STM32 DMA的理论学习附带个人思路分析!!(启蒙基础版~)_stm32f7的dma和eth dma有什么区别?
(笔者的话:写下这一行字的时候我也完全不知道DMA是什么东西,希望我写到最后一张的时候能知道,也希望你们能知道)
概论
那我们先来思考一下两个问题
1.什么是DMA?
2.为什么需要DMA?
(想要学习DMA,哪最开始肯定要从这个名字理解起喽,于是乎我们了解了一下)
DMA,全称Direct(直接) Memory(内存) Access(访问),官方学名为
“直接存储器访问”。
(但是众所周知在嵌入式开发学习中呢,没有任何一个名字是没有意义的)
如果DMA代表是直接访问,哪是不是说明,不使用DMA的情况,STM32并不能直接访问内存
呢?
答:当然不是,STM32的cpu可以随时随地的访问内存.
而着给直接存储器访问的意思是其实是指,外设和存储器之前的交互,虽然上面说了stm32的cpu可以直接访问内存,但是外设却做不到这点,外设则需要通过stm32的cpu这个中转站来进行内存访问.
传统(无 DMA 的系统中)外设(如 UART、ADC)访问内存的方式为:
外设 → CPU 寄存器 → 内存
那么问题来了,如果外设访问内存,都需要经过cpu,那么当大量外设都需要一直访问内存的时候,cpu岂不是不用执行其他任务了,cpu的资源被耗尽.
于是乎,我们是不是得自己想个办法专门来处理外设和内存之间的访问问题,于是恭喜你,你发明了DMA
(不用我们自己想,牛逼前辈们,早就想到了这一点,所以DMA应运而生)
那经过我们上面的这一段思考,我们已经知道了DMA到底是啥!
总结:
1.什么是DMA?
DMA(Direct Memory Access,直接内存访问) 是一种计算机硬件技术,允许外设(如硬盘、网卡、传感器)与系统内存(RAM)之间直接传输数据,无需CPU全程参与。其核心目标是提升数据传输效率,减少CPU的资源占用。
2.为什么需要DMA?
在传统数据传输模式中,CPU需要全程干预外设与内存的交互, 外设 → CPU 寄存器 → 内存
- CPU的痛点:
- 频繁占用总线,导致其他任务延迟(如实时响应按键输入)。
- 需要逐字节/逐块搬运数据,消耗计算资源。
-
DMA的解决方案:
引入DMA控制器(DMAC),接管数据传输任务: 外设 → DMA控制器 → 内存- CPU的角色:仅初始化传输参数,并在完成后处理数据。
那么通过使用DMA,外设和数据之间就能进行绕过CPU的访问,就不再需要频繁的占用CPU资源
二.stm32中的DMA
了解了DMA的基本概念那我们来看看他的实际应用依旧是STM32F407ZET6为例
DMA的特点

在数据手册里找到DMA相关的内容,这里提到了这款芯片里有两个DMA控制器分别是DMA1和DMA2,每个控制器有8个通道,他们能处理从内存到外设的各种相关操作,他们专门为APB和AHB设计了专用的FIFO(先进先出缓冲区),来适配他的这个总线的速度
(后面的大概是说他提供了双缓冲模式,可以自动切换,不用软件干预啥的,他说不用代码干预,我们就暂时放在一边.)
数据手册先看到这里,我看了一下后面有提到DMA的相关内容,大部分都是告诉你某某外设可以使用DMA传输数据,还有就是DMA的功耗大小,以后使用到相关内容的时候我们再去看.
STM32DMA外设
既然DMA也是外设的一种,那我们自然可以在外设手册里找到他

这个简介理论学习我们已经在上面去了解过了,这个总线矩阵架构在数据手册里也有提到:长这个样子
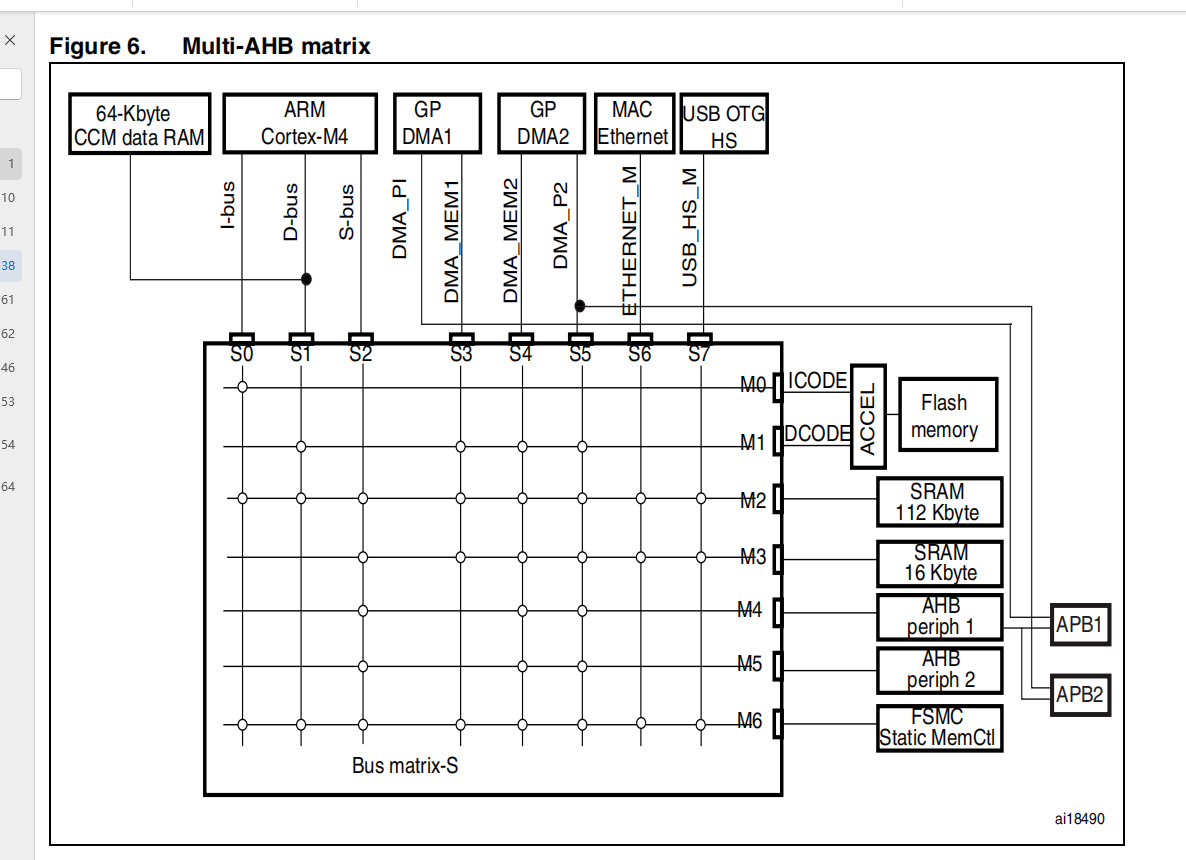
STM32DMA的主要特性

DMA控制器主要特性(从文档中,解读了一部分出来)
- 双AHB总线架构:独立总线分别处理存储器与外设访问,优化系统带宽。
- 高性能数据传输:
- 支持32位地址/数据访问,每个DMA控制器含8个数据流,每个数据流最多8个通道。
- 每个数据流配备32位四级FIFO缓冲区,支持FIFO模式(可配置阈值:1/4、1/2、3/4 FIFO大小)与直接传输模式。
- 灵活传输模式:
- 支持外设→存储器、存储器→外设、存储器→存储器三类传输方向。
- 源/目标地址支持增量/非增量寻址,突发传输支持4/8/16节拍(软件可配置突发大小,通常匹配外设FIFO)。
- 智能管理机制:
- 循环缓冲区管理:每个数据流独立支持,简化循环数据处理。
- 数据宽度自适应:源与目标数据宽度相同时自动转换位宽(FIFO模式下可用)。
- 优先级与仲裁:
- 数据流级优先级:8个数据流优先级可通过软件配置(4级:非常高、高、中、低)。
- 通道级仲裁:每个数据流内8个通道由硬件仲裁器管理优先级。
- 事件与中断:
- 5个独立事件标志(传输完成、FIFO错误、传输错误、直接模式错误、半传输完成),支持逻辑或运算生成单中断请求。
- 高效外设协同:
- 支持外设通过DMA触发传输(仅需配置通道请求),直接利用AHB总线矩阵启动传输,减少CPU干预。
核心优势:高速数据搬运、低CPU占用、灵活配置,适用于外设通信、存储器间数据交互等高频场景。
(如果你想仔细了解,还是去手册里找原版文档)
接下来我们对照着这个特性看框图!

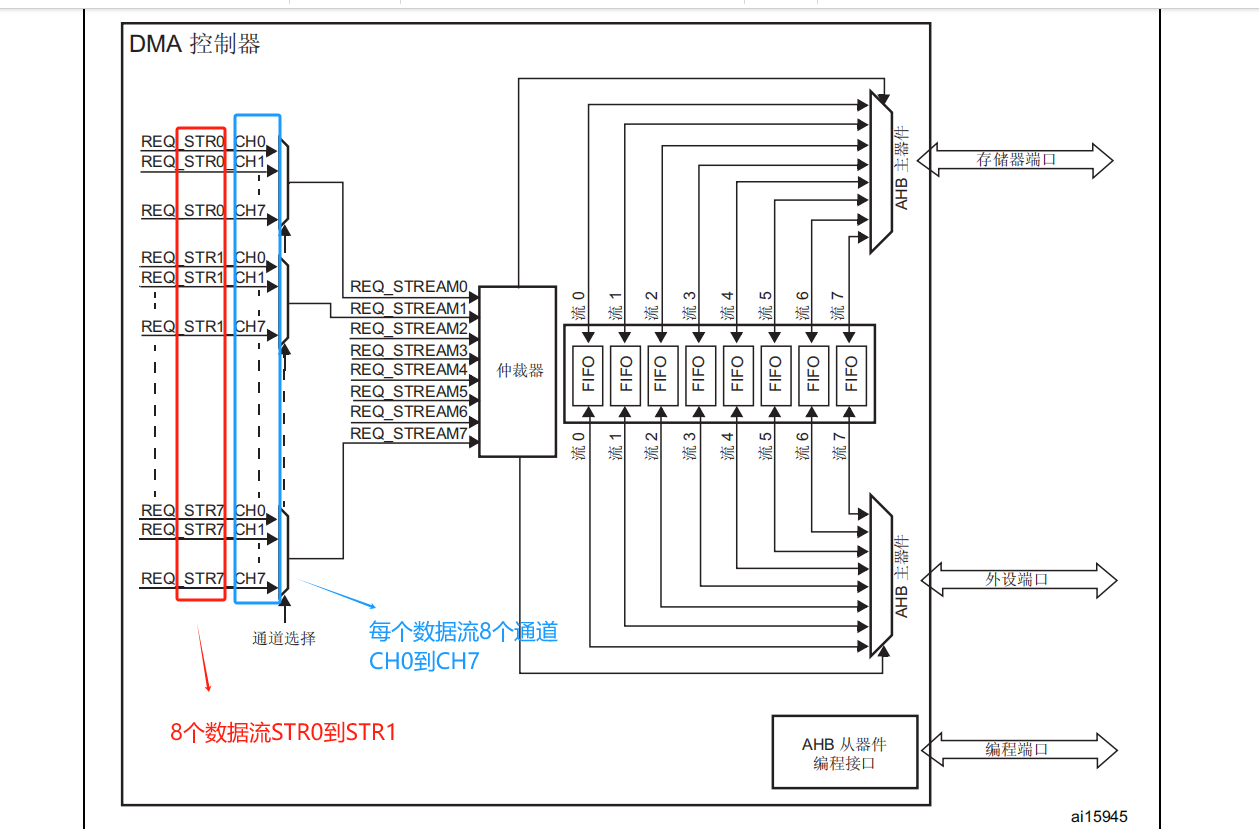
那我们从左边看起,根据主要特性里面讲的,DMA有8个数据流,每个数据流有8个通道正好对照着框图,左边红色蓝色方框的部分.“CH”在stm32中一般指通道,STR我暂时也不知道是啥意思,于是我们可以反推一下,如果我们猜测的不错应该指代的是数据流的意思,

str正是stream的缩写
验证完毕,那我们上面的分析完全正确
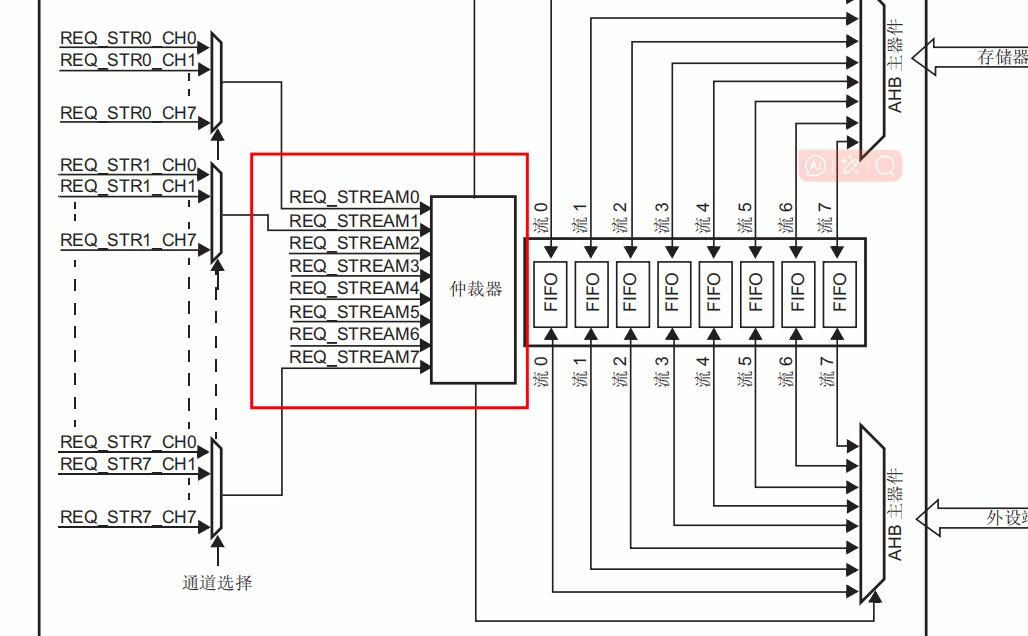
那我们继续来解释中间的这个部分,我们可以看到有8条线路连接到仲裁器,这就是8个数据流啦,每个数据流对应8个通道

这里描述的有点抽象,根据查阅资料,大概是说:8个流各自汇总其8个通道的请求,生成1个流请求信号(REQ_STREAMx)送给仲裁器,其实有8个仲裁器,每个数据流都有一个.

然后仲裁器会根据优先级,来对数据流进行处理,每个数据流都有一个仲裁器.

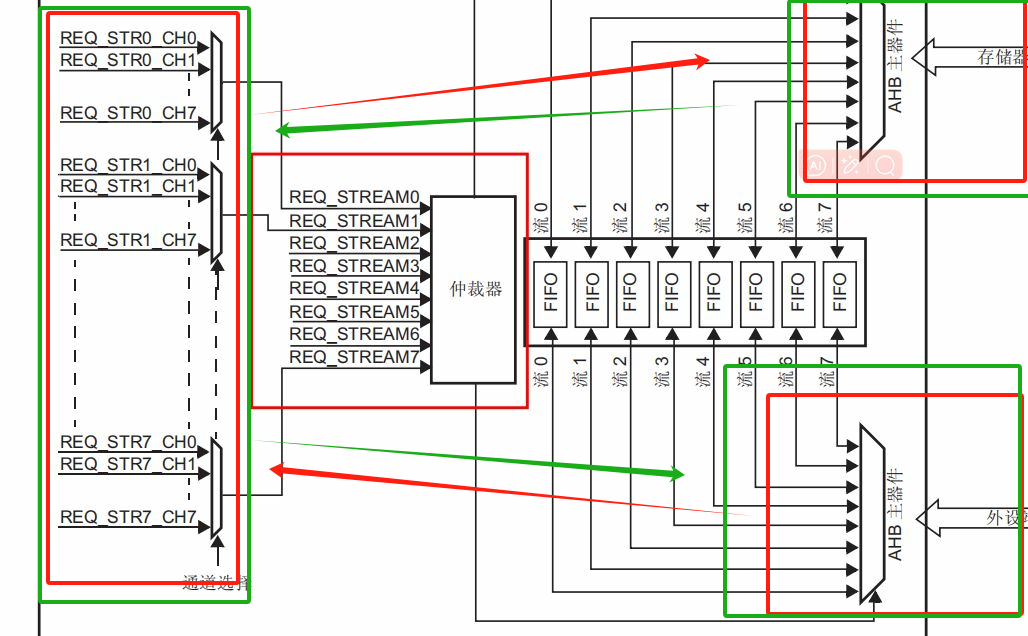
上图红色部分大概就是存储器到外设了,绿色方框部分是外设到存储器,而第三种模式存储器到存储器也大致是这样的流程.
那么框图部分就简单介绍完了,虽然还有一些东西我们没有看到,但是已经初步了了解一下DMA的框图.
笔者的话:这篇简单的DMA入门的的讲解其实过于简陋了,但是正如笔者所说,笔者也是自己纯看手册学习这个内容,希望看手册的思路上能给初学者一点帮助.要想掌握的更加熟悉还是要结合代码实践.笔者也算是个初学者,如果后面写了相关代码,我在补一篇进阶版。


