深入解读Flux.1-Kontext:多模态AI图像生成与编辑的革新之作_flux kontext
前段时间6月底,黑森林发布了Flux.1-Kontex-dev后,笔者就忙着部署Kontext和Lora训练。现在终于有时间回过头看看Flux.1-Kontext和Flux.1的对比了。
本笔记基于官方文献进行扩展,主要介绍Flux.1-Kontext的概念与其他模型的对比,以及简单说说 Kontext [Dev] 版本的部署思路。下面是相关的文献与演示Demo:
- 官方 - 演示用Demo
- 官方 - Flux.1 Kontext文献
一、Flux.1-Kontext介绍
#1. Flux.1-Kontext的概念
FLUX.1-Kontext 是由 Black Forest Labs(黑森林) 开发的一款 多模态AI图像生成与编辑模型,支持 文本+图像双输入,能够实现 上下文感知的精细化编辑。Flux.1-Kontext 与 Flux.1 最大的不同在于「不仅能够文生图,还支持了原生的图片编辑(即图文生图)」。
Flux.1-Kontext 强调了 角色一致性、上下文理解能力、局部编辑能力。
- 局部编辑:修改图像中的特定部分,或调整颜色。
- 风格迁移:将图像转为特定风格,如油画。
- 角色一致性:在多次编辑后仍保持图像中的人物不变
参考自官方文献:
As a multimodal flow model,it combines state-of-the-art character consistency, context understanding and local editing capabilities with strong text-to-image synthesis.
- Character consistency:Preserve unique elements of an image, such as a reference character or object in a picture, across multiple scenes and environments
- Local editing: Make targeted modifications of specific elements in an image withoutaffecting the rest.
- Style Reference: Generate novel scenes while preserving unique styles from a reference image, directed by text prompts.
笔者整理了局部编辑、风格迁移、角色一致性这三个场景的效果图:

图. 官方Flux.1-Kontext演示图(from https://bfl.ai)
#2. 对比:Flux.1-Kontext 与 Flux.1
简单地说,Flux.1 主要用于 生成新图像(文生图),编辑能力有限,需依赖外部工具进行后期调整。而 Flux.1-Kontext 支持了原生的「单文本生图」与「文本+图像双输入来生成图片」。
对于「多轮迭代编辑」,笔者在下面展示对应的案例:

#3. 评估:Flux.1-Kontext与SOTA方法的对比(来自官方文献)
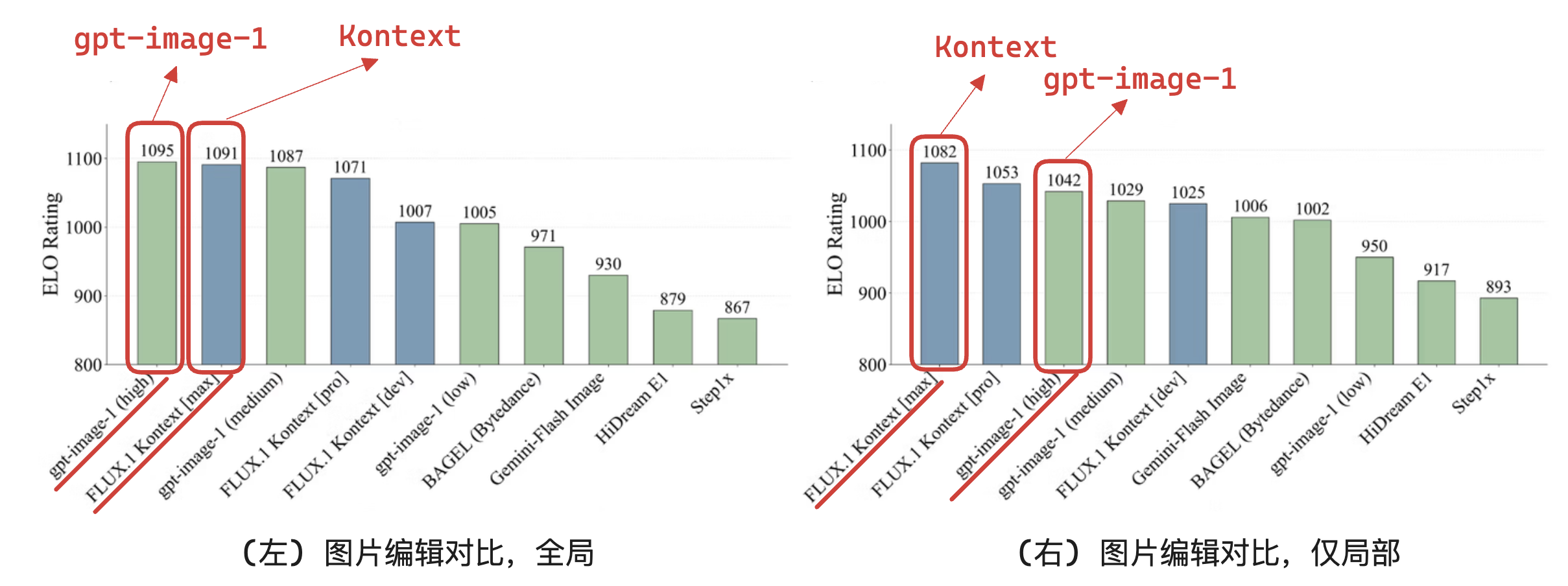
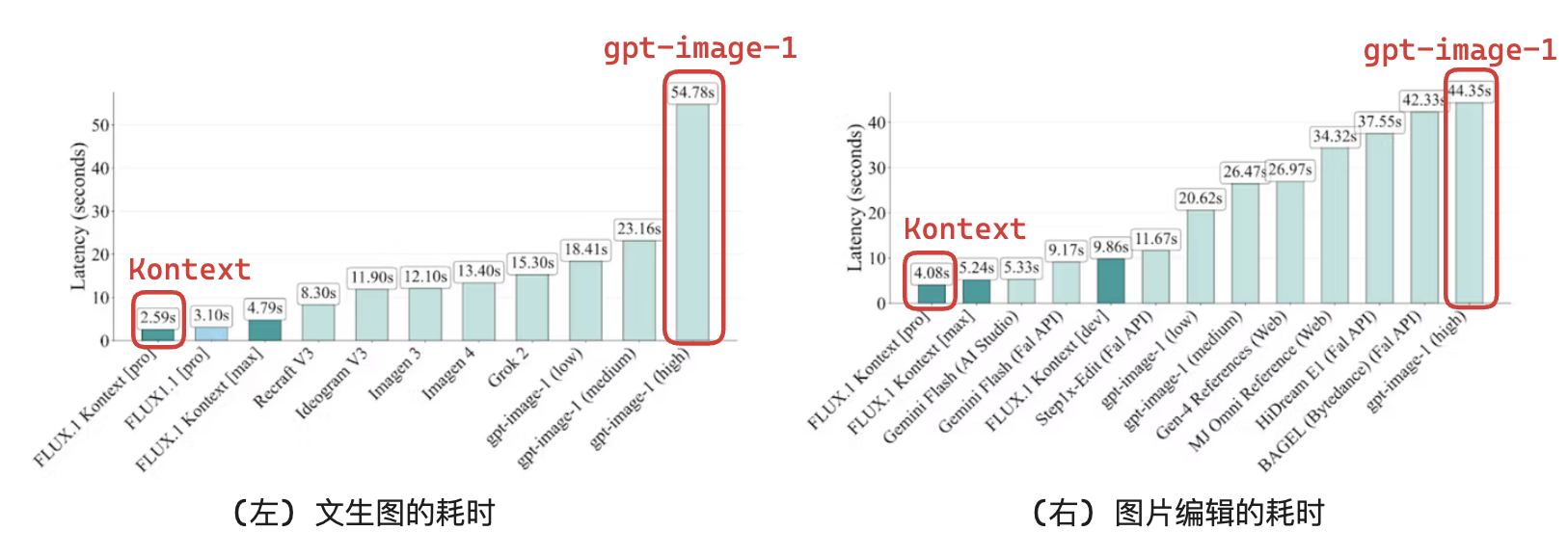
总的来说,在效果上,Flux.1-Kontext与gpt-image-1(hight)不分上下。在生成速度上,Flux.1-Kontext远快于gpt-image-1(hight)。
在「图片编辑能力」上:
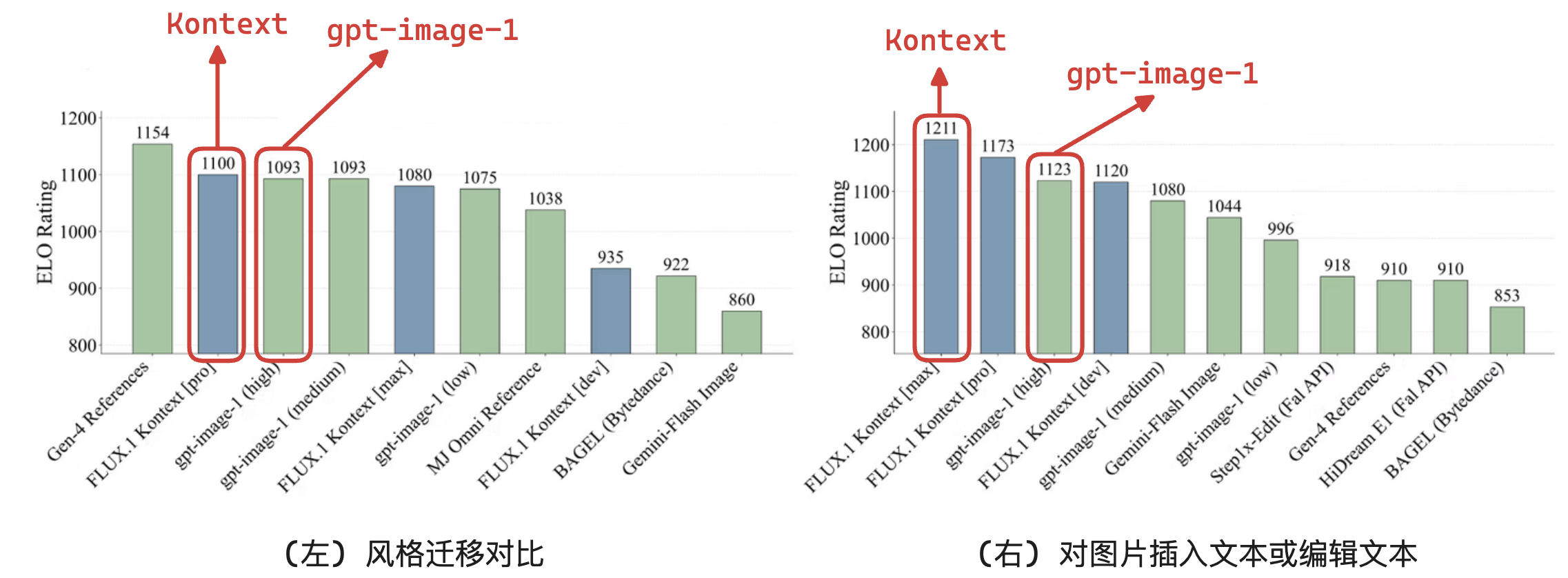
在「风格迁移」与「向图片插入文本或编辑文本」上:
在「生成速度」上的对比:(注意官方并没有说在什么设备上)
#4. Flux.1-Kontext的各版本对比
简单的说,Kontext [max]($0.08)与**Kontext [pro]****($0.04) 需要付费调用官方API,且不支持本地微调。其中前者效果更好且价格为后者双倍,而 Kontext [dev] 作为阉割版,但支持本地部署模型与本地微调Lora,且不需要付费。
下面主要介绍下 Kontext [dev],以及实操部署。
二、Flux.1-Kontext-dev的部署(简称“Kontext [dev]”)
Kontext [dev] 作为一个轻量级12B的生成模型(Diffusion Transformer),与之前的 FLUX.1 [dev] 推理代码兼容。
#1. 笔者对 Kontext [dev] 的部署建议:
训练上:
- 业内人员可以基于Diffusers库开发训练套件,或直接使用现成的AI-Toolkit训练集成库进行Lora训练,截止20250702仅支持Lora训练不支持基础模型的训练
- 非业内人员建议直接使用他人部署好的训练平台,如仙宫云上搜索“ai-toolkit”的镜像,但注意鉴别有些镜像是收费的。
推理上:
- 可以自己搭建仙宫云工作流进行生成。
- 也可以直接使用Diffusers库的进行生成。参考下方笔者代码:
import torchfrom diffusers import FluxKontextPipelinefrom diffusers.utils import load_imagebase_model = \"/root/autodl-fs/FLUX.1-Kontext-dev\"# Flux.1-Kontext基础模型input_image = \"/root/autodl-fs/cat.png\"# 输入图片(即待编辑的图片)input_image = load_image(input_image)# 加载模型pipe = FluxKontextPipeline.from_pretrained(base_model, torch_dtype=torch.bfloat16)pipe.to(\"cuda\")# 生成image = pipe( image=input_image, prompt=\"Add a hat to the cat\",# 文本提示Prompt num_inference_steps=30, guidance_scale=2.5,).images[0]image.save(\"./output.png\")# 保存图片PS:该代码实现图片编辑,若要实现单文本生图,去掉image=input_image,即可。若要加载Lora,加上pipe.load_lora_weights(lora_path)。
#2. Kontext [dev] 的模型文件
模型文件分为「BF16的黑森林官方版」和「FP8量化的ComfyUI版本」(更低的显存占用)。
FP8量化版的注意点:
- FP8量化的ComfyUI版:同时支持 E4M3FN 与 E5M2 格式。
- 该FP8量化版并非完整的Pipeline,仅是 Diffusion Model 组件。即,不支持在Diffusers中使用,仅支持在ComfyUI中使用。
- 下载得到的.safetensors应当放在 ComfyUI 的
diffusion_models目录下。flux1-kontext-dev-fp8-e4m3fn.safetensors:平衡的生成速度与精度flux1-kontext-dev-fp8-e5m2.safetensors:针对 Hopper 架构 GPU 进行了优化,提高了生成速度降低了少量精度
- 参考用的ComfyUI版本: with PyTorch 2.4+ and CUDA 12.4+
根据笔者的实际测试,BF16在显卡L20 48GB下的显存占用:
- 无Control Image:显存占用22GB
- 有Control Image:显存占用32GB,训练时长✖️3倍左右
到底咯,如果这篇文章对您有些许帮助,请帮忙点个赞👍或收个藏📃。您的支持是我继续创作的动力💪!
当暴风雨⚡️过去,你不会记得自己是如何度过的,你甚至不确定暴风雨是否真的结束了。但你已经不再是当初走进暴风雨的那个人了,这就是暴风雨的意义💪。


