深入浅出一下从电子商务到社交网络:排序算法在实际业务中的关键角色——动画可视化排序算法(完结撒花!)

本篇技术博文摘要 🌟
本文全面解析了排序算法的核心理论、经典实现及优化策略,构建了从基础到高阶的完整知识体系。通过动画可视化与多语言代码示例相结合的方式,系统阐述了以下内容:
排序基础与分类
定义与指标:排序的本质是调整数据顺序以满足单调性,评价维度涵盖时间复杂度、空间复杂度、稳定性与适应性。
算法分类:划分为比较排序(插入/交换/选择/归并)与非比较排序(基数/桶/计数),并区分内部排序(内存操作)与外部排序(外存交互)。
经典排序算法详解
插入排序:直接插入排序通过逐元素比较实现有序扩展,引入哨兵优化边界判断;折半插入排序利用二分查找减少比较次数;希尔排序以增量分组提升效率。
交换排序:冒泡排序通过相邻元素交换逐步“浮出”极值;快速排序以分治思想选取枢轴实现高效划分,需优化枢轴选择与递归深度控制。
选择排序:简单选择排序遍历选择极值;堆排序基于大根堆/小根堆结构实现动态极值维护,时间复杂度稳定为O(n logn)。
归并排序:分治策略合并有序子序列,稳定性强,适用于外部排序场景。
基数排序:按关键字位分配与收集数据,适用于整数或字符串排序,时间复杂度达O(n)。
高级主题与优化
外部排序:针对海量数据,通过置换-选择排序生成初始归并段,结合多路平衡归并与最佳归并树减少I/O开销。
败者树:加速多路归并的比较过程,降低全局排序时间。
堆操作:插入时“上浮”调整,删除时“下沉”重建堆结构,分析关键字对比次数优化性能。
性能对比与实践应用
效率分析:
O(n²)算法(冒泡、简单选择)适合小规模数据;
O(n logn)算法(快排、堆排、归并)为通用高效选择;
O(n)算法(基数排序)受限于数据类型。
稳定性:插入、冒泡、归并、基数排序保持稳定,适用于需保留原始顺序的场景。
工程实践:
快速排序需警惕最坏时间复杂度,通过三数取中法优化;
堆排序适合动态数据流场景(如实时Top-K问题);
基数排序广泛用于电话号码、日期排序等场景。
引言 📘
- 在这个变幻莫测、快速发展的技术时代,与时俱进是每个IT工程师的必修课。
- 我是盛透侧视攻城狮,一名什么都会一丢丢的网络安全工程师,也是众多技术社区的活跃成员以及多家大厂官方认可人员,希望能够与各位在此共同成长。
排序算法全动画合集
通过动画可视化算法之希尔排序算法(难度有点大,多看几遍)
通过动画可视化算法快速排序算法
通过动画可视化算法基数排序算法
通过动画可视化算法之归并排序
通过动画可视化算法计数排序算法
通过动画可视化算法之插入排序
通过动画可视化算法之选择排序
通过动画可视化算法之冒泡排序
二分查找/折半查找
通过动画可视化算法之堆排序算法(难度有点大,多看几遍)
上节回顾

排序
1.排序的基本概念
定义:
排序(Sort),就是重新排列表中的元素,使表中的元素满足按关键字有序的过程。
输入:n个记录R1, R2,…, Rn,对应的关键字为k1, k2,…, kn。
输出:输入序列的一个重排R1ʹ, R2ʹ,…, Rnʹ,使得有k1ʹ≤k2ʹ≤…≤knʹ(也可递减)
排序算法的评价指标:
时间复杂度
空间复杂度
算法的稳定性:
若待排序表中有两个元素Ri和Rj,其对应的关键字相同即keyi = keyj,且在排序前Ri在Rj的前面
若使用某一排序算法排序后,Ri仍然在Rj的前面
则称这个排序算法是稳定的,否则称排序算法是不稳定的。
排序算法的分类:
内部排序:数据都在内存中,关注如何使算法时、空复杂度更低
外部排序:数据太多,无法全部放入内存,还要关注如何使读/写磁盘次数更少
2.动画可视化之插入排序
通过动画可视化算法之插入排序
2.1算法思想:
- 每次将一个待排序的记录按其关键字大小插入到前面已排好序的子序列中,直到全部记录插入完成。
代码实现:
(1):直接插入排序
void InsertSort(int A[],int n){ int i,j,temp; for(i=1;i<n;i++) //将各元素插入已排好序的序列中 if(A[i]=0 && A[j]>temp;--j) //检查所有前面已排好序的元素 A[j+1]=A[j]; //所有大于temp的元素都向后挪位 A[j+1]=temp; //复制到插入位置 }}(2):直接插入排序(带哨兵)
void InsertSort(int A[],int n){ int i,j; for(i=2;i<=n;i++) //依次将A[2]~A[n]插入到前面已排序序列 if(A[i]<A[i-1]){ //若A[i]关键码小于其前驱,将A[i]插入有序表 A[0]=A[i]; //复制为哨兵,A[0]不存放元素 for(j=i-1;A[0]<A[j];--j)//从后往前查找待插入位置 A[j+1]=A[j]; //向后挪位 A[j+1]=A[0]; //复制到插入位置 }}算法效率分析:
空间复杂度:O(1)
时间复杂度:主要来自对比关键字、移动元素,若有 n 个元素,则需要 n-1 趟处理
最好时间复杂度:O(n) 共n-1趟处理,每一趟只需要对比关键字1次,不用移动元素
最坏时间复杂度:O(n^2) 共n-1趟处理,每一趟都需要从尾移到到头(全部逆序)
算法稳定性:稳定
2.2动画可视化之—折半插入排序:
二分查找/折半查找
思路:
先用折半查找找到应该插入的位置,再移动元素
当 low>high 时折半查找停止,应将 [low, i-1] 内的元素全部右移,并将 A[0] 复制到 low 所指位置
当 A[mid]==A[0] 时,为了保证算法的“稳定性”,应继续在 mid 所指位置右边寻找插入位置
代码实现:
void InsertSort(int A[],int n){ int i,j,low,high,mid; for(i=2;i<=n;i++){ //依次将A[2]~A[n]插入前面的已排序序列 A[0]=A[i]; //将A[i]暂存到A[0] low=1;high=i-1; //设置折半查找的范围 while(lowA[0]) high=mid-1; //查找左半子表 else low=mid+1; //查找右半子表 } for(j=i-1;j>=high+1;--j) A[j+1]=A[j]; //统一后移元素,空出插入位置 A[high+1]=A[0]; //插入操作 }}优化后的效率
- 比起“直接插入排序”,比较关键字的次数减少了,但是移动元素的次数没变,整体来看时间复杂度依然是O(n^2)
对链表进行插入排序:
使用链表不需要对序列进行依次右移,移动元素的次数变少了
但是关键字对比的次数依然是O(n^2) 数量级,整体来看时间复杂度依然是O(n^2)
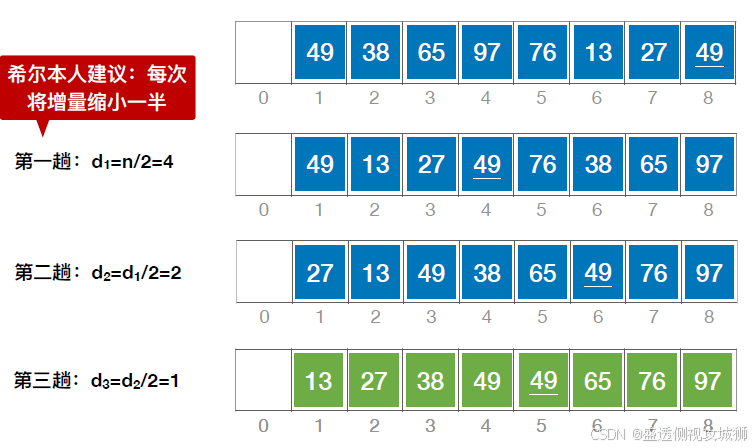
3.动画可视化之希尔排序
通过动画可视化算法之希尔排序算法(难度有点大,多看几遍)
算法思想:
先追求表中元素部分有序,再逐渐逼近全局有序
先将待排序表分割成若干形如 L[i, i + d, i + 2d,…, i + kd] 的“特殊”子表,对各个子表分别进行直接插入排序。缩小增量d,重复上述过程,直到d=1为止。
代码实现:
void ShellSort(int A[],int n){ int d, i, j; //A[0]只是暂存单元,不是哨兵,当j=1; d=d/2) //步长变化 for(i=d+1; i<=n; ++i) if(A[i]0 && A[0]<A[j]; j-=d) A[j+d]=A[j]; //记录后移,查找插入的位置 A[j+d]=A[0]; //插入 }//if}算法性能分析:
空间复杂度:O(1)
时间复杂度:
和增量序列 d1, d2, d3… 的选择有关,目前无法用数学手段证明确切的时间复杂度
最坏时间复杂度为 O(n^2),当n在某个范围内时,可达O(n^1.3)
稳定性:不稳定
适用性:仅适用于顺序表,不适用于链表
4.动画可视化之冒泡排序
通过动画可视化算法之冒泡排序
交换排序分类:
冒泡排序
选择排序
算法思想:
从后往前(或从前往后)两两比较相邻元素的值,若为逆序(即A[i-1]>A[i]),则交换它们,直到序列比较完
这样过程称为“一趟”冒泡排序
第n趟结束后,最小的n个元素会“冒”到最前边
若某一趟排序没有发生“交换”,说明此时已经整体有序。
可以从后往前冒泡,也可以从前往后冒泡
代码实现:
//交换void swap(int &a, int &b){ int temp = a; a = b; b = temp;}//冒泡排序void BubbleSort(int A[],int n){ for(int i=0;ii;j--) //一趟冒泡过程 if(A[j-1]>A[j]){ //若为逆序 swap(A[j-1],A[j]); //交换 flag=true; } if(flag==false) return; //本趟遍历后没有发生交换,说明表已经有序 }}算法性能分析:
空间复杂度:O(1)
时间复杂度:
最好情况(有序):O(n)
最坏情况(逆序):O(n^2)
平均情况:O(n^2)
稳定性:稳定
适用性:顺序表、链表都可以

5.动画可视化之快速排序
通过动画可视化算法快速排序算法
算法思想:
在待排序表L[1…n]中任取一个元素pivot作为枢轴(或基准,通常取⾸元素)
通过一趟排序将待排序表划分为独立的两部分L[1…k-1]和L[k+1…n]
使得L[1…k-1]中的所有元素小于pivot,L[k+1…n]中的所有元素大于等于pivot
则pivot放在了其最终位置L(k)上,这个过程称为一次“划分”
然后分别递归地对两个子表重复上述过程,直至每部分内只有一个元素或空为止,即所有元素放在了其最终位置上
代码实现:
//用第一个元素将待排序列划分成左右两个部分int Partition(int A[],int low,int high){ int pivot=A[low]; //第一个元素作为枢轴 while(low<high){ //用low、high搜索枢轴的最终位置 while(low=pivot) --high; A[low]=A[high]; //比枢轴小的元素移动到左端 while(low<high&&A[low]<=pivot) ++low; A[high]=A[low]; //比枢轴大的元素移动到右端 } A[low]=pivot; //枢轴元素存放到最终位置 return low; //返回存放枢轴的最终位置}算法性能分析:
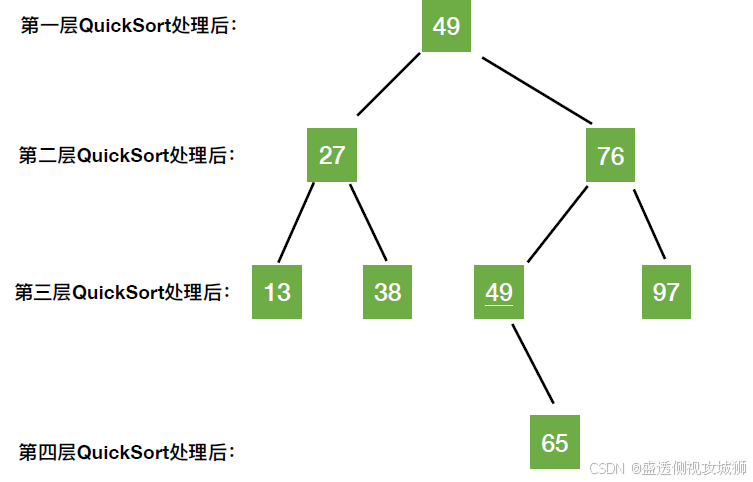
- n个结点的二叉树
-
最小高度 = ⌊log2n⌋ + 1
-
最大高度 = n
-
-
时间复杂度=O(n*递归层数)
-
最好时间复杂度=O(nlog2n)
-
每次选的枢轴元素都能将序列划分成均匀的两部分
-
-
最坏时间复杂度=O(n^2)
-
若序列原本就有序或逆序,则时、空复杂度最高(可优化,尽量选择可以把数据中分的枢轴元素。)
-
-
- 空间复杂度=O(递归层数)
-
最好空间复杂度=O(log2n)
-
最坏空间复杂度=O(n)
-
快速排序算法的缺点
若每一次选中的“枢轴”将待排序序列划分为很不均匀的两个部分,则会导致递归深度增加,算法效率变低
若初始序列有序或逆序,则快速排序的性能最差(因为每次选择的都是最靠边的元素)
快速排序算法优化思路:
- 尽量选择可以把数据中分的枢轴元素。
选头、中、尾三个位置的元素,取中间值作为枢轴元素;
随机选一个元素作为枢轴元素
快速排序性能:
快速排序是所有内部排序算法中平均性能最优的排序算法
稳定性:不稳定

6.动画可视化之简单选择排序
通过动画可视化算法之选择排序
选择排序分类:
-
简单选择排序
-
堆排序
6.1简单选择排序算法思想:
- 每一趟在待排序元素中选取关键字最小(或最大)的元素(每一趟待排序序列长度-1)加入有序子序列(每一趟有序序列长度+1)
代码实现:
//交换void swap(int &a, int &b){ int temp = a; a = b; b = temp;}//简单选择排序void SelectSort(int A[],int n){ for(int i=0;i<n-1;i++){ //一共进行n-1趟 int min=i; //记录最小元素位置 for(int j=i+1;j<n;j++) //在A[i...n-1]中选择最小的元素 if(A[j]<A[min]) min=j; //更新最小元素位置 if(min!=i) swap(A[i],A[min]); //封装的swap()函数共移动元素3次 }}算法性能分析:
无论有序、逆序、还是乱序,一定需要 n-1 趟处理
总共需要对比关键字 (n-1)+(n-2)+…+1=[n(n-1)]/2次
元素交换次数 < n-1
空间复杂度:O(1)
时间复杂度=O(n^2)
稳定性:不稳定
适用性:既可以用于顺序表,也可用于链表
7.动画可视化之堆排序
通过动画可视化算法之堆排序算法(难度有点大,多看几遍)
堆的定义:
- 若n个关键字序列L[1…n] 满足下面某一条性质,则称为堆(Heap):
- 若满足:L(i)≥L(2i)且L(i)≥L(2i+1) (1 ≤ i ≤n/2 )则为大根堆(大顶堆)
即完全二叉树中,任意根≥左、右
若满足:L(i)≤L(2i)且L(i)≤L(2i+1) (1 ≤ i ≤n/2 )则为小根堆(小顶堆)
即完全二叉树中,任意根≤左、右
7.2.1建立大根堆:
- 把所有非终端结点都检查一遍,是否满足大根堆的要求,如果不满足,则进行调整
在顺序存储的完全二叉树中,非终端结点编号 i≤⌊n/2⌋
检查当前结点是否满足 根≥左、右,若不满足,将当前结点与更大的一个孩子互换
i的左孩子:2i
i的右孩子:2i+1
i的父结点:⌊i/2⌋
若元素互换破坏了下一级的堆,则采用相同的方法继续往下调整(小元素不断“下坠”)
建立大根堆代码实现:
//建立大根堆void BuildMaxHeap(int A[],int len){ for(int i=len/2;i>0;i--) //从后往前调整所有非终端结点 HeadAdjust(A,i,len);}//将以 k 为根的子树调整为大根堆void HeadAdjust(int A[],int k,int len){ A[0]=A[k]; //A[0]暂存子树的根结点 for(int i=2*k;i<=len;i*=2){ //沿key较大的子结点向下筛选 if(i<len&&A[i]=A[i]) break; //筛选结束 else{ A[k]=A[i]; //将A[i]调整到双亲结点上 k=i; //修改k值,以便继续向下筛选 } } A[k]=A[0]; //被筛选结点的值放入最终位置}7.2.2基于大根堆进行排序:
选择排序:每一趟在待排序元素中选取关键字最大的元素加入有序子序列
堆排序每一趟完成以下工作:
将堆顶元素(就是最大的元素)加入有序子序列(与待排序序列中的最后一个元素交换)
并将待排序元素序列再次调整为大根堆(小元素不断“下坠”)
注意:大根堆获得的排序序列是递增序列,小跟堆相反,获得的是递减序列
大根堆排序代码实现:
//建立大根堆void BuildMaxHeap(int A[],int len){ for(int i=len/2;i>0;i--) //从后往前调整所有非终端结点 HeadAdjust(A,i,len);}//堆排序的完整逻辑void HeapSort(int A[],int len){ BuildMaxHeap(A,len); //初始建堆 for(int i=len;i>1;i--){ //n-1趟的交换和建堆过程 swap(A[i],A[1]); //堆顶元素和堆底元素交换 HeadAdjust(A,1,i-1); //把剩余的待排序元素整理成堆 }}//将以 k 为根的子树调整为大根堆void HeadAdjust(int A[],int k,int len){ A[0]=A[k]; //A[0]暂存子树的根结点 for(int i=2*k;i<=len;i*=2){ //沿key较大的子结点向下筛选 if(i<len&&A[i]=A[i]) break; //筛选结束 else{ A[k]=A[i]; //将A[i]调整到双亲结点上 k=i; //修改k值,以便继续向下筛选 } } A[k]=A[0]; //被筛选结点的值放入最终位置}堆排序的效率分析:
建堆的过程,关键字对比次数不超过4n,建堆时间复杂度=O(n)
堆排序的时间复杂度 =O(n) + O(nlog2n) = O(nlog2n)
堆排序的空间复杂度 =O(1)
稳定性:不稳定
7.3动画可视化之堆的插入删除
通过动画可视化算法之堆排序算法(难度有点大,多看几遍)
基本操作:
-
i的左孩子:2i
-
i的右孩子:2i+1
-
i的父结点:⌊i/2⌋
在堆中插入新元素:
对于小根堆,新元素放到表尾,与父节点对比,若新元素比父节点更小,则将二者互换。
新元素就这样一路“上升”,直到无法继续上升为止
在堆中删除元素:
被删除的元素用堆底元素替代
然后让该元素不断“下坠”,直到无法下坠为止
关键字对比次数:
每次“上升”调整只需对比关键字1次
每次“下坠”调整可能需要对比关键字2次,也可能只需对比1次

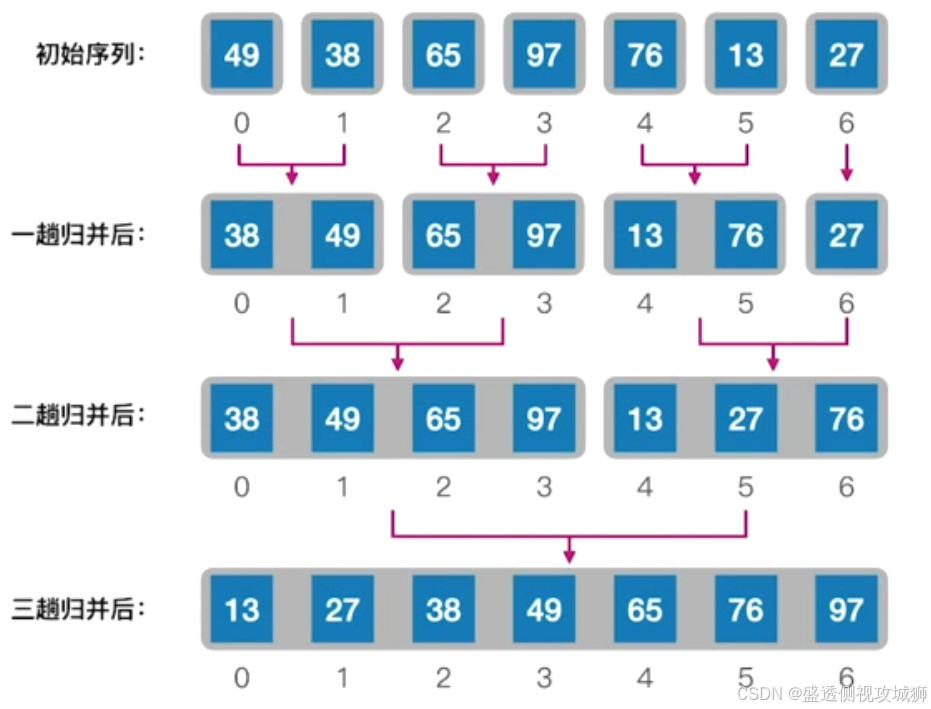
7.动画可视化之归并排序
通过动画可视化算法之归并排序
算法思想:
把两个或多个已经有序的序列合并成一个
对于两个有序序列,将i、j指针指向序列的表头,选择更小的一个放入k所指的位置
k++,i/j指向更小元素的指针++
只剩一个子表未合并时,可以将该表的剩余元素全部加到总表
m路归并:每选出一个小的元素,需要对比关键字m-1次
核心操作:把数组内的两个有序序列归并为一个
代码实现:
// 归并排序主函数void MergeSort(int A[],int low,int high){ if(low<high){ int mid=(low+high)/2; //从中间划分 MergeSort(A,low,mid); //对左半部分归并排序 MergeSort(A,mid+1,high); //对右半部分归并排序 Merge(A,low,mid,high); //归并 }//if}// 辅助数组B,这里假设n已定义int *B=(int *)malloc(n*sizeof(int)); // 归并函数,将两个有序部分A[low...mid]和A[mid+1...high]归并void Merge(int A[],int low,int mid,int high){ int i,j,k; for(k=low;k<=high;k++) B[k]=A[k]; //将A中所有元素复制到B中 for(i=low,j=mid+1,k=i;i<=mid&&j<=high;k++){ if(B[i]<=B[j]) A[k]=B[i++]; //将较小值复制到A中 else A[k]=B[j++]; }//for while(i<=mid) A[k++]=B[i++]; while(j<=high) A[k++]=B[j++];}
low是数组中第一个有序序列的开始
mid是数组中第一个有序序列的结尾
high是数组中第二个有序序列的结尾
辅助数组B临时存放这两段有序序列
算法效率分析:
2路归并的“归并树”形态上就是一棵倒立的二叉树
二叉树的第h层最多有2 ^ (h-1)个结点,若树高为h,则应满足n <= 2 ^ (h-1),即h − 1 = ⌈log2n⌉
n个元素进行2路归并排序,归并趟数=⌈log2n⌉
每趟归并时间复杂度为O(n),则算法时间复杂度O(nlog2n)
空间复杂度=O(n),来自于辅助数组B
稳定性:稳定

8.动画可视化之基数排序
通过动画可视化算法基数排序算法
算法思想:
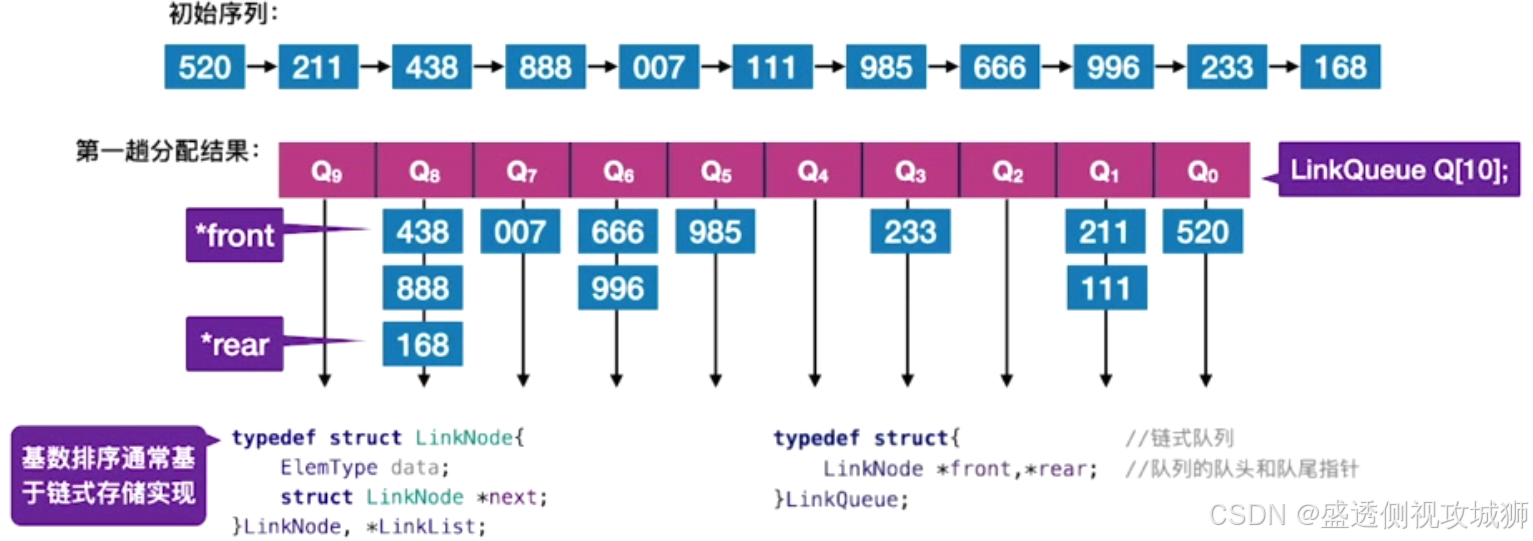
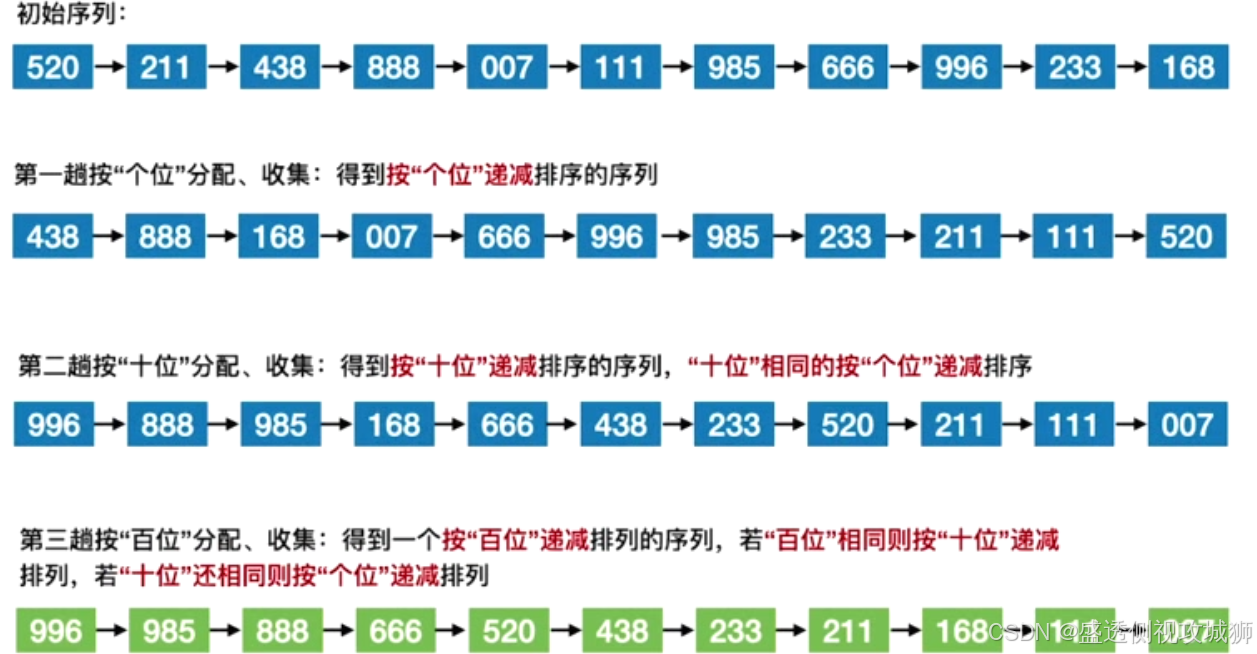
基数排序得到递减序列的过程如下:
初始化: 设置 r 个空队列,Qr-1, Qr-2,…, Q0
按照各个 关键字位 权重递增的次序(个、十、百),对 d 个关键字位分别做“分配”和“收集”
分配:顺序扫描各个元素,若当前处理的关键字位=x,则将元素插入 Qx 队尾
收集:把 Qr-1, Qr-2,…, Q0 各个队列中的结点依次出队并链接
基数排序得到递增序列的过程如下:
初始化: 设置 r 个空队列,Q0, Q1,…, Qr−1
按照各个 关键字位 权重递增的次序(个、十、百),对 d 个关键字位分别做“分配”和“收集”
分配:顺序扫描各个元素,若当前处理的关键字位=x,则将元素插入 Qx 队尾
收集:把 Q0, Q1,…, Qr−1 各个队列中的结点依次出队并链接
算法效率分析:
需要r个辅助队列,空间复杂度 = O(r)
一趟分配O(n),一趟收集O(r),总共 d 趟分配、收集,总的时间复杂度=O(d(n+r))
稳定性:稳定
基数排序的应用:
- 例如:
-
某学校有10000名学生,将学生信息按照年龄递减排序
-
给十亿人的身份证号排序
-
- 基数排序擅长解决的问题:
-
数据元素的关键字可以方便地拆分为 d 组,且 d 较小
-
每组关键字的取值范围不大,即 r 较小
-
数据元素个数 n 较大
-

9.动画可视化之外部排序
外存、内存的数据交换:
- 外存:
操作系统以“块”为单位对磁盘存储空间进行管理
如:每块大小 1KB各个磁盘块内存放着各种各样的数据
- 内存:
磁盘的读/写以“块”为单位
数据读入内存后才能被修改
修改完了还要写回磁盘
外部排序原理:
数据元素太多,无法一次全部读入内存进行排序
使用“归并排序”的方法,最少只需在内存或只能怪分配3块大小的缓冲区即可对任意一个大文件进行排序
”归并排序“要求各个子序列有序,每次读入两个块的内容,进行内部排序后写回磁盘
构造初始“归并段”:
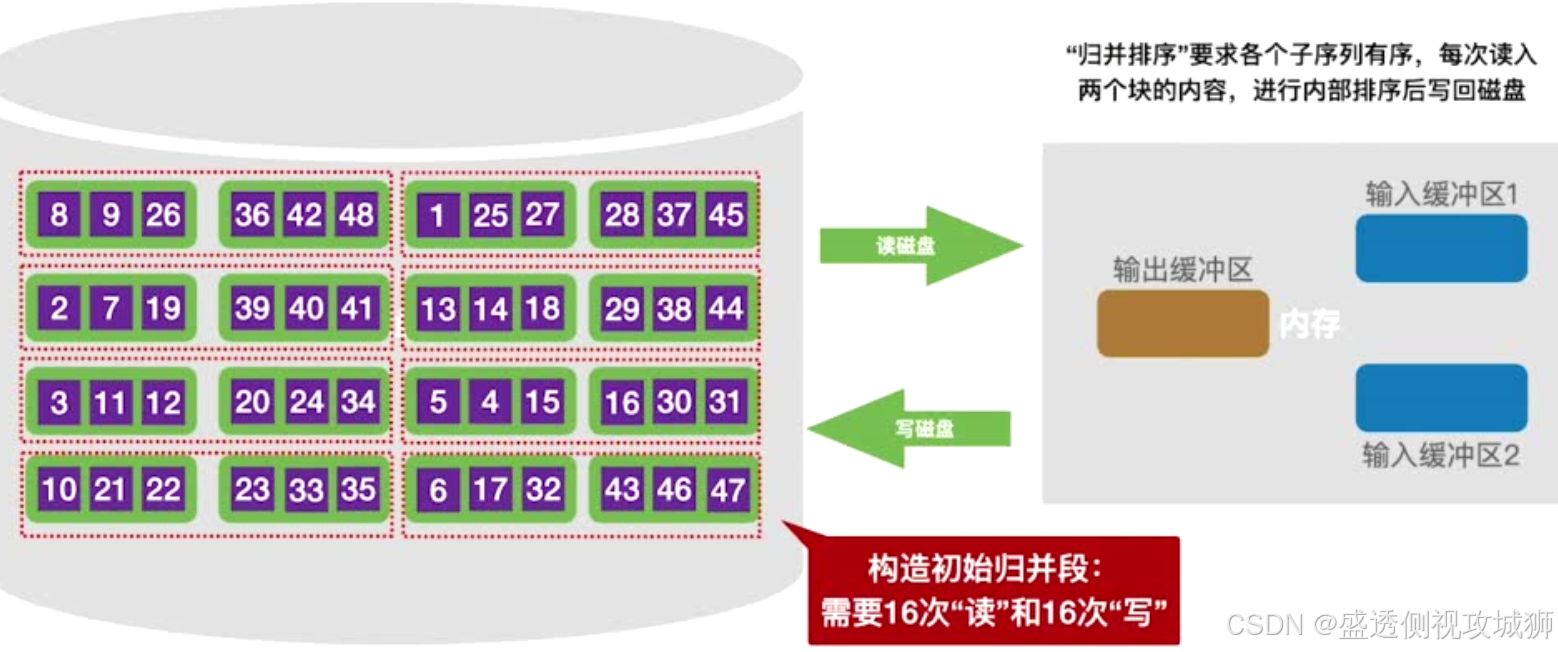
- 若有N个记录,内存工作区可以容纳L个记录,则初始归并段数量=r=N/L
第一趟归并:
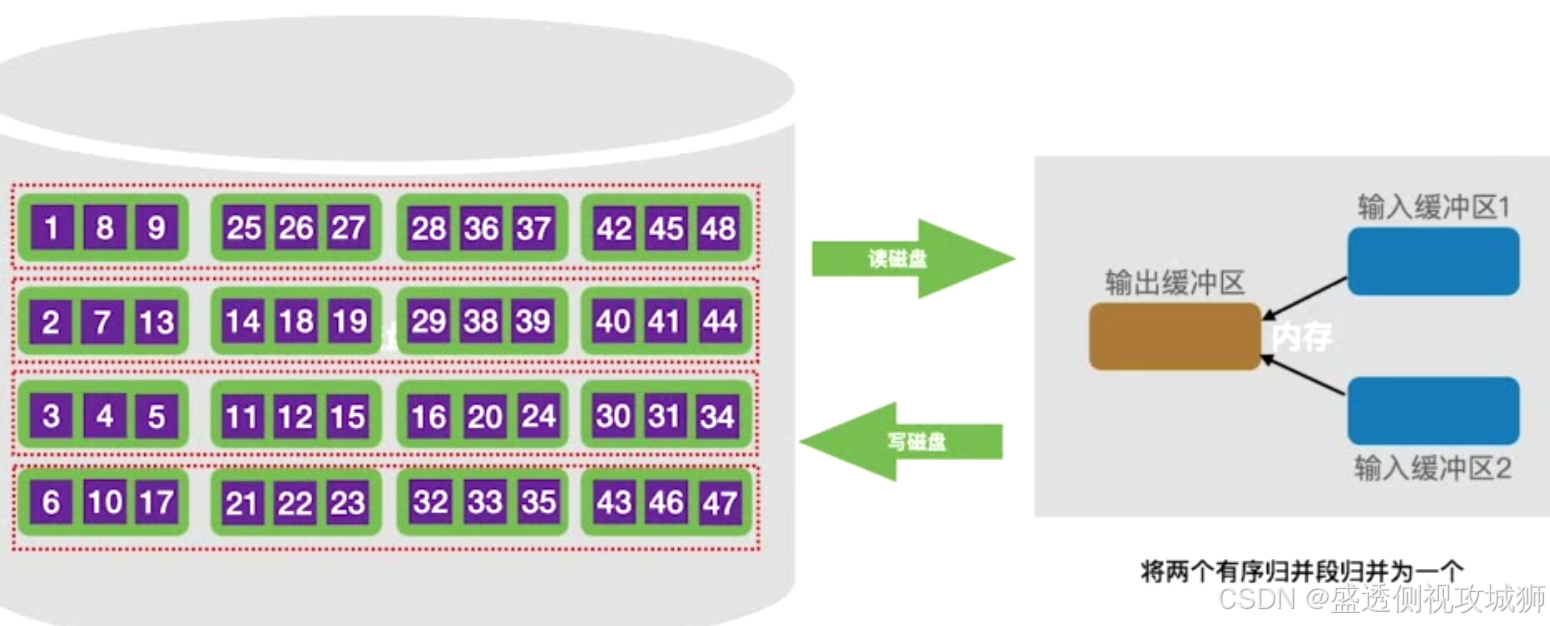
第二趟归并:
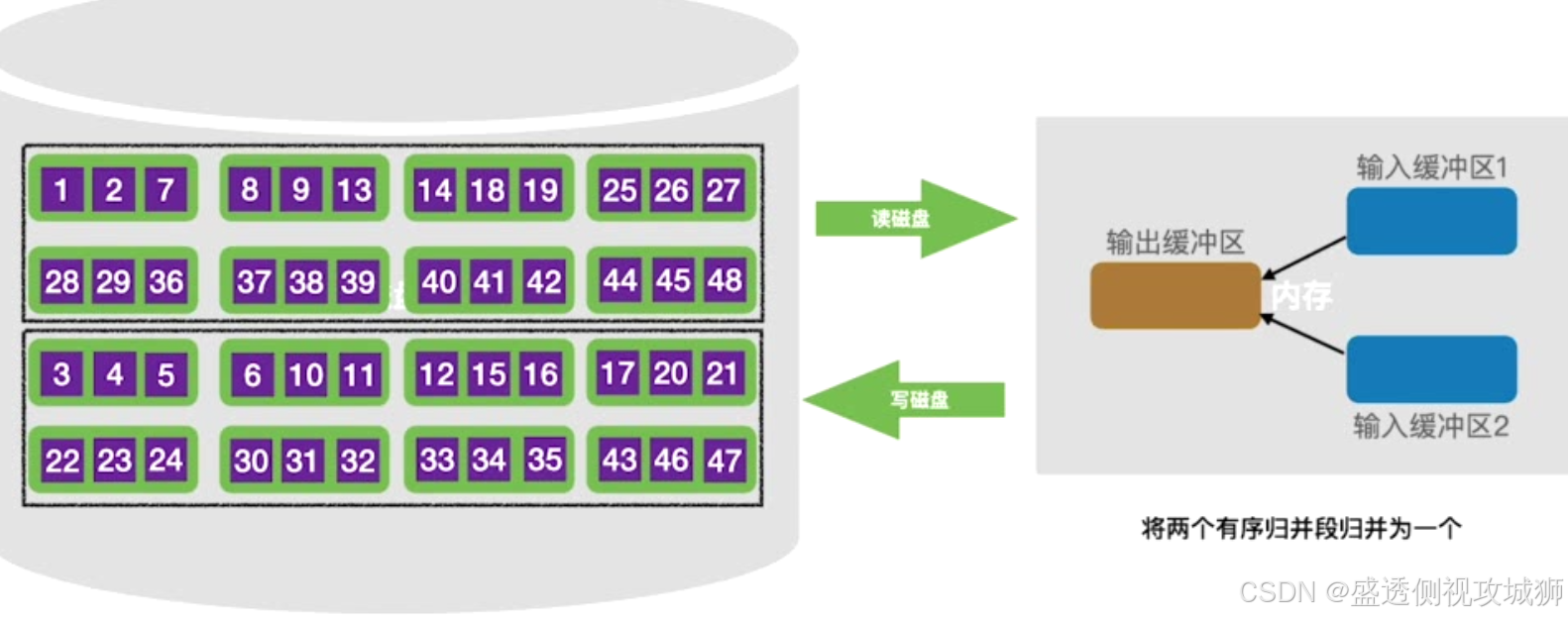
第三趟归并:

时间开销分析:
- 外部排序时间开销=读写外存的时间+内部排序所需时间+内部归并所需时间
归并排序的优化思路:
- 多路归并
采用多路归并可以减少归并趟数,从而减少磁盘I/O(读写)次数
对 r 个初始归并段,做k路归并,则归并树可用 k 叉树表示,若树高为h,则归并趟数 = h-1 = ⌈logkr⌉
推导:k叉树第h层最多有k^(h−1) 个结点,则r ≤ kh−1, (h-1)最小 = ⌈logkr⌉
k越大,r越小,归并趟数越少,读写磁盘次数越少
多路归并带来的负面影响:
k路归并时,需要开辟k个输入缓冲区,内存开销增加
每挑选一个关键字需要对比关键字(k-1)次,内部归并所需时间增加(可使用败者树优化)
减少初始归并段数量
生成初始归并段的“内存工作区”越大,初始归并段越长

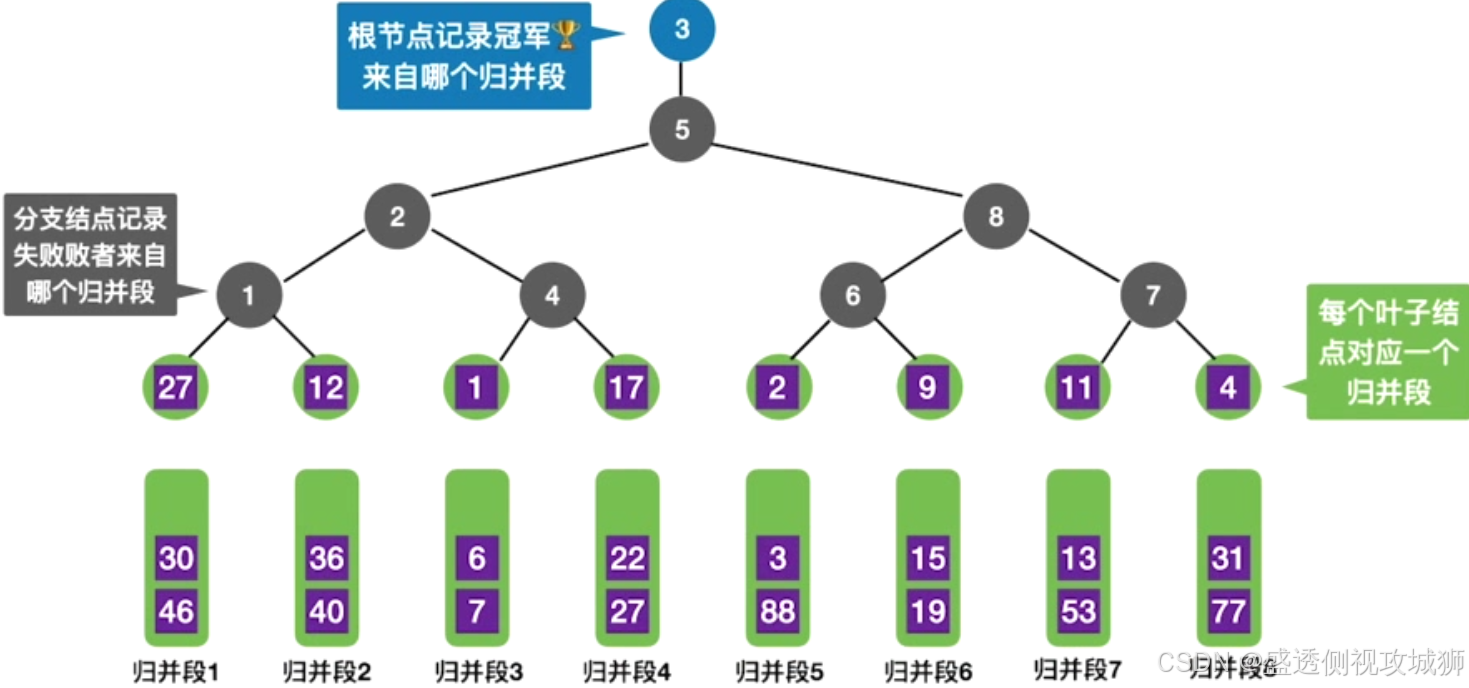
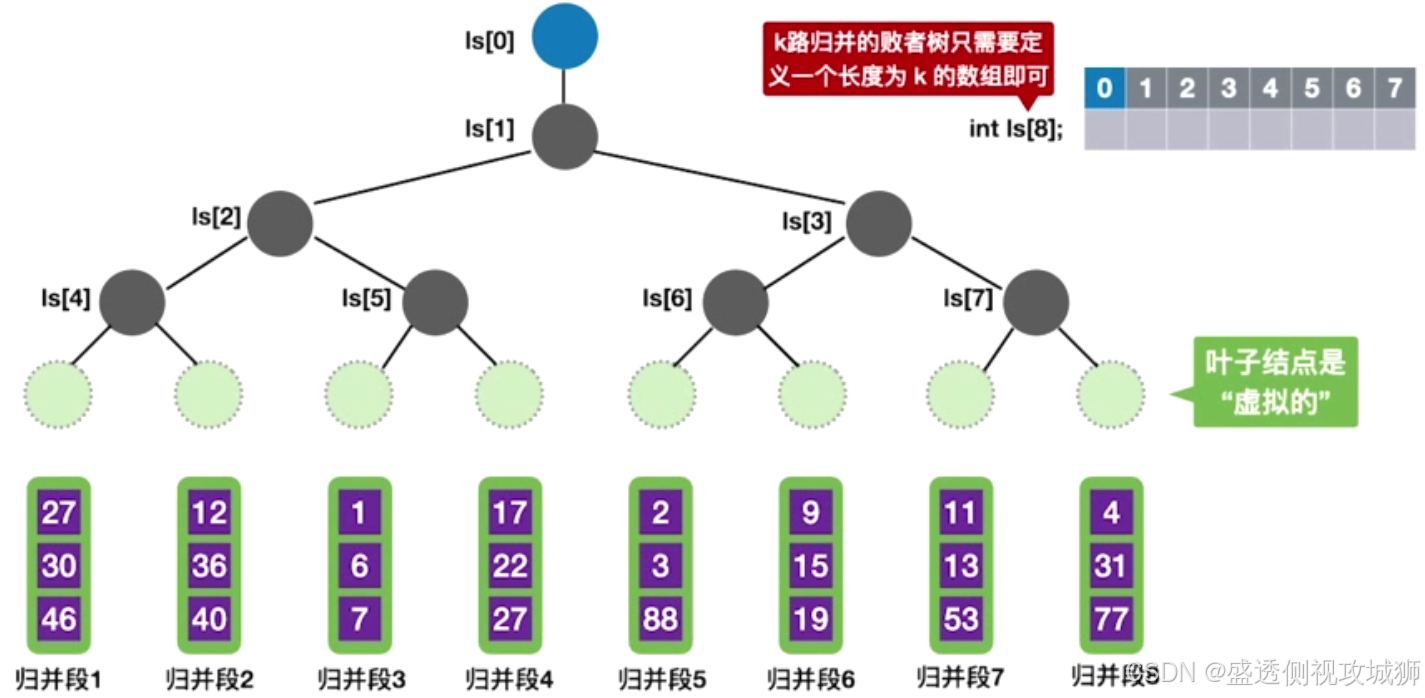
10.败者树
定义:
可视为一棵完全二叉树(多了一个头头)
k个叶结点分别是当前参加比较的元素,非叶子结点用来记忆左右子树中的“失败者”,而让胜者往上继续进行比较,一直到根结点。
即失败者留在这一回合,胜利者进入下一回合比拼
败者树在多路平衡归并中的应用:
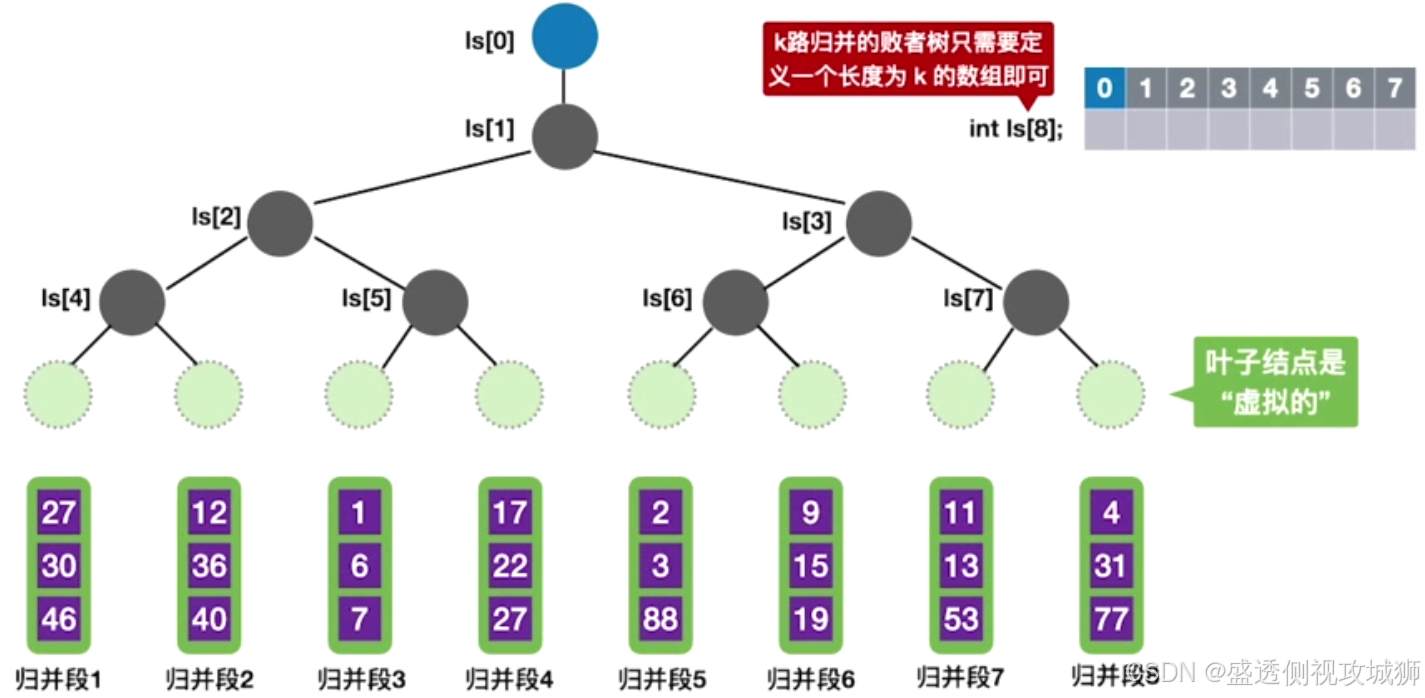
败者树的存储结构:

11置换-选择排序
-
使用置换-选择排序,可以让每个初始归并段的长度超过内存工作区大小的限制
-
设初始待排文件为FI,初始归并段输出文件为FO,内存工作区为WA,FO和WA的初始状态为空,WA可容纳w个记录。
-
置换-选择算法的步骤如下:
-
从FI输入w个记录到工作区WA。
-
从WA中选出其中关键字取最小值的记录,记为MINIMAX记录。
-
将MINIMAX记录输出到FO中去。
-
若FI不空,则从FI输入下一个记录到WA中。
-
从WA中所有关键字比MINIMAX记录的关键字大的记录中选出最小关键字记录,作为新的MINIMAX记录。
-
重复3)~5),直至在WA中选不出新的MINIMAX记录为止,由此得到一个初始归并段,输出一个归并段的结束标志到FO中去。
-
重复2)~6),直至WA为空。由此得到全部初始归并段
-
12.最佳归并树
引子:
归并过程中磁盘I/O次数=归并树的WPL*2
因此要让磁盘I/O次数最小,就要使归并树的WPL最小即构建一个哈夫曼树
m叉最佳归并树的构造:
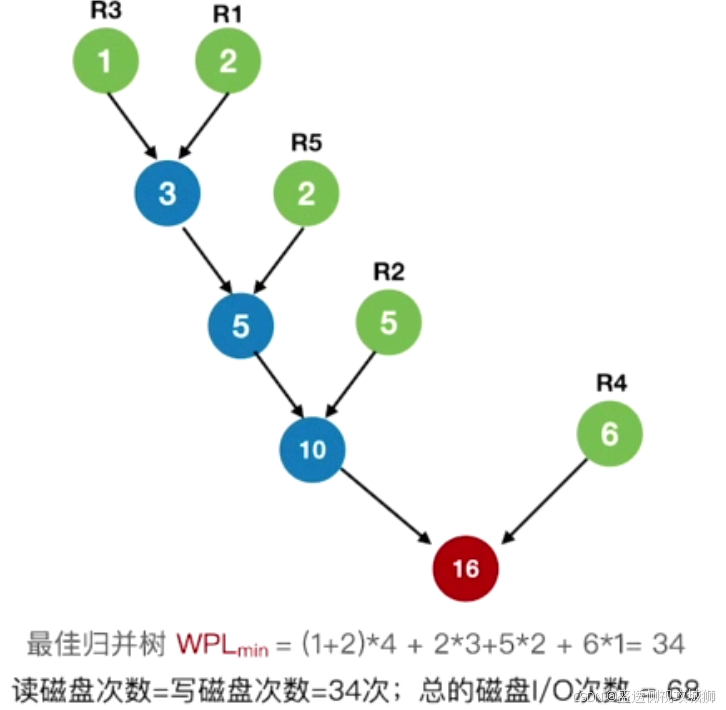
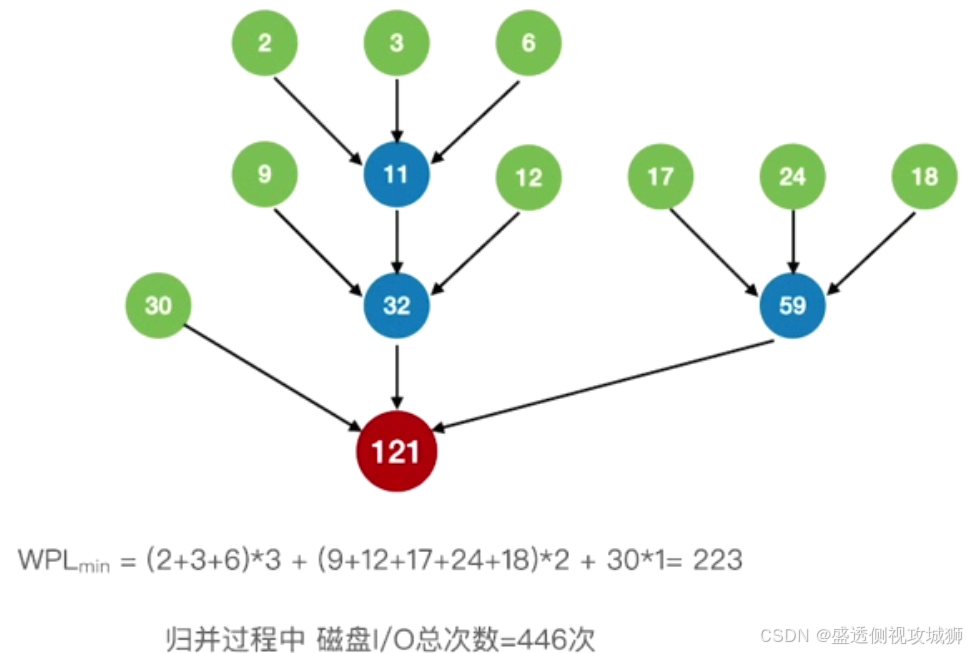
注意:
对于k叉归并,若初始归并段的数量无法构成严格的k叉归并树
则需要补充几个长度为0的“虚段”,再进行k叉哈夫曼树的构造
如何具体增加虚段的数量:
-
若(初始归并段数量 -1)% (k-1)= 0,说明刚好可以构成严格k叉树,此时不需要添加虚段
-
若(初始归并段数量 -1)% (k-1)= u ≠ 0,则需要补充 (k-1) - u 个虚段

欢迎各位彦祖与热巴畅游本人专栏与技术博客
你的三连是我最大的动力
点击➡️指向的专栏名即可闪现
➡️渗透终极之红队攻击行动
➡️动画可视化数据结构与算法
➡️ 永恒之心蓝队联纵合横防御
➡️华为高级网络工程师
➡️华为高级防火墙防御集成部署
➡️ 未授权访问漏洞横向渗透利用
➡️逆向软件破解工程
➡️MYSQL REDIS 进阶实操
➡️红帽高级工程师
➡️红帽系统管理员
➡️HVV 全国各地面试题汇总
目录
本篇技术博文摘要 🌟
引言 📘
上节回顾
排序
1.排序的基本概念
定义:
排序算法的评价指标:
排序算法的分类:
2.动画可视化之插入排序
2.1算法思想:
代码实现:
(1):直接插入排序
(2):直接插入排序(带哨兵)
算法效率分析:
2.2动画可视化之—折半插入排序:
思路:
代码实现:
优化后的效率
3.动画可视化之希尔排序
算法思想:
代码实现:
算法性能分析:
4.动画可视化之冒泡排序
交换排序分类:
算法思想:
代码实现:
5.动画可视化之快速排序
算法思想:
算法性能分析:
快速排序算法的缺点
快速排序算法优化思路:
快速排序性能:
6.动画可视化之简单选择排序
选择排序分类:
6.1简单选择排序算法思想:
代码实现:
算法性能分析:
6.2动画可视化之堆排序
堆的定义:
6.2.1建立大根堆:
建立大根堆代码实现:
6.2.2基于大根堆进行排序:
大根堆排序代码实现:
堆排序的效率分析:
6.3动画可视化之堆的插入删除
基本操作:
在堆中插入新元素:
在堆中删除元素:
关键字对比次数:
7.动画可视化之归并排序
算法思想:
代码实现:
算法效率分析:
8.动画可视化之基数排序
算法思想:
基数排序得到递减序列的过程如下:
基数排序得到递增序列的过程如下:
算法效率分析:
基数排序的应用:
9.动画可视化之外部排序
外存、内存的数据交换:
外部排序原理:
构造初始“归并段”:
时间开销分析:
归并排序的优化思路:
10.败者树
定义:
败者树在多路平衡归并中的应用:
败者树的存储结构:
11置换-选择排序
12.最佳归并树
引子:
m叉最佳归并树的构造:
注意:
如何具体增加虚段的数量:
欢迎各位彦祖与热巴畅游本人专栏与技术博客
你的三连是我最大的动力
点击➡️指向的专栏名即可闪现



