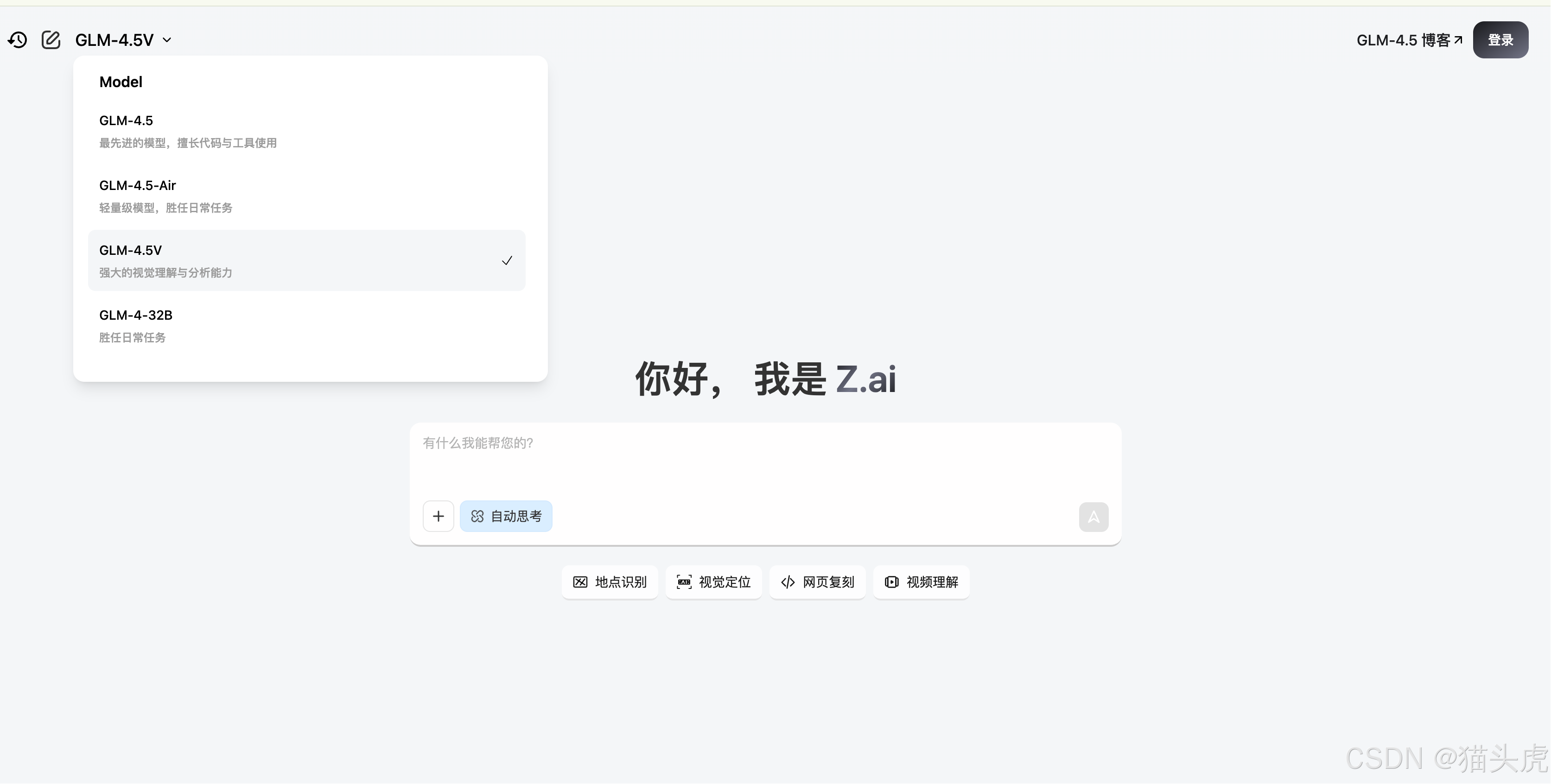
体验截图
以下是用户在使用GLM-4.5V时的一些截图,展示了其强大的多模态输入能力,包括图像、视频、PDF和PPT文件的理解。
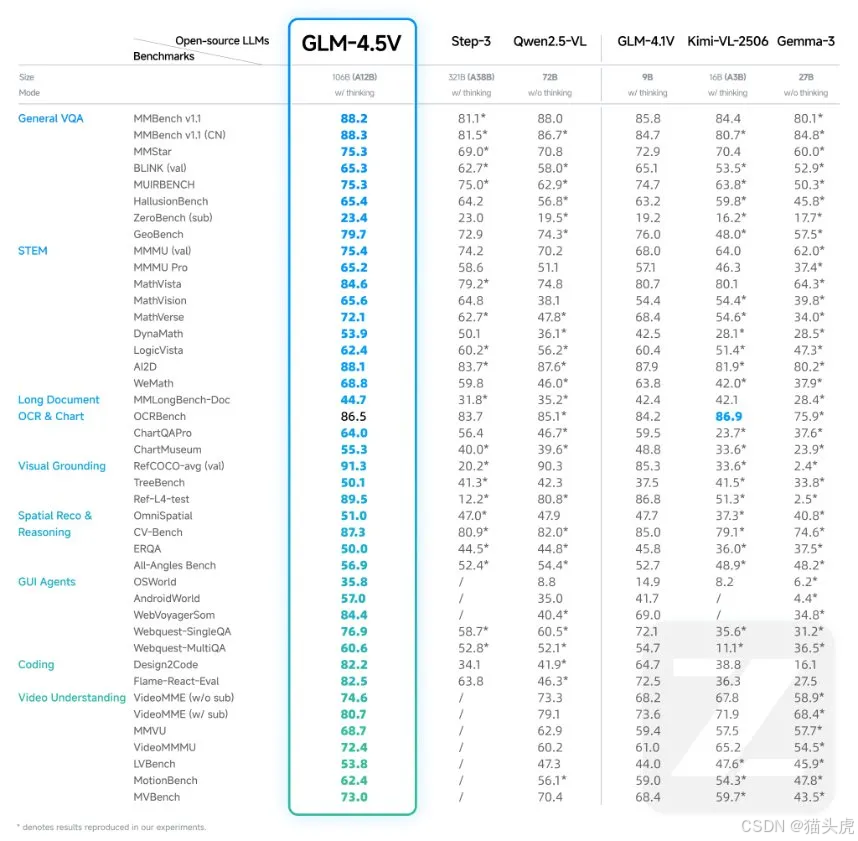
性能对比与基准测试
GLM-4.5V在多个标准基准测试中表现出色,以下是其在部分视觉语言基准上的跑分数据:
快速开始
要在NVIDIA GPU上使用GLM-4.5V进行推理,开发者可以按照以下步骤进行环境配置:
1. 环境安装
# 安装依赖pip install -r requirements.txt# 安装vLLMpip install -U vllm --pre --extra-index-url https://wheels.vllm.ai/nightlypip install transformers-v4.55.0-GLM-4.5V-preview2. 启动推理
vllm serve zai-org/GLM-4.5V \\ --tensor-parallel-size 4 \\ --tool-call-parser glm45 \\ --reasoning-parser glm45 \\ --enable-auto-tool-choice \\ --served-model-name glm-4.5v \\ --allowed-local-media-path / \\ --media-io-kwargs \'{\"video\": {\"num_frames\": -1}}\'3. 使用SGLang
python3 -m sglang.launch_server --model-path zai-org/GLM-4.5V \\ --tp-size 4 \\ --tool-call-parser glm45 \\ --reasoning-parser glm45 \\ --served-model-name glm-4.5v \\ --port 8000 \\ --host 0.0.0.0模型微调
GLM-4.5V支持基于LLaMA-Factory的微调,开发者可以根据自己的需求微调模型。在微调过程中,可以利用图像与文本配对的方式进行定制化训练,提高模型在特定任务上的表现。
例如,以下是微调时使用的示例数据集格式:
[ { \"messages\": [ { \"content\": \"Who are they?\", \"role\": \"user\" }, { \"content\": \"\\nUser asked me to observe the image and find the answer. I know they are Kane and Goretzka from Bayern Munich.\\nThey\'re Kane and Goretzka from Bayern Munich.\", \"role\": \"assistant\" } ], \"images\": [ \"mllm_demo_data/1.jpg\" ] }]总结
智谱AI的GLM-4.5V作为一款全新的多模态视觉语言模型,凭借其强大的视觉推理能力、灵活的多模态支持以及精确的元素定位,成为AI开发者和研究者在图像、视频、文档解析等任务中的得力工具。通过开源和共享,GLM-4.5V将继续推动人工智能领域的技术进步,为智能应用的开发和创新提供更多可能性。如果你对这项技术感兴趣,欢迎访问我们的GitHub和魔搭社区,获取更多信息并开始体验。

