一看视频就能学会的VideoMimic——三步走:先real2sim(涉及视频作为输入、提取姿态且点云化、重定向到G1上),后sim中训练,最后sim2real
前言
本文一开始是此文《从视频学习的最新进展:从Humanoid-X(自动打字幕)、到首个人形VLA Humanoid-VLA》的第三部分,但考虑到VideoMimic的重要性『个人认为是一个小的里程碑,可能不是搞具身的不能立马体会到其价值,说白了,就是通过手机拍摄的人上下台阶的视频,训练模型,使机器人在无需遥控器的前提下,自主上下台阶 』
加之其代码 相比今年5月份刚发布时,新开源了下面的第一份代码(至于第二份、第三份,截止到25年8.6日,暂未开源)
- Release real‑to‑sim pipeline (July 15th, 2025)
- Release the video dataset (July 15th, 2025)
- Release sim‑to‑real pipeline (September 15th, 2025)
故把VideoMimic独立出来,成此文,我在解读的过程中,为了最大程度的让读者一目了然,一者 并未严格按照原论文的行文顺序,二者 对每一部分的标题、配图都做了反复修改、斟酌
PS,为不断扩大我司的具身朋友圈,关联中国更多的具身er
- 在我司的主营业务「具身智能的场景落地与定制开发」之外,我们特开设「七月具身:人形二次开发线下营」,如果国内没人带你,我们带你——以最顶级、最前沿的视角
- 线下营的内容很多,其中之一是分享我看过的200篇具身paper,比如 这个videomimic
欢迎大伙加入
第一部分 UC伯克利VideoMimic:仅看视频就能copy人类动作,宇树G1分分钟掌握100+
1.0 引言与相关工作
1.0.1 引言
如VideoMimic原论文所说,如果人形机器人能够通过观察人类的日常视频去学习视频中对应的人类行为,那它们就能获得多样化的、具有环境上下文的全身技能,而无需为每种新行为和环境依赖人工调整的奖励或动作捕捉数据。我们将这种能够执行与环境相适应动作的能力称为“上下文控制”
对此,来自UC伯克利的研究者提出了VideoMimic,这是一种从真实到仿真再回到真实的流程,可以将单目视频(如随手拍摄的手机视频)转化为类人机器人的可迁移技能

- 其论文为《Visual Imitation Enables Contextual Humanoid Control》
其作者包括:Arthur Allshire∗、Hongsuk Choi∗、Junyi Zhang∗、David McAllister∗
Anthony Zhang、Chung Min Kim
Trevor Darrell(CV牛人)、Pieter Abbeel(RL牛人)、Jitendra Malik、Angjoo Kanazawa - 其项目地址为:videomimic.net
其GitHub地址为:github.com/hongsukchoi/VideoMimic
简言之
- 即从这些视频中联合恢复4D人-场景几何体,将动作重定向到类人机器人,并训练强化学习策略以跟踪参考轨迹
- 随后,将该策略蒸馏为一个统一的策略,该策略仅通过本体感知、本地高度图和期望根部方向进行观察
- 蒸馏后的策略根据地形和身体状态输出低层次的运动动作,使其能够在未知环境中执行合适的行为——如行走、攀爬或坐下——而无需明确的任务标签或技能选择
具体而言
- 先采数据(对应下文的1.1节)
作者开发了一个感知模块,能够从单目RGB视频中重建三维人体运动,并在世界坐标系下对齐场景点云,如下图第一行和第二行的左图所示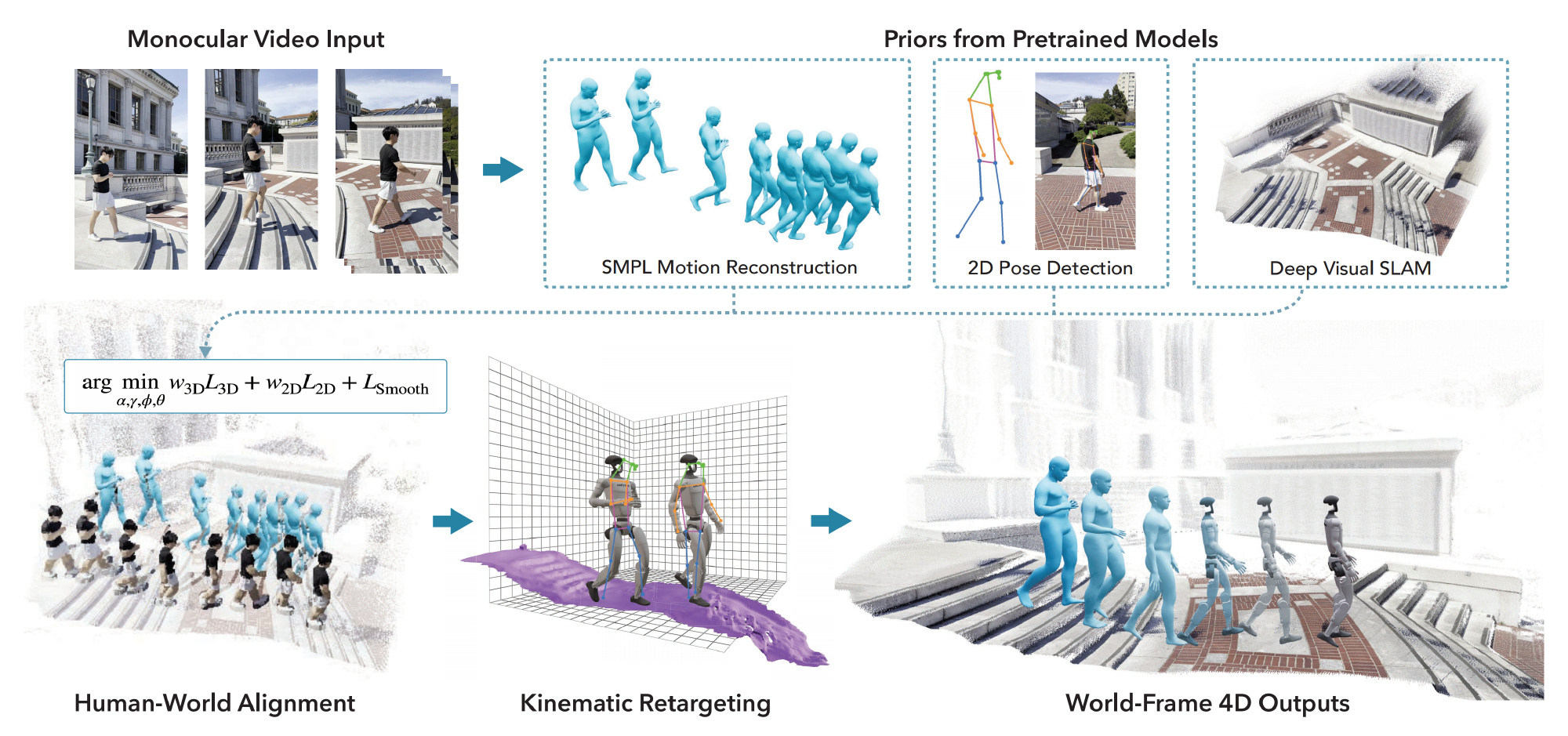
后将点云转换为网格模型,并与重力方向对齐(如上图第二行的中图所示),以确保与物理仿真器的兼容性
全局运动和局部姿态被重定向到一个具身人形体,并施加物理合理性的约束,以弥合具身差距 - 后sim中做策略训练(对应下文的1.2节)
网格和重定向后的数据作为目标条件输入,驱动DeepMimic『1,详见此文《从RoboMimic、DeepMimic到带物理约束的MaskMimic——人形全身运控的通用控制器:自此打通人类-动画-人形的训练路径》的第二部分』风格的IL + RL的阶段具体而言,如下图所示,分为4步骤
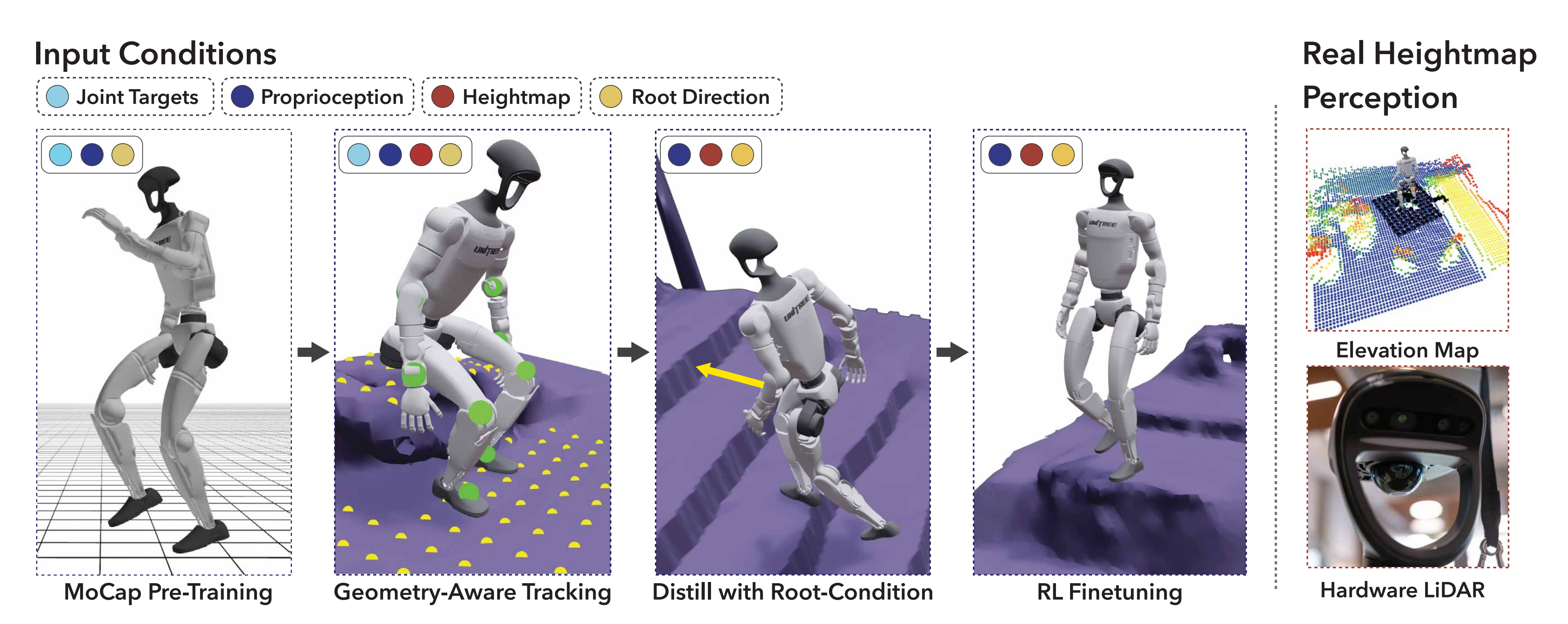
a) mocap pre-Traning,以动作捕捉(MoCap)数据为热启动
通过PPO在该精简观测集下进行微调 - 最终获得一个通用控制器,做真机部署(对应下文的1.3节)
以在测试时根据高度图和根方向选择并平滑执行适合上下文的动作,如行走、攀爬或坐下
尤其值得注意的是,策略的每一步仅依赖于实际部署时可获得的观测信息,因此可直接在真实硬件上运行
- 他们的方法在一个数据驱动的循环中融合了4D视频重建与机器人技能学习。与以往仅单独重建人物或场景的工作不同,作者联合重建了两者,并以物理上有意义的尺度将其表示为网格和运动轨迹,从而适用于基于物理的策略学习
- 且该方法在123段单目RGB视频上进行了训练,这些视频将会公开。且通过在真实的Unitree G1机器人上部署验证了该方法,结果显示机器人在不同环境中,包括未见过的环境中,能够展现出通用的人形运动技能
1.0.2 相关工作
第一,对于在足式机器人上学习技能
近年来,足式机器人运动技能的进展主要沿着两条互补的方向展开
- 基于奖励的方法在仿真环境中采用无模型强化学习
- 通过人工设计的目标函数来塑造行为,该目标函数通常将任务相关项(如速度跟踪)与运动自然性正则项结合起来
得益于大规模并行物理引擎 [11-Per-contact iteration method for solving contact dynamics,12- Isaac gym: High performance gpu-based physics simulation for robot learning],该范式已在四足动物和人形机器人上实现了敏捷的运动能力,且无需动作数据
然而,每引入一种新行为,都需要针对用户自定义的奖励函数和环境脚本进行调优
- 13-Learning agile and dynamic motor skills for legged robots
- 14- Learning quadrupedal locomotion over challenging terrain
- 15-RMA: rapid motor adaptation for legged robots
- 4-Legged locomotion in challenging terrains using egocentric vision
- 6- Real-world humanoid locomotion with reinforcement learning, 2023
即此文《伯克利Digit——基于下一个token预测技术预测机器人动作token:从带RL到不带RL的自回归预测》第一部分所介绍的- 9-Anymal parkour: Learning agile navigation for quadrupedal robots
- 16-Beamdojo: Learning agile humanoid locomotion on sparse footholds
- 17-Learning humanoid locomotion with perceptive internal model
- 数据驱动的方法则通过模仿参考动作——最初为动作捕捉(MoCap)片段或单目视频——训练模拟角色进行跟踪,并将该思想应用于机器人
1-DeepMimic
3-SFV: reinforcement learning of physical skills from videos
18- Human dynamics from monocular video with dynamic camera movements
19-Universal humanoid motion representations for physics-based control
7- Learning human-to-humanoid real-time whole-body teleoperation,即本博客中解读过的H2O
8- Exbody2: Advanced expressive humanoid whole-body control,本博客中也解读了例如,近期的研究
20- Learning humanoid locomotion over challenging terrain
21-Humanoid locomotion as next token prediction,即此文《伯克利Digit——基于下一个token预测技术预测机器人动作token:从带RL到不带RL的自回归预测》第二部分所介绍的将腿式运动建模为下一个token 的预测任务,并在运动学空间中利用人类数据对策略进行预训练,展现出优异的性能
- 尽管模仿学习绕过了奖励工程 [5-Asap: Aligning simulation and real-world physics for learning agile humanoid whole-body skills],但现有工作通常假设平坦地面或手工设计的场景,限制了面向上下文的全身控制
即便是建模人-场景接触的动画系统,也依赖于带仪器的 MoCap 舞台,因此缺乏可扩展性
22- Synthesizing physical character-scene interactions
23- Tokenhsi: Unified synthesis of physical human-scene interactions through task tokenization
VideoMimic基于视觉观测和局部高度图进行条件建模,并直接从单目 RGB 视频中学习具备环境感知能力的技能,如爬楼梯和坐椅子。联合 4D 人体-场景重建提供了物理一致性的参考动作,强化学习(RL)将其提炼为可迁移到真实人形机器人的策略,见下表表1
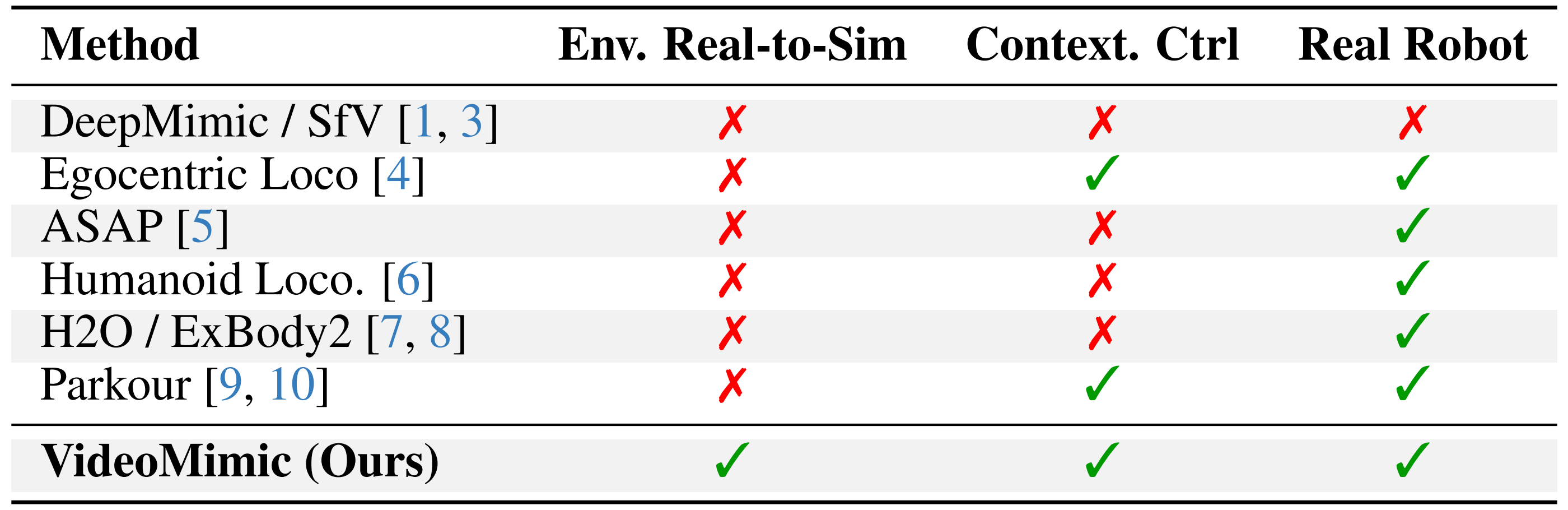
表1:不同特征下方法的比较。VideoMimic能够将真实视频中的人体动作和场景几何结构迁移到仿真环境,在仿真中学习具备上下文感知的控制策略,并能够成功将所得策略部署到现实世界环境中
1.1 先采数据——真实到仿真(Real-to-Sim)数据采集的3大阶段:预处理、人体与场景联合优化、生成仿真数据
该项目的真实到仿真流程如下图图2所示
- 第一步 预处理,如上图第一行
从输入视频中——仅需一段随手拍摄的手机视频作为输入
提取每帧的人体姿态和原始场景点云(raw scene point cloud )『即重建每帧的人体动作和二维关键点,并生成稠密的场景点云』 - 第二步,并对它们进行联合优化(如上图第二行左图),以获得度量对齐的人类轨迹和场景几何
即通过高效的优化算法将动作与点云进行联合对齐,利用人体身高先验恢复统计上准确的度量尺度,并基于与人体相关的点注册人体轨迹 - 第三步,将点云转换为网格,并与重力方向对齐,同时将动作重定向到重建场景中的类人模型上(如上图第二行中图)
具体而言
apply gravity alignment and convert thefiltered point cloud into a lightweight mesh (Sec. 3.3);
and retarget the refined trajectories to the humanoid under joint-limit, contact, and collision constraints (Sec. A.3).最终得到的运动-网格对可用于「下文1.2节所述的」策略学习(如上图第二行右图)
即最终得到的世界坐标系下的轨迹和可用于仿真器的网格,作为策略训练的输入
说白了,如附录A所述,作者的目标是让人形机器人具备全身技能——如行走、攀爬、坐下——这些技能能够在观看人类执行相关动作的单目RGB视频后,综合考虑周围几何环境
且假设:
- i) 单目RGB视频能够清晰捕捉到人物和场景
- ii) 视频片段内环境静止,因此在训练阶段可以将人体运动和地形视为刚性
- iii) 已知机器人运动学参数和关节极限,但没有多视角设备、动作捕捉系统、深度传感器或预扫描网格
作者从视频中联合重建具备度量尺度的4D人体轨迹和稠密场景几何,将它们与重力对齐,对场景点云进行网格化处理,并在保证接触和碰撞的前提下,将运动学重定向到机器人。最终得到的运动与网格配对数据可作为仿真器可用的训练片段
1.1.1 R2S第一阶段 预处理:提取人体姿态和2D关键点,且场景点云重建
作者使用现成的最先进人体姿态估计和结构光流(SfM)方法对单目RGB 视频进行预处理
- 首先
利用Grounded SAM2
45-Sam 2: Segment anything in images and videos
46-Grounded sam: Assembling openworld models for diverse visual tasks
——
如果我不提,你可能不知道这个Grounded SAM2对我产生了多大的影响
具体而言,25年8.7日,我在修订本文时,看到这个Grounded SAM2之后
1 我发现可以专门梳理一下《IDEA-Research推出的一系列检测、分割模型:从DINO(改进版DETR)、Grounding Dino、DINO-X到Grounded SAM2》
2 梳理过程中发现,可以对以前18年写的一篇『目标检测』博客进行大量修订且修改对DETR的解读,如此便把R-CNN、Fast R-CNN、Faster R-CNN、DETR相关的论文分别精读了一遍
3 最后再修订另一篇博客中的《ViT及其变体的发展史》一文以上直到8.12日才基本弄完,
当然 之所以愿意这么做,原因之一是我是希望我的每一篇解读都能成为经典,甚至艺术品,所以会花费很大的代价,哪怕是18年写的一篇文章 如今也会反复修订
——————————————————
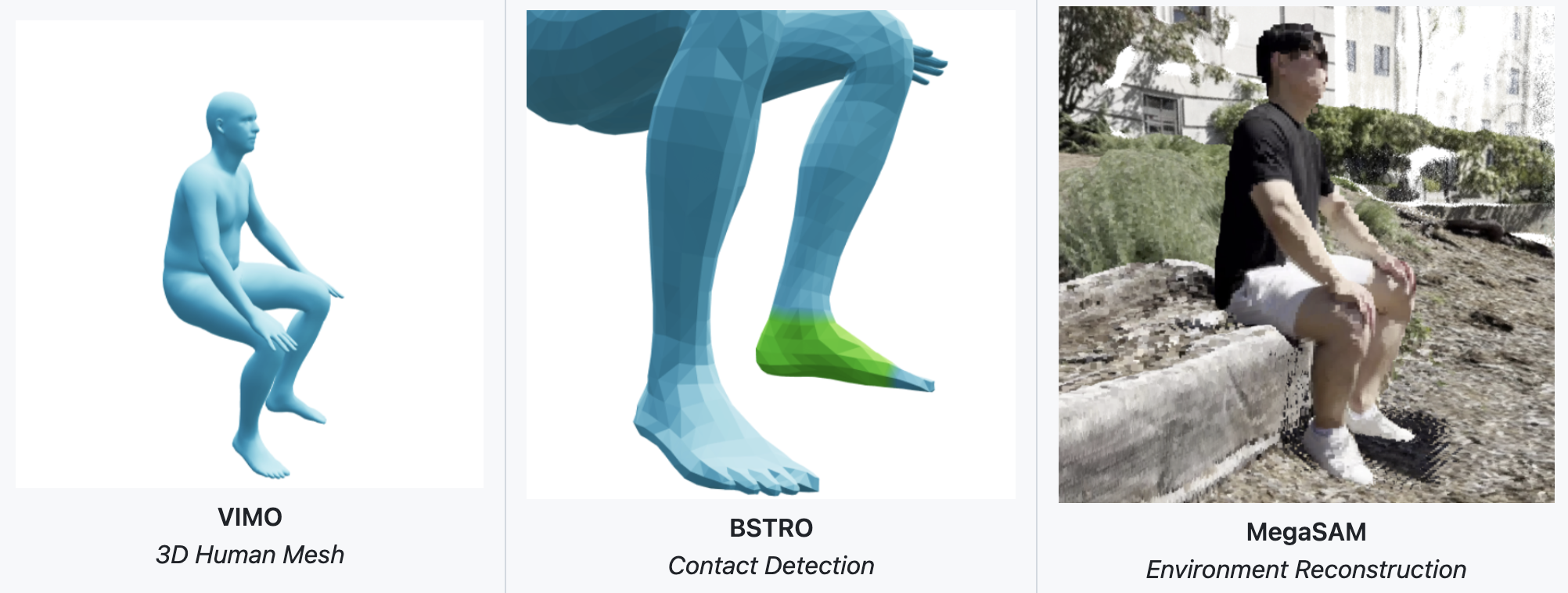
对人物进行检测并在帧间关联对于每个检测到的人体,作者使用VIMO [47-Tram: Global trajectory and motion of 3d humans from in-the-wild videos] 恢复每帧的3D SMPL [24] 参数,得到每帧的局部姿态
、形状
,以及SMPL 3D 关节点

且使用ViTPose [48-Vitpose: Simple vision transformer baselines for human pose estimation,即用于人体姿态估计] 检测2D 关键点
,即身体关节点的像素位置
而足部接触由BSTRO [49- Capturing and inferring dense full-body human-scene contact] 回归获得对于场景重建,作者通过
MegaSaM [35-Megasam: Accurate, fast, and robust structure and motion from casual dynamic videos]
或MonST3R [36-Monst3r: A simple approach for estimating geometry in the presence of motion] 获得世界点云,其参数包括每帧的深度、相机位姿
,以及共享的相机内参矩阵
需要注意的是,所得的点云在度量上并不准确
- 为了在世界坐标系中粗略定位人物,作者遵循SLAHMR [32-Decoupling human and camera motion from videos in the wild] 的初始化策略,利用
与对应的公制尺度3D 肢体长度
之间的比值,从而为每一帧估计一个相似性因子,从而得到一个粗略的全局轨迹
此外,作者还通过将『每个像素的
、深度
』 和『从SfM得到的内参K』进行反投影,以将
「Separately, we also lift ˜J t2D to 3D by un-projecting each pixel (u, v) with its depth Dtu,v and intrinsics K from SfM: ˜J t3D = K−1[u, v, 1]⊤Dtu,v」
提升后的关节点随后被用于联合优化人体姿态和场景几何尺度,具体内容将在下一节中介绍
以下是有关的一些符号说明
- 设置
作者的方法以单目视频序列作为输入。故将每一帧视频记为,分辨率为H × W
给定该输入,以及相机参数和人体姿态的初始估计,作者的方法能够在度量尺度的3D 世界中联合重建全局人体运动轨迹和稠密环境几何- 人体
作者使用SMPL 模型[24] 对视频中的重建人体进行表示。SMPL 是一个可微分函数,将姿态参数和形状参数
映射到具有
个关节的网格
该网格通过全局朝向和位移
被定位于世界坐标系中
因此,在第
帧时,一个人体由以下参数定义
- 相机
假设一个透视相机模型,其内参为,外参由旋转
和平移
定义
一个三维点首先被变换到相机坐标系中,然后投影到图像平面上,如下所示:
其中,表示透视投影,定义为
为
- 场景
该场景使用由MegaSaM [35] 或MonST3R [36] 生成的稠密逐帧深度和相机输出进行表示
具体而言
为了解决相机平移和场景几何的尺度歧义,作者引入了一个缩放参数
。给定每像素深度
,像素
对应的世界坐标
通过对点进行反投影获得:
1.1.2 R2S第二阶段 人体与场景联合重建
该项目下一步的流程是同时优化人体轨迹和场景尺度
- 变量包括人体的全局平移
、全局朝向
、局部姿态
,以及场景点云尺度
由于MegaSam 点云存在尺度歧义,SMPL 身体模型中的人体身高先验作为度量基准,而提升的关节同时优化全局轨迹和局部姿态

因此,作者同时求解
- 受He 等人[7,即H2O] 的启发,可选择性地运行一个尺度自适应步骤,在联合人-场景优化之前,搜索一个SMPL 形状
,其身高和四肢比例与G1 机器人相匹配

然后从重新塑形后的网格中提取SMPL 关节。使用预拟合到G1 尺度的SMPL
对于实际部署,作者跳过此步骤,直接在原始米制尺度场景上操作
该目标函数结合了3D 关节点距离损失(L3D),其计算方式为与
之间的L1 距离,以及2D 投影损失(L2D),同时还包含一个时序平滑正则项(LSmooth ),用于抑制帧与帧之间的抖动
作者使用在 JAX [50] 中实现的 Levenberg–Marquardt 求解器对该目标进行优化。在 NVIDIAA100 GPU 上,优化器在编译后处理 300 帧序列大约需要 20 毫秒。更多细节请参见 Sec.A
据原论文附录「A.2 联合人体-场景重建的目标」,下图代表优化前后,作者可视化了优化前后的人体轨迹和场景点云,并从两个不同的视角进行展示
- 如图7a 所示,粗略的初始化会产生不准确的人体轨迹和错误的场景尺度。作者的优化过程通过联合优化人体的全局平移
- 优化过程如图7b 所示,使人体与世界对齐,并有助于生成可用于仿真的数据
目标函数则结合了三维空间中的关节点距离损失与二维投影损失,并引入了时序平滑正则项,从而抑制了根部轨迹和关节姿态在帧与帧之间的抖动:
其中
其中,
作者使用在JAX [50] 中实现的Levenberg-Marquardt 求解器来优化该目标。在NVIDIA A100 GPU 上运行时,优化器在编译后处理一段300 帧的序列大约需要20 ms

1.1.3 R2S第三阶段 生成可用于仿真的数据(包含重定向)
为了在物理引擎中部署单目重建

- 作者首先使用 GeoCalib [51-Geocalib: Learning single-image calibration with geometric optimization] 将其与现实世界的重力方向对齐
- 其次将噪声较大的稠密点云转换为轻量级网格,从而施加有意义的几何约束,并支持高效的内存并行训练
且采用 NKSR [52] 进行网格化。更多细节请参见 Sec.A.3
据原论文「附录A.3 生成可用于仿真的数据」,进一步解释本节提到的相关概念
- 重力对齐
作者首先估计初始相机坐标系中的重力方向,并定义将三维重建从世界坐标系转换到与物理引擎兼容的重力对齐坐标系的变换
GeoCalib [51] 提供了该坐标系的滚转-俯仰角;复合旋转将重建结果重新定向,使+z轴朝上,从而确保与物理引擎中的重力一致
该变换同时应用于人体关键点和静态场景几何体- 点云滤波
对于每个世界点云,作者通过对深度梯度进行阈值处理,去除噪声背景点和人体点云,然后通过进行旋转、缩放,并在每帧围绕SMPL 关节裁剪到±2 m 的立方体内
随后,0.1 m 体素网格在每个被占据的单元格中最多保留20 个样本,将点云缩减到原始大小的约5 %,同时不会丢失表面细节- 网格化
作者首先使用NKSR [52] 对其进行表面重建,以获得一个粗略的网格。自上而下的射线投射通过在凸包内部进行逆距离插值来填补大的空洞;将填补后的点与原始点合并,并重新运行NKSR,生成最终的网格
整个流程处理一个300 帧的序列大约需要60 s(∼5 s用于重力对齐,∼55 s 用于过滤和网格化)- 仿人动作重定向
给定人体运动轨迹和环境网格作为输入,作者的目标是将这些动作转换为机器人本体的动作
______
类似此文HumanPlus中的这个图,即第二个箭头所示,从SMP模型到H1/G1
________________
即将重定向任务视为一个优化问题,类似于以往的研究[7,65],但作者采用Levenberg-Marquardt求解器,以应对人体场景问题中高度非线性的优化环境再进一步,作者求解以下变量:
- G1 关节角度
,其根部姿态
,以及两种体现之间的每个连杆的缩放因子集合
。注意,
,
和
分量进行惩罚(即,不使用范数)
- 受Cheynel 等人[66] 的启发,作者实现了一种基于运动学树的运动迁移损失

其中
其中,
表示关节
和
之间的位置差异。
表示在机器人运动链中这两个关节是否为直接相邻:若是则为1,否则为0。这两项代价被等权重处理。这些项被正则化以接近1.0,并保持非负
此外,作者还通过一系列接触代价(例如,足部接触点匹配、足部滑动惩罚)以及碰撞代价(自碰与环境碰撞规避),将机器人与环境进行耦合。机器人被近似为一组胶囊体,环境则被建模为高度图。采用基于学习的足部接触估计算法 [49] 来获取接触信号
- 滑行代价定义为
其中,表示在时刻
- 且,作者还包括常见的机器人代价(例如,关节限制、根部姿态和机器人关节的时间平滑性)以及对G1机器人膝部偏航关节的小型正则化代价,以实现稳定的腿部姿态
PS,处理一个300帧的视频片段,在单张A100显卡上大约需要10秒,使用PyRoki库[67]
附录 针对Real-to-Sim的评估:重建与数据
- 评估
作者在 SLOPER4D 数据集 [59] 的一个子集上评估了重建流程的鲁棒性,考察了人体轨迹和场景几何的重建效果
作者按照标准评估协议[60,47],将VideoMimic与基线方法进行了对比。如表2所总结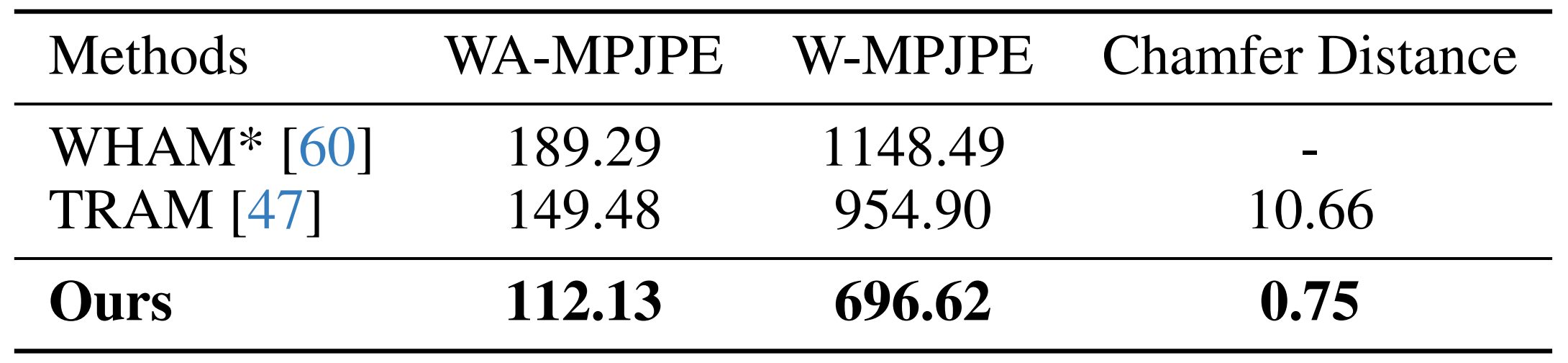
VideoMimic始终表现最佳,在人体轨迹精度(WA/W-MPJPE)和场景几何(Chamfer距离)方面均优于以往的工作。更多评估细节请参见Sec.A.4
如原论文附录「A.4 评估细节」所说,作者为了对他们的真实到仿真(real-to-sim)流程进行定量评估
他们在 SLOPER4D 数据集 [59] 上进行了实验。按照已有的评测协议 [39,60,47],采用世界坐标系下的平均每关节位置误差(W-MPJPE)和世界坐标系对齐的 MPJPE(WA-MPJPE)来评估人体轨迹重建的准确性,并使用 Chamfer 距离评估场景几何重建效果
- 具体来说,在人体轨迹评估中,首先将每个序列划分为 100 帧的片段。W-MPJPE 通过仅将前两帧与真实值对齐来计算,强调全局一致性;而 WA-MPJPE 则将整个片段对齐,用于评估局部轨迹的准确性
- 在几何评估方面,计算预测点云与 RGB 相机视野内的 LiDAR 点之间的 Chamfer 距离(以米为单位)
- 在基准测试中,选取SLOPER-4D 的一个子集,该子集仅包含 SAM2 跟踪(即人体检测加跨帧关联)成功的序列
最终获得了各两段跑步、步行和上下楼梯的序列。WHAM 和 TRAM 的结果均使用其官方代码复现
- 多样性
图4突显了他们的重建流程的广泛适用性「Real-to-Sim流程的多功能能力。VideoMimic实现了:(i)对具有复杂运动和多样环境的互联网视频进行鲁棒跟踪,(ii)同时对多个人体进行重建与重定向,以及(iii)用于具身感知的自我视角RGB-D渲染——尽管当前策略尚未使用该功能,但这突显了该框架在不同输入和任务中的广泛适用性」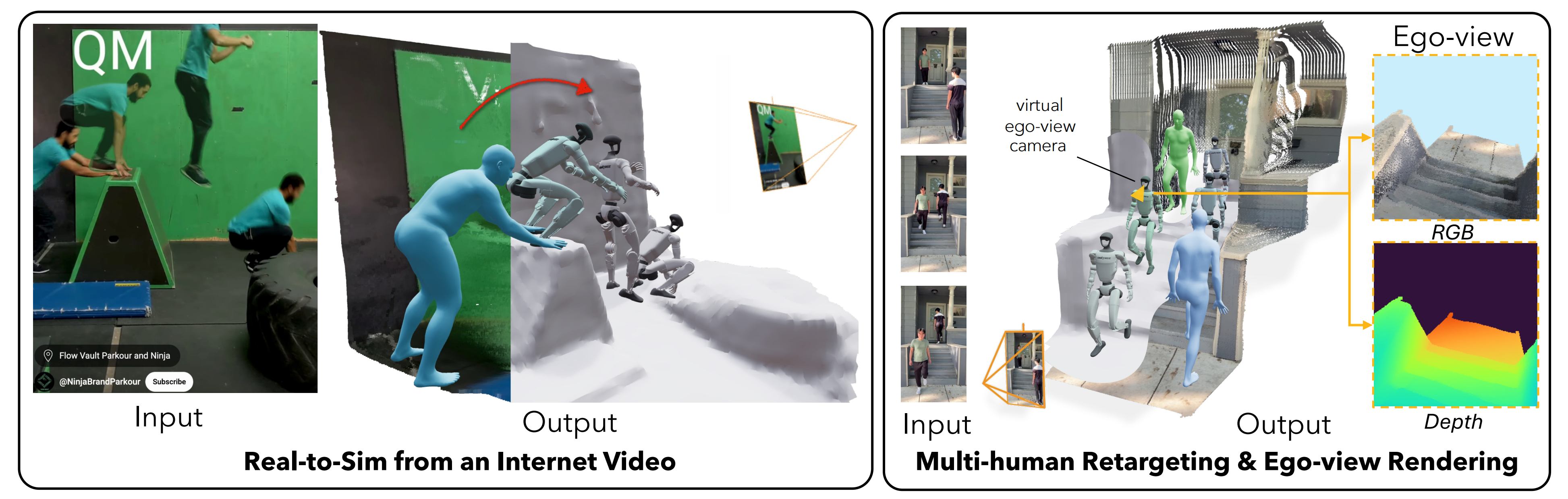
展示了:
i) 针对包含动态人-场景交互的互联网视频的稳健环境重建
ii) 多人重建与重定向此外,密集点云重建通过简单的光栅化,实现了自我视角的RGB-D渲染。虽然我们当前的策略尚未采用该功能,但鉴于在仿真中渲染自然图像的挑战,这为未来的研究指明了一个有前景的方向
如原论文的「A.5 自视角渲染」所说,作者利用具有度量尺度的4D重建,通过将每个三维点投影到Unitree G1头部传感器的虚拟相机中,实现自视角RGB-D帧的渲染
- 这种第一人称视角虽然在本工作中未被策略模块直接使用,但它展示了该流程未来的应用潜力。他们的重建结果能够为未来基于感知的策略提供真实的视觉观测,从而使机器人能够基于自身视角进行主动视觉和语义场景理解
- 然而,一个主要的局限在于,单目采集会导致许多表面无法被观测到;当在光栅化过程中,这些被遮挡的区域会在渲染图像中表现为空洞或缺口
弥补这些空隙是后续研究的一个令人兴奋的方向:现代数据驱动的新视角合成模型能够为不可见表面虚构出合理的几何结构和外观,有望实现逼真的自我中心渲染,从而进一步缩小视觉运动策略在模拟与现实之间的感知差距
总之,虽然他们的策略目前尚未使用RGB条件输入,但他们展示了重建结果在自我视角渲染中的潜力
- 通过将每个三维点投影到虚拟摄像机的图像平面上,将按米尺度缩放的点云光栅化为彩色和深度图像,该虚拟摄像机的俯仰角度与G1头戴式传感器一致
- 这种第一人称视角的渲染为机器人提供了对其周围环境的真实观测,从而为未来在主动视觉和语义理解方面的研究奠定基础,并且可以在强化学习训练期间直接注入到模拟器中,实现感知与控制的耦合

- 视频数据
作者收集了123段由智能手机随意录制的人们在各种室内和室外环境中进行日常活动的视频,这些活动包括坐下、从家具上站起、上下楼梯(甚至倒着走)以及踩踏方块等。更多细节见Sec.B.8
如附录「B.8 训练数据分布」所说
- 在 MPT 阶段之后,当在自有数据上训练流水线时,使用了从自有流水线收集的123 段人体运动数据进行训练
同时,在训练过程中也加入了 MPT 阶段使用过的 LaFan[57] 数据集中 10 段平地行走数据- 由于作者按每段数据进行类别均衡采样,因此训练时90% 来自自有数据,10% 来自 LaFan 数据。作者收集的 123 段数据的动作分布见表 6

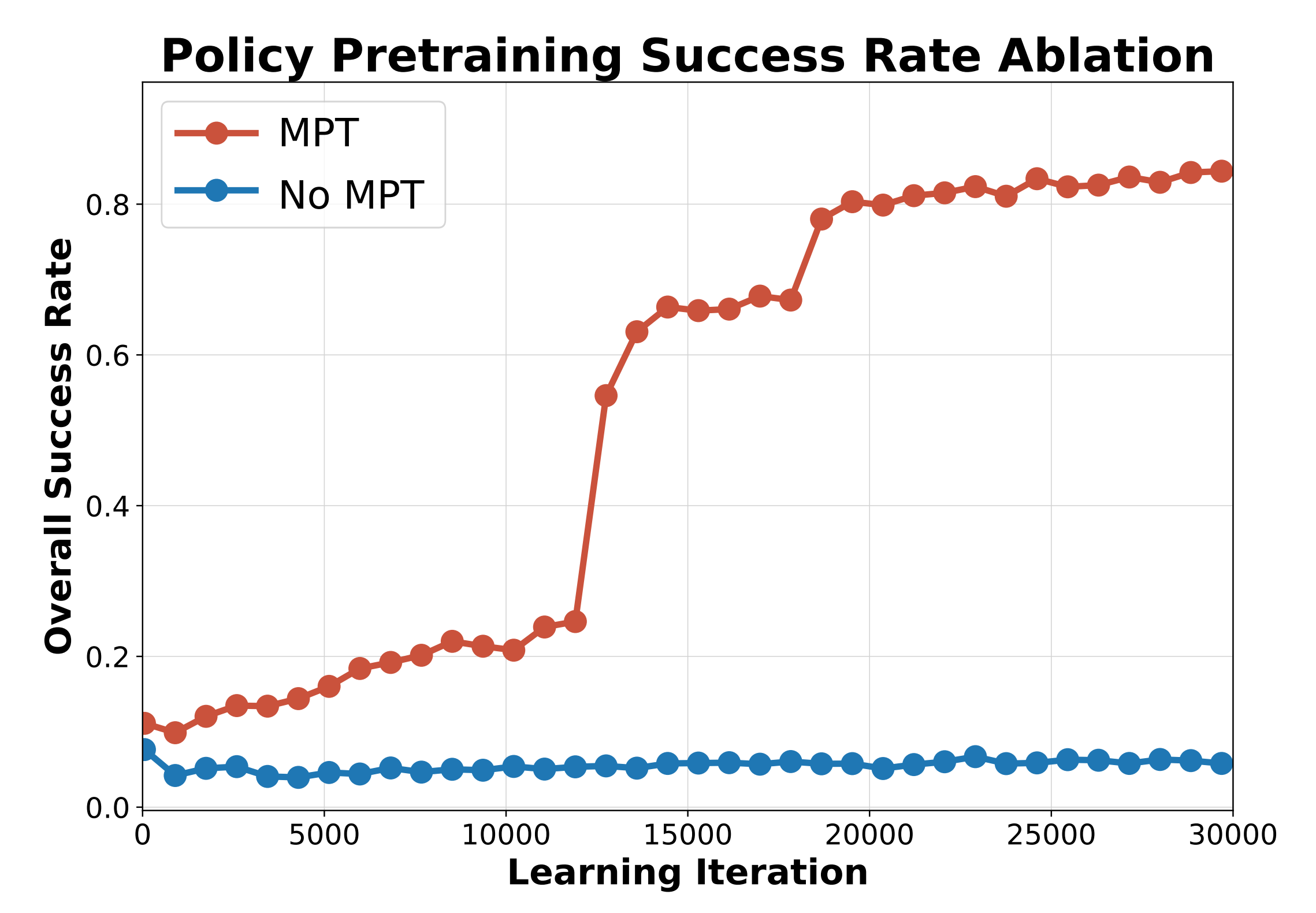
- MPT消融分析
作者分析了在运动捕捉数据上进行预训练的影响。MPT具有多重作用:
首先,参考动作本身存在噪声,因此从零开始学习追踪这些动作更加困难
其次,机器人初始位置通常并不完全静态稳定,或者可能与场景存在一定的穿插现象。因此,MPT能够帮助在初始阶段稳定学习,而从头开始训练的策略甚至可能无法学会如何保持平衡如图6所示,去除MPT会显著削弱策略学习有效行为的能力
1.2 后sim中的策略训练:策略学习的4个步骤
根据剪辑和场景中的运动学参考,策略学习流程能够生成一个基于上下文的策略,该策略在适当的环境上下文提示下,可以执行参考中的技能。图3展示了流程的概览——仿真中的策略训练
简言之
- 该强化学习训练流程始于一组动作捕捉轨迹数据
- 随后,引入高度图观测,并在不同环境中跟踪来自视频的全身参考轨迹
- 接下来,将策略蒸馏为仅依赖机器人根部位置信息的条件策略
- 然后,使用相同的精简观测集,直接通过强化学习微调该策略
该流程受到三个目标的驱动:
a)生成快速且忠实于原始视频示范的动作;
b)确保观测在真实世界环境中可用;
c)训练一个通用策略,将所有视频示范的知识蒸馏到单一模型中,使其适用于训练集之外的场景
具体而言
- 策略学习
采用Rudin等人[54]实现的近端策略优化(Proximal Policy Optimization, PPO)[53]来训练我们的策略
且学习过程在IsaacGym模拟器[12]中进行。有关方法的详细公式和超参数,请参阅Sec.B
如原论文的附录「B.1 强化学习设置与训练」所说,作者使用PPO 算法[53]
- 采用折扣因子γ = 0.99,以及GAE 参数λ = 0.95。且使用自适应学习率,目标KL 为0.02
对于自适应学习率,采用1.2,而不是通常的1.5的学习率变化,因为发现这样可以加快训练速度
在从零开始进行强化学习时,作者将学习率(该值会被自适应KL 机制调整)初始设为1e −3,但在微调时,作者发现从非常低的学习率2e −5 开始非常重要,以防止在所有环境开始时,数据分布在剧集初期存在偏差时,高学习率的早期更新破坏已有的检查点- 作者使用最大梯度范数为1.0。每次采样使用5 个学习周期,采样长度为24
作者的熵系数设置为0.0025
且使用2× NVIDIA 4090 GPU 进行训练,每张GPU 有4096 个环境(因此总共有效环境数为8192)
作者使用具有4 层的MLP,各层维度分别为[1024, 512, 256, 128]
- 观测
策略依赖于本体感受和目标相关的观测。本体感受输入包括机器人关节位置(q)、关节速度( ˙q)、角速度(ω)、重力矢量投影(g)以及前一时刻的动作(at−1)的历史信息;在实际操作中,我们使用长度为5 的历史序列
此外,策略还接收局部目标观测:目标关节角度、目标躯干横滚和俯仰角,以及期望的躯干方向,这些由机器人当前躯干位置与目标躯干之间的相对x-y 偏移和偏航角指定,均在机器人本体坐标系中表达对于依赖高度图的策略,作者还提供躯干周围的高程图。该高程图表示为一个11 × 11 的网格,采样间隔为0.1 m,用于捕捉局部地形几何信息
最后,评论者还会接收额外的特权观测,具体详见表3
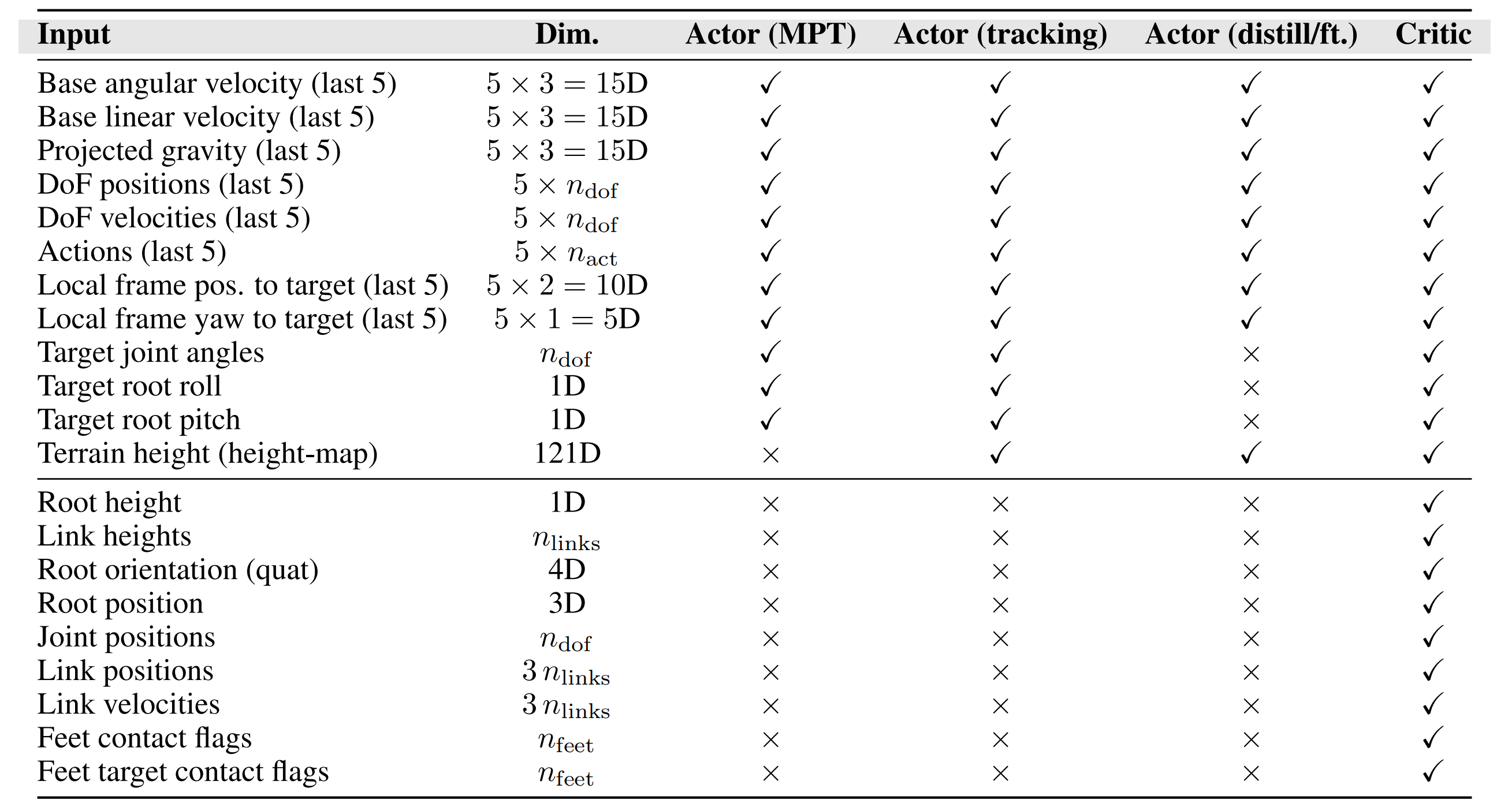
如原论文附录「B.2 观测」所说
- 表3「每个网络的观测项:动作捕捉预训练(MPT)actor、动作追踪actor、蒸馏/微调actor,以及critic。此处对于Unitree G1,dof=23」,详细列出了actor和critic的观测内容
作者注意到,与图形学领域的相关工作[1,3]不同,actor获得的所有非特权观测均可在真实机器人上获取
- 此外,在训练期间,目标根参考被输入到全局坐标系中,以确保其与地形对齐。因此,与[5,8]不同,作者能够利用全局根参考来训练策略,使他们的策略能够在较长时间范围内正确模仿世界坐标系中的参考动作,这对于准确模仿与地形相关的运动至关重要
- 批量跟踪
VideoMimic系统采用了DeepMimic[1]的批量变体,以利用强化学习学习模仿动作
且作者实现了参考状态初始化(Reference State Initialization)[1],并结合了类似于Tessler等人[55]的动作负载均衡机制,对成功率较低的动作进行加权
- 对于动作
如附录「B.3 动作」所说,作者按照[54]的方法,在策略网络输出端采用无激活函数的无限制动作。然而,参照[68],作者将动作裁剪到预设范围,以防止策略在训练早期学习到“开关式”控制,并且为策略网络增加了如下形式的“边界损失”,以在输出层强制施加该限制:
其中表示每个维度的策略动作。作者为该损失项使用了0.0005 的系数。对于G1 humanoid,作者将动作幅度限制为8.0。在实验过程中,他们的初始动作标准差设为0.8
- 对于仿真参数
以200Hz的频率运行Isaac Gym [12],控制稀疏因子为4,因此策略的实际时间步长为0.02秒。作者将最大去穿透速度设置得特别低——为0.1米/秒——以防止在参考动作过程中偶尔与地形发生穿透时出现过大的速度由于 IsaacGym 中存在一个未被记录的漏洞,模拟器会将处于不同虚拟且理论上隔离的“环境”中的机器人之间的碰撞注册为有效碰撞,前提是它们占据了相同的世界坐标空间。这会导致内存使用量急剧增加,并显著降低模拟器的吞吐量
为了解决这一问题——在模拟器中处理地形,在对单个片段或少量片段进行训练时,作者会复制任务地形,并将机器人生成点在空间上分布开,以减少机器人之间的碰撞
- 奖励
他们的强化学习奖励完全围绕数据驱动的跟踪项设计——具体包括连杆和关节位置、关节速度以及足部接触信号——因此可以将原始演示数据以最少的人工调参转化为可物理执行的动作。目标有两个:
(1)减少对通常通过奖励工程引入的手工先验的依赖;
(2)确保生成动作的物理可行性。这两个目标可能存在冲突:由于参考轨迹完全来自于人类的纯运动学数据,精确跟踪可能导致非物理性的动作
因此,作者引入了动作速率惩罚以及其他若干惩罚准则,以防止利用模拟器物理漏洞。完整的公式和权重详见Sec.B.1
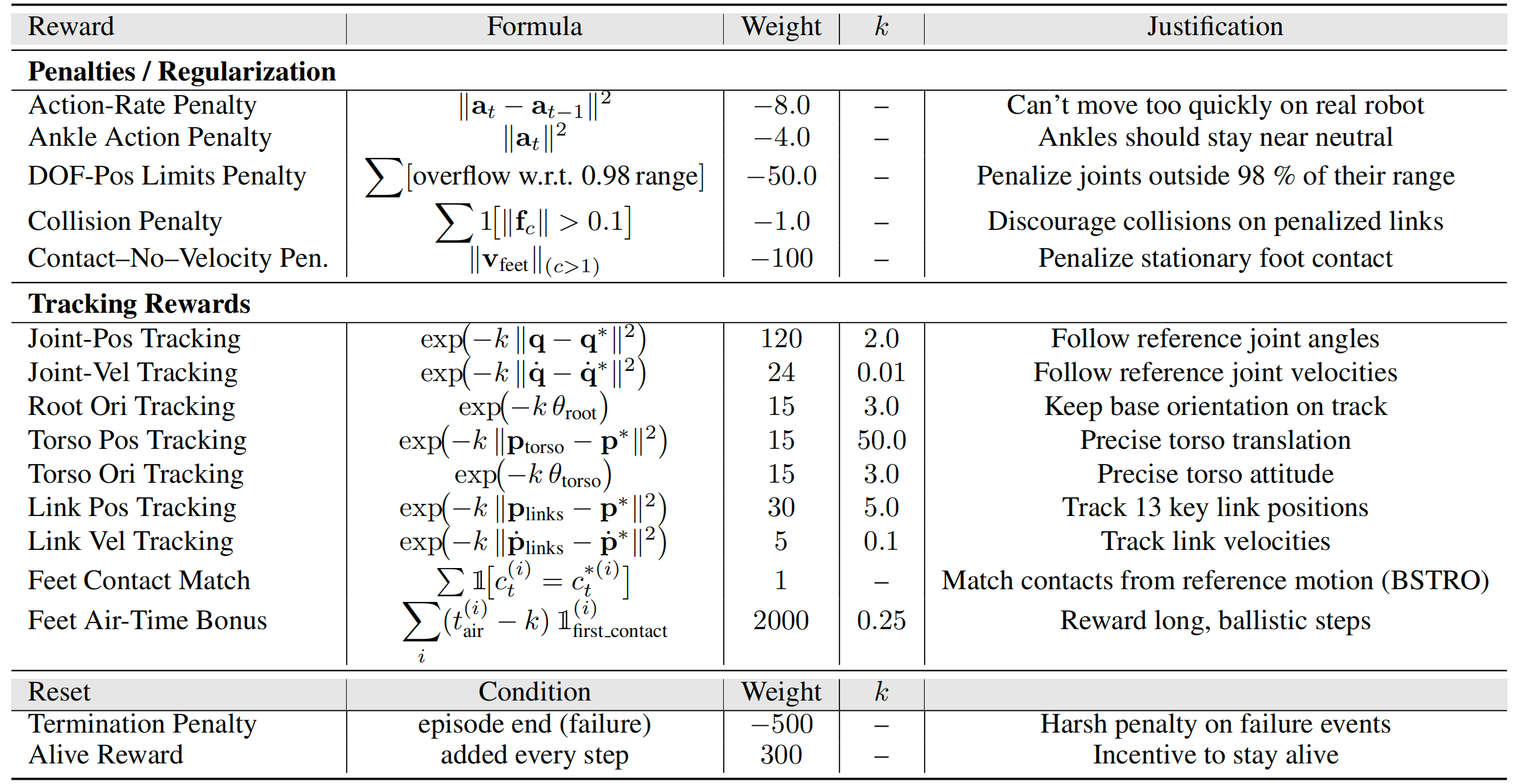
如原论文附录「B.5 奖励函数设计」所说,作者最关心的是构建一个能够接收数据并生成新物理动作的系统;因此,奖励主要由数据驱动项组成——包括跟踪连杆和关节的位置与速度,以及匹配足部接触,且几乎没有重新加权
在奖励设计中,有两个目标:
- 首先,尽量减少通过奖励工程向强化学习跟踪中注入的人工先验的强度
- 其次,生成物理上可行的动作
需要注意的是,这两个目标存在一定的矛盾,因为运动学数据来自人类,若完全精确地跟踪,则会导致非物理的动作。此外,作者还设定了若干惩罚标准,包括动作速率惩罚,以及两个用于防止利用仿真器物理漏洞的惩罚项
下表表4详细列出了用于策略学习的奖励项「奖励项、对应权重以及缩放因子k。这些奖励在各训练阶段保持不变。然而,作者会将动作速率和踝关节动作惩罚分别从0.2和0.0逐步调整到表中给定的数值」
如附录「B.6 终止准则」所说,终止准则取决于机器人所跟踪连杆关节的最大误差。如果在训练过程中的任何一步,笛卡尔误差超过终止阈值,则该回合终止
- 在MPT阶段,作者将该阈值设置为0.3
- 在地形跟踪阶段,由于视觉参考有时较为噪声,将其设置为0.5(阈值越高越好)
- 在RL微调阶段,我们将其设置为1.2。微调阶段阈值较高的原因在于,在强化学习过程中,非常关注恢复行为和多样性的保证,而这些在我们所用数据集规模的常规DeepMimic式训练中并不常见(实际上,如果容差过于严格,则恢复行为根本不会出现)
因此,在保持相同跟踪奖励的前提下,采用较宽松的终止容差,有助于在数据中保留动作的本质,同时实现强大的恢复行为
接下来,咱们更加详细的介绍策略训练的4大阶段
1.2.1 策略训练阶段1:动作捕捉预训练(MoCap Pre-Training)
动作捕捉预训练使策略能够从噪声较大的视频重建中学习复杂技能,同时最大程度减少手工设定的先验知识,并实现从人类到机器人具身差距
- 早期的相关工作要么通过多智能体强化学习采样起始姿态 [3],要么通过特权模拟器模仿动作 [5]
Radosavovic 等人 [21] 和 Singh 等人 [56] 则采用了一种基于人体数据的运动学预训练方法 - 作者采用了一种更简单且有效的策略:首先在 MoCap 轨迹上对策略进行预训练,然后在重建的视频数据上进行微调——这两个阶段均在物理模拟器中使用强化学习
即使是仅基于 MoCap 的策略,也可以像图9所示直接部署到真实机器人上

且作者使用了 LAFAN 动作捕捉数据集 [57- Robust motion in-betweening],并将其重定向到 Unitree G1
对于预训练的策略,策略接收到的条件包括目标关节角度、目标根部横滚/俯仰角以及期望的根部朝向
1.2.2 策略训练阶段2:场景条件跟踪(Geometry-Aware Tracking)
- 在 MoCap 预训练之后,从 MPT 检查点初始化策略,并通过对环境高度图进行条件化来引入场景感知。高度图通过投影方式以残差形式集成到 MPT 策略的潜在空间中,初始权重为 0
- 随后,随机采样动作,并在重建的地形上执行 DeepMimic 风格的跟踪。在此阶段,策略持续接收与动作相关的跟踪条件,包括目标关节角度、躯干横滚/俯仰以及期望的躯干朝向
1.2.3 策略训练阶段3:蒸馏(Distill with Root-Condition)
- 在批量跟踪阶段之后,作者通过DAgger [2]对策略进行蒸馏,使其无需观测目标关节角度或根部横滚/俯仰观测
- 随后,作者能够利用期望的根部方向观测作为调节信号来控制机器人的位置,这一信号既可以来自操纵杆,也可以由高级控制器提供的路径
因此,本框架将此前分离的操纵杆跟踪和全局参考跟踪方法统一起来。他们的蒸馏策略受益于教师策略同样经过观测随机化训练,因此在一定的不确定性下学习动作,这与直接用全身观测训练相比有所不同;已有研究表明,这种方式在其他策略学习场景中也是有益的 [58]
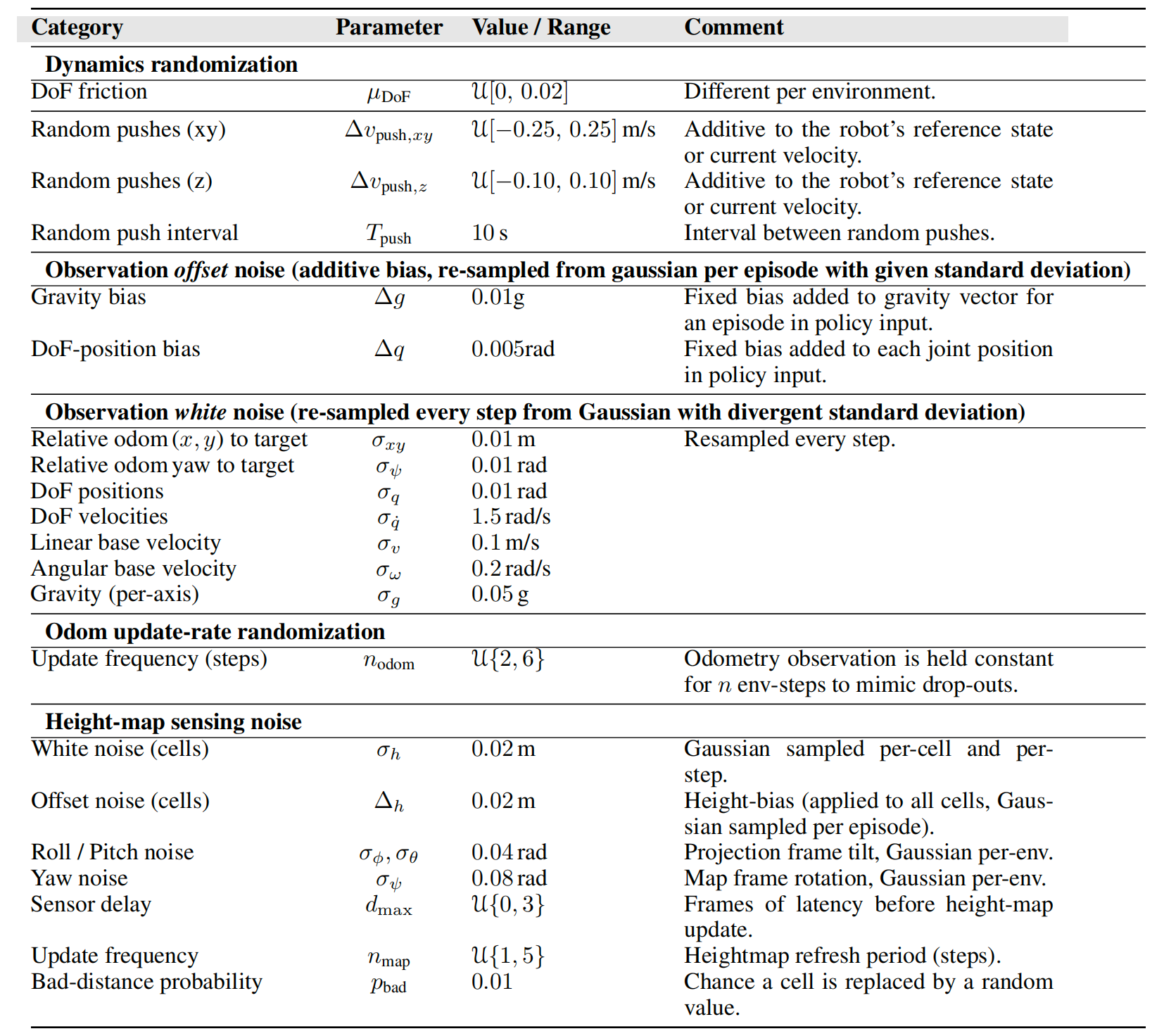
如附录「B.7 域随机化」所说,作者在仿真中引入了多种域随机化,以模拟模拟器中各种未建模物理效应的影响,从而获得更具鲁棒性的策略
具体细节见表5「训练过程中使用的领域随机化和噪声设置。“Offset”项在每个回合内保持固定;“white”项在每个仿真步重新采样。更新频率变量通过在随机步数内保持观测值不变,以模拟低速率传感器」
1.2.4 策略训练阶段4:欠约束的RL微调
在将作者的策略蒸馏为仅以轨迹根节点为条件后,会进行新一轮的强化学习。这是因为基于目标关节条件学习到的行为,对于不以这些目标为条件的策略来说,可能并不是最优的
实际上,作者发现与蒸馏策略相比,这一步骤可以显著提升性能
此外,这一过程还允许将质量较低的参考动作添加到参考集合中,因为移除actor的目标后,实际上使得奖励信号变成了“数据驱动”,而欠约束的actor能够根据上下文跟随更合适的参考动作
1.3 最后Sim2Real:sim中训练好之后,部署到真实机器人上
1.3.1 设置
作者将在23 自由度的Unitree G1 人形机器人上部署我们的控制器,并在机器人本地以50 Hz 的频率运行。按照[61],我们设置了相对较低的关节增益,Kp = 75,以避免过快或过于僵硬的行为:这有助于避免机器人与椅子或楼梯等物体发生剧烈接触时出现过于猛烈的碰撞
高度图通过Fast-lio2 [62] 和概率地形映射[63, 17] 实时计算。我们从人工操作员处输入遥控杆目标。包括策略运行在内,所有操作均在本地运行
通过多次仿真到现实的迭代试验,作者发现实现运动部署成功有两个关键因素:
- i) 放宽与参考运动相关的回合终止容差
- ii) 在训练过程中注入真实的物理扰动。完整细节见Sec. C
如论文附录「C 机器人部署」所说
- 作者在C++ 中使用ROS 和Unitree SDK 2 实现部署代码,以便在板载Jetson Orin NX 上以50Hz 的速度快速运行
- 且对所有关节使用Kp = 75 和Kd = 2 的增益,除了踝关节,在踝关节上,分别对roll 和pitch 使用Kp = 20,Kd = 0.1 和Kd = 0.2,参考文献[61]
且在实际部署阶段,作者采用了渐进式评估方法来部署他们的策略,以便在现实世界中逐步调试能力
- 第一阶段是能够跟踪来自MPT策略的动作捕捉数据
- 随后,对在大规模数据集上训练的动作捕捉策略进行了蒸馏,以测试不同的蒸馏方法;通过这一过程,作者发现以根部位置为条件优于以根部速度为条件
- 最后,作者开始部署基于高度图条件的完整流水线蒸馏策略。图9展示了其中两个示例
1.3.2 实际环境评估
图5及附带视频展示了该策略在 Unitree G1 上执行多种全身行为

- 无需针对特定任务进行调整,同一个网络仅依赖本体感知和带噪声的 LiDAR 高度图(可提供完整的 360° 信息)即可驱动。环绕躯干视角——能够攀爬和下楼梯(包括室内和室外),穿越陡峭的土坡和崎岖的植被,并能可靠地在椅子和长凳上坐下或站起
该控制器表现出令人惊讶的鲁棒性:在下楼梯过程中,脚意外打滑时,它能够通过短暂地单腿跳跃来恢复,并重新获得正常步态
- 且据作者所知,这是首个在现实世界中部署的基于单目人类视频学习的上下文感知类人策略,能够同时展示感知驱动的行走以及由环境触发的全身技能,如坐下、站立和上下楼梯。更多定性结果可在项目网页上查看
1.4 结论与局限性
1.4.1 结论
总之,VideoMimic,是一种从真实到仿真再回到真实的流程,能够将日常人类视频转化为针对环境的仿人控制策略
该系统包括:
- i) 从单目视频片段中重建人类及其周围几何环境
- ii) 将动作重定向到运动学可行的仿人机器人
- iii) 利用恢复出的场景作为动态感知强化学习的任务地形
最终,系统生成的单一策略能够实现稳健且可重复的情境控制——例如,仅通过环境几何与根部方向指令即可驱动仿人机器人上下楼梯、坐下和站起等动作
VideoMimic为从视频直接教会仿人机器人情境技能提供了可扩展的路径。作者预计未来的工作将拓展该系统,以实现更丰富的人-环境交互、多模态传感器驱动的情境学习以及多智能体行为建模等方向
1.4.2 局限性
VideoMimic在实际应用中取得了令人鼓舞的效果,但仍存在一些实际的不足
- 重建
在自然环境中,单目4D人-场景恢复仍然较为脆弱。MegaSaM中的相机位姿漂移常常导致同一表面出现重复的“幽灵”层。由于无法对动态点进行精细调整,来自人物的动态点会被错误地融合到静态点云中,或被不准确地放置(例如,脚部被埋在环境下方)特别是,作者发现MegaSaM在低纹理图像上的表现较差。深度过滤和时空子采样能够去除大量离群点,但过于激进的阈值会留下妨碍网格生成的空洞
NKSR可以减轻噪声,但可能会过度平滑细节几何结构(如狭窄的楼梯踏步);而这些高频细节对于机器人控制至关重要,因此在重建后缺失这些细节的视频会被舍弃此外,在点到网格的转换过程中,离散点还可能导致出现尖刺伪影
- 重定向
运动学优化器假设每一个参考姿态在缩放到机器人后都可以实现
然而,在杂乱的场景中,这一假设并不总是成立,严格的足部接触匹配与避障之间的冲突性代价可能会使求解器陷入较差的局部极小值,之后需要强化学习控制器进行“修正” - 感知与策略输入
在测试阶段,控制器仅接收本体感知和一个11×11的LiDAR高度图。这种粗略的网格对于地形和椅子来说已经足够,但对于精确接触、操作或推理悬空障碍物而言分辨率不足引入更丰富的感知输入——如RGB-D数据或学习得到的占据网格——可能会拓宽该方法的适用范围,并提升其对环境的语义理解能力
- 仿真保真度
作者假设场景可以用单一刚性网格来表示。扩展到关节型或可变形物体则需要更具表现力的仿真器和物体级重建管线——这仍是未来工作的开放问题 - 数据规模与运动质量
蒸馏策略仅在123段视频片段上进行训练,并且偶尔依赖于恢复行为,导致动作出现卡顿。更大且更具多样性的视频语料库以及迭代的真实世界微调,有望提升动作的平滑性和鲁棒性。突破这些限制——通过更优的动态与静态分离、更具抗干扰能力的网格化处理、自适应的重定向成本、更丰富的感知能力以及更大规模的数据集——是未来研究的关键方向
// 待更


