ELK集群部署实战指南:Elasticsearch, Logstash, Kibana
本文还有配套的精品资源,点击获取 
简介:ELK堆栈结合了Elasticsearch、Logstash和Kibana,提供了一个强大的日志管理和分析平台。Elasticsearch,作为分布式搜索引擎,支持全文搜索和复杂的数据分析;Logstash作为数据处理管道,负责从各种源收集、过滤和传输日志数据;而Kibana则提供数据的可视化界面,便于理解和分析日志数据趋势。本方案旨在通过集群部署,实现高效、可扩展的日志解决方案,适用于IT管理员和开发人员监控、搜索和分析大量日志数据。在部署过程中,需要关注JDK1.8的兼容性和RPM包的使用,以确保ELK堆栈的正确安装和运行。 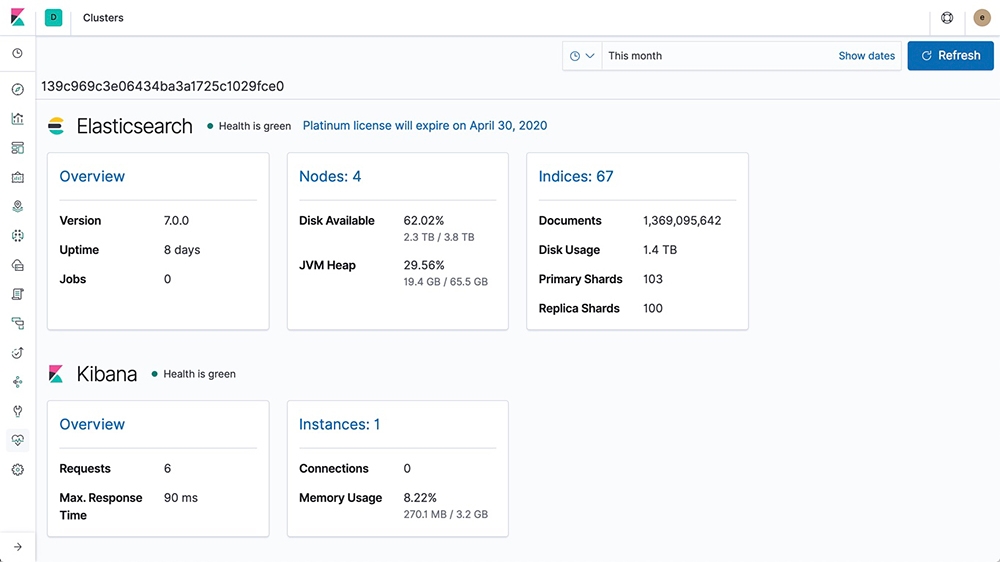
1. ELK集群概览
ELK是Elasticsearch、Logstash和Kibana的缩写,是目前流行的日志管理解决方案。本章将对ELK集群有一个全面的介绍。
1.1 ELK的定义与组成
ELK是一套开源的、功能强大的日志分析工具。它由三个主要组件构成:Elasticsearch,一个基于Lucene的搜索引擎,用于存储、搜索和分析数据;Logstash,一个数据处理管道,能够从不同来源收集数据,然后进行过滤和解析;Kibana,一个数据可视化工具,可以让用户方便地对日志数据进行可视化。
1.2 ELK的应用场景
ELK可以应用在各个领域,包括但不限于日志分析、数据搜索、应用性能监测和商业智能。它支持结构化和非结构化数据,并提供了强大的搜索和分析能力,使得ELK成为处理大数据的理想工具。
1.3 ELK的优势
ELK之所以受到广泛欢迎,主要得益于其灵活性、可扩展性和易用性。无论是部署在单台服务器上,还是在大型分布式环境中,ELK都能够提供稳定的性能和服务。此外,ELK拥有丰富的插件生态,能够满足各种自定义需求,这是其独特的技术优势。
接下来的章节将详细介绍Elasticsearch、Logstash和Kibana的具体功能和特性,以及ELK集群的部署流程和关键配置,帮助读者深入理解和掌握ELK技术栈。
2. Elasticsearch的功能与特性
2.1 Elasticsearch基础架构
2.1.1 Elasticsearch分布式设计原理
Elasticsearch作为一个分布式的全文搜索和分析引擎,它通过集群的方式提供了水平可扩展性、高可用性和容错能力。在分布式设计中,Elasticsearch通过分散数据和负载到多个节点上来提升性能和数据的冗余。每个节点都是一个运行Elasticsearch实例的Java进程。
为了实现数据的分布和冗余,Elasticsearch使用了分片(shards)和副本(replicas)机制。每个索引由多个分片组成,这些分片可以分布在集群的不同节点上。在Elasticsearch中创建索引时,可以定义分片的数量,这通常会根据数据量、查询负载和可用硬件资源来确定。
Elasticsearch集群由以下主要组件构成:
- 节点(Node) :一个运行中的Elasticsearch实例,可以执行数据的存储、索引和搜索操作。
- 分片(Shard) :索引数据的逻辑分片,这些分片可以分布在整个集群中。
- 副本(Replica) :每个分片都可以有零个或多个副本,副本是分片的备份,用于提高数据的可用性和搜索性能。
- 主节点(Master Node) :负责管理集群状态,如索引创建、维护索引元数据、处理节点加入或离开集群等。
- 数据节点(Data Node) :实际存储数据并执行数据相关的操作,如CRUD、搜索和聚合等。
2.1.2 核心组件及其作用
Elasticsearch的核心组件包括:
- 索引(Index) :存储具有相似结构的数据的地方,例如,所有的日志文件可以存储在一个索引中。
- 文档(Document) :索引中的最小数据单元,它是一个JSON对象。
- 类型(Type) :用来描述文档结构,7.x版本之后被弃用,8.x版本已经完全移除。
- 映射(Mapping) :定义索引中字段的名称、类型以及各种属性,例如是否被索引,是否支持聚合等。
每个Elasticsearch节点都可以承担不同的角色,主要有以下几种类型:
- 主节点(Master-Eligible Node) :参与选举行为,负责创建或删除索引、分配分片到节点等。
- 数据节点(Data Node) :存储索引数据的节点,执行数据相关操作。
- 客户端节点(Client Node) :转发请求到主节点或数据节点,不存储数据也不参与集群的选举行为。
- 协调节点(Coordinating Node) :默认情况下,每个节点都是协调节点,负责将请求分发到合适的节点,并将结果聚合返回。
通过将这些核心组件整合在一起,Elasticsearch可以在多个节点之间有效地分散数据和计算负载,从而提供快速和可靠的搜索服务。
2.2 Elasticsearch的数据管理
2.2.1 数据索引与查询机制
在Elasticsearch中,数据索引与查询机制是其核心功能之一,它允许用户以非常灵活的方式来存储和检索数据。数据被索引后,可以迅速进行全文搜索、结构化查询和复杂的数据分析。
索引机制:
- 创建索引 :可以手动创建索引,并指定分片和副本数等参数,或让Elasticsearch根据数据自动创建索引。
- 索引文档 :可以通过REST API将JSON格式的数据文档索引到指定的索引中。
- 文档更新 :Elasticsearch中的文档是不可变的,因此更新操作实际上是删除旧文档并创建一个新文档的过程。
查询机制:
- 查询表达式(Query DSL) :Elasticsearch提供了一个强大的查询表达式语言,允许用户以JSON格式构造复杂的查询。
- 全文搜索 :支持对文本字段进行全文搜索,包括模糊匹配、短语搜索等。
- 布尔查询 :可以使用布尔操作符(AND、OR、NOT)组合多个查询语句。
- 高亮显示 :对于搜索结果,可以高亮显示匹配的文本片段。
- 聚合查询 :除了基本的搜索功能外,Elasticsearch还提供了聚合框架来执行数据分析任务,如统计、数据透视等。
2.2.2 数据分片与副本策略
Elasticsearch使用分片和副本策略来增强数据的可靠性和系统的搜索性能。理解它们的工作原理对于有效地设计和维护Elasticsearch集群至关重要。
分片策略:
- 分片的目的是为了扩展性 :Elasticsearch将索引切分成多个分片,这些分片可以分布到集群中的不同节点上。当索引的数据量变得非常大时,分片可以帮助分散负载和存储压力。
- 数据均匀分布 :Elasticsearch会尽量保证分片均匀分布在所有节点上,以避免出现负载不均的情况。
副本策略:
- 副本提高数据可靠性 :每个分片可以有零个或多个副本。副本与它们的原始分片在功能上是等价的,这意味着任何时候都可以使用副本提供读取服务。
- 自动故障转移 :当一个节点(包含主分片或副本分片)失效时,Elasticsearch会自动将副本提升为新的主分片,以保证集群的可用性。
副本的创建有以下规则:
- 每个分片必须有一个副本 :这是Elasticsearch的默认设置,保证了至少有一份数据的备份。
- 副本数可以配置 :根据需要,副本数量可以在创建索引时或之后动态调整。
合理地配置分片和副本的数量,可以在性能和数据安全性之间取得平衡。例如,如果副本数量设置得太高,可能会增加集群的存储成本;如果分片数量过多,可能会增加集群的管理复杂度。
2.3 Elasticsearch的搜索能力
2.3.1 基于JSON的搜索DSL
Elasticsearch中的搜索功能强大而灵活,主要通过一个基于JSON的Domain Specific Language(DSL)来实现,被称作查询DSL。这个DSL允许用户使用JSON构建查询,并通过Elasticsearch REST API发送。
基本的查询类型包括:
- 全文搜索 :Elasticsearch允许用户执行全文搜索,如匹配文本字段中的某些词汇。
- 精确匹配查询 :用于查找与指定值完全一致的字段。
- 范围查询 :查找字段值在指定范围内的文档。
- 布尔查询 :将多个查询组合成一个复合查询,使用布尔操作符(AND、OR、NOT)来组合。
- 过滤查询(Filter Query) :用于快速筛选出一组符合特定条件的文档,而不计算相关性分数。
2.3.2 聚合与分析功能详解
除了强大的搜索能力之外,Elasticsearch还提供了丰富的聚合功能,允许用户对数据进行分析并提取有价值的信息。聚合可以用于数据汇总、计算统计数据、探索数据的趋势等。
聚合主要分为以下几类:
- 桶聚合(Bucket Aggregations) :将数据分组到桶中,每个桶代表一组满足特定条件的文档集合。
- 度量聚合(Metric Aggregations) :对每个桶中的文档进行计算,提供诸如平均值、最大值、最小值等统计信息。
- 管道聚合(Pipeline Aggregations) :基于其他聚合的结果进行进一步的聚合计算,如基于平均值计算整体平均值。
- 矩阵聚合(Matrix Aggregations) :在多个字段上执行复杂的矩阵运算。
聚合查询的典型用法包括:
- 数据报告 :汇总不同部门的销售额,计算平均值等。
- 数据分析 :根据时间序列数据,分析数据的模式和趋势。
- 结果过滤 :使用聚合结果动态过滤搜索结果。
为了支持复杂的分析操作,Elasticsearch还提供了强大的脚本功能,允许在聚合中使用表达式来执行自定义的计算逻辑。这使得Elasticsearch不仅适用于搜索场景,还可以作为强大的数据分析工具使用。
在本章节中,我们详细探讨了Elasticsearch的基础架构、核心组件、以及其数据管理和搜索能力。接下来的章节将介绍Logstash在数据处理流程中的工作原理及其插件机制。
3. Logstash的数据处理流程
随着日志数据量的不断增长和实时分析需求的提升,Logstash作为ELK堆栈中的日志收集和处理工具,显得尤为重要。它能够有效地将不同来源的数据聚合、过滤并输出到目标系统中,为数据分析和可视化提供必要的支持。本章将深入探讨Logstash的数据处理流程,包括其工作原理、插件机制以及如何在不同使用场景中应用Logstash以实现数据的高效管理。
3.1 Logstash的工作原理
3.1.1 输入、过滤和输出三大组件
Logstash的核心架构基于三个主要的组件:输入(input)、过滤(filter)和输出(output)。这三个组件协同工作,形成了一条高效的数据处理流水线。
-
输入(input) :Logstash能够从多个源接收数据,包括文件、TCP套接字、消息队列、标准输入以及各种API。每个输入源都可以配置多个插件,以适应不同的数据源格式。例如,
file输入插件可以读取指定路径下的日志文件,而beats插件则用于接收通过Filebeat发送的数据。ruby input { file { path => \"/var/log/nginx/access.log\" start_position => \"beginning\" } beats { port => 5044 } }在上述代码段中,
file插件被配置为读取Nginx的访问日志,而beats插件配置为监听端口5044以接收Filebeat发送的日志数据。 -
过滤(filter) :过滤阶段是处理数据流的核心环节,它允许用户对事件进行复杂的处理和转换。这些操作可以通过多种过滤器插件实现,例如
grok用于解析非结构化日志文本,mutate用于字段的重命名、删除或转换等。ruby filter { if [type] == \"nginx-access\" { grok { match => { \"message\" => \"%{COMBINEDAPACHELOG}\" } } mutate { remove_field => [\"message\"] } } }在这个例子中,
grok过滤器使用预定义的正则表达式模式解析Nginx访问日志。解析后的数据将不再需要原始的message字段,因此使用mutate过滤器将其移除。 -
输出(output) :处理完的数据最终需要输出到目的地,Logstash支持多种输出目标,如Elasticsearch、文件、消息队列等。输出插件定义了数据的最终去向。
ruby output { if [type] == \"nginx-access\" { elasticsearch { hosts => [\"localhost:9200\"] index => \"nginx-%{+YYYY.MM.dd}\" } } }在上述代码段中,符合条件的日志事件将被发送到Elasticsearch,并按照日期格式化索引名称。
3.1.2 数据流的生命周期
Logstash处理数据的过程实际上就是数据流的生命周期。这个周期从输入源接收数据开始,经过过滤阶段的加工与转换,最终以预设的格式输出到目标系统。为了保证高吞吐量和低延迟,Logstash采用多线程处理数据流。每个组件独立运行,通过内部队列进行数据传递。
整个数据流的生命周期如下图所示:
graph LR A[输入 Input] --> B[过滤 Filter] B --> C[输出 Output]Logstash的事件处理流程强调线性且可预测的执行顺序。这意味着在一个组件处理完事件后,才会将事件传递给下一个组件。在过滤阶段,可以配置多个过滤器,它们会按照配置顺序依次对事件进行处理。
3.2 Logstash的插件机制
3.2.1 常用插件介绍与应用场景
Logstash的灵活性来源于其插件机制。通过插件,Logstash可以轻松扩展来支持新的输入源、过滤器和输出目标。Logstash社区提供了大量插件,涵盖从常见数据源到复杂数据转换的各种需求。
- 输入插件 :除了基本的
file和beats插件,还有http用于处理HTTP请求,syslog用于处理系统日志等。 - 过滤插件 :除了
grok和mutate,还有drop用于丢弃不感兴趣的事件,csv用于处理CSV格式的日志。 - 输出插件 :除了
elasticsearch,还有file用于将数据写入文件系统,kafka用于将数据发送到Kafka消息队列等。
下表列出了Logstash中一些常用插件及其应用场景:
| 插件类型 | 插件名称 | 应用场景 | |----------|-----------|----------------------------| | 输入插件 | file | 读取文件系统中的日志文件 | | 输入插件 | beats | 接收Filebeat发送的数据流 | | 过滤插件 | grok | 解析非结构化文本 | | 过滤插件 | mutate | 字段的修改与转换 | | 输出插件 | elasticsearch | 将数据输出到Elasticsearch | | 输出插件 | file | 将数据写入到文件 | | 输出插件 | kafka | 将数据发送到Kafka消息队列 |
3.2.2 插件配置与数据处理优化
在配置Logstash插件时,可以通过参数控制插件行为,从而优化数据处理流程。例如,设置 buffer_size 参数以增加内存缓冲区大小,可以在网络波动或负载突增时,减少数据丢失的风险。
filter { mutate { add_field => { \"[@metadata][index]\" => \"my_index\" } remove_field => [\"message\"] }} 在上面的代码块中, mutate 插件被用来添加和删除字段,这样的修改在处理大型日志数据时尤其有用,可以优化搜索性能和提高数据的相关性。
对于过滤器的配置,合理使用条件语句可以控制哪些事件被过滤器处理,以达到精确控制数据流的目的。
if [type] == \"nginx-access\" { grok { ... }} 这段代码展示了如何仅对类型为 nginx-access 的日志事件应用 grok 过滤器,从而避免对不相关日志事件的无效处理。
3.3 Logstash的使用场景分析
3.3.1 日志收集与处理
Logstash在日志收集与处理中扮演着至关重要的角色。通过配置不同的输入插件,它可以覆盖从服务器系统日志到应用程序日志,再到网络设备日志的各种场景。例如,对于系统日志,可以使用 file 插件定期轮转和收集日志文件;对于应用程序日志,可以通过 tcp 或 udp 插件接收应用主动推送的日志消息。
3.3.2 数据转换与增强
数据转换和增强是Logstash强大能力的体现。例如,通过 grok 插件,可以将复杂的非结构化文本日志转换为结构化的字段,方便后续的搜索和分析。进一步地,通过 mutate 插件,可以调整字段类型或进行字段的重命名、合并等操作。最终,Logstash通过输出插件将结构化的日志数据输出到Elasticsearch、文件或消息队列中,为数据分析和监控提供强有力的支撑。
input { file { path => \"/var/log/sys.log\" }}filter { grok { match => { \"message\" => \"%{SYSLOGLINE}\" } } mutate { convert => { \"[@timestamp]\" => \"string\" } }}output { elasticsearch { hosts => [\"localhost:9200\"] index => \"syslog-%{+YYYY.MM.dd}\" }} 这段配置展示了从系统日志文件中收集数据、通过 grok 解析日志内容,并将结构化数据以指定的格式输出到Elasticsearch的过程。通过这种方式,日志数据变得易于查询和分析,极大地提高了运维和开发团队的效率。
4. Kibana的可视化能力
Kibana是ELK堆栈中的可视化和分析平台,使得用户可以轻松地对Elasticsearch中的数据进行探索和可视化展示。Kibana提供了丰富的界面,帮助用户从大量数据中提炼出有价值的信息,以及创建直观的仪表板和报告。本章将深入探讨Kibana的使用,仪表板与故事功能,以及如何进行高级定制。
4.1 Kibana的基本使用
4.1.1 Kibana界面与功能概览
Kibana的界面直观,用户体验友好,功能强大。使用Kibana,用户可以执行以下操作:
- 连接到Elasticsearch集群。
- 管理索引模式,用于指定Kibana将操作哪些数据。
- 使用Discover来搜索和浏览Elasticsearch中的数据。
- 利用Visualize创建图表、地图和其他数据可视化。
- 通过Dashboard创建自定义的仪表板来展示实时数据。
- 制作数据故事和报告,将分析结果分享给他人。
Kibana的界面分为菜单栏、主工作区和侧边栏三个部分。菜单栏包含了主功能的入口,例如Discover、Visualize、Dashboard和Management。主工作区则用于展示相应功能的结果或进行具体的操作。侧边栏为用户提供了索引模式、搜索栏和应用管理等快捷方式。
4.1.2 数据探索与可视化展示
Kibana的Discover面板是进行数据探索的起点。用户可以查看索引中的实时数据,并能够利用内置的搜索功能和过滤器来深入分析。Kibana的搜索语法与Elasticsearch的查询DSL类似,但做了简化,使得用户可以更容易地进行文本搜索、范围搜索等操作。
在Visualize面板中,用户可以将数据进行可视化。Kibana提供了各种类型的图表,例如柱状图、折线图、饼图、表格和地图等。用户可以根据自己的需求选择合适的图表类型,并通过拖拽的方式来调整数据字段,实现不同维度的可视化分析。
4.2 Kibana的仪表板与故事功能
4.2.1 创建和管理仪表板
仪表板功能是将多个可视化组件组合在一起展示的工具。通过仪表板,用户可以构建出包含关键指标的实时仪表板,为决策提供支持。用户可以将Visualize创建的单个图表添加到仪表板上,并进行大小调整、排列和保存。仪表板支持水平和垂直滚动,可以展示大量的数据。
创建仪表板时,Kibana提供了灵活的布局选择,用户可以通过拖放的方式添加、排列和调整组件的位置。此外,Kibana还提供了仪表板分享功能,允许用户将仪表板发布到互联网上或嵌入到其他网站中。
4.2.2 制作数据故事与报告
数据故事功能在Kibana 6.6版本中引入,允许用户通过创建一系列视觉化的幻灯片来讲述数据背后的故事。数据故事可以包含文字描述、图片、视频以及各种可视化的图表。每个幻灯片都可以独立地进行编辑和调整,使得用户可以灵活地构建出数据报告。
与仪表板不同,数据故事更侧重于讲述一个连贯的故事。用户可以逐步展示数据,引导观众按照特定的流程来理解和分析数据。故事可以通过Kibana内置的分享功能进行分享,也可以通过电子邮件或导出为PDF文件的方式进行发布。
4.3 Kibana的高级定制
4.3.1 交互式元素与搜索增强
Kibana支持高级搜索功能,例如带有自动建议的搜索栏、时间过滤器和数据过滤器。用户可以利用这些工具进行精确的数据搜索和筛选,以便更有效地分析数据。Kibana还支持搜索模板,使得用户可以保存常用的搜索查询,并在需要时重复使用。
为了进一步提升用户体验,Kibana提供了多种交互式元素,例如下拉列表、滑块和标签云。这些元素可以集成到仪表板中,使得数据展示更加动态和直观。例如,通过滑块来控制时间范围,可以实时查看不同时间段内的数据变化。
4.3.2 定制化脚本与外部数据集成
Kibana允许用户编写自己的脚本来增强搜索和可视化功能。通过使用Kibana的开发工具,用户可以利用JavaScript来编写自定义的探索、可视化和应用程序。这些定制化的脚本可以极大地扩展Kibana的功能,以满足特定的业务需求。
在集成外部数据方面,Kibana通过其应用程序接口(API)和其他工具,允许用户将第三方数据源或服务集成到现有的Kibana仪表板中。例如,可以使用Elasticsearch的聚合功能对数据进行处理,并结合Kibana的可视化工具来展示结果。
graph LR A[开始创建可视化] --> B[选择图表类型] B --> C[拖拽添加数据字段] C --> D[调整图表设置] D --> E[保存并添加到仪表板] E --> F[编辑仪表板布局] F --> G[完成仪表板构建]在上述流程图中,我们可以看到创建Kibana可视化到仪表板的基本步骤,这为用户提供了可视化构建的概览。
通过上述内容,我们可以看到Kibana不仅是一个强大的数据可视化工具,还提供了丰富的定制化选项和交互功能,使得用户能够深入分析和探索数据,创建出符合自己需求的数据仪表板和故事。
5. 集群部署的重要性与实现
5.1 集群部署的必要性
5.1.1 高可用性与扩展性分析
在现代IT架构中,系统的高可用性是至关重要的。高可用性意味着系统能够在极小的停机时间内运行,并且能够抵御硬件故障、软件错误、网络问题等各种潜在问题。ELK(Elasticsearch、Logstash、Kibana)集群能够通过其分布式特性,显著提升数据处理的高可用性。
ELK集群部署可实现数据的多节点冗余存储,确保在个别节点出现故障时,其他节点能够立即接管工作,保证服务不中断。此外,ELK集群部署还能通过增加节点的方式轻松扩展系统容量,实现水平扩展,以应对不断增长的数据量和处理需求。
5.1.2 集群部署对系统的影响
集群部署不仅仅是为了提高可用性和扩展性,它还对整体系统的性能、稳定性、容错性产生了深远的影响。在性能方面,多个节点协同工作可以分摊处理负载,提升查询和索引的响应速度。稳定性方面,节点间的数据副本机制可以有效防止数据丢失。在容错性方面,集群设计能自我检测和恢复单点故障,极大提升了整体系统的鲁棒性。
在实施集群部署时,需要考虑网络延迟、节点配置均衡、数据一致性等诸多因素,这些因素都直接关系到集群部署的成功与否。
5.2 集群部署的准备工作
5.2.1 硬件与网络环境要求
部署ELK集群之前,硬件和网络环境的准备至关重要。理想的硬件配置应包括足够的CPU资源以处理大量的数据和并发查询,足够的内存用于缓存频繁查询的数据,以及足够的存储空间用于长期保存日志数据。网络方面,稳定的网络连接和适当的带宽是必要的,以保证节点间通信的顺畅。
5.2.2 JDK与相关依赖软件安装
ELK组件依赖于Java开发环境,因此需要先安装Java Development Kit(JDK)。一般推荐使用最新版本的JDK。除了JDK之外,ELK集群各组件的安装还需要依赖于一些其他的系统软件,如gcc、gcc-c++等。在安装这些依赖之前,应当确保操作系统的包管理器已更新到最新状态。
5.3 集群部署的实施步骤
5.3.1 Elasticsearch集群部署细节
Elasticsearch集群的基本配置
部署Elasticsearch集群需要对每个节点进行详细配置。配置内容包括但不限于集群名称、节点名称、网络地址、数据和日志目录。下面是一个Elasticsearch节点配置文件的示例:
# elasticsearch.ymlcluster.name: my-elasticsearch-clusternode.name: \"es-node1\"network.host: 192.168.1.10http.port: 9200transport.tcp.port: 9300path.data: /var/lib/elasticsearch/datapath.logs: /var/log/elasticsearch/logsdiscovery.seed_hosts: [\"192.168.1.10\", \"192.168.1.11\"]cluster.initial_master_nodes: [\"es-node1\"]以上配置指定了集群名称、节点名称、网络地址、端口信息、数据存储路径以及集群发现的种子节点。
Elasticsearch节点的启动与加入集群
配置完成后,需要以特定的配置启动Elasticsearch实例。每个实例启动后会加入到集群中,成为集群的一部分。可以通过Elasticsearch提供的RESTful API或者通过Kibana的Dev Tools查看集群状态,确保节点成功加入集群。
5.3.2 Logstash与Kibana的集成配置
Logstash的配置与集成
Logstash的配置文件通常包括输入、过滤和输出三个部分。集成到Elasticsearch集群非常简单,只需在输出配置中指定Elasticsearch的集群地址即可:
# logstash.confinput { file { path => \"/path/to/logfile.log\" }}filter { # 过滤规则}output { elasticsearch { hosts => [\"http://elasticsearch_node_address:9200\"] }} 上述配置中, hosts 参数指向了Elasticsearch集群中的一个或多个节点地址。
Kibana的配置与集成
Kibana的配置文件 kibana.yml 需要指定Elasticsearch服务器的地址,以及Kibana服务的监听地址和端口:
# kibana.ymlserver.host: \"localhost\"elasticsearch.hosts: [\"http://elasticsearch_node_address:9200\"]完成配置后,启动Kibana服务,就可以通过浏览器访问Kibana界面,并开始使用其数据可视化和分析功能。
总结
在本章中,我们深入探讨了ELK集群部署的必要性、准备工作和实施步骤。ELK集群部署的核心目的是提高系统的高可用性与扩展性,为日志管理和数据分析提供强大的支持。通过合理的硬件选型、网络规划,以及仔细的配置和集成步骤,可以有效地将ELK组件整合成为强大的日志处理和分析系统。在后续的章节中,我们将继续深入ELK集群部署的细节,包括具体的环境预配置、关键步骤的实施,以及部署后的监控和维护策略。
6. ELK集群部署流程及关键配置
在前几章中,我们深入探讨了ELK(Elasticsearch, Logstash, Kibana)集群的各个组件及其强大的数据处理能力。随着对每个组件功能的了解,本章将焦点转向实际部署。我们将通过一系列步骤,详细讲解如何部署一个稳定且高效的ELK集群,以及在此过程中需要关注的关键配置。
6.1 ELK环境的预配置
在动手部署ELK集群之前,准备工作是不可或缺的。预配置环节通常包括软件安装和环境设置,为后续部署打下坚实基础。
6.1.1 RPM包的安装与环境搭建
首先,需要确保操作系统环境满足ELK组件的运行需求。对于基于RPM包管理器的Linux发行版,如CentOS或RHEL,可通过以下命令安装Elasticsearch, Logstash, Kibana的RPM包:
# 安装Elasticsearch RPM包sudo rpm -i https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.x.x.rpm# 安装Logstash RPM包sudo rpm -i https://artifacts.elastic.co/downloads/logstash/logstash-7.x.x.rpm# 安装Kibana RPM包sudo rpm -i https://artifacts.elastic.co/downloads/kibana/kibana-7.x.x-x.rpm紧接着,安装Java环境,因为ELK是基于Java构建的:
sudo yum install java-1.8.0-openjdk安装完成后,需要对每个组件进行环境配置,包括但不限于内存分配、网络配置和日志级别等。
6.1.2 配置文件的定制化调整
ELK组件的配置文件通常位于 /etc 目录下,例如Elasticsearch的配置文件为 /etc/elasticsearch/elasticsearch.yml 。针对不同的使用场景,需要进行相应的配置定制。以下是一些基本配置项示例:
# Elasticsearch配置示例cluster.name: \"my-elk-cluster\"node.name: \"node-1\"network.host: 0.0.0.0http.port: 9200transport.tcp.port: 9300# Logstash配置示例input { # 例如从文件系统收集日志 file { path => \"/var/log/myapp.log\" start_position => \"beginning\" }}output { # 将数据发送到Elasticsearch elasticsearch { hosts => [\"localhost:9200\"] index => \"myapp-logs-%{+YYYY.MM.dd}\" }}# Kibana配置示例server.host: \"localhost\"elasticsearch.hosts: [\"http://localhost:9200\"]注意,针对生产环境,还需要考虑安全性、认证、加密通信等因素。
6.2 部署过程中的关键步骤
一旦环境搭建和配置文件准备就绪,接下来是部署过程中的关键步骤,包括节点配置、集群初始化以及网络设置等。
6.2.1 节点配置与集群初始化
配置每个节点以加入集群。例如,在Elasticsearch的配置文件 elasticsearch.yml 中,需要指定该节点所属的集群名称,并设置 node.name :
# Elasticsearch节点配置示例cluster.name: \"my-elk-cluster\"node.name: \"node-2\"对于集群的初始化,通常从一个主节点开始,然后逐步添加数据节点和客户端节点。在Elasticsearch中,可以这样启动节点:
sudo systemctl start elasticsearch6.2.2 网络设置与安全加固
在网络设置方面,要确保各个组件之间能够通信,并遵循最小权限原则进行配置。例如,Elasticsearch节点间的通信端口可能需要开放。同时,为了安全,可以通过配置防火墙规则来限制访问:
# 示例命令,开放Elasticsearch端口sudo firewall-cmd --zone=public --add-port=9200/tcp --permanentsudo firewall-cmd --reload安全加固是部署过程中的重要环节,包括设置强密码、启用SSL/TLS加密、配置X-Pack进行安全审计和监控等。
6.3 部署后的监控与维护
部署完成后,监控和维护工作成为日常运营中的关键任务,以确保集群性能稳定和数据安全。
6.3.1 性能监控与故障排查
在性能监控方面,Kibana提供了X-Pack插件,其中的监控功能能够展示集群状态、索引性能等信息。通过Kibana的仪表板,管理员可以实时监控集群的健康状态:
graph TD A[收集指标] --> B[存储指标] B --> C[分析指标] C --> D[展示指标] D --> E[通过Kibana监控面板]遇到问题时,结合Elasticsearch的慢查询日志、Logstash的错误日志等,进行故障排查。
6.3.2 日志管理与系统升级策略
日志管理是ELK集群维护的重要组成部分。例如,定期审查Elasticsearch和Logstash的日志,确保一切运行正常。系统升级策略同样至关重要,需要制定详细计划,确保升级过程中数据的完整性和系统的稳定性。
# 示例命令,用于升级Elasticsearchsudo rpm --upgrade https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.x.x.rpm在升级前应创建数据快照,避免数据丢失。升级后,确保一切组件都能正常工作,并对集群性能进行评估。
通过上述部署流程及关键配置的详细讲解,可以保证ELK集群的顺利实施和稳定运行。ELK集群的有效部署不仅需要对组件有深刻理解,还需要对整个系统有全面的规划和细致的配置。从预配置到监控维护,每一环节都至关重要。希望本章内容对读者在实际部署ELK集群时有所帮助。
本文还有配套的精品资源,点击获取
简介:ELK堆栈结合了Elasticsearch、Logstash和Kibana,提供了一个强大的日志管理和分析平台。Elasticsearch,作为分布式搜索引擎,支持全文搜索和复杂的数据分析;Logstash作为数据处理管道,负责从各种源收集、过滤和传输日志数据;而Kibana则提供数据的可视化界面,便于理解和分析日志数据趋势。本方案旨在通过集群部署,实现高效、可扩展的日志解决方案,适用于IT管理员和开发人员监控、搜索和分析大量日志数据。在部署过程中,需要关注JDK1.8的兼容性和RPM包的使用,以确保ELK堆栈的正确安装和运行。
本文还有配套的精品资源,点击获取

