Redis Pipeline性能翻倍秘籍:告别网络延迟,吞吐量提升10倍_redis pipeline 耗时高
💡 一句话真相:Redis Pipeline就像\"快递集装箱\"📦——把100件小包裹(命令)打包成1个大箱发送,运费(网络开销)降低90%!
🔧 一、为什么需要Pipeline?网络延迟的致命伤
传统命令执行痛点:
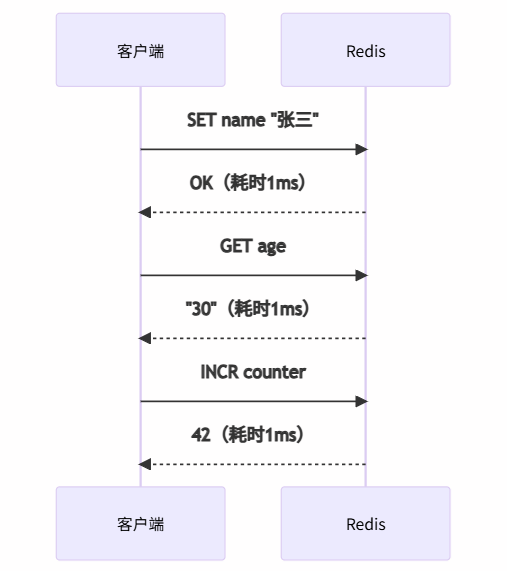
总耗时 = 命令数 × (网络延迟 + Redis处理时间)
- 100次命令:100 × (1ms + 0.1ms) = 110ms
- 其中网络开销占 91%!
⚙️ 二、Pipeline原理:批处理的艺术
1. 工作流程对比
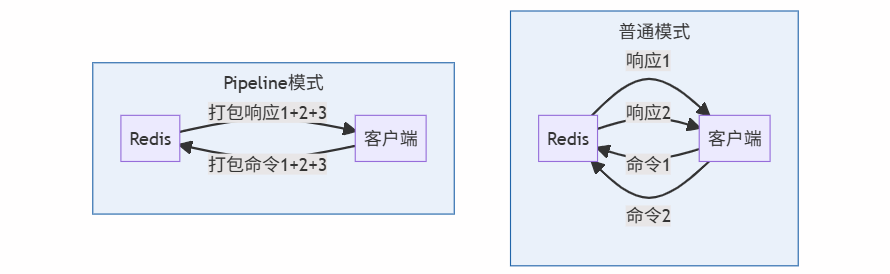
2. 核心优势
🛠️ 三、Pipeline使用全指南(4种语言示例)
1. 原生Redis-CLI
# 将命令写入文件 echo -e \"SET name 张三\\nGET age\\nINCR counter\" > cmds.txt # 管道执行 cat cmds.txt | redis-cli --pipe 输出:
All data transferred. Waiting for the last reply... Last reply received. 3 replies received. 2. Python(redis-py)
import redis r = redis.Redis() # 创建管道 pipe = r.pipeline() # 批量添加命令 pipe.set(\'name\', \'张三\') pipe.get(\'age\') pipe.incr(\'counter\') # 一次性执行 result = pipe.execute() print(result) # [True, b\'30\', 43] 3. Java(Jedis)
Jedis jedis = new Jedis(\"localhost\"); Pipeline pipe = jedis.pipelined(); pipe.set(\"name\", \"张三\"); pipe.get(\"age\"); pipe.incr(\"counter\"); // 执行并获取响应列表 List<Object> responses = pipe.syncAndReturnAll(); System.out.println(responses); // [OK, 30, 44] 4. Node.js(ioredis)
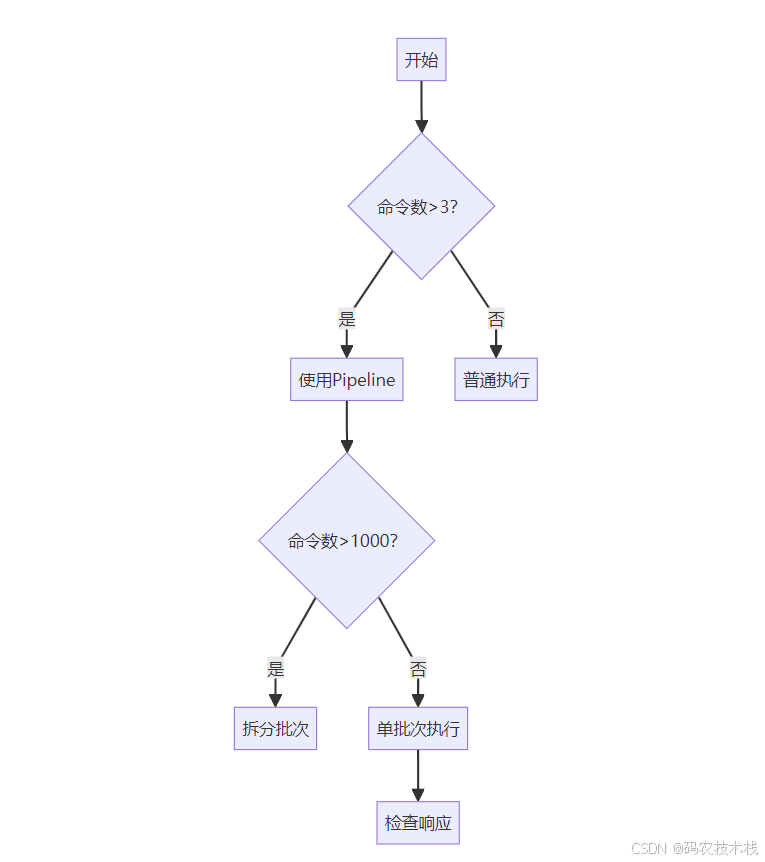
const redis = require(\'ioredis\'); const client = new redis(); const pipe = client.pipeline(); pipe.set(\'name\', \'张三\'); pipe.get(\'age\'); pipe.incr(\'counter\'); pipe.exec().then(results => { console.log(results); // [[null, \'OK\'], [null, \'30\'], [null, 45]] }); ⚠️ 四、四大使用误区与解决方案
🚫 误区1:Pipeline包过大导致阻塞
危险操作:
pipe = r.pipeline() for i in range(100000): pipe.set(f\'key:{i}\', \'value\') # 10万命令打包! pipe.execute() # 阻塞其他客户端! 优化方案:
# 分批次发送(每批1000条) for i in range(0, 100000, 1000): pipe = r.pipeline() for j in range(i, min(i+1000, 100000)): pipe.set(f\'key:{j}\', \'value\') pipe.execute() 🚫 误区2:误以为Pipeline是事务
区别对比:
🚫 误区3:忽略网络延迟影响
不同网络环境对比:
💡 结论:网络越差,Pipeline收益越大!
🚫 误区4:未处理部分失败
正确做法:
pipe.set(\'key1\', \'val1\') pipe.incr(\'key2\') # 若key2非数字会失败 results = pipe.execute() # 检查每个响应 for res in results: if isinstance(res, redis.exceptions.ResponseError): print(\"命令失败:\", res) 📊 五、Pipeline vs 其他优化方案
🚀 六、性能实测:不同数据量对比
测试环境:4核CPU/8GB内存/千兆网络
💡 压测命令:
redis-benchmark -t set -n 100000 -P 100(-P指定Pipeline打包数)
💎 七、最佳实践:四要三不要
✅ 四要:
- 要批量操作:超过3个命令就应使用Pipeline
- 要控制包大小:单批次命令数控制在100-1000
- 要检查响应:逐条验证命令执行结果
- 要复用连接:避免每次创建新Pipeline
❌ 三不要:
- 不要混用读写:读命令依赖写结果时用事务
- 不要阻塞主线程:避免单批次超大Package
- 不要忽略超时:配置合理socket超时时间
🔧 八、高级技巧:结合Lua脚本
场景:需要原子性+批处理(如批量扣库存)
-- batch_decrease.lua local keys = KEYS local amounts = ARGV for i, key in ipairs(keys) do local amt = tonumber(amounts[i]) if redis.call(\'GET\', key) < amt then return {err = \"库存不足\"} end end for i, key in ipairs(keys) do redis.call(\'DECRBY\', key, amounts[i]) end return {msg = \"成功扣减\"} Pipeline调用Lua脚本:
pipe = r.pipeline() # 预加载脚本 sha = pipe.script_load(lua_script) # 批量调用 items = {\'product:1\', \'product:2\'} amounts = [5, 3] pipe.evalsha(sha, len(items), *items, *amounts) results = pipe.execute() 💡 九、总结:Pipeline核心价值
- 碾压级性能优势:
- 网络延迟降低99%
- QPS提升10倍+
- 简单易用:
- 无需复杂配置
- 主流客户端完美支持
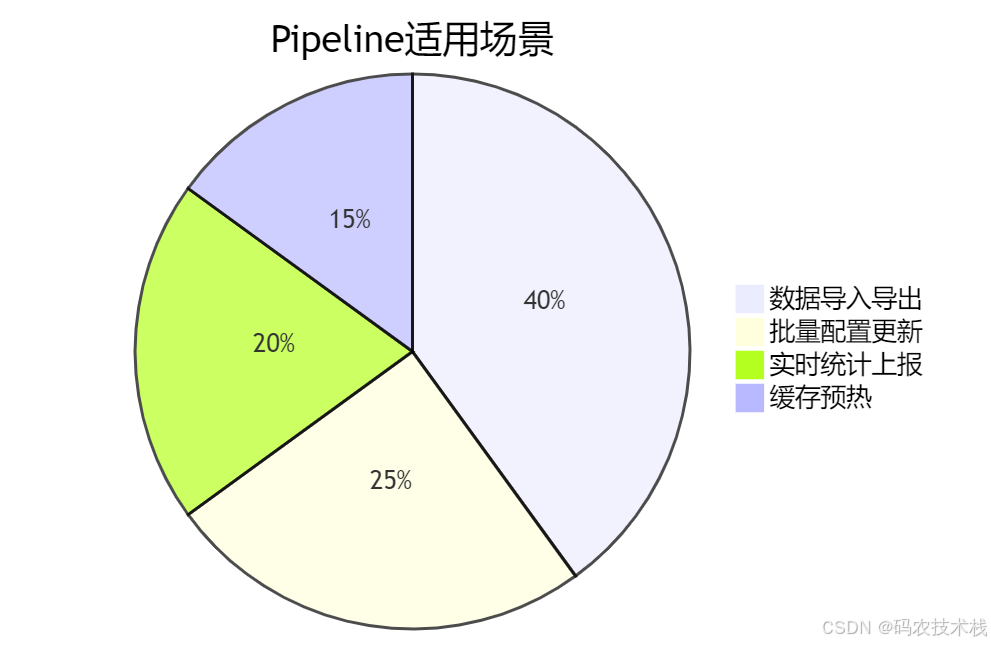
- 场景普适:
- 数据迁移
- 批量初始化
- 实时统计上报
🔥 黄金口诀:
- 网络延迟是瓶颈
- 命令打包用管道
- 千级批量控大小
- 响应检查不可少
#Redis优化 #高并发 #性能提升


