【AI大模型前沿】Kwai Keye-VL:颠覆认知、国产多模态大模型突然发布,视频理解能力堪比人类
系列篇章💥
目录
- 系列篇章💥
- 前言
- 一、项目概述
- 二、技术原理
-
- (一)模型架构
- (二)预训练策略
- (三)后训练策略
- 三、主要功能
-
- (一)视频理解
- (二)图像识别与描述
- (三)逻辑推理
- (四)多模态交互
- (五)智能创作
- 四、应用场景
-
- (一)视频内容创作
- (二)智能客服
- (三)教育辅导
- (四)广告营销
- (五)医疗辅助
- 五、快速使用
-
- (一)安装相关依赖
- (二)模型加载与推理
- 六、结语
- 七、项目地址
前言
在人工智能的浪潮中,多模态大语言模型正成为推动技术进步的关键力量。快手作为国内领先的短视频平台,凭借其强大的技术实力和对创新的不懈追求,推出了 Kwai Keye-VL 多模态大语言模型。这一模型不仅展现了快手在 AI 领域的深厚积累,也为多模态交互和智能应用开辟了新的可能性。

一、项目概述
Kwai Keye-VL 是快手自主研发的多模态大语言模型,基于 Qwen3-8B 语言模型整合 SigLIP 初始化的视觉编码器,支持动态分辨率输入。该模型能够深度融合和处理文本、图像、视频等多模态信息,凭借创新的自适应交互机制与动态推理能力,致力于为用户打造更智能、更全面的多模态交互新范式。Kwai Keye-VL 在视频理解、复杂视觉感知、逻辑推理等方面表现出色,尤其在 2025 年高考全国数学卷中狂砍 140 分,展现了其卓越的推理能力。
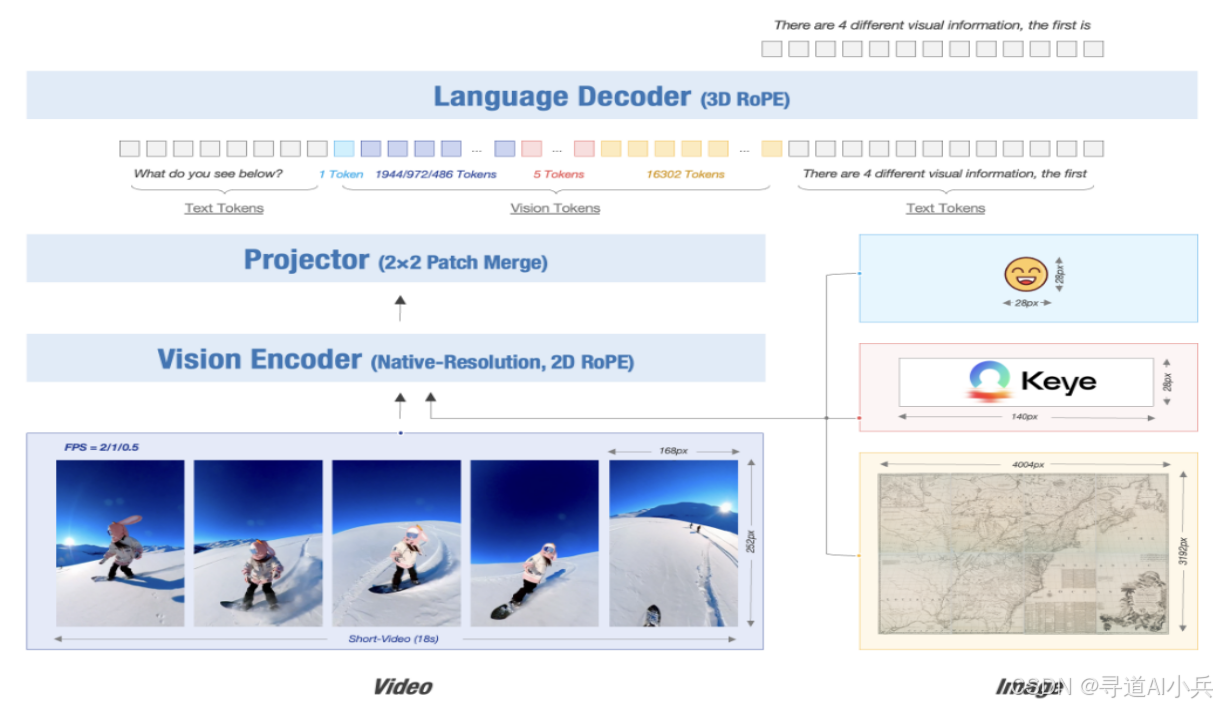
二、技术原理
(一)模型架构
Kwai Keye-VL 的架构基于 Qwen3-8B 语言模型,整合了 SigLIP 初始化的视觉编码器。该模型支持动态分辨率输入,能够按原始比例将图像切分为 14×14 分块,通过 MLP 层整合视觉特征。3D RoPE(旋转位置编码)技术被用于统一处理文本、图像和视频,基于位置编码与时间戳对齐,精准捕捉视频时序变化。
(二)预训练策略
Kwai Keye-VL 采用四阶段预训练策略:
1、视觉预训练:持续预训练视觉编码器,适配内部数据分布并支持动态分辨率输入。
2、跨模态对齐:冻结主干模型,仅训练轻量级 MLP 适配器,用极低成本高效建立鲁棒的图文/视频-文本对齐关系。
3、多任务预训练:解锁全部模型参数,进行多任务联合训练,全面提升模型的综合视觉理解能力。
4、退火训练:用精选高质量数据进行精调,进一步提升模型的精细理解和判别能力。探索同构异质融合技术,基于参数平均融合不同数据配比的退火训练模型,在保留多维度能力的同时,减小模型偏差,增强模型的鲁棒性。
(三)后训练策略
1、非推理训练:使用 500 万条高质量多模态 VQA 数据,结合自研 TaskGalaxy 方案建立的任务体系(包含 7 万种任务),以及 AI 筛选困难样本及人工标注保障数据质量。结合开源数据与自建的偏好数据,后者收集 SFT 错误样本作提问素材、Qwen2.5VL 72B 与 SFT 模型生成答案对、人工排序获得。
2、推理训练:混合四种推理模式的训练数据,实现对模型思维链能力的零基础激活,初步掌握人类分步思考的推理范式。在冷启动基础上,用 GRPO 算法进行混合模式强化学习,基于创新的双轨奖励机制(同步评估结果正确性与过程一致性)深度优化多模态感知、数学推理、短视频理解及智能体协同等综合能力,显著提升模型的推理能力。基于 MPO 算法对优劣数据对进行多轮迭代,根治内容重复崩溃与逻辑断层问题,最终赋予模型根据问题复杂度智能选择深度推理模式的自适应能力,实现性能与稳定性的双重突破。
三、主要功能
(一)视频理解
Kwai Keye-VL 能够对短视频内容进行深度理解,分析视频中的场景、人物、动作等信息,为视频生成描述、标签或推荐相关内容。这一功能对于视频内容创作、视频推荐系统等应用场景具有重要意义,能够帮助创作者更好地理解视频内容,为用户提供更精准的视频推荐。
(二)图像识别与描述
该模型可以自动解析图像细节,识别图像中的物体、场景等,并生成准确的描述。在图像识别领域,Kwai Keye-VL 的表现可与一些专业的图像识别模型相媲美,为图像标注、图像搜索等应用提供了强大的技术支持。
(三)逻辑推理
Kwai Keye-VL 在复杂的逻辑推理任务中表现出色,例如解决数学问题、进行科学推理等。其推理能力不仅体现在对数学问题的求解上,还能够处理一些涉及逻辑判断和推理的复杂任务,为教育辅导、智能客服等地方提供了有力的辅助工具。
(四)多模态交互
Kwai Keye-VL 支持处理文本、图像、视频等多种模态的信息,并在模态之间进行有效的交互和融合。这种多模态交互能力使得模型能够更好地理解用户的输入,提供更加智能和全面的交互体验,适用于智能客服、智能创作等多种场景。
(五)智能创作
基于对多模态信息的理解,Kwai Keye-VL 可以辅助用户进行内容创作,如生成文案、脚本、创意方案等。这一功能对于广告营销、内容创作等行业具有巨大的价值,能够提高创作效率,激发创意灵感。
四、应用场景
(一)视频内容创作
Kwai Keye-VL 能够帮助短视频创作者快速生成标题、描述和脚本,提高创作效率。通过对视频内容的理解和分析,模型可以为创作者提供有价值的创作建议和灵感,使创作者能够更加专注于创意和内容的表达。
(二)智能客服
基于多模态交互(文本、语音、图像),Kwai Keye-VL 可以为用户提供智能客服服务,提升用户体验。模型能够理解用户的多种输入方式,并给出准确、及时的回复,解决用户的问题,提高客户满意度。
(三)教育辅导
Kwai Keye-VL 可以为学生提供个性化的学习辅导,包括作业解答和知识点讲解,助力学习。其逻辑推理能力和多模态交互能力使得模型能够更好地理解学生的问题,提供有针对性的辅导和解答,提高学习效果。
(四)广告营销
Kwai Keye-VL 能够为广告商生成吸引人的文案和脚本,提高广告效果。通过对目标受众的兴趣和需求的理解,模型可以创作出更具吸引力和针对性的广告内容,提升广告的点击率和转化率。
(五)医疗辅助
Kwai Keye-VL 可以辅助医生分析医学影像,提供初步诊断建议,提升医疗效率。在医疗影像诊断领域,模型的图像识别和分析能力能够为医生提供有价值的参考,帮助医生更快地做出诊断,提高医疗服务质量。
五、快速使用
(一)安装相关依赖
使用 pip 安装 keye-vl-utils 工具库:
pip install keye-vl-utils(二)模型加载与推理
以下是使用 Kwai Keye-VL 进行推理的代码示例:
from transformers import AutoModel, AutoProcessorfrom keye_vl_utils import process_vision_info# 默认:在可用设备上加载模型model_path = \"Kwai-Keye/Keye-VL-8B-Preview\"model = AutoModel.from_pretrained( model_path, torch_dtype=\"auto\", device_map=\"auto\", attn_implementation=\"flash_attention_2\", trust_remote_code=True,).to(\'cuda\')# 您可以通过环境变量 VIDEO_MAX_PIXELS 设置视频的最大像素# 基于模型可以接受的最大 token 数量。# export VIDEO_MAX_PIXELS = 32000 * 28 * 28 * 0.9# 您可以直接在文本中插入本地文件路径、URL 或 base64 编码的图像。messages = [ # 图像 # 本地文件路径 [{\"role\": \"user\", \"content\": [{\"type\": \"image\", \"image\": \"file:///path/to/your/image.jpg\"}, {\"type\": \"text\", \"text\": \"Describe this image.\"}]}], # 图像 URL [{\"role\": \"user\", \"content\": [{\"type\": \"image\", \"image\": \"http://path/to/your/image.jpg\"}, {\"type\": \"text\", \"text\": \"Describe this image.\"}]}], # Base64 编码的图像 [{\"role\": \"user\", \"content\": [{\"type\": \"image\", \"image\": \"data:image;base64,/9j/...\"}, {\"type\": \"text\", \"text\": \"Describe this image.\"}]}], # PIL.Image.Image [{\"role\": \"user\", \"content\": [{\"type\": \"image\", \"image\": pil_image}, {\"type\": \"text\", \"text\": \"Describe this image.\"}]}], # 模型动态调整图像大小,如有需要可指定尺寸。 [{\"role\": \"user\", \"content\": [{\"type\": \"image\", \"image\": \"file:///path/to/your/image.jpg\", \"resized_height\": 280, \"resized_width\": 420}, {\"type\": \"text\", \"text\": \"Describe this image.\"}]}], # 视频 # 本地视频路径 [{\"role\": \"user\", \"content\": [{\"type\": \"video\", \"video\": \"file:///path/to/video1.mp4\"}, {\"type\": \"text\", \"text\": \"Describe this video.\"}]}], # 本地视频帧 [{\"role\": \"user\", \"content\": [{\"type\": \"video\", \"video\": [\"file:///path/to/extracted_frame1.jpg\", \"file:///path/to/extracted_frame2.jpg\", \"file:///path/to/extracted_frame3.jpg\"],}, {\"type\": \"text\", \"text\": \"Describe this video.\"},],}], # 模型动态调整视频帧数、视频高度和宽度。如有需要可指定参数。 [{\"role\": \"user\", \"content\": [{\"type\": \"video\", \"video\": \"file:///path/to/video1.mp4\", \"fps\": 2.0, \"resized_height\": 280, \"resized_width\": 280}, {\"type\": \"text\", \"text\": \"Describe this video.\"}]}],]processor = AutoProcessor.from_pretrained(model_path)model = AutoModel.from_pretrained(model_path, torch_dtype=\"auto\", device_map=\"auto\").to(\'cuda\')text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)images, videos, video_kwargs = process_vision_info(messages, return_video_kwargs=True)inputs = processor(text=text, images=images, videos=videos, padding=True, return_tensors=\"pt\", **video_kwargs).to(\"cuda\")print(inputs)generated_ids = model.generate(**inputs)print(generated_ids)通过上述代码,您可以快速加载 Kwai Keye-VL 模型,并对图像和视频进行推理,生成相应的描述和分析结果。
六、结语
Kwai Keye-VL 作为快手推出的多模态大语言模型,在技术原理、功能实现和应用场景等方面都展现出了强大的优势和潜力。其创新的模型架构和训练策略,使其在视频理解、图像识别、逻辑推理等多模态任务中表现出色,为多模态交互和智能应用提供了有力的技术支持。随着技术的不断发展和完善,Kwai Keye-VL 将在更多领域发挥更大的作用,为人工智能的发展注入新的活力。
七、项目地址
- 项目官网:https://kwai-keye.github.io/
- GitHub 仓库:https://github.com/Kwai-Keye/Keye/tree/main
- HuggingFace 模型库:https://huggingface.co/Kwai-Keye

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!


