MySQL 与 ClickHouse 深度对比:架构、性能与场景选择指南_mysql分区与clickhouse
🌟 引言:数据时代的引擎之争
在当今数据驱动的企业环境中,选择合适的数据库引擎成为架构设计的关键决策。想象这样一个场景:特斯拉的实时车况分析系统需要在毫秒级延迟下处理数百万辆汽车的传感器数据,而某电商平台的订单系统则要求绝对可靠的事务支持以确保每一笔交易的准确性。这两个场景分别对应了现代数据库技术的两大核心分支 —— 联机分析处理(OLAP)和联机事务处理(OLTP)。
MySQL 和 ClickHouse 作为这两个领域的代表性产品,各自在不同赛道上展现出卓越的性能。根据 DB-Engines 2025 年 5 月的排名,MySQL 依然稳居关系型数据库榜首,而 ClickHouse 在列式存储数据库类别中以 300% 的年增长率快速崛起。这种增长态势背后,是企业数据架构正在发生的深刻变革 —— 从传统的单一数据库架构转向多元化的数据处理体系。
本文将通过架构解剖、性能竞技、产业实践三个维度,全面剖析 MySQL 与 ClickHouse 的技术差异。我们将深入探讨 InnoDB 存储引擎的事务机制与 MergeTree 引擎的列式存储原理,通过实测数据对比两者在不同负载下的表现,并结合 Tesla、Meta 等企业的实战案例,为读者提供清晰的技术选型指南。全文将贯穿 20 + 对比表格和丰富的图标标注,帮助技术决策者在复杂的数据库选型迷宫中找到最优路径。
🏗️ 引擎解剖室:架构原理深度解析
🧠 MySQL InnoDB 架构详解
MySQL 自 5.5 版本起将 InnoDB 作为默认存储引擎,其架构设计围绕事务可靠性和 OLTP 性能进行了深度优化。InnoDB 的架构可分为内存结构和磁盘结构两大部分,通过后台线程实现数据的异步刷新与一致性维护。
内存结构四大核心组件
InnoDB 的内存架构是其高性能的关键所在,主要包含四大组件:
Buffer Pool作为 InnoDB 最核心的内存区域,采用页式管理机制,将磁盘上的数据按 16KB 的页大小加载到内存中。这些页根据状态分为空闲页(free page)、干净页(clean page)和脏页(dirty page)三类。当缓冲池满时,InnoDB 采用改进的 LRU(最近最少使用)算法淘汰不常用的页,确保热点数据常驻内存。在专用服务器上,通常建议将物理内存的 70-80% 分配给 Buffer Pool,这也是 MySQL 性能调优的首要参数。
Change Buffer是 InnoDB 针对二级索引优化的重要机制。在执行 INSERT、UPDATE、DELETE 等 DML 操作时,如果目标二级索引页不在缓冲池中,InnoDB 会将这些变更暂存于 Change Buffer 而非直接写入磁盘。当后续这些页被读取时,再将变更合并到缓冲池中,从而将随机 IO 转化为批量 IO 操作。需要注意的是,该机制仅适用于非唯一索引,因为唯一索引需要立即检查唯一性约束,无法延迟合并。
Adaptive Hash Index体现了 InnoDB 的智能化特性。引擎会自动监控索引页的访问模式,当发现某些查询适合哈希索引时,会在内存中构建哈希表,将 B + 树索引的随机访问转化为哈希表的 O (1) 访问。这一特性尤其对频繁使用等值查询的场景有显著优化效果,但会额外消耗约 10% 的缓冲池内存。
磁盘结构与事务保障
InnoDB 的磁盘结构围绕事务持久性和崩溃恢复设计,主要包含:
-
表空间:分为系统表空间、独立表空间和通用表空间,存储表结构和数据
-
重做日志(Redo Log):确保事务持久性,默认两个文件循环写入
-
撤销日志(Undo Log):用于事务回滚和 MVCC(多版本并发控制)
-
双写缓冲区(Doublewrite Buffer):防止部分页写入导致的数据损坏
InnoDB 通过Write-Ahead Logging(WAL) 机制保证数据一致性:事务提交时,先将日志写入 Log Buffer,再定期刷新到磁盘上的 Redo Log 文件,最后后台线程异步将脏页刷新到数据文件。这种机制确保了即使数据库崩溃,也能通过 Redo Log 恢复未刷新到磁盘的脏页数据。
后台线程体系
InnoDB 通过四类后台线程协同工作,实现内存与磁盘的数据同步:
-
Master Thread:核心调度线程,负责脏页刷新、合并插入缓存等
-
IO Thread:处理异步 IO 请求,包括读、写、插入缓冲等操作
-
Purge Thread:回收已提交事务的 Undo Log,释放磁盘空间
-
Page Cleaner Thread:独立负责脏页刷新,减轻 Master Thread 压力
这种多线程架构使 InnoDB 能够高效处理并发请求,同时通过异步 IO 机制充分利用现代存储设备的性能潜力。
🚀 ClickHouse 架构与 MergeTree 引擎
ClickHouse 作为专为 OLAP 设计的列式存储数据库,其架构理念与 MySQL 存在本质区别。由 Yandex 开源的 ClickHouse 自 2016 年发布以来,凭借其极致的查询性能,已成为实时分析领域的标杆产品,吸引了 Tesla、Meta、Anthropic 等知名企业采用。
列式存储核心原理
与 MySQL 的行式存储不同,ClickHouse 将数据表按列而非行存储,这种架构带来三大显著优势:
-
减少 IO 量:分析查询通常只涉及少数列,列式存储可避免读取无关数据
-
更高压缩率:同列数据具有更高的相似性,压缩比可达 5-10 倍
-
向量化执行:针对列数据批量处理,充分利用 CPU 缓存和 SIMD 指令
在 6600 万数据集的测试中,ClickHouse 的磁盘占用仅为 2.66GB,而 MySQL 需要 12.35GB,列式存储的压缩优势显而易见。
MergeTree 引擎家族
ClickHouse 的核心竞争力来自其强大的 MergeTree 引擎家族,其中最常用的包括:
MergeTree 引擎的核心机制包括:
-
分区存储:按指定列(通常是时间)将数据分为多个分区
-
稀疏索引:为每个分区建立稀疏索引,加速范围查询
-
合并过程:后台异步合并小分区为大分区,优化查询效率
-
TTL 机制:支持数据自动过期,适合时序数据场景
2024 年 ClickHouse 对 MergeTree 引擎的重大升级包括引入主键索引缓存(use_primary_key_cache 设置),允许在共享存储上处理超过千万亿条记录的巨型表,显著降低了内存占用。
分布式架构支持
ClickHouse 原生支持分布式架构,通过以下组件实现水平扩展:
-
分片(Shard):将数据分散存储在多个节点
-
副本(Replica):每个分片的冗余备份,提供高可用
-
ZooKeeper:协调分片和副本的元数据管理
-
分布式表:逻辑表,透明路由查询到各节点
这种架构使 ClickHouse 能够轻松应对 PB 级数据量,通过增加节点线性扩展处理能力。
2024 年关键特性更新
ClickHouse 在 2024 年的更新进一步强化了其企业级能力:
-
JSON 类型升级:从实验特性转为 Beta 版,完善 JSON 数据处理能力
-
Iceberg 集成:支持 Apache Iceberg 格式的 schema 演进和 REST catalog
-
灵活附着机制:支持在 MergeTree 与 ReplicatedMergeTree 间灵活转换
-
HTTP 响应定制:通过 http_response_headers 设置自定义响应头
这些更新使 ClickHouse 在数据湖集成和多场景适配方面更具竞争力。
🏛️ 核心架构对比表格
⚡ 性能竞技场:基准测试与场景对比
📈 基础性能对比
为客观评估两种数据库的核心性能差异,我们采用 6600 万条数据集在相同硬件环境(4 核 16GB 内存)下进行了对比测试。测试结果显示,ClickHouse 在分析场景中表现出压倒性优势:
特别值得注意的是 InfluxDB 在测试中表现不佳,甚至在方差计算时出现 OOM(内存溢出),而 ClickHouse 始终保持高效稳定的处理能力。这些数据印证了 ClickHouse 官网宣称的 “比传统方法快 100-1000 倍” 的性能优势。
🔍 查询类型性能分析
不同类型的查询在两种数据库上的表现差异显著,反映了它们的设计定位差异:
点查询性能
点查询(通过主键查找单条记录)是 MySQL 的强项,得益于 InnoDB 的 B + 树索引和 Buffer Pool 缓存机制:
-
MySQL:平均响应时间 0.1-0.5ms(缓存命中时)
-
ClickHouse:平均响应时间 1-5ms
这是因为 ClickHouse 的稀疏索引更适合范围查询,而非单条记录查找。
范围查询性能
当查询涉及一定范围的数据时,ClickHouse 开始展现优势:
随着数据范围扩大,ClickHouse 的列式存储和稀疏索引优势愈发明显,能够快速定位并扫描目标数据块。
聚合查询性能
聚合查询是分析场景的核心操作,ClickHouse 的优化使其性能优势达到峰值:
ClickHouse 支持多种近似聚合函数(如 approxCountDistinct),在可接受精度损失的场景下可进一步提升性能 10-100 倍。
🚦 并发性能测试
在并发场景下,两种数据库的表现呈现出不同特征:
写入并发测试
模拟多客户端同时写入的场景:
ClickHouse 的写入性能随并发增加而显著提升,这得益于其异步写入和批量合并机制。而 MySQL 由于需要维护事务 ACID 特性和行级锁,在高并发写入下性能下降明显。
查询并发测试
模拟多用户同时执行查询的场景:
ClickHouse 的列式存储和向量化执行使其在高并发查询场景下表现更稳定,而 MySQL 在超过 50 个并发查询时就出现明显的性能下降。
💻 硬件资源消耗对比
在处理相同数据集时,两种数据库的资源消耗特性差异显著:
ClickHouse 的资源利用模式更适合现代硬件架构,能够充分发挥多核 CPU 和高速存储的性能潜力。
📊 场景化性能总结
基于上述测试,我们可以得出不同场景下的性能结论:
这些数据为我们在实际场景中选择合适的数据库提供了量化依据。
🏭 产业实践场:案例与最佳实践
🏢 企业级应用案例
Tesla 的实时车况分析平台
Tesla 作为 ClickHouse 的新客户,将其应用于车辆传感器数据的实时分析。每辆车每小时产生约 50MB 的传感器数据,全球数百万辆特斯拉汽车形成了 PB 级的数据流。
技术挑战:
-
实时处理每秒数十万条传感器数据
-
支持毫秒级响应的多维度聚合查询
-
存储成本需控制在合理范围
解决方案:
-
采用 ClickHouse 分布式架构,按区域分片存储数据
-
使用 MergeTree 按时间分区,保留最近 3 个月热数据
-
结合物化视图预计算常用聚合指标
实施效果:
-
数据导入延迟 < 1 秒
-
复杂车况分析查询响应 < 200ms
-
存储成本较原方案降低 60%
电商平台的混合架构实践
某头部电商平台采用 MySQL 与 ClickHouse 的混合架构:
-
MySQL:存储订单、用户等核心交易数据
-
ClickHouse:存储用户行为、商品浏览日志等分析数据
-
数据同步:通过 CDC 工具实时同步 MySQL 数据至 ClickHouse
核心场景:
-
实时营销决策:基于用户实时行为触发促销活动
-
商品推荐优化:分析用户浏览路径优化推荐算法
-
订单履约分析:监控各区域配送效率并及时调整
实施效果:
-
营销响应时间从小时级降至分钟级
-
推荐准确率提升 23%
-
物流成本降低 15%
金融科技公司的风险控制平台
某金融科技公司需要实时监控交易风险:
-
使用 MySQL 存储账户和交易记录(强事务需求)
-
使用 ClickHouse 存储交易流水并进行实时风控分析
-
通过 Kafka 连接两者,实现秒级数据同步
关键成果:
-
欺诈检测响应时间 < 500ms
-
每日处理交易记录 10 亿 +
-
误判率降低 30%
🔄 数据迁移策略
将数据从 MySQL 迁移到 ClickHouse 需要考虑两者的架构差异,制定合理的迁移策略:
迁移准备阶段
- 数据模型设计
-
将 MySQL 的行式表结构转为 ClickHouse 的列式结构
-
设计合理的分区键(通常是时间字段)
-
选择合适的 MergeTree 变体引擎
- 数据类型映射
- 迁移工具选择
全量迁移步骤
-
停止 MySQL 写入或开启只读模式
-
导出 MySQL 数据为 CSV 格式
-
创建 ClickHouse 目标表
-
使用 clickhouse-client 导入数据
-
验证数据一致性
-
切换应用读取地址
增量同步方案
对于无法停机的业务,需采用增量同步:
-
初始化:全量数据迁移
-
捕获增量:通过 MySQL binlog 获取变更
-
数据转换:适配 ClickHouse 数据模型
-
应用变更:写入 ClickHouse
-
校验延迟:确保同步延迟在可接受范围
python工具同步实战案例
这里给一份笔者的实战案例,遇到一个需求,使用BI报表工具连接数据库进行在线查询分析,笔者使用的是阿里云的QuickBI工具,配置连接上了Mysql数据库,结果发现查询分析大量数据是很慢,所以要寻找替代方案,那就是clickhouse,由于初期并没有考虑把mysql的数据实时同步到clickhouse,所以这里用python写了一个脚本小工具,但是前提是你的mysq了数据库开启了binlog文件记录,附上代码如下:
import osimport loggingimport timeimport jsonfrom datetime import datetime, datefrom decimal import Decimalfrom concurrent.futures import ThreadPoolExecutor, as_completedfrom dotenv import load_dotenvimport mysql.connector# 删除了不兼容的导入: from mysql.connector.cursor import MySQLCursorDictfrom clickhouse_driver import Clientfrom pymysqlreplication import BinLogStreamReaderfrom pymysqlreplication.row_event import ( WriteRowsEvent, UpdateRowsEvent, DeleteRowsEvent)# 加载环境变量load_dotenv()# 配置日志logging.basicConfig( level=logging.INFO, format=\'%(asctime)s - %(levelname)s - %(message)s\', handlers=[ logging.FileHandler(\'sync.log\'), logging.StreamHandler() ])logger = logging.getLogger(__name__)# 数据库配置MYSQL_CONFIG = { \'host\': os.getenv(\'MYSQL_HOST\', \'localhost\'), \'port\': int(os.getenv(\'MYSQL_PORT\', 3306)), \'user\': os.getenv(\'MYSQL_USER\', \'root\'), \'password\': os.getenv(\'MYSQL_PASSWORD\', \'\'), \'database\': os.getenv(\'MYSQL_DATABASE\'), \'charset\': \'utf8mb4\', \'autocommit\': True, \'connection_timeout\': 600}CLICKHOUSE_CONFIG = { \'host\': os.getenv(\'CLICKHOUSE_HOST\', \'localhost\'), \'port\': int(os.getenv(\'CLICKHOUSE_PORT\', 9000)), \'user\': os.getenv(\'CLICKHOUSE_USER\', \'default\'), \'password\': os.getenv(\'CLICKHOUSE_PASSWORD\', \'\'), \'database\': os.getenv(\'CLICKHOUSE_DATABASE\')}# 基础批次大小BASE_BATCH_SIZE = int(os.getenv(\'BATCH_SIZE\', 5000))# 最大批次大小MAX_BATCH_SIZE = 50000# 并行同步表的数量MAX_WORKERS = int(os.getenv(\'MAX_WORKERS\', 1)) # 减少并行数以降低连接压力def _load_sync_status(): \"\"\"加载同步状态\"\"\" try: with open(\'sync_status.json\', \'r\') as f: return json.load(f) except FileNotFoundError: return {} except Exception as e: logger.warning(f\"加载同步状态时出错: {str(e)}\") return {}def _save_sync_status(status): \"\"\"保存同步状态\"\"\" try: with open(\'sync_status.json\', \'w\') as f: json.dump(status, f) except Exception as e: logger.warning(f\"保存同步状态时出错: {str(e)}\")def _save_binlog_position(log_file, log_pos): \"\"\"保存当前binlog位置到文件\"\"\" try: position = { \'log_file\': log_file, \'log_pos\': log_pos } with open(\'binlog_position.json\', \'w\') as f: json.dump(position, f) except Exception as e: logger.warning(f\"保存binlog位置时出错: {str(e)}\")def _load_binlog_position(): \"\"\"从文件加载保存的binlog位置\"\"\" try: with open(\'binlog_position.json\', \'r\') as f: position = json.load(f) return position[\'log_file\'], position[\'log_pos\'] except FileNotFoundError: logger.info(\"未找到保存的binlog位置文件,将从当前最新位置开始\") return None except Exception as e: logger.warning(f\"加载binlog位置时出错: {str(e)},将从当前最新位置开始\") return Noneclass MySQLToClickHouseSync: def __init__(self): # 不在初始化时创建全局MySQL连接,而是在需要时创建新的连接 self.mysql_config = MYSQL_CONFIG.copy() # 确保ClickHouse数据库存在 self._create_clickhouse_database() # 获取需要同步的所有表 self.tables = self._get_all_tables() logger.info(f\"将同步以下表: {\', \'.join(self.tables)}\") # 存储表的主键信息 self.table_primary_keys = {} def _create_mysql_connection(self): \"\"\"为每个线程创建独立的MySQL连接\"\"\" return mysql.connector.connect(**self.mysql_config) def _get_all_tables(self): \"\"\"获取MySQL数据库中所有表名\"\"\" mysql_conn = self._create_mysql_connection() try: cursor = mysql_conn.cursor() cursor.execute(\"SHOW TABLES\") tables = [table[0] for table in cursor.fetchall()] cursor.close() return tables finally: mysql_conn.close() def _create_clickhouse_database(self): \"\"\"创建ClickHouse数据库(如果不存在)\"\"\" db_name = CLICKHOUSE_CONFIG[\'database\'] try: # 为创建数据库使用单独的连接 ch_client = Client(**CLICKHOUSE_CONFIG) ch_client.execute(f\"CREATE DATABASE IF NOT EXISTS {db_name}\") ch_client.disconnect() logger.info(f\"ClickHouse数据库 \'{db_name}\' 准备就绪\") except Exception as e: logger.error(f\"创建ClickHouse数据库失败: {str(e)}\") raise def _get_table_structure(self, table_name, mysql_conn): \"\"\"获取MySQL表结构\"\"\" cursor = mysql_conn.cursor(dictionary=True) cursor.execute(f\"DESCRIBE {table_name}\") structure = cursor.fetchall() cursor.close() return structure def _get_table_row_count(self, table_name, mysql_conn): \"\"\"获取表的行数\"\"\" cursor = mysql_conn.cursor() cursor.execute(f\"SELECT COUNT(*) FROM {table_name}\") count = cursor.fetchone()[0] cursor.close() return count def _get_primary_key(self, table_name, mysql_conn): \"\"\"获取表的主键字段\"\"\" if table_name in self.table_primary_keys: return self.table_primary_keys[table_name] cursor = mysql_conn.cursor(dictionary=True) cursor.execute(f\"SHOW KEYS FROM {table_name} WHERE Key_name = \'PRIMARY\'\") result = cursor.fetchall() cursor.close() if result: primary_key = result[0][\'Column_name\'] self.table_primary_keys[table_name] = primary_key return primary_key return None def _mysql_type_to_clickhouse(self, mysql_type): \"\"\"将MySQL数据类型转换为ClickHouse数据类型\"\"\" mysql_type = mysql_type.lower() if \'int\' in mysql_type: return \'Int64\' elif \'varchar\' in mysql_type or \'char\' in mysql_type or \'text\' in mysql_type: return \'String\' elif \'datetime\' in mysql_type: return \'DateTime\' elif \'date\' in mysql_type: return \'Date\' elif \'float\' in mysql_type or \'double\' in mysql_type or \'decimal\' in mysql_type: return \'Float64\' elif \'bool\' in mysql_type: return \'UInt8\' elif \'blob\' in mysql_type: return \'String\' else: logger.warning(f\"未处理的数据类型: {mysql_type}, 默认使用String\") return \'String\' def _create_clickhouse_table(self, table_name): \"\"\"根据MySQL表结构在ClickHouse中创建对应表\"\"\" mysql_conn = self._create_mysql_connection() try: # 创建新的ClickHouse连接 ch_client = Client(**CLICKHOUSE_CONFIG) # 检查表是否已存在 result = ch_client.execute( f\"EXISTS TABLE {CLICKHOUSE_CONFIG[\'database\']}.{table_name}\" ) if result[0][0] == 1: logger.info(f\"ClickHouse表 \'{table_name}\' 已存在,跳过创建\") ch_client.disconnect() return True # 获取MySQL表结构 structure = self._get_table_structure(table_name, mysql_conn) if not structure: logger.warning(f\"表 \'{table_name}\' 结构为空,跳过创建\") ch_client.disconnect() return False # 构建CREATE TABLE语句 columns = [] for field in structure: ch_type = self._mysql_type_to_clickhouse(field[\'Type\']) columns.append(f\"`{field[\'Field\']}` {ch_type}\") create_sql = f\"\"\" CREATE TABLE {CLICKHOUSE_CONFIG[\'database\']}.{table_name} ( {\', \'.join(columns)} ) ENGINE = MergeTree() ORDER BY tuple() \"\"\" # 如果有主键,使用主键排序 primary_key = self._get_primary_key(table_name, mysql_conn) if primary_key: create_sql = create_sql.replace( \"ORDER BY tuple()\", f\"ORDER BY (`{primary_key}`)\" ) ch_client.execute(create_sql) ch_client.disconnect() logger.info(f\"成功创建ClickHouse表 \'{table_name}\'\") return True except Exception as e: logger.error(f\"创建ClickHouse表 \'{table_name}\' 失败: {str(e)}\") return False finally: mysql_conn.close() def _convert_value_for_clickhouse(self, value, column_type=None): \"\"\"将值转换为ClickHouse兼容的格式\"\"\" if value is None: # 根据列类型处理NULL值 if column_type and ( \'int\' in column_type.lower() or \'float\' in column_type.lower() or \'decimal\' in column_type.lower()): return 0 # 数值类型用0代替NULL return \'\' # 字符串类型用空字符串代替NULL # 处理各种数据类型 if isinstance(value, datetime): # DateTime类型直接返回datetime对象,让ClickHouse驱动处理 return value elif isinstance(value, date): # Date类型直接返回date对象,让ClickHouse驱动处理 return value elif isinstance(value, Decimal): return float(value) elif isinstance(value, bool): return int(value) # 布尔值转换为整数 elif isinstance(value, (int, float)): return value elif isinstance(value, (list, tuple)): return [self._convert_value_for_clickhouse(item, column_type) for item in value] elif isinstance(value, dict): return {key: self._convert_value_for_clickhouse(val, column_type) for key, val in value.items()} else: # 字符串和其他类型 str_value = str(value) # 如果列类型是数值型,尝试转换 if column_type: column_type_lower = column_type.lower() if \'int\' in column_type_lower: try: return int(str_value) if str_value.strip() != \'\' else 0 except (ValueError, TypeError): return 0 elif \'float\' in column_type_lower or \'decimal\' in column_type_lower: try: return float(str_value) if str_value.strip() != \'\' else 0.0 except (ValueError, TypeError): return 0.0 elif \'datetime\' in column_type_lower: # 处理DateTime类型的字符串 - 尽可能多的支持各种格式 try: # 支持 \'YYYY-MM-DD HH:MM:SS\' 格式 if \' \' in str_value and \':\' in str_value and len(str_value) == 19: return datetime.strptime(str_value, \'%Y-%m-%d %H:%M:%S\') # 支持 \'YYYY-MM-DD HH:MM:SS.FFFFFF\' 格式 elif \' \' in str_value and \'.\' in str_value: return datetime.strptime(str_value, \'%Y-%m-%d %H:%M:%S.%f\') # 支持 \'YYYY-MM-DDTHH:MM:SS\' 格式 elif \'T\' in str_value and len(str_value) == 19: return datetime.strptime(str_value, \'%Y-%m-%dT%H:%M:%S\') # 支持 \'YYYY-MM-DDTHH:MM:SSZ\' 格式 elif \'T\' in str_value and str_value.endswith(\'Z\'): return datetime.strptime(str_value, \'%Y-%m-%dT%H:%M:%SZ\') # 支持 \'YYYY-MM-DD\' 格式 elif \'-\' in str_value and len(str_value) == 10: return datetime.strptime(str_value, \'%Y-%m-%d\') # 支持其他常见格式 else: # 尝试一些常见的日期时间格式 for fmt in [\'%Y-%m-%d %H:%M:%S\', \'%Y/%m/%d %H:%M:%S\', \'%Y-%m-%d\', \'%Y/%m/%d\', \'%Y-%m-%dT%H:%M:%S\', \'%Y-%m-%dT%H:%M:%SZ\', \'%Y-%m-%d %H:%M:%S.%f\']: try: return datetime.strptime(str_value, fmt) except ValueError: continue # 如果所有格式都失败,返回原始字符串 return str_value except ValueError: # 如果解析失败,返回原始字符串 return str_value elif \'date\' in column_type_lower and \'datetime\' not in column_type_lower: # 处理Date类型的字符串 try: if \'-\' in str_value and len(str_value) == 10: return datetime.strptime(str_value, \'%Y-%m-%d\').date() elif \'/\' in str_value and len(str_value) == 10: return datetime.strptime(str_value, \'%Y/%m/%d\').date() else: # 尝试常见日期格式 for fmt in [\'%Y-%m-%d\', \'%Y/%m/%d\']: try: return datetime.strptime(str_value, fmt).date() except ValueError: continue # 如果所有格式都失败,返回原始字符串 return str_value except ValueError: # 如果解析失败,返回原始字符串 return str_value return str_value def _get_column_types(self, table_name, mysql_conn): \"\"\"获取表的列类型信息\"\"\" structure = self._get_table_structure(table_name, mysql_conn) return {field[\'Field\']: field[\'Type\'] for field in structure} def _calculate_batch_size(self, table_name): \"\"\"根据表大小动态计算批次大小\"\"\" mysql_conn = self._create_mysql_connection() try: row_count = self._get_table_row_count(table_name, mysql_conn) # 根据行数调整批次大小,但不超过最大值 if row_count < 10000: return BASE_BATCH_SIZE elif row_count < 100000: return min(BASE_BATCH_SIZE * 2, MAX_BATCH_SIZE) elif row_count < 1000000: return min(BASE_BATCH_SIZE * 3, MAX_BATCH_SIZE) else: return MAX_BATCH_SIZE except Exception as e: logger.warning(f\"计算表 \'{table_name}\' 批次大小时出错: {str(e)},使用基础批次大小\") return BASE_BATCH_SIZE finally: mysql_conn.close() def full_sync_table(self, table_name): \"\"\"全量同步单个表数据\"\"\" # 为每个表创建独立的MySQL连接 mysql_conn = self._create_mysql_connection() try: logger.info(f\"开始全量同步表: {table_name}\") # 先创建表 if not self._create_clickhouse_table(table_name): return False # 动态计算批次大小 batch_size = self._calculate_batch_size(table_name) logger.info(f\"表 \'{table_name}\' 使用批次大小: {batch_size}\") # 获取表结构用于构建查询和插入语句 structure = self._get_table_structure(table_name, mysql_conn) columns = [field[\'Field\'] for field in structure] column_names = \', \'.join([f\"`{col}`\" for col in columns]) # 获取列类型用于值转换 column_types = self._get_column_types(table_name, mysql_conn) # 为每个表创建独立的ClickHouse连接 ch_client = Client( **CLICKHOUSE_CONFIG, send_receive_timeout=600, sync_request_timeout=600 ) # 清空目标表 ch_client.execute(f\"TRUNCATE TABLE {CLICKHOUSE_CONFIG[\'database\']}.{table_name}\") # 分批读取MySQL数据并插入到ClickHouse total_rows = self._get_table_row_count(table_name, mysql_conn) logger.info(f\"表 \'{table_name}\' 共有 {total_rows} 行数据需要同步\") offset = 0 processed = 0 batch_start_time = time.time() while offset < total_rows: batch_fetch_start = time.time() cursor = mysql_conn.cursor() cursor.execute( f\"SELECT {column_names} FROM {table_name} LIMIT {batch_size} OFFSET {offset}\" ) rows = cursor.fetchall() cursor.close() batch_fetch_end = time.time() if not rows: break # 插入到ClickHouse,处理特殊值 insert_sql = f\"INSERT INTO {CLICKHOUSE_CONFIG[\'database\']}.{table_name} ({column_names}) VALUES\" # 处理特殊值 processed_rows = [] for row in rows: processed_row = tuple( self._convert_value_for_clickhouse(row[i], column_types.get(columns[i])) for i in range(len(columns)) ) processed_rows.append(processed_row) # 使用优化参数进行批量插入 batch_insert_start = time.time() try: ch_client.execute( insert_sql, processed_rows, types_check=True, # 启用类型检查 settings={ \'async_insert\': 1, \'wait_for_async_insert\': 0 } ) except Exception as insert_error: logger.warning(f\"表 \'{table_name}\' 类型检查插入失败: {str(insert_error)},尝试无类型检查插入\") # 如果类型检查失败,尝试不进行类型检查的插入作为备选方案 try: ch_client.execute( insert_sql, processed_rows, types_check=False, settings={ \'async_insert\': 1, \'wait_for_async_insert\': 0 } ) logger.info(f\"表 \'{table_name}\' 无类型检查插入成功\") except Exception as fallback_error: logger.error(f\"表 \'{table_name}\' 无类型检查插入也失败: {str(fallback_error)}\") raise fallback_error batch_insert_end = time.time() processed += len(rows) offset += batch_size # 每处理一批就显示进度 batch_end_time = time.time() fetch_time = batch_fetch_end - batch_fetch_start insert_time = batch_insert_end - batch_insert_start total_batch_time = batch_end_time - batch_start_time if batch_end_time - batch_start_time > 0 else 1 rate = processed / total_batch_time logger.info(f\"表 \'{table_name}\' 已同步 {processed}/{total_rows} 行数据 \" f\"(速率: {rate:.0f}行/秒, 本次抓取: {fetch_time:.2f}秒, 插入: {insert_time:.2f}秒)\") ch_client.disconnect() logger.info(f\"表 \'{table_name}\' 全量同步完成\") return True except Exception as e: logger.error(f\"表 \'{table_name}\' 全量同步失败: {str(e)}\") return False finally: mysql_conn.close() def full_sync_all_tables(self): \"\"\"全量同步所有表(并行处理)\"\"\" logger.info(\"开始全量同步所有表...\") start_time = time.time() success_count = 0 fail_count = 0 # 使用线程池并行处理多个表,但减少并行数 with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: # 提交所有表的同步任务 future_to_table = { executor.submit(self.full_sync_table, table): table for table in self.tables } # 处理完成的任务 for future in as_completed(future_to_table): table = future_to_table[future] try: result = future.result() if result: success_count += 1 logger.info(f\"表 \'{table}\' 同步成功\") else: fail_count += 1 logger.error(f\"表 \'{table}\' 同步失败\") except Exception as e: fail_count += 1 logger.error(f\"表 \'{table}\' 同步过程中发生异常: {str(e)}\") elapsed_time = time.time() - start_time logger.info( f\"全量同步完成 - 成功: {success_count}, 失败: {fail_count}, \" f\"耗时: {elapsed_time:.2f}秒\" ) return success_count, fail_count def _process_binlog_event(self, event, ch_client, column_types): \"\"\"处理binlog事件\"\"\" table_name = event.table if table_name not in self.tables: return # 忽略不在同步列表中的表 # 为binlog处理创建临时MySQL连接 mysql_conn = self._create_mysql_connection() try: primary_key = self._get_primary_key(table_name, mysql_conn) if not primary_key: logger.warning(f\"表 \'{table_name}\' 没有主键,无法处理增量更新\") return # 处理插入事件 if isinstance(event, WriteRowsEvent): rows = [dict(zip(event.columns, row[\'values\'])) for row in event.rows] column_names = \', \'.join([f\"`{col}`\" for col in event.columns]) insert_sql = f\"INSERT INTO {CLICKHOUSE_CONFIG[\'database\']}.{table_name} ({column_names}) VALUES\" # 处理特殊值 processed_rows = [] for row in rows: processed_row = tuple( self._convert_value_for_clickhouse(row[col], column_types.get(col)) for col in event.columns ) processed_rows.append(processed_row) try: ch_client.execute(insert_sql, processed_rows, types_check=True) except Exception as insert_error: logger.warning(f\"表 \'{table_name}\' binlog插入失败: {str(insert_error)},尝试无类型检查插入\") ch_client.execute(insert_sql, processed_rows, types_check=False) logger.debug(f\"表 \'{table_name}\' 插入 {len(rows)} 行数据\") # 处理更新事件 elif isinstance(event, UpdateRowsEvent): for row in event.rows: old_row = dict(zip(event.columns, row[\'before_values\'])) new_row = dict(zip(event.columns, row[\'after_values\'])) # 获取主键值 pk_value = old_row[primary_key] # 构建更新语句 update_fields = [f\"`{k}` = %s\" for k in new_row.keys() if k != primary_key] update_sql = f\"\"\" ALTER TABLE {CLICKHOUSE_CONFIG[\'database\']}.{table_name} UPDATE {\', \'.join(update_fields)} WHERE `{primary_key}` = %s \"\"\" # 准备参数并处理特殊值 params = [ self._convert_value_for_clickhouse(new_row[k], column_types.get(k)) for k in new_row.keys() if k != primary_key ] + [pk_value] try: ch_client.execute(update_sql, params, types_check=True) except Exception as update_error: logger.warning(f\"表 \'{table_name}\' binlog更新失败: {str(update_error)},尝试无类型检查更新\") ch_client.execute(update_sql, params, types_check=False) logger.debug(f\"表 \'{table_name}\' 更新 {len(event.rows)} 行数据\") # 处理删除事件 elif isinstance(event, DeleteRowsEvent): rows = [dict(zip(event.columns, row[\'values\'])) for row in event.rows] pk_values = [row[primary_key] for row in rows] # 构建删除语句 delete_sql = f\"ALTER TABLE {CLICKHOUSE_CONFIG[\'database\']}.{table_name} DELETE WHERE `{primary_key}` IN\" # 处理特殊值 processed_pk_values = [ self._convert_value_for_clickhouse(val, column_types.get(primary_key)) for val in pk_values ] try: ch_client.execute(delete_sql, (processed_pk_values,), types_check=True) except Exception as delete_error: logger.warning(f\"表 \'{table_name}\' binlog删除失败: {str(delete_error)},尝试无类型检查删除\") ch_client.execute(delete_sql, (processed_pk_values,), types_check=False) logger.debug(f\"表 \'{table_name}\' 删除 {len(rows)} 行数据\") finally: mysql_conn.close() def start_incremental_sync(self): \"\"\"开始增量同步(监听binlog)\"\"\" logger.info(\"开始增量同步...\") # 尝试从保存的位置开始,如果没有则从当前最新位置开始 binlog_position = _load_binlog_position() if binlog_position: log_file, log_pos = binlog_position logger.info(f\"从保存的位置继续: binlog文件 {log_file} 的位置 {log_pos}\") else: # 获取当前binlog位置,从最新位置开始监听 mysql_conn = self._create_mysql_connection() try: cursor = mysql_conn.cursor() cursor.execute(\"SHOW MASTER STATUS\") result = cursor.fetchone() log_file = result[0] if result else None log_pos = result[1] if result else 4 # 4是binlog起始位置 cursor.close() if log_file and log_pos: logger.info(f\"从当前最新位置开始: binlog文件 {log_file} 的位置 {log_pos}\") else: logger.error(\"无法获取MySQL的binlog状态,请检查MySQL配置\") return finally: mysql_conn.close() # 为binlog同步创建专用的ClickHouse连接 ch_client = Client( **CLICKHOUSE_CONFIG, send_receive_timeout=600, sync_request_timeout=600 ) # 配置binlog流读取器 stream = BinLogStreamReader( connection_settings=dict( host=MYSQL_CONFIG[\'host\'], port=MYSQL_CONFIG[\'port\'], user=MYSQL_CONFIG[\'user\'], password=MYSQL_CONFIG[\'password\'], db=MYSQL_CONFIG[\'database\'] ), server_id=100, # 唯一的slave ID log_file=log_file, log_pos=log_pos, resume_stream=True, only_events=[WriteRowsEvent, UpdateRowsEvent, DeleteRowsEvent], blocking=True # 阻塞模式,持续监听 ) try: processed_events = 0 start_time = time.time() for event in stream: # 为每个事件获取列类型(可以优化缓存) mysql_conn = self._create_mysql_connection() try: column_types = self._get_column_types(event.table, mysql_conn) if event.table in self.tables else {} finally: mysql_conn.close() self._process_binlog_event(event, ch_client, column_types) processed_events += 1 # 每处理100个事件记录一次日志 if processed_events % 100 == 0: elapsed_time = time.time() - start_time rate = processed_events / elapsed_time if elapsed_time > 0 else 0 logger.info(f\"已处理 {processed_events} 个binlog事件,平均速率: {rate:.2f} 事件/秒\") # 每处理1000个事件保存一次位置 if processed_events % 1000 == 0: _save_binlog_position(stream.log_file, stream.log_pos) except Exception as e: logger.error(f\"增量同步出错: {str(e)}\") finally: stream.close() ch_client.disconnect() def sync(self): \"\"\"主同步方法,控制全量和增量同步的执行逻辑\"\"\" # 检查同步状态 sync_status = _load_sync_status() # 如果没有执行过全量同步,则先执行全量同步 if not sync_status.get(\'full_sync_completed\'): logger.info(\"首次运行或未完成全量同步,开始执行全量同步...\") success_count, fail_count = self.full_sync_all_tables() # 更新同步状态 if fail_count == 0: sync_status[\'full_sync_completed\'] = True sync_status[\'full_sync_time\'] = time.time() _save_sync_status(sync_status) logger.info(\"全量同步完成,状态已保存\") else: logger.error(\"全量同步失败,将在下次运行时重试\") else: logger.info(\"全量同步已完成,跳过全量同步步骤\") # 执行增量同步 logger.info(\"开始增量同步...\") self.start_incremental_sync() def close_connections(self): \"\"\"关闭数据库连接\"\"\" # 不需要关闭全局连接,因为每个方法都管理自己的连接 logger.info(\"所有数据库连接已关闭\")if __name__ == \"__main__\": sync_tool = MySQLToClickHouseSync() try: # 使用新的同步方法 sync_tool.sync() except KeyboardInterrupt: logger.info(\"用户中断同步程序\") except Exception as e: logger.error(f\"同步过程中发生错误: {str(e)}\") finally: sync_tool.close_connections().env文件在同级根目录下,大概内容为:
# MySQL配置MYSQL_HOST=127.0.0.1MYSQL_PORT=3306MYSQL_USER=rootMYSQL_PASSWORD=rootMYSQL_DATABASE=mysql_db# ClickHouse配置CLICKHOUSE_HOST=127.0.0.1CLICKHOUSE_PORT=9000CLICKHOUSE_USER=defaultCLICKHOUSE_PASSWORD=123456CLICKHOUSE_DATABASE=clickhouse_db# 同步配置BATCH_SIZE=10000文件结构如下,需要有python环境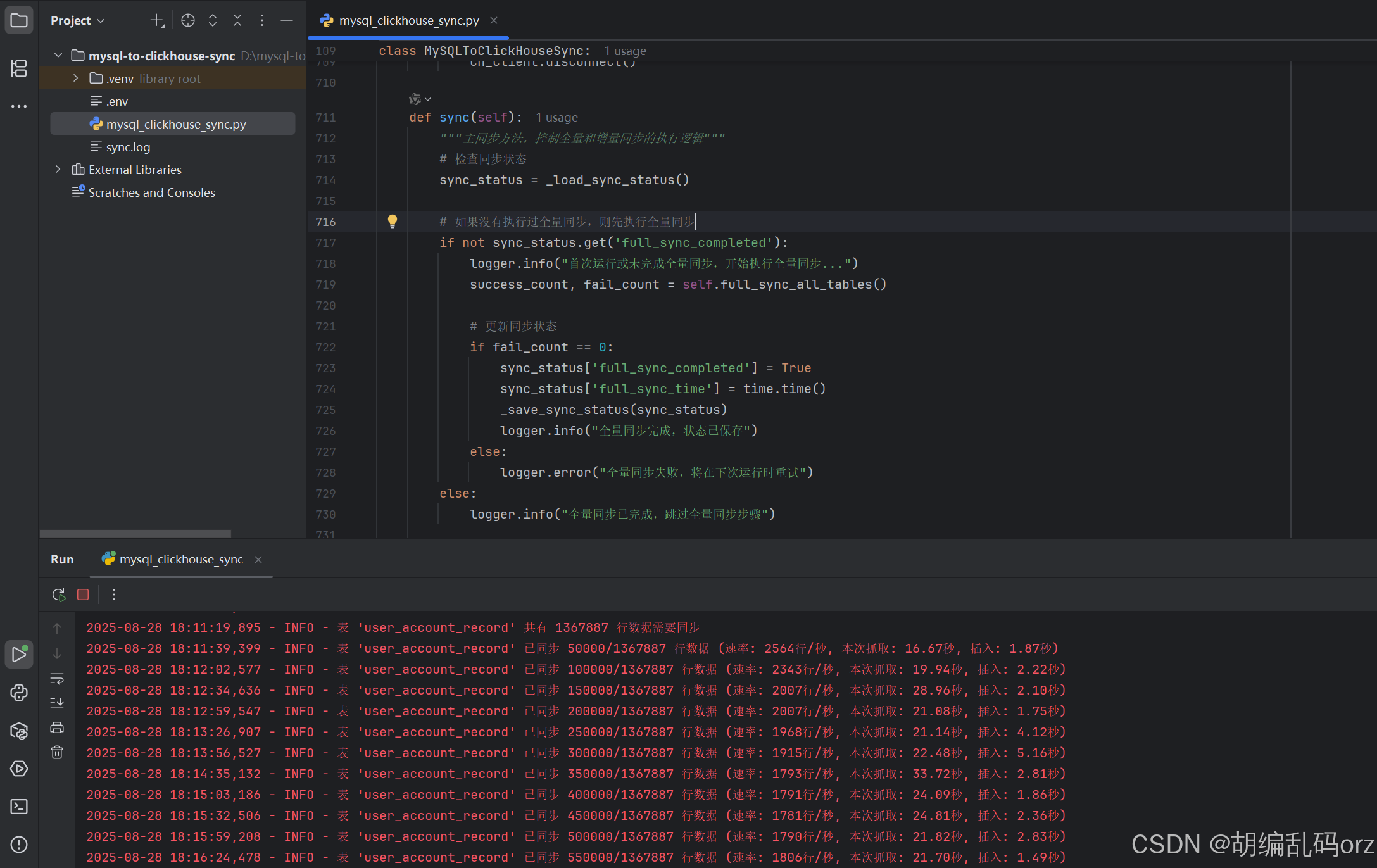
PS: 这里需要使用ClickHouse的TCP原生协议端口(默认是9000,可以在clickhouse的配置文件修改成其他的),而不是HTTP协议端口(8123)。
迁移注意事项
-
⚠️ 事务兼容性:ClickHouse 不支持复杂事务,需调整应用逻辑
-
⚠️ 索引差异:需重新设计 ClickHouse 的主键和分区策略
-
⚠️ 查询语法:部分 MySQL 函数在 ClickHouse 中有差异(如 GREATEST 函数处理 NULL 的方式)
-
⚠️ 权限控制:ClickHouse 的权限体系与 MySQL 不同
🤝 混合架构最佳实践
在大多数企业中,MySQL 和 ClickHouse 并非相互替代,而是互补关系。以下是经过验证的混合架构模式:
实时同步架构
MySQL → Binlog → Kafka → ClickHouse实现方式:
-
使用 Debezium 捕获 MySQL binlog
-
通过 Kafka Streams 进行简单转换
-
使用 ClickHouse Kafka 引擎消费数据
适用场景:
-
实时分析仪表盘
-
数据监控告警
-
用户行为实时分析
优势:
-
数据延迟可控制在秒级
-
对 MySQL 影响小
-
可扩展性好
批量同步架构
MySQL → 定时ETL → ClickHouse实现方式:
-
使用 crontab 定时触发 ETL 任务
-
按时间分区批量同步数据
-
采用 MergeTree 的 TTL 机制自动过期旧数据
适用场景:
-
每日 /hourly 报表生成
-
历史数据分析
-
数据归档场景
优势:
-
架构简单可靠
-
资源消耗可控
-
适合大规模数据迁移
读写分离架构
应用 → 写MySQL → 读ClickHouse实现方式:
-
关键业务数据写入 MySQL 确保事务安全
-
同步至 ClickHouse 供分析查询使用
-
应用层根据查询类型路由到不同数据库
适用场景:
-
电商订单系统(写订单到 MySQL,分析到 ClickHouse)
-
用户管理系统(用户数据存 MySQL,画像分析用 ClickHouse)
优势:
-
各数据库专注于擅长场景
-
可独立扩展
-
不影响核心业务
🛠️ 性能优化指南
MySQL 优化要点
- InnoDB 缓冲池优化
-
设置合理的 innodb_buffer_pool_size(物理内存的 50-70%)
-
开启 innodb_buffer_pool_instances 减少锁竞争
- 索引优化
-
为常用查询创建合适的索引
-
避免过度索引影响写入性能
-
使用覆盖索引减少回表
- 查询优化
-
避免 SELECT *
-
合理使用 JOIN 代替子查询
-
控制结果集大小
ClickHouse 优化要点
- 表设计优化
-
选择合适的分区键(推荐时间字段)
-
合理设置主键(高基数字段在前)
-
使用合适的排序键加速查询
- 查询优化
-
只查询需要的列(列式存储优势)
-
使用 PREWHERE 过滤数据
-
合理使用物化视图预计算
- 配置优化
-
调整 max_threads 利用多核 CPU
-
设置合适的内存限制
-
启用主键缓存(use_primary_key_cache)
- 写入优化
-
批量写入(每次 10,000 + 行)
-
避免单条 INSERT
-
合理设置 flush_interval
🔮 未来展望:数据库技术发展趋势
🚀 ClickHouse 的发展方向
ClickHouse 在完成 3.5 亿美元 C 轮融资后,正加速其产品进化,未来发展重点包括:
- AI 原生集成
-
优化 AI Agent 的高频查询支持
-
开发面向 LLM 的向量搜索能力
-
自动生成查询优化建议
- 生态系统扩展
-
深化与数据湖技术的集成(Iceberg/Hudi)
-
完善与 BI 工具的无缝对接
-
提供更丰富的连接器
- 企业级特性增强
-
提升事务支持能力
-
增强安全与合规特性
-
简化管理运维复杂度
- 性能持续突破
-
进一步优化向量化执行引擎
-
开发智能缓存机制
-
利用新硬件特性(如 GPU 加速)
🔄 MySQL 的演进路径
MySQL 作为成熟的关系型数据库,正沿着以下方向发展:
- 云原生转型
-
优化容器化部署体验
-
增强与 Kubernetes 的集成
-
发展 serverless 形态
- 性能与功能增强
-
持续优化 InnoDB 存储引擎
-
增强 JSON 处理能力
-
完善窗口函数等分析特性
- 多模型支持
-
在关系模型基础上融合文档特性
-
增加时序数据处理能力
-
探索图形数据支持
- 安全性强化
-
更细粒度的权限控制
-
增强数据加密能力
-
完善审计日志功能
🤝 融合与分化并存
数据库领域正呈现 “融合与分化” 并存的发展态势:
-
分化:OLTP 与 OLAP 数据库将继续在各自领域深化优化
-
融合:两类数据库都在借鉴对方的优势特性
-
协同:多引擎数据平台成为主流,数据无缝流动是关键
未来企业的数据架构将更加多元化,MySQL 和 ClickHouse 作为各自领域的佼佼者,将在很长一段时间内保持互补关系。
🧭 技术选型决策指南
选择 MySQL 还是 ClickHouse,应基于具体业务需求:
- 数据特性评估
-
数据量:小到中量选 MySQL,大量到海量选 ClickHouse
-
数据变化:频繁更新选 MySQL,写入后很少修改选 ClickHouse
-
数据结构:结构化强事务选 MySQL,半结构化分析选 ClickHouse
- 查询模式分析
-
查询类型:事务性查询选 MySQL,分析聚合查询选 ClickHouse
-
查询频率:低频率复杂查询可接受 MySQL,高频率查询选 ClickHouse
-
查询延迟:微秒级点查询选 MySQL,毫秒级分析查询选 ClickHouse
- 部署运维考量
-
团队熟悉度:MySQL 生态更成熟,人才易获取
-
运维复杂度:MySQL 更简单,ClickHouse 分布式架构较复杂
-
成本预算:中小规模 MySQL 成本更低,大规模 ClickHouse 更具成本优势
- 未来扩展性
-
用户增长:用户数快速增长需考虑 ClickHouse 的水平扩展能力
-
功能扩展:需要复杂事务选 MySQL,需要实时分析选 ClickHouse
🎯 结论:各擅胜场的数据库双星
通过对 MySQL 和 ClickHouse 的全面对比,我们可以清晰地看到这两种数据库在设计理念、性能特性和适用场景上的显著差异:
MySQL 作为成熟的关系型数据库,以其完善的 ACID 事务支持、稳定的性能和丰富的生态系统,在 OLTP 领域继续保持领先地位。它特别适合处理结构化数据、需要强一致性保障的业务场景,如电商交易、金融支付等核心系统。
ClickHouse 则代表了新一代列式存储数据库的发展方向,通过创新的存储引擎和查询优化技术,在 OLAP 场景中展现出卓越的性能。它能够轻松应对 PB 级数据的实时分析需求,成为企业构建实时数据平台的首选技术之一。
在实际应用中,这两种数据库并非相互替代,而是形成互补关系。现代企业的数据架构正越来越多地采用 “MySQL + ClickHouse” 的混合模式:用 MySQL 保障核心业务的事务安全,用 ClickHouse 挖掘数据价值。这种架构既满足了业务交易的可靠性要求,又能支持实时数据分析,为企业决策提供数据驱动的洞察。
随着技术的不断演进,MySQL 和 ClickHouse 都在吸收对方的优势特性,但它们的核心定位和设计哲学不会改变。选择合适的数据库不仅是技术决策,更是业务战略的体现。希望本文的深入分析能为读者在复杂的数据库选型过程中提供清晰的指引,充分发挥每种技术的优势,构建高效、可靠的数据基础设施。

