AI 应用 图文 解说 (二) -- 百度智能云 ASR LIM TTS 语音AI助手源码
文章的目的为了记录AI应用学习的经历,降低AI的入门难度。同时记录开发流程和要点有些记忆模糊,防止忘记。也希望可以给看到文章的朋友带来一些收获。
相关链接:
AI 应用 图文 解说 (一) -- 百度智能云 实现 语音 聊天-CSDN博客
AI 应用 图文 解说 (二) -- 百度智能云 ASR LIM TTS 语音AI助手程序 -CSDN博客
推荐链接:
开源 python 应用 开发(一)python、pip、pyAutogui、python opencv安装-CSDN博客
开源 python 应用 开发(二)基于pyautogui、open cv 视觉识别的工具自动化-CSDN博客
开源 python 应用 开发(三)python语法介绍-CSDN博客
开源 python 应用 开发(四)python文件和系统综合应用-CSDN博客
开源 python 应用 开发(五)python opencv之目标检测-CSDN博客
开源 python 应用 开发(六)网络爬虫-CSDN博客
开源 python 应用 开发(七)数据可视化-CSDN博客
开源 python 应用 开发(八)图片比对-CSDN博客
开源 python 应用 开发(九)目标跟踪-CSDN博客
开源 python 应用 开发(十)音频压缩-CSDN博客
开源 python 应用 开发(十一)AI应用--百度智能云ASR短语音转文本-CSDN博客
开源 python 应用 开发(十二)AI应用--百度智能云Agent聊天-CSDN博客
开源 python 应用 开发(十三)AI应用--百度智能云TTS语音合成-CSDN博客
开源 python 应用 开发(十四)python快速建设网站-CSDN博客
推荐链接:
开源 Arkts 鸿蒙应用 开发(一)工程文件分析-CSDN博客
开源 Arkts 鸿蒙应用 开发(二)封装库.har制作和应用-CSDN博客
开源 Arkts 鸿蒙应用 开发(三)Arkts的介绍-CSDN博客
开源 Arkts 鸿蒙应用 开发(四)布局和常用控件-CSDN博客
开源 Arkts 鸿蒙应用 开发(五)控件组成和复杂控件-CSDN博客
推荐链接:
开源 java android app 开发(一)开发环境的搭建-CSDN博客
开源 java android app 开发(二)工程文件结构-CSDN博客
开源 java android app 开发(三)GUI界面布局和常用组件-CSDN博客
开源 java android app 开发(四)GUI界面重要组件-CSDN博客
开源 java android app 开发(五)文件和数据库存储-CSDN博客
开源 java android app 开发(六)多媒体使用-CSDN博客
开源 java android app 开发(七)通讯之Tcp和Http-CSDN博客
开源 java android app 开发(八)通讯之Mqtt和Ble-CSDN博客
开源 java android app 开发(九)后台之线程和服务-CSDN博客
开源 java android app 开发(十)广播机制-CSDN博客
开源 java android app 开发(十一)调试、发布-CSDN博客
开源 java android app 开发(十二)封库.aar-CSDN博客
推荐链接:
开源C# .net mvc 开发(一)WEB搭建_c#部署web程序-CSDN博客
开源 C# .net mvc 开发(二)网站快速搭建_c#网站开发-CSDN博客
开源 C# .net mvc 开发(三)WEB内外网访问(VS发布、IIS配置网站、花生壳外网穿刺访问)_c# mvc 域名下不可訪問內網,內網下可以訪問域名-CSDN博客
开源 C# .net mvc 开发(四)工程结构、页面提交以及显示_c#工程结构-CSDN博客
开源 C# .net mvc 开发(五)常用代码快速开发_c# mvc开发-CSDN博客
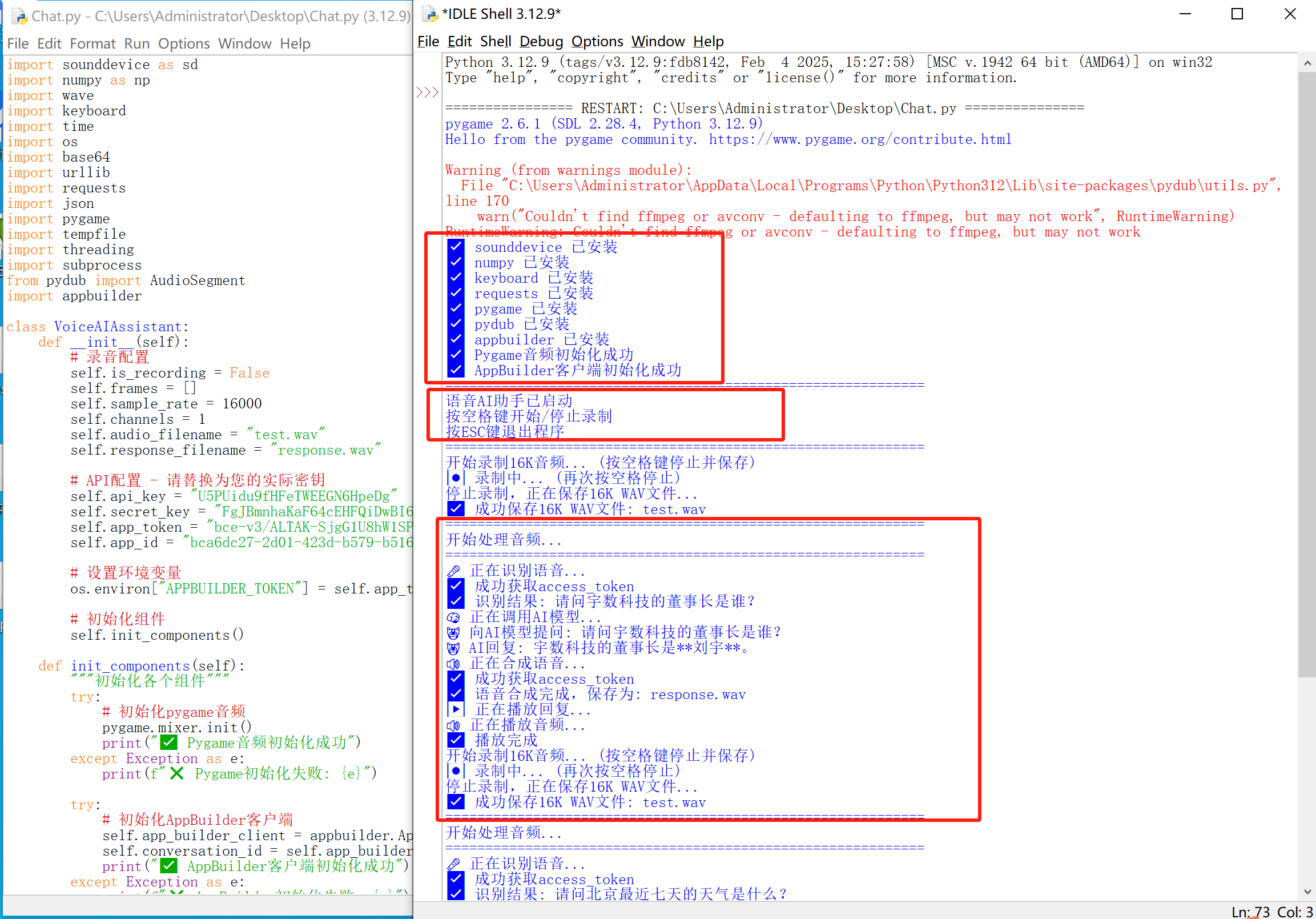
主要内容:一个完整的语音AI助手程序,使用Python实现录音、语音识别、AI对话和语音合成的功能。
目录:
1.主要功能
2.源码分析
3.所有源码
4.显示效果
一、主要功能
音频录制:使用sounddevice库录制16kHz单声道音频
语音识别:通过百度语音识别API将音频转换为文本
AI对话:使用AppBuilder AI模型进行智能对话
语音合成:通过百度语音合成API将文本转换为语音
音频播放:使用多种方式播放生成的语音回复
二、源码分析
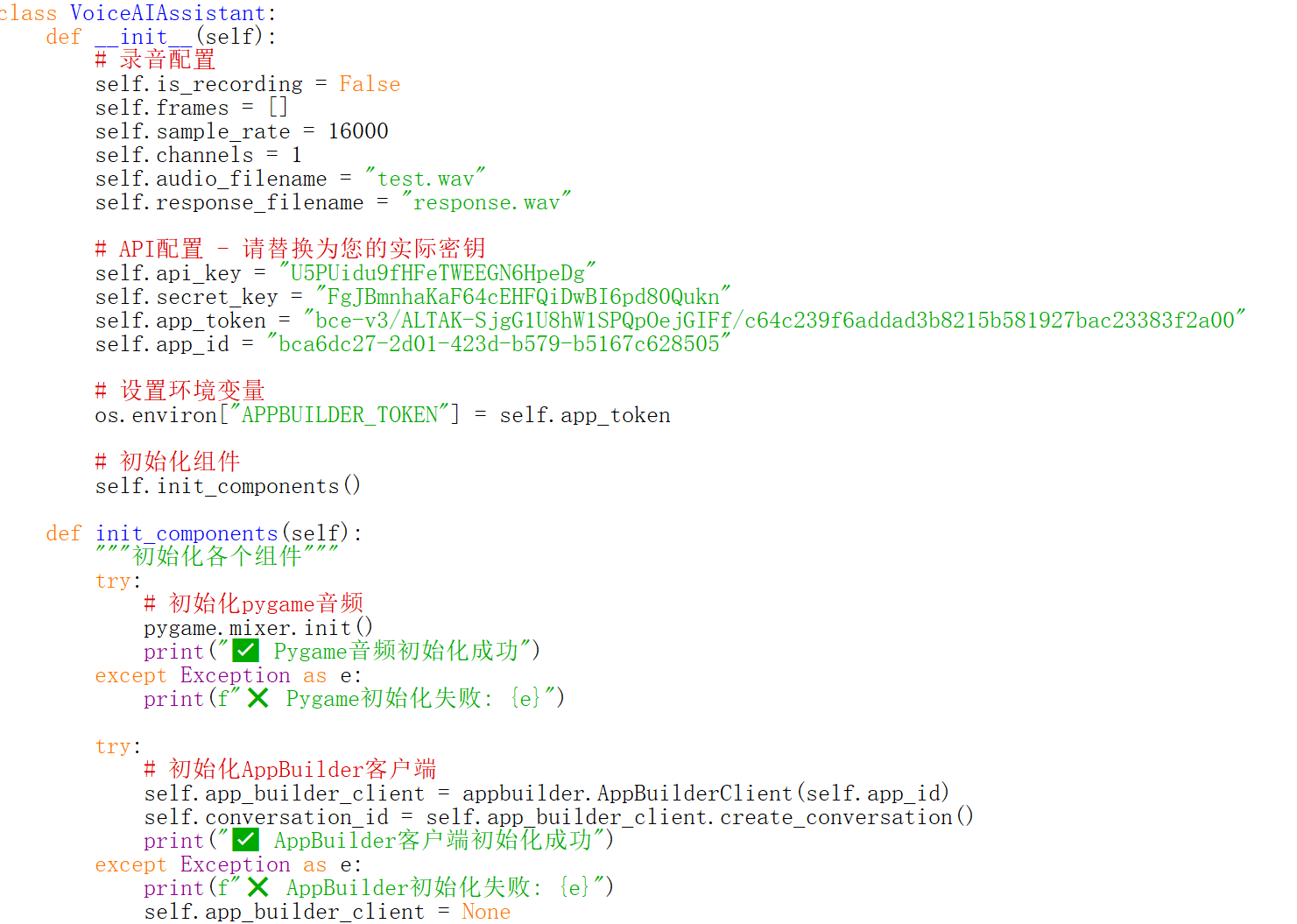
2.1 类定义和初始化 (VoiceAIAssistant)
初始化录音配置参数(采样率、声道数等)
设置API密钥和认证信息
初始化各个组件(pygame音频、AppBuilder客户端)
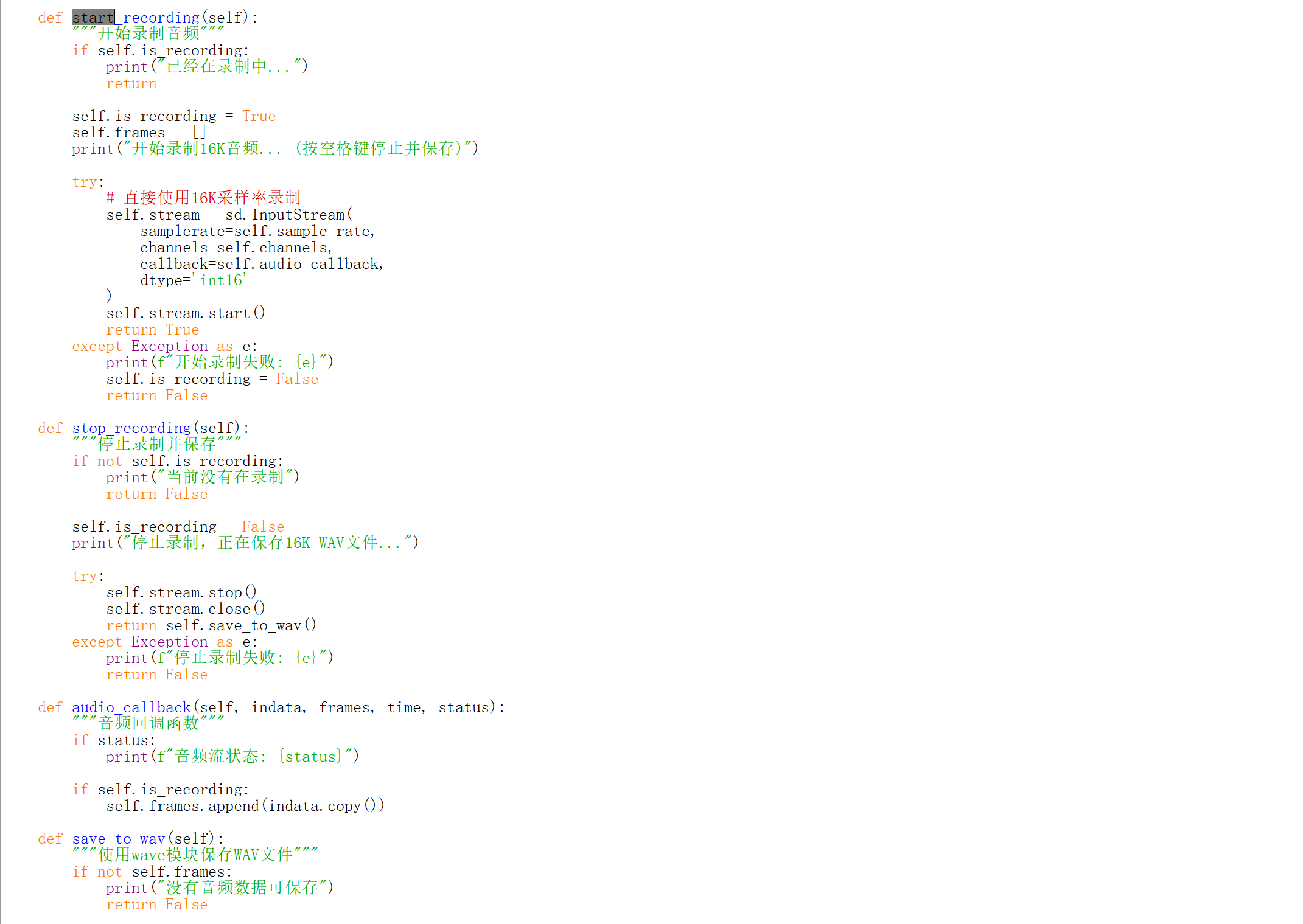
2.2 音频处理功能
start_recording(): 开始录制音频
stop_recording(): 停止录制并保存
audio_callback(): 音频流回调函数,收集音频数据
save_to_wav(): 使用wave模块保存WAV文件
2.3 API调用功能
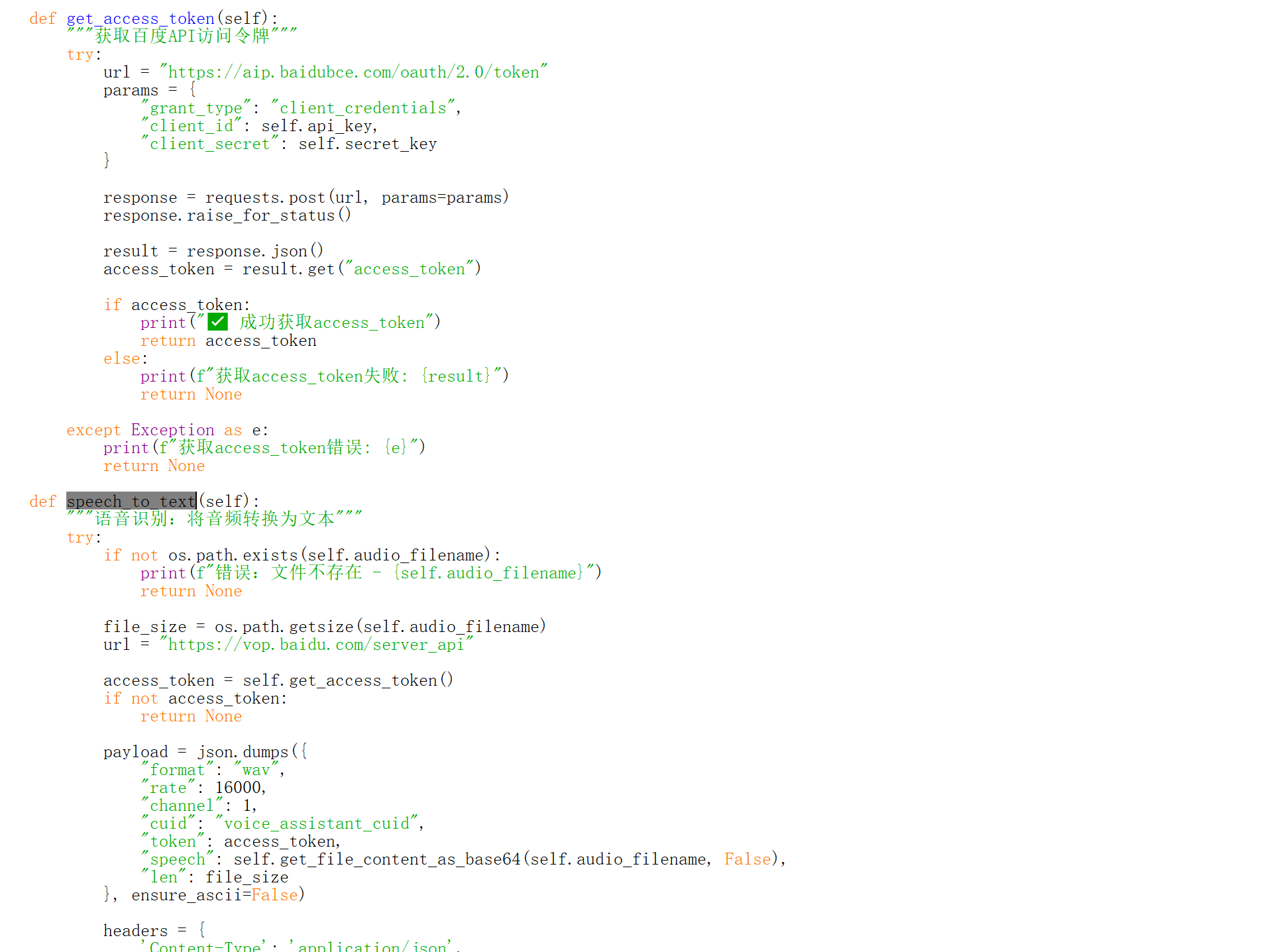
get_access_token(): 获取百度API访问令牌
speech_to_text(): 调用百度语音识别API
text_to_speech(): 调用百度语音合成API
call_ai_model(): 调用AppBuilder AI模型
2.4 辅助功能
play_audio(): 使用多种方式播放音频文件
process_audio(): 完整的音频处理流程
keyboard_listener(): 键盘监听主循环

5. 工具函数
check_dependencies(): 检查所需Python库是否已安装
main(): 程序主函数

三、所有源码
import sounddevice as sdimport numpy as npimport waveimport keyboardimport timeimport osimport base64import urllibimport requestsimport jsonimport pygameimport tempfileimport threadingimport subprocessfrom pydub import AudioSegmentimport appbuilderclass VoiceAIAssistant: def __init__(self): # 录音配置 self.is_recording = False self.frames = [] self.sample_rate = 16000 self.channels = 1 self.audio_filename = \"test.wav\" self.response_filename = \"response.wav\" # API配置 - 请替换为您的实际密钥 self.api_key = \"\" self.secret_key = \"\" self.app_token = \"\" self.app_id = \"\" # 设置环境变量 os.environ[\"APPBUILDER_TOKEN\"] = self.app_token # 初始化组件 self.init_components() def init_components(self): \"\"\"初始化各个组件\"\"\" try: # 初始化pygame音频 pygame.mixer.init() print(\"✅ Pygame音频初始化成功\") except Exception as e: print(f\"❌ Pygame初始化失败: {e}\") try: # 初始化AppBuilder客户端 self.app_builder_client = appbuilder.AppBuilderClient(self.app_id) self.conversation_id = self.app_builder_client.create_conversation() print(\"✅ AppBuilder客户端初始化成功\") except Exception as e: print(f\"❌ AppBuilder初始化失败: {e}\") self.app_builder_client = None def start_recording(self): \"\"\"开始录制音频\"\"\" if self.is_recording: print(\"已经在录制中...\") return self.is_recording = True self.frames = [] print(\"开始录制16K音频... (按空格键停止并保存)\") try: # 直接使用16K采样率录制 self.stream = sd.InputStream( samplerate=self.sample_rate, channels=self.channels, callback=self.audio_callback, dtype=\'int16\' ) self.stream.start() return True except Exception as e: print(f\"开始录制失败: {e}\") self.is_recording = False return False def stop_recording(self): \"\"\"停止录制并保存\"\"\" if not self.is_recording: print(\"当前没有在录制\") return False self.is_recording = False print(\"停止录制,正在保存16K WAV文件...\") try: self.stream.stop() self.stream.close() return self.save_to_wav() except Exception as e: print(f\"停止录制失败: {e}\") return False def audio_callback(self, indata, frames, time, status): \"\"\"音频回调函数\"\"\" if status: print(f\"音频流状态: {status}\") if self.is_recording: self.frames.append(indata.copy()) def save_to_wav(self): \"\"\"使用wave模块保存WAV文件\"\"\" if not self.frames: print(\"没有音频数据可保存\") return False try: # 合并所有音频帧 audio_data = np.concatenate(self.frames, axis=0) audio_data = audio_data.flatten() # 确保数据在16位范围内 audio_data = np.clip(audio_data, -32768, 32767) audio_data = audio_data.astype(np.int16) # 使用wave模块保存 with wave.open(self.audio_filename, \'wb\') as wav_file: wav_file.setnchannels(self.channels) wav_file.setsampwidth(2) # 16位 = 2字节 wav_file.setframerate(self.sample_rate) wav_file.writeframes(audio_data.tobytes()) print(f\"✅ 成功保存16K WAV文件: {self.audio_filename}\") return True except Exception as e: print(f\"保存文件时出错: {e}\") return False def get_file_content_as_base64(self, path, urlencoded=False): \"\"\"获取文件base64编码\"\"\" try: with open(path, \"rb\") as f: content = base64.b64encode(f.read()).decode(\"utf8\") if urlencoded: content = urllib.parse.quote_plus(content) return content except Exception as e: print(f\"读取文件错误: {e}\") return None def get_access_token(self): \"\"\"获取百度API访问令牌\"\"\" try: url = \"https://aip.baidubce.com/oauth/2.0/token\" params = { \"grant_type\": \"client_credentials\", \"client_id\": self.api_key, \"client_secret\": self.secret_key } response = requests.post(url, params=params) response.raise_for_status() result = response.json() access_token = result.get(\"access_token\") if access_token: print(\"✅ 成功获取access_token\") return access_token else: print(f\"获取access_token失败: {result}\") return None except Exception as e: print(f\"获取access_token错误: {e}\") return None def speech_to_text(self): \"\"\"语音识别:将音频转换为文本\"\"\" try: if not os.path.exists(self.audio_filename): print(f\"错误:文件不存在 - {self.audio_filename}\") return None file_size = os.path.getsize(self.audio_filename) url = \"https://vop.baidu.com/server_api\" access_token = self.get_access_token() if not access_token: return None payload = json.dumps({ \"format\": \"wav\", \"rate\": 16000, \"channel\": 1, \"cuid\": \"voice_assistant_cuid\", \"token\": access_token, \"speech\": self.get_file_content_as_base64(self.audio_filename, False), \"len\": file_size }, ensure_ascii=False) headers = { \'Content-Type\': \'application/json\', \'Accept\': \'application/json\' } response = requests.post(url, headers=headers, data=payload.encode(\"utf-8\")) if response.status_code == 200: result = response.json() if result.get(\"err_no\") == 0: text = result.get(\"result\", [\"\"])[0] print(f\"✅ 识别结果: {text}\") return text else: print(f\"语音识别失败: {result.get(\'err_msg\')}\") return None else: print(f\"请求失败,状态码: {response.status_code}\") return None except Exception as e: print(f\"语音识别错误: {e}\") return None def text_to_speech(self, text): \"\"\"文本转语音:将文本转换为音频\"\"\" try: url = \"https://tsn.baidu.com/text2audio\" access_token = self.get_access_token() if not access_token: return None encoded_text = urllib.parse.quote(text) params = { \'tex\': encoded_text, \'tok\': access_token, \'cuid\': \'voice_assistant_cuid\', \'ctp\': 1, \'lan\': \'zh\', \'spd\': 5, \'pit\': 5, \'vol\': 5, \'per\': 0, \'aue\': 6 # WAV格式 } headers = { \'Content-Type\': \'application/x-www-form-urlencoded\', \'Accept\': \'audio/wav\' } response = requests.post(url, data=params, headers=headers) if response.status_code == 200: # 保存音频文件 with open(self.response_filename, \'wb\') as f: f.write(response.content) print(f\"✅ 语音合成完成,保存为: {self.response_filename}\") return self.response_filename else: print(f\"语音合成失败,状态码: {response.status_code}\") return None except Exception as e: print(f\"语音合成错误: {e}\") return None def call_ai_model(self, text): \"\"\"调用AI大模型处理文本\"\"\" if not self.app_builder_client: print(\"❌ AppBuilder客户端未初始化\") return \"抱歉,AI服务暂时不可用。\" try: print(f\"🤖 向AI模型提问: {text}\") resp = self.app_builder_client.run(self.conversation_id, text) answer = resp.content.answer print(f\"🤖 AI回复: {answer}\") return answer except Exception as e: print(f\"调用AI模型错误: {e}\") return \"抱歉,我暂时无法处理您的请求。\" def play_audio(self, audio_file): \"\"\"播放音频文件\"\"\" if not os.path.exists(audio_file): print(f\"错误:音频文件不存在 - {audio_file}\") return False try: # 方法1: 使用winsound播放(最简单) import winsound print(\"🔊 正在播放音频...\") winsound.PlaySound(audio_file, winsound.SND_FILENAME) print(\"✅ 播放完成\") return True except Exception as e: print(f\"winsound播放失败: {e}\") try: # 方法2: 使用pygame播放 pygame.mixer.music.load(audio_file) pygame.mixer.music.play() print(\"🔊 正在播放音频...\") # 等待播放完成 while pygame.mixer.music.get_busy(): pygame.time.wait(100) print(\"✅ 播放完成\") return True except Exception as e: print(f\"pygame播放失败: {e}\") try: # 方法3: 使用系统命令播放 if os.name == \'nt\': # Windows os.startfile(audio_file) else: # Linux/Mac subprocess.run([\'aplay\', audio_file]) print(\"✅ 使用系统播放器播放\") return True except Exception as e: print(f\"系统播放失败: {e}\") return False def process_audio(self): \"\"\"完整处理流程:录音->识别->AI->语音合成->播放\"\"\" print(\"=\" * 60) print(\"开始处理音频...\") print(\"=\" * 60) # 1. 语音识别 print(\"🎤 正在识别语音...\") recognized_text = self.speech_to_text() if not recognized_text: print(\"❌ 语音识别失败\") return False # 2. 调用AI模型 print(\"🧠 正在调用AI模型...\") ai_response = self.call_ai_model(recognized_text) # 3. 语音合成 print(\"🔊 正在合成语音...\") audio_file = self.text_to_speech(ai_response) if not audio_file: print(\"❌ 语音合成失败\") return False # 4. 播放音频 print(\"▶️ 正在播放回复...\") return self.play_audio(audio_file) def keyboard_listener(self): \"\"\"键盘监听主循环\"\"\" print(\"=\" * 60) print(\"语音AI助手已启动\") print(\"按空格键开始/停止录制\") print(\"按ESC键退出程序\") print(\"=\" * 60) recording_started = False while True: # 检测空格键 if keyboard.is_pressed(\'space\'): if not recording_started: if not self.is_recording: # 开始录制 if self.start_recording(): print(\"⏺️ 录制中... (再次按空格停止)\") else: # 停止录制并处理 if self.stop_recording(): # 在新线程中处理音频,避免阻塞键盘监听 processing_thread = threading.Thread(target=self.process_audio) processing_thread.daemon = True processing_thread.start() recording_started = True time.sleep(0.5) # 防抖 else: recording_started = False # 检测ESC键退出 if keyboard.is_pressed(\'esc\'): if self.is_recording: self.stop_recording() print(\"👋 程序退出\") break time.sleep(0.1)def check_dependencies(): \"\"\"检查所需依赖\"\"\" required_libs = [ \'sounddevice\', \'numpy\', \'keyboard\', \'requests\', \'pygame\', \'pydub\', \'appbuilder\' ] missing_libs = [] for lib in required_libs: try: if lib == \'appbuilder\': import appbuilder elif lib == \'pydub\': from pydub import AudioSegment else: __import__(lib) print(f\"✅ {lib} 已安装\") except ImportError: print(f\"❌ {lib} 未安装\") missing_libs.append(lib) if missing_libs: print(f\"\\n请安装缺失的库: pip install {\' \'.join(missing_libs)}\") return False return Truedef main(): \"\"\"主函数\"\"\" # 检查依赖 if not check_dependencies(): return # 创建语音助手实例 try: assistant = VoiceAIAssistant() # 启动键盘监听 assistant.keyboard_listener() except KeyboardInterrupt: print(\"\\n👋 程序被用户中断\") except Exception as e: print(f\"❌ 程序运行错误: {e}\")if __name__ == \"__main__\": main()四、使用效果
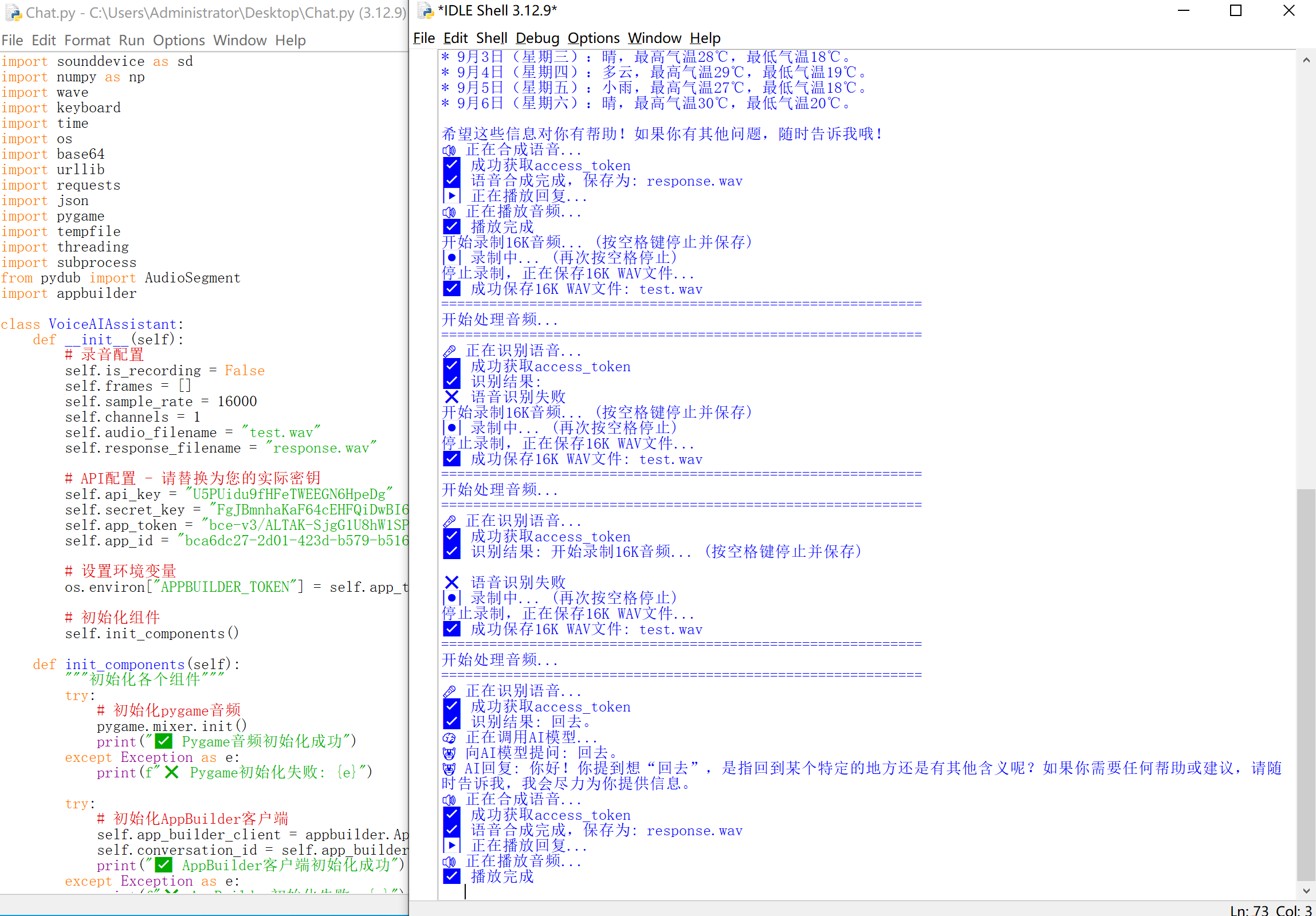
使用python IDE 运行或双击.py文件,代码会检查所需要的库,如果没有安装,使用pip安装就行。
如果报错 Appbuilder问题,可以进行升级。
pip install --upgrade appbuilder-sdk -i https://mirrors.aliyun.com/pypi/simple/程序不再报错后,按下空格开始录音,会音频提交到智能云,与AI对话,最后返回合成的语音。音频文件为.wav存放在桌面。