计算机毕业设计Hadoop+Spatk+Hive滴滴出行分析 出租车供需平衡优化系统 出租车分析预测 大数据毕业设计(源码+LW+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《Hadoop+Spark+Hive滴滴出行出租车供需平衡优化系统分析预测》的开题报告范文,供参考:
开题报告
题目:基于Hadoop+Spark+Hive的滴滴出行出租车供需平衡优化系统分析与预测
一、研究背景与意义
1. 研究背景
随着城市化进程加速和共享经济兴起,出租车/网约车已成为城市交通的重要组成部分。以滴滴出行为代表的平台每日处理数千万订单,但供需失衡问题依然突出:
- 高峰期运力不足:通勤、恶劣天气等场景下乘客打车难;
- 低谷期司机空驶率高:非热点区域司机等待时间长,收入下降;
- 区域性供需错配:商业区、交通枢纽等热点区域订单集中,而郊区运力闲置。
传统调度策略依赖人工经验或简单规则,难以应对动态复杂的城市交通环境。大数据与机器学习技术为实时供需分析、预测及优化调度提供了可能。
2. 研究意义
- 理论意义:探索时空大数据在交通领域的应用,构建出租车供需预测模型,丰富城市计算理论。
- 实践意义:
- 提升乘客打车体验(减少等待时间);
- 提高司机收入(降低空驶率);
- 优化平台运营效率(减少资源浪费);
- 缓解城市交通压力(平衡区域运力分布)。
二、国内外研究现状
1. 供需预测技术研究
- 传统方法:ARIMA、SARIMA等时间序列模型(精度受季节性、突发事件影响较大)。
- 机器学习方法:XGBoost、随机森林等(依赖特征工程,难以捕捉时空依赖性)。
- 深度学习方法:LSTM、ConvLSTM(在时空预测任务中表现优异,如Didi Chuxing的STG2Seq模型)。
2. 大数据平台应用
- Hadoop生态:国内外主流出行平台(如Uber、滴滴)均采用Hadoop+Spark处理海量订单与轨迹数据。
- 实时计算框架:Spark Streaming、Flink用于供需比的动态更新与热力图生成。
- 数据仓库:Hive/Impala支持离线分析与模型训练。
3. 现有不足
- 多源数据融合不足:天气、事件、道路状况等外部因素未充分整合;
- 模型可解释性弱:深度学习模型黑箱特性影响调度策略制定;
- 实时性与扩展性矛盾:高并发场景下模型推理延迟与系统吞吐量需平衡。
三、研究目标与内容
1. 研究目标
构建一个基于Hadoop+Spark+Hive的出租车供需分析与预测系统,实现:
- 实时计算区域供需比;
- 预测未来15/30分钟供需变化趋势;
- 输出优化调度策略(如司机推荐路线、动态定价)。
2. 研究内容
- 数据采集与预处理
- 数据源:滴滴出行订单数据、GPS轨迹、天气、节假日、POI(兴趣点)数据;
- 技术:Kafka流式采集、Hive数据清洗、GeoHash空间编码。
- 供需特征分析
- 空间维度:城市网格化(1km×1km),计算网格供需比;
- 时间维度:识别高峰时段、通勤走廊、周期性模式;
- 外部因素:量化天气、活动事件对供需的影响权重。
- 供需预测模型构建
- 模型选型:
- 短期预测(0-30分钟):LSTM网络捕捉时空依赖性;
- 长期预测(1-24小时):Prophet+XGBoost混合模型;
- 优化方向:结合图神经网络(GNN)处理道路拓扑关系。
- 模型选型:
- 系统实现与优化
- 架构设计:
- 离线层:Hive存储历史数据,Spark批处理训练模型;
- 实时层:Spark Streaming更新供需状态,Kafka推送预测结果;
- 性能优化:
- 数据倾斜处理:随机重分区、组合键设计;
- 模型轻量化:TensorRT加速LSTM推理。
- 架构设计:
四、研究方法与技术路线
1. 研究方法
- 数据分析法:通过Hive SQL统计供需时空分布规律;
- 机器学习法:基于Spark MLlib实现模型训练与调优;
- 对比实验法:验证LSTM模型相较于传统方法的精度提升。
2. 技术路线
mermaid
graph TDA[数据采集] --> B[数据存储]B --> C[特征工程]C --> D[模型训练]D --> E[实时预测]E --> F[调度优化]subgraph 数据层A -->|Kafka| B[HDFS+Hive]endsubgraph 计算层B -->|Spark SQL| C[供需特征计算]C -->|Spark MLlib| D[LSTM/XGBoost模型]D -->|Spark Streaming| E[实时预测API]endsubgraph 应用层E --> F[Grafana可视化+调度引擎]end五、预期成果与创新点
1. 预期成果
- 完成供需预测模型开发,短期预测MAPE≤15%;
- 搭建实时分析平台,支持每5分钟更新供需热力图;
- 输出调度优化策略,降低司机空驶率10%以上。
2. 创新点
- 多模态数据融合:结合道路拓扑、POI分布等非传统交通数据;
- 轻量化实时预测:通过模型剪枝与量化实现边缘端部署;
- 可解释性增强:引入SHAP值解释模型决策逻辑。
六、研究计划与进度安排
七、参考文献
[1] Zheng Y, et al. Urban Computing: Concepts, Methodologies, and Applications[J]. TKDE, 2014.
[2] 滴滴出行. STG2Seq: Spatial-Temporal Graph to Sequence Model for Metro Passenger Volume Prediction[C]. KDD, 2019.
[3] Apache Spark官方文档. Structured Streaming Programming Guide[EB/OL]. 2023.
[4] 李明. 基于Hadoop的出租车供需预测系统设计与实现[D]. 北京邮电大学, 2021.
备注:本开题报告需结合具体实验环境与数据可用性进一步细化技术细节,建议在中期检查前完成小规模数据验证。
希望这篇范文对您有所帮助!可根据实际研究方向调整技术选型或创新点描述。
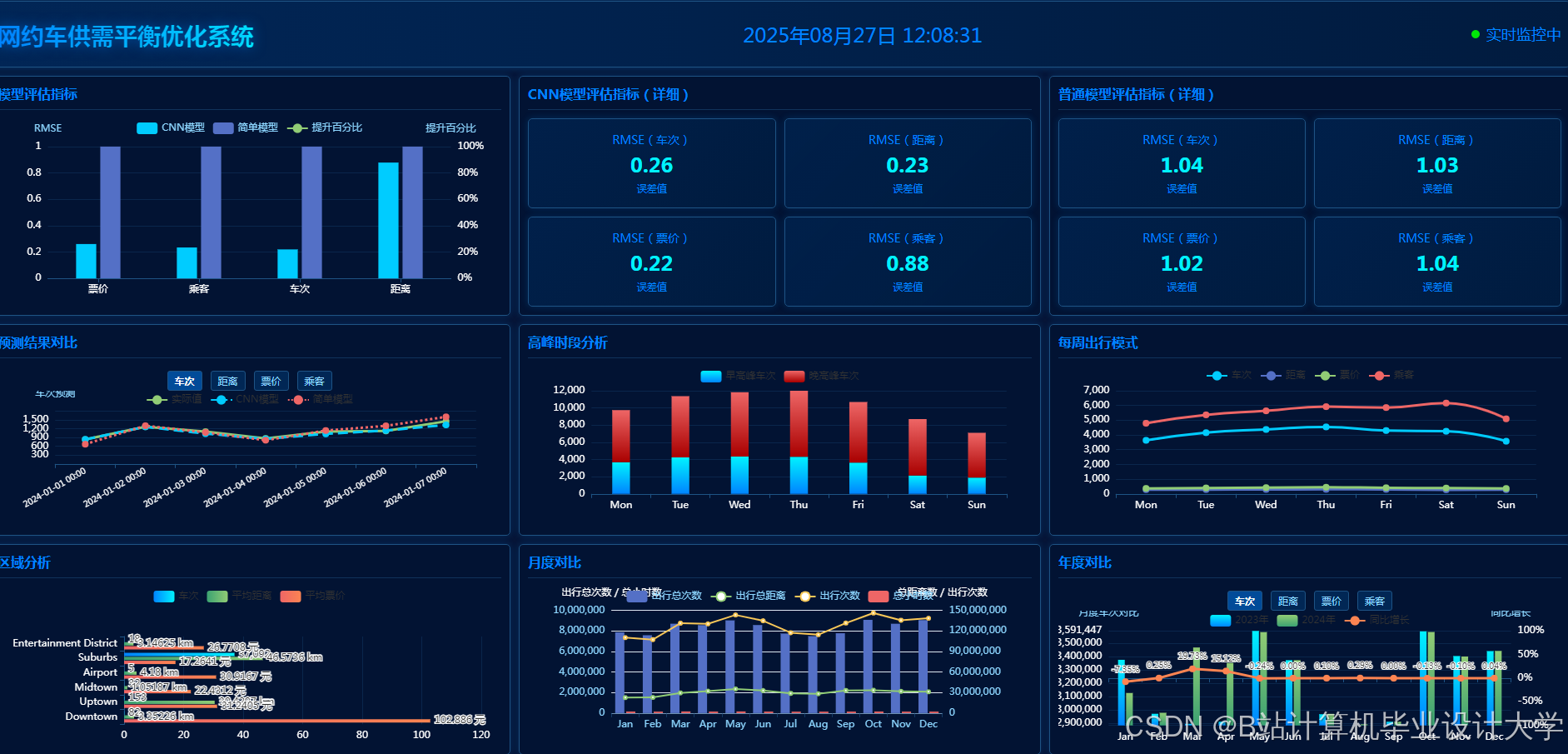
运行截图
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


