【AI深究】深度Q网络(DQN)全网最详细全流程详解与案例(附Python代码演示)| 原理与数学基础、案例流程(CartPole示例)| 案例代码演示 | 关键点与工程建议
大家好,我是爱酱。本篇我们聚焦于强化学习中最具代表性的深度方法之一——DQN(Deep Q-Network)。DQN是Q-Learning的深度扩展,能处理高维状态空间(如图像),广泛用于Atari游戏、机器人等场景。下面以简单环境为例,详细讲解DQN的原理、流程和代码实现。
注:本文章含大量数学算式、详细例子说明及代码演示,大量干货,建议先收藏再慢慢观看理解。新频道发展不易,你们的每个赞、收藏跟转发都是我继续分享的动力!
一、DQN原理与数学基础
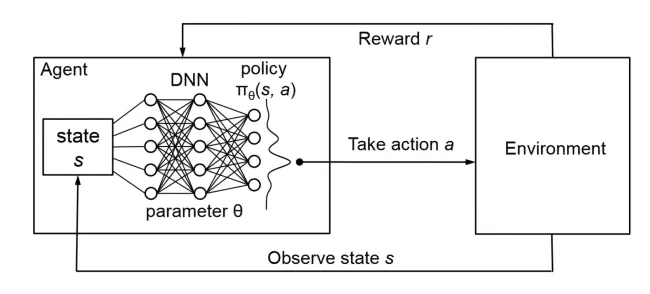
1. Q-Learning回顾
我们之前在强化学习的文章也介绍过Q-Learning,大家可以先去了解一下。这里附上传送门:
上篇:
【算法解析5/5 上】强化学习(RL)深度解析:常用算法、数学目标与核心公式、与其他任务的差别 | 状态、动作、奖励、策略、环境转移概率、折扣因子 | MDP、累积奖励、策略与价值函数、贝尔曼方程-CSDN博客
下篇:
【算法解析5/5 下】强化学习(RL)深度解析:常用主流算法(附Python代码)|动态规划、蒙特卡洛方法、时序差分学习、Q-Learning、策略梯度与Actor-Critic方法|优缺点与工程建议-CSDN博客
懒得看的伙伴可以看接下来的略解,不过强烈建议大家先去看看,对了解DQN会有大帮助!
Q-Learning算法通过维护Q表(Q-table)来学习最优动作价值函数,其更新公式为:
但在高维或连续状态空间,Q表无法存储,Q-Learning难以扩展。
2. DQN核心思想
DQN用神经网络近似Q函数,输入状态,输出所有动作的Q值:
其中为神经网络参数。
DQN的关键创新:
-
用神经网络替代Q表,解决高维状态空间问题
-
引入经验回放(Experience Replay),打破数据相关性
-
引入目标网络(Target Network),稳定训练过程
3. DQN目标与损失函数
DQN的目标是让Q网络输出的Q值尽量接近理想的“目标Q值”:
损失函数为:
其中为目标网络的参数,
为经验回放池。
二、DQN案例流程(以CartPole为例)
1. 环境介绍
-
以OpenAI Gym的CartPole-v1为例:智能体控制小车平衡一根杆,状态为4维连续变量,动作为左右移动。
2. DQN训练流程
-
初始化:
-
初始化Q网络和目标网络,参数相同
-
创建经验回放池(Replay Buffer)
-
-
每个回合(Episode):
-
重置环境,获取初始状态
-
对每个时间步
:
-
按
-贪婪策略选择动作
-
执行动作,观察奖励
和新状态
-
存储
到回放池
-
从回放池随机采样小批量数据
-
计算目标Q值
,用当前Q网络和目标网络分别计算
-
最小化损失
,用梯度下降更新Q网络参数
-
每隔若干步,将Q网络参数复制到目标网络
-
-
-
训练收敛后,智能体能学会平衡杆子
三、DQN案例代码演示(以CartPole为例,Stable-Baselines3简化版)
Stable-Baselines3是业界标准的强化学习库,DQN实现高度优化,能非常稳定地解决CartPole-v1。
注:记得要先 pip install 相應的Dependency及Library喔~还有请大家复制并在本地执行喔~
1) 依赖安装:
pip install stable-baselines3[extra] gym2) 代码(只需几行,训练和演示都很简单):
from stable_baselines3 import DQNimport gymenv = gym.make(\"CartPole-v1\", render_mode=\"human\")model = DQN( \"MlpPolicy\", env, verbose=1, learning_rate=0.001, buffer_size=100000, batch_size=128, gamma=0.99, exploration_fraction=0.4, exploration_final_eps=0.02, target_update_interval=250, train_freq=4, policy_kwargs=dict(net_arch=[256, 256]))model.learn(total_timesteps=80000, log_interval=10)# 演示obs, info = env.reset()while True: action, _ = model.predict(obs, deterministic=True) obs, reward, terminated, truncated, info = env.step(action) if terminated or truncated: obs, info = env.reset()参数设定:
-
exploration_fraction=0.4~0.5 -
exploration_final_eps=0.02 -
learning_rate=0.001 -
buffer_size=100000 -
batch_size=128 -
target_update_interval=250
注:谨记!训练是需要时间的,但实际最费时间的部分是调试参数,这部分往往要占大部分心血!
这已经是借助了stable-baselines的帮助,手写的话会更难,所以不要小看强化学习!
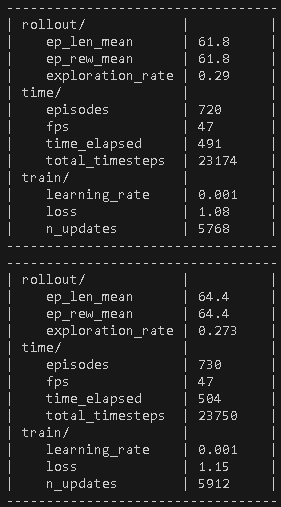
注:CartPole-v1用DQN通常需要5万~10万步才能收敛,实际时间可能会需要20分钟-1小时!
上图的Reward(ep_rew_mean)才六十几,要二百分才满分喔~
四、DQN关键点与工程建议
-
经验回放:打乱数据相关性,提升训练稳定性
-
目标网络:减少目标漂移,提升收敛速度
-
epsilon-贪婪策略:平衡探索与利用
-
适用场景:高维状态空间(如图像、连续变量),Q表无法表示时
五、总结
深度Q网络(DQN)是强化学习领域的重要里程碑,将深度神经网络与Q-Learning相结合,使得强化学习首次在高维状态空间(如图像、连续变量)上取得突破性进展。DQN通过引入经验回放和目标网络等关键技术,有效提升了训练的稳定性和泛化能力,推动了AI在游戏、机器人等实际场景的应用。
然而,DQN也存在一定的局限性,如对超参数和训练技巧较为敏感,容易出现训练不稳定、过估计等问题。针对这些挑战,后续又发展出了Double DQN、Dueling DQN、Rainbow DQN等改进方法。
实际工程中,建议合理设置超参数,结合经验回放、目标网络、探索策略等trick,并充分利用社区成熟实现(如Stable-Baselines3),以获得更高效、更稳定的强化学习效果。
DQN的提出不仅丰富了强化学习算法家族,也为深度强化学习的进一步发展奠定了坚实基础。希望本篇内容能帮助你全面理解DQN的原理、流程和实战要点,为你的AI探索之路提供有力工具。
如需进一步案例、调参技巧或进阶算法介绍,欢迎留言交流!
谢谢你看到这里,你们的每个赞、收藏跟转发都是我继续分享的动力。
如需进一步案例、代码实现或与其他聚类算法对比,欢迎留言交流!我是爱酱,我们下次再见,谢谢收看!


