Spark SQL-结构化数据文件处理_sparksession 开发 sql 文档
目录
任务背景
认识 Spark SQL
了解 Spark SQL基本概念
配置 Spark SQL
了解 Spark SQL与Shell 交互
掌握 DataFrame 基础操作
创建 DataFrame 对象
2.通过外部数据库创建DataFrame
3.通过 RDD 创建 DataFrame
4.通过 Hive 中的表创建DataFrame
任务背景
基于大数据技术对房价进行分析和预测,是科学精准调控,促进房地产市场平稳健康发展的重要手段,住房是民生之要,为民造福是立党为公、执政为民的本质要求。
现有一份房屋销售数据文件house.csv,记录了某地区的房屋销售情况,包含销售价格、销售日期、房屋评分等共14个数据字段,字段说明如表所示(1英尺=0.3048米)。
房屋销售数据字段说明
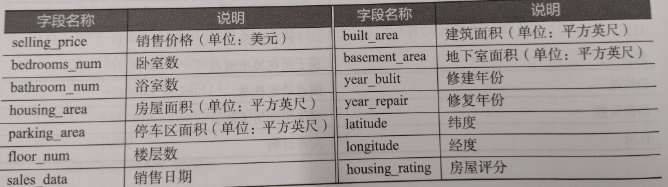
在进行房价数据分析之前,由于无法直接判断出各个数据字段之间的关系,因此需要先对数据进行基础的探索,探索各个数据字段间的关系并加以分析。本章将使用Spark SQL即席查询框架解决房价数据探索分析的问题。
认识 Spark SQL
使用Spark SQL探索分析房价数据前,需要先了解Spark SQL是什么有什么作用。因此,本节的任务是了解Spark SQL框架,SpetkSQL的编码模型 DataFrame和Spark SQL的运行过程。并对SparkSQL相关环境进行配置
了解 Spark SQL基本概念
Spark SQL是一个用于处理结构化数据的框架,可被视为一个分布式的SQL查询引擎,提供了一个抽象的可编程数据模型DataFrameSpark SQL框架的前身是Shurk框架,由于 Shark 需要依赖于Hive,这制约了Spark各个组件的相互集成,因此Spark团队提出了 Spath SQL项目。Spark SQL借鉴了Shark的优点,同时摆脱了对Hive 的依赖。相对于Sat Spark SQL在数据兼容、性能优化、组件扩展等方面更有优势。
Spark SQL在数据兼容方面的发展,使得开发人员不仅可以直接处理RDD.还可以处理Parquet 文件或 JSON 文件,甚至可以处理外部数据库中的数据,Hive中存在的表数据。 Spark SQL的一个重要特点是能够统一处理关系表数据和RDD数据,开发人员可以轻松地使用SQL或HiveQL语句进行外部查询,也可以进行更复杂的数据分析。
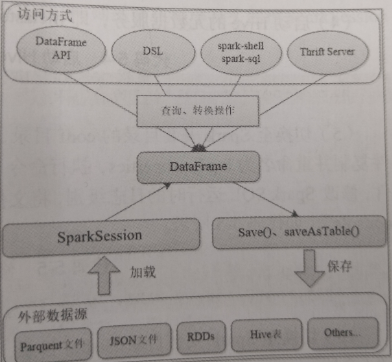
Spark SQL 的运行过程如图所示。Spark SQL提供的核心的编程数据模型是 DataFrame。DataFrame是一个分布式的Row对象的数据集合,实现了RDD的绝大多数功能。SparkSQL通过SparkSession入口对象提供的方法可从外部数据源如Parquent文件、JSON文件、RDDs、Hive表等加载数据为DataFrame,再通过DataFrame提供的API接口、DSL(领域特定语言)、spark-shell、 spark-sql或Thrift Server等方式对Data Frame数据进行查询、转换等操作,并将结果展现出来或使用save()、saveAsTable()方法将结果存储为不同格式的文件。
配置 Spark SQL
Spark SQL 可以兼容 Hive以便在SparkSQL中访问Hive表、使用UDF(用户自定义函数)和使用Hive查询语言。从Spark开始,Spark增加了Spark SQL命令行界面(CommandLineInterface,CLI)和Thrift Server功能,使得Hive的用户和更熟悉 SQL 语句的数据库管理员更容易上手。
即使没有部署好Hive,Spark SQL也可以运行。若使用Spark SQL的方式访问并操作 Hive表数据,则需要对Spark SQL进行如下的环境配置(Spark 集群已搭建好),将Spark SQL连接至部署成功的 Hive上。
(1)将hive-sitexml 复制至/usr/locaU/spark-3.2.1-bin-hadoop2.7/comf目录下:
cp /usr/local/hive-3.1.2/cont/hive-site.xml \\/usr/1ocal/spark-3.2.1-bin-hadoop2.7/conf/(2)在/usr/local/spark-3.2.1-bin-hadoop2.7/conf/spark-v.sh文件中配置MySQL驱动,使用MySQL驱动包为mysql-connector-java-8.0.26jar。将MySQL驱动包复制至所有节点的与装目录的/lib目录下。执行命令“vim /usr/local/spark-3.2.1-bin-hadoop2.7/comf/spark有芳 spark-env.sh 文件,在文件末尾添加所示的内容。
export SPARK_CLASSPATH= \\/usr/local/spark-3.2.1-b1n-hadoop2.7/jars/=mysql-connector-jar-8.0.26.jar(3)启动 MySQL服务:
systemctl start mysqld.servics(4)启动 Hive 的元数据服务,即metastore服务:
hive --service metastore &(5)切换至Spark 安装目录的/conf目录,将/conf目录下的log4j.properties.template 文件复制并重命名为log4j.properties,执行命令“vim log4j.properties”打开log4j.properies 文件,修改Spark SQL运行时的日志级别,将文件中“log4jrootCategory”的值修改为“WARN console\"如下代码所示:
log4j.rootCategary=WARN,console(6)切换至Spark 安装目录的/sbin目录,执行命令“/start-allsh”启动 Spark 集群,如图代码所示:
[root@master sbin]# ./start-all.shstarting org.apache.spark.deploy.master.Master,logging to /usr/local/spark-3.2.I-bin- adoop2.7/logs/spark-root-org.apache.spark.deplay.master,Master-I-master.outlave2: starting org.apache.spark.deploy.worker.Worker,logging to /usr/ocaL/spark-3.1-bin hadoop2.7/logs/spark-roat-org.apache.spark.deplay.worker ,worker.l-slave2.out slavel: starting org.apache. spark.deploy.worker ,Morker,iogqing to /usr/ocal/spark-3.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker,Worker l.slavel.out(7)切换至Spark安装目录的/bin目录,执行命令“./spark-sql”开启Spark SQL命令行界面,在Spark SQL命令行界面中可以直接执行HiveQL语句。在Hive中创建一个students表,如代码所示:
#查看数据库show databases;#创建一个表create table students( id int,name string, score double, classes string)row format delimited fields terminated by \'\\t\';了解 Spark SQL与Shell 交互
Spark SQL 框架其实已经集成在spark-shell中,因此,启动spark-shell 即可使用Spark SQL 的 Shell 交互接口。从Spark 2.x版本开始,Spark对SQLContext和HiveContext进行整合。提供一种全新的人口方式:SparkSession。
如果在spark-shell中执行SQL语句,那么需要使用SparkSession对象调用sql()方法。
spark-shell在启动的过程中会初始化SparkSession对象为spark,此时初始化的spark对象既支持SQL语法解析器,也支持HiveQL语法解析器。也就是说,使用spark可以执行SQL语和 HiveQL语句。
如果是使用IntelliJ IDEA软件开发SparkSQL程序,则需要在程序开头创建SparkSession对象,如代码所示。
import org.apache.spark.{SparkConf,SparkContext} import org.apache,spark.sql.SparkSessionobject Test { def main(args: Array[String]); Unit={ val spark=SparkSession .builder() //使用SparkSession的builder方法创建SparkSession 对象 .appName(\"SparkSQL\") //appName等效于 SparkContext的setAppName 方法 .master(\"local\") //master等效于SparkContext的setMaster 方法 .getOrCreate() //如果对象已存在,则使用它;否则创建它 }}如果需要支持Hive,还需要启用enableHiveSupport()方法,如代码所示,并且Hive的配置文件hive-site.xml已经存在于工程中。
val spark=SparkSession .builder() .appName(\"SparkSQL\") .master(\"local\") .config(\"hive.metastore.uris\",\"thrift://192.168.128.130:9083\") //设置 hive 的 thrift服务地址及端口.enableHiveSupport() // 启用Hive支持.getOrCreate()掌握 DataFrame 基础操作
Spark SQL 提供了一个抽象的编程数据模型DataFrame,DataFrame是由 SchemaRDD 发展而来的,从Spark1.3.0开始,SchemaRDD更名为DataFrame. SchemaRDD直接继承自RDD,而DataFrame 则自身实现RDD的绝大多数功能。可以将SparkSQL的DataFrame理解为一个分布式的Row对象的数据集合,该数据集合提供了由列组成的详细模式信息。本节的任务是学习DataFrame对象的创建方法及基础的操作。
创建 DataFrame 对象
DataFrme可以通过结构化数据文件、外部数据库、Spark计算过程中生成的 RDD、 Hive 中的表进行创建。不同数据源的数据转换成DataFrame的方式也不同。
1.通过结构化数据文件创建DataFrame
一般情况下,结构化数据文件存储在HDFS中,较为常见的结构化数据文件是Parquet文件或JSON 文件。SparkSQL可以通过load()方法将HDFS上的结构化文件数据转换为 DataFrame,load()方法默认导入的文件格式是Parquet。
将/usr/local/spark-3.2.1-bin-hadoop2.7/examples/src/main/resources目录下的users.parquret 文件上传至HDFS 的/user/root/sparkSql目录下,加载HDFS上的users.parquet 文件数据并将其转换为DataFrame,如下代码所示。
val dfUsers = spark.read.load (\"/user/root/sparkSq1/users.parquet\" )若加载JSON格式的文件数据,将其转换为DataFrame,则还需要使用format()方法。将/usr/local/spark-3.2.1-bin-hadoop2.7/examples/src/main/resources目录下的people.json 文件上传至HDFS的/user/root/sparkSql目录下,使用format()方法及load()方法加载HDFS上的 people,json 文件数据,并将其转换为DataFrame,如下代码所示。
val dfPeople = spark.read.format (\"json\") .load( \"/user/root/sparkSql/people.json\" )读者也可以直接使用json()方法将JSON文件数据转换为DataFrame,如下代码所示。
val dfPeople = spark.read.json(\"/uner/root/sparkSql/people.json\")2.通过外部数据库创建DataFrame
Spark SQL还可以过外部数据库(如MySQL、Oracle数据库)创建DataFrame,使用该方式创建 DataFrame需要通过Java数据库互连(Java Databae Connectivity,JDBC)连接或开放式数据库互连(Open Database Connectivity,ODBC)连接的方式访问数据库。以 MySQL数据库的表数据为例,将MySQL数据库test中的people表的数据转换为DataFrame,如代码所示,读者需要将“user”“password”对应的值修改为实际进入MySQL数据库时的账户名称和密码。
#设置MySQL的url的地址及端口 val url=\"jdbc:mysql://192.168.128.130:3306/teat\"#连接MySQL获取数据库 test 中的 people 表val jdbcDF = spack.read.format (\"jdbc\").options( Map(\"url\" -> uri,\"user\" -> \"root\",\"password\" -> \"123456\",\"dbtable\" -> \"people\")).load ()3.通过 RDD 创建 DataFrame
通过RDD数据创建DataFrame有两种方式。第一种方式是利用反射机制推断RDD模式,首先需要定义一个样例类,因为只有样例类才能被Spark隐式地转换为DataFrame。将/usr/local/spark-3.2.1-bin-hadoop2.7/examples/src/main/resources目录下的people.txt文件上传至HDFS的/user/root/sparkSql目录下。读取 HDFS上的people.txt文件数据创建RDD,再将该RDD转换为DataFrame,如代码所示。
#定义一个样例类case class Person(name:String,age:Int)#读取文件创建RDDval data = sc.textFile(\"/user/root/sparkSql/people.txt\").map (_.split(\",\"))#RDD转成 DataFrameval people = data.map(p => Person (p(0),p(1).trim,toInt)).toDF() 第二种方式是采用编程指定 Schema 的方式将 RDD转换成DataFrame,实现步骤如下:
(1)加载数据创建RDD。
(2)使用StructType创建一个和步骤(1)的RDD中的数据结构相匹配的Schema
(3)通过createDataFrame()方法将Schema应用到RDD 上,将RDD数据转换成 DataFrame,如下代码所示。
#创建RDDval people = sc.textFile(\"/user/root/sparkSq1/people.txt\")#用structType创建一个数据结构相匹配的Schema val schemaString = \"name age\"import org.apache.spark.sql.Row import org.apache.spark.sql.types.{StructType,StructField,StringType}val schema = StructType(schemaString.split(\" \").map( fieldName => StructField(fieldName,StringType, true)))#Schema 转成RDD再转成 DataFrameval rowRDD = people.map(_.split(\",\")).map(P => Row (p(0),p(1).trim)) val peopleDataFrame = spark.createDataFrame(rowRDD,schema)4.通过 Hive 中的表创建DataFrame
通过Hive中的表创建DataFrame,可以使用SparkSession对象。
使用SparkSession对象并调用sqI(方法查询Hive中的表数据并将其转换成DataFrame.如查询test数据库中的people表数据并将其转换成DataFrame,如代码所示。
#选择 Hive 中的 test数据库 spark.sql(\"use test\")#将Hive中test数据库中的people表转换成DataFrame val people = spark.sql(\"select * from people\" )

