实现Elasticsearch的高效嵌入向量相似打分功能
本文还有配套的精品资源,点击获取 
简介:Elasticsearch是一个强大的分布式全文搜索引擎,广泛用于数据搜索和分析。结合Python,我们可以通过嵌入向量技术提高Elasticsearch的查询性能和结果的相关性。本插件利用机器学习中的向量概念,通过点积或余弦相似度对文档进行评分,从而改进传统的搜索方式。具体步骤包括数据预处理、存储向量、查询处理、相似度计算和结果排序。通过这样的技术集成,开发者可以提升数据检索的精度,并为用户提供更优的体验。
1. Elasticsearch分布式全文搜索引擎
1.1 Elasticsearch概述
Elasticsearch是一个高度可扩展的开源全文搜索和分析引擎。它允许你快速、近实时地存储、搜索和分析大量数据。它基于Apache Lucene构建,并以REST API的形式提供服务,使其能够轻松与各种编程语言进行交互。
1.2 Elasticsearch分布式特性
Elasticsearch的核心是其分布式特性。通过简单的配置,它能够自动在多台服务器之间分发数据和负载,提供数据的高可用性和容错性。其设计目标是水平可扩展性、高可用性和容错性,使其非常适合于处理PB级别的结构化或非结构化数据。
1.3 Elasticsearch应用场景
Elasticsearch广泛应用于日志数据分析、实时数据存储与分析、实时搜索等多个场景。它支持复杂的查询,如全文搜索、结构化搜索以及地理位置信息搜索等。结合强大的数据可视化工具Kibana,Elasticsearch还可以帮助用户以直观的方式分析数据和探索趋势。
2. Python与Elasticsearch交互
在上一章中,我们了解了Elasticsearch的分布式全文搜索引擎的基本概念和架构。随着第二章的展开,我们将重点关注Python与Elasticsearch交互的详细步骤,从基础的操作到高级查询技巧,再到同步与异步交互模式。通过本章节的介绍,Python开发者可以学会如何高效地利用Elasticsearch实现强大的搜索功能。
2.1 Python操作Elasticsearch基础
2.1.1 安装与配置Elasticsearch-Python客户端
在使用Python与Elasticsearch进行交互之前,首先需要安装一个专门为Elasticsearch设计的Python客户端库。最常用的客户端库之一是 elasticsearch-py ,可以通过Python的包管理工具pip进行安装:
pip install elasticsearch安装完成后,接下来要配置该客户端以便能够与Elasticsearch集群进行通信。通常需要指定集群的地址,有时还需要额外的配置如认证信息、超时设置等。
下面的代码示例展示了如何初始化一个Elasticsearch对象,以便Python脚本可以与Elasticsearch集群进行交互:
from elasticsearch import Elasticsearch# 连接到本地运行的Elasticsearch实例es = Elasticsearch([ {\'host\': \'localhost\', \'port\': 9200}])# 检查连接状态print(es.cluster.health()) elasticsearch-py 客户端库与Elasticsearch版本有着紧密的关联。在实际开发中,应确保Python客户端库与Elasticsearch集群版本兼容。
2.1.2 索引的创建与数据操作接口
创建索引是Elasticsearch中数据存储的基本操作。Python客户端提供了创建索引的接口,并允许开发者在创建索引时定义一些属性,如分片数和副本数等。
# 创建一个新的索引,并设置分片数和副本数es.indices.create(index=\"test-index\", body={ \'settings\': { \'number_of_shards\': 3, \'number_of_replicas\': 2 }})索引创建后,接下来是数据的操作接口。Elasticsearch提供了一系列的API来操作数据,包括索引文档、删除文档、更新文档等。以下是Python客户端对这些操作的接口示例:
# 索引(插入)一个文档document = { \'title\': \'Elasticsearch Basics\', \'content\': \'An introductory tutorial on Elasticsearch.\'}response = es.index(index=\"test-index\", id=1, document=document)# 更新文档response = es.update(index=\"test-index\", id=1, body={ \'doc\': {\'content\': \'Updated Elasticsearch tutorial.\'}})# 删除文档es.delete(index=\"test-index\", id=1)对于这些操作,Python客户端在方法调用完成后都会返回一个响应对象。开发者可以通过这个响应对象获取操作的结果,比如操作是否成功、文档的ID、版本信息等。
2.2 Elasticsearch的高级查询技巧
2.2.1 DSL查询语言基础
Elasticsearch使用了一种名为Domain Specific Language(DSL)的查询语言来构建复杂的查询。在Python客户端中,我们可以通过构建字典的方式传递DSL查询给Elasticsearch。
# 使用DSL进行搜索query = { \'query\': { \'match\': { \'title\': \'Elasticsearch\' } }}response = es.search(index=\"test-index\", body=query) 在上例中,我们构建了一个简单的 match 查询来搜索标题中包含”Elasticsearch”的文档。
2.2.2 聚合查询与数据分析实例
聚合查询是Elasticsearch强大的功能之一,它允许我们对数据进行分组、统计和分析。在Python客户端中,我们可以使用与构建搜索查询相似的方式来构建聚合查询。
# 使用聚合进行数据统计aggs_query = { \'aggs\': { \'categories\': { \'terms\': { \'field\': \'category.keyword\' } } }}response = es.search(index=\"test-index\", body=aggs_query) 在这个例子中,我们对一个名为 category 的字段进行了术语聚合,以统计不同类别的文档数量。
2.3 Elasticsearch的同步与异步交互模式
2.3.1 同步API的使用与效率分析
同步API是Elasticsearch默认的交互方式,它会在每次请求后等待响应再继续执行。这种模式简单直接,但在高并发环境下可能会导致线程阻塞。
# 使用同步API进行搜索response = es.search(index=\"test-index\", body=query)同步API在高并发或大体量数据的场景中可能会成为瓶颈,因为它会阻塞Python脚本的执行,等待Elasticsearch返回结果。
2.3.2 异步API的优势与应用场景
与同步API不同,异步API通过提供回调函数来避免阻塞。异步API在Elasticsearch较新版本中通过 async 关键字和 aiohttp 库实现。
import asyncioasync def async_search(): async with aiohttp.ClientSession() as session: response = await es.search_async(session=session, index=\"test-index\", body=query) print(response)# 使用Python的事件循环执行异步查询loop = asyncio.get_event_loop()loop.run_until_complete(async_search())异步API在处理大规模或高频率的查询时非常有用,例如在实时分析或大规模数据导入时。它允许其他操作在等待Elasticsearch响应的过程中继续运行,从而提高了整体的效率和响应速度。
在第二章中,我们学习了如何使用Python与Elasticsearch进行基础操作,包括安装与配置客户端、创建索引、执行基本的增删改查操作,以及利用高级查询技巧提升搜索的质量。接下来,我们将深入探讨如何利用异步API提高应用的交互效率,并探索如何使用嵌入向量技术在搜索中实现更为复杂的语义理解。通过这些知识和技能,开发者将能够构建更加高效和智能的搜索应用。
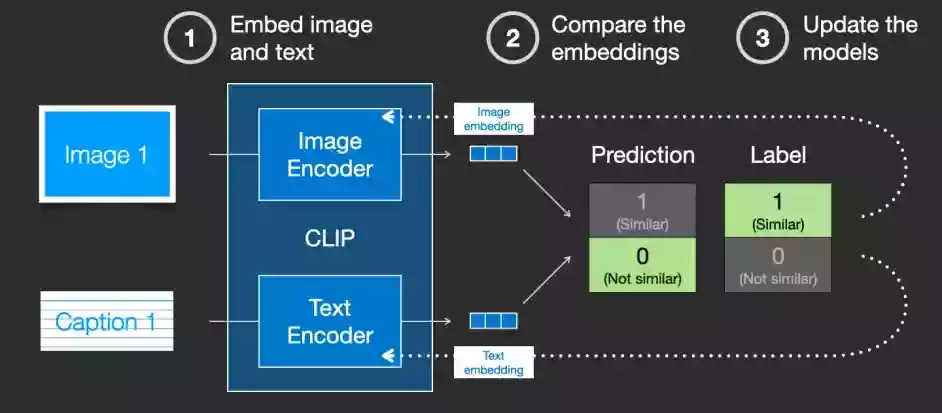
3. 嵌入向量技术在搜索中的应用
随着技术的发展,搜索引擎不再仅仅依靠关键词匹配来返回结果。用户期望搜索引擎能更准确地理解他们的查询意图,并提供更相关的结果。嵌入向量技术正是解决这一问题的关键。
3.1 嵌入向量技术概述
3.1.1 向量技术的起源与发展
向量技术最早应用于自然语言处理领域,其起源可以追溯到上世纪的分布式假设,即语义相似的词汇在文本中也往往会出现在相似的上下文中。这一假设被用来训练词向量模型,如Word2Vec和GloVe,它们能够捕捉词汇的语义信息。
随着时间的推移,向量技术已经从单个词汇的表示发展到能够捕捉整个句子甚至段落的复杂含义。Transformer架构的出现,尤其是BERT(Bidirectional Encoder Representations from Transformers)及其衍生模型,通过自注意力机制进一步提升了向量表示的质量。
3.1.2 嵌入向量在搜索中的角色与优势
嵌入向量技术在搜索引擎中的角色至关重要。它能够将文档、查询以及其他实体转换为高维空间中的向量表示,使得语义相近的向量彼此靠近。在搜索中,这意味着可以通过计算查询与文档向量之间的相似度来进行结果的排序,从而提供更加相关和精确的搜索结果。
嵌入向量技术的优势在于其能够在没有明确关键词匹配的情况下,通过向量间的数学距离来评估内容的相关性。这为处理同义词、语义搜索、个性化推荐等复杂场景提供了可能。
3.2 嵌入向量技术的实现方法
3.2.1 常见的向量嵌入模型
在实现向量嵌入时,开发者可以使用多种成熟的模型。例如,BERT、GPT(Generative Pretrained Transformer)、SimCLR(A Simple Framework for Contrastive Learning of Visual Representations)等。这些模型基于大量的数据进行预训练,能够学习到丰富的语义和视觉表示。
选择合适的模型对于最终的搜索质量至关重要。通常,需要根据应用的具体需求来选择预训练模型或定制训练。例如,如果搜索的主要内容为文本,那么BERT类的模型会是较好的选择;如果内容涉及图像或视频,那么可能需要使用像SimCLR这样的模型来捕捉视觉特征。
3.2.2 向量嵌入模型在实际应用中的调整与优化
在将向量嵌入技术应用于实际搜索引擎时,往往需要对预训练模型进行微调。微调可以通过在特定数据集上继续训练模型来实现,目的是让模型更好地适应搜索领域的特定语境和语言风格。
微调过程中,需要关注的优化指标包括但不限于:向量表示的准确性、搜索结果的相关性以及模型推理的速度。针对这些指标,开发者可以采取不同的策略,例如使用领域特定数据集进行额外的训练,或者使用量化技术来加速模型的推理过程。
下面是使用Python进行向量嵌入的一个简单示例:
from transformers import BertTokenizer, BertModelimport torch# 加载预训练模型和分词器tokenizer = BertTokenizer.from_pretrained(\'bert-base-uncased\')model = BertModel.from_pretrained(\'bert-base-uncased\')# 编码文本text = \"Replace me by any text you\'d like.\"encoded_input = tokenizer(text, return_tensors=\'pt\')# 通过模型获取嵌入向量with torch.no_grad(): output = model(**encoded_input)# 提取最后一层的输出last_hidden_states = output.last_hidden_state 在这个代码块中,我们首先导入了必要的库和预训练的模型及分词器。随后,我们将一段文本进行编码,并通过BERT模型获取其向量表示。 last_hidden_state 包含了文本的嵌入向量,这是进一步处理和分析的基础。
向量嵌入技术的应用正变得越来越广泛,为搜索引擎提供了更深入的理解用户查询意图的能力。这种能力对于提升用户体验,尤其是在复杂的语义搜索中,至关重要。随着技术的不断演进,我们可以期待未来的搜索引擎将更加智能和高效。
4. 点积和余弦相似度评分机制
4.1 点积相似度评分的原理与实践
4.1.1 点积评分机制的理论基础
在向量空间模型中,点积是一种用于衡量两个向量相似度的基本方法。点积的值越大,表示两个向量的方向越相似。点积评分机制的核心思想是:如果两个向量(代表两个文档或查询条件)的方向越接近,那么它们在向量空间中的夹角就越小,点积结果也就越大。
点积评分公式如下:
[ \\text{点积评分} = \\sum_{i=1}^{n} (向量A_i \\times 向量B_i) ]
其中,( 向量A_i ) 和 ( 向量B_i ) 是两个向量在第 i 个维度上的值,n 为维度总数。计算得到的结果是一个数值,它表示了两个向量的相似程度。
4.1.2 实现点积评分的方法与代码示例
为了具体展示如何实现点积评分,以下是一个用Python代码实现的简单例子:
def dot_product(vector_a, vector_b): \"\"\" 计算两个向量的点积 :param vector_a: 向量A :param vector_b: 向量B :return: 点积结果 \"\"\" return sum(a * b for a, b in zip(vector_a, vector_b))# 示例向量vector_a = [1, 2, 3]vector_b = [4, 5, 6]# 计算点积评分score = dot_product(vector_a, vector_b)print(f\"点积评分结果为: {score}\") 上述代码定义了一个 dot_product 函数,该函数接收两个列表类型的参数 vector_a 和 vector_b ,分别代表两个向量。通过 zip 函数将两个向量的对应元素配对,并对每对元素进行相乘,最后通过 sum 函数得到点积的结果。
4.1.3 点积评分的优缺点分析
点积评分的优点在于它的计算简单快速,尤其适合处理大量数据的场景。然而,点积评分也存在一些局限性。由于点积会受到向量长度的影响(长向量会导致评分值增大),因此它并不适用于标准化长度不一的向量。此外,点积评分无法区分不同维度的重要性,每个维度对于评分的贡献是均等的。
4.2 余弦相似度评分的原理与实践
4.2.1 余弦相似度评分机制的理论基础
余弦相似度评分机制是通过测量两个向量夹角的余弦值来衡量它们之间的相似度。它是一种非常有效的计算两个向量在方向上的相似性的方法,不受向量长度的影响。其公式如下:
[ \\text{余弦相似度} = \\frac{A \\cdot B}{|A| |B|} = \\frac{\\sum_{i=1}^{n} (向量A_i \\times 向量B_i)}{\\sqrt{\\sum_{i=1}^{n} (向量A_i)^2} \\sqrt{\\sum_{i=1}^{n} (向量B_i)^2}} ]
其中,( A \\cdot B ) 表示向量 A 和向量 B 的点积,(|A|) 和 (|B|) 分别表示向量 A 和向量 B 的欧几里得长度。通过这个公式,可以得到一个介于 -1 和 1 之间的值,这个值越接近 1,表示两个向量越相似。
4.2.2 实现余弦相似度评分的方法与代码示例
实现余弦相似度评分的Python代码如下:
import mathdef cosine_similarity(vector_a, vector_b): \"\"\" 计算两个向量的余弦相似度 :param vector_a: 向量A :param vector_b: 向量B :return: 余弦相似度结果 \"\"\" dot_prod = sum(a * b for a, b in zip(vector_a, vector_b)) norm_a = math.sqrt(sum(a**2 for a in vector_a)) norm_b = math.sqrt(sum(b**2 for b in vector_b)) return dot_prod / (norm_a * norm_b)vector_a = [1, 2, 3]vector_b = [4, 5, 6]similarity = cosine_similarity(vector_a, vector_b)print(f\"余弦相似度评分结果为: {similarity}\")在这段代码中,我们首先计算了向量的点积,然后分别计算了两个向量的欧几里得长度,最后通过点积除以两个向量长度的乘积来得到余弦相似度。
4.2.3 余弦相似度评分的适用场景
余弦相似度评分在处理具有不同大小和方向的向量时非常有用。由于它忽略了向量的大小,因此它特别适用于衡量文本、图片和任何其他类型的特征向量的相似度,这些向量的长度和单位可能因文档或数据集的不同而变化。然而,余弦相似度评分也有其局限性,比如它可能会放大稀疏向量中的噪声,因此在应用时需要根据实际情况进行适当的数据预处理。
5. 文档评分与排序
文档评分与排序是搜索引擎中极为重要的一个环节,它决定了用户在发起搜索查询后,哪些文档会被优先展示。Elasticsearch作为一款强大的搜索引擎,提供了灵活的评分机制和多样的排序选项。本章将深入探讨Elasticsearch的评分机制,以及如何利用向量相似度对搜索结果进行排序。
5.1 Elasticsearch的评分机制详解
评分机制是搜索引擎用于衡量搜索结果相关性的一种算法。了解评分机制的工作原理,可以帮助我们更好地优化搜索结果,提升用户体验。
5.1.1 Elasticsearch评分机制的工作原理
Elasticsearch使用一种称为TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文档频率)的算法作为默认的评分机制。TF-IDF算法通过分析文档中特定词语的出现频率,并结合该词语在所有文档中出现的频率,来评估词语的重要性。该算法的核心思想是,如果一个词语在一个文档中频繁出现,且在其他文档中出现次数很少,那么它很可能是该文档的一个重要关键词。
Elasticsearch中的评分计算公式可以概括为:
_score = ∑(TF(t in d) * IDF(t)^2 * fieldNorm(d))在这个公式中,TF(t in d) 表示词项在文档中的频率,IDF(t)^2 表示词项的逆文档频率的平方,而 fieldNorm(d) 是一个规范化的因子,用于调整字段长度对评分的影响。
5.1.2 自定义评分算法与应用场景
尽管TF-IDF提供了合理的默认评分算法,但在某些特定场景下,可能需要自定义评分逻辑以获得更相关的结果。Elasticsearch允许我们通过自定义脚本或评分查询来实现这一需求。
自定义评分可以基于多种因素,例如:
- 结合用户历史行为数据
- 根据文档的新鲜度打分
- 利用地理位置信息进行评分
例如,下面是一个简单的自定义脚本评分示例,该脚本将根据文档的创建日期(假设字段名为 created_at )来调整评分,使得较新的文档评分更高。
GET /_search{ \"query\": { \"function_score\": { \"query\": { \"match_all\": {} }, \"script_score\": { \"script\": \"1 / (1 + doc[\'created_at\'].value / params衰减因子)\" }, \"params\": { \"衰减因子\": \"3600000\" // 以毫秒为单位 } } }} 在这个脚本中,我们通过 script_score 方法使用了一个简单的衰减函数,其中 衰减因子 可以根据实际情况进行调整,以控制文档的新鲜度对评分的影响程度。
5.2 向量相似度在文档排序中的应用
在向量搜索的场景中,我们可以利用向量之间的相似度来进行文档排序。向量搜索一般涉及向量的嵌入表示和计算其相似度,例如使用余弦相似度或点积来衡量两个向量之间的相似性。
5.2.1 排序技术在搜索引擎中的重要性
排序技术对于搜索引擎而言至关重要,因为它决定了用户首先看到的内容。一个有效的排序算法能够确保用户获得最相关、最有价值的搜索结果。
5.2.2 利用向量相似度进行文档排序的实战分析
假设我们已经将一些文档的文本内容转化为向量,并存储在Elasticsearch的向量字段中。我们希望根据用户查询的向量与存储向量之间的相似度来进行排序。
Elasticsearch不直接支持向量字段的查询,因此我们需要借助插件或Elasticsearch 7.3及之后版本中引入的向量搜索功能。这里,我们利用Elasticsearch的向量搜索能力进行排序,使用 script_score 来计算向量之间的相似度。
以下是一个向量相似度排序的示例,我们使用了余弦相似度:
GET /_search{ \"size\": 10, \"query\": { \"match_all\": {} }, \"sort\": [ { \"_script\": { \"type\": \"number\", \"script\": { \"lang\": \"painless\", \"source\": \"cosineSimilarity(params.queryVector, doc[\'vector\'])\", \"params\": { \"queryVector\": [1.0, -0.2, 3.0, ...] // 用户查询向量 } }, \"order\": \"desc\" } } ]} 在这个查询中,我们首先使用了 match_all 查询来获取所有文档,然后通过 sort 部分中的 _script 来指定自定义的排序规则。 cosineSimilarity 函数用于计算两个向量的余弦相似度, queryVector 是我们根据当前查询生成的向量。结果将按照余弦相似度的逆序(从高到低)进行排序,从而实现向量相似度排序。
在实际应用中,向量的生成通常基于深度学习模型,例如使用词嵌入、BERT等预训练模型进行转换。这样的方法在处理自然语言问题时尤其有效,并且可以应用在诸如文档相似性搜索、推荐系统等多个场景中。
6. 向量数据预处理和存储
在构建高效的向量搜索系统时,数据预处理和存储是两个重要的环节。预处理的目的是提高数据的质量,保证查询时的准确性;而存储则是为了保证数据的可访问性和扩展性。接下来,我们将深入探讨向量数据的预处理流程和存储管理策略。
6.1 向量数据的预处理流程
预处理是确保搜索系统能够准确响应查询请求的关键步骤。它通常包括数据清洗、向量化、归一化和标准化等步骤。
6.1.1 数据清洗与向量化
在预处理的第一步,需要清洗原始数据以确保它们的质量。这个过程可能涉及到去除重复项、纠正错误和填补缺失值。例如,如果数据是文本形式的,那么可以通过自然语言处理技术进行清洗。
接下来是向量化步骤,即将非结构化数据(如文本、图片等)转换为向量表示。这一步通常涉及到使用机器学习模型,例如词嵌入模型如Word2Vec,或者通过训练深度学习模型来获得特征向量。
from gensim.models import Word2Vecfrom sklearn.feature_extraction.text import TfidfVectorizer# 示例:文本数据的向量化documents = [\"example text document 1\", \"example text document 2\", \"...\"]vectorizer = TfidfVectorizer()X = vectorizer.fit_transform(documents)6.1.2 数据归一化与标准化方法
为了减少不同尺度和量纲对搜索结果的影响,我们通常需要对特征向量进行归一化和标准化。归一化是将数据缩放到特定范围,而标准化则是将数据按比例缩放,使之具有单位方差。
from sklearn.preprocessing import StandardScaler, MinMaxScaler# 示例:数据标准化X_normalized = StandardScaler().fit_transform(X.toarray())# 示例:数据归一化X_minmax = MinMaxScaler().fit_transform(X.toarray())6.2 向量数据的存储与管理
预处理后的向量数据需要被存储在一个能够快速检索和高效管理的系统中。这通常涉及到选择合适的数据存储方案以及与Elasticsearch等搜索引擎的整合策略。
6.2.1 向量数据的存储方案比较
向量数据可以通过多种方式存储。传统的数据库可能不适合存储高维向量数据,因为它们查询效率低且难以进行高效的相似度搜索。近年来,出现了一些专为向量数据优化的存储系统,如Faiss、Annoy和Milvus。
6.2.2 向量数据库与Elasticsearch的整合策略
Elasticsearch是一个流行的大规模全文搜索引擎,它支持对文本数据的高效搜索。通过一些工具和策略,我们可以将向量数据以Elasticsearch中的向量字段形式存储,并利用其强大的搜索能力进行快速相似度搜索。
# 示例:Elasticsearch中嵌入向量字段的索引映射PUT my-index{ \"mappings\": { \"properties\": { \"my_vector\": { \"type\": \"dense_vector\", \"dims\": 256 } } }}通过上述整合策略,Elasticsearch可以用来检索与查询向量最相似的其他向量数据,这是通过向量搜索API实现的:
POST my-index/_search{ \"size\": 10, \"query\": { \"script_score\": { \"query\": { \"match_all\": {} }, \"script\": { \"source\": \"cosineSimilarity(params.queryVector, \'my_vector\') + 1.0\", \"params\": { \"queryVector\": query_vector } } } }}通过上述方法,我们可以将预处理后的向量数据存储在适合的数据库中,并利用Elasticsearch进行向量相似度的搜索查询。这为建立一个高效且准确的向量搜索引擎奠定了基础。
本文还有配套的精品资源,点击获取
简介:Elasticsearch是一个强大的分布式全文搜索引擎,广泛用于数据搜索和分析。结合Python,我们可以通过嵌入向量技术提高Elasticsearch的查询性能和结果的相关性。本插件利用机器学习中的向量概念,通过点积或余弦相似度对文档进行评分,从而改进传统的搜索方式。具体步骤包括数据预处理、存储向量、查询处理、相似度计算和结果排序。通过这样的技术集成,开发者可以提升数据检索的精度,并为用户提供更优的体验。
本文还有配套的精品资源,点击获取


