Linux云计算集群装机与PXE技术课件资料
本文还有配套的精品资源,点击获取 
简介:Linux运维在企业级系统管理中扮演核心角色,特别是在云计算领域,高效的集群装机技术如PXE(Preboot Execution Environment)变得至关重要。本课件资料深入探讨PXE技术在Linux云计算环境中的应用,包括其在网络启动中的优势、工作流程、ISO映像和kickstart自动化脚本的使用,以及在高可用性、负载均衡和故障切换方面的实现。同时,课件内容还涵盖Linux运维中的关键工具,如系统监控、日志管理和性能分析。
1. Linux运维基本概念
Linux运维是保障企业级Linux系统稳定、高效运行的不可或缺的技术领域。它涉及操作系统安装、配置、监控、维护以及故障处理等多个方面。本章将概述Linux运维的基本概念,以帮助读者构建坚实的理论基础,并为进一步深入学习PXE技术及集群装机等高级主题打下良好开端。
在Linux系统中,运维工程师需要确保系统安全性、高效性和稳定性。这包括但不限于系统的安装与配置、网络配置、用户和权限管理、系统监控、故障诊断和修复以及性能调优等。为了有效地执行这些任务,运维工程师通常会利用各种工具和脚本来自动化这些流程,减少手动操作带来的错误和时间消耗。
理解Linux运维的基本概念是成长为一名高级Linux系统管理员的第一步。下面的章节将详细探讨PXE技术,并说明如何通过其优势和应用场景来提升系统部署的效率和可扩展性。让我们开始深入PXE的世界,并探索如何利用这项技术简化大规模系统的部署。
2. PXE技术介绍与优势
2.1 PXE技术基础
2.1.1 PXE技术定义
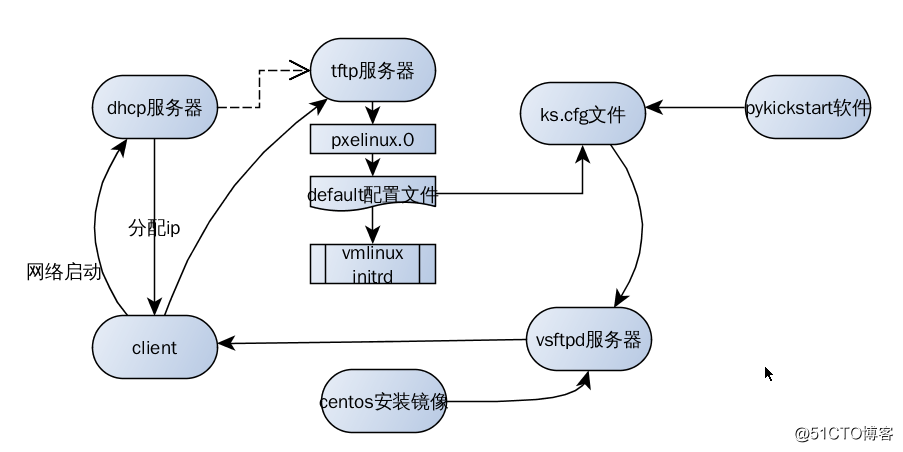
PXE,全称Preboot eXecution Environment,指的是在计算机启动过程中通过网络接口进行启动的环境。它允许计算机通过网络获取启动映像,并使用这个映像启动计算机。PXE技术需要服务器支持,即PXE服务器,其主要作用是为网络中的客户端计算机提供启动文件、配置文件以及其他操作系统安装所需的信息。
PXE技术的关键在于网络接口卡(NIC)中的一个固件模块,它称为PXE ROM。这个模块负责在计算机启动时,通过网络发送一个DHCP请求,用于获取网络信息及启动文件的位置。一旦网络启动环境被成功载入,便可以加载操作系统或其他类型的操作系统镜像。
2.1.2 PXE工作原理
PXE工作的核心是一个启动流程,涉及几个关键步骤:
-
PXE启动请求 :计算机启动时,检查是否有可用的PXE ROM。如果有,它会发出一个PXE启动请求。
-
DHCP租约 :网络中的DHCP服务器会响应PXE请求,并为客户端计算机分配一个IP地址,同时提供网络启动所需的信息,如PXE服务器的IP地址以及启动文件(通常是boot.img或者pxelinux.0)的路径。
-
TFTP下载 :客户端计算机利用TFTP(Trivial File Transfer Protocol)协议从PXE服务器下载启动文件。TFTP是一种简单的文件传输协议,适用于小型文件的快速传输。
-
引导程序执行 :客户端利用下载的启动文件进行自我引导,执行操作系统的安装过程,或者进入一个操作系统安装环境。
2.2 PXE技术的优势
2.2.1 减少人工干预
PXE技术最显著的优势之一就是减少人工干预。在没有PXE技术的情况下,需要手动给每台计算机安装操作系统,这在大规模部署时非常耗时耗力。利用PXE,计算机可以直接从网络获取操作系统镜像进行安装,无需人工将操作系统介质(如光盘或USB驱动器)插入每台计算机。
2.2.2 提高运维效率
通过使用PXE技术,IT运维人员可以远程管理大量计算机的安装与配置,大大提高了运维的效率。不仅可以实现快速部署,还可以在系统更新和维护时,通过网络分发新的配置文件或软件包,实现远程系统升级。
2.2.3 系统部署的快速响应
在需要快速部署新计算机的环境中,PXE技术能够快速响应。例如在教育机构或企业环境中,新计算机的快速部署至关重要。通过PXE,可以在短时间内为大量新计算机安装操作系统和所需的应用程序,从而满足业务的迅速展开。
graph LR A[计算机启动] --> B{检测PXE ROM} B -->|存在| C[网络启动请求] B -->|不存在| D[本地启动] C --> E[DHCP请求] E --> F[获取IP和启动文件位置] F --> G[TFTP下载启动文件] G --> H[执行引导程序] H --> I[操作系统安装/引导]根据以上PXE的工作原理,可以描绘出整个流程的流程图。在实际应用中,为了实现这一过程,运维人员需要配置DHCP服务器以及PXE服务器,以提供网络启动相关服务。
操作步骤
-
配置DHCP服务器 :
- 添加启动文件的选项,指定TFTP服务器的IP地址和启动文件名。 -
设置TFTP服务器 :
- 确保服务器有PXE启动文件,如pxelinux.0。 -
准备操作系统镜像 :
- 准备好ISO镜像,如果需要自动化安装,还需要配置kickstart文件。 -
计算机启动时网络引导 :
- 计算机开机后会自动通过网络获取启动文件,并按照上述流程完成操作系统的安装或引导。
通过这些步骤,管理员可以实现计算机的远程、无介质安装,大幅度提升了工作效率。在接下来的章节中,我们将深入探讨PXE技术在集群装机中的具体应用和工作流程。
3. 集群装机与PXE工作流程
3.1 集群装机概念与应用场景
3.1.1 集群装机的定义
集群装机指的是通过网络将操作系统部署到一组计算机(节点)上,实现快速的自动化部署。集群装机通常用于数据中心,高密度计算环境,以及需要快速部署多台服务器的场景。通过集群装机,管理员可以减少对物理硬件的直接干预,实现批量操作系统安装,系统配置以及软件部署等任务。
3.1.2 集群装机的应用场景
集群装机在多个领域具有广泛的应用,如:
- 数据中心 : 需要快速部署数百台甚至更多服务器。
- 科研机构 : 快速设置高性能计算集群(HPC)。
- 云计算服务提供商 : 需要快速构建并维护大量的虚拟机或物理节点。
- 教育机构 : 提供学生和研究人员快速访问计算资源的实验室。
集群装机大大加快了系统部署速度,降低了人力成本,同时提高了系统的可管理性和一致性。
3.2 PXE工作流程详解
3.2.1 PXE服务器的搭建
PXE(Preboot Execution Environment)服务器的搭建,主要步骤包括配置DHCP服务器、放置系统镜像和配置TFTP服务器等。下面是通过ISC DHCP Server配置PXE服务器的基本步骤:
-
安装并配置DHCP服务器 :
bash apt-get install isc-dhcp-server # 以Debian/Ubuntu为例 nano /etc/dhcp/dhcpd.conf
在dhcpd.conf文件中,添加以下配置以支持PXE启动:
conf subnet 192.168.1.0 netmask 255.255.255.0 { range 192.168.1.10 192.168.1.100; option domain-name-servers ns1.example.org, ns2.example.org; option domain-name \"mydomain.example\"; option routers 192.168.1.1; option broadcast-address 192.168.1.255; default-lease-time 600; max-lease-time 7200; next-server 192.168.1.2; # PXE服务器的IP地址 filename \"pxelinux.0\"; # PXE引导文件 } -
配置TFTP服务器 :
bash apt-get install tftpd-hpa nano /etc/default/tftpd-hpa
在tftpd-hpa配置文件中指定TFTP根目录:
conf TFTP_DIRECTORY=\"/var/lib/tftpboot\" -
放置PXE相关文件 :
将系统安装介质中的pxelinux.0、vmlinuz、initrd.img以及Kickstart文件复制到TFTP服务器根目录下。
3.2.2 客户端启动与网络引导
客户端计算机配置为从网络启动,通常在BIOS或UEFI设置中完成。当计算机启动时,它会向网络发送DHCP请求,DHCP服务器随后为客户端分配一个IP地址并提供PXE启动信息。
客户端获得PXE引导信息后,会使用TFTP协议下载 pxelinux.0 文件。之后,客户端加载并运行该引导文件,进而下载 vmlinuz 和 initrd.img 文件以进行内核初始化,最后加载Kickstart自动化安装脚本。
3.2.3 系统安装与配置
根据Kickstart文件的指示,系统安装流程可以实现无人值守自动化安装。以下是系统安装的简化步骤:
- 分区 : 根据Kickstart文件中的分区指令,对客户端硬盘进行分区。
- 格式化 : 对分区进行格式化操作。
- 安装 : 将操作系统文件安装到格式化后的分区中。
- 配置 : 根据Kickstart文件中配置部分的指令,设置系统的基本配置,如网络、主机名等。
- 软件安装 : 根据指定的软件包列表安装额外的软件包。
完成上述步骤后,系统会重启进入已安装的操作系统环境。此时,管理员可以根据需要进行后续的优化和配置工作。
在接下来的章节中,我们将深入探讨ISO映像与Kickstart自动化脚本的制作和应用,它们在集群装机过程中扮演着关键角色,不仅简化了安装流程,还为系统配置提供了一致性和可重复性。
4. ISO映像与kickstart自动化脚本
4.1 ISO映像与安装介质制作
4.1.1 ISO映像的作用
ISO映像是一种光盘映像文件格式,它包含了光盘的所有内容,包括文件系统、目录结构、文件数据以及引导信息等。在Linux运维中,ISO映像广泛应用于操作系统安装、软件分发、数据备份和灾难恢复等多种场景。
ISO映像能够完整地复现原光盘内容,因此在需要批量部署相同系统配置的场合,通过使用ISO映像可以极大地简化部署过程,提高工作效率。此外,ISO映像还可以在不同物理机、虚拟机之间快速传播,确保每个环境的一致性和标准化。
4.1.2 制作自定义ISO映像
制作自定义ISO映像通常包括以下几个步骤:
- 准备安装源 :首先需要下载或创建Linux发行版的安装源,这通常是一个或多个包含系统文件和安装脚本的ISO文件。
- 集成额外软件 :根据实际需要,在安装源中集成额外的软件包、补丁或驱动程序。这可以通过挂载ISO文件,并利用Linux的包管理工具手动添加。
- 编写Kickstart自动化脚本 :创建一个kickstart文件,该文件包含了安装过程中的所有自动化配置信息,使得在安装系统时无需人工干预。
- 构建ISO映像 :使用工具如
mkisofs或者genisoimage,将安装源和kickstart文件打包成ISO文件。在这个过程中可以指定引导加载器等额外的参数。 - 校验ISO文件 :最后,应该校验生成的ISO文件以确保没有错误。这通常可以通过计算并对比ISO文件的MD5或SHA1哈希值来完成。
示例代码如下:
# 创建一个目录用于存放ISO文件的内容mkdir -p ~/custom.iso_content# 挂载原ISO文件到这个目录mount -o loop /path/to/original.iso ~/custom.iso_content# 将额外的软件包复制到挂载的ISO目录中cp /path/to/additional/package.rpm ~/custom.iso_content/Packages/# 在挂载点创建kickstart文件touch ~/custom.iso_content/ks.cfg# 编辑kickstart文件# 使用genisoimage制作新的ISO映像genisoimage -r -T -J -V \"Custom Linux ISO\" \\ -b isolinux/isolinux.bin \\ -no-emul-boot -boot-load-size 4 \\ -boot-info-table -c boot.cat \\ ~/custom.iso_content ~/custom.iso# 解除挂载umount ~/custom.iso_content# 检查生成的ISO文件的MD5md5sum ~/custom.iso4.2 kickstart自动化脚本的配置与应用
4.2.1 kickstart脚本的作用与优势
kickstart是一种安装自动化脚本,它允许用户在安装过程中无需人工干预地自动应答所有安装程序提出的问题。通过使用kickstart,可以快速一致地部署多个具有相同配置的系统,特别是在云计算集群环境中,这可以显著减少设置和配置所需的时间和资源。
使用kickstart脚本的优势在于:
- 一致性 :确保每个节点按照相同的配置和设置进行安装。
- 效率 :加快系统安装过程,减少重复劳动。
- 可重复性 :使得系统安装过程可重复执行,易于管理和维护。
- 可扩展性 :支持通过脚本添加额外的自定义安装步骤和配置。
4.2.2 kickstart脚本的编写与部署
要编写一个kickstart脚本,首先需要了解系统安装过程中可能遇到的常见问题,包括分区布局、网络配置、系统语言、时区设置和初始用户账号等。一旦了解了这些选项,就可以开始编写kickstart配置文件了。
一个简单的kickstart文件示例:
#version=RHEL7# System authorization informationauth --enableshadow --passalgo=sha512# Use CDROM installation mediacdrom# Use text mode installtext# Run the Setup Agent on first bootfirstboot --enable# Keyboard layoutskeyboard --vckeymap=us --xlayouts=\'us\'# System languagelang en_US.UTF-8# Network informationnetwork --bootproto=dhcp --device=eth0 --onboot=on --ipv6=auto --no-activate# Root passwordrootpw --iscrypted $6$randomSalt$encryptedRootPasswordHere# System servicesservices --enabled=\"chronyd\"# System timezonetimezone America/New_York --isUtc# System bootloader configurationbootloader --location=mbr --boot-drive=sda# Clear the Master Boot Recordzerombr# Partition clearing informationclearpart --all --initlabel --drives=sda# Disk partitioning informationpart /boot --fstype=\"xfs\" --ondisk=sda --size=200part swap --fstype=\"swap\" --ondisk=sda --size=2048part / --fstype=\"xfs\" --ondisk=sda --size=1 --grow# User configurationuser --name=myuser --password=$6$randomSalt$encryptedUserPasswordHere --iscrypted --gecos=\"First Last\"# System bootloader configurationbootloader --append=\" crashkernel=auto\" --location=mbr --boot-drive=sda# System initialization%firstboot --interpreter=pythonimport sysfrom pykickstart一脚本 import FirstbootCmdscommands = FirstbootCmds()# Run the Setup Agent on first bootcommands.system_config.firstboot = True部署kickstart脚本通常涉及以下步骤:
- 配置PXE服务器 :设置PXE服务器以提供kickstart文件,确保在安装过程中,系统可以从网络引导并加载kickstart脚本。
- 引导客户端 :从客户端机器启动,选择通过网络启动的选项,此时系统会通过DHCP获取网络配置并从PXE服务器下载kickstart文件。
- 自动化安装 :系统将根据kickstart文件中的指令自动完成安装过程。
部署kickstart自动化脚本能够让运维人员从繁杂的重复工作中解放出来,将更多的精力投入到系统优化和性能提升等更有价值的任务中去。通过这种方式,可以实现Linux系统的快速和统一部署,为构建稳定、可靠的云计算集群打下坚实的基础。
5. 高可用性、负载均衡与故障切换
5.1 高可用性解决方案
5.1.1 高可用性的定义
高可用性(High Availability,简称 HA)是指系统无中断地执行其功能的能力,其目标是在规定的条件和时间内保证系统的正常运行。在IT领域,高可用性解决方案的实施是为了最小化因硬件故障、软件故障、自然灾害、人为错误等原因导致的服务中断时间。
5.1.2 实现高可用性的技术手段
要实现高可用性,需要依靠多种技术手段和策略,以下是几种常见的高可用性解决方案:
- 冗余 :通过增加硬件或网络组件的备份来提高系统的可靠性,确保单点故障不会导致整个系统的崩溃。
- 故障转移 :在检测到故障时,系统能够自动切换到备用系统或组件继续运行,对用户透明。
- 心跳检测 :通过在网络中发送心跳信号来监控系统的健康状态,一旦心跳信号丢失,系统可以及时作出反应。
- 负载均衡 :将工作负载分配给多个节点,即使某节点发生故障,其他节点仍能继续承担工作负载。
5.2 负载均衡技术详解
5.2.1 负载均衡的概念
负载均衡是一种提高网络、服务器、应用或数据库的可用性和性能的技术。它通过在多个服务器之间智能分配网络或应用流量来优化资源使用、最大化吞吐量、最小化响应时间,并确保用户的快速访问。
5.2.2 常见的负载均衡技术
在IT运维中,常见的负载均衡技术有以下几种:
- 硬件负载均衡器 :如F5、A10等,这些专用的物理设备提供了强大的性能和高度可配置的负载均衡功能,但成本较高。
- 软件负载均衡器 :如Nginx、HAProxy和LVS,这些解决方案通常安装在标准的服务器硬件上,成本较低,但需要额外的维护工作。
- DNS负载均衡 :通过DNS响应中提供多个IP地址来分发请求,简单且易于实施,但缺乏对实际服务器负载的感知能力。
- 云负载均衡服务 :如AWS的Elastic Load Balancing(ELB)、Azure Load Balancer等,这些服务由云提供商管理,可以轻松扩展,且不需要用户自行维护。
5.3 故障切换机制与实践
5.3.1 故障切换的必要性
故障切换(failover)机制是指系统在主用组件发生故障时,自动切换到备用组件的过程。故障切换是高可用性的重要组成部分,它确保了关键服务在出现故障时能够迅速恢复正常运行,从而最小化对业务的影响。
5.3.2 故障切换的实现方法
故障切换的实现通常依赖于以下几种方法:
- 主备故障切换 :系统有一个主节点和一个或多个备节点。正常情况下,所有流量都流向主节点。当主节点出现故障时,流量自动切换到备节点上。
- 多活故障切换 :多活故障切换涉及两个或多个活动节点,它们都能够独立处理流量。当其中一个节点故障时,其余节点分担故障节点的负载。
- 使用心跳信号 :心跳信号用于实时监测系统的健康状态。当心跳信号丢失时,故障切换机制被触发。
- 虚拟IP地址 :通常与主备故障切换结合使用。当主节点故障时,备用节点接管虚拟IP地址,客户端继续使用该IP地址访问服务。
示例代码:使用Pacemaker和Corosync实现故障切换
Pacemaker是一种高可用性集群资源管理器,它配合Corosync心跳检测软件,可以实现故障切换。
# 安装Pacemaker和Corosyncyum install pacemaker corosync# 配置Corosynccat > /etc/corosync/corosync.conf << EOFtotem { version: 2 cluster_name: hacluster transport: udpu}logging { fileline: off to_logfile: yes to_syslog: yes}EOF# 启动并启用Corosync服务systemctl start corosync.servicesystemctl enable corosync.service# 创建Pacemaker资源,并设置故障切换策略pcs resource create myIP ocf:heartbeat:IPaddr2 ip=\"192.168.122.100\" cidr_netmask=\"24\" meta target-role=\"Started\"pcs resource defaults resource-stickiness=\"100\"pcs constraint location myIP avoids @your_node_id# 启用Pacemaker资源的自动故障切换pcs resource master myIP master 在上述示例中,我们配置了一个名为 myIP 的虚拟IP资源,并将其设置为在故障时自动切换到健康的节点。通过调整 resource-stickiness 参数,我们可以控制资源在节点间的粘性,以及通过 constraint 命令来控制资源的位置策略,确保虚拟IP始终在健康的节点上可用。
故障切换是确保业务连续性的关键,因此IT运维人员必须精通故障切换的原理和实现方法,并能够在实际场景中正确应用。通过实践上述技术手段,可以有效地保障系统的高可用性和稳定性。
6. 云计算集群运维工具
云计算集群运维的工具和策略是确保大规模计算资源高效、稳定运行的关键。随着企业对云计算依赖程度的加深,运维工具的角色变得愈发重要。本章将重点介绍系统监控工具、日志管理策略与实践以及性能分析与优化等方面。
6.1 系统监控工具介绍
6.1.1 系统监控的作用
系统监控是云计算集群运维不可或缺的环节。通过监控工具能够实时收集和分析系统性能指标,如CPU、内存、磁盘I/O以及网络流量等,帮助运维工程师识别和响应潜在的系统问题。有效的监控可以减少系统的故障时间,提高系统的可用性和稳定性。
6.1.2 常用系统监控工具的比较
市场上的系统监控工具有很多种,不同的工具侧重点不同,但总体可以分为商业和开源两大类。下面比较几种流行的系统监控工具:
-
Nagios :一个非常老牌的开源监控工具,支持复杂的插件系统,可以对服务器、网络设备等进行监控。它的缺点是界面较为陈旧,操作复杂。
-
Zabbix :是一个功能强大的开源监控解决方案,支持自动发现网络资源,有友好的Web界面。Zabbix还支持高级功能,如自动注册和Web监控。
-
Prometheus :专为云计算设计的开源监控系统,支持多维数据模型,基于拉取(Pull)方式收集数据,并有强大的查询语言支持。
-
Datadog :是一个商业的监控平台,支持多种服务和应用的监控,包括云基础设施、容器以及应用程序性能。它提供丰富的可视化和分析功能,但也需要一定的成本投入。
下面是一个简化的表格比较这些工具的特征:
6.2 日志管理策略与实践
6.2.1 日志的重要性
日志文件记录了系统运行中的各种活动,是诊断问题和追踪系统行为的重要信息源。在云计算环境中,由于运行着大量的服务和应用,日志的数量和复杂性大大增加,这就需要一个有效的日志管理策略来处理这些数据。
6.2.2 日志管理的策略与工具
日志管理包括日志收集、存储、分析和可视化等环节。有效的日志管理策略不仅能帮助运维团队及时发现系统异常,还能在事后分析中起到关键作用。
一些常用日志管理工具包括:
-
ELK Stack :由Elasticsearch, Logstash, 和Kibana组成的日志分析工具组合。Elasticsearch用于存储和检索日志数据,Logstash负责数据的收集和处理,而Kibana提供数据的可视化和分析。
-
Graylog :一个开源的日志管理和分析平台,支持日志数据的收集、索引和搜索,也提供强大的警报系统。
-
Fluentd :是一个开源数据收集器,用于统一日志层。它的主要功能是将数据统一收集和发送到各种系统。
下面是一个mermaid格式的流程图展示一个简单日志收集和分析的过程:
graph LR A[日志源] --> B(Logstash) B --> C[Elasticsearch] C --> D[Kibana] B --> E[Graylog] E --> D D --> F[分析报告]6.3 性能分析与优化
6.3.1 性能分析的基本方法
性能分析是评估系统资源使用情况的过程,目的是识别瓶颈并优化系统性能。常用的基本性能分析方法有:
- 基准测试 :通过运行预定义的负载来评估系统性能。
- CPU分析 :检查CPU使用率和上下文切换情况。
- 内存分析 :监控内存使用情况和内存泄漏。
- 磁盘I/O分析 :评估磁盘读写活动和性能。
- 网络分析 :监控网络流量和延迟。
6.3.2 性能优化的实践案例
优化工作应当基于性能分析的结果来进行。实践中,我们可能需要调整系统参数、优化代码或者升级硬件来提高性能。下面是一个通过优化MySQL数据库性能的实践案例:
- 问题发现 :通过慢查询日志发现部分查询响应时间异常。
- 分析原因 :使用
EXPLAIN命令分析慢查询的执行计划。 - 实施优化 :
- 索引优化 :根据查询需求调整或添加索引。
- 配置调整 :修改MySQL配置文件中的参数,如
innodb_buffer_pool_size。 - 硬件升级 :增加更多的内存或更快的磁盘。
- 验证效果 :重新运行慢查询,检查响应时间是否达到预期。
本章介绍了云计算集群运维中系统监控、日志管理和性能优化的方法与工具。掌握这些知识对于IT专业人员来说,不仅可以提升工作效率,还能增强系统稳定性,为企业提供更加可靠的云服务。
7. Linux云计算集群装机实战演练
7.1 实战演练准备
在开始实战演练之前,我们需要做好充分的准备工作,以确保实验的成功和顺畅。这包括搭建实验环境、配置必要的工具和脚本等。
7.1.1 环境搭建与配置
在开始之前,需要准备好Linux云环境,这通常涉及安装虚拟化软件如VMware或VirtualBox,并创建多个虚拟机作为实验节点。为了便于管理,可以采用KVM进行虚拟化环境的搭建,KVM是Linux下的完整虚拟化解决方案。
sudo apt-get install qemu-kvm libvirt-daemon-system libvirt-clients bridge-utilssudo systemctl enable libvirtdsudo systemctl start libvirtd确保安装过程中,网络桥接配置正确,以便虚拟机可以访问外部网络,也可以使用网络启动。
7.1.2 工具与脚本的准备
为了自动化部署集群,我们需要准备一些工具和脚本。如前面章节所述,PXE和kickstart是实现自动化安装的关键工具。同时,还应该准备一些监控和日志管理工具,以便在实战演练过程中能够实时观察集群状态。
例如,可以使用Ansible作为自动化配置管理工具,编写脚本自动化安装过程:
- name: Ensure the system is up to date apt: upgrade: dist update_cache: yes7.2 实战演练过程
实战演练过程是检验之前所有准备工作是否到位的环节。我们将通过一系列操作来完成集群装机的整个过程。
7.2.1 集群装机步骤
- 在PXE服务器上配置好网络启动环境,包括tftp、DHCP、HTTP服务。
- 创建一个kickstart配置文件,定义系统安装过程中的自动配置选项。
- 启动客户端,通常通过设置BIOS或UEFI,让客户端从网络启动。
- 监控PXE引导过程,确保客户端能够从PXE服务器获取IP地址,并下载内核和安装程序。
- 完成系统安装后,进行自动化配置,如创建用户、安装必要的软件包等。
7.2.2 PXE引导与kickstart自动化部署
当客户端从网络启动后,它将向PXE服务器发送请求以获取启动文件。PXE服务器响应请求后,客户端加载引导文件并启动内核。之后,内核加载初始内存文件系统,并从HTTP服务器下载安装介质。kickstart文件被识别并用于自动化安装过程。
# Kickstart configuration example# Use this file as a template for an automatic installlang en_US.UTF-8keyboard --vckeymap=us --xlayouts=\'us\'timezone America/New_York --isUtcfirstboot --enablezerombrclearpart --all --initlabelpart / --fstype ext4 --ondisk=sda --size=1 --growbootloader --location=mbr --boot-drive=sdarootpw --iscrypted $6$random加密字符串user --groups=wheel --name=用户名 --password=$6$random加密字符串auth --useshadow --passalgo=sha512selinux --enforcingfirewall --enabled --service=sshnetwork --bootproto=dhcp --device=eth0 --onboot=yes --ipv6=auto --activatesshd7.3 实战演练总结与优化
在实战演练结束后,需要总结整个过程,分析可能遇到的问题,并探讨如何优化以提高效率和稳定性。
7.3.1 遇到的问题与解决方案
问题可能包括网络配置错误、引导过程中的中断、自动化脚本执行失败等。例如,如果在网络引导过程中遇到客户端无法连接到PXE服务器的问题,需要检查网络配置,确保网络设备设置正确,并且PXE服务器的DHCP服务运行正常。
# DHCP Server配置示例subnet 192.168.1.0 netmask 255.255.255.0 { range 192.168.1.10 192.168.1.100; option broadcast-address 192.168.1.255; option routers 192.168.1.1; next-server 192.168.1.2; # PXE服务器IP地址 filename \"pxelinux.0\";}7.3.2 经验总结与未来展望
实战演练的经验对于改进运维流程和提升技能至关重要。可以考虑将这些经验整理成文档,为将来的操作提供指导。同时,随着云计算和虚拟化技术的快速发展,需要持续关注新技术,如容器化、微服务等,以适应未来技术的发展趋势。
在自动化和集群管理方面,持续优化和改进是必要的。例如,采用更加灵活的自动化工具,如Ansible、Puppet、Chef等,以提供更高级别的抽象,简化配置和管理任务。
本文还有配套的精品资源,点击获取
简介:Linux运维在企业级系统管理中扮演核心角色,特别是在云计算领域,高效的集群装机技术如PXE(Preboot Execution Environment)变得至关重要。本课件资料深入探讨PXE技术在Linux云计算环境中的应用,包括其在网络启动中的优势、工作流程、ISO映像和kickstart自动化脚本的使用,以及在高可用性、负载均衡和故障切换方面的实现。同时,课件内容还涵盖Linux运维中的关键工具,如系统监控、日志管理和性能分析。
本文还有配套的精品资源,点击获取


