基于Spring Cloud Gateway构建API网关
目录
网关是干什么的?
GateWay?
基本概念:
执行流程:
Gateway工作流程以及GateWay搭建
Predicate
Filter
实战分析
限流?
接口防刷?
参数解密、验证签名?
网关是干什么的?
在微服务架构中,一个系统会被拆分为很多个微服务。那么作为客户端要如何去调用这么多的微服务呢?如果没有网关的存在,我们只能在客户端记录每个微服务的地址,然后分别去调用。这样的话会产生很多问题,例如:
-
客户端多次请求不同的微服务,增加客户端代码或配置编写的复杂性
-
认证复杂,每个微服务都有独立认证
-
存在跨域请求,在一定场景下处理相对复杂
为解决上面的问题所以引入了网关的概念:所谓的API网关,就是指系统的统一入口,提供内部服务的路由中转,为客户端提供统一服务,一些与业务本身功能无关的公共逻辑可以在这里实现,诸如认证、鉴权、监控、路由转发等。
GateWay?
SpringCloud GateWay使用的是Webflux中的reactor-netty响应式编程组件,底层使用了Netty通讯框架。
Spring Cloud Gateway 基于Spring Boot 2.x、Spring WebFlux和Project Reactor,它旨在为微服务架构提供一种简单有效的统一的 API 路由管理方式。它的目标是替代Netflix Zuul,其不仅提供统一的路由方式,并且基于 Filter 链的方式提供了网关基本的功能,例如:安全,监控和限流。
特点:
-
性能强劲:是Zuul的1.6倍
-
功能强大:内置了很多实用的功能,例如转发、监控、限流等
-
设计优雅,容易扩展
基本概念:
路由(Route) 是 gateway 中最基本的组件之一,表示一个具体的路由信息载体。主要定义了下面的几个信息:
-
id:路由标识、区别于其他route
-
uri:路由指向的目的地uri,即客户端请求最终被转发到的微服务
-
order:用于多个route之间的排序,数值越小排序越靠前,匹配优先级越高
-
predicate:断言的作用是进行条件判断,只有断言都返回真,才会真正的执行路由
-
filter:过滤器用于修改请求和响应信息
执行流程:
-
Gateway Client向Gateway Server发送请求
-
请求首先会被HttpWebHandlerAdapter进行提取组装成网关上下文
-
然后网关的上下文会传递到DispatcherHandler,它负责将请求分发给RoutePredicateHandlerMapping
-
RoutePredicateHandlerMapping负责路由查找,并根据路由断言判断路由是否可用
-
如果过断言成功,由FilteringWebHandler创建过滤器链并调用
-
请求会一次经过PreFilter--微服务--PostFilter的方法,最终返回响应
Gateway工作流程以及GateWay搭建
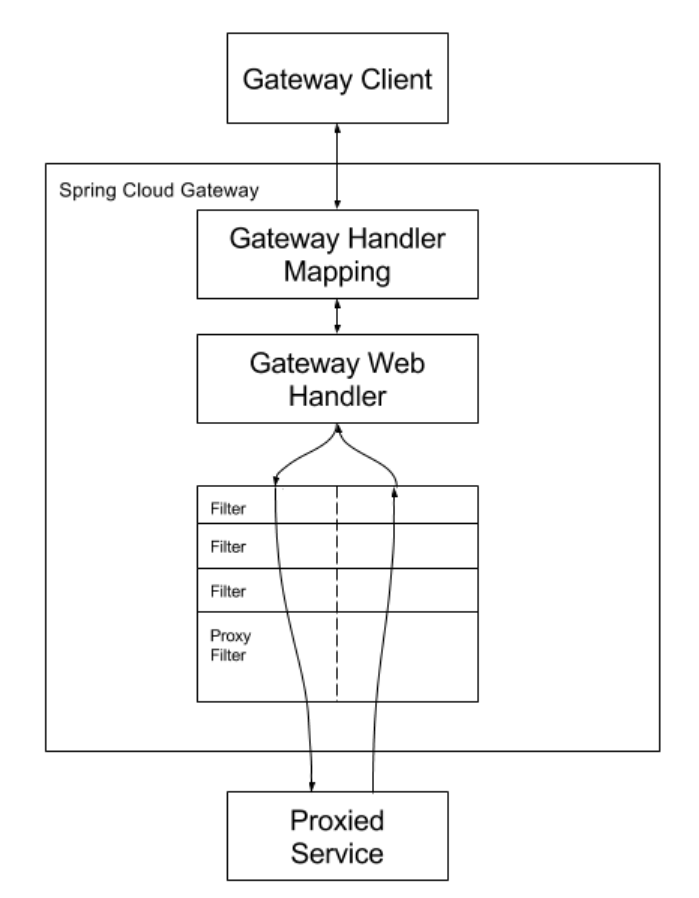
核心概念:
客户端向 Spring Cloud Gateway 发出请求。如果Gateway Handler Mapping确定请求与路由匹配,则将其发送到Gateway Web Handler 处理程序。此处理程序通过特定于请求的Fliter链运行请求。Fliter被虚线分隔的原因是Fliter可以在发送代理请求之前(pre)和之后(post)运行逻辑。执行所有pre过滤器逻辑。然后进行代理请求。发出代理请求后,将运行“post”过滤器逻辑。
过滤器作用:
-
Filter在pre类型的过滤器可以做参数效验、权限效验、流量监控、日志输出、协议转换等。
-
Filter在post类型的过滤器可以做响应内容、响应头的修改、日志输出、流量监控等
-
这两种类型的过滤器有着非常重要的作用
核心组件:
-
Route(路由)
路由是构建网关的基础模块,它由ID,目标URI,包括一些列的断言和过滤器组成,如果断言为true则匹配该路由
-
Predicate(断言)
参考的是Java8的java.util.function.Predicate,开发人员可以匹配HTTP请求中的所有内容(例如请求头或请求参数),请求与断言匹配则进行路由
-
Filter(过滤)
指的是Spring框架中GateWayFilter的实例,使用过滤器,可以在请求被路由前或者之后对请求进行修改。
-
三个核心点连起来:
当用户发出请求到达GateWay,GateWay会通过一些匹配条件,定位到真正的服务节点,并在这个转发过程前后,进行一些及细化控制。其中Predicate就是我们匹配的条件,而Filter可以理解为一个拦截器,有了这两个点,再加上目标URI,就可以实现一个具体的路由了。
Predicate
就是为了实现一组匹配规则,让请求过来找到对应的Route进行处理。
每一个Predicate的使用,可以理解为:当满足条件后才会进行转发,如果十多个,那就是满足所有条件才会转发
断言种类:
-
After:匹配在指定日期时间之后发生的请求。
-
Before:匹配在指定日期之前发生的请求。
-
Between:需要指定两个日期参数,设定一个时间区间,匹配此时间区间内的请求。
-
Cookie:需要指定两个参数,分别为name和regexp(正则表达式),也可以理解Key和Value,匹配具有给定名称且其值与正则表达式匹配的Cookie。
-
Header:需要两个参数header和regexp(正则表达式),也可以理解为Key和Value,匹配请求携带信息。
-
Host:匹配当前请求是否来自于设置的主机。
-
Method:可以设置一个或多个参数,匹配HTTP请求,比如GET、POST
-
Path:匹配指定路径下的请求,可以是多个用逗号分隔
-
Query:需要指定一个或者多个参数,一个必须参数和一个可选的正则表达式,匹配请求中是否包含第一个参数,如果有两个参数,则匹配请求中第一个参数的值是否符合正则表达式。
-
RemoteAddr:匹配指定IP或IP段,符合条件转发。
-
Weight:需要两个参数group和weight(int),实现了路由权重功能,按照路由权重选择同一个分组中的路由
Filter
路由过滤器允许以某种方式修改传入的 HTTP 请求或传出的 HTTP 响应。路由过滤器的范围是特定的路由。Spring Cloud Gateway 包含许多内置的 GatewayFilter 工厂。
内置Filter
-
GateWay内置的Filter生命周期为两种:pre(业务逻辑之前)、post(业务逻辑之后)
-
GateWay本身自带的Filter分为两种: GateWayFilter(单一)、GlobalFilter(全局)
-
单一的有32种,全局的有9种
-
官方网址:Spring Cloud Gateway
自定义Filter
要实现GateWay自定义过滤器,那么我们需要实现两个接口
-
GlobalFilter
-
Ordered
@Component@Slf4jpublic class MyFilter implements Ordered, GlobalFilter { /** * @param exchange 可以拿到对应的request和response * @param chain 过滤器链 * @return 是否放行 */ @Override public Mono filter(ServerWebExchange exchange, GatewayFilterChain chain) { String username = exchange.getRequest().getQueryParams().getFirst(\"username\"); log.info(\"*************MyFilter:\"+new Date()); if(username == null){ log.info(\"**********用户名为null,非法用户,请求被拒绝!\"); //如果username为空,返回状态码为406,不可接受的请求 exchange.getResponse().setStatusCode(HttpStatus.NOT_ACCEPTABLE); return exchange.getResponse().setComplete(); } return chain.filter(exchange); } /** * 加载过滤器的顺序 * @return 整数数字越小优先级越高 */ @Override public int getOrder() { return 0; }}实战分析
大麦的Gateway业务网关,主要承载了对接口的参数解密和验证签名、将解密后的请求体传递给业务服务、指定接口进行规则限制防刷、将返回的数据进行加密等操作。
根据pre和post区分, 参数解密、验证签名、防刷;post:返回数据加密。
限流?
Java限流的方案可以采用 信号量 semaphore 方式。
引用JUC并发工具-CountDownLatch、Semaphore、CyclicBarrier-CSDN博客
// 操作太频繁,请稍后再试if (!semaphore.tryAcquire(1, timeUnit)) { throw new DaMaiFrameException(BaseCode.OPERATION_IS_TOO_FREQUENT_PLEASE_TRY_AGAIN_LATER);}@Component@Slf4jpublic class RequestValidationFilter implements GlobalFilter, Ordered { @Override public Mono filter(final ServerWebExchange exchange, final GatewayFilterChain chain) { // 是否限流了,如果限流,那么我们需要进行获取资源-信号量 // RateLimiterProperty 本质上 是个配置类,里面有个 rateSwitch 字段,如果 rateSwitch 为 true 则表示开启限流功能 if (rateLimiterProperty.getRateSwitch()) { try { // 信号量 // rataLimiter.acquire() 阻塞式获取信号量,直到获取成功 rateLimiter.acquire(); return doFilter(exchange, chain); } catch (InterruptedException e) { log.error(\"interrupted error\", e); throw new DaMaiFrameException(BaseCode.THREAD_INTERRUPTED); } finally { // 释放信号量 rateLimiter.release(); } } else { return doFilter(exchange, chain); } }}接口防刷?
除了网关统一接口限流以外,还有某些特定接口限制,是通过Redis+Lua脚本实现的。
-- 是否需要进行限制local trigger_result = 0-- 是否进行保存记录local trigger_call_Stat = 0-- 请求数local api_count = 0-- 规则阈值local threshold = 0-- 规则对象local apiRule = cjson.decode(KEYS[1])-- 规则类型local api_rule_type = apiRule.apiRuleType-- 普通规则中要进行统计请求数local rule_key = apiRule.ruleKey-- 普通规则中进行统计的时间local rule_stat_time = apiRule.statTime-- 普通规则中进行统计的阈值local rule_threshold = apiRule.threshold-- 普通规则超过阈值后限制的时间local rule_effective_time = apiRule.effectiveTime-- 实现普通规则执行限制local rule_limit_key = apiRule.ruleLimitKey-- 进行统计超过普通规则的数量sorted set结构 score当前时间 member唯一值(当前时间_请求数)local z_set_key = apiRule.zSetRuleStatKey-- 当前时间local current_Time = apiRule.currentTime-- 定制的规则提示语索引local message_index = -1-- 请求数local count = tonumber(redis.call(\'incrby\', rule_key, 1))-- 第一次设置普通规则的统计时间if (count == 1) then redis.call(\'expire\', rule_key, rule_stat_time)end-- 如果在普通规则的统计时间下请求数超过了阈值if ((count - rule_threshold) >= 0) then -- 如果普通规则之前没有生效限制过或者限制已经失效 if (redis.call(\'exists\', rule_limit_key) == 0) then redis.call(\'set\', rule_limit_key, rule_limit_key) redis.call(\'expire\', rule_limit_key, rule_effective_time) -- 进行这一轮的初次限制要保存记录 trigger_call_Stat = 1 -- 每一轮发生初次限制保存到sorted set local z_set_member = current_Time .. \"_\" .. tostring(count) redis.call(\'zadd\',z_set_key,current_Time,z_set_member) end -- 发生了限制 trigger_result = 1end-- 普通规则还在生效限制中if (redis.call(\'exists\', rule_limit_key) == 1) then -- 发生了限制 trigger_result = 1endapi_count = countthreshold = rule_threshold-- 如果深度规则存在的话if (api_rule_type == 2) then -- 获取所有的深度规则 local depthRules = apiRule.depthRules -- 循环深度规则 for index,depth_rule in ipairs(depthRules) do -- 深度规则的开始时间范围 local start_time_window = depth_rule.startTimeWindowTimestamp -- 深度规则的结束时间范围 local end_time_window = depth_rule.endTimeWindowTimestamp -- 深度规则中进行统计的时间 local depth_rule_stat_time = depth_rule.statTime -- 深度规则中进行统计的阈值 local depth_rule_threshold = depth_rule.threshold -- 深度规则超过阈值后限制的时间 local depth_rule_effective_time = depth_rule.effectiveTime -- 实现深度规则执行限制 local depth_rule_limit_key = depth_rule.depthRuleLimit threshold = depth_rule_threshold -- 将当前时间之前的时间范围的普通规则统计清除掉,因为这些过期了 if (current_Time > start_time_window) then redis.call(\'zremrangebyscore\',z_set_key,0,start_time_window - 1000) end -- 如果当前时间在设置的时间范围内 if (current_Time >= start_time_window and current_Time depth_rule_stat_time * 1000) then z_set_min_score = current_Time - (depth_rule_stat_time * 1000) end -- 根据时间范围获得普通规则的限制数量 local rule_trigger_count = tonumber(redis.call(\'zcount\',z_set_key,z_set_min_score,z_set_max_score)) api_count = rule_trigger_count -- 如果统计的数量超过限制的话 if ((rule_trigger_count - depth_rule_threshold) >= 0) then -- 如果深度规则之前没有生效限制过或者限制已经失效 if (redis.call(\'exists\', depth_rule_limit_key) == 0) then redis.call(\'set\', depth_rule_limit_key, depth_rule_limit_key) redis.call(\'expire\', depth_rule_limit_key, depth_rule_effective_time) -- 发生了限制 trigger_result = 1 -- 进行这一轮的初次限制要保存记录 trigger_call_Stat = 2 -- 提示信息的索引值 message_index = index return string.format(\'{\"triggerResult\": %d, \"triggerCallStat\": %d, \"apiCount\": %d, \"threshold\": %d, \"messageIndex\": %d}\',trigger_result,trigger_call_Stat,api_count,threshold,message_index) end end -- 普通规则还在生效限制中 if (redis.call(\'exists\', depth_rule_limit_key) == 1) then -- 发生了限制 trigger_result = 1 -- 提示信息的索引值 message_index = index return string.format(\'{\"triggerResult\": %d, \"triggerCallStat\": %d, \"apiCount\": %d, \"threshold\": %d, \"messageIndex\": %d}\',trigger_result,trigger_call_Stat,api_count,threshold,message_index) end end endendreturn string.format(\'{\"triggerResult\": %d, \"triggerCallStat\": %d, \"apiCount\": %d, \"threshold\": %d, \"messageIndex\": %d}\',trigger_result,trigger_call_Stat,api_count,threshold,message_index)参数解密、验证签名?
/** * 生成链路调用id * 如果是json请求则进行参数验证 * 判断是否跳过参数验证 * 根据渠道code获得秘钥相关参数 * 如果是v2加密版本则要根据RSA的私钥进行解密 * 进行签名验证 * 判断是否需要验证登录 * 根据规则对api接口进行防刷限制 * 将修改后的请求体和生成要添加请求头的数据传递给业务服务 * * @param exchange * @param chain * @return */public Mono doFilter(final ServerWebExchange exchange, final GatewayFilterChain chain) { ServerHttpRequest request = exchange.getRequest(); // 链路ID String traceId = request.getHeaders().getFirst(TRACE_ID); //灰度标识 String gray = request.getHeaders().getFirst(GRAY_PARAMETER); // 是否验证参数 String noVerify = request.getHeaders().getFirst(NO_VERIFY); // 如果请求链路ID不存在,则生成一个新的ID if (StringUtil.isEmpty(traceId)) { traceId = String.valueOf(uidGenerator.getUid()); } //将链路id放到日志的MDC中便于日志输出 MDC.put(TRACE_ID, traceId); Map headMap = new HashMap(8); headMap.put(TRACE_ID, traceId); headMap.put(GRAY_PARAMETER, gray); if (StringUtil.isNotEmpty(noVerify)) { headMap.put(NO_VERIFY, noVerify); } // 将链路ID和灰度标识放入BaseParameterHolder中 ThreadLocal BaseParameterHolder.setParameter(TRACE_ID, traceId); BaseParameterHolder.setParameter(GRAY_PARAMETER, gray); MediaType contentType = request.getHeaders().getContentType(); //application json请求 if (Objects.nonNull(contentType) && contentType.toString().toLowerCase().contains(MediaType.APPLICATION_JSON_VALUE.toLowerCase())) { // 如果是json则进行参数验证 return readBody(exchange, chain, headMap); } else { // 如果没有json请求,则直接放行 Map map = doExecute(\"\", exchange); map.remove(REQUEST_BODY); map.putAll(headMap); request.mutate().headers(httpHeaders -> { map.forEach(httpHeaders::add); }); return chain.filter(exchange); }}/** * 具体进行参数验证的逻辑 * * @param originalBody * @param exchange * @return */private Map doExecute(String originalBody, ServerWebExchange exchange) { log.info(\"current thread verify: {}\", Thread.currentThread().getName()); ServerHttpRequest request = exchange.getRequest(); // 得到请求体 String requestBody = originalBody; Map bodyContent = new HashMap(32); if (StringUtil.isNotEmpty(originalBody)) { // 解析请求体,转化为map结构 bodyContent = JSON.parseObject(originalBody, Map.class); } // 基础参数Code 渠道 String code = null; // 用户的token String token; // 用户的UserId String userId = null; // 请求的地址 String url = request.getPath().value(); // 是否跳过参数验证 String noVerify = request.getHeaders().getFirst(NO_VERIFY); // 是否允许跳过参数验证? boolean allowNormalAccess = gatewayProperty.isAllowNormalAccess(); if ((!allowNormalAccess) && (VERIFY_VALUE.equals(noVerify))) { throw new DaMaiFrameException(BaseCode.ONLY_SIGNATURE_ACCESS_IS_ALLOWED); } // 是否跳过 参数验证 if (checkParameter(originalBody, noVerify) && !skipCheckParameter(url)) { String encrypt = request.getHeaders().getFirst(ENCRYPT); //应用渠道 code = bodyContent.get(CODE); //token token = request.getHeaders().getFirst(TOKEN); //验证code参数并获取基础参数 GetChannelDataVo channelDataVo = channelDataService.getChannelDataByCode(code); //如果v2版本就要先对参数进行解密 if (StringUtil.isNotEmpty(encrypt) && V2.equals(encrypt)) { //使用rsa私钥进行解密 String decrypt = RsaTool.decrypt(bodyContent.get(BUSINESS_BODY), channelDataVo.getDataSecretKey()); //将解密后的请求体替换加密的请求体 bodyContent.put(BUSINESS_BODY, decrypt); } //进行签名验证 boolean checkFlag = RsaSignTool.verifyRsaSign256(bodyContent, channelDataVo.getSignPublicKey()); if (!checkFlag) { throw new DaMaiFrameException(BaseCode.RSA_SIGN_ERROR); } //判断是否跳过验证登录的token //默认注册和登录接口跳过验证 boolean skipCheckTokenResult = skipCheckToken(url); if (!skipCheckTokenResult && StringUtil.isEmpty(token)) { ArgumentError argumentError = new ArgumentError(); argumentError.setArgumentName(token); argumentError.setMessage(\"token参数为空\"); List argumentErrorList = new ArrayList(); argumentErrorList.add(argumentError); throw new ArgumentException(BaseCode.ARGUMENT_EMPTY.getCode(), argumentErrorList); } //获取用户id if (!skipCheckTokenResult) { UserVo userVo = tokenService.getUser(token, code, channelDataVo.getTokenSecret()); userId = userVo.getId(); } //如果上一步没有获取到用户id,并且此url在有token情况下还需要解析出userid, //那么就再解析一遍token if (StringUtil.isEmpty(userId) && checkNeedUserId(url) && StringUtil.isNotEmpty(token)) { UserVo userVo = tokenService.getUser(token, code, channelDataVo.getTokenSecret()); userId = userVo.getId(); } requestBody = bodyContent.get(BUSINESS_BODY); } // 根据规则对api接口进行防刷限制 apiRestrictService.apiRestrict(userId, url, request); // 将请求体和相关参数放入map中 Map map = new HashMap(4); map.put(REQUEST_BODY, requestBody); if (StringUtil.isNotEmpty(code)) { map.put(CODE, code); } if (StringUtil.isNotEmpty(userId)) { map.put(USER_ID, userId); } return map;}

