云计算-----第八周
1. 总结 tomcat实现多虚拟机
安装[root@ubuntu ~]# wget https://dlcdn.apache.org/tomcat/tomcat-9/v9.0.108/bin/apache-tomcat-9.0.108.tar.gz[root@ubuntu ~]# tar xf apache-tomcat-9.0.108.tar.gz -C /usr/local/[root@ubuntu ~]# cd /usr/local/[root@ubuntu local]# ln -sv apache-tomcat-9.0.108/ tomcat[root@ubuntu local]# ln -sv /usr/local/tomcat/bin/* /usr/local/bin/[root@ubuntu ~]# useradd -r -s /sbin/nologin tomcat[root@ubuntu ~]# chown -R tomcat.tomcat /usr/local/tomcat/[root@rocky ~]# vim /lib/systemd/system/tomcat.service [Unit] Description=Tomcat After=syslog.target network.target [Service] Type=forking Environment=JAVA_HOME=/usr/lib/jvm/jdk-11-oracle-x64/ ExecStart=/usr/local/tomcat/bin/startup.sh ExecStop=/usr/local/tomcat/bin/shutdown.sh PrivateTmp=true User=tomcat Group=tomcat [Install] WantedBy=multi-user.target[root@ubuntu ~]# systemctl daemon-reload配置服务[root@ubuntu /usr/local/tomcat]$ vim ./conf/server.xml --> [root@ubuntu tomcat]# chown -R tomcat.tomcat /data[root@ubuntu ~]$ tree /data//data/├── webapps1│ └── ROOT│ ├── index.html│ └── test.jsp└── webapps2 └── ROOT ├── index.html └── test.jsp4 directories, 4 files [root@ubuntu ~]# cat /data/webapps/ROOT/test.jsp jsp hello world!
SessionID =
[root@ubuntu ~]$ cat /etc/hosts127.0.0.1 localhost127.0.1.1 ubuntu# The following lines are desirable for IPv6 capable hosts::1 ip6-localhost ip6-loopbackfe00::0 ip6-localnetff00::0 ip6-mcastprefixff02::1 ip6-allnodesff02::2 ip6-allrouters10.0.0.152 www.tomcat-cswz1.com www.tomcat-cswz2.com测试[root@ubuntu ~]$ curl -H \"Hocurl -H \"Host: www.tomcat-cswz2.com\" http://localhost:8080/test.jsp jsp hello world!
this is test page
http://www.tomcat-cswz2.com/test.jsp
127.0.0.1:8080
SessionID = D836140E7CA5C1E9DF9177DCA26141AA
</html[root@ubuntu ~]$ curl -H \"Hocurl -H \"Host: www.tomcat-cswz1.com\" http://localhost:8080/test.jsp jsp hello world!
this is test page
http://www.tomcat-cswz1.com/test.jsp
127.0.0.1:8080
SessionID = BC7E35422442E7166F7F0D2B49BBC13F
2. 总结 tomcat定制访问日志格式和反向代理tomcat
1.定制访问日志格式
[root@ubuntu ~]$ vim /usr/local/tomcat/conf/server.xml2.反向代理tomcat
[root@ubuntu tomcat]# cat conf/server.xml [root@ubuntu ~]$ cat /etc/nginx/conf.d/www.tomcat-cswz1.com.conf server{listen 80;server_name www.tomcat-cswz1.com;location / {proxy_pass http://127.0.0.1:8080;proxy_set_header host $http_host;}}[root@ubuntu ~]$ cat /etc/nginx/sites-enabled/www.tomcat-cswz1.com.conf server{listen 80;server_name java.m99-magedu.com;root /var/www/html/java.m99-magedu.com; location ~* \\.jsp$ { proxy_pass http://127.0.0.1:8080; proxy_set_header host $http_host; } }[root@ubuntu ~]$ 3. 总结iptable 5表5链, 基本使用,扩展模块。
1.五表五链
1.五表
1.raw表
主要用于配置数据包是否绕过连接跟踪(NOTRACK)机制
2.mangle表
修改数据包的 IP 头信息或给数据包打上特殊的标记(MARK),供后续处理或高级
路由使用
3.nat表
网络地址转换 (NAT)。修改数据包的源或目标 IP 地址/端口。
4.filter表
最常用的表。负责数据包的过滤(放行、拒绝、丢弃)
5.security表
设置强制访问控制(MAC)网络规则,通常与 SELinux 等安全框架结合使用。优
先级在 filter 表之后。
2.五链
1.PREROUTING链
(在 raw 表) 决定是否跟踪连接;(在 mangle 表) 修改包头;(在 nat 表)
做 DNAT (目标地址转换,端口转发)。
2.INPUT链
(在 mangle 表) 修改目标为本机的包;(在 filter 表) 过滤目标为本机的入站流
量(防火墙的主要入口);(在 security 表) 应用 MAC 规则。
3.FORWARD链
(在 mangle 表) 修改转发的包;(在 filter 表) 过滤经过本机转发的流量(路
由器/网关防火墙的核心功能)
4.OUTPUT链
(在 raw 表) 决定是否跟踪本地产生的连接;(在 mangle 表) 修改本地产生的
包;(在 nat 表) 对本地产生的包做 NAT(较少见);(在 filter 表) 过滤本机
产生的出站流量;(在 security 表) 应用 MAC 规则。
5.POSTROUTING链
(在 mangle 表) 做最后的包头修改;(在 nat 表) 做 SNAT / MASQUERADE (源地址转
换,共享上网)。
2.基本使用
完整格式示例iptables -t filter -A INPUT -s 192.168.0.1 -j DROP#指定表-t|--table table #指定表raw|mangle|nat|filter,如果不显式指定,默认是filter#操作链-N|--new-chain chain #添加自定义新链 -X|--delete-chain [chain] #删除自定义链(要求链中没有规则) -P|--policy chain target #设置默认策略,对filter表中的链而言,其默认策略有ACCEPT|DROP-E|--rename-chain old-chain new-chain #重命名自定义链,引用计数不为0的自定义链不能被重命名-L|--list [chain] #列出链上的所有规则 -S|--list-rules [chain] #列出链上的的有规则 -F|--flush [chain] #清空链上的所有规则,默认是所有链 -Z|--zero [chain [rulenum]] #置0,清空计数器,默认操作所有链上的所有规则#操作具体规则-A|--append chain rule-specification #往链上追加规则 -I|--insert chain [rulenum] rule-specification #往链上插入规则,可以指定编号,默认插入到最前面(第一条)-C|--check chain rule-specification #检查链上的规则是否正确 -D|--delete chain rule-specification #删除链上的规则 -D|--delete chain rulenum #根据编号删除链上的规则 -R|--replace chain rulenum rule-specifica #根据链上的规则编号,使用新的规则替换原有规则#其它选项-h|--help #显示帮助 -V|--version #显示版本 -v|--verbose #显示详细信息-n|--numeric #以数字形式显示IP和端口,默认显示主机名和协议名--line-numbers #显示每条规则编号3.扩展模块
基本匹配[!] -s|--source address[/mask][,...] #匹配源IP地址或网段 [!] -d|--destination address[/mask][,...] #匹配目标IP地址或网段 [!] -p|--protocol protocol #匹配具体协议,可以使用协议号或协议名,具体见 /etc/protocols[!] -i|--in-interface name #匹配报文流入接口,只用于数据流入 [!] -o|--out-interface name #匹配报文流出接口,只用于数据流出扩展匹配隐式扩展无需再用 -m 选项指明扩展模块的扩展机制,不需要手动加载扩展模块,不需要用 -m 显式指定的扩展,即隐式扩展tcp 协议的扩展选项[!] --source-port|--sport port[:port] #匹配报文源端口,可为端口连续范围 [!] --destination-port|--dport port[:port] #匹配报文目标端口,可为连续范围 [!] --tcp-flags mask comp#mask 需检查的标志位列表,用逗号分隔例如 SYN,ACK,FIN,RST #comp 在mask列表中必须为1的标志位列表,无指定则必须为0,用逗号分隔tcp协议的扩展选项--tcp-flags SYN,ACK,FIN,RST SYN #检查SYN,ACK,FIN,RST四个标志位,其中SYN值为1,其它值为0,表示第一次握手--tcp-flags SYN,ACK,FIN,RST SYN,ACK --tcp-flags SYN,ACK,FIN,RST SYN,ACK #第二次握手 [!] --syn #第一次握手的简单写法upd 协议的扩展选项[!] --source-port|--sport port[:port] #匹配报文的源端口或端口范围[!] --destination-port|--dport port[:port] #匹配报文的目标端口或端口范围icmp 协议的扩展选项[!] --icmp-type {type[/code]|typename}0/0|echo-reply #icmp应答8/0|echo-request #icmp请求显式扩展及相关模块显示扩展即必须使用 -m 选项指明要调用的扩展模块名称格式-m matchname [per-match-options]multiport 扩展以离散方式定义多端口匹配,最多指定15个端口[!] --source-ports|--sports port[,port|,port:port]... #指定多个源端口 [!] --destination-ports|--dports port[,port|,port:port]... #指定多个目标端口 [!] --ports port[,port|,port:port]... #多个源或目标端口iprange 扩展指明连续的(但一般不是整个网络)ip地址范围[!] --src-range from[-to] #源IP地址范围[!] --dst-range from[-to] #目标IP地址范围mac 扩展mac 模块可以指明源MAC地址,适用于:PREROUTING, FORWARD,INPUT chains[!] --mac-source XX:XX:XX:XX:XX:XXstring 扩展对报文中的应用层数据做字符串模式匹配检测--algo {bm|kmp} #过滤算法 Boyer-Moore|Knuth-Pratt-Morris,在Rocky8.6中bm算法配合nginx有问题--from offset #开始偏移量,一般用来跳过包头,只检查具体内容,这样能提高效率--to offset #结束偏移量 [!] --string pattern #具体要匹配的字符串 [!] --hex-string pattern #具体要匹配的字符串,16进制格式time 扩展根据将报文到达的时间与指定的时间范围进行匹配,此扩展中默认使用UTC时间,所以使用时,要根据当前时区进行计算注此扩展在CentOS8中有问题--datestart YYYY[-MM[-DD[Thh[:mm[:ss]]]]] #开始生效时间--datestop YYYY[-MM[-DD[Thh[:mm[:ss]]]]] #结束生效时间--timestart hh:mm[:ss]#开始生效时间--timestop hh:mm[:ss] #结束生效时间[!] --monthdays day[,day...] #指定几号,1-31 [!] --weekdays day[,day...] #指定星期几,可以写Mon|Tue|Wed|Thu|Fri|Sat|Sun,也可以写1|2|3|4|5|6|7--contiguous--kerneltz #内核时区,此选项不建议使用,CentOS7版本以上系统默认UTCconnlimit 扩展根据每客户端IP做并发连接数数量匹配,可防止 Dos(Denial of Service,拒绝服务)攻击--connlimit-upto N #连接的数量小于等于N时匹配--connlimit-above N #连接的数量大于N时匹配limit 扩展基于收发报文的速率做匹配 , 令牌桶过滤器。connlimit 扩展是限制单个客户端对服务器的并发连接数,limit 扩展是限制服务器上所有的连接数。--limit-burst number #前多少个包不限制--limit [/second|/minute|/hour|/day] #在一个时间区间内能接收的连接数state 扩展state 扩展,可以根据 \"连接追踪机制\" 去检查连接的状态,比较耗费资源[!] --state statestate 扩展的状态NEW 新发出请求;连接追踪信息库中不存在此连接的相关信息条目,因此,将其识别为第一次发出的请求ESTABLISHED NEW状态之后,连接追踪信息库中为其建立的条目失效之前期间内所进行的通信状态RELATED 新发起的但与已有连接相关联的连接,如:ftp协议中的数据连接与命令连接之间的关系INVALID 无效的连接,如flag标记不正确UNTRACKED 未进行追踪的连接,如:raw表中关闭追踪4. 总结iptables规则优化实践,规则保存和恢复。
1.规则优化实践
1.安全放行所有入站和出站的状态为ESTABLISHED状态连接,建议放在第一条,效率更高
2.谨慎放行入站的新请求
3.有特殊目的限制访问功能,要在放行规则之前加以拒绝
4.同类规则(访问同一应用,比如:http )匹配范围小的放在前面,用于特殊处理 不同类的规则
(访问不同应用,一个是http.另一个是mysql ),匹配范围大的放在前面,效率更 高
5.应该将那些可由一条规则能够描述的多个规则合并为一条,减少规则数量,提高检查
效率
6.设置默认策略,建议白名单(只放行特定连接)
7.默认规则(iptables -P)是 ACCEPT,不建议修改,容易出现 “自杀” 现象
8.规则的最后定义规则做为默认策略,推荐使用,放在最后一条
2.规则保存和恢复
1.使用iptables 命令定义的规则,手动删除之前,其生效期限为 kernel 存活期限,当系
统重启之后,定义 的规则会消失。
持久化保存规则 iptables -t filter -A INPUT -s 10.0.0.1 -j ACCEPT#导出到文件[root@ubuntu ~]# iptables-save > iptables.rule#导入[root@ubuntu ~]# iptables-restore < ./iptables.rule 5. 总结NAT转换原理, DNAT/SDNAT原理,并自行设计架构实现DNAT/SNAT。
1.NAT转换原理
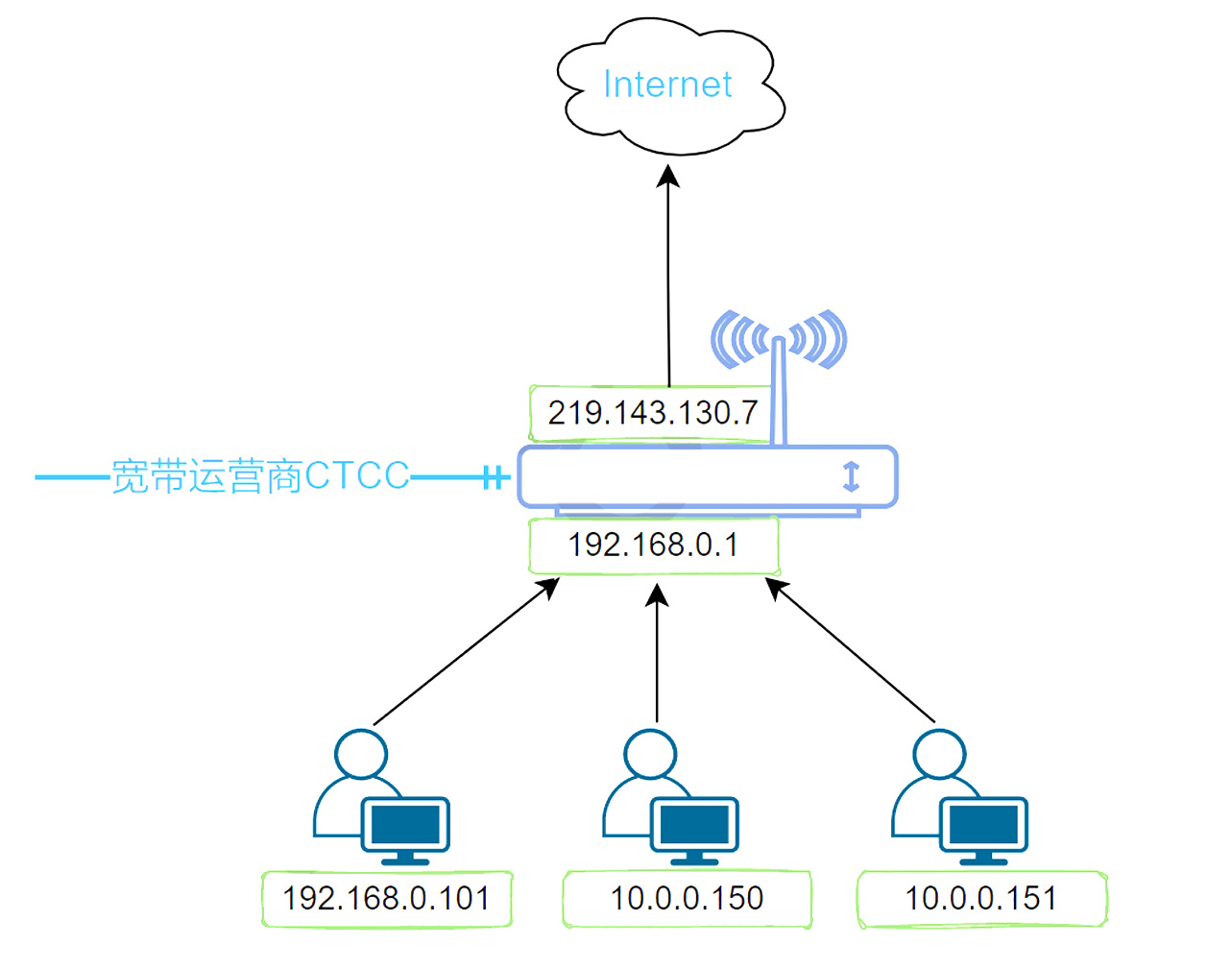
局域网中的主机都是分配的私有IP地址,这些IP地址在互联网上是不可达的,局域网中的主机,在与互 联网通讯时,要经过网络地址转换,去到互联网时,变成公网IP地址对外发送数据。服务器返回数据 时,也是返回到这个公网地址,再经由网络地址转换返回给局域网中的主机
2.DNAT/SDNAT原理
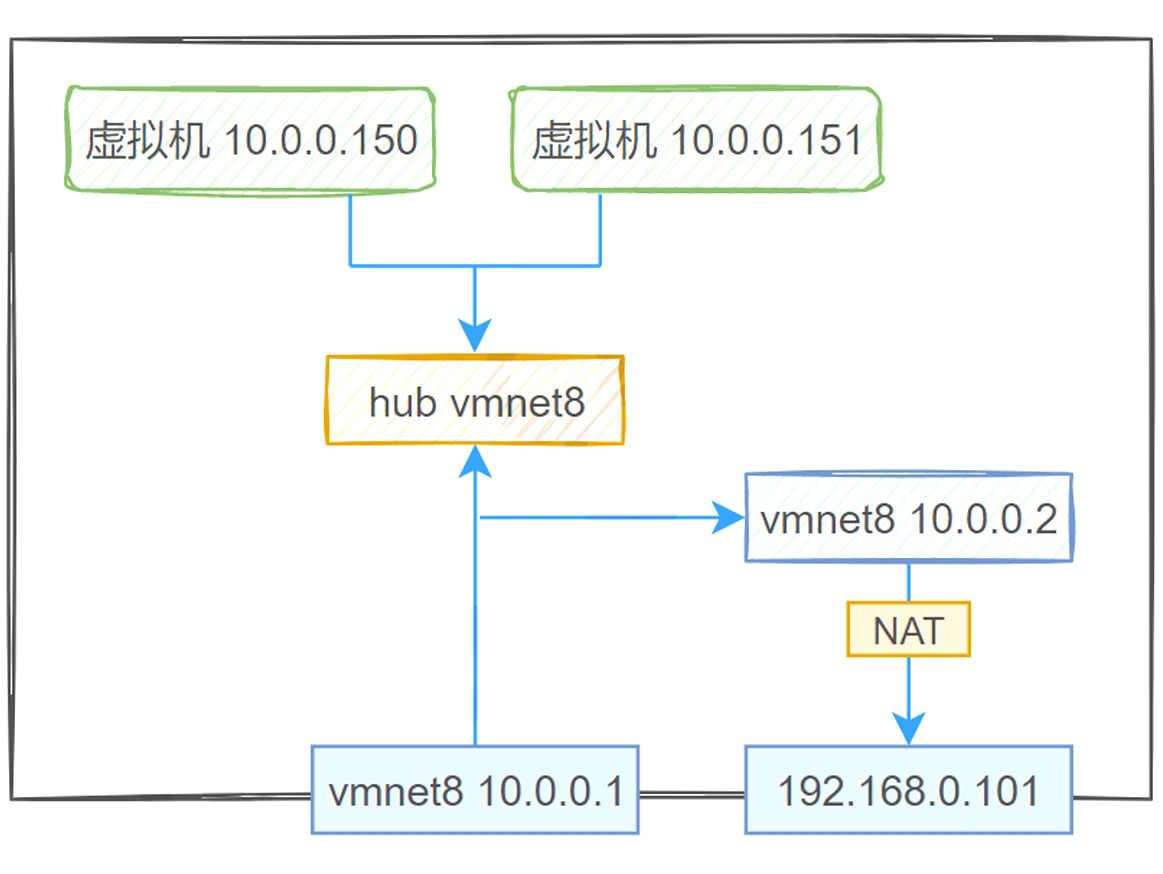
DNAT
在 PREROUTING 链(路由决策前)进行DNAT操作
修改目标地址后,内核根据新目标IP重新路由(可能转发到本机或其他设备)
公网用户访问网关的公网IP,DNAT将其转发到内网服务器
SNAT
在 POSTROUTING 链(路由决策后,数据包发出前)进行SNAT操作
内网主机 访问公网服务器 ,SNAT将源IP替换为网关公网IP
3.自行设计架构实现DNAT/SNAT
启用 IP 转发[root@ubuntu ~]$ echo \"net.iecho \"net.ipv4.ip_forward = 1\" >> /etc/sysctl.conf[root@ubuntu ~]$ sysctl -p[root@ubuntu ~]$ iptables -tiptables -t nat -A POSTROUTING -s 10.0.0.100/24 -j SNAT --to-source 10.0.0.152[root@ubuntu ~]$ iptables -Aiptables -A FORWARD -s 10.0.0.100/24 -j ACCEPT配置 DNATiptables -t nat -A PREROUTING -d 10.0.0.152 -p tcp --dport 8080 -j DNAT --to-destination 10.0.0.100:80iptables -A FORWARD -d 10.0.0.100 -p tcp --dport 80 -j ACCEPTiptables -t nat -A POSTROUTING -d 10.0.0.100 -p tcp --dport 80 -j SNAT --to-source 10.0.0.1526. 使用REDIRECT将90端口重定向80,并可以访问到80端口的服务
iptables -t nat -A PREROUTING -p tcp --dport 90 -j REDIRECT --to-port 80测试[root@ubuntu ~]$ curl -I http://127.0.0.1:90HTTP/1.1 200 OKServer: nginx/1.18.0 (Ubuntu)Date: Fri, 22 Aug 2025 08:39:01 GMTContent-Type: text/htmlContent-Length: 612Last-Modified: Sun, 10 Aug 2025 01:45:40 GMTConnection: keep-aliveETag: \"6897f9c4-264\"Accept-Ranges: bytes7. firewalld常见区域总结。
8. 通过ntftable来实现暴露本机80/443/ssh服务端口给指定网络访问
[root@ubuntu ~]$ vim /etc/nftables.conf#!/usr/sbin/nft -fflush rulesettable inet filter { chain input { type filter hook input priority 0; policy drop; ip saddr 10.0.0.152/24 tcp dport { 22, 80, 443 } accept; } chain forward { type filter hook forward priority 0;policy drop; } chain output { type filter hook output priority 0;policy accept; }}应用[root@ubuntu ~]$ nft -f /etc/nftables.conf 9. 完成 nginx 反向代理 tomcat实现基于redis会话复制的集群构建
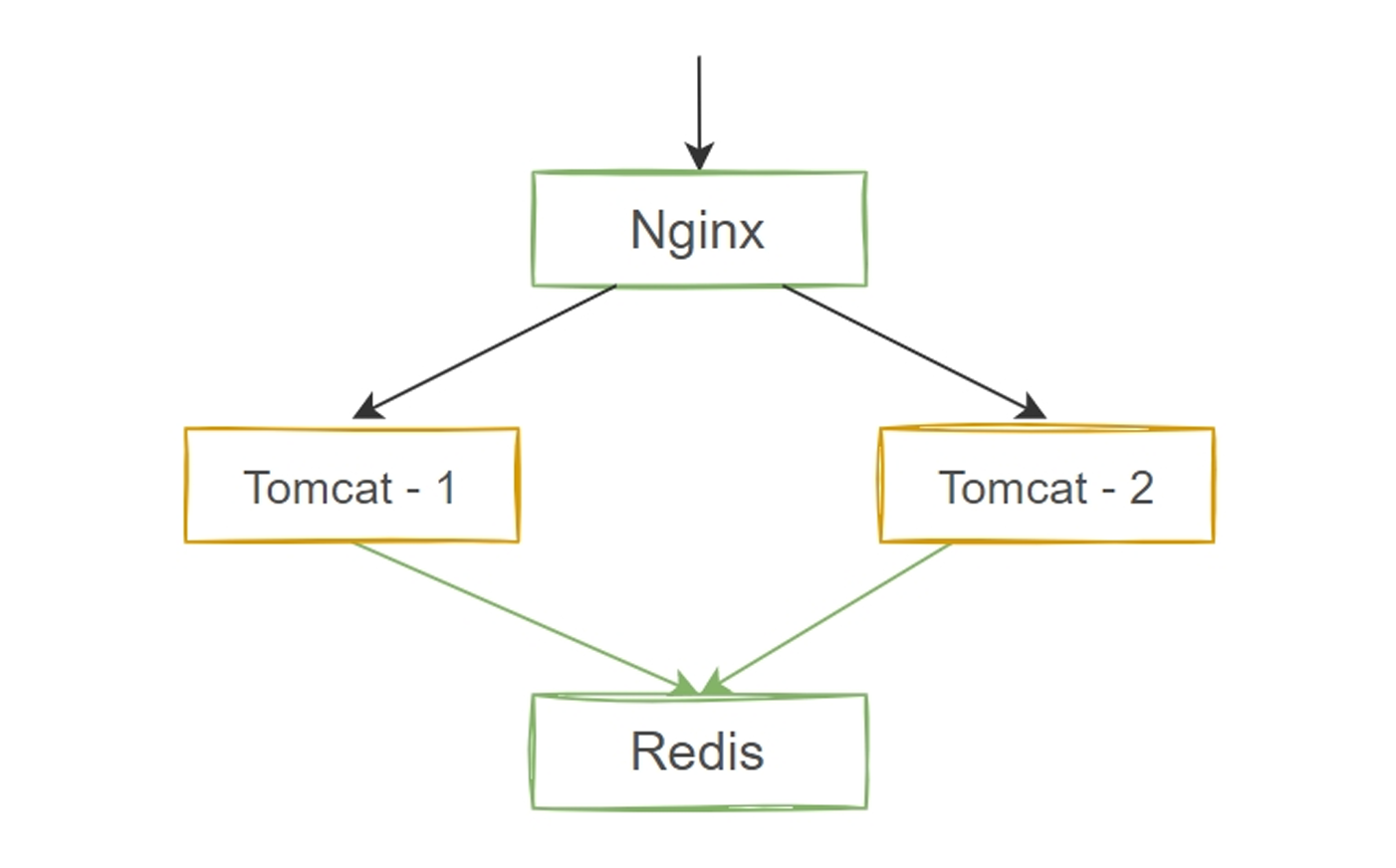
配置 Redisvim /etc/redis/redis.conf# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~#bind 127.0.0.1 ::1bind 0.0.0.0sudo systemctl restart redis-serversudo systemctl enable redis-server配置 Tomcat [root@ubuntu ~]# cat /usr/local/tomcat/conf/context.xml WEB-INF/web.xml WEB-INF/tomcat-web.xml ${catalina.base}/conf/web.xml <!-- -->root@ubuntu162:/etc/systemd/system# cat /etc/systemd/system/tomcat.service [Unit]Description=Apache Tomcat Web Application ContainerAfter=network.target syslog.target[Service]Type=forkingEnvironment=JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64User=tomcatGroup=tomcatExecStart=/usr/tomcat/bin/startup.shExecStop=/usr/tomcat/bin/shutdown.shPrivateTmp=true[Install]WantedBy=multi-user.targetroot@ubuntu162:/etc/systemd/system# 创建 Nginx 配置cat /etc/nginx/sites-enabled/www.tomcswy.com.confupstream tomcat { server 10.0.0.152:8080; server 10.0.0.162:8080; } server{ listen 80; server_name www.tomcswy.com; location ~* \\.jsp$ { proxy_pass http://tomcat; proxy_set_header host $http_host; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; } } 10. 总结 JVM垃圾回收算法和分代
1.JVM垃圾回收算法
1.Garbage 垃圾确定方法
1.引用计数:每一个堆内对象上都与一个私有引用计数器,记录着被引用的次数,
引用计数清零,该 对象所占用堆内存就可以被回收。循环引用的对象都无法将引用
计数归零,就无法清除。
2.垃圾回收基本算法
1.标记-清除 Mark-Sweep
1.分垃圾标记阶段和内存释放两个阶段
1.标记阶段,找到所有可访问对象打个标记。
2.清理阶段,遍历整个堆 对未标记对象(即不再使用的对象)逐一进行清理
3.特点:算法简单,不会浪费内存空间,效率较高,但会形成内存碎片
2.标记-压缩 (压实)Mark-Compact
1.分垃圾标记阶段和内存整理两个阶段
1.标记阶段,找到所有可访问对象打个标记
2.内存清理阶段时,整理时将对象向内存一端移动,整理后存活对象连续
的集中在内存一端
3.特点:整理后的内存空间是连续分配的,有大段的连续内存可分配,没
有内存碎片,缺点是内存整理过 程有消耗,效率相对低下
3.复制 Copying
1.先将可用内存分为大小相同两块区域A和B,每次只用其中一块,比如A。当
A用完后,则将A中存活的对 象复制到B。复制到B的时候连续的使用内存,最
后将A一次性清除干净
2.特点:好处是没有碎片,复制过程中保证对象使用连续空间,且一次性清除所
有垃圾,所以即使对象很 多,收回效率也很高,缺点是比较浪费内存,只能
使用原来一半内存,因为内存对半划分了,复制过程 毕竟也是有代价
4.没有最好的算法,在不同场景选择最合适的算法
1.效率:复制算法>标记清除算法> 标记压缩算法
2.内存整齐度:复制算法=标记压缩算法> 标记清除算法
3.内存利用率:标记压缩算法=标记清除算法>复制算
2.分代
1.将heap内存空间分为三个不同类别: 年轻代、老年代、持久代
1.年轻代
1.伊甸园区 eden:只有一个,刚刚创建的对象
2.幸存(存活)区 Servivor Space:有2个幸存区,一个是from区,一个是to区。大小
相等、地位相同、可互 换
3.年轻代回收 Minor GC
1. 起始时,所有新建对象(特大对象直接进入老年代)都出生在eden,当eden满了,
启动GC。这个称 为Young GC 或者 Minor GC
2. 先标记eden存活对象,然后将存活对象复制到s0(假设本次是s0,也可以是
s1,它们可以调 换),eden剩余所有空间都清空。GC完成
3. 继续新建对象,当eden再次满了,启动GC
4. 先同时标记eden和s0中存活对象,然后将存活对象复制到s1。将eden和s0清空,
此次GC完成
5. 继续新建对象,当eden满了,启动GC
6. 先标记eden和s1中存活对象,然后将存活对象复制到s0。将eden和s1清空,此次
GC完成
7. 以后就重复上面的步骤
注:通常场景下,大多数对象都不会存活很久,而且创建活动非常多,新生代就需要
频繁垃圾回收。但是,如 果一个对象一直存活,它最后就在from、to来回复制,如
果from区中对象复制次数达到阈值(默认15 次,CMS为6次,可通过java的选项 -
XX:MaxTenuringThreshold=N 定),就直接复制到老年代
2.老年代
1.长时间存活的对象
2.老年代回收 Major GC
1.进入老年代的数据较少,所以老年代区被占满的速度较慢,所以垃圾回收也
不频繁
2.如果老年代也满了,会触发老年代GC,称为Old GC或者 Major GC
3.由于老年代对象一般来说存活次数较长,所以较常采用标记-压缩算法
4.当老年代满时,会触发 Full GC,即对所有\"代\"的内存进行垃圾回收
5.Minor GC比较频繁,Major GC较少。但一般Major GC时,由于老年代对象
也可以引用新生代对 象,所以先进行一次Minor GC,然后在Major GC会提高
效率。可以认为回收老年代的时候完成了 一次FullGC
6.所以可以认为 MajorGC = FullGC
3.持久代
1.JDK1.7之前使用,即Method Area方法区,保存 JVM 自身的类和方法,存储
JAVA 运行时的环境信息,
2.JDK1.8 后改名为 MetaSpace,此空间不存在垃圾回收,关闭JVM会释放此区域
内存,此空间物理上不属 于heap内存,但逻辑上存在于heap内存
3.永久代必须指定大小限制,字符串常量JDK1.7存放在永久代,1.8后存放在heap中
4.MetaSpace 可以设置,也可不设置,无上限


