搜索引擎Elasticsearch入门——学习笔记_elasticsearch学习
第一章 初识ES
第一节 认识
官网地址: Elastic — 搜索 AI 公司 | Elastic
elasticsearch具备下列优势:支持分布式,可水平扩展;提供Restful接口,可被任何语言调用
elasticsearch结合kibana、Logstash、Beats,是一整套技术栈,被叫做ELK。被广泛应用在日志数据分析、实时监控等地方。

第二节 安装
一 安装单机版ES
通过网盘分享的文件:ES1.zip
链接: https://pan.baidu.com/s/1F4B8rFs_vaDfoFSLA8K8mQ 提取码: 7q55
将提供的包拉取到虚拟机的指定目录上,然后在该目录下,运行
docker load -i es.tardocker load -i kibana.tar然后运行下面的指令创建单机版的容器
docker run -d \\ --name es \\ -e \"ES_JAVA_OPTS=-Xms512m -Xmx512m\" \\ -e \"discovery.type=single-node\" \\ -v es-data:/usr/share/elasticsearch/data \\ -v es-plugins:/usr/share/elasticsearch/plugins \\ --privileged \\ --network hm-net \\ -p 9200:9200 \\ -p 9300:9300 \\ elasticsearch:7.12.1访问一下:http://192.168.233.100:9200/(记得改成自己的ip)
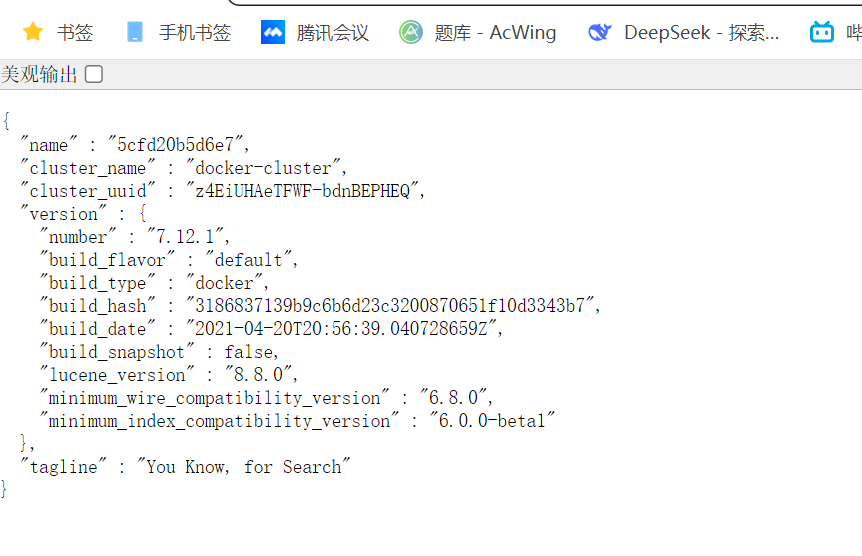
可以访问到就部署成功了
二 安装Kibana
这个是图形化工具,可以方便我们操作ES,jar包在上一节分享的文件里,导入jar包然后load
然后执行下面的docker run:
docker run -d \\--name kibana \\-e ELASTICSEARCH_HOSTS=http://es:9200 \\--network=hm-net \\-p 5601:5601 \\kibana:7.12.1访问网址:http://192.168.233.100:5601/
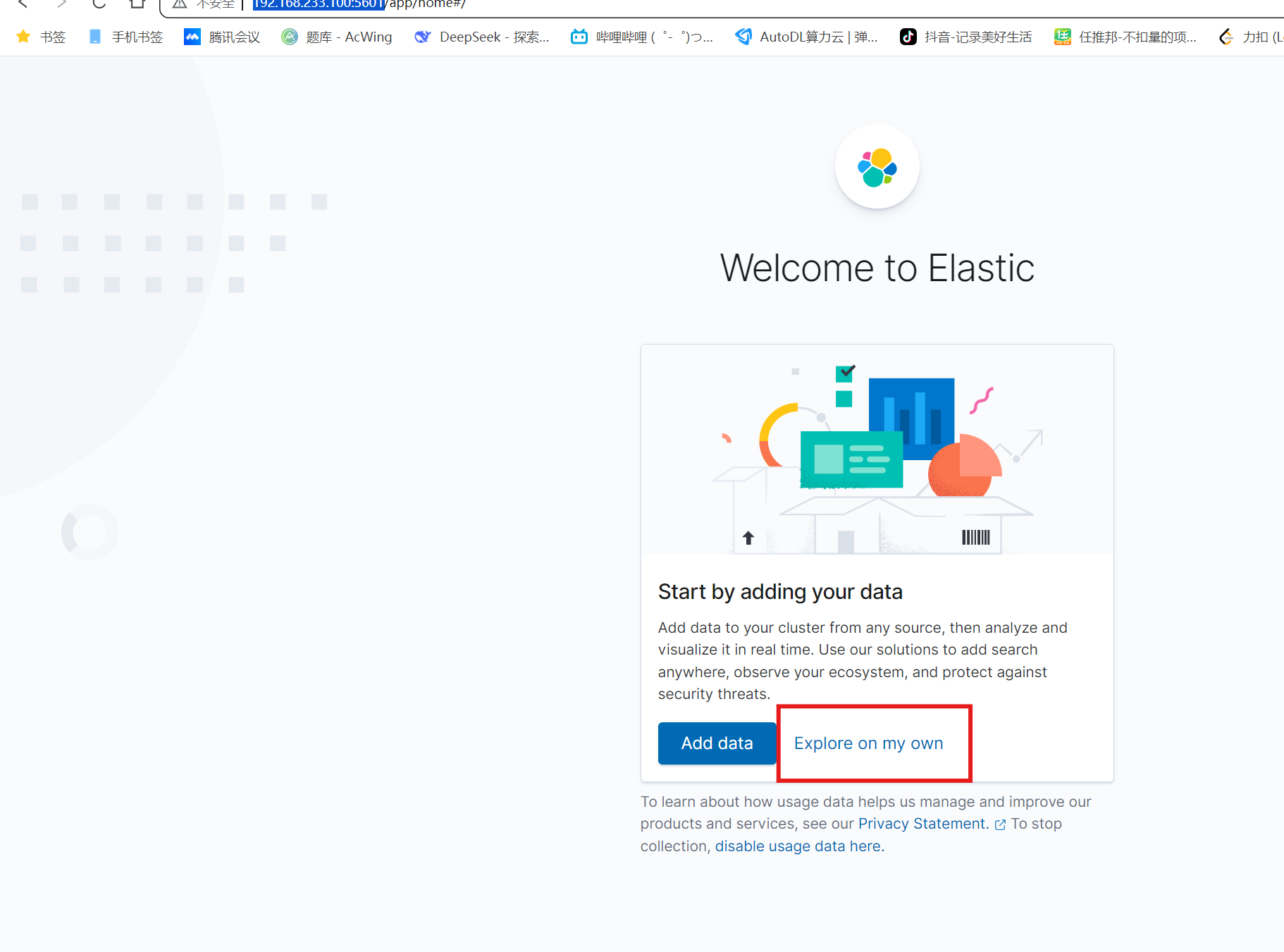
出现上面页面就表示部署成功!——可以点击红框内的选项进入页面
第三节 倒排索引
传统数据库在存储时,可以给每个数据建立索引id,通过id快速查询信息。但是如果要对数据进行模糊查询(比如我们搜索东西),那么数据库就只能逐条查询,从头查到尾了。
而倒排索引不一样,除了给每条数据增加索引之外,还会根据语义提取出词语建立一个词语文档,如下:——然后再给词语建立索引

搜索的时候:——因为词条表也会建立索引,所以分词后的搜索会非常快。通过索引查出数据表的索引,两次搜索全是根据索引搜索,效率会高很多!
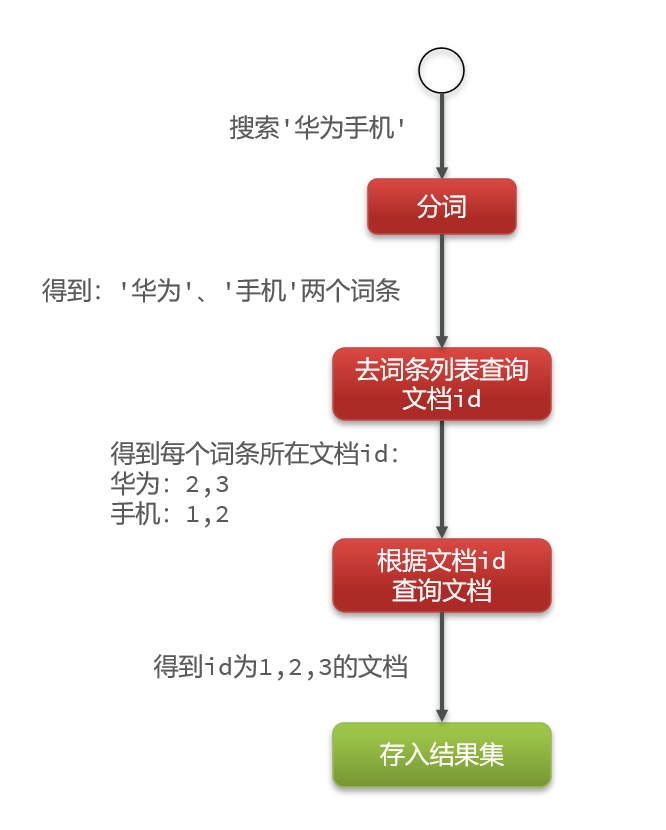
第四节 IK分词器
一 部署
英文的句子天生就有空格,分词容易。但是中文分词往往需要根据语义分析,比较复杂,这就需要用到中文分词器,例如IK分词器。(所以分词器最好选用国人做的)IK分词器是林良益在2006年开源发布的,其采用的正向迭代最细粒度切分算法一直沿用至今。
其安装的方式也比较简单,只要将资料提供好的分词器放入elasticsearch的插件目录即可:
官网:https://github.com/medcl/elasticsearch-analysis-ik/releases/download
可以选择在线安装:
docker exec -it es ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip//重启es容器docker restart es这边我就选择离线安装了,找到我下面资料里的ik文件夹
通过网盘分享的文件:elasticsearch-analysis-ik-7.12.1.zip
链接: https://pan.baidu.com/s/1Veh4a4cxwV9EOzqb1inx3A 提取码: eu5e
输入:——es-plugins在docker run的时候就已经挂载了
docker volume inspect es-plugins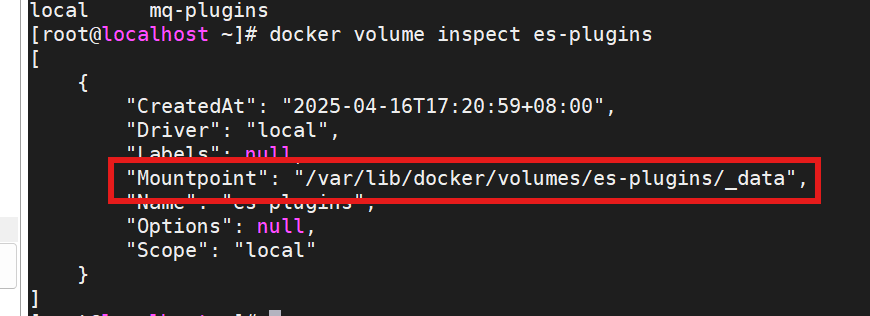
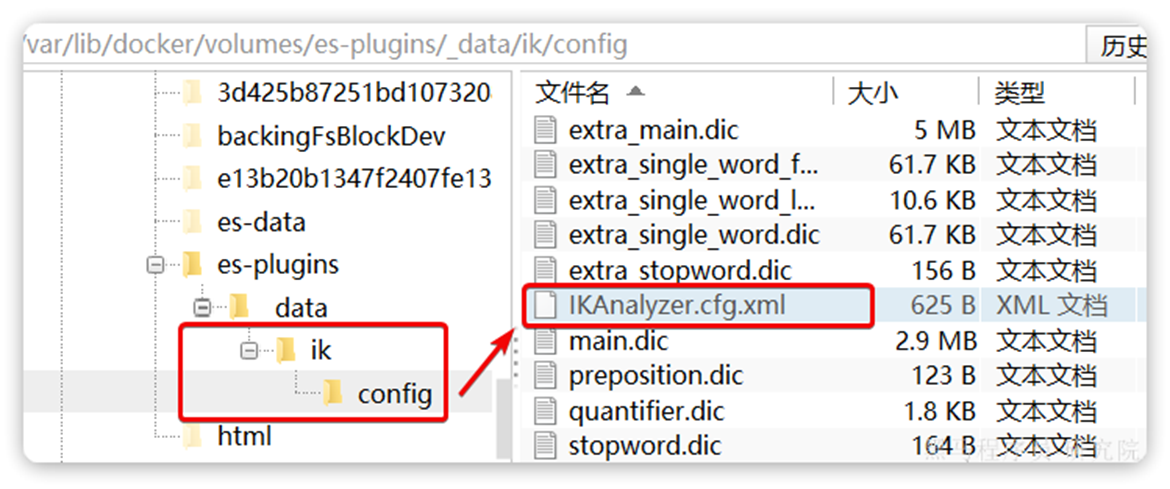
复制这段,利用ssh打开到这个地方——然后把整个目录拖进去
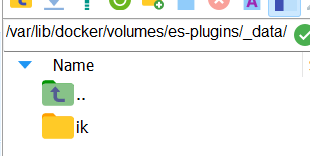
如果你和我一样也使用MobaXterm_Personal,那么只需要 cd /var/lib/docker/volumes/es-plugins/_data,,然后点击左下角的:——就可以打开到这个目录,然后把文件拉进去就行
然后重启容器就行
docker restart es二 测试
点开http://192.168.233.100:5601/,选择Explore on my own,进入主页面,点击右上角Devtool
左侧区域可以写发送的请求,点击右侧倒三角就可以发送
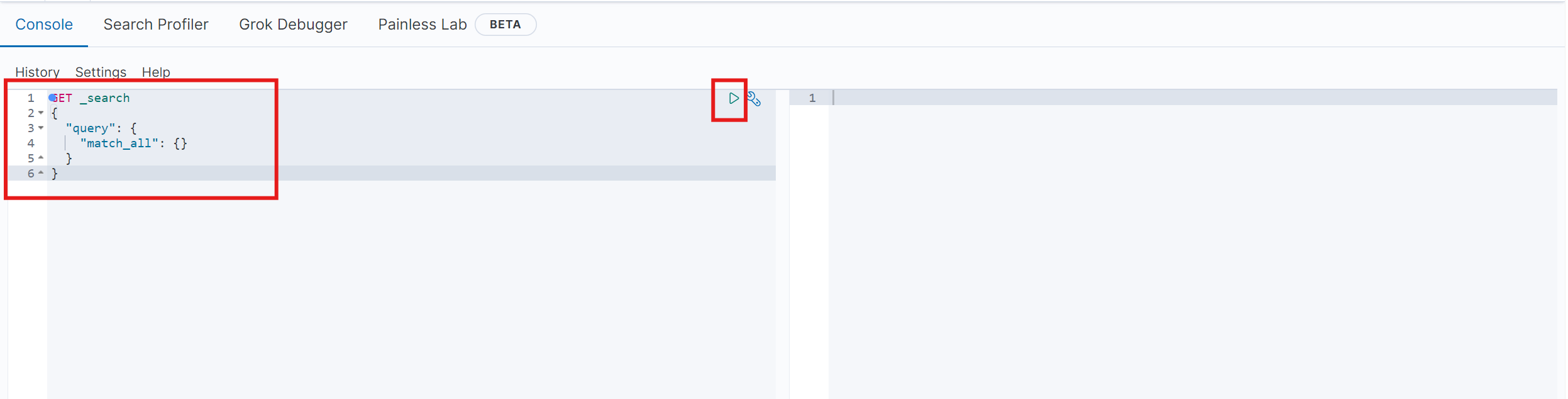
把下面这段复制到左侧,点击倒三角——analyzer就是分词器
POST /_analyze{ \"analyzer\": \"standard\", \"text\": \"程序员学习java真的是太棒了\"}这就是基础的分词器,分英文好使,分中文只能一个字一个字分
我们可以更换成我们导入的分词器ik
POST /_analyze{ \"analyzer\": \"ik_smart\", \"text\": \"程序员学习java真的是太棒了\"}结果如下:
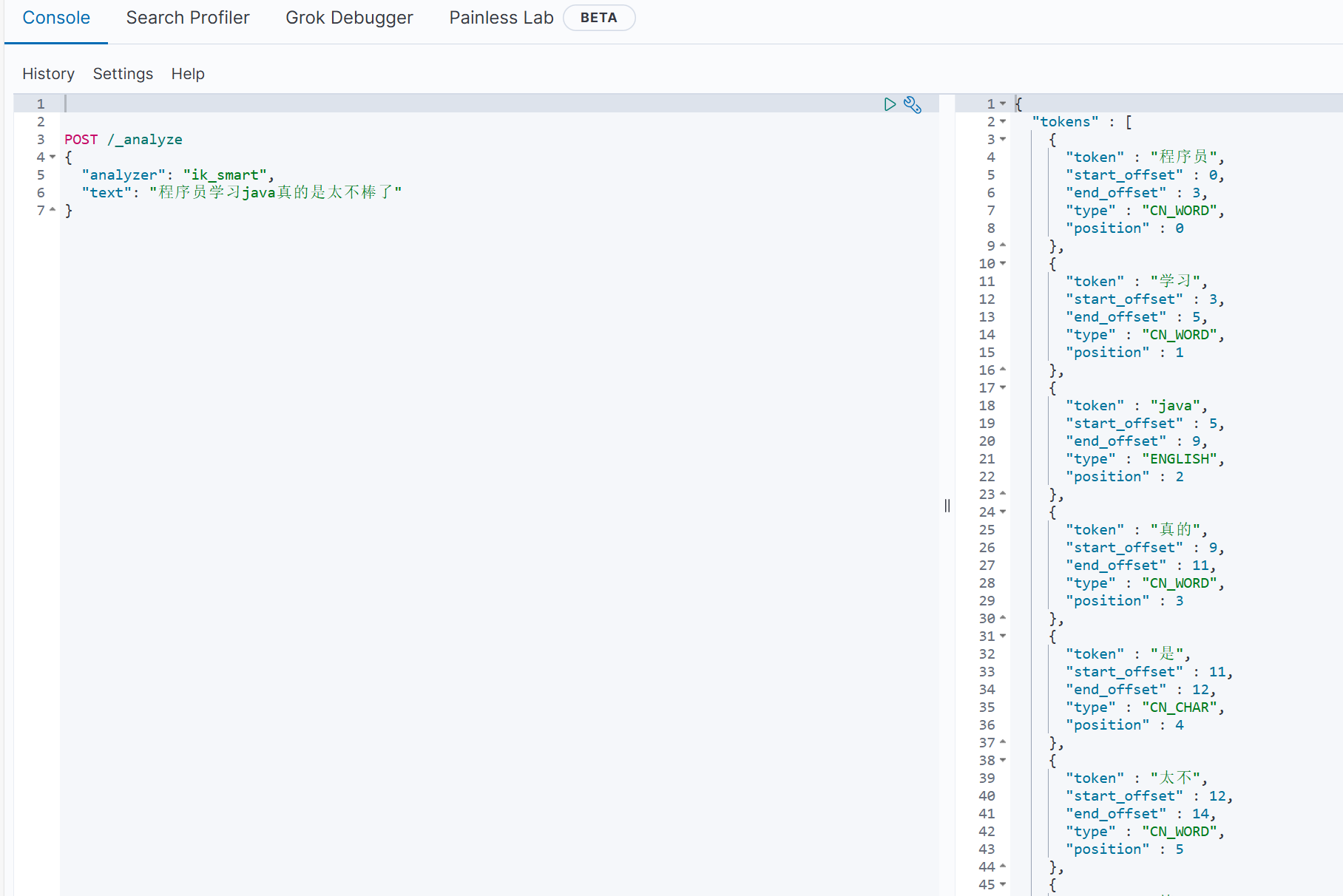
ik分词器有两种模式:
ik_smart:粗粒度的,一般选择这个
ik_max_word:细粒度的,比如程序员这个词语,就会分成程序员,程序两个词
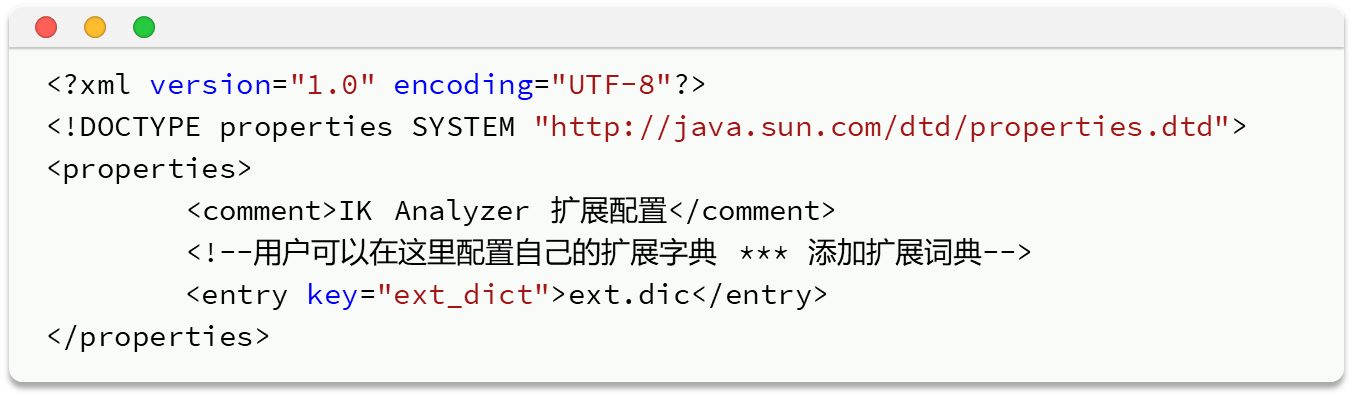
ik也可以增加词典来保持它的使用性
第五节 ES的概念
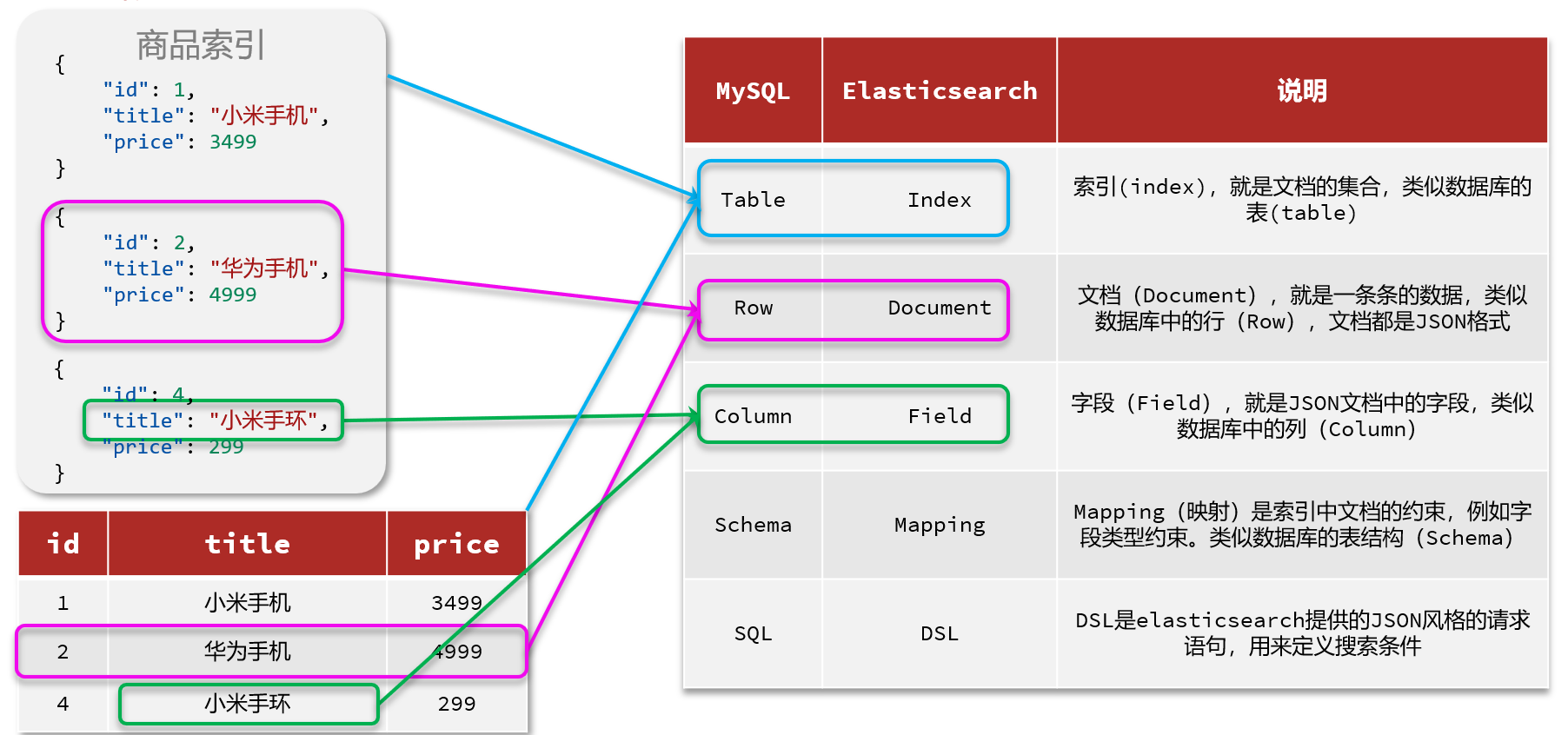
第二章 索引库和文档操作
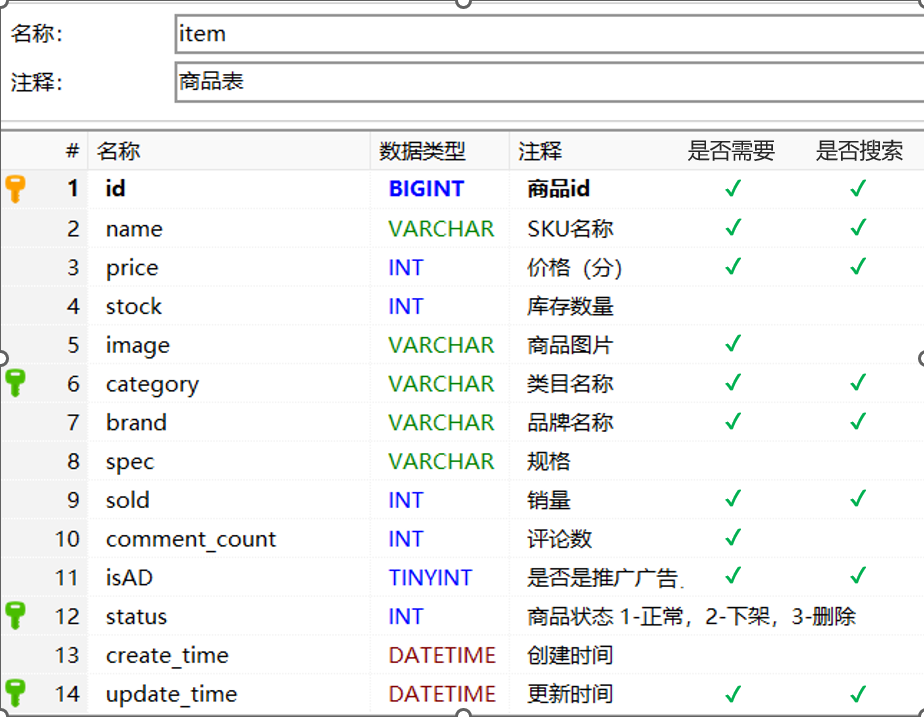
第一节 Mapping映射

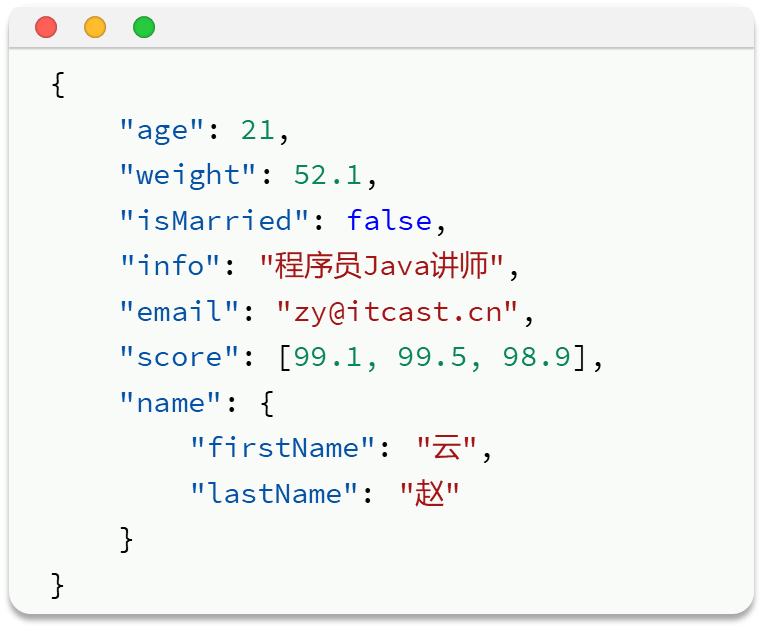
像下面这个JSON,第一个可以用byte,第二个float,第三个text,第四个keyword(邮箱分词没意义),score(注意,多个JSON排序的时候,如果是升序,就会选出数组中最小的来排,降序就会选出最大的排)——是否创建索引一般取决于是否需要搜索和排序
注意,在mapping映射中,id一般是keyword
第二节 操作索引库
对索引库的CRUD操作,要满足Restful风格的接口规范
下面是创建索引库的示例:

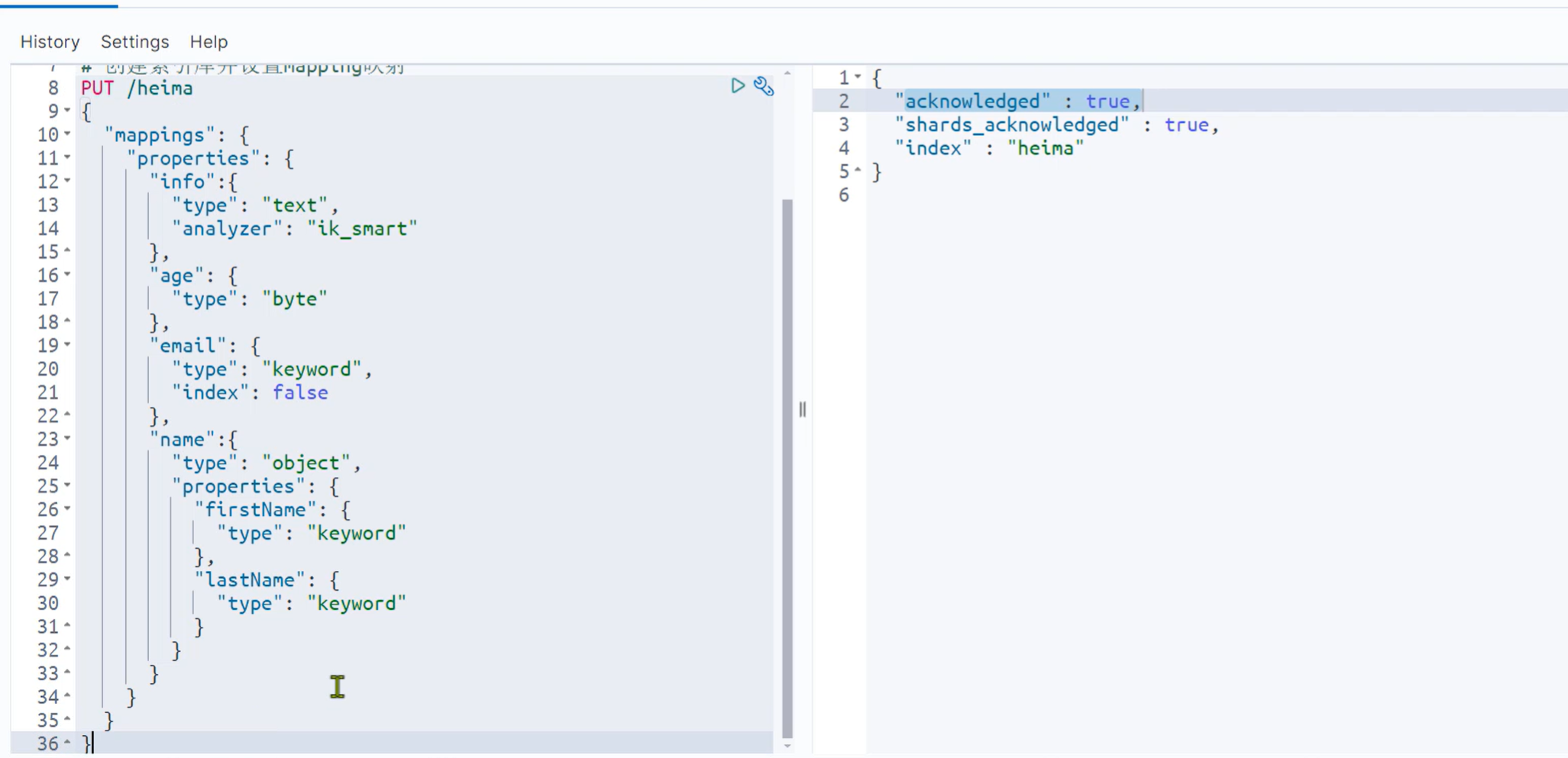
其他操作:
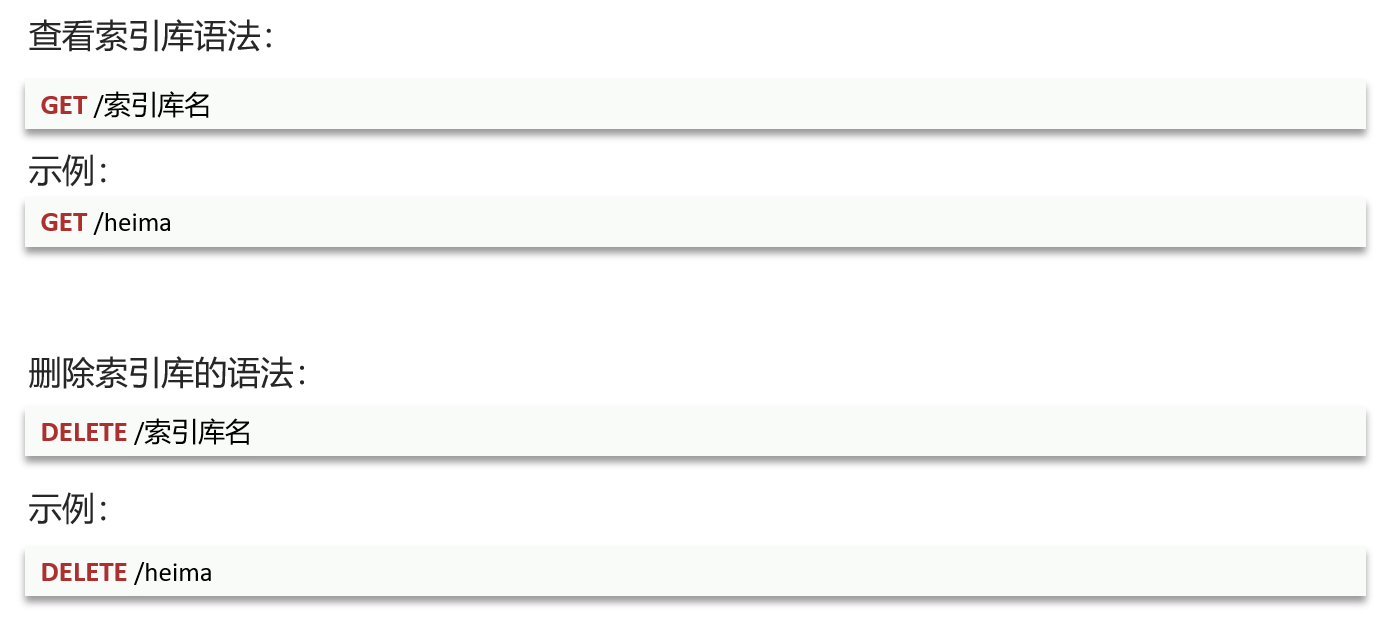

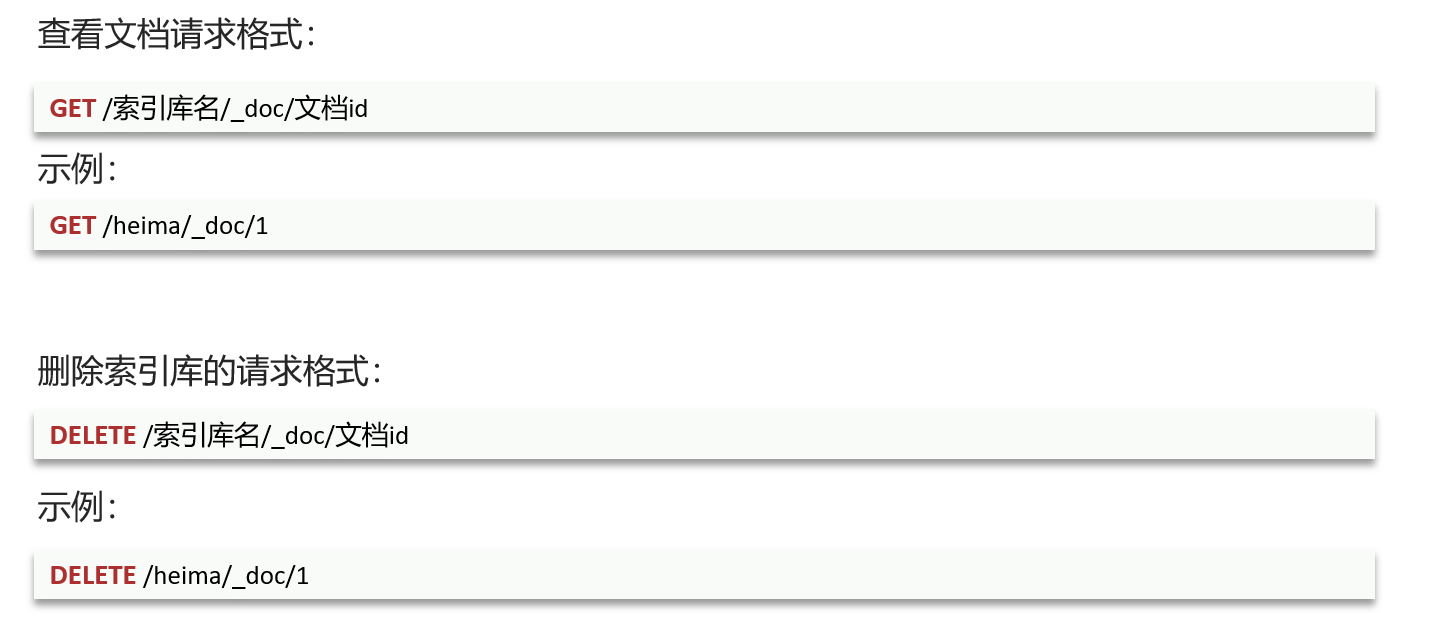
第三节 文档操作
一 CRUD
新增文档:——注意,要自己指定文档id,否则它会随机生成一个。未来操作就会很麻烦

编写代码的时候,可以使用右侧的工具来实现自动排版
修改有两种方式:——方式一如果写错了文档id,那么会新增一个文档

二 批量操作
批量新增:
POST /_bulk{\"index\": {\"_index\":\"heima\", \"_id\": \"3\"}}{\"info\": \"黑马程序员C++讲师\", \"email\": \"ww@itcast.cn\", \"name\":{\"firstName\": \"五\", \"lastName\":\"王\"}}{\"index\": {\"_index\":\"heima\", \"_id\": \"4\"}}{\"info\": \"黑马程序员前端讲师\", \"email\": \"zhangsan@itcast.cn\", \"name\":{\"firstName\": \"三\", \"lastName\":\"张\"}}批量删除:
POST /_bulk{\"delete\":{\"_index\":\"heima\", \"_id\": \"3\"}}{\"delete\":{\"_index\":\"heima\", \"_id\": \"4\"}}批量修改:
POST _bulk{ \"update\" : {\"_id\" : \"1\", \"_index\" : \"test\"} }{ \"doc\" : {\"field2\" : \"value2\"} }第三章 客户端JavaRestClient
目前JavaRestClient已经属于低级旧版客户端了,新版本8以上的和下面几乎完全不同
官方文档地址:Elasticsearch Clients | Elastic
第一节 客户端初始化
一 引入依赖
org.elasticsearch.client elasticsearch-rest-high-level-client二 覆盖版本
SpringBoot默认的ES版本是7.17.0,根据项目实际情况我们需要覆盖默认的ES版本
11 11 7.12.1 三 初始化RestHighLevelClient:——有多个ES地址,就写多个HttpHost,用逗号分隔
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder( HttpHost.create(\"http://192.168.233.100:9200\")));第二节 Mapping映射字段选择
一般不能照搬数据库的字段,而是要根据页面选择,以下面为例子
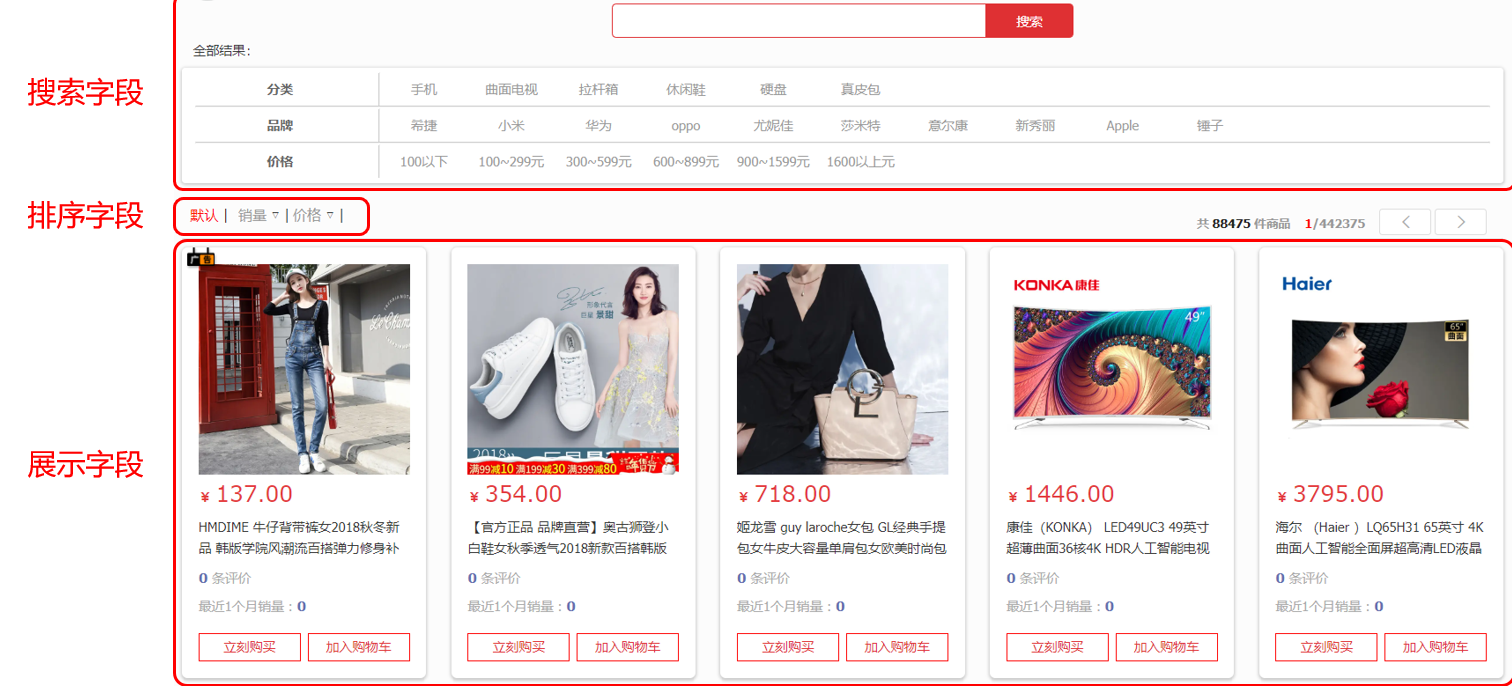
注意,在mapping映射中,id一般是keyword
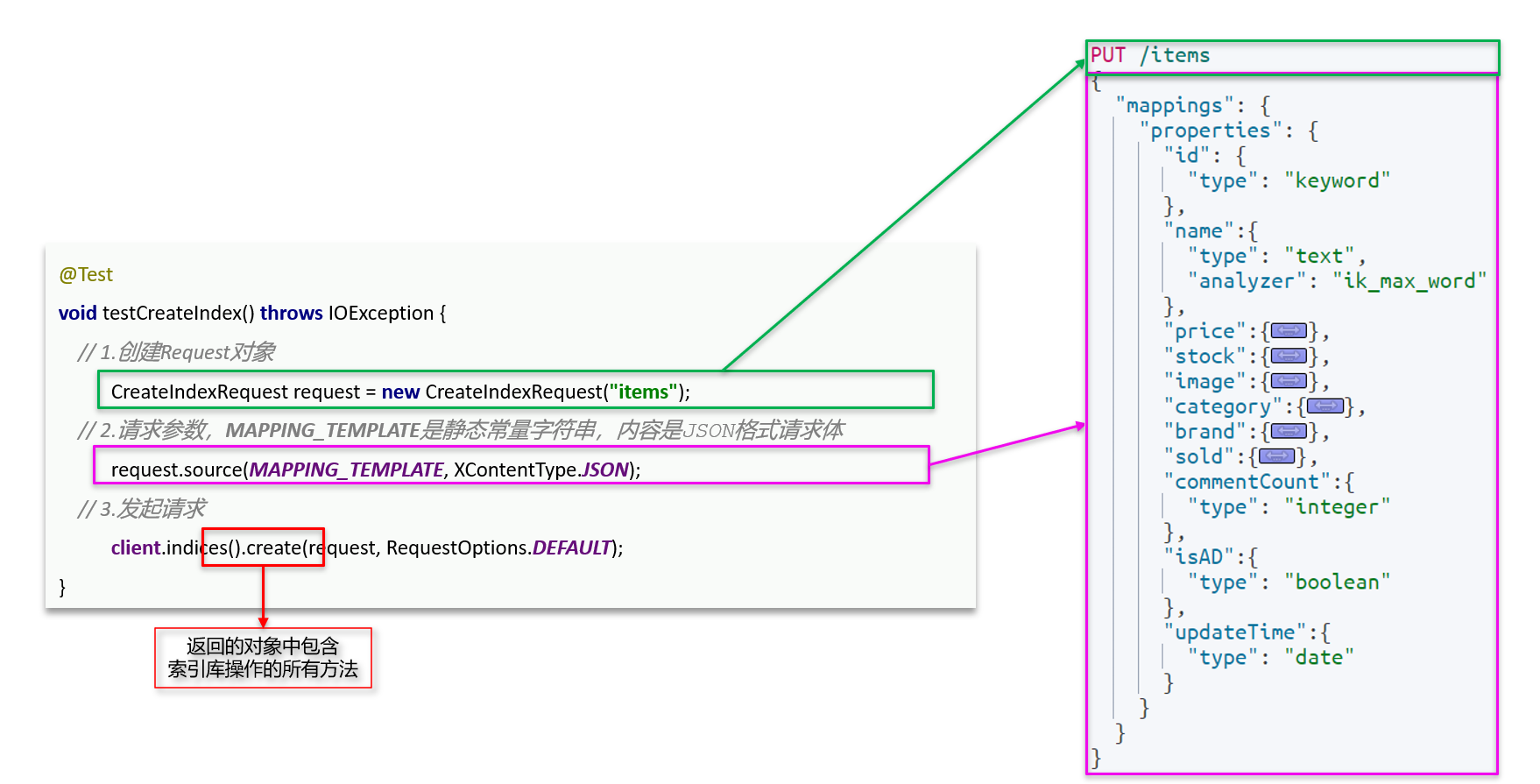
第三节 索引库操作
创建索引库:——先创建request对象,然后调用source传递参数(MAPPING_TEMPLATE就是我们右侧的JSON参数),最后调用indices().create方法
删除索引库:

查询索引库:

如果只是想判断索引库是否存在,那么调用exists方法就行

第四节 操作文档
一 新增文档
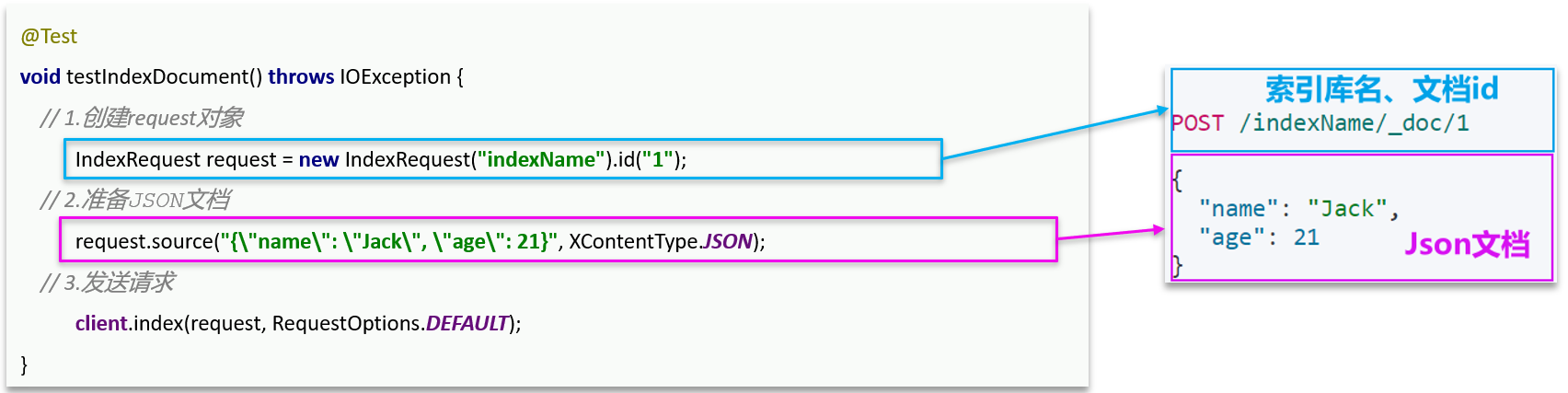
实际使用:——先从数据库查出实体,再转换成我们符合我们索引库映射的实体,使用hutool的JSONUtil工具把对象转成JSON
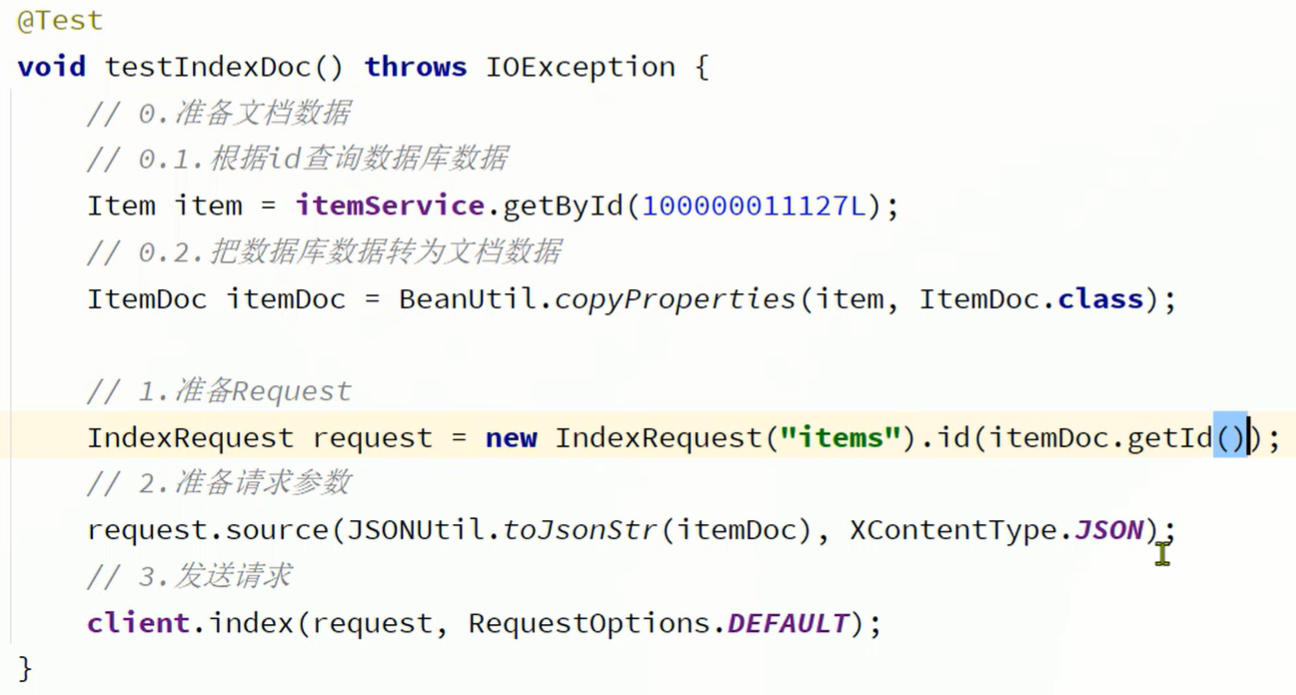
二 删除文档

三 查询文档
——多了一步结果解析,只需要source对象
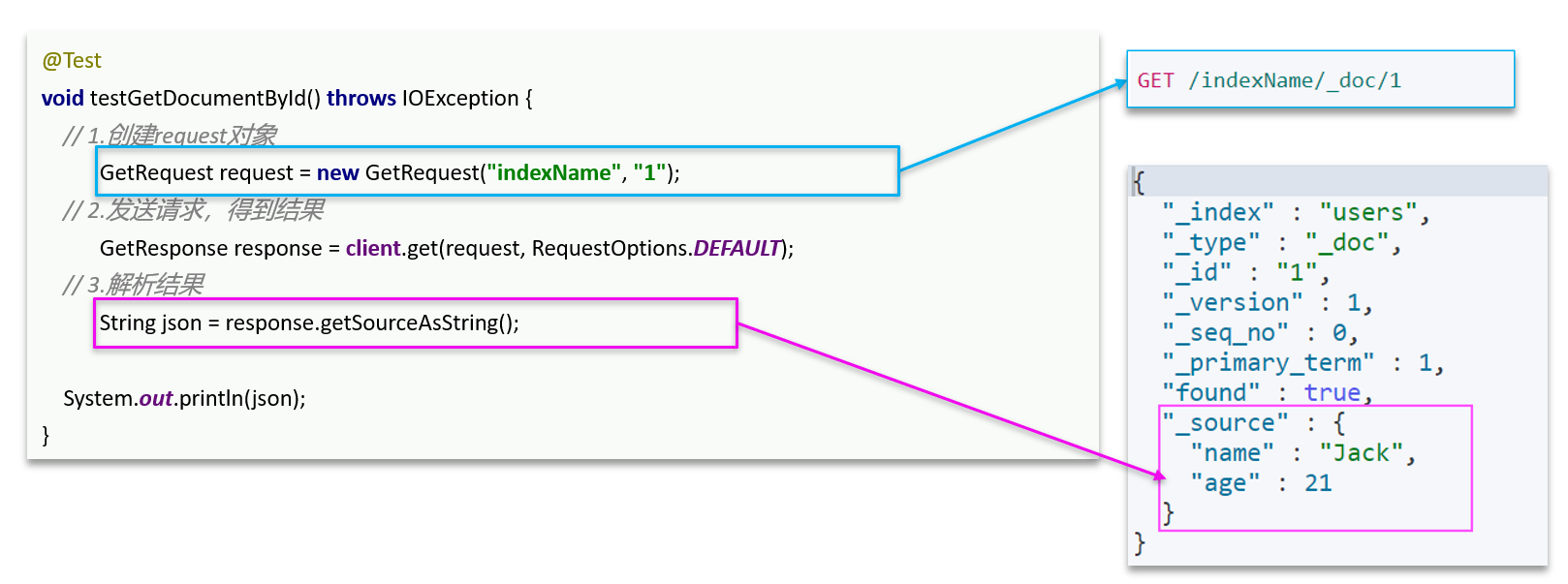
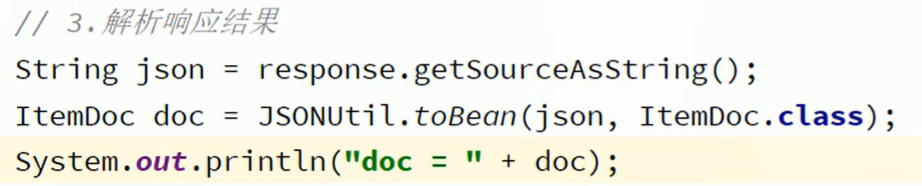
不过获取的source对象也只是一个JSON,要把它转换成我们需要的实体——可以使用hutool工具
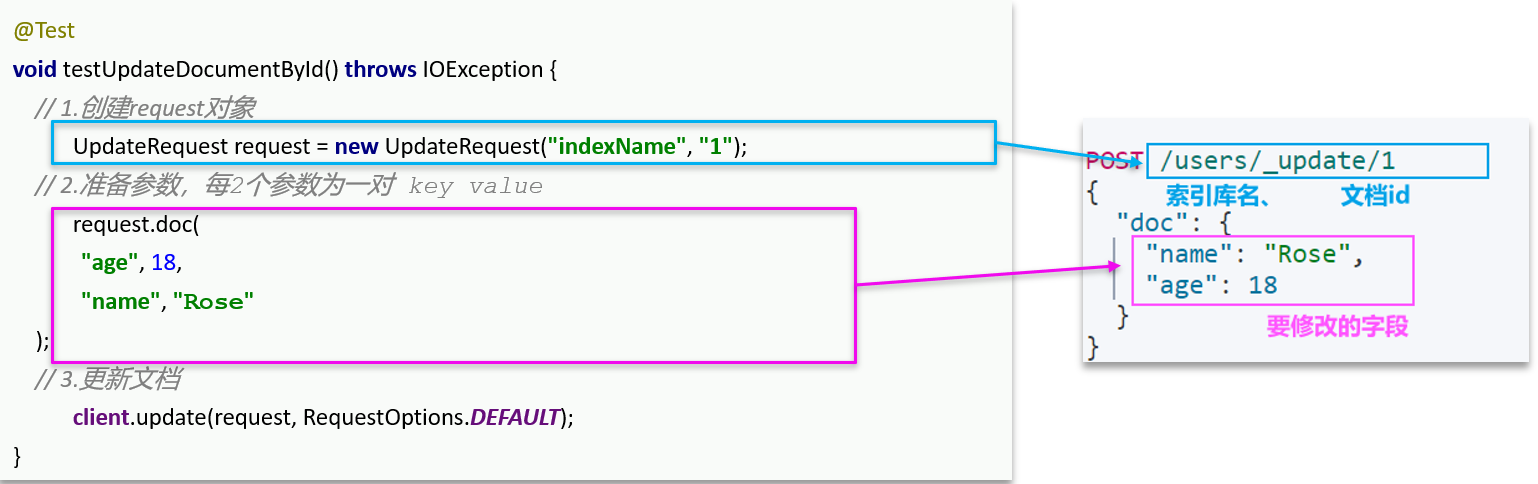
四 修改文档
方式一:全量更新。再次写入id一样的文档,就会删除旧文档,添加新文档。与新增的JavaAPI一致!!!
方式二:局部更新。只更新指定部分字段。
五 批处理
批处理代码流程与之前类似,只不过构建请求会用到一个名为BulkRequest来封装普通的CRUD请求:
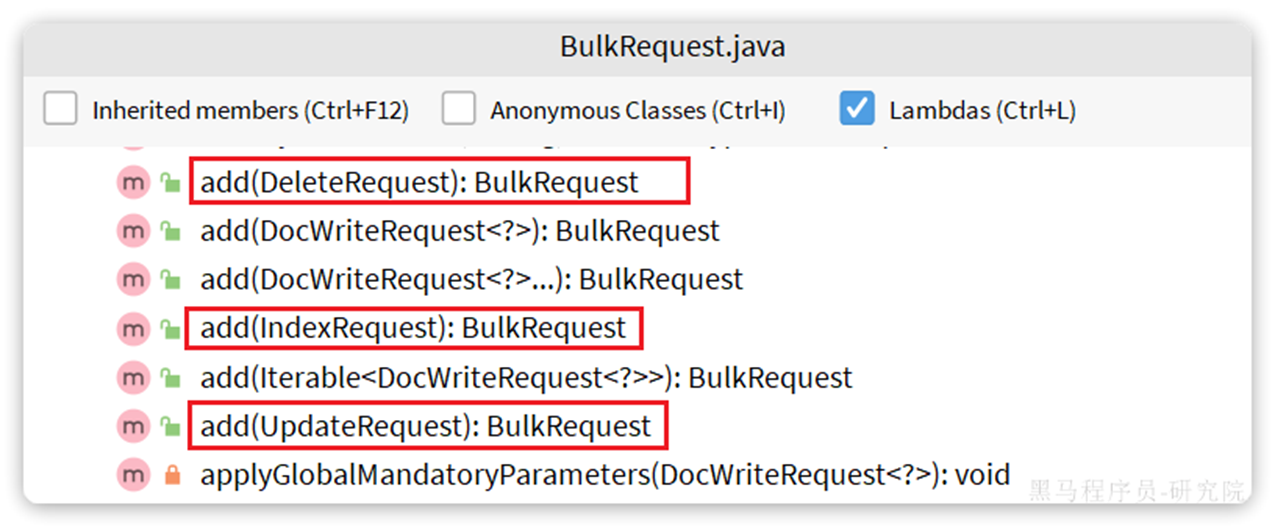
批量新增示例:

实际处理业务示例如下:——不能使用list,一次性查太多了会把内存爆了,应该分页一页一页查
@Testvoid testLoadItemDocs() throws IOException { // 分页查询商品数据 int pageNo = 1; int size = 1000; while (true) { Page page = itemService.lambdaQuery().eq(Item::getStatus, 1).page(new Page(pageNo, size)); // 非空校验 List items = page.getRecords(); if (CollUtils.isEmpty(items)) { return; } log.info(\"加载第{}页数据,共{}条\", pageNo, items.size()); // 1.创建Request BulkRequest request = new BulkRequest(\"items\"); // 2.准备参数,添加多个新增的Request for (Item item : items) { // 2.1.转换为文档类型ItemDTO ItemDoc itemDoc = BeanUtil.copyProperties(item, ItemDoc.class); // 2.2.创建新增文档的Request对象 request.add(new IndexRequest() .id(itemDoc.getId()) .source(JSONUtil.toJsonStr(itemDoc), XContentType.JSON)); } // 3.发送请求 client.bulk(request, RequestOptions.DEFAULT); // 翻页 pageNo++; }}第四章 DSL查询语法

第一节 快速入门
查询全部信息
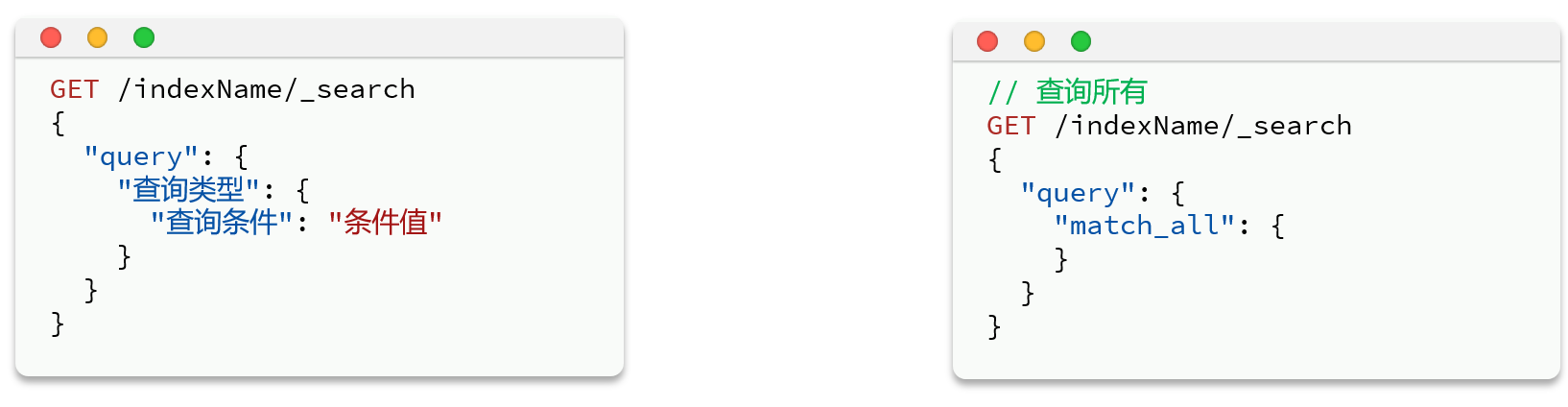
返回值分析:
took——耗时;timed_out——是否超时;_shards——跟集群相关;hits——数据总体
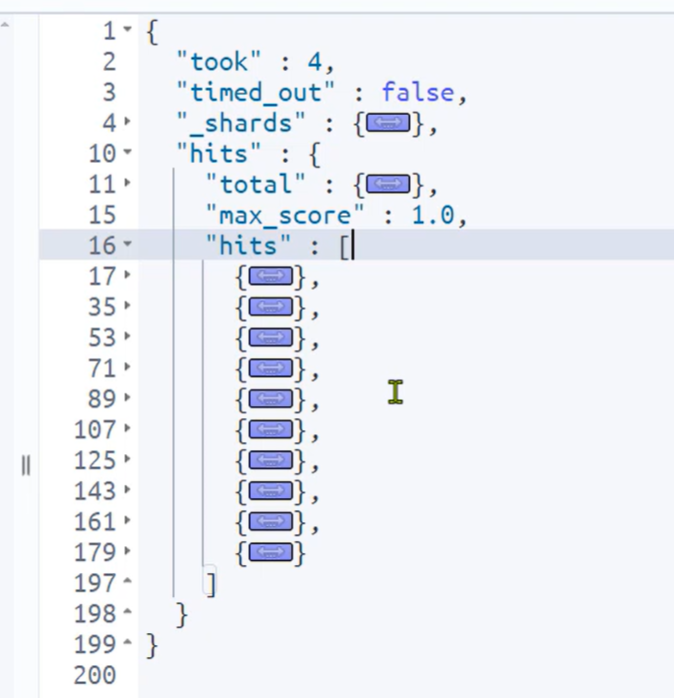
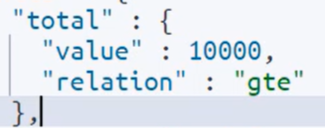
hits之下还有几个:total——总数(最大10000,relation的“gte”是大于等于的意思,即总数大于等于10000);max_score——类似于匹配度;hits——数据,默认单词最多返回10条
第二节 叶子查询
叶子查询还可以进一步细分,常见的有:
全文检索:利用分词器对用户输入内容分词,然后去词条列表中匹配。例如:match_query;multi_match_query
精确查询:不对用户输入内容分词,直接精确匹配,一般是查找keyword、数值、日期、布尔等类型。例如:ids,range,term
地理查询:用于搜索地理位置,搜索方式很多。例如:geo_distance,geo_bounding_box
一 全文检索
match查询:全文检索查询的一种,会对用户输入内容分词,然后去倒排索引库检索,语法:
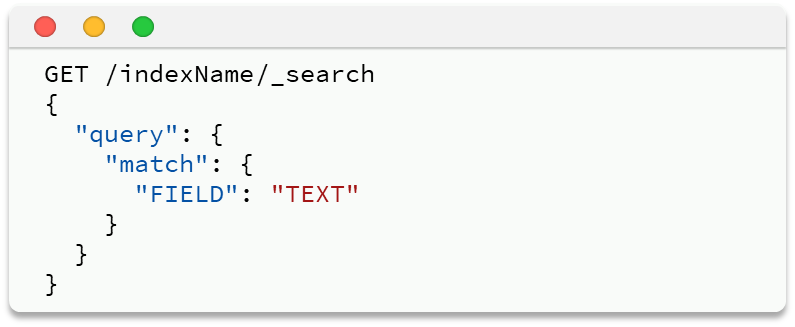
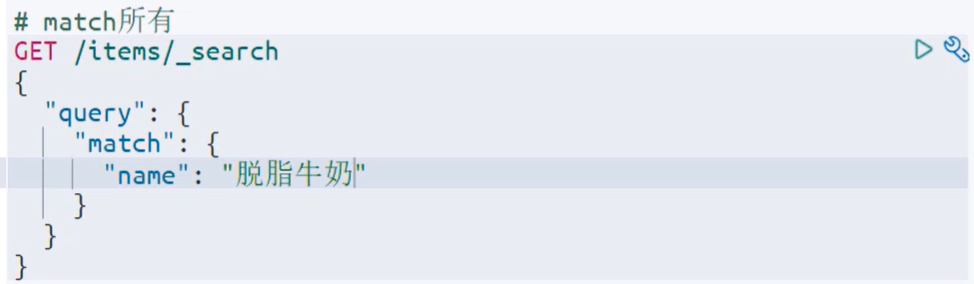
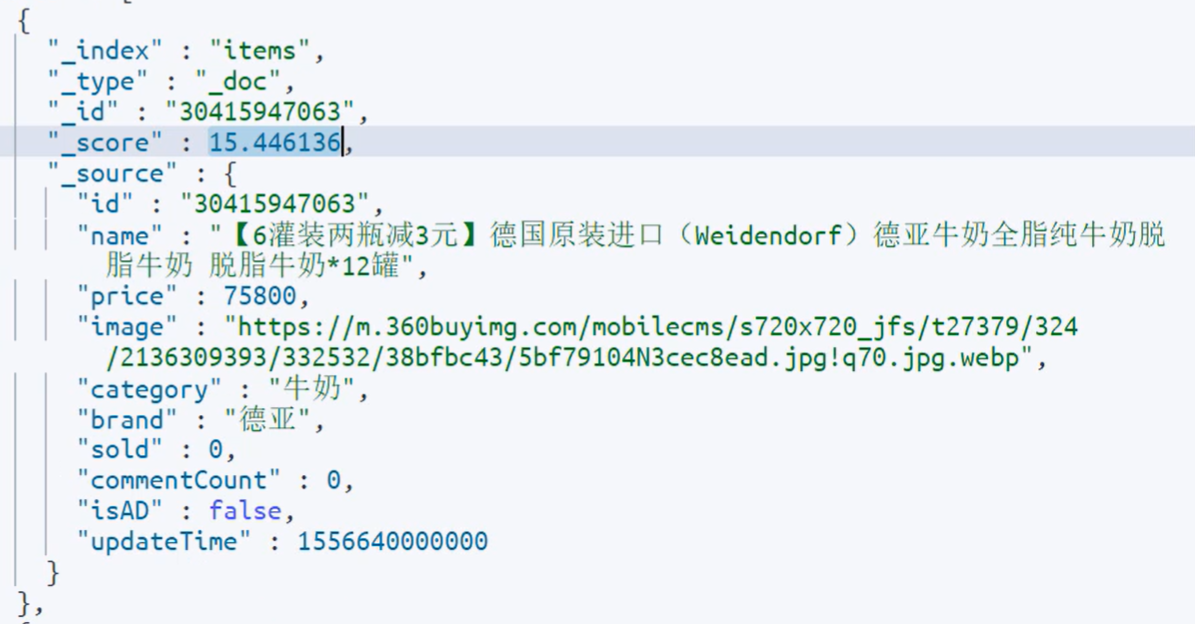
返回值会按照匹配分数排序,分数高的排前面
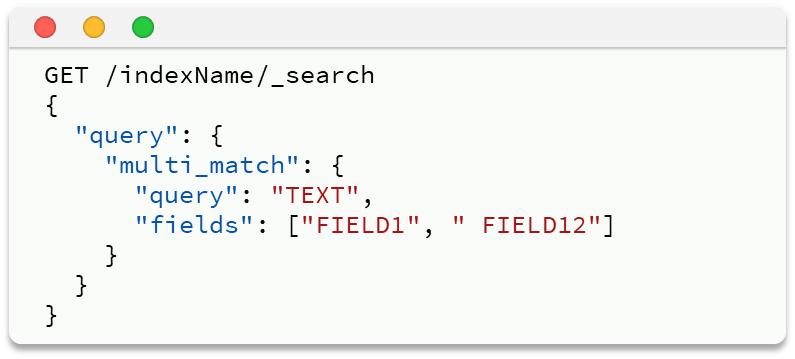
multi_match:与match查询类似,只不过允许同时查询多个字段,语法:——多个字段进行分词查询,FIELD1/FIELD2就是查询字段,query就是查询内容(字段越多,性能越差)
二 精确搜索
term查询:——按照keyword查询
注意,它不会对你的value进行分词,也就是说如果你搜索的是“脱脂牛奶”,在全文搜索里会把这个词语拆成“脱脂”和“牛奶”分别进行查询,但是这里不会,而词典里很可能没有这个词语,那就查不到数据了。
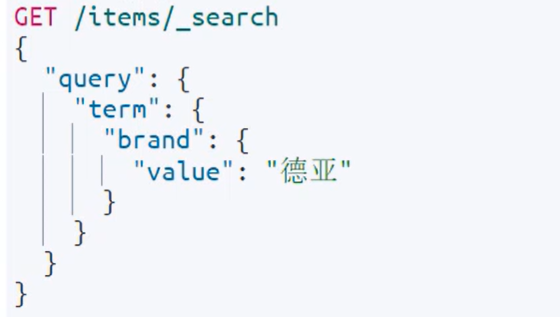
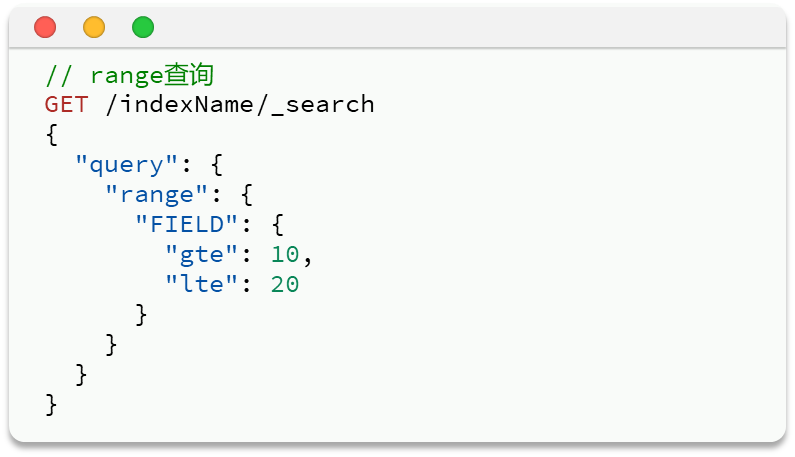
range查询:——查询(gte~lte之间)gte:大于等于,lte:小于等于(gt:大于,lt:小于)
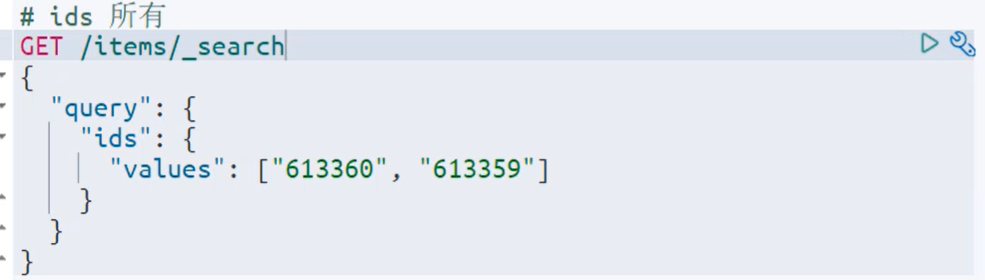
ids查询:——根据_id查询数据
第三节 复合查询
复合查询大致可以分为两类:
第一类:基于逻辑运算组合叶子查询,实现组合条件,例如:bool
第二类:基于某种算法修改查询时的文档相关性算分,从而改变文档排名。例如:function_score,dis_max
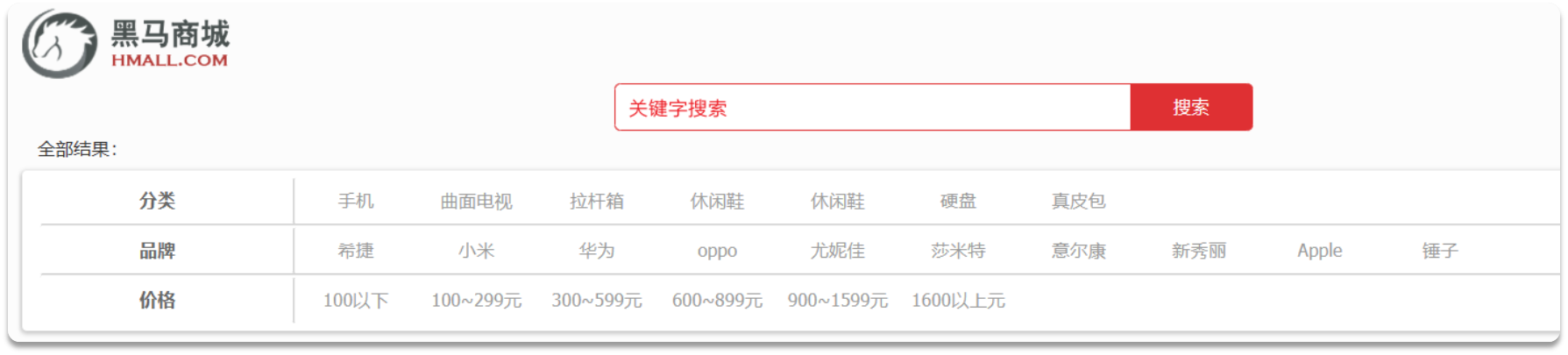
一 布尔查询
布尔查询是一个或多个查询子句的组合。子查询的组合方式有:
must:必须匹配每个子查询,类似“与”
should:选择性匹配子查询,类似“或”
must_not:必须不匹配,不参与算分,类似“非”
filter:必须匹配,不参与算分——相对于过滤条件,必须符合,不符合直接过滤
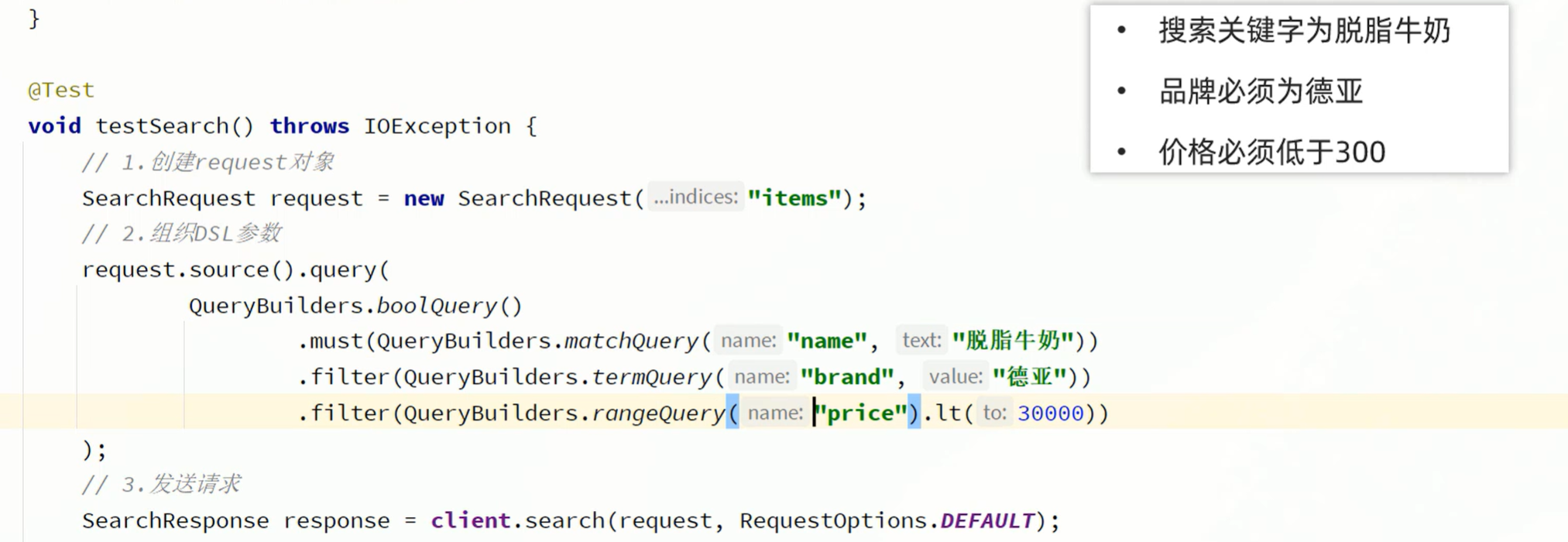
比如,下面的关键字可以用must,而品牌,价格要用filter
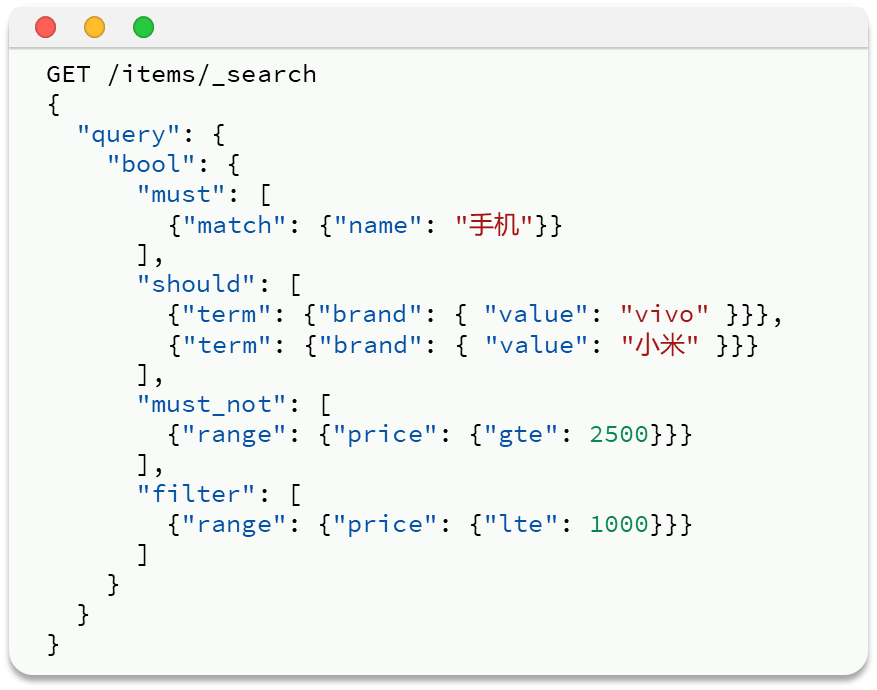
二 算分函数查询
当我们利用match查询时,文档结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列
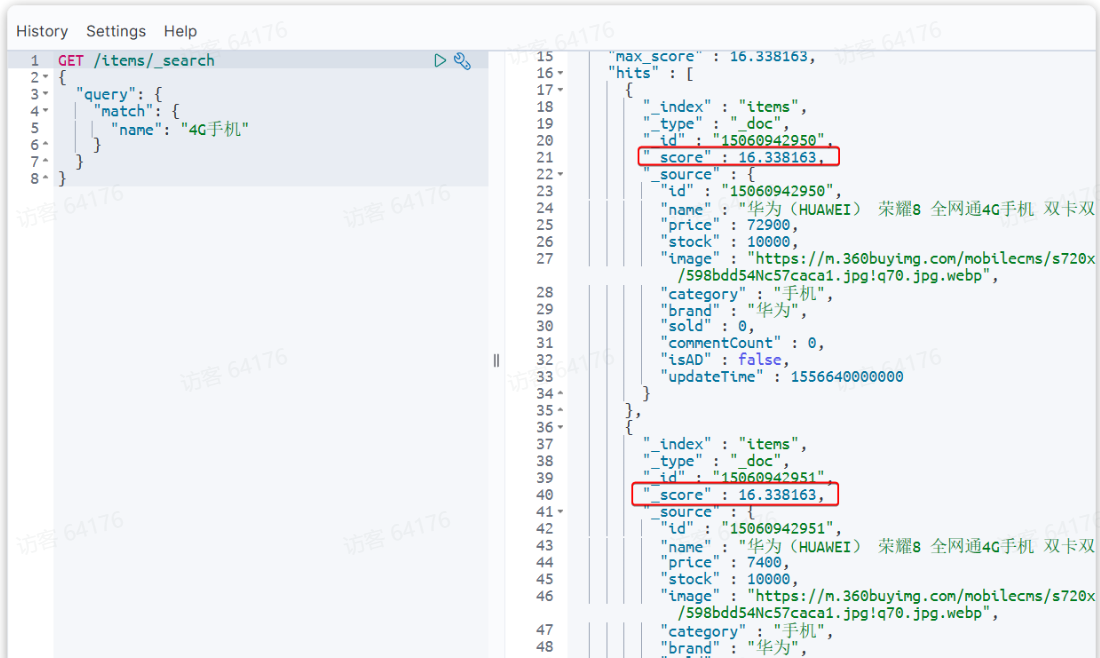
从elasticsearch5.1开始,采用的相关性打分算法是BM25算法,公式如下:

基本语法:
function score 查询中包含四部分内容:
-
原始查询条件:query部分,基于这个条件搜索文档,并且基于BM25算法给文档打分,原始算分(query score)
-
过滤条件:filter部分,符合该条件的文档才会重新算分
-
算分函数:符合filter条件的文档要根据这个函数做运算,得到的函数算分(function score),有四种函数
-
weight:函数结果是常量
-
field_value_factor:以文档中的某个字段值作为函数结果
-
random_score:以随机数作为函数结果
-
script_score:自定义算分函数算法
-
-
运算模式:算分函数的结果、原始查询的相关性算分,两者之间的运算方式,包括:
-
multiply:相乘
-
replace:用function score替换query score
-
其它,例如:sum、avg、max、min
-
示例:给IPhone这个品牌的手机算分提高十倍,分析如下:
-
过滤条件:品牌必须为IPhone
-
算分函数:常量weight,值为10
-
算分模式:相乘multiply
对应代码如下:
GET /hotel/_search{ \"query\": { \"function_score\": { \"query\": { .... }, // 原始查询,可以是任意条件 \"functions\": [ // 算分函数 { \"filter\": { // 满足的条件,品牌必须是Iphone \"term\": { \"brand\": \"Iphone\" } }, \"weight\": 10 // 算分权重为10 } ], \"boost_mode\": \"multipy\" // 加权模式,求乘积 } }}第四节 排序和分页
一 排序
elasticsearch支持对搜索结果排序,默认是根据相关度算分(_score)来排序,也可以指定字段排序。可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。做了排序后不不再打分了
在原先query字段下面增加sort字段,排序字段可以设置多个,当前面字段的值一样时就按照后面的字段排
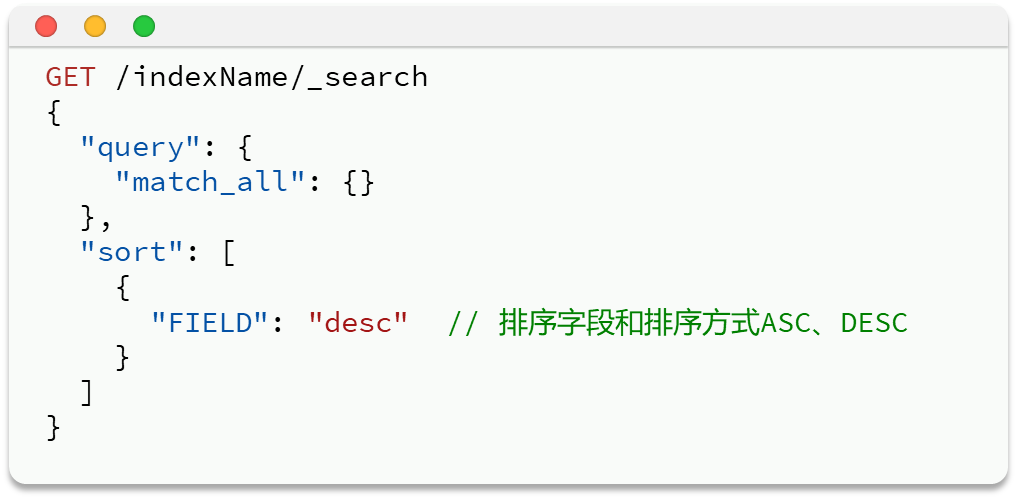
二 分页
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。elasticsearch中通过修改from、size参数来控制要返回的分页结果:
from:从第几个文档开始——注意,比如一次查10页,那么下一页from就是10,再下一页就是20
size:总共查询几个文档
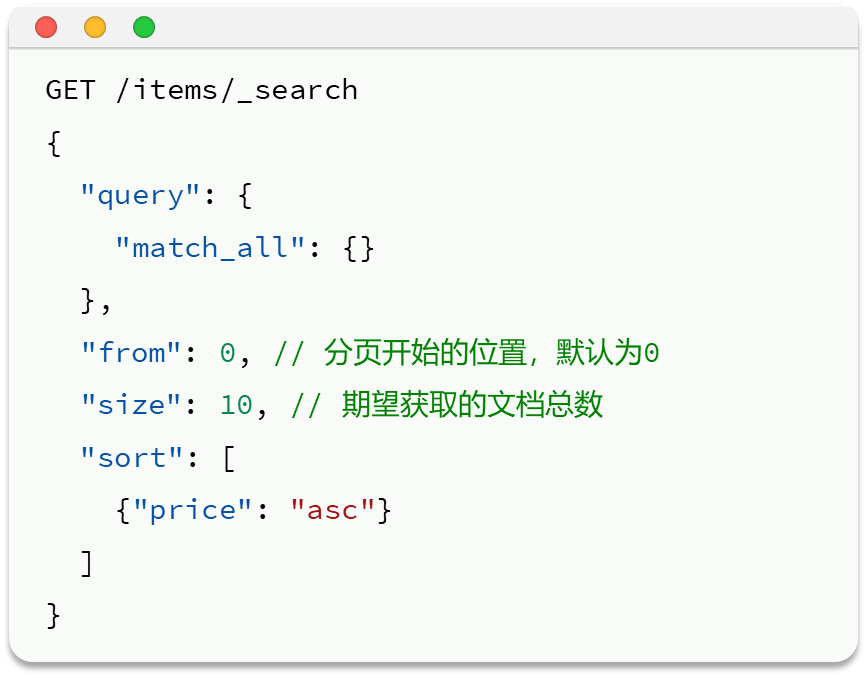
三 深度分页问题
elasticsearch的数据量很大,一般会采用分片存储,也就是把一个索引中的数据分成N份,存储到不同节点上。查询数据时需要汇总各个分片的数据。
假如我们要查询第100页数据,每页查10条,那么我们就必须先排序找出前1000的数据,把这些数据放到内存里做分页,分完页后才能找出990~1000之内的数据
对于ES集群,数据被分散混乱地存储在多台服务器中,那么找出排序前1000的数据,最好的方法就是找出每台服务器排名前1000的数据,然后把这些数据聚合起来取出真正的前1000
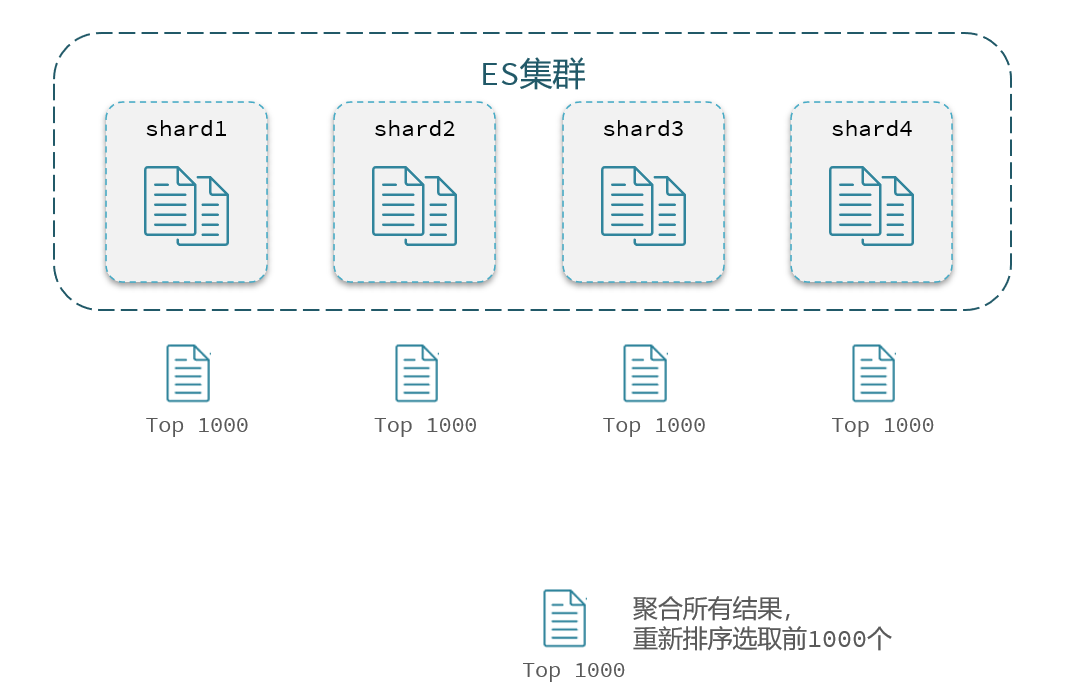
这时候就带来一个问题:如果我查询的不是第100页,而是第10000页,那么每台都要查出前10w条数据来整合;随着页面继续加深,要查询的数据量越大,内存压力越大甚至会爆
针对深度分页,ES提供了两种解决方案,官方文档:
search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。(要有稳定的排序规则!之后的搜索:比如现在存下了第1000页的排序值,如果要查第1200页,就会从第1000页开始,效率提高)
scroll:原理将排序数据形成快照,保存在内存。官方已经不推荐使用。

不过我们的很多软件都可以随机翻页,那是因为他们设置了深度分页的上限,最多查那么多页,再往下不给查了。ES也设置了限制,from+size不能超过10000
第五节 高亮显示
高亮显示:就是在搜索结果中把搜索关键字突出显示。
前端收到的数据的关键词都会带有标签,前端通过html代码给标签加style就可以改颜色高亮。但是给关键词加上标签前端不太好做
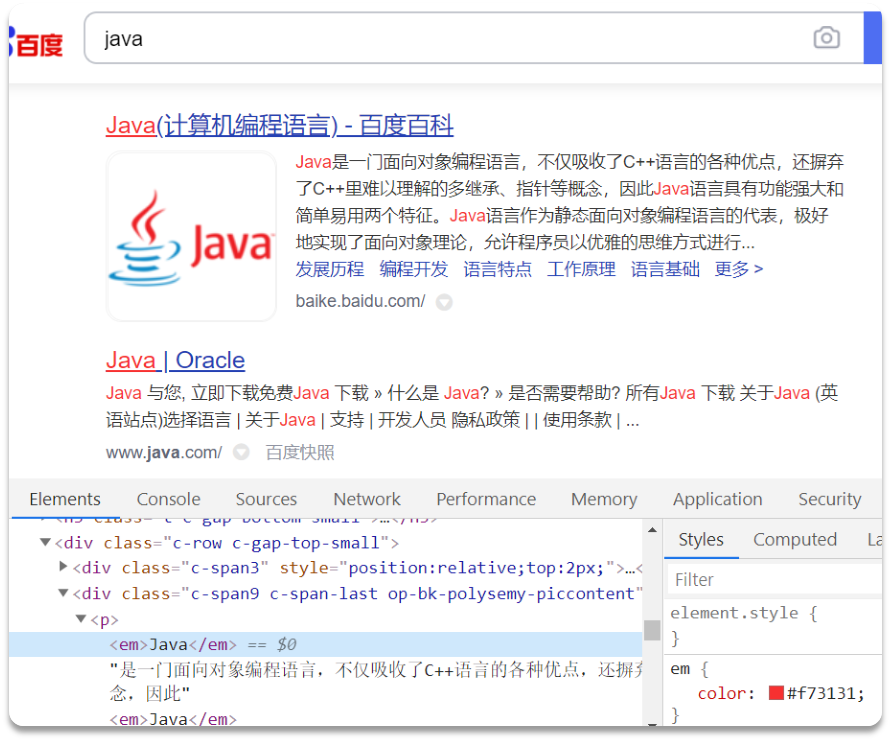
在使用ES搜索的时候,ES同时还会标记出各个关键词的位置。可以利用这一点让后端返回前端的时候给字段加高亮

实际案例:——name里面其实可以不用写,因为会自动默认加
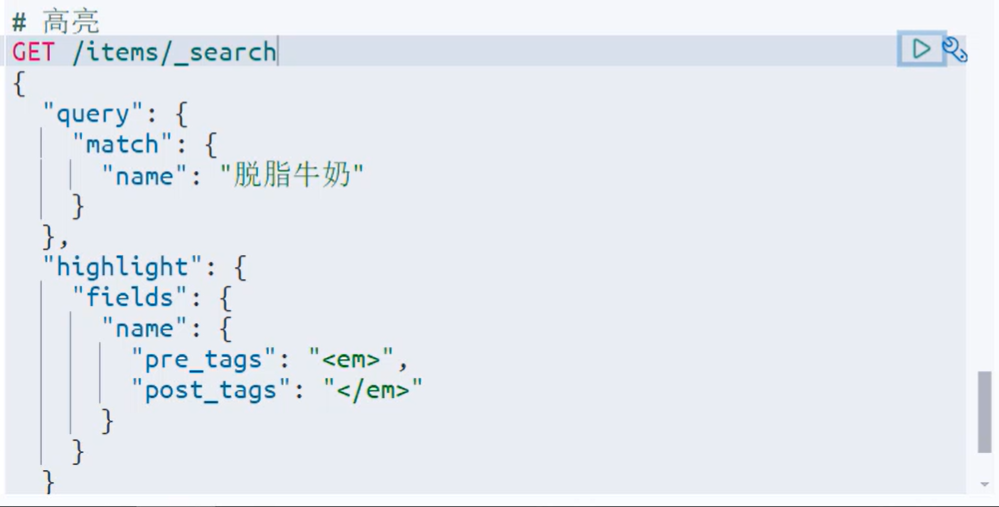
返回:——会在hits同级下增加一个highlight字段

第五章 JavaRestClient的查询
第一节 快速入门
一 构建并且发出对象
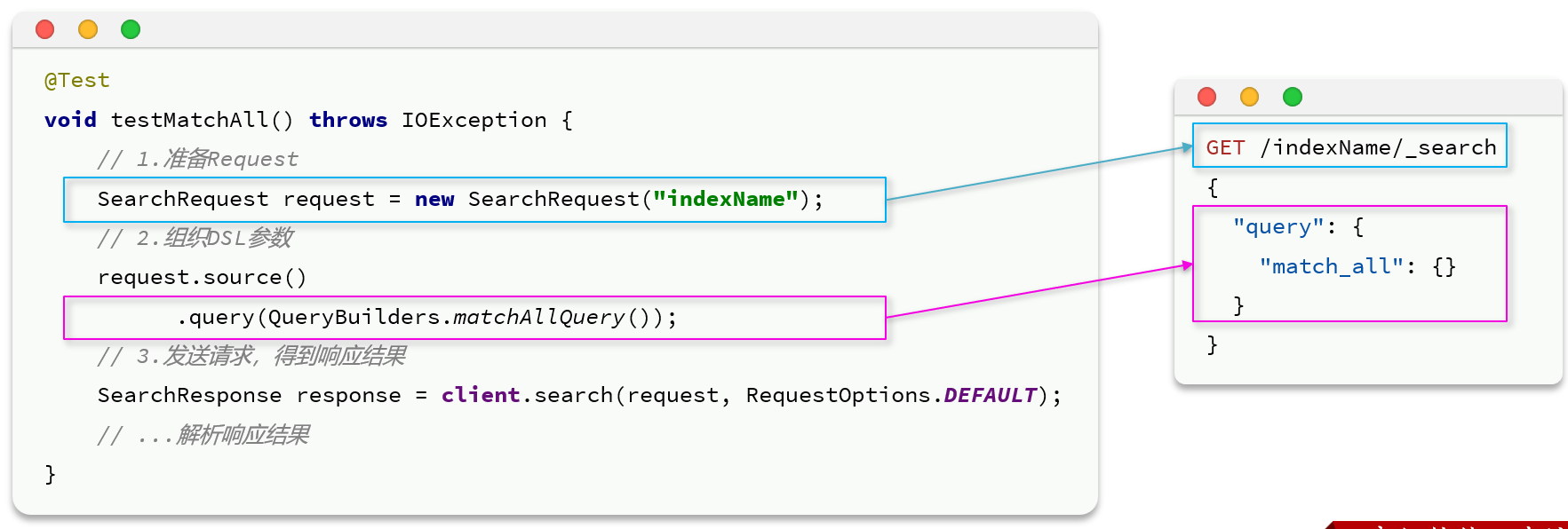
通过request.source()就可以调用各种方法构造请求
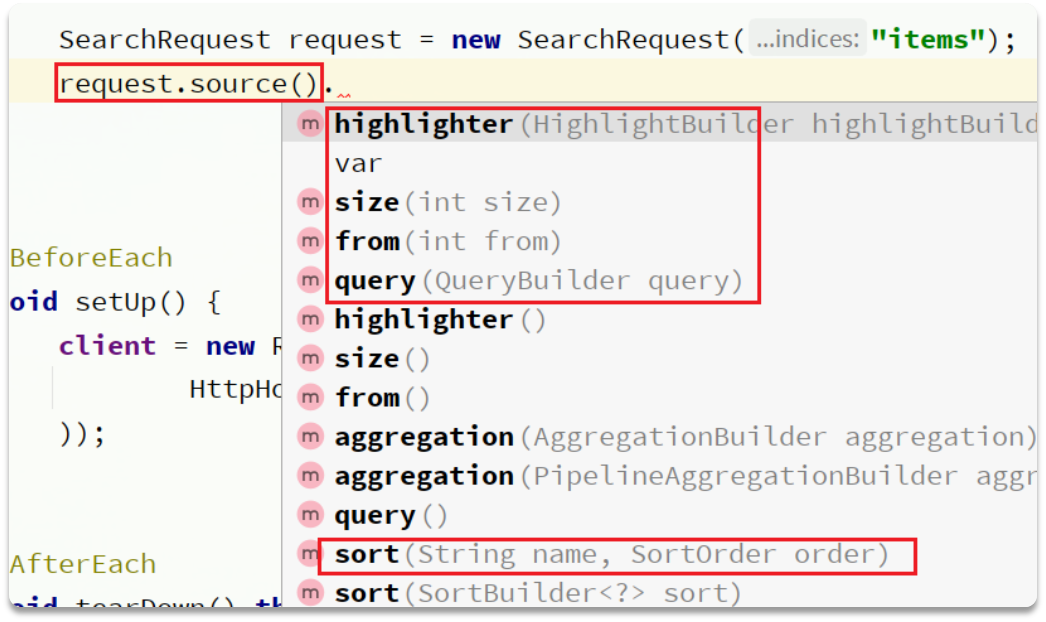
注意看,query的参数是QueryBuilder类型(对于多种查询功能):——可以直接调用QueryBuilders里面的静态方法
最后调用client的search方法发送
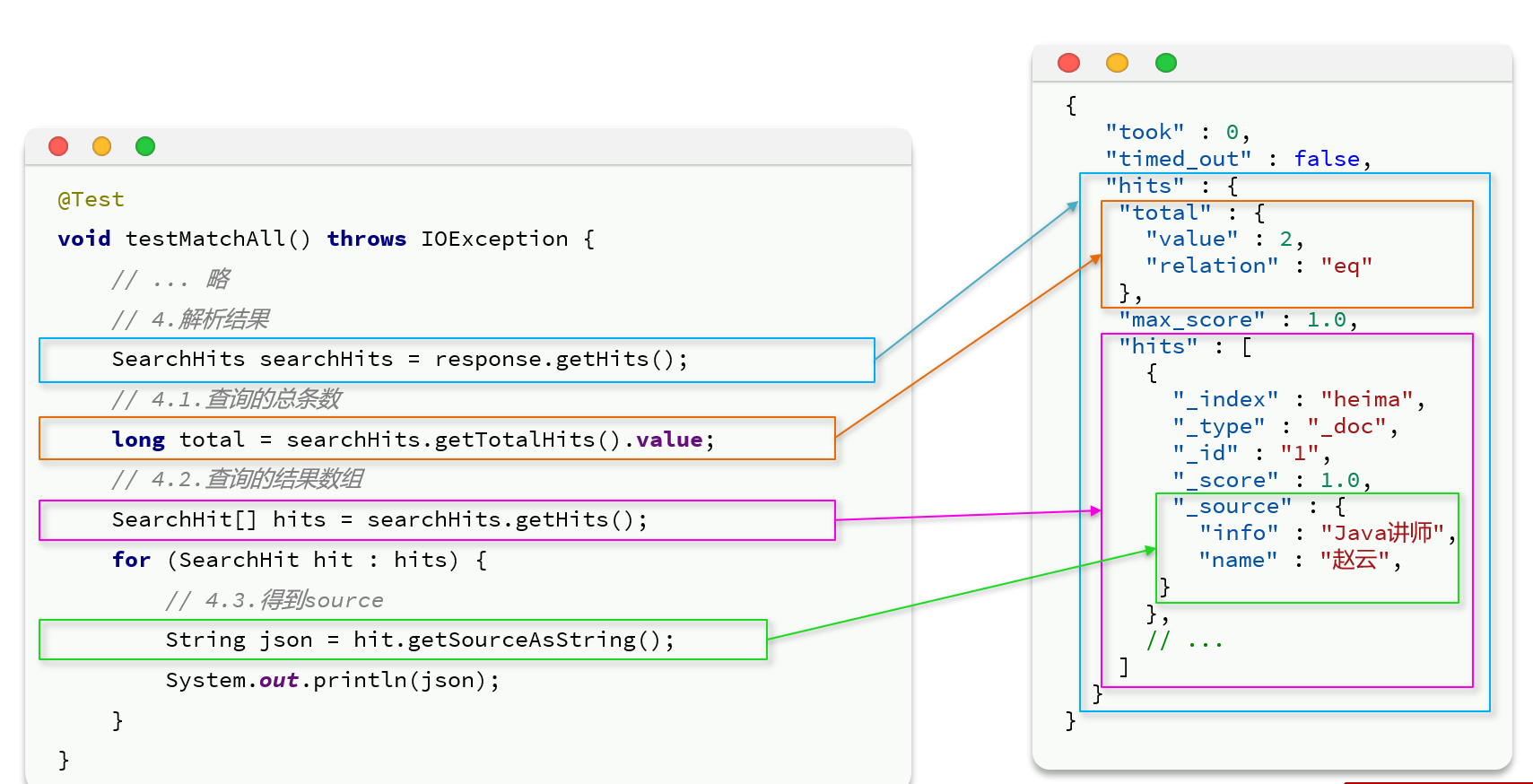
二 解析结果
参考下面,最后的JSON转对象可以使用hutool工具
第二节 构建查询条件
在JavaRestAPI中,所有类型的query查询条件都是由QueryBuilders来构建的:
一 全文搜素

二 精确查询

三 复合查询

简单示例:
第三节 排序和分页
from的数值 = (pageNo - 1) * pageSize
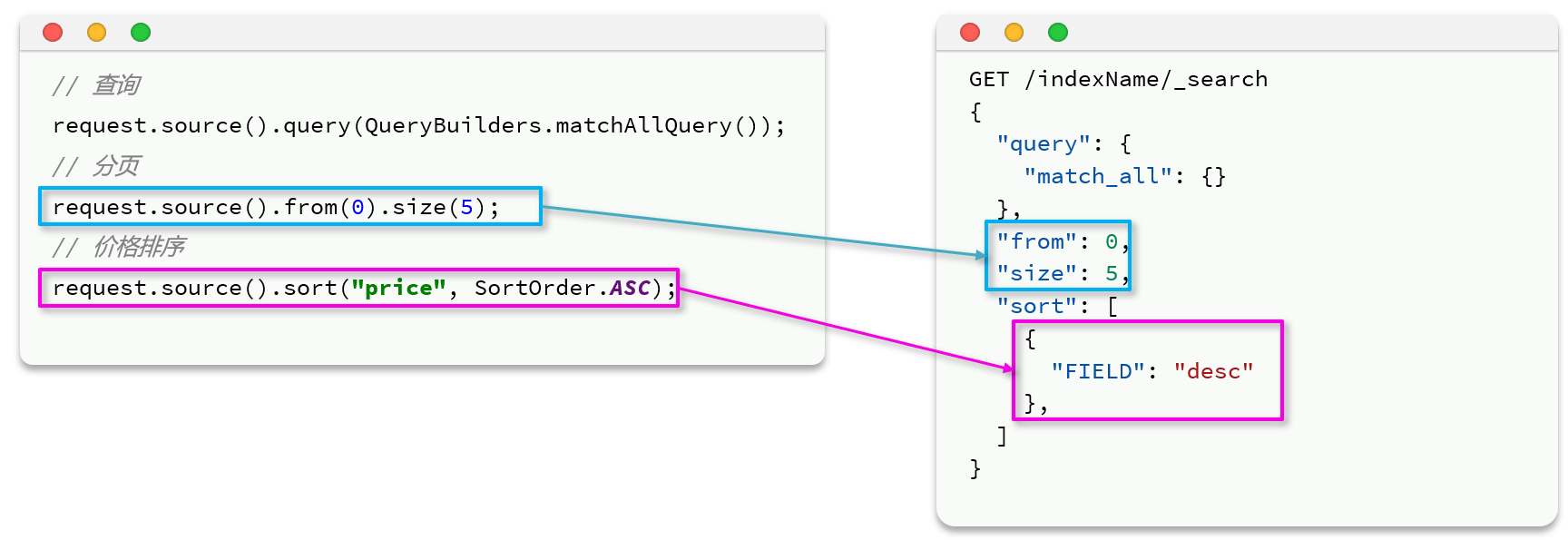
排序是支持多个sort的
第四节 高亮显示
需要额外使用一个highlight构建器
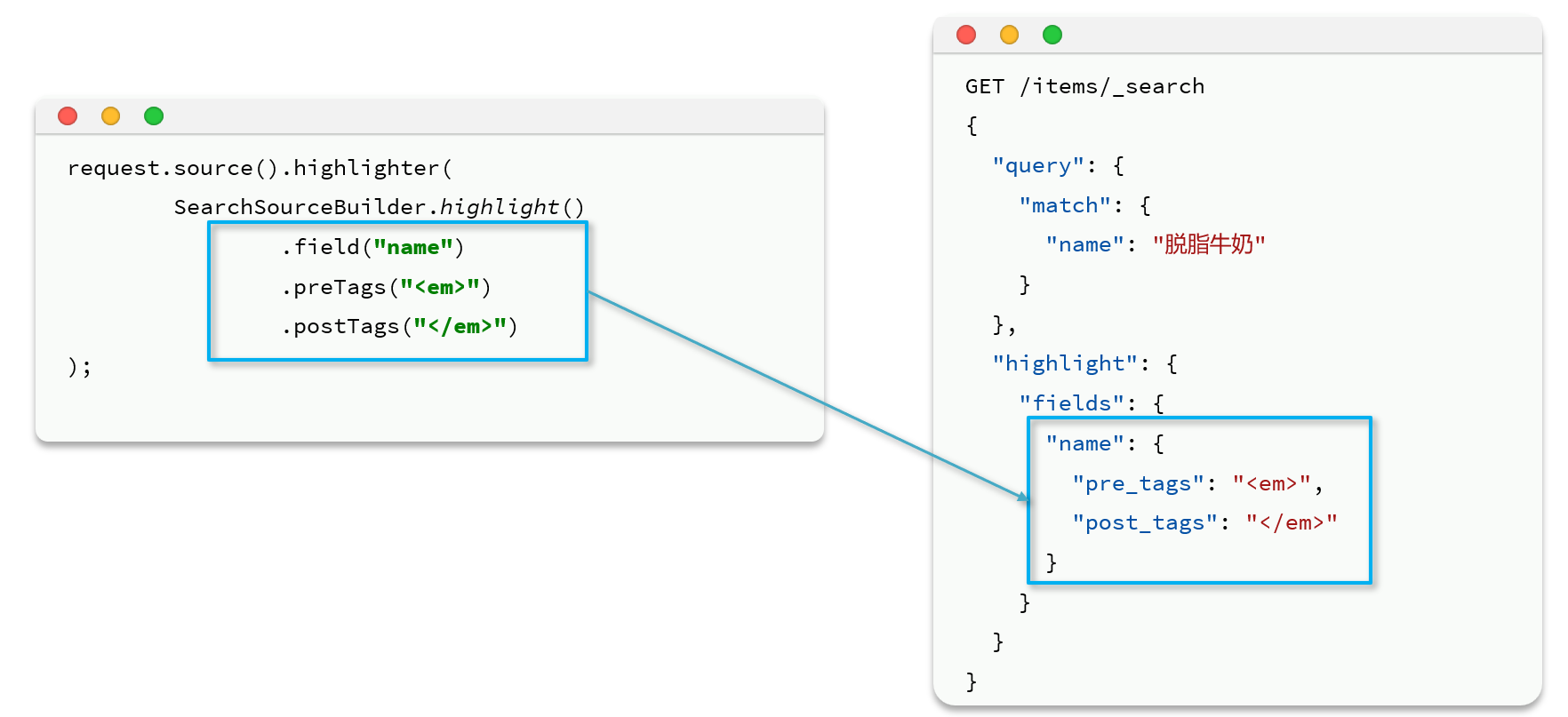
实例:

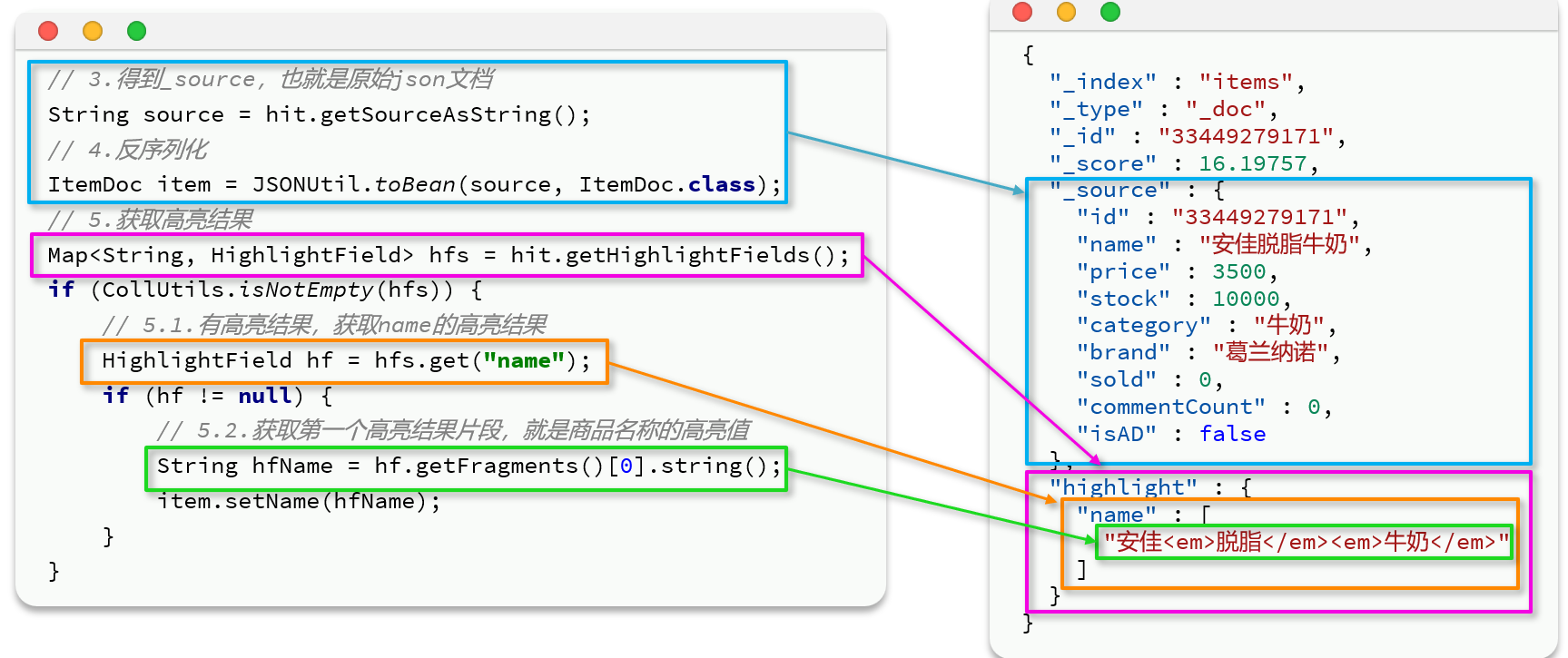
获取高亮结果:name是一个数组,因为底层在给关键字加标签的时候,如果文本太长了就把把它分成多段存在数组里,所以真正在处理的时候要拼接而不是只取第一个。
最后有一个set,把原来item的名字给覆盖掉
第六章 数据聚合
聚合(aggregations)可以实现对文档数据的统计、分析、运算。聚合常见的有三类:
桶聚合:用来对文档做分组
TermAggregation:按照文档字段值分组
Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
度量聚合:用以计算一些值,比如:最大值(Max)、最小值(Min)、平均值(Avg),Stats:同时求max、min、avg、sum等
管道聚合:其它聚合的结果为基础做聚合
第一节 DSL聚合
一 桶聚合
简单聚合:size是因为返回的结果包含文档,内容可能很多,会影响性能;
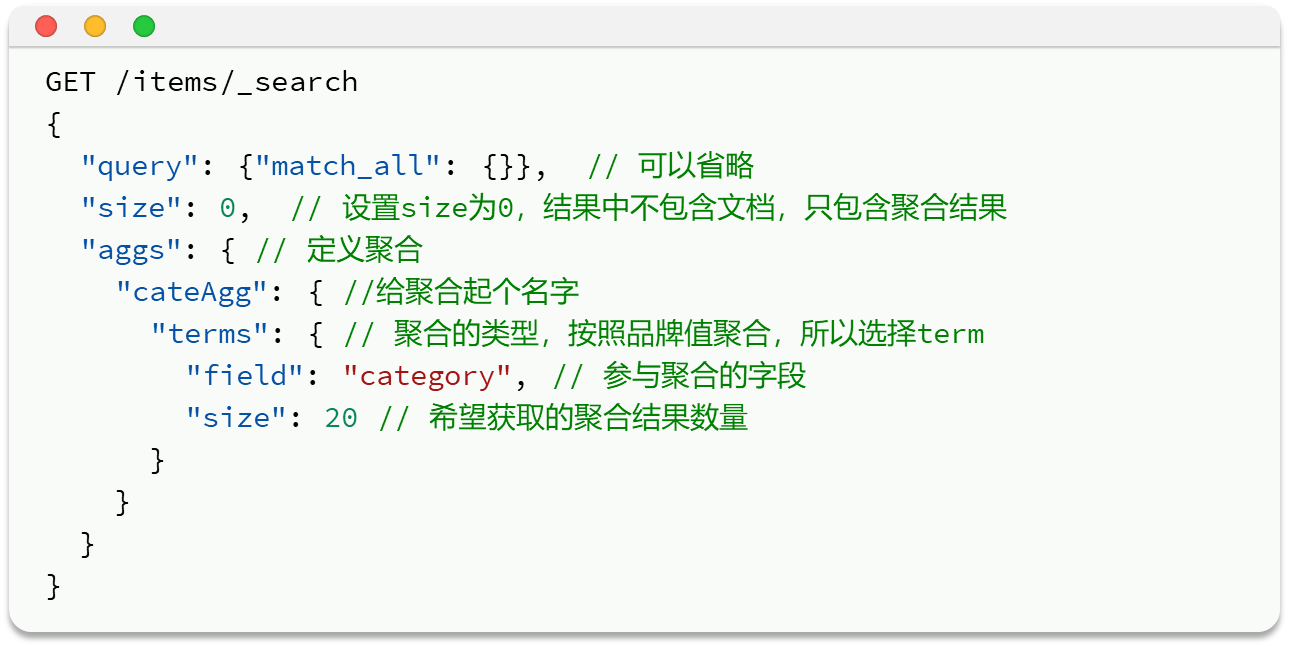
增加了条件的聚合:
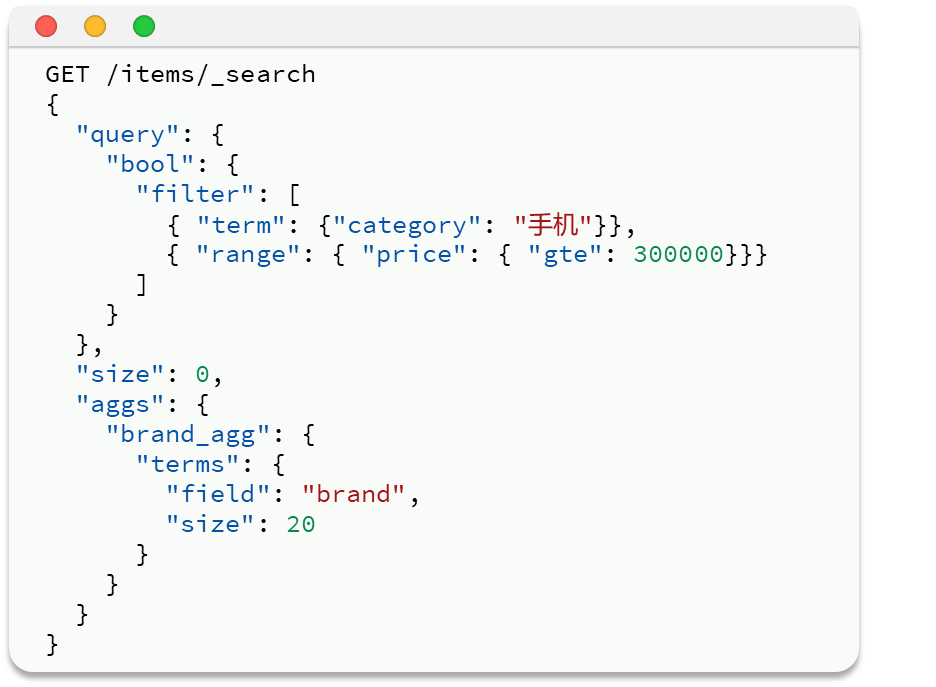
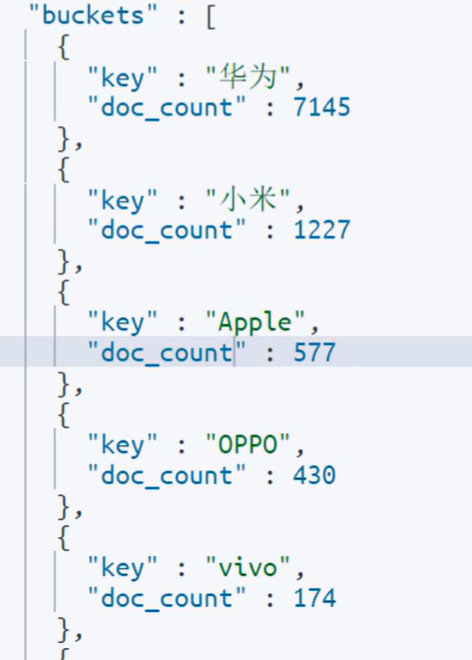
返回的数据:
二 度量聚合
除了对数据分组(Bucket)以外,我们还可以对每个Bucket内的数据进一步做数据计算和统计。
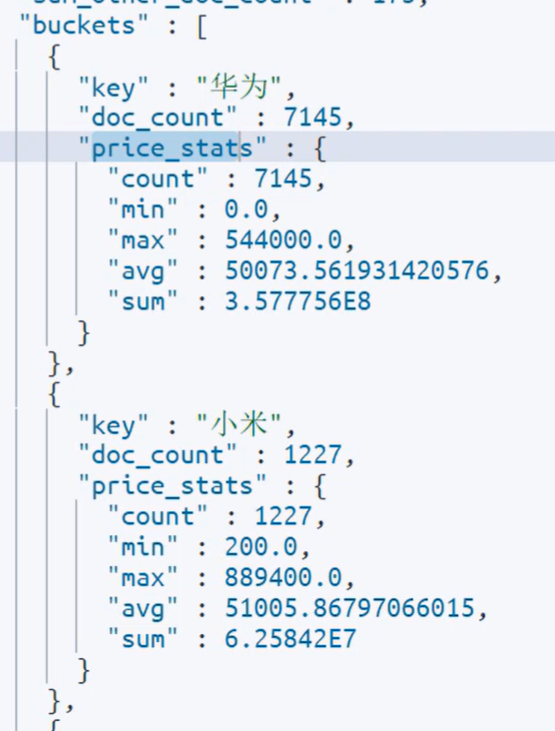
例如:我想知道手机有哪些品牌,每个品牌的价格最小值、最大值、平均值。——聚合里做聚合
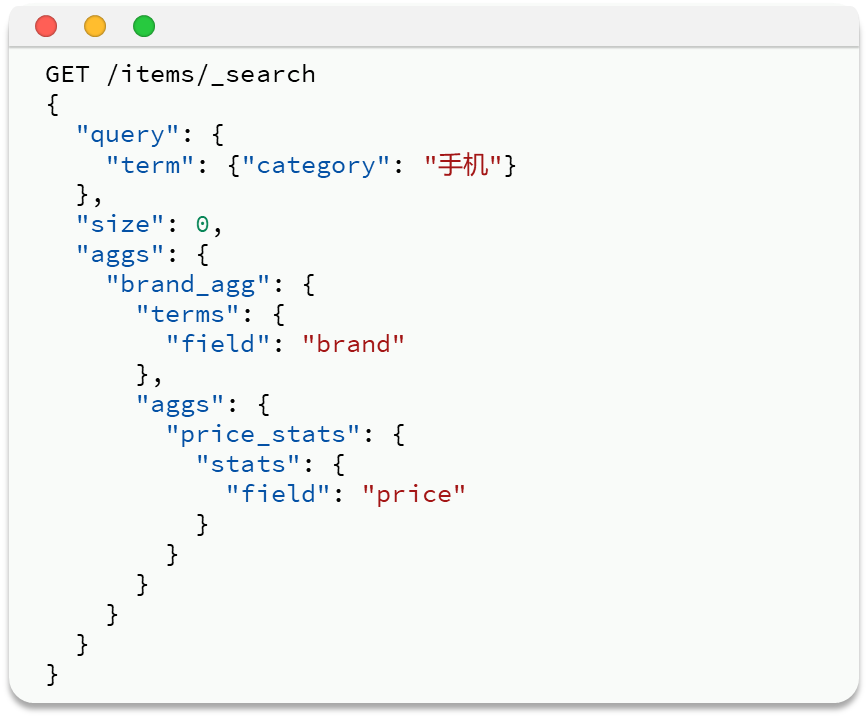
返回的数据
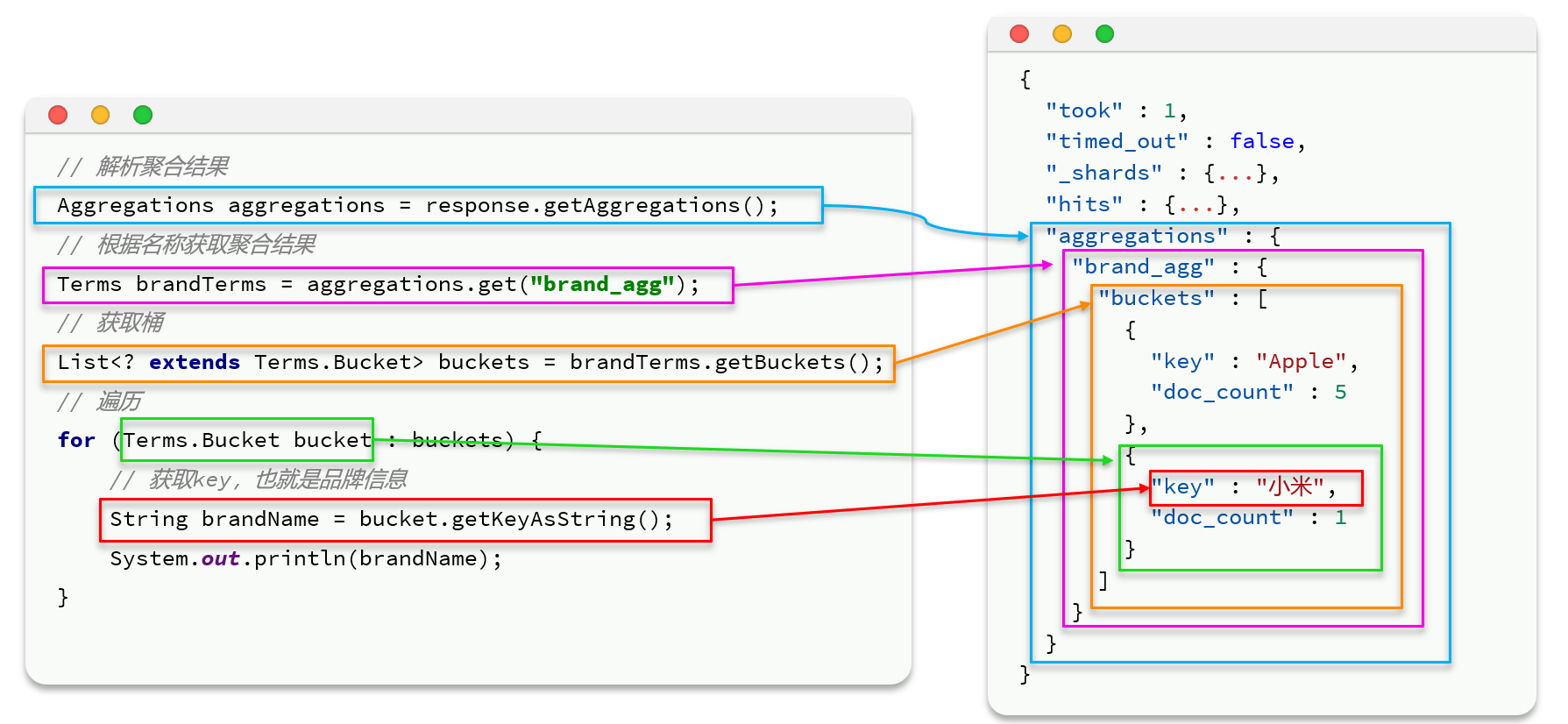
第二节 客户端实现聚合
aggs和query同级:
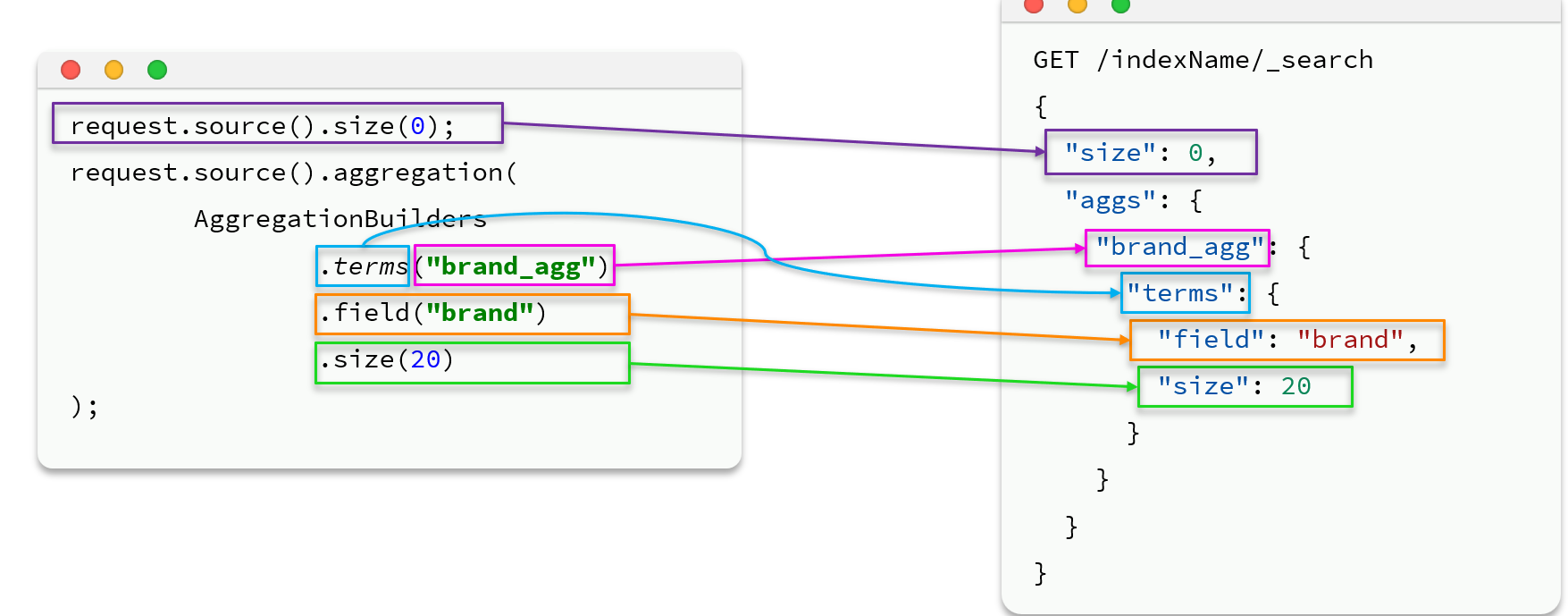
上面用的是.terms来根据指定词分桶;也可以用.status来获取最大值最小值
解析结果:注意,你用什么数据类型来分,就要用什么数据类型来取(有点抽象,上图的蓝色框框和下图的粉色框框)