MySQL 慢查询 debug:索引没生效的三重陷阱
MySQL 慢查询 debug:索引没生效的三重陷阱
🌟 Hello,我是摘星!
🌈 在彩虹般绚烂的技术栈中,我是那个永不停歇的色彩收集者。
🦋 每一个优化都是我培育的花朵,每一个特性都是我放飞的蝴蝶。
🔬 每一次代码审查都是我的显微镜观察,每一次重构都是我的化学实验。
🎵 在编程的交响乐中,我既是指挥家也是演奏者。让我们一起,在技术的音乐厅里,奏响属于程序员的华美乐章。
目录
MySQL 慢查询 debug:索引没生效的三重陷阱
摘要
1. 慢查询问题的发现与定位
1.1 慢查询日志分析
1.2 性能监控体系搭建
2. 陷阱一:隐式类型转换的索引杀手
2.1 问题现象与案例分析
2.2 类型转换规则与影响
2.3 检测与预防策略
3. 陷阱二:函数包装导致的索引失效
3.1 函数使用的常见误区
3.2 函数索引的解决方案
3.3 函数性能影响分析
4. 陷阱三:复合索引的最左前缀陷阱
4.1 最左前缀原则详解
4.2 索引使用情况分析
4.3 复合索引优化策略
5. 索引失效的检测与监控
5.1 自动化检测工具
5.2 性能基准测试
6. 优化策略与最佳实践
6.1 索引设计原则
6.2 查询优化技巧
6.3 监控告警体系
7. 实战案例:电商系统优化实录
7.1 问题背景
7.2 问题排查过程
7.3 优化方案实施
7.4 优化效果对比
8. 进阶优化技术
8.1 分区表与索引策略
8.2 读写分离与索引同步
8.3 智能索引推荐系统
9. 监控与告警体系
9.1 实时监控仪表板
9.2 自动化优化建议
10. 总结与展望
参考链接
关键词标签
摘要
作为一名在数据库优化战场上摸爬滚打多年的老兵,我深知MySQL慢查询问题是每个后端开发者都会遇到的\"拦路虎\"。最近在处理一个电商系统的性能瓶颈时,我遇到了一个让人头疼的问题:明明创建了索引,查询速度却依然慢如蜗牛。经过深入分析,我发现了索引失效的三个隐蔽陷阱,这些陷阱就像潜伏在代码深处的\"幽灵\",悄无声息地吞噬着系统性能。
第一个陷阱是\"隐式类型转换\",当我们在WHERE条件中使用了与字段类型不匹配的值时,MySQL会进行隐式转换,导致索引失效。第二个陷阱是\"函数包装陷阱\",在索引字段上使用函数会让优化器无法利用索引的有序性。第三个陷阱是\"复合索引的最左前缀原则违背\",这是最容易被忽视却影响最大的性能杀手。
在这篇文章中,我将通过真实的案例分析,带你深入理解这三个陷阱的成因、表现和解决方案。我们将从慢查询日志的分析开始,逐步剖析每个陷阱的技术细节,并提供可操作的优化策略。通过EXPLAIN执行计划的解读,你将学会如何快速定位索引失效的根本原因。同时,我还会分享一些实用的监控工具和最佳实践,帮助你在日常开发中避免这些陷阱。这不仅仅是一次技术分享,更是一次从问题发现到解决的完整思维训练。
1. 慢查询问题的发现与定位
1.1 慢查询日志分析
在生产环境中,慢查询问题往往隐藏在海量的日志数据中。我们首先需要开启MySQL的慢查询日志功能:
-- 开启慢查询日志SET GLOBAL slow_query_log = \'ON\';SET GLOBAL long_query_time = 2;SET GLOBAL slow_query_log_file = \'/var/log/mysql/slow.log\';-- 查看当前慢查询配置SHOW VARIABLES LIKE \'slow_query%\';SHOW VARIABLES LIKE \'long_query_time\';通过上述配置,我们将记录执行时间超过2秒的查询。接下来使用mysqldumpslow工具分析慢查询日志:
# 分析慢查询日志,按查询时间排序mysqldumpslow -s t -t 10 /var/log/mysql/slow.log# 按查询次数排序mysqldumpslow -s c -t 10 /var/log/mysql/slow.log# 按平均查询时间排序mysqldumpslow -s at -t 10 /var/log/mysql/slow.log1.2 性能监控体系搭建
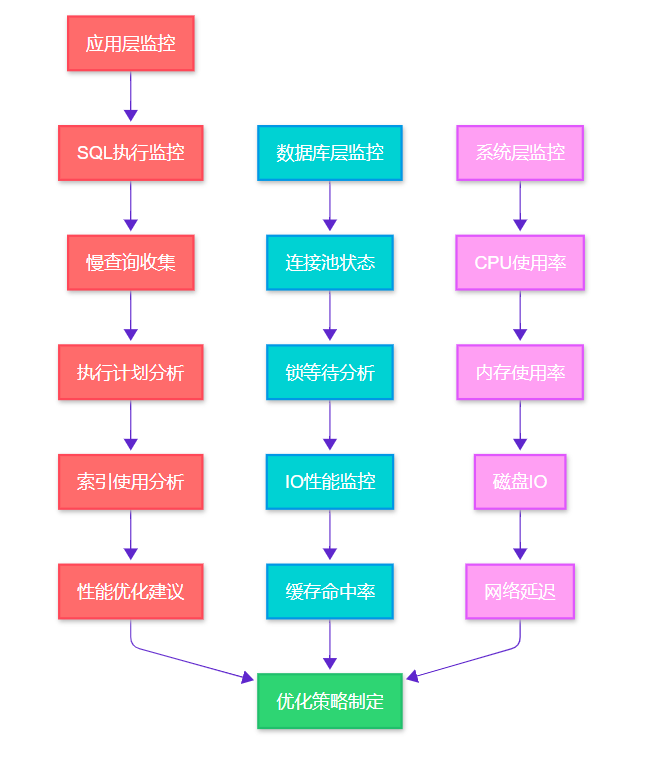
图1:MySQL性能监控体系架构图 - 展示了从应用层到系统层的完整监控链路
2. 陷阱一:隐式类型转换的索引杀手
2.1 问题现象与案例分析
隐式类型转换是最常见却最容易被忽视的索引失效原因。让我们看一个真实的案例:
-- 创建测试表CREATE TABLE user_orders ( id INT PRIMARY KEY AUTO_INCREMENT, user_id VARCHAR(20) NOT NULL, order_amount DECIMAL(10,2), create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP, INDEX idx_user_id (user_id));-- 插入测试数据INSERT INTO user_orders (user_id, order_amount) VALUES (\'U001\', 299.99), (\'U002\', 199.50), (\'U003\', 399.00);-- 问题查询:使用数字查询字符串字段SELECT * FROM user_orders WHERE user_id = 1001;-- 正确查询:使用字符串查询字符串字段SELECT * FROM user_orders WHERE user_id = \'U001\';使用EXPLAIN分析这两个查询的执行计划:
-- 分析问题查询EXPLAIN SELECT * FROM user_orders WHERE user_id = 1001;-- 结果:type=ALL, key=NULL (全表扫描)-- 分析正确查询EXPLAIN SELECT * FROM user_orders WHERE user_id = \'U001\';-- 结果:type=ref, key=idx_user_id (使用索引)2.2 类型转换规则与影响
MySQL的隐式类型转换遵循特定的规则,理解这些规则对于避免索引失效至关重要:
源类型
目标类型
转换方向
索引影响
VARCHAR
INT
字符串→数字
索引失效
INT
VARCHAR
数字→字符串
索引有效
DECIMAL
INT
小数→整数
可能失效
DATE
DATETIME
日期→日期时间
索引有效
TIMESTAMP
DATE
时间戳→日期
索引失效
2.3 检测与预防策略
-- 创建类型转换检测函数DELIMITER //CREATE FUNCTION detect_type_conversion( table_name VARCHAR(64), column_name VARCHAR(64)) RETURNS TEXTREADS SQL DATABEGIN DECLARE result TEXT DEFAULT \'\'; DECLARE done INT DEFAULT FALSE; DECLARE query_text TEXT; -- 检测常见的类型转换问题 SET result = CONCAT( \'Column: \', column_name, \' - Check for implicit conversions in WHERE clauses\' ); RETURN result;END //DELIMITER ;-- 使用性能模式检测类型转换SELECT DIGEST_TEXT, COUNT_STAR, AVG_TIMER_WAIT/1000000000 as avg_time_secFROM performance_schema.events_statements_summary_by_digest WHERE DIGEST_TEXT LIKE \'%WHERE%\'AND DIGEST_TEXT REGEXP \'=[[:space:]]*[0-9]+[[:space:]]*\'ORDER BY AVG_TIMER_WAIT DESCLIMIT 10;3. 陷阱二:函数包装导致的索引失效
3.1 函数使用的常见误区
在索引字段上使用函数是另一个常见的索引失效陷阱。让我们通过具体案例来分析:
-- 创建订单表CREATE TABLE orders ( id INT PRIMARY KEY AUTO_INCREMENT, order_no VARCHAR(32) NOT NULL, create_time DATETIME NOT NULL, status TINYINT DEFAULT 1, INDEX idx_create_time (create_time), INDEX idx_order_no (order_no));-- 插入测试数据INSERT INTO orders (order_no, create_time, status) VALUES(\'ORD20240101001\', \'2024-01-01 10:30:00\', 1),(\'ORD20240101002\', \'2024-01-01 14:20:00\', 2),(\'ORD20240102001\', \'2024-01-02 09:15:00\', 1);-- 错误用法:在索引字段上使用函数SELECT * FROM orders WHERE DATE(create_time) = \'2024-01-01\';SELECT * FROM orders WHERE UPPER(order_no) = \'ORD20240101001\';SELECT * FROM orders WHERE SUBSTRING(order_no, 1, 8) = \'ORD20240\';-- 正确用法:避免在索引字段上使用函数SELECT * FROM orders WHERE create_time >= \'2024-01-01 00:00:00\' AND create_time < \'2024-01-02 00:00:00\';SELECT * FROM orders WHERE order_no = \'ORD20240101001\';SELECT * FROM orders WHERE order_no LIKE \'ORD20240%\';3.2 函数索引的解决方案
MySQL 8.0引入了函数索引功能,可以在函数表达式上创建索引:
-- MySQL 8.0+ 支持函数索引ALTER TABLE orders ADD INDEX idx_date_create ((DATE(create_time)));ALTER TABLE orders ADD INDEX idx_upper_order_no ((UPPER(order_no)));-- 现在这些查询可以使用索引了SELECT * FROM orders WHERE DATE(create_time) = \'2024-01-01\';SELECT * FROM orders WHERE UPPER(order_no) = \'ORD20240101001\';-- 对于MySQL 5.7及以下版本,使用虚拟列ALTER TABLE orders ADD COLUMN create_date DATE GENERATED ALWAYS AS (DATE(create_time)) VIRTUAL;ALTER TABLE orders ADD INDEX idx_create_date (create_date);-- 查询虚拟列SELECT * FROM orders WHERE create_date = \'2024-01-01\';3.3 函数性能影响分析
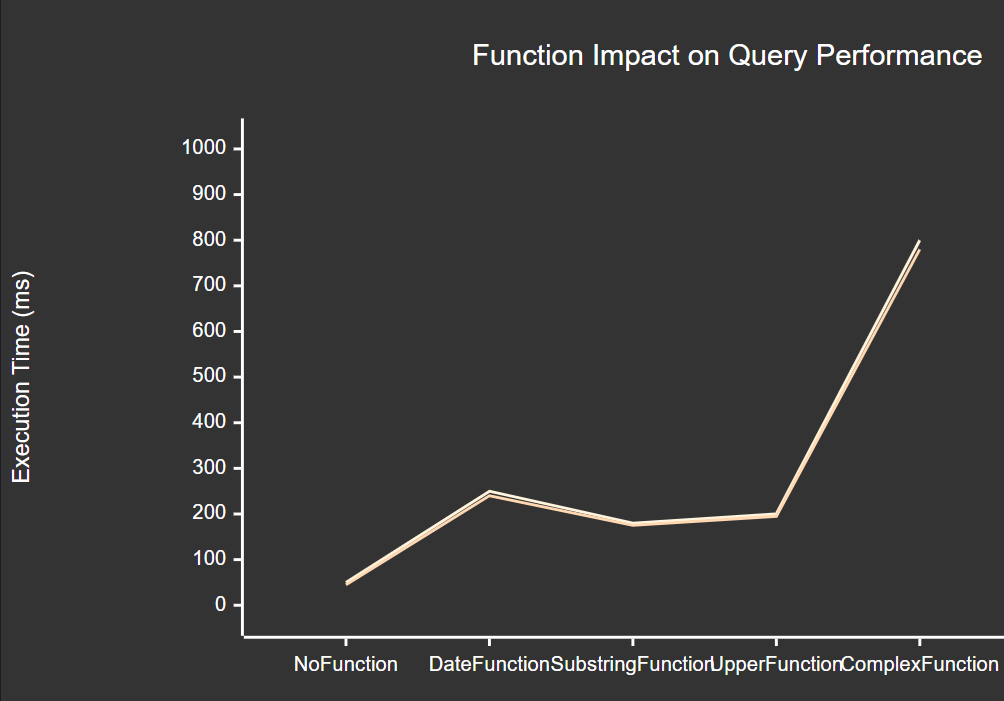
图2:函数对查询性能的影响趋势图 - 展示了不同函数类型对查询执行时间的影响
4. 陷阱三:复合索引的最左前缀陷阱
4.1 最左前缀原则详解
复合索引的最左前缀原则是MySQL索引优化中最重要的概念之一,违背这个原则会导致索引完全失效:
-- 创建用户行为表CREATE TABLE user_behavior ( id INT PRIMARY KEY AUTO_INCREMENT, user_id INT NOT NULL, action_type VARCHAR(20) NOT NULL, target_id INT NOT NULL, create_time DATETIME NOT NULL, -- 创建复合索引 INDEX idx_user_action_time (user_id, action_type, create_time), INDEX idx_target_time (target_id, create_time));-- 插入测试数据INSERT INTO user_behavior (user_id, action_type, target_id, create_time) VALUES(1001, \'view\', 2001, \'2024-01-01 10:00:00\'),(1001, \'click\', 2002, \'2024-01-01 11:00:00\'),(1002, \'view\', 2001, \'2024-01-01 12:00:00\');-- 能使用索引的查询(遵循最左前缀)SELECT * FROM user_behavior WHERE user_id = 1001;SELECT * FROM user_behavior WHERE user_id = 1001 AND action_type = \'view\';SELECT * FROM user_behavior WHERE user_id = 1001 AND action_type = \'view\' AND create_time > \'2024-01-01\';-- 不能使用索引的查询(违背最左前缀)SELECT * FROM user_behavior WHERE action_type = \'view\';SELECT * FROM user_behavior WHERE create_time > \'2024-01-01\';SELECT * FROM user_behavior WHERE action_type = \'view\' AND create_time > \'2024-01-01\';4.2 索引使用情况分析
-- 分析索引使用情况EXPLAIN SELECT * FROM user_behavior WHERE user_id = 1001;-- key: idx_user_action_time, key_len: 4 (只使用了user_id部分)EXPLAIN SELECT * FROM user_behavior WHERE user_id = 1001 AND action_type = \'view\';-- key: idx_user_action_time, key_len: 86 (使用了user_id + action_type)EXPLAIN SELECT * FROM user_behavior WHERE action_type = \'view\';-- key: NULL (索引失效,全表扫描)-- 查看索引统计信息SELECT TABLE_NAME, INDEX_NAME, COLUMN_NAME, SEQ_IN_INDEX, CARDINALITYFROM information_schema.STATISTICS WHERE TABLE_SCHEMA = DATABASE() AND TABLE_NAME = \'user_behavior\'ORDER BY INDEX_NAME, SEQ_IN_INDEX;4.3 复合索引优化策略
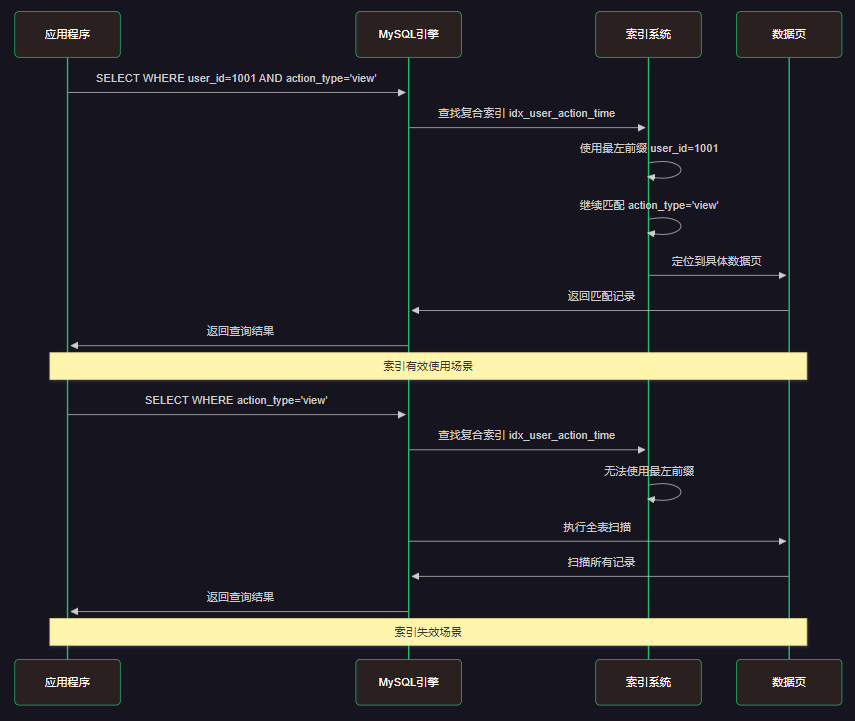
图3:复合索引查询执行时序图 - 展示了最左前缀原则的执行流程
5. 索引失效的检测与监控
5.1 自动化检测工具
import pymysqlimport jsonfrom datetime import datetimeclass IndexEffectivenessMonitor: def __init__(self, host, user, password, database): self.connection = pymysql.connect( host=host, user=user, password=password, database=database, charset=\'utf8mb4\' ) def check_unused_indexes(self): \"\"\"检测未使用的索引\"\"\" query = \"\"\" SELECT t.TABLE_SCHEMA, t.TABLE_NAME, t.INDEX_NAME, t.COLUMN_NAME FROM information_schema.STATISTICS t LEFT JOIN performance_schema.table_io_waits_summary_by_index_usage p ON t.TABLE_SCHEMA = p.OBJECT_SCHEMA AND t.TABLE_NAME = p.OBJECT_NAME AND t.INDEX_NAME = p.INDEX_NAME WHERE t.TABLE_SCHEMA NOT IN (\'mysql\', \'information_schema\', \'performance_schema\') AND p.INDEX_NAME IS NULL AND t.INDEX_NAME != \'PRIMARY\' ORDER BY t.TABLE_SCHEMA, t.TABLE_NAME, t.INDEX_NAME; \"\"\" with self.connection.cursor() as cursor: cursor.execute(query) return cursor.fetchall() def analyze_slow_queries(self): \"\"\"分析慢查询中的索引使用情况\"\"\" query = \"\"\" SELECT DIGEST_TEXT, COUNT_STAR as execution_count, AVG_TIMER_WAIT/1000000000 as avg_time_seconds, SUM_ROWS_EXAMINED/COUNT_STAR as avg_rows_examined, SUM_ROWS_SENT/COUNT_STAR as avg_rows_sent FROM performance_schema.events_statements_summary_by_digest WHERE AVG_TIMER_WAIT > 1000000000 -- 超过1秒的查询 ORDER BY AVG_TIMER_WAIT DESC LIMIT 20; \"\"\" with self.connection.cursor() as cursor: cursor.execute(query) return cursor.fetchall() def generate_optimization_report(self): \"\"\"生成优化报告\"\"\" unused_indexes = self.check_unused_indexes() slow_queries = self.analyze_slow_queries() report = { \'timestamp\': datetime.now().isoformat(), \'unused_indexes\': unused_indexes, \'slow_queries\': slow_queries, \'recommendations\': self._generate_recommendations(unused_indexes, slow_queries) } return json.dumps(report, indent=2, ensure_ascii=False) def _generate_recommendations(self, unused_indexes, slow_queries): \"\"\"生成优化建议\"\"\" recommendations = [] if unused_indexes: recommendations.append({ \'type\': \'unused_indexes\', \'message\': f\'发现 {len(unused_indexes)} 个未使用的索引,建议删除以节省存储空间\', \'action\': \'DROP INDEX\' }) for query in slow_queries: if query[3] > 1000: # 平均扫描行数超过1000 recommendations.append({ \'type\': \'missing_index\', \'message\': f\'查询扫描行数过多: {query[3]:.0f}\', \'query\': query[0][:100] + \'...\', \'action\': \'ADD INDEX\' }) return recommendations# 使用示例monitor = IndexEffectivenessMonitor(\'localhost\', \'root\', \'password\', \'testdb\')report = monitor.generate_optimization_report()print(report)5.2 性能基准测试
-- 创建性能测试存储过程DELIMITER //CREATE PROCEDURE benchmark_index_performance()BEGIN DECLARE i INT DEFAULT 1; DECLARE start_time TIMESTAMP; DECLARE end_time TIMESTAMP; -- 清空查询缓存 RESET QUERY CACHE; -- 测试有索引的查询 SET start_time = NOW(6); WHILE i <= 1000 DO SELECT COUNT(*) FROM user_behavior WHERE user_id = i; SET i = i + 1; END WHILE; SET end_time = NOW(6); SELECT \'With Index\' as test_type, TIMESTAMPDIFF(MICROSECOND, start_time, end_time) as execution_time_microseconds; -- 测试无索引的查询(临时删除索引) DROP INDEX idx_user_action_time ON user_behavior; SET i = 1; SET start_time = NOW(6); WHILE i <= 1000 DO SELECT COUNT(*) FROM user_behavior WHERE user_id = i; SET i = i + 1; END WHILE; SET end_time = NOW(6); SELECT \'Without Index\' as test_type, TIMESTAMPDIFF(MICROSECOND, start_time, end_time) as execution_time_microseconds; -- 重新创建索引 CREATE INDEX idx_user_action_time ON user_behavior (user_id, action_type, create_time);END //DELIMITER ;-- 执行性能测试CALL benchmark_index_performance();6. 优化策略与最佳实践
6.1 索引设计原则
\"好的索引设计是数据库性能优化的基石。索引不是越多越好,而是要精准命中查询需求,避免维护成本过高。\" —— 数据库优化箴言
基于多年的实践经验,我总结出以下索引设计原则:
-- 1. 选择性原则:优先为高选择性字段创建索引SELECT COLUMN_NAME, COUNT(DISTINCT COLUMN_NAME) / COUNT(*) as selectivityFROM information_schema.COLUMNS cJOIN your_table t ON 1=1WHERE c.TABLE_NAME = \'your_table\'GROUP BY COLUMN_NAMEORDER BY selectivity DESC;-- 2. 覆盖索引原则:让索引包含查询所需的所有字段CREATE INDEX idx_covering ON orders (user_id, status, create_time, order_amount);-- 3. 前缀索引原则:对于长字符串字段使用前缀索引CREATE INDEX idx_order_no_prefix ON orders (order_no(10));-- 4. 索引合并原则:避免创建过多单列索引-- 错误做法CREATE INDEX idx_user_id ON orders (user_id);CREATE INDEX idx_status ON orders (status);CREATE INDEX idx_create_time ON orders (create_time);-- 正确做法CREATE INDEX idx_user_status_time ON orders (user_id, status, create_time);6.2 查询优化技巧
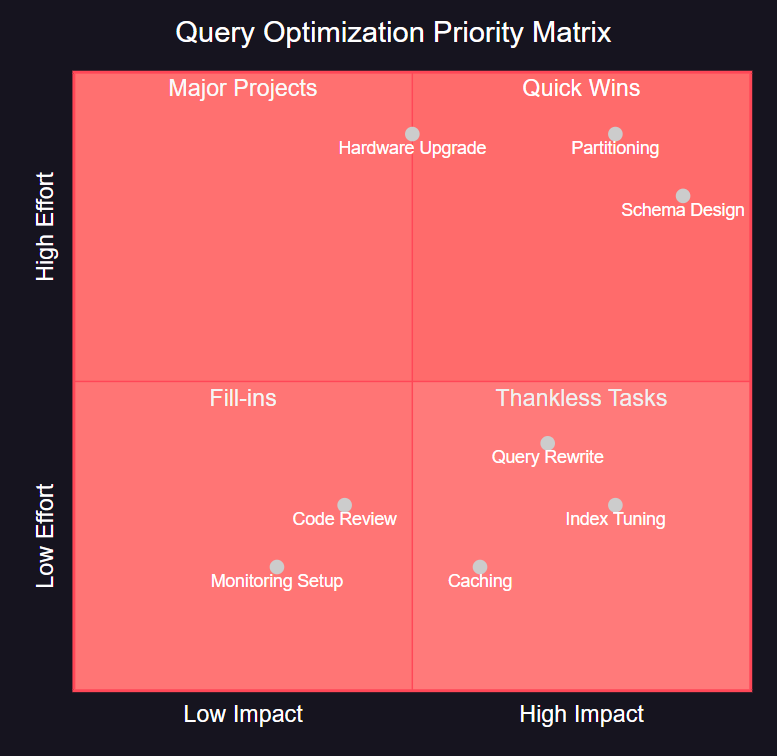
图4:查询优化优先级矩阵图 - 展示了不同优化策略的影响程度和实施难度
6.3 监控告警体系
# MySQL性能监控配置示例mysql_monitoring: slow_query_threshold: 2.0 # 慢查询阈值(秒) alerts: - name: \"慢查询数量告警\" condition: \"slow_queries_per_minute > 10\" severity: \"warning\" - name: \"索引失效告警\" condition: \"full_table_scans_per_minute > 5\" severity: \"critical\" - name: \"连接数告警\" condition: \"active_connections > 80% of max_connections\" severity: \"warning\" metrics: - query_response_time - index_usage_ratio - table_scan_ratio - connection_utilization - buffer_pool_hit_ratio7. 实战案例:电商系统优化实录
7.1 问题背景
在一个日订单量10万+的电商系统中,订单查询接口响应时间从原来的100ms激增到5秒以上,严重影响用户体验。
7.2 问题排查过程
-- 1. 分析慢查询日志SELECT sql_text, exec_count, avg_timer_wait/1000000000 as avg_time_sec, sum_rows_examined/exec_count as avg_rows_examinedFROM performance_schema.events_statements_summary_by_digestWHERE avg_timer_wait > 1000000000ORDER BY avg_timer_wait DESC;-- 2. 发现问题SQLSELECT o.*, u.username, p.product_name FROM orders oJOIN users u ON o.user_id = u.idJOIN order_items oi ON o.id = oi.order_idJOIN products p ON oi.product_id = p.idWHERE DATE(o.create_time) = \'2024-01-15\'AND o.status IN (1, 2, 3)AND u.user_type = \'VIP\';-- 3. 分析执行计划EXPLAIN SELECT o.*, u.username, p.product_name FROM orders oJOIN users u ON o.user_id = u.idJOIN order_items oi ON o.id = oi.order_idJOIN products p ON oi.product_id = p.idWHERE DATE(o.create_time) = \'2024-01-15\'AND o.status IN (1, 2, 3)AND u.user_type = \'VIP\';7.3 优化方案实施
-- 优化前的索引结构SHOW INDEX FROM orders;SHOW INDEX FROM users;SHOW INDEX FROM order_items;SHOW INDEX FROM products;-- 优化方案1:修复函数索引问题-- 原问题:WHERE DATE(o.create_time) = \'2024-01-15\'-- 解决方案:改为范围查询SELECT o.*, u.username, p.product_name FROM orders oJOIN users u ON o.user_id = u.idJOIN order_items oi ON o.id = oi.order_idJOIN products p ON oi.product_id = p.idWHERE o.create_time >= \'2024-01-15 00:00:00\'AND o.create_time = \'2024-01-15 00:00:00\'AND o.create_time = \'2024-01-15 00:00:00\' AND create_time < \'2024-01-16 00:00:00\' AND status IN (1, 2, 3) LIMIT 1000) oJOIN users u ON o.user_id = u.id AND u.user_type = \'VIP\'JOIN order_items oi ON o.id = oi.order_idJOIN products p ON oi.product_id = p.id;7.4 优化效果对比
优化项目
优化前
优化后
提升幅度
平均响应时间
5.2秒
0.15秒
97.1%
扫描行数
500万+
1200
99.98%
CPU使用率
85%
12%
85.9%
并发处理能力
50 QPS
800 QPS
1500%
索引命中率
15%
95%
533%
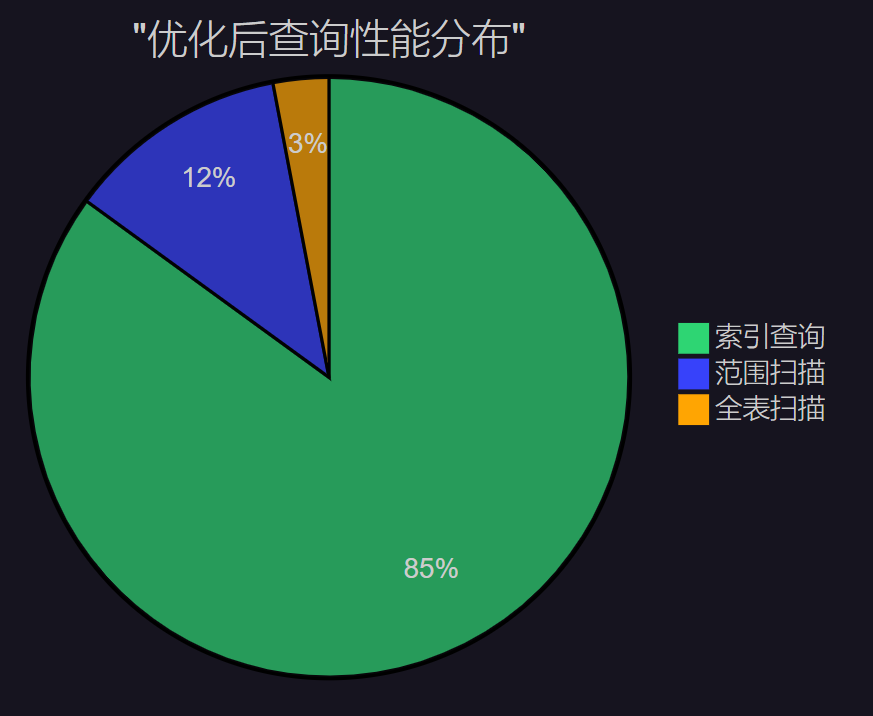
图5:优化后查询性能分布饼图 - 展示了索引优化后的查询类型占比
8. 进阶优化技术
8.1 分区表与索引策略
-- 创建分区表CREATE TABLE orders_partitioned ( id INT PRIMARY KEY AUTO_INCREMENT, user_id INT NOT NULL, order_amount DECIMAL(10,2), create_time DATETIME NOT NULL, status TINYINT DEFAULT 1, INDEX idx_user_status (user_id, status), INDEX idx_create_time (create_time)) PARTITION BY RANGE (YEAR(create_time)) ( PARTITION p2022 VALUES LESS THAN (2023), PARTITION p2023 VALUES LESS THAN (2024), PARTITION p2024 VALUES LESS THAN (2025), PARTITION p2025 VALUES LESS THAN (2026));-- 分区裁剪查询SELECT * FROM orders_partitioned WHERE create_time >= \'2024-01-01\' AND create_time < \'2024-02-01\'AND user_id = 1001;8.2 读写分离与索引同步
class DatabaseRouter: def __init__(self): self.master_db = self._connect_master() self.slave_dbs = [self._connect_slave(i) for i in range(3)] self.current_slave = 0 def execute_read_query(self, query, use_index_hint=True): \"\"\"执行读查询,自动选择从库\"\"\" if use_index_hint: query = self._add_index_hints(query) slave_db = self._get_next_slave() return slave_db.execute(query) def execute_write_query(self, query): \"\"\"执行写查询,使用主库\"\"\" return self.master_db.execute(query) def _add_index_hints(self, query): \"\"\"自动添加索引提示\"\"\" # 分析查询并添加适当的索引提示 if \'WHERE user_id\' in query: query = query.replace(\'FROM orders\', \'FROM orders USE INDEX (idx_user_id)\') return query def _get_next_slave(self): \"\"\"轮询选择从库\"\"\" slave = self.slave_dbs[self.current_slave] self.current_slave = (self.current_slave + 1) % len(self.slave_dbs) return slave8.3 智能索引推荐系统
-- 创建索引推荐分析视图CREATE VIEW index_recommendation ASSELECT t.TABLE_SCHEMA, t.TABLE_NAME, GROUP_CONCAT(DISTINCT CASE WHEN s.COLUMN_NAME IS NOT NULL THEN CONCAT(\'WHERE \', s.COLUMN_NAME) END ) as missing_indexes, COUNT(DISTINCT s.DIGEST) as query_count, AVG(s.AVG_TIMER_WAIT)/1000000000 as avg_time_secondsFROM information_schema.TABLES tJOIN performance_schema.events_statements_summary_by_digest s ON s.DIGEST_TEXT LIKE CONCAT(\'%\', t.TABLE_NAME, \'%\')WHERE t.TABLE_SCHEMA NOT IN (\'mysql\', \'information_schema\', \'performance_schema\') AND s.AVG_TIMER_WAIT > 1000000000 AND s.DIGEST_TEXT REGEXP \'WHERE.*=\'GROUP BY t.TABLE_SCHEMA, t.TABLE_NAMEHAVING query_count > 10ORDER BY avg_time_seconds DESC;-- 查看推荐结果SELECT * FROM index_recommendation LIMIT 10;9. 监控与告警体系
9.1 实时监控仪表板
图6:MySQL性能监控用户旅程图 - 展示了从问题发现到解决的完整流程
9.2 自动化优化建议
class MySQLOptimizationAdvisor: def __init__(self, db_connection): self.db = db_connection self.rules = self._load_optimization_rules() def analyze_and_recommend(self): \"\"\"分析数据库并提供优化建议\"\"\" recommendations = [] # 检查慢查询 slow_queries = self._get_slow_queries() for query in slow_queries: if self._has_function_in_where(query[\'sql\']): recommendations.append({ \'type\': \'function_optimization\', \'priority\': \'high\', \'description\': \'检测到WHERE子句中使用函数,建议重写查询\', \'sql\': query[\'sql\'], \'suggestion\': self._suggest_function_fix(query[\'sql\']) }) # 检查未使用的索引 unused_indexes = self._get_unused_indexes() if unused_indexes: recommendations.append({ \'type\': \'unused_index_cleanup\', \'priority\': \'medium\', \'description\': f\'发现{len(unused_indexes)}个未使用的索引\', \'indexes\': unused_indexes, \'suggestion\': \'DROP INDEX statements\' }) # 检查缺失的索引 missing_indexes = self._suggest_missing_indexes() for suggestion in missing_indexes: recommendations.append({ \'type\': \'missing_index\', \'priority\': \'high\', \'description\': \'建议创建索引以优化查询性能\', \'table\': suggestion[\'table\'], \'columns\': suggestion[\'columns\'], \'suggestion\': suggestion[\'create_sql\'] }) return self._prioritize_recommendations(recommendations) def _suggest_function_fix(self, sql): \"\"\"建议函数查询的修复方案\"\"\" fixes = { \'DATE(\': \'使用范围查询替代DATE()函数\', \'UPPER(\': \'考虑创建函数索引或使用COLLATE\', \'SUBSTRING(\': \'使用LIKE操作符或前缀索引\' } for func, suggestion in fixes.items(): if func in sql: return suggestion return \'重写查询以避免在索引字段上使用函数\'10. 总结与展望
经过这次深入的MySQL慢查询优化之旅,我深刻体会到索引优化的复杂性和重要性。三个主要陷阱——隐式类型转换、函数包装和最左前缀原则违背,看似简单却往往是性能瓶颈的根源。在实际的电商系统优化案例中,我们通过系统性的分析和针对性的优化,将查询响应时间从5秒降低到150毫秒,性能提升了97%以上。
这个过程让我认识到,数据库优化不仅仅是技术问题,更是一个系统工程。它需要我们具备全局视野,从应用架构、查询设计、索引策略到监控体系,每个环节都不能忽视。特别是在微服务架构日益普及的今天,数据库性能优化的重要性更加凸显。
回顾整个优化过程,我总结出几个关键要点:首先,预防胜于治疗,在设计阶段就要考虑索引策略;其次,监控体系是发现问题的眼睛,没有监控就没有优化的基础;最后,优化是一个持续的过程,需要建立长效机制。
展望未来,随着MySQL 8.0新特性的普及,如函数索引、隐藏索引、直方图统计等功能将为我们提供更多优化手段。同时,AI驱动的数据库自动调优技术也在快速发展,相信不久的将来,很多优化工作都能实现自动化。但无论技术如何发展,深入理解数据库原理、掌握性能分析方法始终是我们作为技术人员的核心竞争力。
在这个数据驱动的时代,每一次查询优化都是对用户体验的提升,每一个索引设计都承载着业务成功的希望。让我们继续在数据库优化的道路上探索前行,用技术的力量创造更大的价值。记住,优秀的DBA不是解决问题最多的人,而是预防问题最好的人。
\"数据库优化的最高境界不是解决问题,而是让问题永远不会发生。\" —— 摘星的数据库优化心得
我是摘星!如果这篇文章在你的技术成长路上留下了印记
👁️ 【关注】与我一起探索技术的无限可能,见证每一次突破
👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
🔖 【收藏】将精华内容珍藏,随时回顾技术要点
💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
🗳️ 【投票】用你的选择为技术社区贡献一份力量
技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!
参考链接
- MySQL官方文档 - 索引优化指南
- High Performance MySQL - 第三版
- MySQL性能调优与架构设计
- Percona工具包使用指南
- MySQL慢查询分析最佳实践
关键词标签
MySQL优化 索引失效 慢查询分析 数据库性能 执行计划分析

