Elasticsearch《一》
一、初识ES
Elasticsearch为一款高性能分布式搜索引擎。
ES之所以有如此高性能的搜索表现,正是得益于底层的倒排索引技术。
正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
而倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
MYSQL采用正向索引,可以给多个字段创建索引,根据索引字段搜索、排序速度非常快。但是根据非索引字段,或者索引字段的部分词条扫描时,只能全表扫描。
而ES根据词条搜索、模糊搜索时,速度非常快。但只能给词条做索引,而不是字段,也没法根据字段做排序。
下表为MYSQL与ES的对应关系:
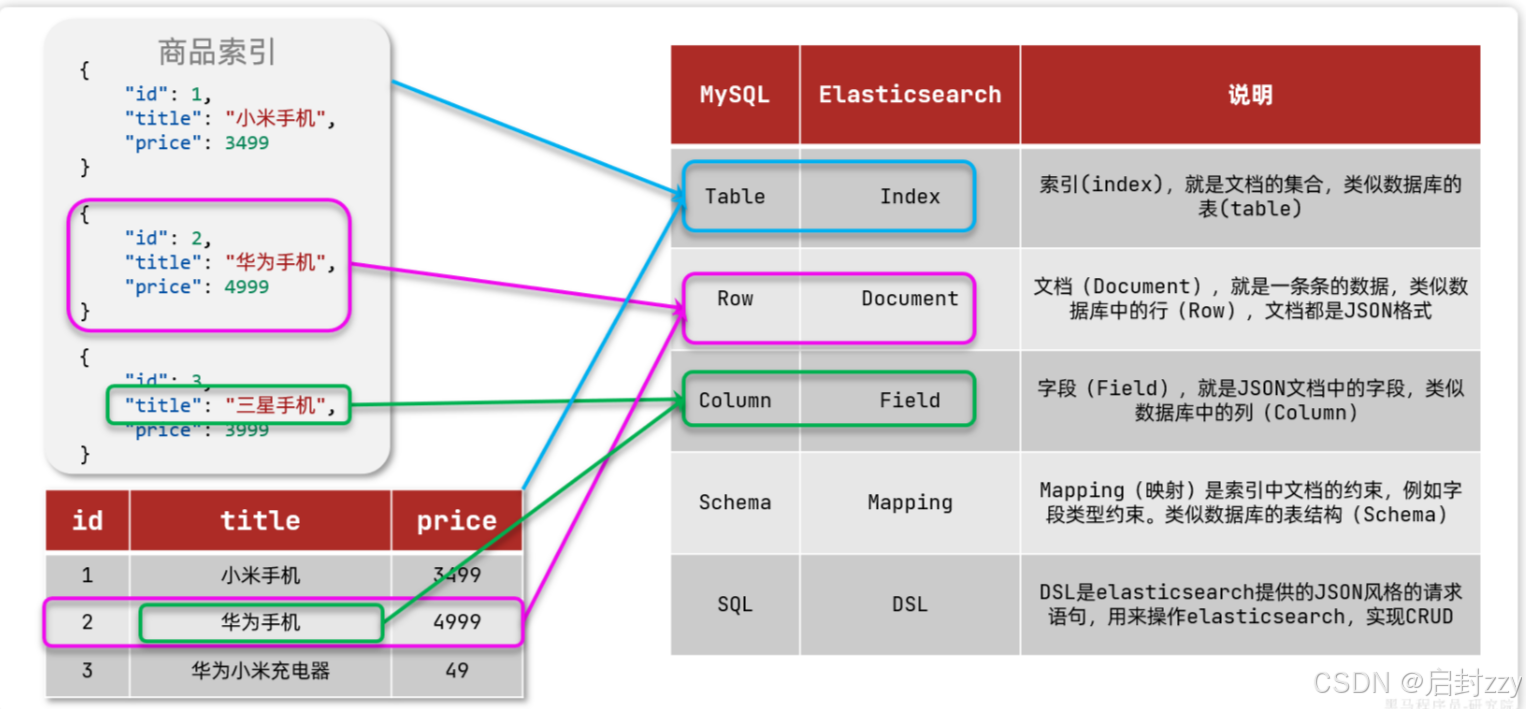
MYSQL与ES各有千秋,Mysql:擅长事务类型操作,可以确保数据的安全和一致性,Elasticsearch:擅长海量数据的搜索、分析、计算;两者通常结合使用,对安全性能较高的写操作使用mysql实现,对查询性能要求较高的搜索需求时,使用elasticsearch实现,两者基于某种方式(4种方式,常利用binlog实现实时同步),实现mysql与es数据的同步,保证一致性。
ES可通过IK分词器实现分词。
Q1:分词器的作用是什么?
创建倒排索引时,对文档分词
用户搜索时,对输入的内容进行分词。
Q2:IK分词器的模式?
ik_smart:智能切分,粗粒度
ik_max_word:最细切分,细粒度
Q3:IK分词器如何拓展词条?如何停用词条?
利用config目录的IkAnalyzer.cfg.xml文件添加拓展词典和停用词典
在词典中添加拓展词条或者停用词条
二、索引库操作
创建索引库: PUT /索引库名
查询索引库: GET /索引库名
删除索引库: DELETE /索引库名
修改索引库,添加字段(无法修改,只能添加字段):PUT /索引库名/_mapping
三、文档操作
创建文档: POST /{索引库名}/_doc/文档id { json文档 }
查询文档: GET /{索引库名}/_doc/文档id
删除文档: DELETE /{索引库名}/_doc/文档id
修改文档: 全量修改: PUT /{索引库名}/_doc/文档id { json文档 }
局部修改:POST /{索引库名}/_update/文档id{\"doc\":{字段}}
四、RestClient操作索引库
ES官方提供了各种不同语言的客户端,用来操作ES。这些客户端的本质就是组装DSL语句,通过http请求发送给ES。
在elasticsearch提供的API中,与elasticsearch一切交互都封装在一个名为RestHighLevelClient的类中,必须先完成这个对象的初始化,建立与elasticsearch的连接。
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder( HttpHost.create(\"http://192.168.150.101:9200\") ));
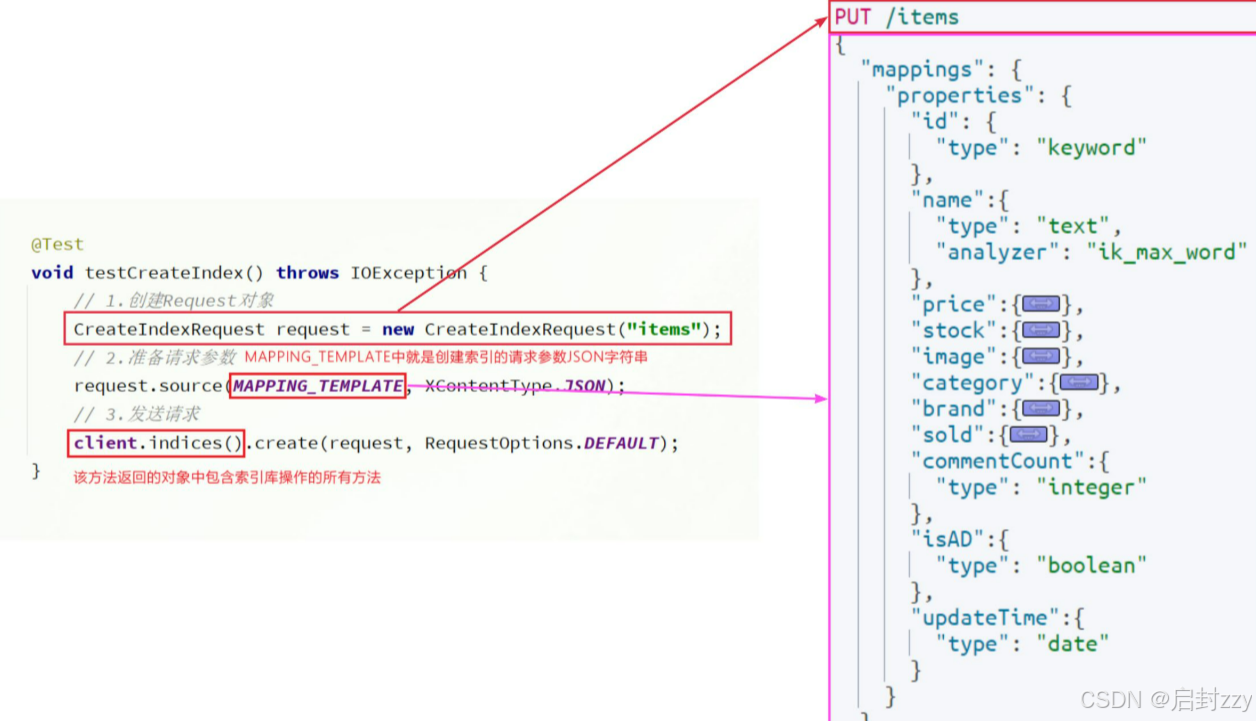
JavaRestClient核心是client.indices()方法来获取索引库的操作对象。
索引库操作的基本步骤:
1.初始化RestHighLevelClient
2.创建XxxIndexRequest。Xxx是Create、Get、Delete
3.准备请求参数(Create时需要,其他可省略)
4.发送请求,调用RestHighLevelClient#indices().xxx()方法
xxx为create、exists、delete。
五、RestClient操作文档
索引库准备好以后,就可以操作文档了。
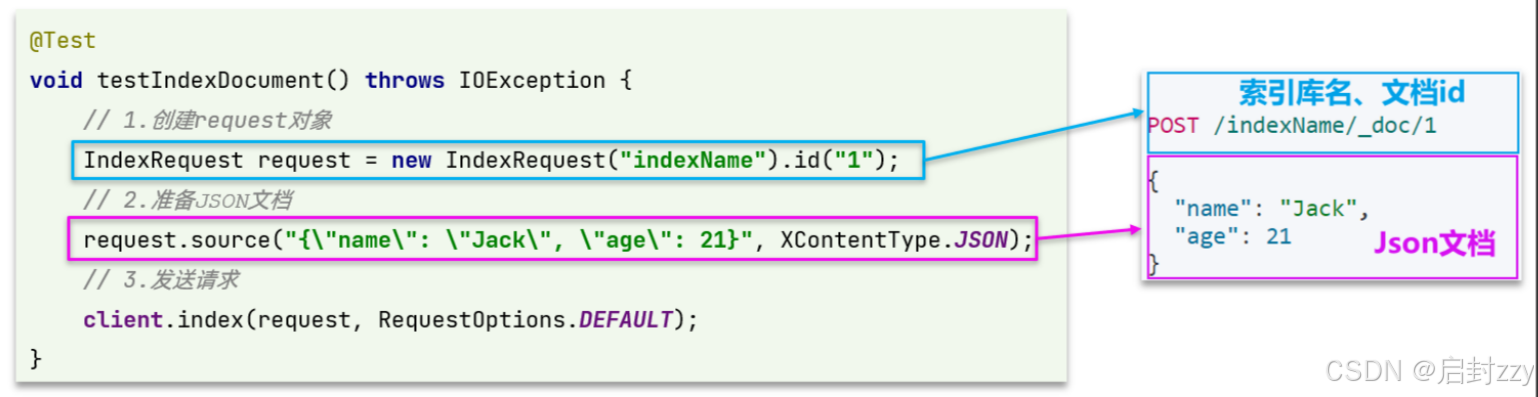
变化的地方在于这里直接使用client.xxx()的API,不在使用client.indices()了。
我们导入商品数据,除了参考API模板“三步走”以外,还需要做几点准备工作:
-
商品数据来自于数据库,我们需要先查询出来,得到
Item对象 -
Item对象需要转为ItemDoc对象 -
ItemDTO(也就是ItemDoc)需要序列化为json格式
因此,代码整体步骤如下:
1)根据id查询商品数据Item
2)将Item封装为ItemDoc
3)将ItemDoc序列化为JSON
4)创建IndexRequest,指定索引名和id
5)准备请求参数,也极速Json文档
6)发送请求
@Testvoid testAddDocument() throws IOException { // 1.根据id查询商品数据 Item item = itemService.getById(100002644680L); // 2.转换为文档类型 ItemDoc itemDoc = BeanUtil.copyProperties(item, ItemDoc.class); // 3.将ItemDTO/ItemDoc转json String doc = JSONUtil.toJsonStr(itemDoc); // 1.准备Request对象 IndexRequest request = new IndexRequest(\"items\").id(itemDoc.getId()); // 2.准备Json文档 request.source(doc, XContentType.JSON); // 3.发送请求 client.index(request, RequestOptions.DEFAULT);}文档操作的基本步骤:
1.初始化RestHighLevelClient
2.创建XxxRequest,Xxx可以是Index、Get、Update、Delete、Bulk
3.准备参数(Index、Update、Bulk时需要)
4.发送请求 调用RestHighLevelClient#.xxx()
xxx可以是index,get,update,delete,bulk
5.解析结果(Get时需要)如下:
@Testvoid testGetDocumentById() throws IOException { // 1.准备Request对象 GetRequest request = new GetRequest(\"items\").id(\"100002644680\"); // 2.发送请求 GetResponse response = client.get(request, RequestOptions.DEFAULT); // 3.获取响应结果中的source String json = response.getSourceAsString(); ItemDoc itemDoc = JSONUtil.toBean(json, ItemDoc.class); System.out.println(\"itemDoc= \" + ItemDoc);}
