Springboot使用Selenium+ChormeDriver在服务器(Linux)端将网页保存为图片或PDF
应用场景
Java导出PDF有很多种方式,靠代码拼内容输出,在应对复杂报表将会很麻烦。
如果将要导出的内容做成网页,将网页保存为PDF,进行打印,这样将会比较灵活方便,适用于做复杂报表打印或者简历打印等场景。
实现思路
通过Selenium+ChormeDriver,调用Google Chrome 浏览器,将网页打印成PDF。
实现步骤
1.服务器端配置
(1)安装 Python
以CentOS / RHEL / Alibaba Cloud Linux系统为例。
# 更新系统包
sudo yum update -y# 安装 Python 3
sudo yum install -y python3 python3-pip# 验证安装
python3 --versionpip3 --versionAlibaba Cloud Linux 默认可能已预装 Python 3。
(2)安装 Selenium
pip3 install selenium
(3)安装 Google Chrome 浏览器
# 设置 Chrome 的 yum 源
sudo tee /etc/yum.repos.d/google-chrome.repo <<EOF[google-chrome]name=google-chromebaseurl=http://dl.google.com/linux/chrome/rpm/stable/x86_64enabled=1gpgcheck=1gpgkey=https://dl.google.com/linux/linux_signing_key.pubEOF# 安装 Chrome
sudo yum install -y google-chrome-stable# 验证安装
google-chrome --version输出:Google Chrome 139.0.7258.127 (具体版本以实际为准),记住这个版本号,后面下载ChromeDriver、引用java包时,都需要对应的版本,版本不一致运行不起。
(4)安装 ChromeDriver
ChromeDriver可以从华为的镜像下载,https://mirrors.huaweicloud.com/chromedriver/,下载对应版本号的文件。
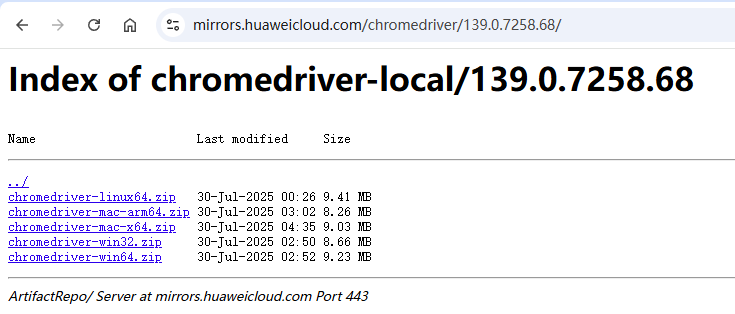
下载解压后,将chromedriver文件复制到 /usr/local/bin/chromedriver,并给执行权限。
sudo chmod +x /usr/local/bin/chromedriver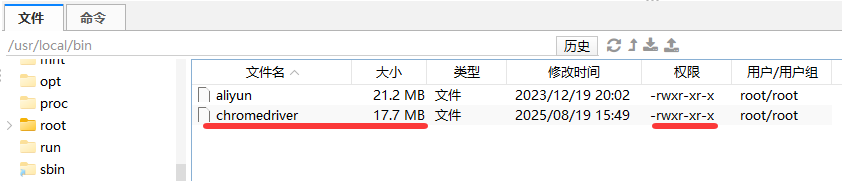
# 验证安装
chromedriver --version输出:ChromeDriver 139.0.7258.68 (40ff94600b6ed9fa7778a3a2566f254ad85f2147-refs/branch-heads/7258@{#2228})
2.Springboot集成 Selenium
(1)引入依赖
org.seleniumhq.seleniumselenium-java4.16.0org.seleniumhq.seleniumselenium-chrome-driver4.16.0注意引用的版本号要和selenum和ChromeDriver一致。
4.11 ~ 4.27.04.11 ~ 4.27.04.11 ~ 4.27.04.11 ~ 4.27.04.8 ~ 4.104.1 ~ 4.74.0 ~ 4.53.141.59(最后版本)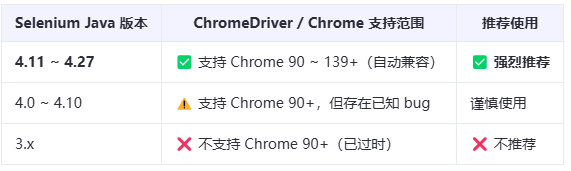
从 Selenium 4.11 开始,不再需要严格匹配 ChromeDriver 版本,只要主版本一致(如 Chrome 139)即可自动兼容。
(2)编写代码
/** * 将网页地址保存 * @param response * @param url * @return */@GetMapping(\"/urlToPdf\")@ResponseBodypublic Result urlToPdf(HttpServletResponse response, @RequestParam(value = \"url\", required = false) String url) {if (url == null || url.isEmpty()) {return Result.error(\"抱歉,url不能为空!\");}if (!isValidUrl(url)) {return Result.error(\"抱歉,url格式错误!\");}// 设置 ChromeDriver 的路径//Linux 系统System.setProperty(\"webdriver.chrome.driver\", \"/usr/local/bin/chromedriver\");//Windows系统//System.setProperty(\"webdriver.chrome.driver\", \"D:\\\\chromedriver-win64\\\\chromedriver.exe\");// 设置Chrome选项ChromeOptions options = new ChromeOptions();Map prefs = new HashMap();prefs.put(\"profile.default_content_setting_values.images\", 1); // 1:允许加载图片,2:阻止加载图片options.setExperimentalOption(\"prefs\", prefs);options.addArguments(\"--incognito\");options.setAcceptInsecureCerts(true);options.addArguments(\"--headless=new\");// 无头模式options.addArguments(\"--disable-gpu\");options.addArguments(\"--no-sandbox\");options.addArguments(\"--disable-dev-shm-usage\");options.addArguments(\"--window-size=1920,1080\");// 创建 WebDriver 实例ChromeDriver driver = new ChromeDriver(options);try {// 打开目标网页driver.get(url);// 设置打印选项PrintOptions printOptions = new PrintOptions();printOptions.setPageRanges(\"1-500\"); // 打印页码范围printOptions.setOrientation(PrintOptions.Orientation.PORTRAIT); // 纵向//printOptions.setScale(0.79); // 缩放比例printOptions.setBackground(true); // 打印背景// 执行打印并获取 PDF(Base64 编码)String pdfBase64 = ((PrintsPage) driver).print(printOptions).getContent();byte[] pdfBytes = Base64.getDecoder().decode(pdfBase64);//2.文件流OutputStream os = response.getOutputStream();//3.输出文件response.setContentType(\"application/pdf\");response.setCharacterEncoding(StandardCharsets.UTF_8.name());String fileName = URLEncoder.encode(System.currentTimeMillis() + \".pdf\", StandardCharsets.UTF_8); // 这里URLEncoder.encode可以防止中文乱码response.setHeader(\"Content-disposition\", \"attachment;filename*=utf-8\'\'\" + fileName);os.write(pdfBytes);os.flush();os.close();} catch (Exception e) {return Result.error(e.getMessage());} finally {driver.quit(); // 关闭浏览器}return Result.success(\"success\");}至此,完成了服务器端根据网页地址,下载成PDF的功能。


