计算机毕业设计Hadoop+Spatk+Hive滴滴出行分析预测 网约车供需平衡优化系统 网约车分析预测 大数据毕业设计(源码+LW+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《Hadoop+Spark+Hive滴滴出行分析预测:网约车供需平衡优化系统任务书》的范例,包含任务目标、分解、技术要求、进度安排及考核标准等内容:
任务书
项目名称:基于Hadoop+Spark+Hive的滴滴出行网约车供需平衡分析与预测系统开发
项目编号:XXXX-XXXX
委托单位:XXX学院/实验室
承担单位:XXX数据科学团队
负责人:XXX
起止时间:YYYY年MM月—YYYY年MM月
一、任务背景与目标
1.1 背景
网约车平台(如滴滴出行)面临供需时空分布不均衡问题,导致乘客打车难、司机空驶率高。现有调度系统依赖静态规则,缺乏对多源异构数据(订单、轨迹、天气)的实时分析与预测能力。本项目旨在构建基于大数据技术的动态供需平衡优化系统,提升平台运营效率。
1.2 目标
- 短期目标:
- 实现基于Hadoop+Spark+Hive的网约车数据存储与处理框架;
- 开发供需预测模型,预测未来15分钟网格区域订单需求与司机供给,误差率≤15%;
- 输出司机调度建议,降低空驶率10%以上。
- 长期目标:
- 形成可复用的城市交通供需分析方法论,支持多城市扩展;
- 申请软件著作权1项,发表核心期刊/国际会议论文1篇。
二、任务分解与分工
- 整合天气、交通事件等外部数据;
- 清洗异常值(如GPS漂移点)、填充缺失值。
- 使用Hive构建数据仓库,定义订单、司机、区域等数据表;
- 部署Spark计算引擎,优化资源分配(Executor内存/核心数)。
- 开发LSTM+Attention模型,捕捉突发需求(如演唱会散场);
- 对比模型效果(MAPE、RMSE),选择最优方案。
- 结合供需预测结果,生成价格系数(α值)调整方案;
- 模拟测试调度策略对订单完成率的影响。
- 部署Lambda架构,批处理层(Hive)处理历史数据,速度层(Spark Streaming)处理实时数据;
- 压力测试(模拟10万级并发请求)。
三、技术要求与规范
3.1 数据规范
- 数据格式:
- 订单数据:CSV/JSON,包含字段
order_id, passenger_id, driver_id, start_time, end_time, start_lon, start_lat, price; - 轨迹数据:GeoJSON,每条记录包含
driver_id, timestamp, lon, lat, speed。
- 订单数据:CSV/JSON,包含字段
- 数据脱敏:
- 乘客/司机ID需通过MD5哈希加密;
- 地理位置数据保留到街道级(GeoHash编码前6位)。
3.2 模型要求
- 预测粒度:
- 空间:500m×500m网格;
- 时间:15分钟间隔。
- 性能指标:
- 模型训练时间≤2小时(100GB数据);
- 实时预测延迟≤500ms。
3.3 系统要求
- 集群配置:
- Hadoop:3台虚拟机(8核16GB内存,Ubuntu 20.04);
- Spark:Standalone模式,Executor内存分配为4GB/核。
- 接口规范:
- 供需预测API:RESTful接口,输入
grid_id, timestamp,输出demand_score, supply_score; - 调度建议API:返回
driver_id, suggested_lon, suggested_lat。
- 供需预测API:RESTful接口,输入
四、进度安排与里程碑
五、考核指标与验收标准
5.1 考核指标
- 功能指标:
- 支持10万级司机/乘客数据实时处理;
- 供需预测模型MAPE≤15%。
- 性能指标:
- 系统吞吐量≥5000订单/秒;
- 调度策略提升订单完成率≥15%。
5.2 验收标准
- 文档验收:
- 提交《设计文档》《测试报告》《论文初稿》;
- 代码注释覆盖率≥30%,符合Google Java Style规范。
- 系统验收:
- 在滴滴公开数据集(如DiDi Chuxing GAIA Initiative)上复现实验结果;
- 专家评审通过率≥80%。
六、经费预算
七、注意事项
- 数据安全:
- 严禁将原始数据导出至本地,所有分析需在集群内完成;
- 定期备份HDFS数据至对象存储(如AWS S3)。
- 知识产权:
- 代码归属团队所有,需在GitLab私有仓库管理;
- 论文投稿前需通过团队内部查重(相似率≤15%)。
委托单位(盖章):
负责人签字:
日期:
说明:
- 实际任务书需根据学校/企业模板调整格式;
- 若涉及企业合作,需补充《数据使用协议》和《保密承诺书》;
- 模型部分可引用滴滴技术博客(如滴滴技术)中的公开方法。
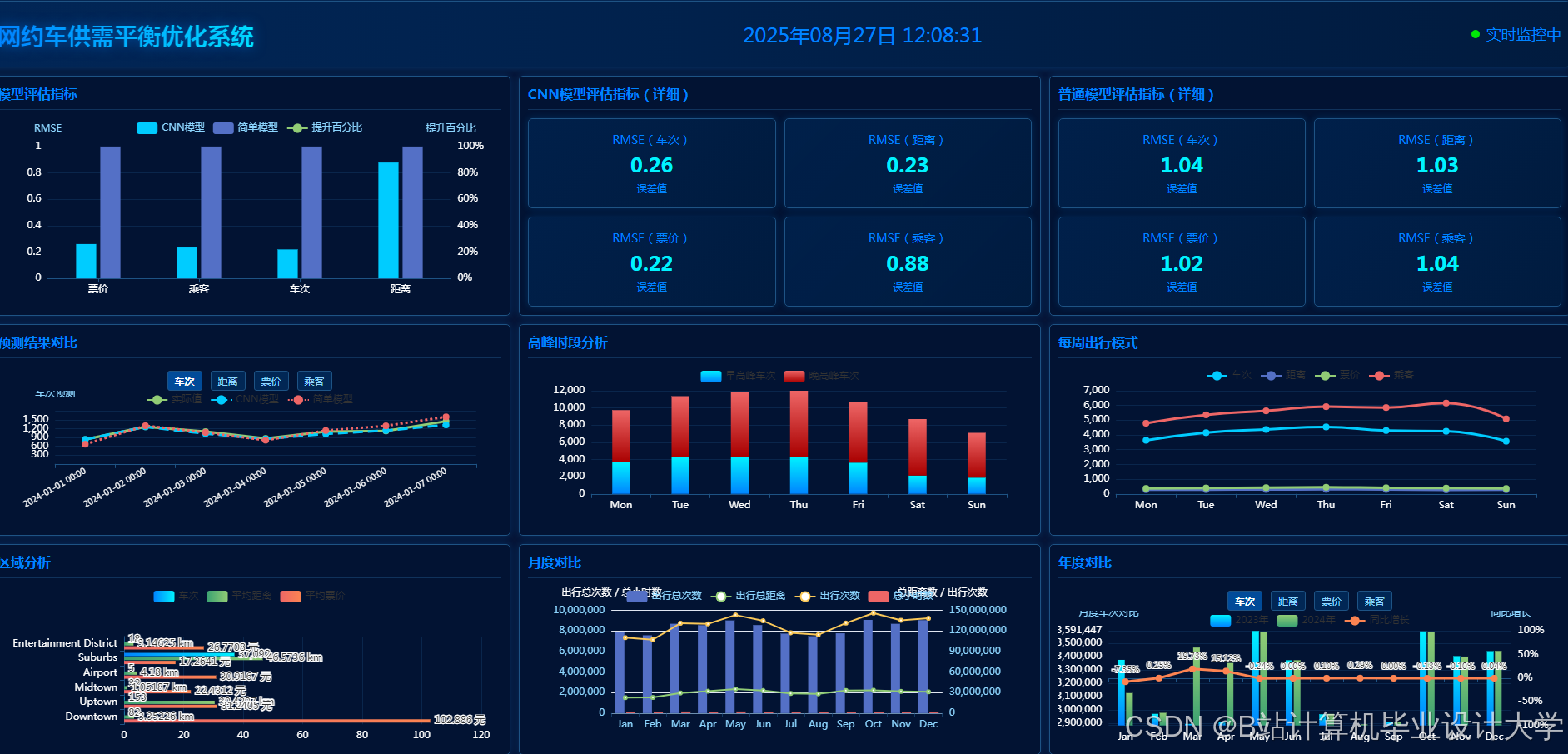
运行截图
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


