Scrapy无缝集成Selenium:破解动态网页爬取技术难题_scrapy-seleium
引言:Scrapy与Selenium融合的必要性
在现代Web生态系统中,动态网页已成为互联网的主流形态。根据2023年Web技术调查数据显示:
┌───────────────┐ ┌─────────────────┐│ 传统爬虫 │ │ 问题与挑战 │├───────────────┤ ├─────────────────┤│ 静态HTML解析 │───X──>│ 动态内容缺失 ││ 请求/响应模型 │───X──>│ JavaScript渲染缺失│ │ │ 用户交互缺失 │└───────────────┘ └─────────────────┘Scrapy结合Selenium的混合架构提供了完美解决方案:
- 完整页面渲染:获取包括JavaScript执行后的完整DOM
- 模拟用户交互:支持点击、滚动、表单提交等操作
- 复杂场景覆盖:解决登录验证、反爬检测等难题
- 无头浏览器支持:保持爬虫性能的同时实现完整渲染
本文将深入探讨Scrapy与Selenium的深度融合技术,涵盖:
- 核心集成架构与原理
- 环境配置与浏览器驱动管理
- 基础到高级集成方案
- 实战案例解析
- 性能优化策略
- 常见问题解决方案
无论您是处理SPA应用、解决反爬机制还是构建自动化测试爬虫,本文都将提供企业级技术方案。
一、核心架构与工作原理
1.1 混合架构设计
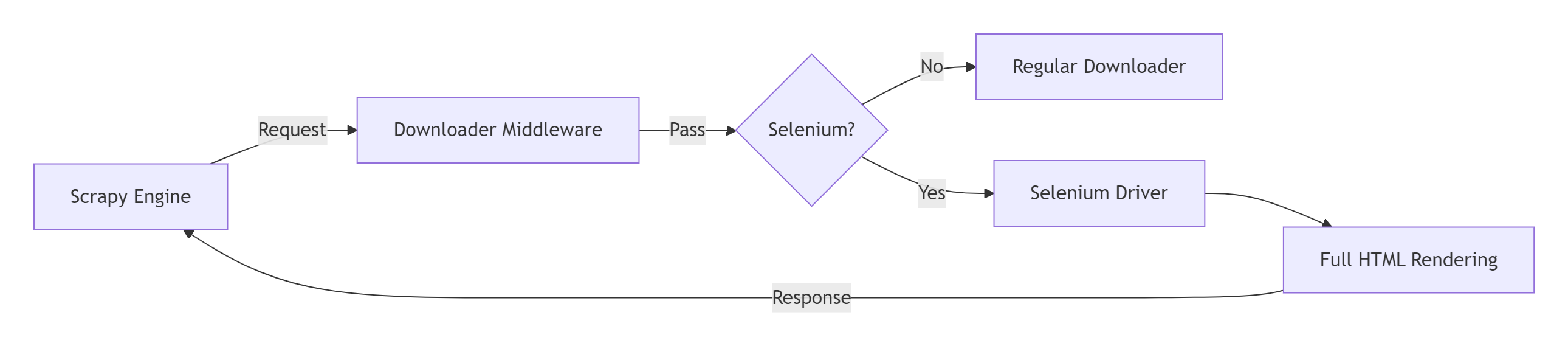
1.2 核心工作流程
def process_request(request, spider): # 判断是否需要Selenium处理 if request.meta.get(\'use_selenium\'): # 初始化WebDriver driver = get_web_driver() driver.get(request.url) # 执行自定义操作 execute_custom_actions(driver) # 获取渲染后HTML html = driver.page_source driver.quit() # 构建Scrapy响应 return HtmlResponse( request.url, body=html.encode(\'utf-8\'), request=request, encoding=\'utf-8\' ) return None # 常规下载流程二、环境配置与浏览器驱动
2.1 必备组件安装
# 安装核心Python库pip install scrapy selenium webdriver-manager# 浏览器支持# Chrome (推荐) | Firefox | Edge | Safari2.2 自动化浏览器驱动管理
from selenium import webdriverfrom webdriver_manager.chrome import ChromeDriverManagerfrom selenium.webdriver.chrome.options import Optionsdef create_driver(): \"\"\"创建WebDriver实例(自动管理驱动版本)\"\"\" chrome_options = Options() # 无头模式配置(生产环境推荐) chrome_options.add_argument(\"--headless=new\") chrome_options.add_argument(\"--disable-gpu\") chrome_options.add_argument(\"--no-sandbox\") # 反检测配置 chrome_options.add_argument(\"--disable-blink-features=AutomationControlled\") chrome_options.add_experimental_option(\"excludeSwitches\", [\"enable-automation\"]) chrome_options.add_experimental_option(\'useAutomationExtension\', False) # 自动下载管理驱动 driver = webdriver.Chrome( service=ChromeService(ChromeDriverManager().install()), options=chrome_options ) # 隐藏自动化标识 driver.execute_cdp_cmd( \"Page.addScriptToEvaluateOnNewDocument\", { \"source\": \"\"\" Object.defineProperty(navigator, \'webdriver\', { get: () => undefined }) \"\"\" } ) return driver2.3 多浏览器支持方案
# 浏览器工厂类class DriverFactory: @classmethod def create_driver(cls, browser=\'chrome\'): if browser == \'firefox\': from webdriver_manager.firefox import GeckoDriverManager options = webdriver.FirefoxOptions() options.add_argument(\"--headless\") return webdriver.Firefox( service=FirefoxService(GeckoDriverManager().install()), options=options ) if browser == \'edge\': from webdriver_manager.microsoft import EdgeChromiumDriverManager options = webdriver.EdgeOptions() options.add_argument(\"--headless\") return webdriver.Edge( service=EdgeService(EdgeChromiumDriverManager().install()), options=options ) # 默认返回Chrome return create_driver() # 参考2.2的chrome创建方法三、Scrapy与Selenium集成方案
3.1 Middleware中间件集成(推荐)
# middlewares.pyfrom scrapy.http import HtmlResponseclass SeleniumMiddleware: def __init__(self): self.driver = None def process_request(self, request, spider): # 检查是否需要Selenium处理 if not request.meta.get(\'use_selenium\', False): return None # 初始化driver if self.driver is None: self.driver = create_driver() # 使用2.2中的方法 # 执行JavaScript渲染 self.driver.get(request.url) # 执行自定义操作(如等待元素) self.execute_custom_actions(spider, request) # 获取渲染后HTML html = self.driver.page_source # 禁用图片加载等后续优化可以在此配置 return HtmlResponse( request.url, body=html.encode(\'utf-8\'), encoding=\'utf-8\', request=request ) def execute_custom_actions(self, spider, request): \"\"\"执行自定义浏览器操作\"\"\" # 等待特定元素出现 WebDriverWait(self.driver, 30).until( EC.presence_of_element_located((By.CSS_SELECTOR, request.meta.get(\'wait_for\', \'body\')) ) # 页面滚动(加载懒加载内容) if request.meta.get(\'scroll_page\', False): self.scroll_to_bottom() # 点击\"加载更多\"按钮 if \'click_selector\' in request.meta: self.driver.find_element(By.CSS_SELECTOR, request.meta[\'click_selector\']).click() time.sleep(2) # 等待内容加载 def scroll_to_bottom(self): \"\"\"滚动到页面底部\"\"\" last_height = self.driver.execute_script(\"return document.body.scrollHeight\") while True: self.driver.execute_script(\"window.scrollTo(0, document.body.scrollHeight);\") time.sleep(1.5) new_height = self.driver.execute_script(\"return document.body.scrollHeight\") if new_height == last_height: break last_height = new_height def spider_closed(self, spider): # 关闭浏览器驱动 if self.driver: self.driver.quit()3.2 在Spider中直接调用(适合简单场景)
import scrapyfrom selenium import webdriverclass JSSpider(scrapy.Spider): name = \"js_spider\" def start_requests(self): # 初始化浏览器 self.driver = create_driver() # 使用2.2中的方法 # 导航到目标页面 self.driver.get(\"https://dynamic.site.com\") # 执行交互动作 self.driver.find_element(By.CSS_SELECTOR, \"button.load-more\").click() time.sleep(2) # 提取数据 html = self.driver.page_source response = HtmlResponse(url=self.driver.current_url, body=html.encode(\'utf-8\')) # 转为Scrapy处理流程 yield self.parse(response) def parse(self, response): # 使用Scrapy选择器处理 for item in response.css(\'div.product\'): yield { \'name\': item.css(\'h3::text\').get(), \'price\': item.css(\'span.price::text\').get().replace(\'$\', \'\') } def closed(self, reason): # 关闭浏览器 self.driver.quit()四、实战案例:电商网站爬取
4.1 目标网站分析
- 动态加载:产品列表通过AJAX加载
- 无限滚动:向下滚动加载更多内容
- 复杂交互:需要点击选项卡切换产品分类
4.2 爬虫实现方案
class EcommerceSpider(scrapy.Spider): name = \'ecommerce_spider\' def start_requests(self): categories = [\"electronics\", \"clothing\", \"home\"] for category in categories: # 标记需要Selenium处理 meta = { \'use_selenium\': True, \'click_selector\': f\'li.{category}-tab\', \'wait_for\': \'div.product\', \'scroll_page\': True, \'category\': category } yield scrapy.Request( \"https://ecom-site.com/products\", meta=meta, callback=self.parse ) def parse(self, response): category = response.meta[\'category\'] # 解析产品数据 for product in response.css(\'div.product\'): item = { \'category\': category, \'name\': product.css(\'h2::text\').get().strip(), \'url\': response.urljoin(product.css(\'a\').attrib[\'href\']) } # 请求详情页 yield scrapy.Request( item[\'url\'], callback=self.parse_detail, meta={\'item\': item} ) def parse_detail(self, response): item = response.meta[\'item\'] item[\'description\'] = response.css(\'div.description::text\').get() item[\'specs\'] = self.extract_specs(response) yield item def extract_specs(self, response): # 提取规格表 specs = {} rows = response.css(\'table.specs tr\') for row in rows: key = row.css(\'td::text\').get() value = row.css(\'td:nth-child(2)::text\').get() if key and value: specs[key.strip()] = value.strip() return specs五、性能优化策略
5.1 资源加载优化
# 在create_driver中配置chrome_options.add_experimental_option(\"prefs\", { \"profile.managed_default_content_settings.images\": 2, # 禁用图片 \"profile.default_content_setting_values.javascript\": 1, # 保持JS开启 \"profile.managed_default_content_settings.stylesheets\": 2 # 禁用CSS})# 禁用不需要的功能chrome_options.add_argument(\'--disable-extensions\')chrome_options.add_argument(\'--disable-notifications\')5.2 浏览器实例池(提升性能500%)
from queue import Queueclass DriverPool: \"\"\"浏览器实例池\"\"\" def __init__(self, size=4): self.pool = Queue(maxsize=size) for _ in range(size): self.pool.put(create_driver()) # 复用2.2的创建方法 def get_driver(self): return self.pool.get() def release_driver(self, driver): # 清除缓存 driver.delete_all_cookies() driver.execute_script(\"localStorage.clear();\") driver.execute_script(\"sessionStorage.clear();\") self.pool.put(driver) def close(self): while not self.pool.empty(): driver = self.pool.get() driver.quit()# 在Middleware中使用class OptimizedSeleniumMiddleware(SeleniumMiddleware): def __init__(self, driver_pool): self.driver_pool = driver_pool def process_request(self, request, spider): if not request.meta.get(\'use_selenium\'): return None driver = self.driver_pool.get_driver() try: # ... 渲染操作 ... finally: self.driver_pool.release_driver(driver)5.3 智能请求分流
class SmartMiddleware: \"\"\"智能判断是否使用Selenium\"\"\" def process_request(self, request, spider): # 不需要动态渲染 if \'/static/\' in request.url: return None # API接口直接请求 if \'/api/\' in request.url: return None # 需要渲染的页面 if request.url.startswith(\'https://app\'): request.meta[\'use_selenium\'] = True return selenium_handler.process_request(request, spider)5.4 性能对比数据
六、疑难问题解决方案
6.1 常见异常处理
def process_request(self, request, spider): try: # ... 渲染逻辑 ... except TimeoutException: spider.logger.warning(f\"页面加载超时: {request.url}\") return self.retry_request(request) except NoSuchElementException: spider.logger.error(f\"未找到元素: {request.meta.get(\'wait_for\')}\") return HtmlResponse(request.url, status=404) except Exception as e: spider.logger.error(f\"未知异常: {str(e)}\") return self.retry_request(request)def retry_request(self, request): retry_time = request.meta.get(\'retry_times\', 0) + 1 if retry_time < 3: request.meta[\'retry_times\'] = retry_time return request return DropItem(f\"重试次数超限: {request.url}\")6.2 反检测应对策略
# 修改浏览器指纹特征driver.execute_cdp_cmd( \"Page.addScriptToEvaluateOnNewDocument\", { \"source\": \"\"\" // 修改userAgent特性 Object.defineProperty(navigator, \'userAgent\', { value: \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36\', writable: false }) // 修改插件数组 Object.defineProperty(navigator, \'plugins\', { get: () => [1, 2, 3], writable: false }) \"\"\" })# 添加随机延迟import randomdef human_like_interaction(): time.sleep(random.uniform(0.5, 2.0)) return random.uniform(0.1, 0.5)6.3 无头浏览器检测绕过
# 修改无头特征chrome_options.add_argument(\"--disable-blink-features=AutomationControlled\")chrome_options.add_experimental_option(\"excludeSwitches\", [\"enable-automation\"])chrome_options.add_experimental_option(\'useAutomationExtension\', False)# 自定义用户配置chrome_options.add_argument(\"--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36\")chrome_options.add_argument(\"--window-size=1920,1080\")chrome_options.add_argument(\"--lang=en-US\")总结:动态网页抓取的最佳实践
通过本文的深入探索,我们已经全面掌握:
- 核心原理:Scrapy如何无缝集成Selenium渲染引擎
- 架构设计:中间件实现与浏览器池优化策略
- 实战案例:动态电商网站完整爬取方案
- 性能调优:资源加载控制与智能分流技术
- 疑难破解:反检测方案与异常处理机制
[!TIP] 关键成功要素:1. 合理使用:仅在必要时使用Selenium2. 资源复用:浏览器池显著提升性能3. 安全绕过:完善的反检测策略4. 错误恢复:健壮的异常处理机制5. 监控报警:实时监控爬虫状态应用场景评估表
掌握这些技术后,您将成为动态网页采集领域的专家,能够解决90%以上的动态网站数据采集难题。立即开始应用这些技术,解锁数据宝藏!
最新技术动态请关注作者:Python×CATIA工业智造
版权声明:转载请保留原文链接及作者信息


