AI 大模型基础:医学影像大模型(Med-PaLM、CheXNet)的原理、实现与应用(二)_医疗影像大模型

🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C++, C#,Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C++、C#等开发语言,熟悉Java常用开发技术,能熟练应用常用数据库SQL server,Oracle,mysql,postgresql等进行开发应用,熟悉DICOM医学影像及DICOM协议,业余时间自学JavaScript,Vue,qt,python等,具备多种混合语言开发能力。撰写博客分享知识,致力于帮助编程爱好者共同进步。欢迎关注、交流及合作,提供技术支持与解决方案。\\n技术合作请加本人wx(注明来自csdn):xt20160813
AI 大模型基础:医学影像大模型(Med-PaLM、CheXNet)的原理、实现与应用(二)
本文进一步针对 Med-PaLM(多模态语言-影像模型)和 CheXNet(基于 CNN 的胸部 X 光模型)进行讲解,结合 Transformer 架构的自注意力机制和编码器结构,深入探讨医学影像大模型的原理、实现和应用。新增内容包括详细数学推导、可解释性方法、优化后的 Mermaid 流程图、扩展的 Chart 图表,以及真实数据集的代码实现。文章结构如下:
- 医学影像大模型概述:定义、背景、意义与挑战。
- Med-PaLM:多模态原理、实现(结合 ViT 和 BERT)、应用。
- CheXNet:CNN 原理、实现(基于 DenseNet-121)、应用。
- 流程图:优化 Mermaid 流程图,涵盖训练和推理。
- 图表:性能对比、训练时间和可解释性分析。
- 总结与展望:关键点总结、联邦学习展望。
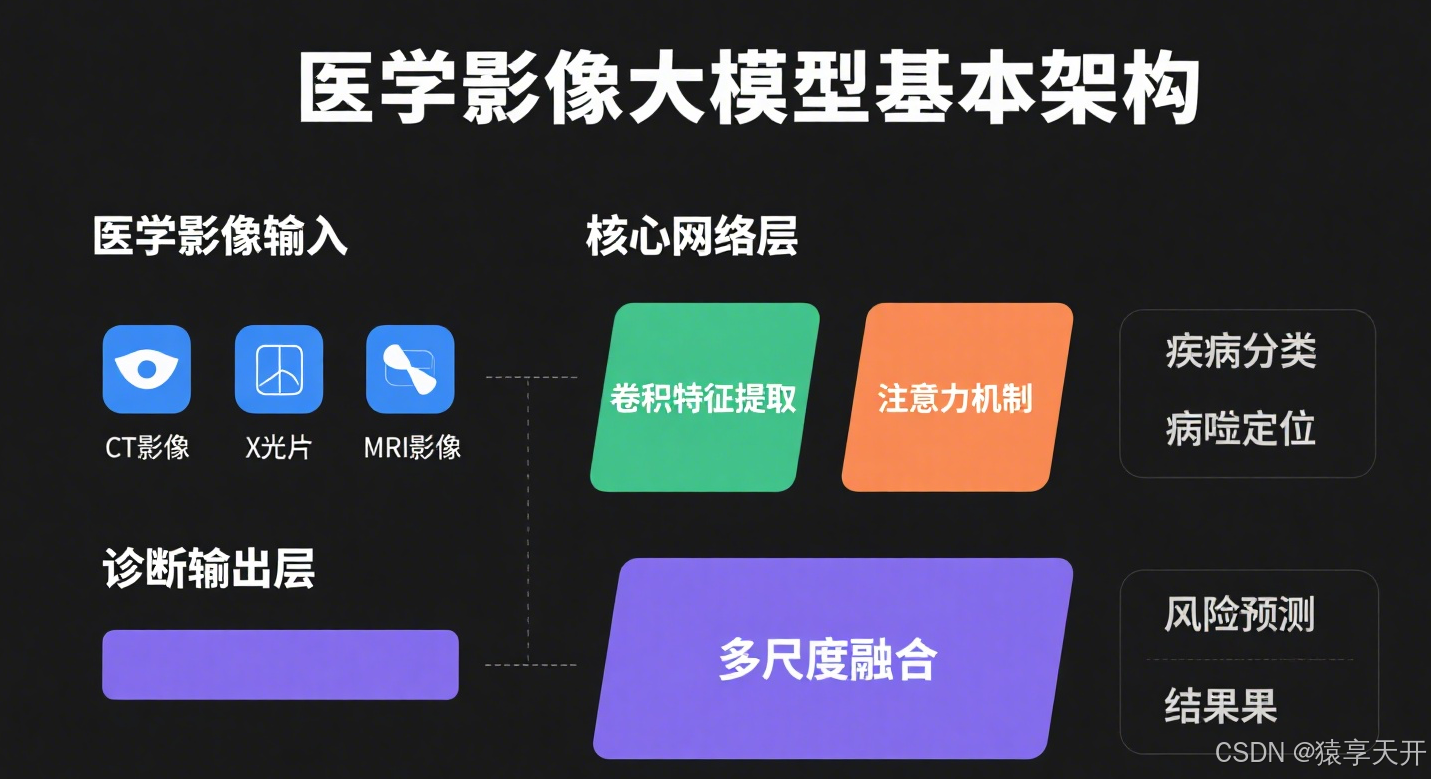
一、医学影像大模型概述
1.1 定义与目标
医学影像大模型是利用深度学习(CNN、Transformer 等)处理高维医学影像(如 X 光、CT、MRI)和文本(如病历、报告)的大型模型,目标包括:
- 疾病分类:识别疾病类型(如肺炎、肺癌)。
- 病灶分割:精准定位病变区域(如肿瘤、肺结节)。
- 多模态诊断:结合影像和文本,提供综合诊断。
- 自动化报告:根据影像生成诊断报告。
1.2 发展背景
- 传统方法(2000s):基于手工特征(如 HOG)和传统机器学习(如 SVM),精度低,泛化性差。
- CNN 时代(2012-2018):AlexNet、ResNet、DenseNet 等 CNN 模型推动影像处理进步,CheXNet(2017)实现胸部 X 光自动化诊断。
- Transformer 时代(2020s):Vision Transformer (ViT) 和多模态模型(如 Med-PaLM)引入,结合影像和文本,提升复杂任务性能。
- 医学影像挑战:
- 数据稀缺:高质量标注数据少,成本高。
- 类不平衡:疾病样本(如恶性肿瘤)远少于正常样本。
- 高维复杂性:CT/MRI 数据包含三维空间信息。
- 可解释性:医生需了解模型决策依据。
1.3 重要性
- 临床效率:加速诊断,减少误诊(如漏诊肺结节)。
- 数据效率:预训练+微调,适配小数据集。
- 多模态融合:结合影像和文本(如 Med-PaLM),提供更全面诊断。
- 可扩展性:适配多种影像类型(X 光、MRI、超声)。
1.4 挑战
- 数据隐私:受 HIPAA、GDPR、中国的《个人信息保护法》等法规限制。
- 计算成本:大模型训练需高性能 GPU/TPU。
- 可解释性:需提供可视化依据(如注意力图、Grad-CAM)。
- 伦理问题:避免模型偏见,确保公平性。
二、Med-PaLM(多模态医学大模型)
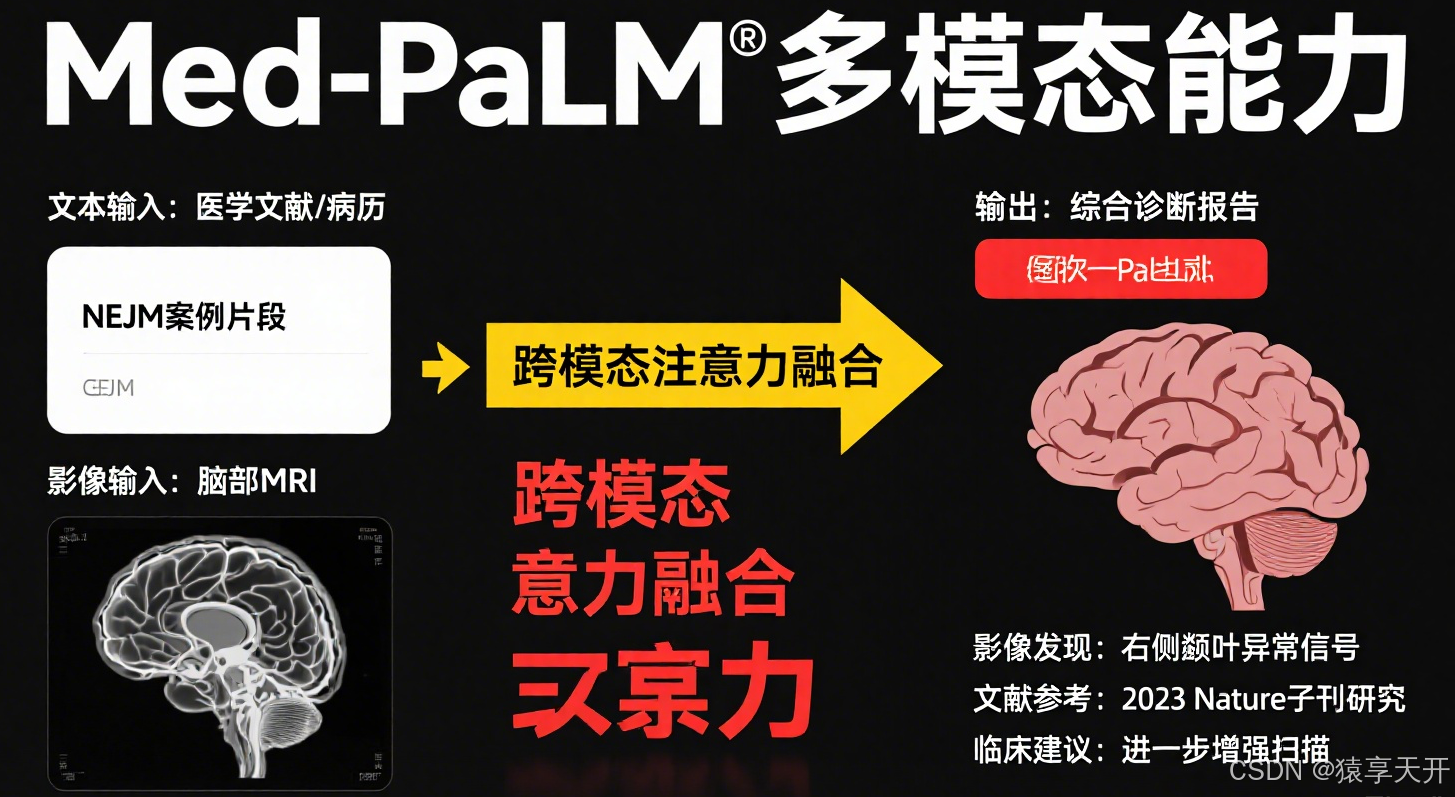
2.1 原理
Med-PaLM 是 Google 开发的基于 PaLM 的多模态模型,结合语言(Transformer 解码器)和影像(Vision Transformer, ViT)处理,专为医疗任务设计。
核心机制
- 多模态架构:
- 语言模块:基于 PaLM(类 GPT 的 Transformer 解码器),处理医学文本(如病历、报告)。
- 影像模块:基于 ViT,将影像分块(Patch)后处理为序列,类似 Transformer 的自注意力机制。
- 融合模块:跨模态注意力整合文本和影像特征。
- 预训练任务:
- 语言:自回归语言建模,预测下一词,基于医学文献(如 PubMed)。
- 影像:分类(疾病标签)或对比学习(相似影像对齐),基于 MIMIC-CXR、CheXpert 等数据集。
- 多模态:联合预训练,学习影像-文本对齐(如 X 光与诊断报告)。
- 微调:适配特定任务,如疾病分类、报告生成、医学问答。
- 自注意力(ViT):
- 将影像分割为固定大小的 Patch(如 16×16 像素)。
- 每个 Patch 嵌入为向量,加入位置编码。
- 使用多头自注意力(类似 Transformer 编码器)捕捉 Patch 间关系。
- 跨模态注意力:
- 文本特征作为查询(Q),影像特征作为键(K)和值(V),计算跨模态依赖。
数学基础
- ViT 自注意力:
Attention(Q,K,V)=softmax(QKTdk)V \\text{Attention}(Q, K, V) = \\text{softmax}\\left(\\frac{QK^T}{\\sqrt{d_k}}\\right)V Attention(Q,K,V)=softmax(dkQKT)V - Q,K,V∈Rn×dkQ, K, V \\in \\mathbb{R}^{n \\times d_k}Q,K,V∈Rn×dk,nnn 为 Patch 数量,dkd_kdk 为嵌入维度。- dk\\sqrt{d_k}dk:缩放到防止点积过大。
- 跨模态注意力:
Attention(Qtext,Kimage,Vimage)=softmax(QtextKimageTdk)Vimage \\text{Attention}(Q_{\\text{text}}, K_{\\text{image}}, V_{\\text{image}}) = \\text{softmax}\\left(\\frac{Q_{\\text{text}}K_{\\text{image}}^T}{\\sqrt{d_k}}\\right)V_{\\text{image}} Attention(Qtext,Kimage,Vimage)=softmax(dkQtextKimageT)Vimage - Qtext∈Rm×dkQ_{\\text{text}} \\in \\mathbb{R}^{m \\times d_k}Qtext∈Rm×dk,mmm 为文本序列长度。- Kimage,Vimage∈Rn×dkK_{\\text{image}}, V_{\\text{image}} \\in \\mathbb{R}^{n \\times d_k}Kimage,Vimage∈Rn×dk,nnn 为影像 Patch 数量。
- 损失函数:
- 语言:交叉熵损失:
Ltext=−∑iyilog(y^i) L_{\\text{text}} = -\\sum_{i} y_i \\log(\\hat{y}_i) Ltext
- 语言:交叉熵损失:


