从零开始的python学习(九)P134+P135+P136+P137+P138+P139+P140
本文章记录观看B站python教程学习笔记和实践感悟,视频链接:【花了2万多买的Python教程全套,现在分享给大家,入门到精通(Python全栈开发教程)】 https://www.bilibili.com/video/BV1wD4y1o7AS/?p=6&share_source=copy_web&vd_source=404581381724503685cb98601d6706fb
上节课学习模块的简介及自定义模块,模块的导入,Python中的包,主程序运行,Python中常用的内置模块及random模块中常用函数的使用,本节课学习time模块中datetime类的使用,datetime模块中datetime类的使用,timedelta类的使用,第三方模块的安装与卸载,requests模块的使用,openpyxl模块的使用,pdfplumber模块的使用。
1. time模块中datetime类的使用

time模块的作用就是进行时间的处理,一些关于定义的解释:参考什么是时间戳?时间戳有什么用?(适合新人)-CSDN博客
什么是时间戳?
一个能表示一份数据在某个特定时间之前已经存在的、 完整的、 可验证的数据,通常是一个字符序列,唯一地标识某一刻的时间。说白了就是,表示某一刻的时间;
时间戳有什么用?
一般在互联网公司都会在项目种使用时间戳,时间戳主要用于清理缓存,大多数用于版本更新。
为什么要用时间戳?
客户端在向服务端接口进行请求,如果请求信息进行了加密处理,被第三方截取到请求包,可以使用该请求包进行重复请求操作。如果服务端不进行防重放攻击,就会服务器压力增大,而使用时间戳的方式可以解决这一问题。
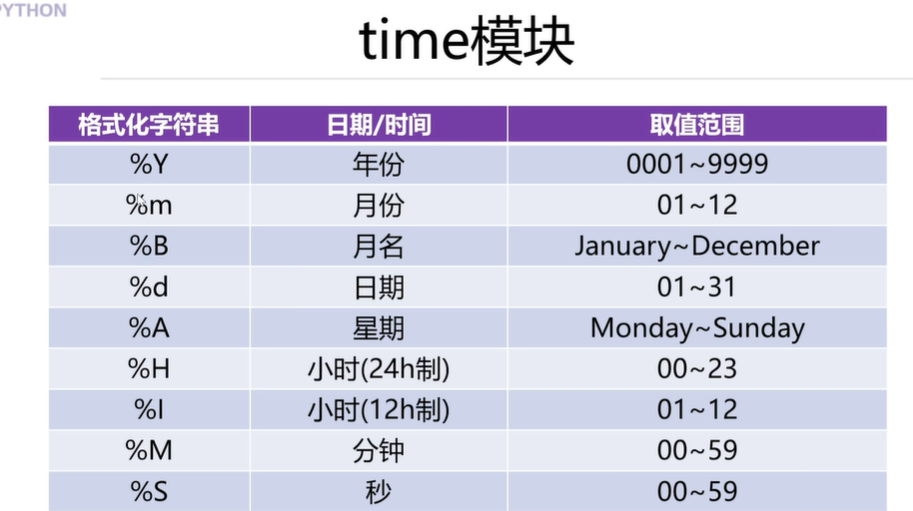
下面是上述用法的应用:
import timenow=time.time()print(now)obj=time.localtime() #struct_time对象print(obj)obj2=time.localtime(60) #60秒 1970年,1月1日,8时1分,0秒print(obj2)print(type(obj2))print(\'年份\',obj2.tm_year)print(\'月份\',obj2.tm_mon)print(\'日期\',obj2.tm_mday)print(\'时\',obj2.tm_hour)print(\'分\',obj2.tm_min)print(\'秒\',obj2.tm_sec)print(\'星期\',obj2.tm_wday) #[0,6],3表示是星期四,2表示的是星期三print(\'今年的多少天:\',obj2.tm_yday)print(time.ctime()) #时间戳对应的易读的字符串 Sun Aug 3 16:22:51 2025#日期时间格式化print(time.strftime(\'%Y-%m-%d\',time.localtime()))print(time.strftime(\'%H:%M:%S\',time.localtime()))print(\'%B月份的名称:\',time.localtime(time.time()))print(\'%A星期的名称:\',time.localtime(time.time()))print(\'%B月份的名称:\',time.strftime(\'%B\',time.localtime()))print(\'%A星期的名称:\',time.strftime(\'%A\',time.localtime()))#字符串转成struct_timeprint(time.strptime(\'2008-08-08\',\'%Y-%m-%d\'))time.sleep(20) #程序暂停20秒才输出下面的内容print(\'helloworld\')运行结果如下:
1754211091.3255155time.struct_time(tm_year=2025, tm_mon=8, tm_mday=3, tm_hour=16, tm_min=51, tm_sec=31, tm_wday=6, tm_yday=215, tm_isdst=0)time.struct_time(tm_year=1970, tm_mon=1, tm_mday=1, tm_hour=8, tm_min=1, tm_sec=0, tm_wday=3, tm_yday=1, tm_isdst=0)年份 1970月份 1日期 1时 8分 1秒 0星期 3今年的多少天: 1Sun Aug 3 16:51:31 20252025-08-0316:51:31%B月份的名称: time.struct_time(tm_year=2025, tm_mon=8, tm_mday=3, tm_hour=16, tm_min=51, tm_sec=31, tm_wday=6, tm_yday=215, tm_isdst=0)%A星期的名称: time.struct_time(tm_year=2025, tm_mon=8, tm_mday=3, tm_hour=16, tm_min=51, tm_sec=31, tm_wday=6, tm_yday=215, tm_isdst=0)%B月份的名称: August%A星期的名称: Sundaytime.struct_time(tm_year=2008, tm_mon=8, tm_mday=8, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=4, tm_yday=221, tm_isdst=-1)helloworld进程已结束,退出代码为 02.datetime模块中datetime类的使用
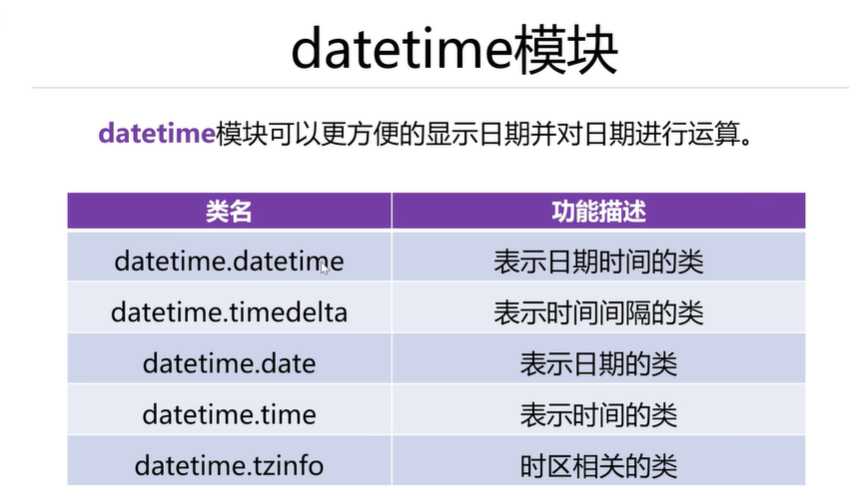
使用上述功能的实例:
from datetime import datetime #从datetime模块中导入datetime类dt=datetime.now()print(\'当前的系统时间为:\',dt)#datetime是一个类,手动创建这个类的对象dt2=datetime(2028,8,8,20,8)print(\'dt2的数据类型\',type(dt2),\'dt2所表示的日期时间:\',dt2)print(\'年:\',dt2.year,\'月:\',dt2.month,\'日:\',dt2.day)print(\'时:\',dt2.hour,\'分:\',dt2.minute,\'秒:\',dt2.second)#比较两个datetime类型对象的大小labor_day=datetime(2028,5,1,0,0,0)national_day=datetime(2028,10,1,0,0,0)print(\'2028年5月1日比2028年10月1日早吗?\',labor_day<national_day) #True#datetime类型与字符串进行转换nowdt=datetime.now()nowdt_str=nowdt.strftime(\'%Y/%m/%d %H:%M:%S\')print(\'nowdt的数据类型:\',type(nowdt_str),\'nowdt所表示的数据是什么?\',nowdt_str)#字符串类型转成datetime类型str_datetime=\'2028年8月8日 20点8分8秒\'dt3=datetime.strptime(str_datetime,\'%Y年%m月%d日 %H点%M分%S秒\')print(\'str_datetime的数据类型\',type(str_datetime),\'str_datetime所表示的数据:\',str_datetime)print(\'dt3的数据类型\',type(dt3),\'dt3所表示的数据:\',dt3)运行结果如下:
E:\\anaconda3\\envs\\py39-qt\\python.exe D:\\pycharm_project\\learn_pytorch\\pythonProject1\\2practice\\p135.py 当前的系统时间为: 2025-08-05 22:41:54.572553dt2的数据类型 dt2所表示的日期时间: 2028-08-08 20:08:00年: 2028 月: 8 日: 8时: 20 分: 8 秒: 02028年5月1日比2028年10月1日早吗? Truenowdt的数据类型: nowdt所表示的数据是什么? 2025/08/05 22:41:54str_datetime的数据类型 str_datetime所表示的数据: 2028年8月8日 20点8分8秒dt3的数据类型 dt3所表示的数据: 2028-08-08 20:08:08进程已结束,退出代码为 03.timedelta类的使用
在上面的要求里我们使用datetime这个类实现一些实例,在下面的模块使用timedelta类能够实现时间间隔的类但是不能实现年月的加减(datetime类可以实现),因为年月依赖于具体的年份月份,不同的年份和月份时间期限不一样,而这个类可以具体到小时分秒毫秒。
from datetime import datetimefrom datetime import timedelta# 创建两个datetime类型的对象delta1=datetime(2028,10,1)-datetime(2028,5,1)print(\'delta1的数据类型是:\',type(delta1),\'delta1所表示的数据是:\',delta1)print(\'2028年5月1日之后的153是:\',datetime(2020,5,1)+delta1)#通过传入参数的方式创建一个timedelta对象td1=timedelta(10)print(\'创建一个10天的timedelta对象\',td1)td2=timedelta(10,11)print(\'创建一个10天11秒的timedelta对象\',td2)运行结果如下:
delta1的数据类型是: delta1所表示的数据是: 153 days, 0:00:002028年5月1日之后的153是: 2020-10-01 00:00:00创建一个10天的timedelta对象 10 days, 0:00:00创建一个10天11秒的timedelta对象 10 days, 0:00:11进程已结束,退出代码为 0其中最后一行timedelta(天,秒,毫秒,...)因此可以具体到多少秒。
4.第三方模块的安装与卸载
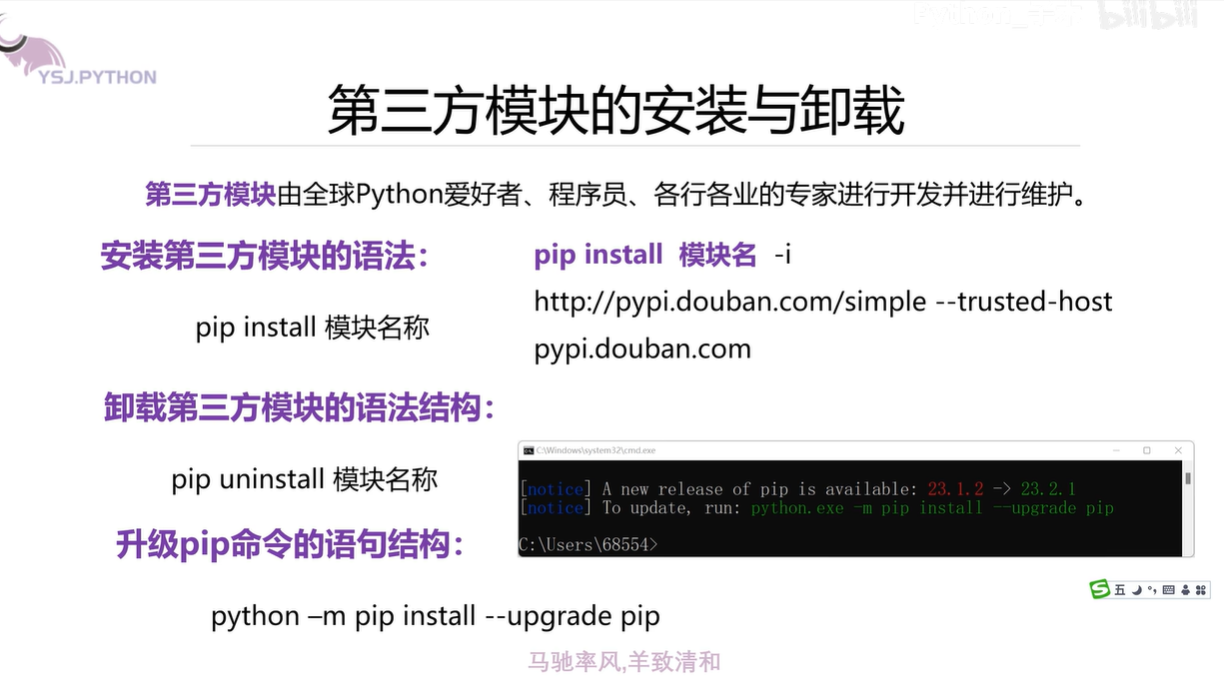
对于第三方模块的安装,如果cmd无法安装可以直接在pycharm的Terminal(也就是“终端”)中国输入pip install 库名,或者执行import +那个库名,这时候就会弹出警告说没有这个库,然后给出解决方案,直接复制并执行那个指令。
图片中的网址是库的镜像源 http://pypi.doubanio.com/simple --trusted-hostpypi.doubanio.com

5.requests模块的使用

使用这个作为爬虫的基本结构:
import requestsurl=\'\'request=requests.get(url)
以爬取天气网的信息为例子,https://www.weather.com.cn/
我们点开北京页面
https://www.weather.com.cn/weather1d/101010100.shtml
比方说想要爬取这个界面里面的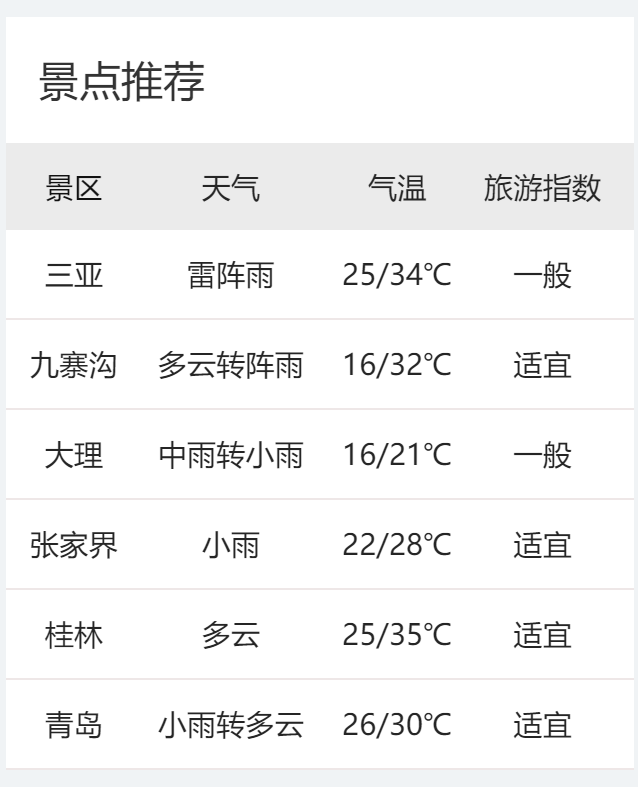
我们先要右键以后找到并且点击检查,点击左侧第一个小箭头,然后把光标放在网络界面(左边),右边的黑色代码就会高亮标出:
那么代码内容如下:
import requestsimport reurl=\'https://www.weather.com.cn/weather1d/101010100.shtml\' #爬虫打开的浏览器上的网页resp = requests.get(url) #将url输入到里面,get意思就是打开浏览器并打开网址#设置一下编码的格式resp.encoding=\'utf-8\'print(resp.text) #res响应对象,对象名.属性名 resp.test#这样爬取出来的内容叫做HTML页面,但是我们只需要提取在这个页面中我们需要的内容#以提取景区相关信息的内容为例,我们需要先根据页面的检查界面city=re.findall(\'([\\u4e00-\\u9fa5]*)\',resp.text) #我们要提取所有span标签中class name当中的某些中文标签,但是要写成中文相应阿斯克码表weather=re.findall(\'([\\u4e00-\\u9fa5]*)\',resp.text)wd=re.findall(\'(.*)\',resp.text)zs=re.findall(\'([\\u4e00-\\u9fa5]*)\',resp.text)#上面的模式字符串不加括号就会捕获整个pattern,导致代码很复杂。[]里面是中文对应的Unicode范围吧#括号里的是正则表达式,[]号里的是unicode码,这个范围内只有汉字,*是通配符,表示所有print(city)print(weather)print(wd)print(zs)print(city)lst=[]for a,b,c,d in zip(city,weather,wd,zs): lst.append([a,b,c,d])for i in lst: print(i)\'\'\'三亚雷阵雨25/34℃一般\'\'\'代码部分运行结果如下:
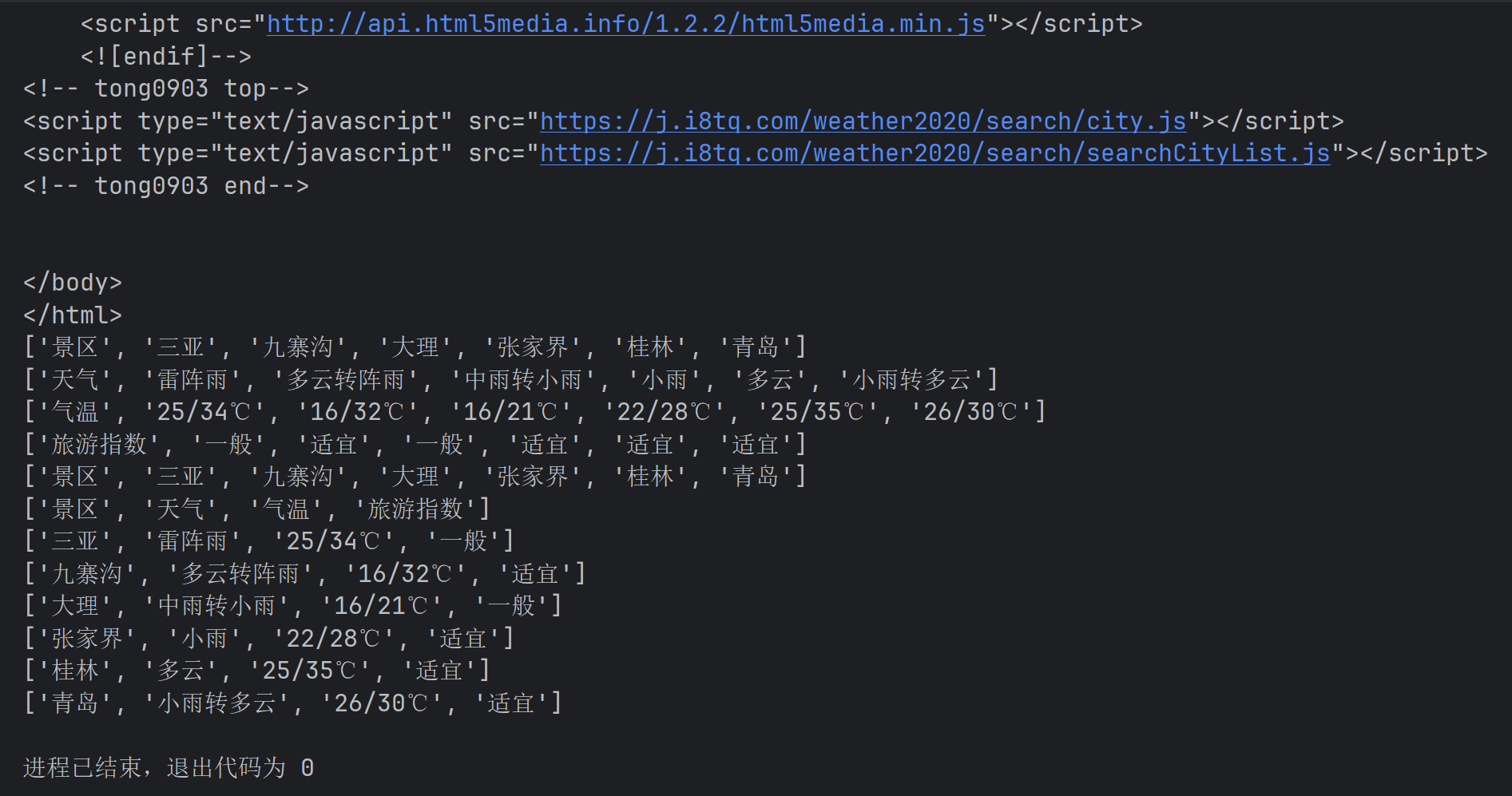
第二个例子是爬取网页的图片,以百度的界面那个百度的图片为例:
双击网址链接,也就是http://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png
得到图片 、
、
import requestsurl=\'http://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png\'resp=requests.get(url)#保存到本地,保存到本地二进制数据with open(\'logo.png\',\'wb\') as file: file.write(resp.content)可以看到在代码文件的同一目录下成功保存了图片:

6.openpyxl模块的使用
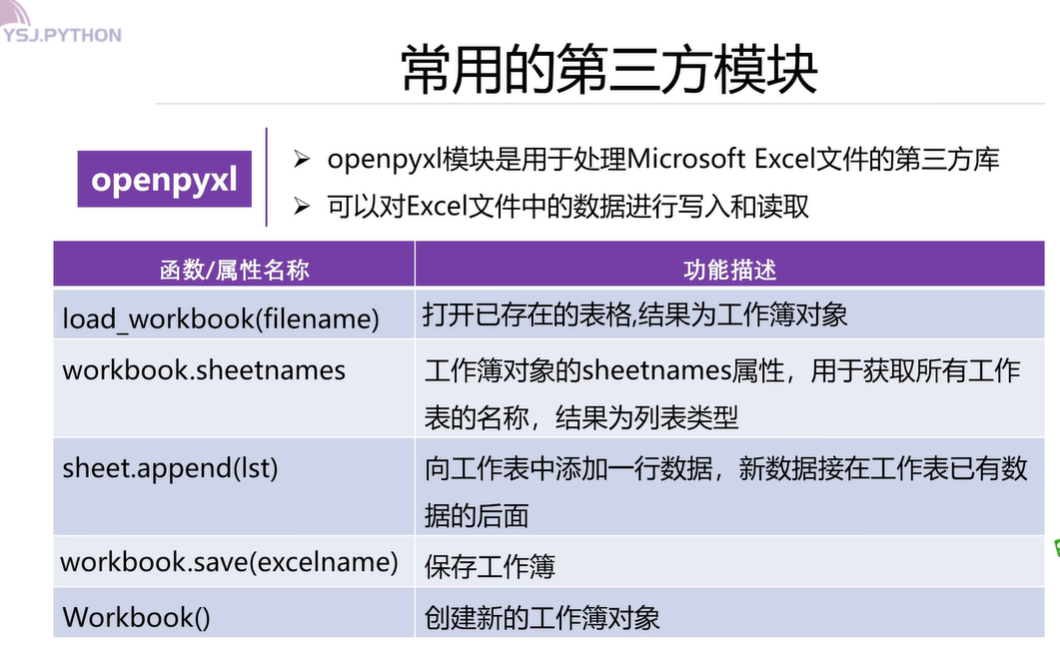
如果想将网页中的内容导入Excel文件,示例如下:
import weatherimport openpyxlhtml=weather.get_html() #发出请求,得到响应结果lst=weather.parse_html(html) #解析数据#创建一个新的Excel工作簿workbook=openpyxl.Workbook() #创建对象#在Excel文件中创建工作表sheet=workbook.create_sheet(\'景区天气\')#向工作表中添加数据for item in lst: sheet.append(item) #一次添加一行workbook.save(\'景区天气.xlsx\')运行结果如下:
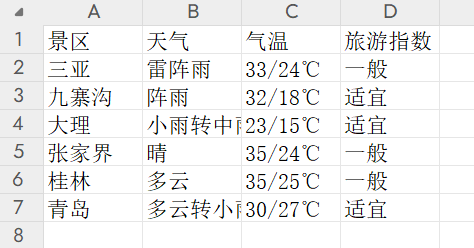
读取已有的工作表的某一个表格,首先在上面已经新建好的Excel的文件夹下新建新的python文件:
import openpyxl#打开工作簿workbook=openpyxl.load_workbook(\'景区天气.xlsx\') #这个操作相当于双击打开景区天气这个Excel文件#对于这个Excel表格的多个工作表,就要选择操作的工作表sheet=workbook[\'景区天气\']#表格数据是二维列表,先遍历的是行,后遍历的是列lst=[]#存储的是行数据for row in sheet.rows: sublst=[] #存储单元格数据 for cell in row: #其中cell指的是单元格 sublst.append(cell.value) lst.append(sublst)for item in lst: print(item)运行结果如下:
[\'景区\', \'天气\', \'气温\', \'旅游指数\'][\'三亚\', \'雷阵雨\', \'33/24℃\', \'一般\'][\'九寨沟\', \'阵雨\', \'32/18℃\', \'适宜\'][\'大理\', \'小雨转中雨\', \'23/15℃\', \'适宜\'][\'张家界\', \'晴\', \'35/24℃\', \'一般\'][\'桂林\', \'多云\', \'35/25℃\', \'一般\'][\'青岛\', \'多云转小雨\', \'30/27℃\', \'适宜\']进程已结束,退出代码为 07.pdfplumber模块的使用

import pdfplumber#打开pdf文件,就是with 文件名with pdfplumber.open(\'2020scool.pdf\') as pdf: for i in pdf.pages: #其中这里的pdf.pages就是这个pdf的页数 print(i.extract_text()) #extract_text()方法提取内容 print(f\'---------第{i.page_number}页结束\') #意思就是使用分隔符将页与页之间隔开运行结果部分如下:
本节完


