基于 Python + Tkinter + DrissionPage 的抖音数据爬取图形化工具开发一、项目背景在数据分析、短视频研究等场景中,常常需要获取抖音平台的视频数据,如视频作者信息、点赞评_python tkinter 抖音
一、项目背景
在数据分析、短视频研究等场景中,常常需要获取抖音平台的视频数据,如视频作者信息、点赞评论数等。为了更便捷地采集数据,摆脱命令行操作的繁琐,我们开发了这款带有图形化界面(GUI)的抖音数据爬取工具,让用户能通过直观的界面输入关键词、控制爬取流程。
二、技术选型
1. 语言与核心库
- Python:作为当下热门的编程语言,拥有丰富的第三方库资源,便于快速开发各类应用。
- Tkinter:Python 内置的 GUI 开发库,无需额外安装,能轻松创建基础图形界面,满足简单交互需求 。
- DrissionPage:一个强大的网页自动化工具,可模拟浏览器操作,方便我们监听网络请求、获取页面数据,简化了与抖音网页端的数据交互过程 。
- csv:Python 标准库,用于处理 CSV 文件,实现数据的存储。
- threading:用于多线程处理,避免爬取数据时界面冻结,提升用户体验。
2. 选择原因
- Tkinter 属于 Python 标配,学习成本低,适合快速搭建轻量级 GUI;DrissionPage 对浏览器操作的封装简洁高效,能便捷获取抖音页面数据,二者结合可快速实现 “图形界面 + 数据爬取” 的完整流程,满足项目需求。
三、功能设计
1. 界面布局
- 顶部区域:包含关键词输入框(用于填写抖音搜索关键词)、最大爬取页数输入框(设定爬取的页面数量上限),以及 “开始爬取”“停止爬取” 按钮,控制爬取流程。
- 中间区域:滚动文本框,实时显示爬取状态、错误信息、已爬取数据详情等,让用户了解爬取进度。
- 底部区域:状态栏,简洁展示当前工具的整体状态(如 “就绪”“正在爬取” 等 )。
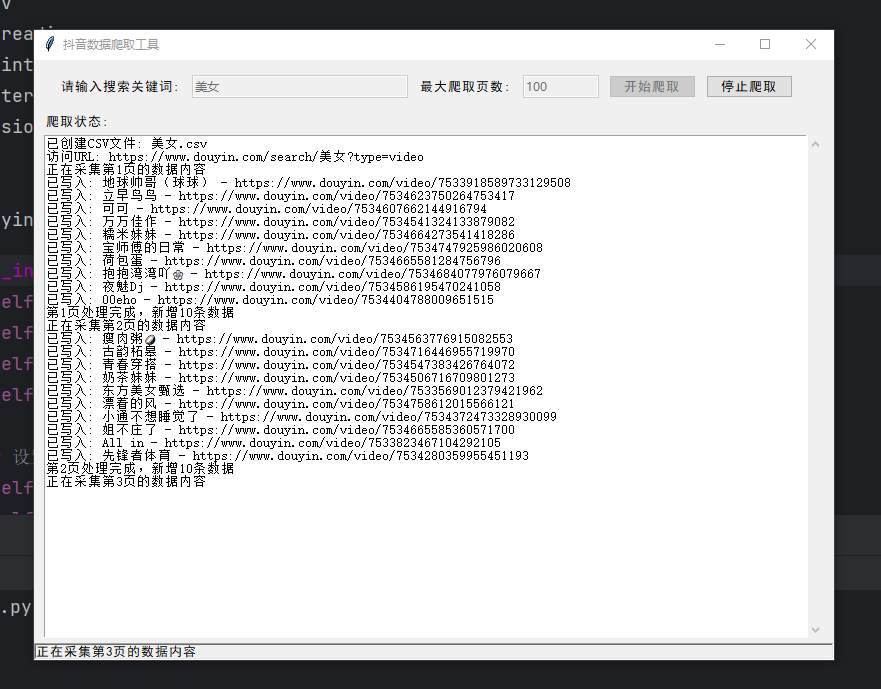
2. 核心功能
- 数据爬取:输入关键词后,程序模拟浏览器访问抖音搜索页面,滚动加载更多内容,监听并解析网络请求中的视频数据,提取作者信息、视频点赞数等字段。
- 数据存储:将爬取到的有效数据写入 CSV 文件,方便后续数据分析。
- 流程控制:支持 “开始爬取” 启动任务,“停止爬取” 随时中断任务,避免无效爬取,节省资源。
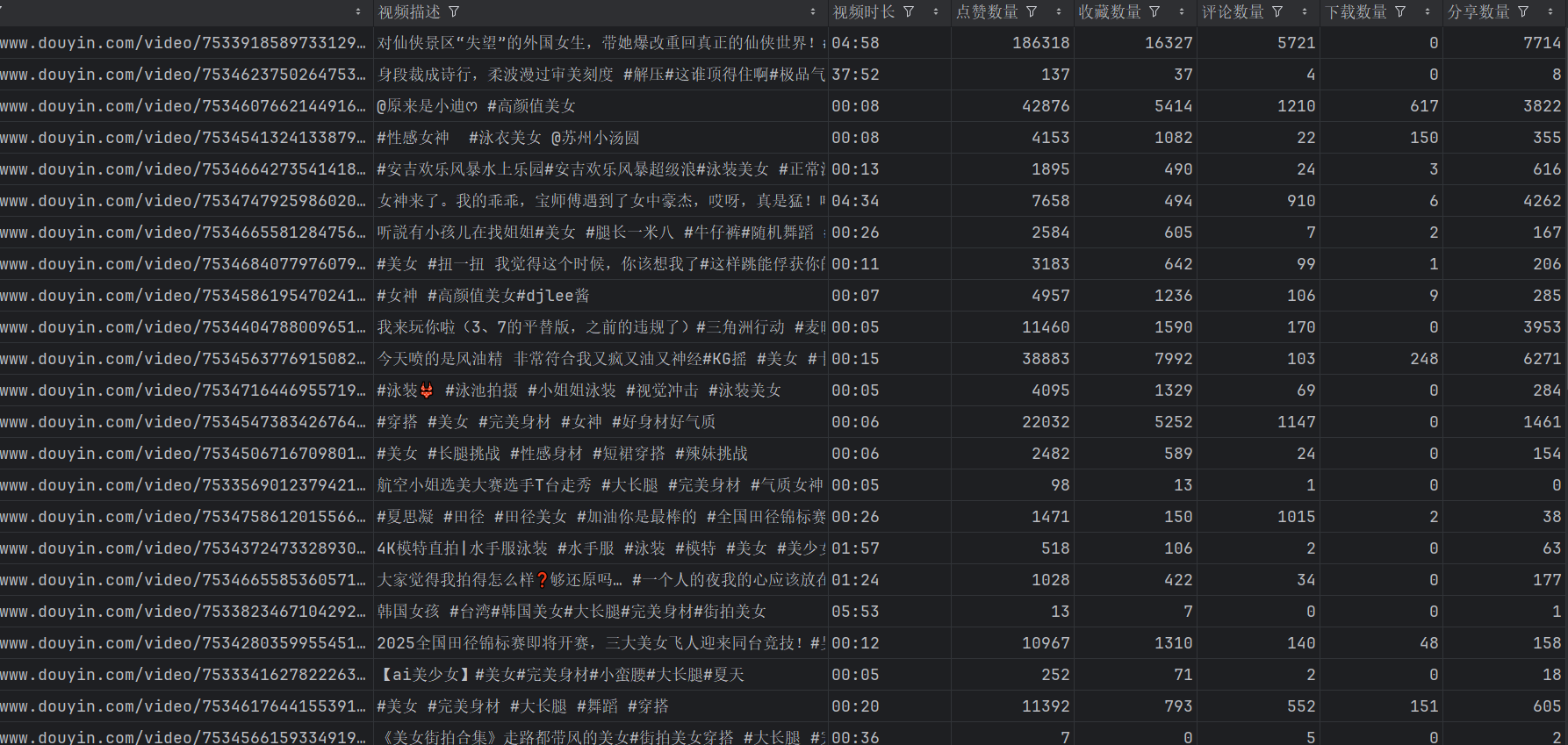
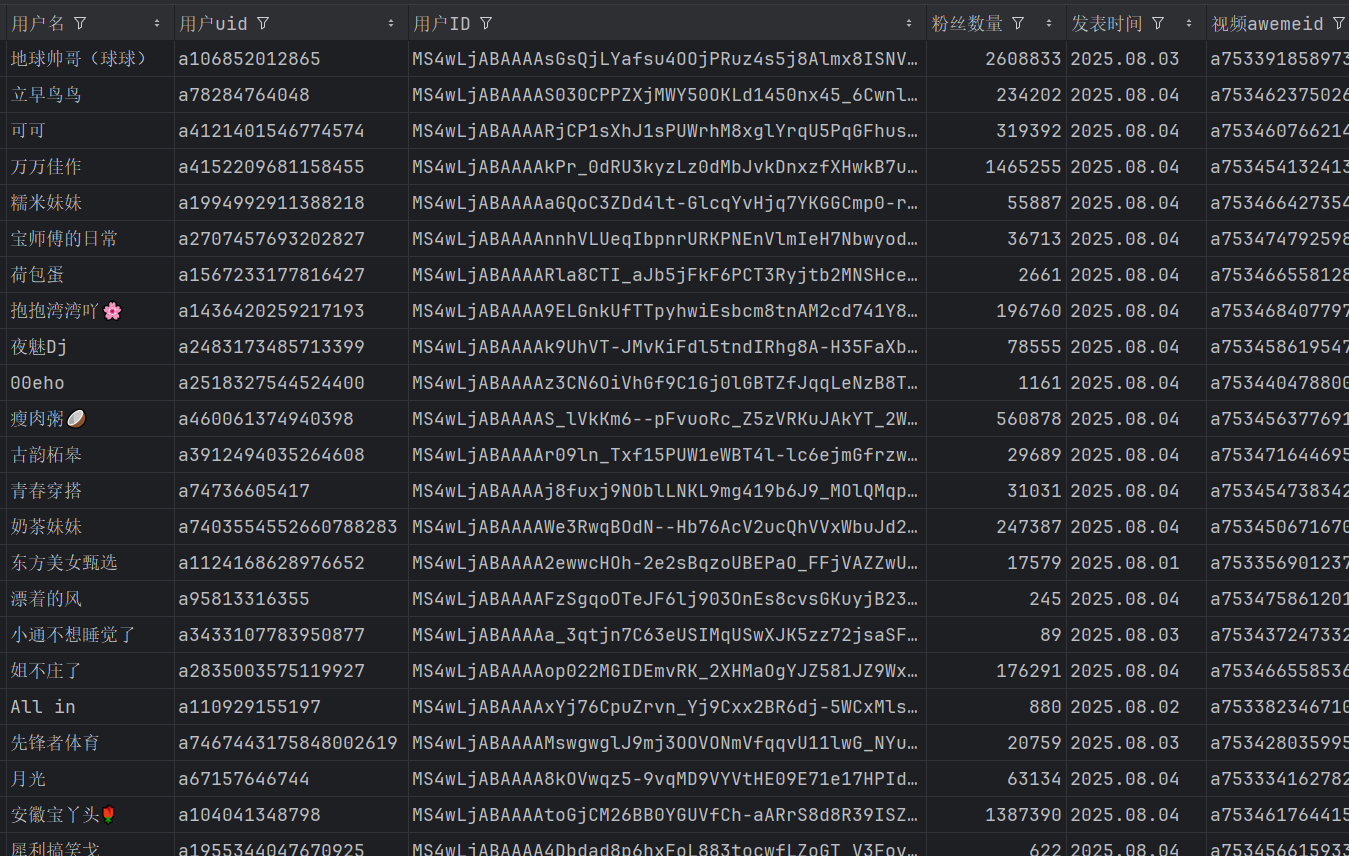
四、代码解析
1. 类与初始化
python
运行
class DouyinScraperGUI: def __init__(self, root): self.root = root self.root.title(\"抖音数据爬取工具\") # 界面配置、状态标志初始化等操作 self.create_widgets() # 构建界面组件- 初始化 GUI 类,设置窗口标题,初始化爬取状态标志(
is_running)、线程对象(scraper_thread)等,调用create_widgets方法构建界面。
2. 界面构建(create_widgets 方法)
python
运行
def create_widgets(self): # 顶部框架,包含输入框、按钮 top_frame = ttk.Frame(self.root, padding=\"10\") # 关键词、页数标签与输入框创建及布局 ttk.Label(top_frame, text=\"请输入搜索关键词:\").pack(side=tk.LEFT, padx=5) self.keyword_entry = ttk.Entry(top_frame, width=30) # (页数输入框、按钮类似创建布局...) # 状态显示区域 self.status_text = scrolledtext.ScrolledText(self.root, wrap=tk.WORD, height=25) self.status_text.pack(fill=tk.BOTH, expand=True, padx=10, pady=5) # 底部状态栏 self.status_var = tk.StringVar() self.status_var.set(\"就绪\") status_bar = ttk.Label(self.root, textvariable=self.status_var, relief=tk.SUNKEN, anchor=tk.W) status_bar.pack(side=tk.BOTTOM, fill=tk.X)- 通过
ttk.Framettk.Labelttk.Entry等组件,搭建界面布局,将输入框、按钮、滚动文本框、状态栏合理排列,实现可视化交互区域。
3. 爬取流程控制
- 开始爬取(
start_scraping方法):
python
运行
def start_scraping(self): keyword = self.keyword_entry.get().strip() max_pages = self.page_entry.get().strip() # 输入验证(关键词非空、页数为有效数字) self.is_running = True # 更新按钮状态(开始按钮禁用、停止按钮启用等) self.scraper_thread = threading.Thread( target=self.scrape_data, args=(keyword, max_pages), daemon=True ) self.scraper_thread.start() # 启动爬取线程-
获取输入框内容并验证,更新界面状态(按钮可用状态等 ),创建并启动新线程执行
scrape_data方法,避免爬取操作阻塞 GUI 主线程。 -
停止爬取(
stop_scraping方法):
python
运行
def stop_scraping(self): self.is_running = False self.update_status(\"正在停止爬取...\") self.log(\"用户请求停止爬取\")- 修改
is_running标志位,触发爬取线程内的循环终止逻辑,实现任务中断。
4. 数据处理
- 时间格式化(
get_time方法)
python
运行
def get_time(self, ctime): return time.strftime(\"%Y.%m.%d\", time.localtime(ctime))-
将抖音返回的时间戳转换为易读的日期格式(如
2025.08.05)。 -
视频信息提取(
save_video_info方法):
python
运行
def save_video_info(self, video_data): # 从视频数据中提取用户名、点赞数等字段并格式化 return { \'用户名\': video_data[\'author\'][\'nickname\'].strip(), -
解析抖音返回的视频数据 JSON 结构,提取所需字段并封装为字典,异常时记录错误信息。
-
实际爬取逻辑(
scrape_data方法):
python
运行
def scrape_data(self, keyword, max_pages): try: # 创建 CSV 文件并写入表头 filename = f\'{keyword}.csv\' with open(filename, mode=\'w\', encoding=\'utf-8\', newline=\'\') as f: csv_writer = csv.DictWriter(f, fieldnames=[...]) csv_writer.writeheader() # 初始化浏览器、监听请求、访问抖音页面 driver = ChromiumPage() driver.listen.start(\'www.douyin.com/aweme/v1/web/search/item\', method=\'GET\') url = f\'https://www.douyin.com/search/{keyword}?type=video\' driver.get(url) time.sleep(3) # 循环爬取多页数据 with open(filename, mode=\'a\', encoding=\'utf-8\', newline=\'\') as f: writer = csv.DictWriter(f, fieldnames=[...]) for page in range(max_pages): if not self.is_running: break # 滚动页面、获取响应数据 driver.scroll.to_bottom() time.sleep(2) try: resp = driver.listen.wait(timeout=10) json_data = resp.response.body except Exception as e: self.log(f\"获取数据出错: {str(e)}\") continue # 处理数据并写入 CSV # (循环处理每条视频数据...) driver.close() # 关闭浏览器 except Exception as e: self.log(f\"爬取过程出错: {str(e)}\")- 完成 CSV 文件初始化、浏览器启动与页面访问,循环执行 “滚动页面 - 获取数据 - 解析处理 - 写入文件” 流程,根据
is_running标志判断是否继续,异常时记录错误,结束后关闭浏览器。
五、运行与测试
1. 环境准备
- 确保已安装 Python 环境,通过
pip install drissionpage安装 DrissionPage 库(若使用 Chrome 浏览器,需保证浏览器驱动与浏览器版本适配,DrissionPage 一般可自动处理简单情况 )。
2. 操作步骤
- 运行代码,弹出图形界面;在 “请输入搜索关键词” 框填写内容(如 “美食教程” ),“最大爬取页数” 填合适数值(如
10);点击 “开始爬取”,观察状态文本框和状态栏,查看数据爬取情况;需要中断时点击 “停止爬取”。
3. 测试要点
- 验证输入为空(关键词或页数不填)时,是否弹出错误提示;
- 测试 “开始爬取” 后,滚动文本框是否实时显示爬取状态、视频数据写入是否正常;
- 检查 “停止爬取” 能否有效中断任务,界面是否正常响应。
六、总结与优化方向
1. 项目价值
- 实现了从抖音平台图形化采集数据的需求,相比纯命令行工具,降低了使用门槛,用户通过简单界面操作即可完成数据爬取,为后续数据分析提供基础支持 。
2. 优化点
- 界面美化:Tkinter 默认样式较简单,可引入
ttkbootstrap等库替换主题,提升界面美观度; - 功能扩展:增加数据去重逻辑(基于视频 ID 等标识),避免重复采集;支持设置爬取时间区间,精准获取特定时段视频;
- 异常处理增强:细化不同网络异常(如超时、连接失败)的提示与重试机制,提升工具稳定性。
通过不断优化,可让这款抖音数据爬取工具在易用性、功能性上更贴合实际需求,助力高效开展短视频数据相关研究与分析工作。
七.资料领取
私信老师


