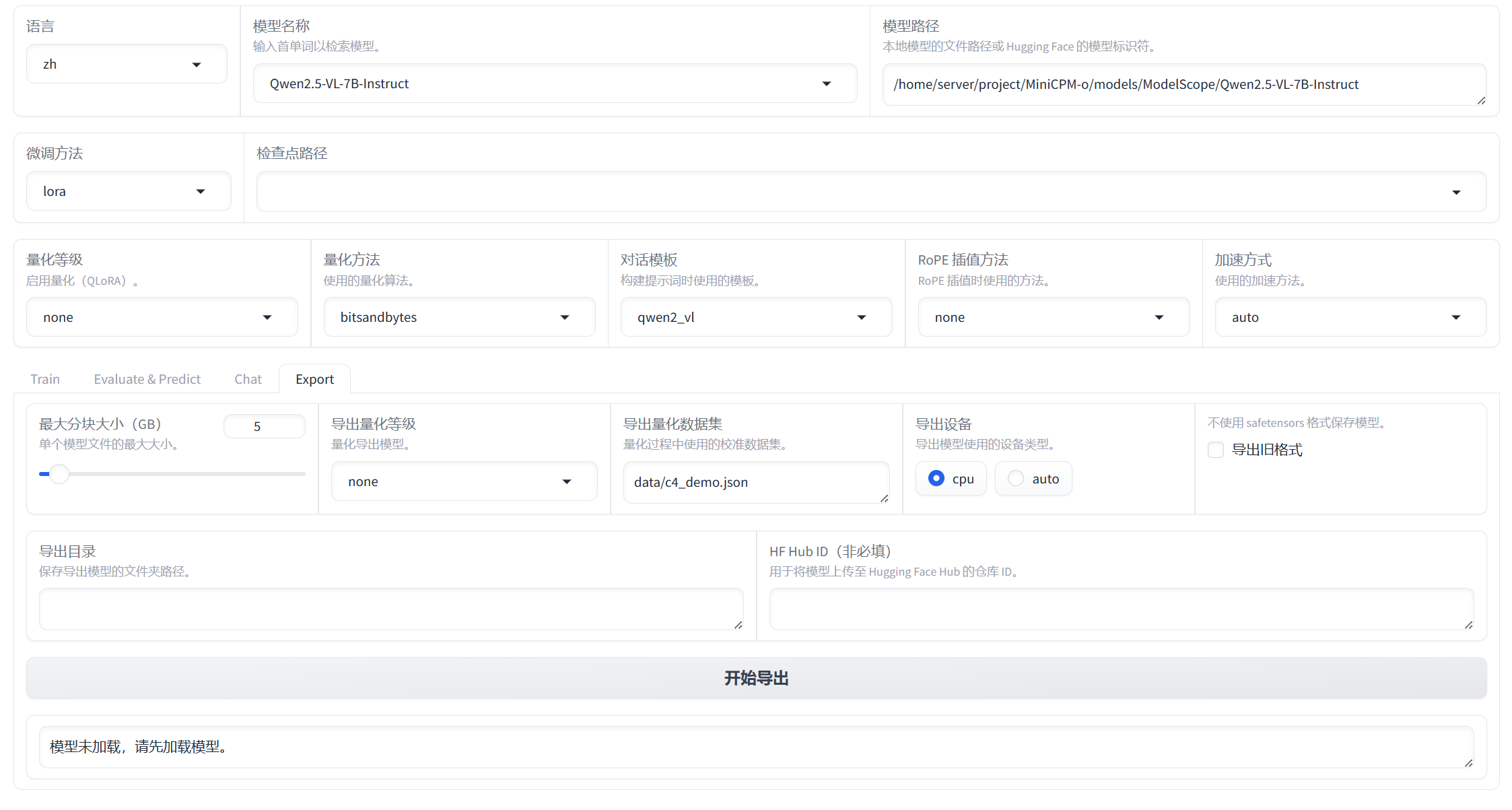
LLaMA-Factory全流程自学(详细到每一步)--网页使用篇_llamafactory-cli webui 的界面说明
1. 界面显示
经过前面的准备,我们已经学会了运行模型,此时我们就可以在webui上进行操作了,如下所示
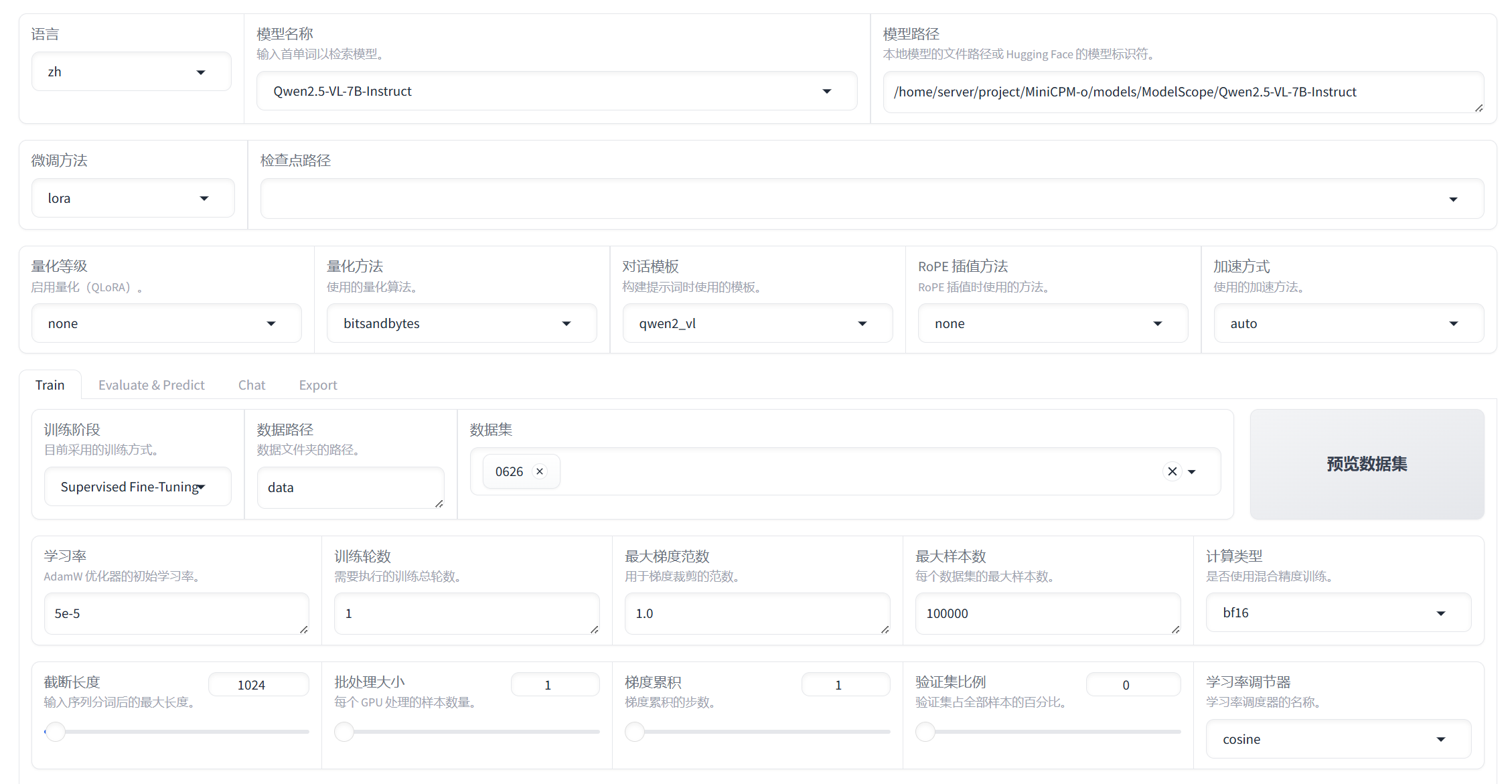
2. 微调流程
首先,在这个web上,我们一共需要进行4步骤

训练 评估 推理 导出(模型)
3. 训练
3.1 按前一章说的,导入模型路径+数据集(此时有一个更简单的方法,直接cd LLaMA-Factory,再运行LLaMA-Factory webui 就会自动弹出路径和数据集)
然后我们不改变任何参数,点击”开始“就可以训练了
3.2 点击”预览命令“,可以看到我们训练参数的设置,下面是我训练的参数:
llamafactory-cli train \\ --stage sft \\ --do_train True \\ --model_name_or_path /home/server/project/MiniCPM-o/models/ModelScope/Qwen2.5-VL-7B-Instruct \\ --preprocessing_num_workers 16 \\ --finetuning_type lora \\ --template qwen2_vl \\ --flash_attn auto \\ --dataset_dir data \\ --dataset 0626 \\ --cutoff_len 1024 \\ --learning_rate 5e-05 \\ --num_train_epochs 1.0 \\ --max_samples 100000 \\ --per_device_train_batch_size 1 \\ --gradient_accumulation_steps 8 \\ --lr_scheduler_type cosine \\ --max_grad_norm 1.0 \\ --logging_steps 5 \\ --save_steps 100 \\ --warmup_steps 0 \\ --packing False \\ --report_to none \\ --output_dir saves/Qwen2.5-VL-7B-Instruct/lora/train_2025-06-30-09-07-23 \\ --bf16 True \\ --plot_loss True \\ --trust_remote_code True \\ --ddp_timeout 180000000 \\ --include_num_input_tokens_seen True \\ --optim adamw_torch \\ --lora_rank 8 \\ --lora_alpha 16 \\ --lora_dropout 0 \\ --lora_target all
注意,如果报错,出现了内存不足的情况,可以修改一下以下参数

Ⅰ. 批处理大小(Batch Size)
- 每个 GPU 同时处理的样本数量,直接影响显存使用量。
Ⅱ. 截断长度(Sequence Length)
- 输入序列的最大长度。越大,模型需要处理的数据量就越多,消耗的显存也越多。
Ⅲ. 梯度累积(Gradient Accumulation Steps)
- 越小越好。
Ⅳ. 计算类型(Mixed Precision)
- 混合精度训练(fp16/bf16)可以显著减少显存占用。
3.3 训练结果
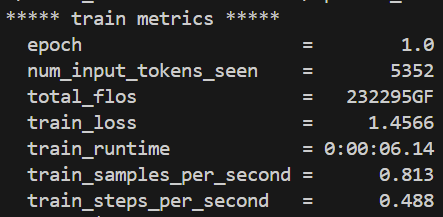
在终端里可以看到train metrics,这是一个epoch的结果 :
num_input_tokens_seen: 模型看到的 token 总数为 5352。total_flos: 总共执行了约 232,295 千亿次浮点运算(GigaFLOPs),用来表示计算量。train_loss: 训练损失为 1.4566,数值越高说明模型当前拟合效果越差(现在效果就很不好)。train_runtime: 整个 epoch 的运行时间是 6.14 秒。train_samples_per_second: 每秒处理约 0.813 个样本。train_steps_per_second: 每秒完成约 0.488 个优化步(step)。
运行完一次之后,显存就会降下来,不用担心多次运行会把显存占满
4 评估
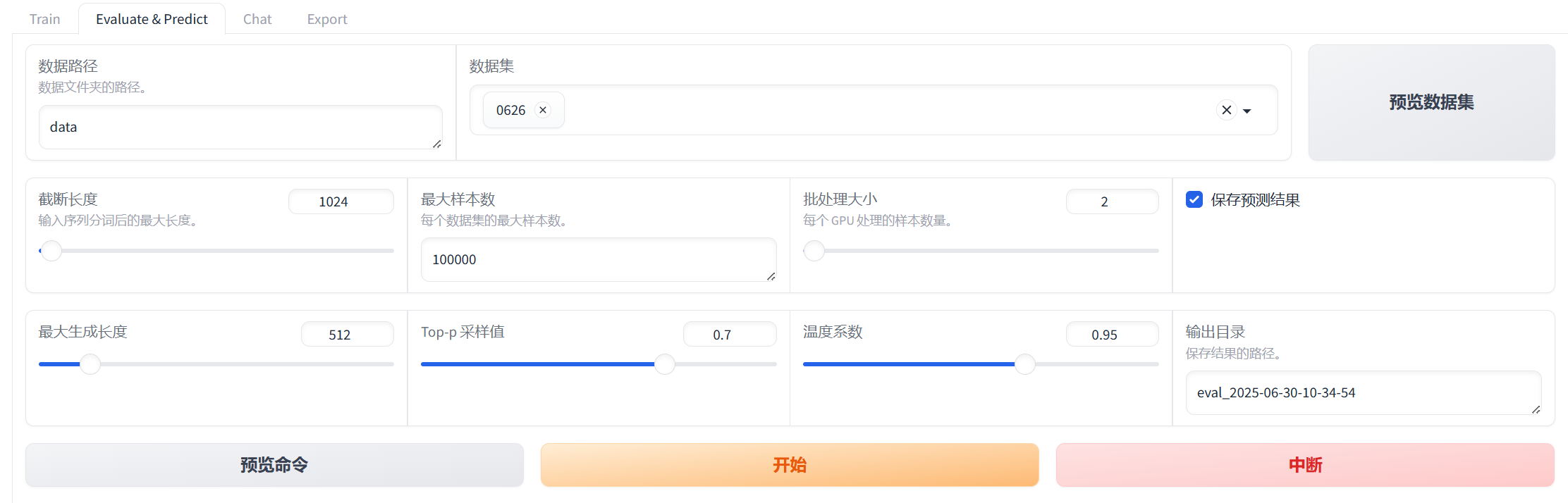
这个界面一共有六个参数,输出结果到eval文件夹中
- 截断长度:如果输入文本超过这个长度,会被截断以适应模型的输入要求。这对于控制模型处理的文本长度以及确保所有输入具有相似的大小非常重要。
- 最大样本数:定义每个数据集中用于评估或预测的最大样本数量。
- 批处理大小:指每个GPU处理的样本数量。这是深度学习中常见的概念,用于控制一次前向和反向传播中处理的数据量。较大的批处理大小可以提高训练效率,但占用更多显存。
- 最大生成长度:设定生成文本的最大长度。当生成的文本达到这个长度时,生成过程会停止。
- Top-p采样值:这是一种文本生成策略,其中模型根据概率分布选择下一个词。Top-p采样选择累积概率达到p的最小词汇子集,并从中随机选择下一个词。例如,如果p=0.7,则选择那些累积概率达到70%的词作为候选词。这种方法有助于平衡探索性和确定性,避免生成过于重复或单调的文本。
- 温度系数:控制生成文本的多样性。较低的温度值(如0.1)会使模型更倾向于选择高概率的词,从而生成更保守、更可预测的文本;而较高的温度值(如1.5)则鼓励模型探索低概率的词,增加生成文本的多样性和创造性。
点击”预览命令“
llamafactory-cli train \\ --stage sft \\ --model_name_or_path /home/server/project/MiniCPM-o/models/ModelScope/Qwen2.5-VL-7B-Instruct \\ --preprocessing_num_workers 16 \\ --finetuning_type lora \\ --quantization_method bitsandbytes \\ --template qwen2_vl \\ --flash_attn auto \\ --dataset_dir data \\ --eval_dataset 0626 \\ --cutoff_len 1024 \\ --max_samples 100000 \\ --per_device_eval_batch_size 2 \\ --predict_with_generate True \\ --max_new_tokens 512 \\ --top_p 0.7 \\ --temperature 0.95 \\ --output_dir saves/Qwen2.5-VL-7B-Instruct/lora/eval_2025-06-30-10-34-54 \\ --trust_remote_code True \\ --do_predict True \\ --adapter_name_or_path saves/Qwen2.5-VL-7B-Instruct/lora/train_2025-06-30-10-34-54
我的电脑报错内存不足,批处理大小改成1

这次没有报错out of memory了,而是wandb让我三选一
这段警告的意思是,当前的 run_name(即运行名称,在Weights & Bias平台中用于标识一次训练或预测任务的名字)被设置成与 TrainingArguments.output_dir 相同的值。通常情况下,output_dir 是用来指定模型输出、检查点和其他结果文件存放目录的路径。如果你没有特意设置 run_name 参数,它可能会默认使用这个目录路径作为其名字
我选择了3,即不把我的运算结果可视化,应该也不会传到wandb平台了
{ \"predict_bleu-4\": 11.667883333333334, \"predict_model_preparation_time\": 0.0076, \"predict_rouge-1\": 41.86638333333334, \"predict_rouge-2\": 11.897333333333334, \"predict_rouge-l\": 22.21473333333334, \"predict_runtime\": 26.0097, \"predict_samples_per_second\": 0.192, \"predict_steps_per_second\": 0.115}
这是我得到的评估结果,翻译一下就是:
predict_bleu-4: 11.6679
- BLEU(Bilingual Evaluation Understudy) 分数范围从0到100,分数越高,表示生成的文本与参考文本越接近。这里的
predict_bleu-4表示使用了4个连续的n-gram来计算BLEU得分,得分为11.6679,模型的表现不好。
predict_model_preparation_time: 0.0076
- 这是指模型准备时间,即加载和初始化模型所需的时间。
predict_rouge-1: 41.8664
ROUGE-1主要衡量单字词重叠情况,得分41.8664意味着你的模型在单字词层面与参考摘要有较高的重叠度。
predict_rouge-2: 11.8973
ROUGE-2考虑的是两个连续单词的重叠情况,较ROUGE-1低很多,表明在长序列的匹配上模型表现不佳。
predict_rouge-l: 22.2147
ROUGE-L使用最长公共子序列(LCS)来比较生成文本与参考文本之间的相似性,考虑了句子结构。得分22.2147显示在保持句子结构相似性方面较差。
predict_runtime: 26.0097
- 总运行时间为26.0097秒。
predict_samples_per_second: 0.192
- 每秒处理的样本数量为0.192,数值小意味着处理每个样本需要较长的时间。
predict_steps_per_second: 0.115
- 每秒执行的步骤数为0.115,较低的值表示模型复杂度高或者硬件资源有限。
综合分析:
- 模型性能:从BLEU和ROUGE得分来看,模型在生成文本的质量上有一定的表现,特别是在单字词层面(ROUGE-1),但在多词组合(如ROUGE-2)和句法结构(ROUGE-L)上存在不足。
- 效率问题:模型准备时间很短,但是处理速度(samples_per_second 和 steps_per_second)较低,这可能是由于模型较大、批处理大小设置不当或是硬件限制导致的。
5. 推理结果
选择检查点路径(就选刚才训练好的)
选用默认的方法

一样的图片和prompt, 训练后结果:
是否存在安全隐患: 是
安全等级: 3
不安全生产因素:
- 木制表面上存在明显的损坏,可能会导致桌面上的物品掉落,增加滑倒或砸伤的风险。
- 桌面中心的孔洞周围有碎片,增加了割伤的风险。
- 木质表面有明显的裂痕,长期使用可能会导致桌面结构不稳固,增加倒塌的风险。
建议措施:
- 对桌面上的孔洞进行修复,清除周围碎片,防止割伤。
- 使用胶水或其他材料填补桌面的裂缝,确保桌面结构稳固。
- 在桌子周围放置防滑垫,以降低滑倒的风险。
- 如果发现桌面有更多损坏或不稳固的地方,应尽快联系专业人员进行修复或更换。
点击卸载模型,删除检查点路径,然后点击加载模型,输入同样的图片和提示词
是否存在安全隐患: 是
安全等级: 2
不安全生产因素:
- 木制桌面上的洞孔可能使物体(如笔、纸张等)掉入,存在安全隐患。
- 洞孔边缘有明显的木屑,表明可能存在工具使用不当或操作失误。
建议措施:- 立即修补桌面上的洞孔,防止物体掉入。可以使用木胶或木屑填补,并用砂纸打磨光滑。
- 清理洞孔周围的木屑,保持桌面整洁,减少安全隐患。
- 对使用工具进行定期检查,确保操作安全,避免类似情况再次发生。
结论:
1.结果明显发生改变,训练前后,安全等级评级有改动
2.训练后会同时输出不安全因素与措施,训练前只输出不安全因素
6. 导出模型
依然是不修改任何参数,选择刚训练好的检查点路径,并且选择导出目录,就可以导出了