MySQL 索引(二)_mysql删除索引
文章目录
- 索引理解
-
- MySQL对page做管理
-
- page的概念
- 单个page
- 多个page
- 页目录
-
- 单页情况(提高page内部的查找的效率)
- 多页情况(提高page间的查找效率)
- 复盘一下
- 为什么选择B+树,不选择其他数据结构呢
- 聚簇索引 VS 非聚簇索引
- 索引操作
-
- 主键索引
- 唯一键索引
- 普通索引
- 增加多列索引(复合索引)
- 查询索引
- 删除索引
- 索引创建原则
- 全文索引

索引理解
MySQL对page做管理
page的概念
- MySQL中存在大量的page,mysql需要将多个page管理起来
- 先组织,再描述,用链表管理单个page和多个page
- 不能简单地认为page是一个内存块,page内部也是要写入管理信息的

单个page
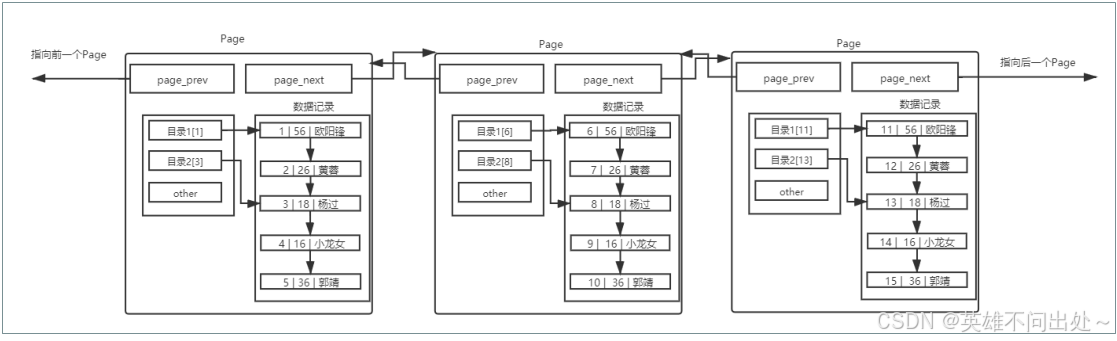
- MySQL 中要管理很多数据表文件,而要管理好这些文件,就需要 先描述,在组织 ,我们目前可以简单理解成一个个独立文件是有一个或者多个Page构成的。
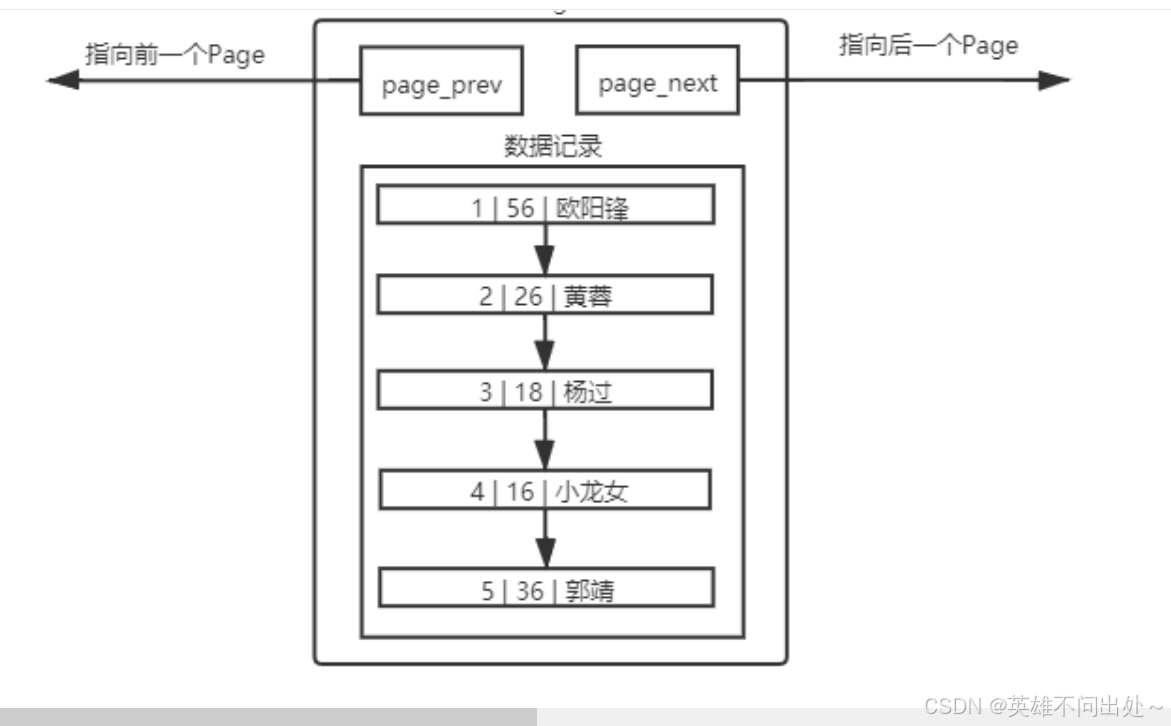
2. 不同的 Page ,在 MySQL 中,都是 16KB ,使用 prev 和 next 构成双向链表
3. 为什么mysql在插入数据时要给我们排序呢?
因为有主键的问题, MySQL 会默认按照主键给我们的数据进行排序,从上面的Page内数据记录可以看
出,数据是有序且彼此关联的。
插入数据时排序的目的,就是优化查询的效率。
页内部存放数据的模块,实质上也是一个链表的结构,链表的特点也就是增删快,查询修改慢,所以优化查询
的效率是必须的。
正式因为有序,在查找的时候,从头到后都是有效查找,没有任何一个查找是浪费的,而且,如果运气好,是可以提前结束查找过程的。
多个page
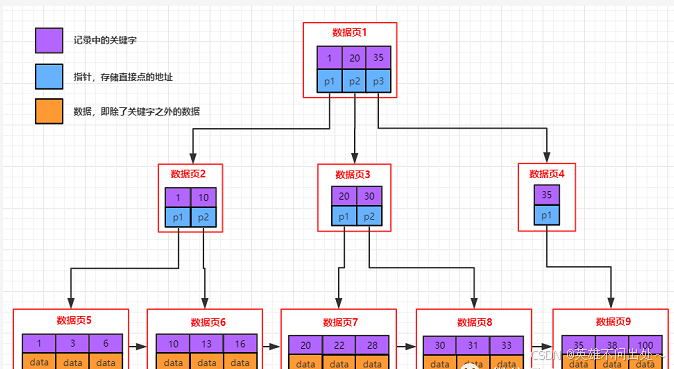
- 通过上面的分析,我们知道,上面页模式中,只有一个功能,就是在查询某条数据的时候直接将一整页的数据加载到内存中,以减少硬盘IO次数,从而提高性能。
- 在page中是按照链表的从前往后查找的,效率就太低了
页目录
- 一本书通常会有一个目录,目录就是用空间换时间的做法,通过目录的查找可以快速定位要查找的关键字的位置,大大地提高了效率
单页情况(提高page内部的查找的效率)
- 单页情况就是一个page,在page内部引入目录
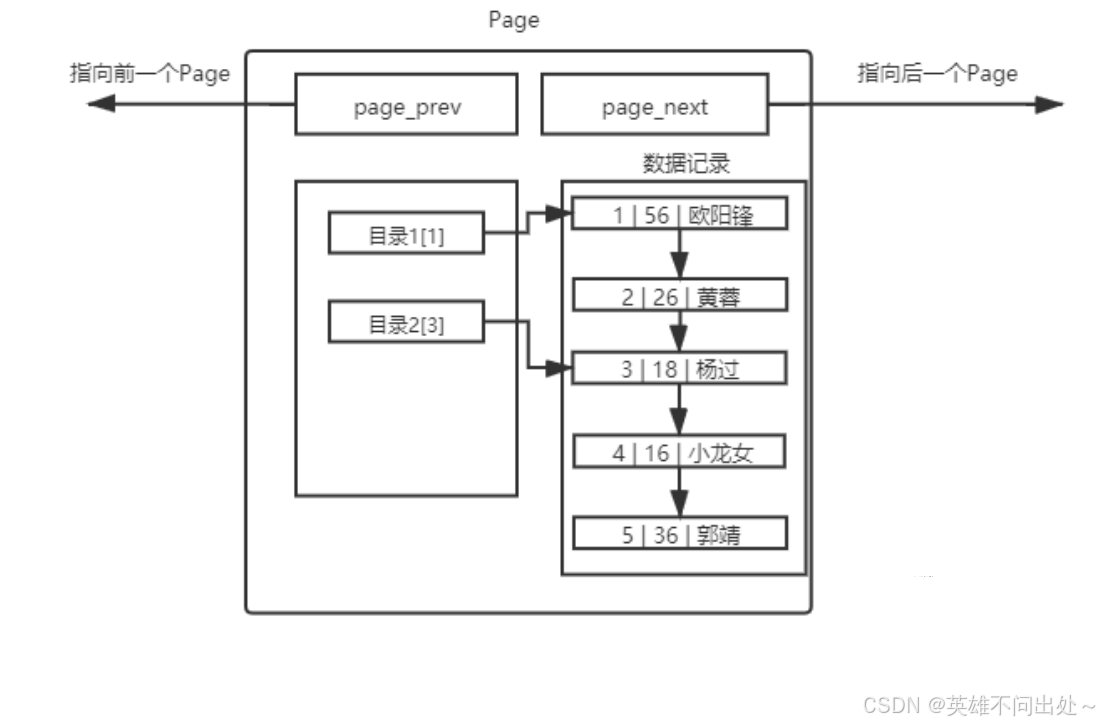
- 那么当前,在一个Page内部,我们引入了目录。比如,我们要查找id=4记录,之前必须线性遍历4次,才能拿到结果。现在直接通过目录2[3],直接进行定位新的起始位置,提高了效率。现在我们可以再次正式回答上面的问题了, 为何通过键值 MySQL 会自动排序?可以很方便引入目录
多页情况(提高page间的查找效率)
- 在单表数据不断被插入的情况下, MySQL 会在容量不足的时候,自动开辟新的Page来保存新的数据,然后通过指针的方式,将所有的Page组织起来。
2. 如果有很多页的page,通过线性遍历,效率还是很低的,这样多页page也需要引入目录
使用一个目录项来指向某一页,而这个目录项存放的就是将要指向的页中存放的最小数据的键值。
和页内目录不同的地方在于,这种目录管理的级别是页,而页内目录管理的级别是行。
其中,每个目录项的构成是:键值+指针。图中没有画全。
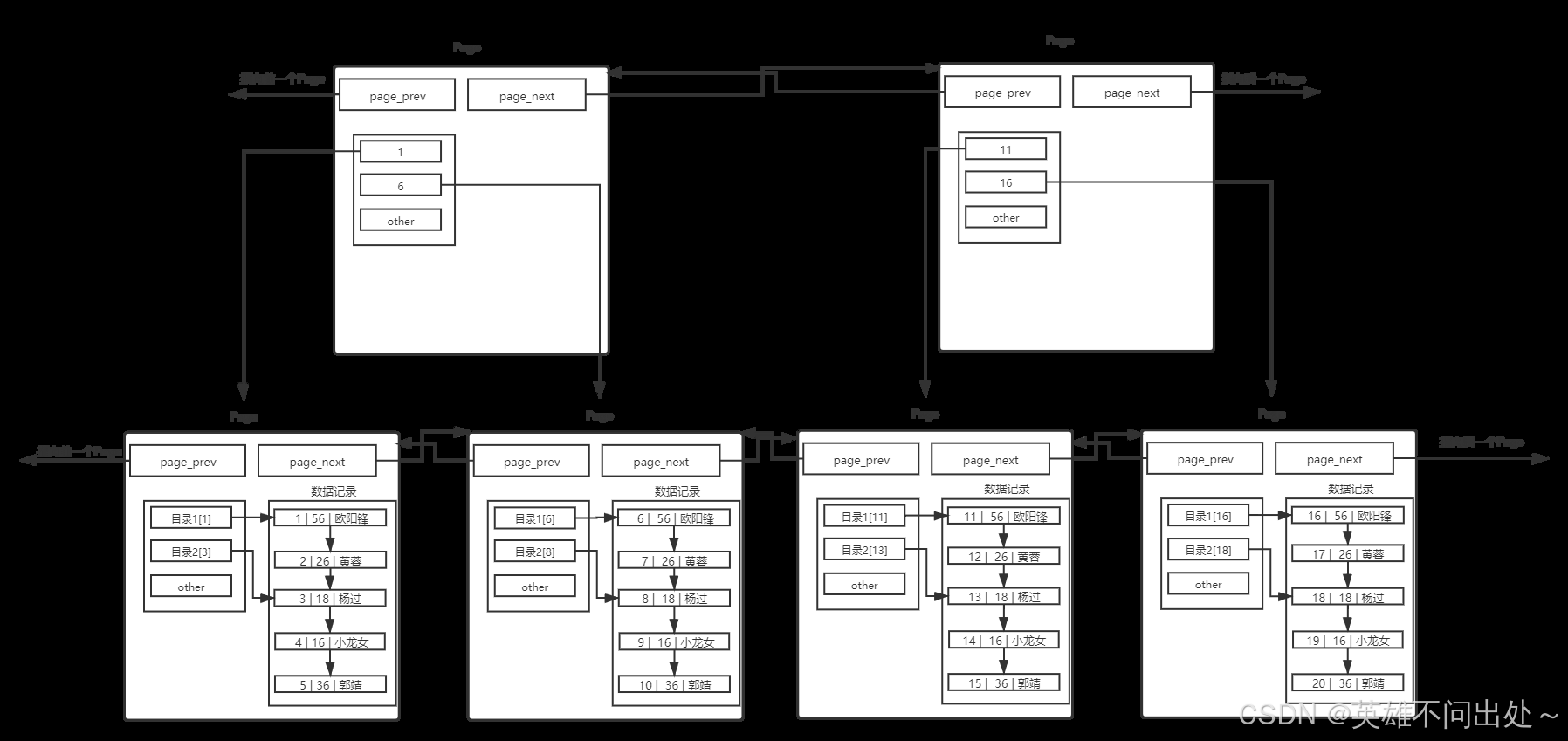
3. 存在一个目录页来管理页目录,目录页中的数据存放的就是指向的那一页中最小的数据。有数据,就可通过比较,找 到该访问那个Page,进而通过指针,找到下一个Page。
4. 最底层的叶子节点的目录页存的是用户的数据,中间的节点存的是目录页的地址
5. 如果叶子结点非常多,需要更多的目录页,那就多加几层,就可以存放更多的叶子目录页
6. 这就是B+树,一个分支有多个树
- B+树,不一定是全的,需要哪些会加载那些page进来
- 叶子节点用B+树连接起来,非叶子节点不用B+树连接起来是为什么呢?
a. 这是B+树的特点
b.我们比较希望进行范围查找
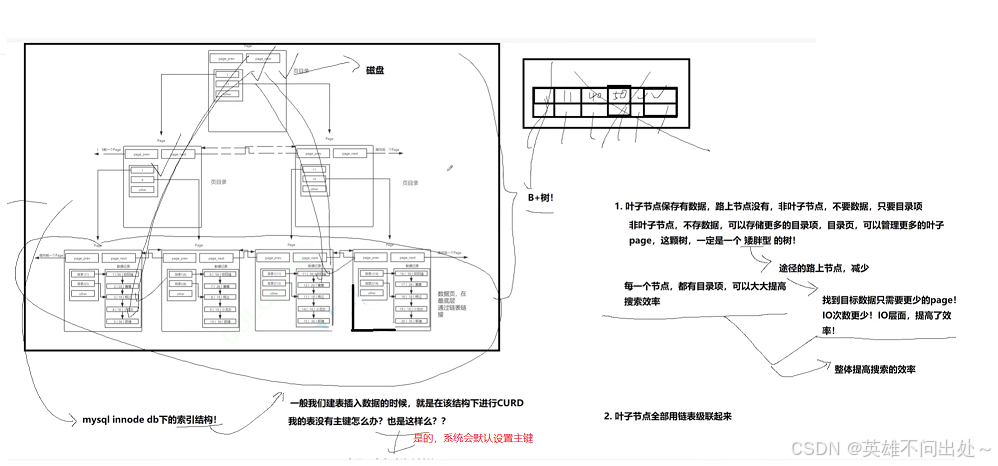
复盘一下
- Page分为目录页和数据页。目录页只放各个下级Page的最小键值。
- 查找的时候,自定向下找,只需要加载部分目录页到内存,即可完成算法的整个查找过程,大大减少了IO次数
为什么选择B+树,不选择其他数据结构呢
- 链表?线性遍历,效率太慢
- 二叉搜索树?退化问题,可能退化成为线性结构
- AVL和红黑树,是二叉结构的数,是又瘦又高的树,要进行多次的IO操作,导致效率的下降
- Hash?官方的索引实现方式中, MySQL 是支持HASH的,不过 InnoDB 和 MyISAM 并不支持.Hash跟进其算法特征,决定了虽然有时候也很快(O(1)),不过,在面对范围查找就明显不行

5. 为什么不选择B树,而选择B+树呢?
B树
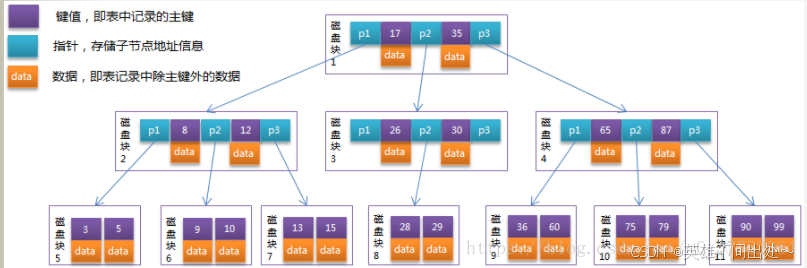
B+树
区别:
-
B树节点,既有数据,又有Page指针,而B+,只有叶子节点有数据,其他目录页,只有键值和Page指针
-
B+叶子节点,全部相连,而B没有
为什么选择B+树
- 节点不存储data,这样一个节点就可以存储更多的key。可以使得树更矮,所以IO操作次数更少。
- 叶子节点相连,更便于进行范围查找
聚簇索引 VS 非聚簇索引
- MyISAM 存储引擎-主键索引,也使用B+树,叶子节点的数据域存放的是数据记录的地址
- MyISAM 最大的特点是,将索引Page和数据Page分离,也就是叶子节点没有数据,只有对应数据的地址。
- InnoDB 索引, InnoDB 是将索引和数据放在一起的。
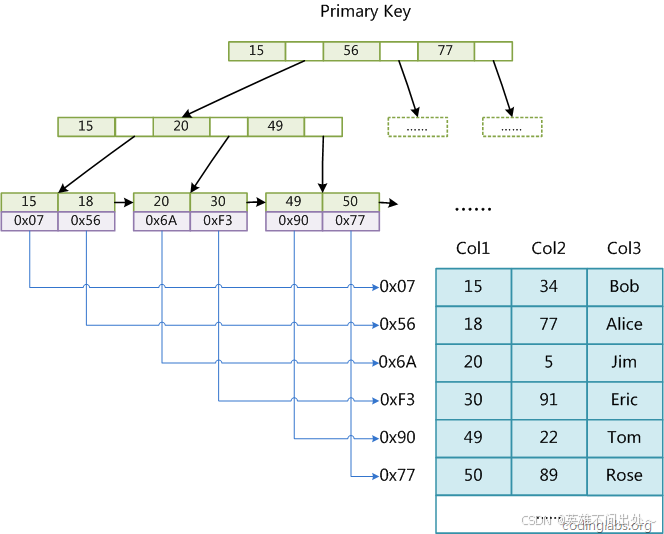
4. 聚簇索引:对应的是InnoDB的存储方式
5. 非聚簇索引:对应的是MyISAM的存储方式
-
myisam
-
innodb


-
索引的本质是B+结构,建立一个索引,会加入一颗B+树
-
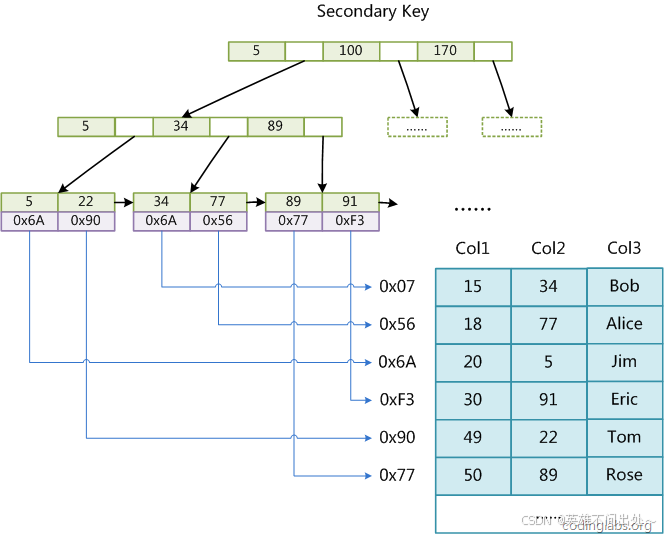
MySQL 除了默认会建立主键索引外,我们用户也有可能建立按照其他列信息建立的索引,一般这种索引可以叫做辅助(普通)索引。
-
对于 MyISAM ,建立辅助(普通)索引和主键索引没有差别,无非就是主键不能重复,而非主键可重复。
-
下面就是以Col2建立的非主键索引
-
InnoDB 除了主键索引,用户也会建立辅助(普通)索引,我们以上表中的 Col3 建立对应的辅助
索引如下图:
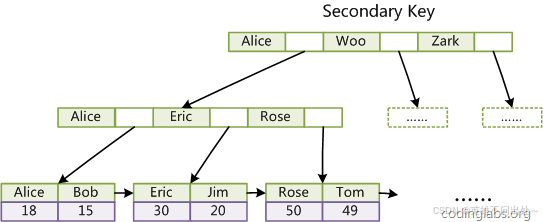
13. InnoDB 的非主键索引中叶子节点并没有数据,而只有对应记录的key值。
所以通过辅助(普通)索引,找到目标记录,需要两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。这种过程,就叫做回表查询
为何 InnoDB 针对这种辅助(普通)索引的场景,不给叶子节点也附上数据呢?原因就是太浪费空间了。
索引操作
主键索引
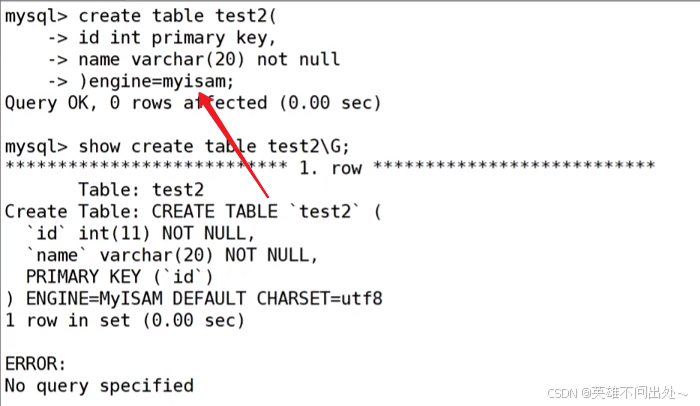
- 创建主键索引
第一种方式:
-- 在创建表的时候,直接在字段名后指定 primary keycreate table user1(id int primary key, name varchar(30));第二种方式:
-- 在创建表的最后,指定某列或某几列为主键索引create table user2(id int, name varchar(30), primary key(id));第三种方式:
create table user3(id int, name varchar(30));-- 创建表以后再添加主键alter table user3 add primary key(id);show index from test1\\G;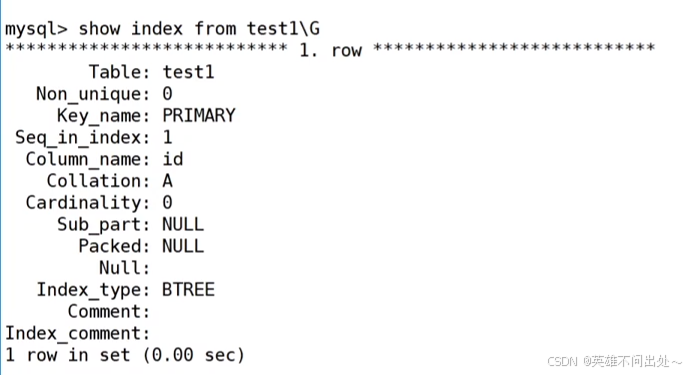
特点:
一个表中,最多有一个主键索引,当然可以使用复合主键
主键索引的效率高(主键不可重复)
创建主键索引的列,它的值不能为null,且不能重复
主键索引的列基本上是int
唯一键索引
- 第一种方式:
-- 在表定义时,在某列后直接指定unique唯一属性。create table user4(id int primary key, name varchar(30) unique);- 第二种方式:
-- 创建表时,在表的后面指定某列或某几列为uniquecreate table user5(id int primary key, name varchar(30), unique(name));- 第三种方式:
create table user6(id int primary key, name varchar(30));alter table user6 add unique(name);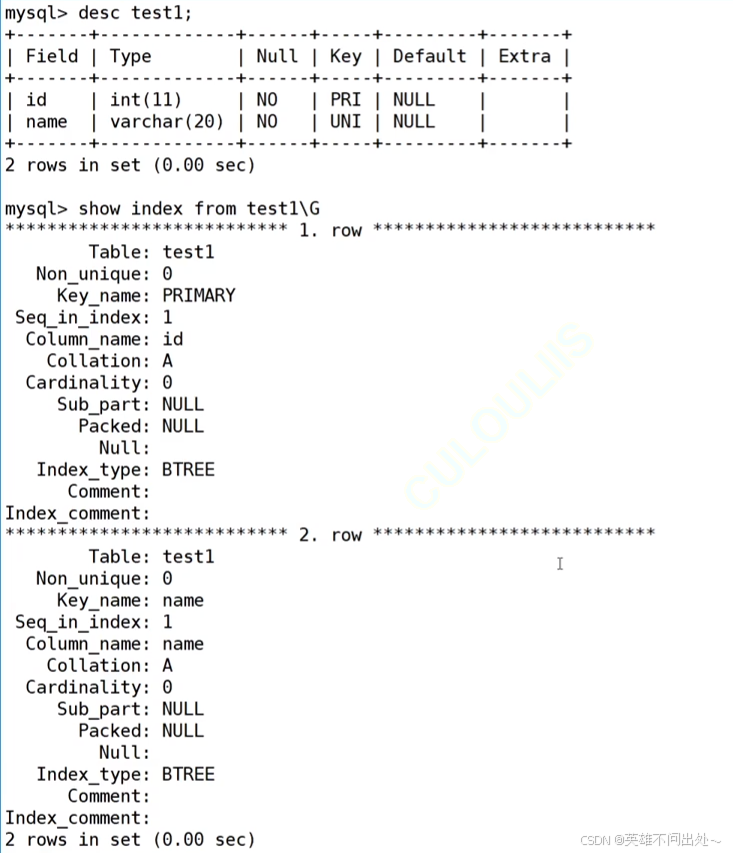
特点:
一个表中,可以有多个唯一索引
查询效率高
如果在某一列建立唯一索引,必须保证这列不能有重复数据
如果一个唯一索引上指定not null,等价于主键索引
普通索引
- 第一种方式:
create table user8(id int primary key,name varchar(20),email varchar(30),index(name) --在表的定义最后,指定某列为索引);- 第二种方式:
create table user9(id int primary key, name varchar(20), email varchar(30));alter table user9 add index(name);--创建完表以后指定某列为普通索引第三种方式:给索引取个名字
create table user10(id int primary key, name varchar(20), email varchar(30));-- 创建一个索引名为 idx_name 的索引create index idx_name on user10(name);
增加多列索引(复合索引)
- 新增一列
alter table test1 add email varchar(30) not null after name;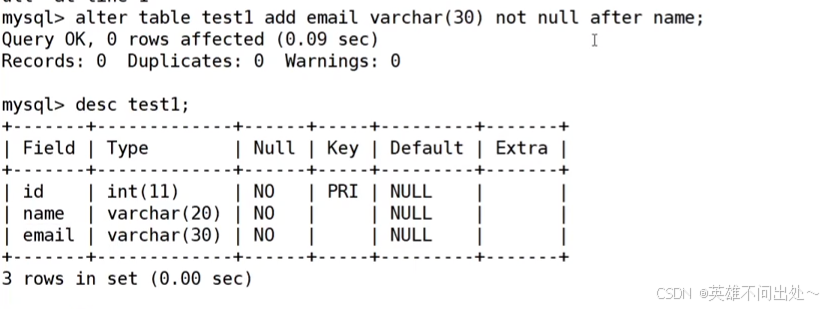
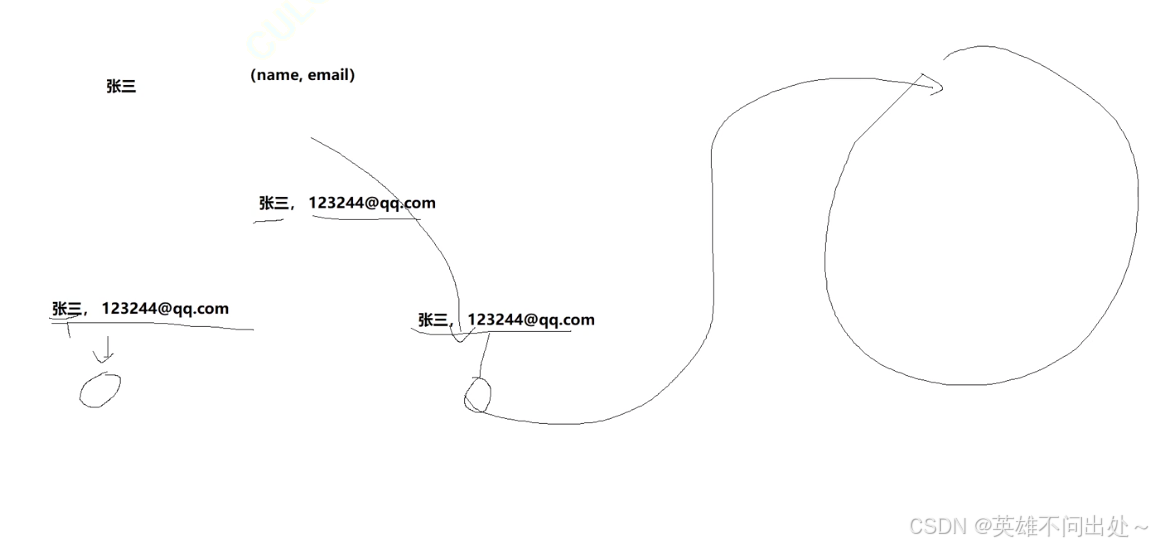
2. 增加多列索引,显示有两颗B+树,其实是一颗B+树,都是name为键值的一颗B+树
3. 复合索引:以多列作为索引,并不是创建了两颗B+树,而是会以第一个作为索引列
4. 索引覆盖:有多个索引构成一颗B+树,通过第一个列找到它的其他列,就不需要回表查询了
5. 索引的最左匹配原则:下图中可以拿张三匹配,可以拿张三和它的qq匹配,但是不能只拿qq进行匹配(是找不到的)
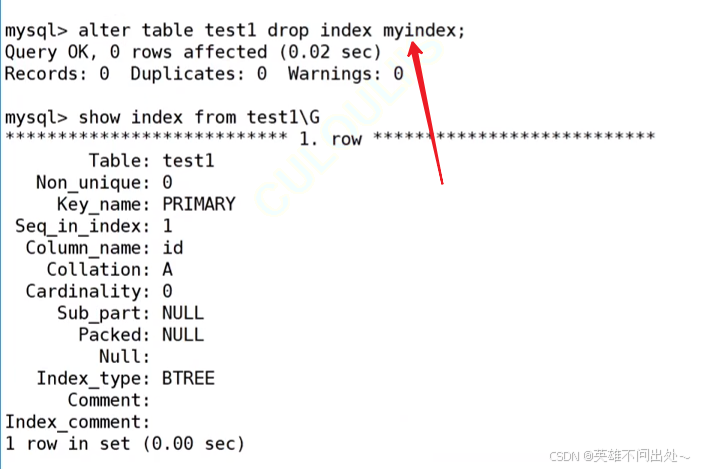
alter table test1 add index(name,email);alter table test1 drop index name;// 只需要删一个就行,因为他两是共用一个key的create index myindex on test1(name,email);alter table test1 drop index myindex;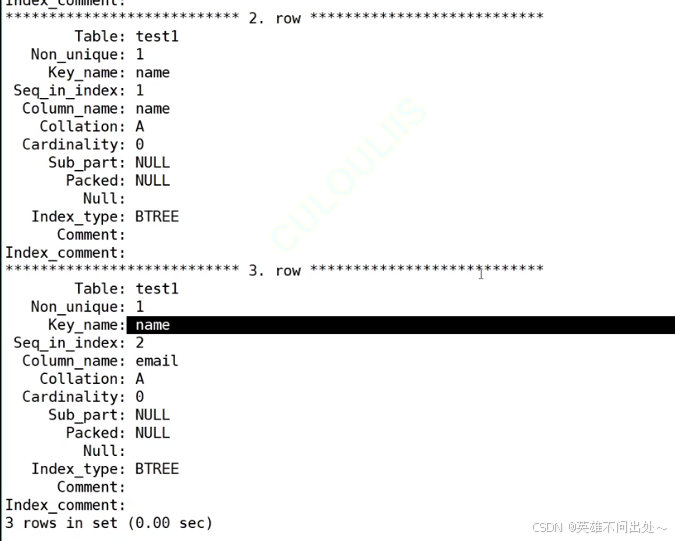
查询索引
-
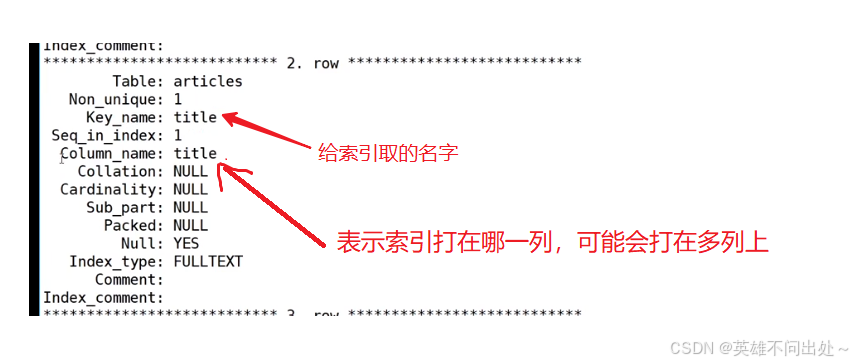
第一种方式:show keys from 表名;

-
第二种方式:show index from 表名;
-
第三种方式:desc 表名;
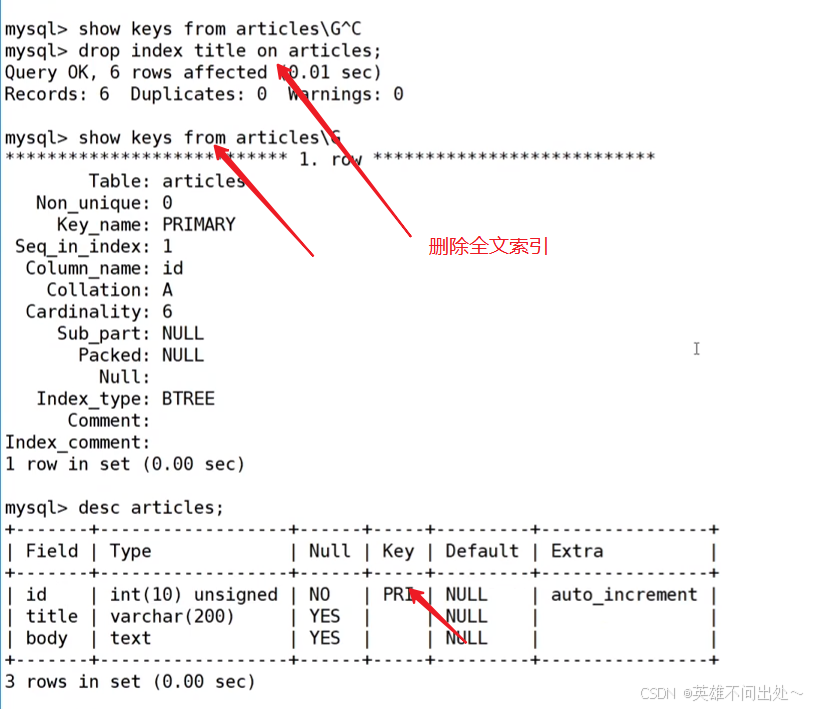
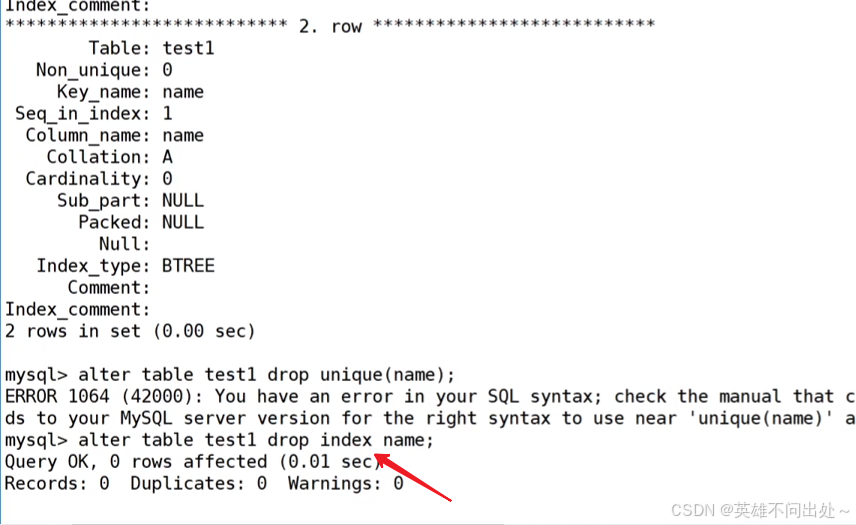
删除索引
- 第一种方法-删除主键索引:
alter table 表名 drop primary key; - 第二种方法-其他索引的删除(包括普通索引,唯一键索引):
alter table 表名 drop index 索引名;
索引名就是show keys from 表名中的 Key_name 字段 - 第三种方法: drop index 索引名 on 表名
mysql> drop index name on user8;
索引创建原则
-
比较频繁作为查询条件的字段应该创建索引
-
唯一性太差的字段(比如性别)不适合单独创建索引,即使频繁作为查询条件
-
更新非常频繁的字段不适合作创建索引
-
不会出现在where子句中的字段不该创建索引
全文索引
- 当对文章字段或有大量文字的字段进行检索时,会使用到全文索引。MySQL提供全文索引机制,但是有要求,要求表的存储引擎必须是MyISAM ,而且默认的全文索引支持英文,不支持中文。如果对中文进行全文检索,可以使用sphinx的中文版(coreseek)。
建表
CREATE TABLE articles (id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,title VARCHAR(200),body TEXT,// 文本FULLTEXT (title,body))engine=MyISAM;
插入数据
INSERT INTO articles (title,body) VALUES(\'MySQL Tutorial\',\'DBMS stands for DataBase ...\'),(\'How To Use MySQL Well\',\'After you went through a ...\'),(\'Optimizing MySQL\',\'In this tutorial we will show ...\'),(\'1001 MySQL Tricks\',\'1. Never run mysqld as root. 2. ...\'),(\'MySQL vs. YourSQL\',\'In the following database comparison ...\'),(\'MySQL Security\',\'When configured properly, MySQL ...\');
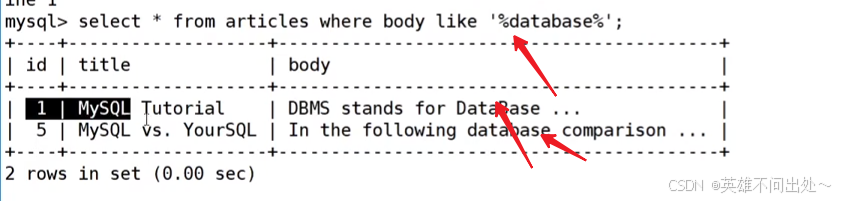
对列的内容进行查询
查询包含database字段的数据
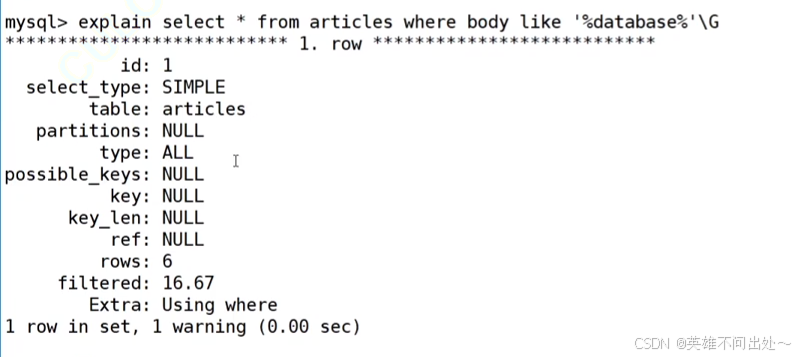
2. 可以用explain工具看一下,是否使用到索引
3. key为NULL表示没有用到全文索引
4. 如何使用全文索引呢?
select * from articleswhere match(title,body) against(\'database\');// against表示匹配关键字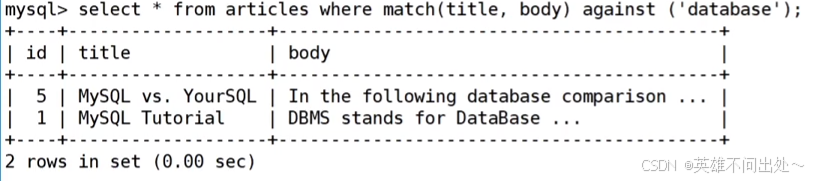

column_name是表中实际存在的列名
key_name是有索引的列名