llama.cpp部署Qwen2.5大模型(9分钟搞定)_windows llamcpp部署 qwen
最新教程,逐步操作就可以将大模型部署。
1.服务器环境
GPU RTX 4090
PyTorch 2.1.0
Python 3.10(ubuntu22.04)
CUDA 12.1
2.下载大模型
设置镜像:
export HF_ENDPOINT=https://hf-mirror.com
创建download_qwen2.5.sh,内容如下:
#!/bin/bash
set -eMODEL_NAME=\"qwen2.5-7b-instruct\"
MODEL_DIR=\"./$MODEL_NAME\"
HF_MIRROR=\"https://hf-mirror.com/Qwen/Qwen2.5-7B-Instruct-GGUF/resolve/main\"mkdir -p \"$MODEL_DIR\"
cd \"$MODEL_DIR\"files=(
\"qwen2.5-7b-instruct-fp16-00001-of-00004.gguf\"
\"qwen2.5-7b-instruct-fp16-00002-of-00004.gguf\"
\"qwen2.5-7b-instruct-fp16-00003-of-00004.gguf\"
\"qwen2.5-7b-instruct-fp16-00004-of-00004.gguf\"
)echo \"🚀 开始下载 Qwen2.5-7B-Instruct-GGUF 所有文件...\"
for file in \"${files[@]}\"; do
echo \"📦 Downloading $file ...\"
aria2c -x 16 -s 16 -k 1M \"$HF_MIRROR/$file\" -o \"$file\"
doneecho \"✅ 下载完成!\"
运行download_qwen2.5.sh,步骤如下:
chmod +x download_qwen2.5.sh
./download_qwen2.5.sh
3.安装llama.cpp
wget https://github.com/ggerganov/llama.cpp/archive/refs/heads/master.zip
unzip master.zip
mv llama.cpp-master llama.cpp
4.编译
进入llama.cpp文件夹,通过以下步骤进行编译:
cmake -B build_cuda -DLLAMA_CUDA=ON
sudo apt-get install make cmake gcc g++ locate
cmake --build build_cuda --config Release -j 8
如果报错如下:

解决方案:
sudo apt-get install libcurl4-openssl-dev
但如果报错如下:
 解决方案是反复执行:
解决方案是反复执行:
cmake --build build_cuda --config Release -j 8
5.运行
进入./build_cuda/bin,执行:
./llama-server \\
-m /root/autodl-tmp/qwen2.5-7b-instruct/qwen2.5-7b-instruct-fp16-00001-of-00004.gguf \\
--host 127.0.0.1 \\
--port 8080 \\
-c 2048 \\
--gpu-layers 128
至此,大模型已经成功部署。
6.转接端口
最后一步,通过vscode转接端口,就可以与大模型交互了。
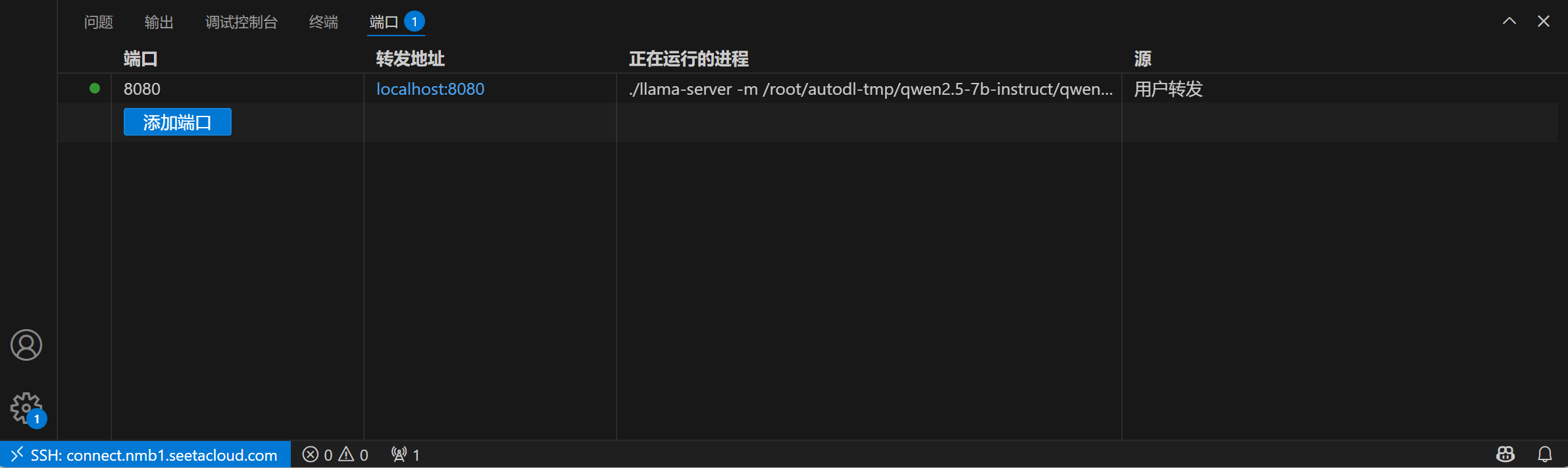 交互界面如下。
交互界面如下。
 参考文献:https://github.com/echonoshy/cgft-llm
参考文献:https://github.com/echonoshy/cgft-llm


