Ollama+openwebUI的windows10/11部署方案,利用docker desktop中的docker compose快速部署,外行人快速上手本地大语言模型安装_ollama docker
持续更新中,边研究边总结,使用中发现问题就会整理到本文中,便于指导无经验使用者发现问题解决问题,并尽量保留已完成成果,少做改动。
目录
〇 简介
0.1 Ollama和openwebUI以及docker简单介绍
0.2 站内相关文章不少,为什么我还要自己写本教程
一 启发
1.1 可能遇到的问题
1.2 简单的回答
二 安装
2.1 安装Docker Desktop for Windows
2.2 Docker Desktop装完了,它到底是什么?WSL2需要我在意吗?
2.2.1 Docker Desktop for Windows 是什么?
2.2.2 WSL2 是什么?我需要管它吗?
2.3 用 docker-compose 来运行 Ollama + Open WebUI!
2.3.1 安装 Docker Desktop(刚才你已经完成!)
2.3.2 创建一个项目文件夹(比如 D:\\ollama-openwebui)
2.3.3 编辑 docker-compose.yml 文件
2.3.4 在文件夹里打开终端(命令行)
方法 1:使用 PowerShell 或 CMD(方便)
方法 2:使用 VS Code(更友好)
2.3.5运行 docker-compose
2.3.6 打开浏览器访问 Open WebUI,开始使用!!!
2.3.7 从局域网其他设备访问
✅ 总结(新手必看)
2.4 网络问题拉取镜像失败
2.5 关于WSL2和docker desktop的进一步说明
2.5.1 WSL2怎么单独开启,有哪些方式?通过在docker desktop安装时勾选WSL2有什么区别?
2.5.2 WSL2会在平时占用资源消耗性能吗?
2.5.3 在WSL2安装ubuntu后不想占用C盘空间怎么办?
2.5.4 WSL2下安装的Ubuntu与Windows高效互通
2.6 进阶功能
三 ※性能问题※
3.1 一个坑: WSL2跨文件系统交互性能差
3.2 ※页面影响巨大,openwebui一些配置修改※
3.3 上下文长度参数
3.4 openwebui发送会话请求时调用的接口
3.5 你用的模型是什么
3.6 把docker容器和WSL2时间调整一致
四 进阶功能
4.1 联网能力(基础版,Open WebUI提供,国内环境可能不太好用)
方法一:在 Open WebUI 中启用其内置的联网搜索功能(最简单、最原生)
方法二:在 Ollama 层面为 DeepSeek 模型添加搜索工具(更底层,更复杂)
4.2 记忆系统实现(本节重点)
4.2.1 建议架构
4.2.2 向量数据库
4.2.3 组建RAG
第 1 步:环境准备
第 2 步:准备你的数据
第 3 步:编写代码
第 4 步:运行和查询
第 5 步:进阶优化和改进
完整代码示例(整合版)
4.2.4 进阶管理
4.2.4.1 docker容器+宿主机
4.2.4.2 docker容器+宿主机+WSL2虚拟机
4.2.4.3 ※Ubuntu下python的安装※
建议
4.3 性格塑造方法
〇 简介
想看干货,直接跳到章节2.1和章节2.3按步骤安装。
0.1 Ollama和openwebUI以及docker简单介绍
Ollama统合了各路大语言框架,方便一般使用者加载调用各种大语言模型,而不需在意各种框架之间的实现差异。openwebUI提供了可视化界面来运行和管理。
基于数据安全等需要,一般使用者(windows用户)可以安装上述两个软件来部署使用自己本地的大语言模型。简单来做可以按照官网说明分别直接在windows下安装两程序并进行环境配置,但是用户操作较多,部署环境不独立,一旦使用出现问题不容易排查,机器较多时也不方便迁移和拷贝,所以可以用docker容器来配置运行镜像系统,在独立的环境中运行服务。基于docker容器来部署的方案更加便捷,服务的启动和停止也可以交给docker desktop来管理。
基于docker容器部署,不需要自己下载ollama、openwebui等程序,只需要用配置文件指示docker compose进行拉取部署。
0.2 站内相关文章不少,为什么我还要自己写本教程
本文旨在为外行人解决安装部署中产生的各种困惑,希望读者无论是否有编程经验都能有所收获。
写本文原因:站内的该类方案教程,比较入门的有直接安装ollama和openwebui等程序,但东西左一个右一个,放的比较分散不利于管理,喜欢折腾的用户还可能跟别的软件的环境冲突,用的久了自己都搞不清装了什么东西,当想清理环境时要怎么搞。也有结合docker来部署的方案,但要么过时要么不彻底(比如只有openwebui用了docker镜像),要么就是自身也是在探索中,方法不完全正确,过程描述的也过于复杂,或是有冗余操作让人摸不着头脑,比如装docker desktop时选择wsl2方案后又要从应用商店安装什么terminal和ubuntu之类的(可以装,但装ubuntu一般用于后续其他目的),不知道是不是当时要那么做,但现在来说都是不必要的操作,一般使用者没必要搞那么复杂。马上2026年了,开发人员为你解决了一切问题,不需要你自己一步步搭建各种工具,如果你用着win10/11,一切都很简单。
本文结合当前混元AI、deepseek提供的答案整理部署过程。
说明:你要做的只有装docker desktop for windows,建几个放数据用的文件夹,写写配置文件,运行一个启动命令,就可以开始你的本地大数据使用之途。若docker compose拉取镜像时,你的网络环境因为众所周知的原因出现访问不了docker hub或它的底层接口的情况,你可以试试换源,镜像下载,文中给出了该问题的解决方法。
一 启发
1.1 可能遇到的问题
对于一个单纯使用AI来办公的使用者、AI领域的外行人来说,在安装和部署中,你可能会像我一样思考到一些问题:
1.我难道要自己在docker装个干净的linux镜像,然后一个个程序来安装和修改配置?
2.我用网上现成的镜像的话,什么网站有Ollama+Open WebUI的docker镜像?
3.我是搞一个同时装了Ollama+Open WebUI的镜像,还是搞两个镜像再通过什么方法联合启动?(你会搜到docker compose方案,这也是被建议的方案)
4.我考虑用docker compose安装,很容易找到了docker-compose.yml配置文件,我要先自己装好两个单独的镜像再通过该配置关联两镜像?还是说docker-compose会通过该文件自动拉取ollama和openwebui?
5.我有固态硬盘,要不要把ollama和大模型文件、数据等放在固态硬盘,会不会运行更快一些,要怎么搞?
6.我在windows上部署,而docker在windows上实际是运行在WSL2虚拟环境中的类linux系统上,那我还要自己在虚拟环境装ubuntu之类的吗?
1.2 简单的回答
我先简单回答一下上述问题,方便你看过其他教程或自己尝试安装后快速理解问题所在。
1.不用造轮子,不需要从头安装和配置;也不需要上网上到处找镜像文件,你只要到docker官网下个windows AMD64版本的docker desktop安装包就行,其他的交给这些很赶时髦的公司。
2.建议用多镜像/多容器联合部署方式,而不是把ollama和openwebui弄到一个镜像容器里,他俩的组合是常用搭配方案,但不是官方固定方案。用docker compose可以很容易实现。
3.写好docker-compose.yml配置文件,docker compose会自动从docker hub上拉取镜像。
4.大模型IO(读写)较高,建议把数据装在非系统盘的固态硬盘上。
5.不需要自己安装其他乱七八糟的任何东西,比如ubuntu、增强的terminal等(有高收藏的文章里这么搞)。你完全不需要手动在 WSL2 中安装 Ubuntu 或其它 Linux 系统。
简单来说,Docker Desktop for Windows 已经内置了 WSL2 环境(包括一个默认的 Linux 发行版),你只需要使用 Docker Desktop 自带的 Docker 和 docker-compose 功能,直接编写并运行 docker-compose.yml就可以了!其他的一切交给技术人员!
二 安装
2.1 安装Docker Desktop for Windows
官网你应该能直接打开,访问可能会比较慢,下载用多线程下载工具会比浏览器自带下载快不少。
Docker: Accelerated Container Application Development
实在打不开就再想办法。一般下图里这个。
下载好安装包,双击安装,直接全下一步安完。其中有几个复选框都不用改。一个是用WSL(新的虚拟机技术,不用了解)替代Hiper-V,一个是不了解风险不建议勾选,总之按默认的装就都OK。
即安装时勾选 \"Use WSL 2 based engine\"(如果选项存在)
安装后打开软件,不想登录就跳过
一般这时候打开的界面右侧提示你电脑里自带的WSL2过时了需要升级,你把提示给你的命令行语句在命令行里执行一下,升级下WSL2。
装完后开始菜单有这几个

2.2 Docker Desktop装完了,它到底是什么?WSL2需要我在意吗?
若是刚接触 Docker 和 WSL2 的新手,这时可以先大概了解以下信息
2.2.1 Docker Desktop for Windows 是什么?
-
Docker Desktop 是Docker工具官方推出的一个图形化软件,它让你可以在 Windows 系统上通过用户交互窗口非常方便地运行 Docker 容器。在docker容器中,你相当于把一个部署了自己应用的操作系统打包起来并开放一些端口,方便管理和迁移你的服务环境。
-
在 Windows 10 / 11 上,Docker Desktop 默认使用 WSL2(Windows Subsystem for Linux 2)作为其后端引擎——windows上Docker 实际上是在一个 轻量级的 Linux 虚拟环境(由 WSL2虚拟机 提供) 中运行的。
-
但你 不需要自己去到windows自带的WSL2中安装 Linux 系统(比如 Ubuntu),因为 Docker Desktop 已经帮你搞定了一切!
2.2.2 WSL2 是什么?我需要管它吗?
-
WSL2(Windows Subsystem for Linux 2) 是微软提供的一种技术,允许 Windows 直接运行一个 完整的 Linux 内核和文件系统,速度很快,体验接近原生 Linux。
-
Docker Desktop 默认就使用了 WSL2,而且已经包含了一个 Linux 发行版(通常是 Ubuntu 或类似系统),专门用来运行 Docker 容器。
-
你作为用户,不进行进阶开发的话,完全不需要自己去 WSL2 里安装 Ubuntu,也无需打开命令行去操作 WSL2。
✅ 你只需要使用 Docker Desktop 的图形界面 或者 直接用 Docker CLI(命令行)写
docker-compose.yml文件并运行,就可以了!
2.3 用 docker-compose 来运行 Ollama + Open WebUI!
继续安装,步骤非常简单!按下面来就行:
2.3.1 安装 Docker Desktop(刚才你已经完成!)
为了你的C盘空间着想,建议立刻在Docker Desktop的settings-resources的Disk image location修改到其他盘。不需要手动创建wsl之类的目录,Docker Desktop会在你选的目录下创建目录结构。
2.3.2 创建一个项目文件夹(比如 D:\\ollama-openwebui)
-
打开 文件资源管理器
-
新建一个文件夹,比如:
D:\\ollama-openwebui(建议放在 SSD 上,并且不要放C盘)
这个文件夹将用来放:
· Docker 配置文件(D:\\ollama-openwebui\\docker-compose.yml)
· 模型数据目录(比如D:\\ollama-openwebui\\models),模型数据的实际存储位置,Docker 容器中访问数据时的路径会映射到你主操作系统中的该目录,也就是服务在容器里运行,数据在外面放着。(用 Volume 设置该路径映射)
· Open WebUI用户数据,如聊天信息、设置/配置、插件信息、上传的文件等(D:\\ollama-openwebui\\webui-data)
最终你的目录结构应该是这样的:
D:\\ollama-openwebui
├── docker-compose.yml
├── models/ ← Ollama 模型文件(已优化)
└── webui-data/ ← Open WebUI 数据(现在你要新增并映射)
2.3.3 编辑 docker-compose.yml 文件
在刚才创建的文件夹里,新建一个文本文件,命名为:docker-compose.yml
(确保后缀是 .yml或 .yaml,推荐用 .yml)
右键点击 docker-compose.yml→ 选择 用记事本(Notepad)或其他编辑器打开(比如 VS Code 更好),然后粘贴以下内容(参考下面官方文档):
https://github.com/open-webui/open-webui/blob/main/docker-compose.yaml
services: ollama: image: ollama/ollama:${OLLAMA_DOCKER_TAG-latest} # 这个如果下载不动就用后面的方法改docker配置 container_name: ollama pull_policy: always tty: true restart: unless-stopped ports: - \"11434:11434\" volumes: - D:\\ollama-openwebui\\models:/root/.ollama # 👈 Ollama 模型存放在 D 盘 SSD open-webui: build: context: . args: OLLAMA_BASE_URL: \'/ollama\' dockerfile: Dockerfile image: ghcr.nju.edu.cn/open-webui/open-webui:${WEBUI_DOCKER_TAG-main} # 官方写的是ghcr.io/open-webui/open-webui:${WEBUI_DOCKER_TAG-main},但用前面那个可以速度很快地下载下来 container_name: open-webui restart: unless-stopped depends_on: - ollama ports: - ${OPEN_WEBUI_PORT-3000}:8080 environment: - OLLAMA_BASE_URL=http://ollama:11434 - \'WEBUI_SECRET_KEY=\' extra_hosts: - host.docker.internal:host-gateway volumes: - D:\\ollama-openwebui\\webui-data:/app/backend/data # 👈 Open WebUI 数据也存放在 D 盘 SSDvolumes: ollama: {} open-webui: {}📌 这个配置做了以下事情:
启动了一个
ollama/ollama容器(运行 Ollama 后端服务)启动了一个
openwebui/openwebui容器(运行 Web 前端界面)两个容器之间可以互相通信(通过 Docker 内部网络)
Open WebUI 会通过
http://ollama:11434访问 Ollama 的 API使用 Docker Volume 来持久化保存模型和数据(避免丢失)
📌 重点说明:
volumes: 下的这一行:
D:\\ollama-openwebui\\models:/root/.ollama
表示把 Windows 的 D:\\ollama-openwebui\\models 文件夹映射到容器内的 /root/.ollama(Ollama 默认存放模型的位置)
/app/backend/data 是openwebui官方存放用户数据的地方
2.3.4 在文件夹里打开终端(命令行)
方法 1:使用 PowerShell 或 CMD(方便)
-
按住 Shift 键,然后 右键点击你刚才创建的文件夹(比如 ollama-openwebui)
-
选择 “在此处打开 PowerShell 窗口” 或 “在此处打开命令窗口”
-
或者你也可以直接打开 PowerShell / CMD,然后
cd到该目录:
>>D:\\>>cd D:\\ollama-openwebui方法 2:使用 VS Code(更友好)
-
安装 Visual Studio Code(免费)
-
右键点击你的
docker-compose.yml所在文件夹 -
选择 “用 VS Code 打开”
-
按下
Ctrl + `打开内置终端
2.3.5运行 docker-compose
确保docker引擎处于运行状态(主界面左下角显示engine running),在终端里输入以下命令:
docker-compose up -d🧠 说明:
docker-compose up:根据docker-compose.yml启动所有服务
-d:后台运行(detached 模式)
Docker 会自动:
-
从 Docker Hub 下载
ollama/ollama和openwebui/openwebui镜像(如果本地没有) -
启动两个容器
-
模型存放在
D:\\ollama-openwebui\\models - Open WebUI 数据存放在
D:\\ollama-openwebui\\webui-data -
一切就绪!
2.3.6 打开浏览器访问 Open WebUI,开始使用!!!
等待几分钟后(第一次启动 Ollama 可能需要下载基础模型,如果你不指定模型,它可能默认拉取 ollama/llama2),打开浏览器访问:
👉 http://localhost:3000
你应该就能看到 Open WebUI 的登录界面或主页,在里面可以和 LLM 聊天了!
2.3.7 从局域网其他设备访问
确保防火墙允许外部访问 3000 端口,Windows 防火墙默认可能会 阻止外部设备访问你本机的 3000 端口。
方法:允许 3000 端口通过防火墙
- 打开 控制面板 > Windows Defender 防火墙 > 高级设置
- 选择 “入站规则” > “新建规则”
- 选择 “端口” > 下一步
- 选择 “TCP”,并输入 特定本地端口:3000
- 选择 “允许连接”
- 勾选所有(域、专用、公用)或者根据你的网络环境选择(比如只勾选“专用”如果你只在家庭局域网用)
- 给规则起个名字,比如
OpenWebUI Port 3000 - 完成
✅ 总结(新手必看)
问题
答案
我需要自己安装 Ubuntu 或 WSL2 吗?
❌ 不需要!Docker Desktop 已经内置了 WSL2 和 Linux 环境
我怎么运行 Ollama + Open WebUI?
用 Docker Desktop + docker-compose.yml 文件,按上面步骤操作即可
我需要打开命令行吗?
是的,但只是为了进入你的项目文件夹并运行 docker-compose up -d,可以使用 PowerShell / CMD / VS Code
我能在 Windows 资源管理器里操作吗?
可以!你只需要创建文件夹、写 docker-compose.yml文件,然后用 Docker Desktop 或命令行启动
模型文件存放在哪里?默认性能如何?
默认在 Docker 内部存储,建议通过 Volume 映射到 SSD 目录(如 D:\\ollama_models)来提高加载速度
注: 不需要手动安装 Ubuntu / WSL2 !
Docker Desktop 已经 自动集成了 WSL2 和一个 Linux 环境,你无需手动安装任何 Linux 系统(比如 Ubuntu)。
你 不需要打开 WSL2 终端、不需要运行 Linux 命令去安装 Docker。
你只需要使用 Docker Desktop 提供的图形界面 或 Docker CLI(命令行) 即可!
2.4 网络问题拉取镜像失败
方法参考这篇
阿里云镜像源无法访问?使用 DaoCloud 镜像源加速 Docker 下载(Linux 和 Windows 配置指南)_m.daocloud.io-CSDN博客
在docker engine增加配置如下(应该可以解决问题)
\"registry-mirrors\": [\"https://docker.mirrors.ustc.edu.cn\",\"https://hub-mirror.c.163.com\",\"https://docker.m.daocloud.io\",\"https://f1361db2.m.daocloud.io\"],
\"dns\": [\"8.8.8.8\", \"114.114.114.114\"]
如果用compose启动时拉取失败,在命令行里执行
docker pull ollama/ollama
docker pull ghcr.io/open-webui/open-webui(上docker hub看,现在不是叫openwebui/openwebui了)
单独执行拉取操作看看能否成功拉取。注意名称是否正确,可以结合官方文档看看。像我学人用pull openwebui/openwebui试了半天,结果官网上一搜现在根本不叫这个。
2.5 关于WSL2和docker desktop的进一步说明
进阶使用时(比如当你想建立自己的数据库让本地大模型拥有记忆时,一般涉及RAG方案,怎么做后面会讲),会遇到下面的问题。
2.5.1 WSL2怎么单独开启,有哪些方式?通过在docker desktop安装时勾选WSL2有什么区别?
一般来说,单独接触到WSL2的人,会有两种方法安装、开启WSL2功能。
方法一:手动开启、安装(旧方法)
- 通过控制面板-程序-程序和功能-启用或关闭windows功能勾选适用于Linux的Windows子系统
- 打开PowerShell,输入
wsl --set-default-version 2来设置WSL2为默认版本 - 最后再去微软商店下载安装Ubuntu
方法二:一站式安装(新方法)
微软后来推出的超级简单的命令。只需要在PowerShell(管理员身份)里输入这一条命令:
wsl --install这条命令会自动按顺序完成以下所有事情:
- 在后台为你勾选“适用于Linux的Windows子系统”和“虚拟机平台”功能。
- 自动将WSL2设置为默认版本。
- 自动下载并安装默认的Linux发行版(通常是Ubuntu)。
- 完成后会提示你重启电脑,重启后系统就全部配置好了。
所以,wsl --install 是“勾选功能 + 安装发行版”的合体。 它是现在官方推荐的最简单安装方式。
而通过Docker Desktop安装WSL2相当于第三种方法:
方法三:安装Docker Desktop并选择“使用WSL2后端”时,Docker的安装程序自动在后台帮你完成了“方式一”中的第1步和第2步(启用功能并设置版本)。但是没有完成第三步(安装一个像Ubuntu这样的完整发行版),因为它自己只需要两个专用的最小化发行版(docker-desktop,可以通过wsl -l -v查看)来运行容器。
所以如果你还需要基于虚拟Linux环境进行开发,还要自己安装发行版如Ubuntu(=Linux内核+一些特色的用户文件,docker容器和ubuntu都共同运行在WSL中的Linux内核上),通过商店安装或命令行安装:
# 方法A:安装指定的Ubuntu版本(推荐)wsl --install -d Ubuntu-22.04# 或方法B:安装最新的Ubuntu版本wsl --install -d Ubuntu
总结:WSL2 是“引擎”,不是“整车”,WSL2 (Windows Subsystem for Linux 2) 本身只是一个“平台”或“功能”,它不自动包含任何具体的Linux发行版(如Ubuntu),但是初次安装时如果用的是wsl --install方法,会自动为你装一个ubuntu。而通过docker desktop启用则只启用WSL2基本的本体。
2.5.2 WSL2会在平时占用资源消耗性能吗?
WSL2 默认不会在你开机时自动启动完整的Linux系统,并且在你不用它时,它几乎不占用任何CPU和内存资源。但它会占用一定的磁盘空间。
WSL2 的设计非常智能。当你开机进入Windows后:
- WSL2 的“组件”和“驱动” 是加载的,这就像插上了虚拟机的电源线,但还没按下开机按钮。
- 你的 Ubuntu 发行版(即完整的Linux环境) 默认是关闭状态的,就像一个没开机的虚拟机。
你的Ubuntu只会在你第一次执行以下操作时才会真正启动:
- 在
开始菜单里点击Ubuntu图标。 - 在 PowerShell 或 CMD 中输入
wsl或wsl ~。 - 在 VSCode 中通过 WSL 远程扩展连接它。
- 运行任何依赖于WSL2的命令(比如
docker命令,因为Docker Desktop依赖于WSL2)。
在你完全不使用WSL2时,它对Windows的前台性能没有任何负面影响。它就像一个放在角落里的工具箱,你不用它,它就不会碍事。而你使用他时,若处于空闲状态,他也会释放资源。
不过如果你启动了数据库(MySQL)、服务器(nginx)之类的后台常驻进程的话,就要用wsl --shutdown才能彻底关闭他们了。
2.5.3 在WSL2安装ubuntu后不想占用C盘空间怎么办?
后面再说为什么还考虑ubuntu的问题。
WSL2 本质上是一个虚拟机。它占用的是你硬盘上的一个虚拟硬盘文件。
若你因为某些需求选择在WSL2中安装上ubuntu,但又担心占用C盘空间,或操作系统出了问题找不回虚拟系统文件,可以考虑把虚拟硬盘文件迁到其他盘。
这个文件通常在:
C:\\Users\\\\AppData\\Local\\Packages\\CanonicalGroupLimited.Ubuntu_79rhkp1fndgsc\\LocalState\\ext4.vhdx
这个 .vhdx 文件就是你的整个 WSL2 Ubuntu 系统,包括:
- 操作系统本身 (
/usr,/etc,/bin) - 你通过
apt安装的软件 - 你的项目代码 (
/home/yourname/projects) - 你的配置文件和家目录 (
~/.bashrc,~/.ssh) - 你在WSL2里用
pip install安装的Python包(RAG所需) - 你的ChromaDB向量数据库文件(RAG所需)
迁移方法:导出再导入(最安全、最灵活)
这个方法会创建一个新的虚拟硬盘,是最干净可靠的方式。比直接剪切文件更安全。
步骤 1:确认当前发行版和大小
-
打开 PowerShell,查看已安装的发行版
wsl -l -v -
在文件资源管理器地址栏输入
%USERPROFILE%\\AppData\\Local\\Packages并回车,找到类似CanonicalGroupLimited.Ubuntu...的文件夹,查看其中的LocalState\\ext4.vhdx文件大小,做到心中有数。
步骤 2:导出当前系统
-
首先关闭WSL,确保所有状态都已写入磁盘。wsl --shutdown
-
创建用于存放备份和新系统的文件夹,例如
D:\\WSL\\ -
将当前的发行版导出到一个压缩文件中(这不会删除原系统):
# 语法:wsl --export wsl --export Ubuntu D:\\WSL\\ubuntu-backup.tar这个过程需要一些时间,导出的
.tar文件会比原来的.vhdx文件小。
步骤 3:注销原系统并导入到新位置
-
导出成功后,注销(删除)原来的发行版。(注意:这会删除C盘上的原虚拟磁盘文件以释放空间)
wsl --unregister Ubuntu
-
将刚才导出的备份文件,导入到一个新的位置,并为你新创建的发行版起个名字(比如
Ubuntu):# 语法:wsl --import --version 2wsl --import Ubuntu D:\\WSL\\ Ubuntu D:\\WSL\\ubuntu-backup.tar --version 2
D:\\WSL\\:这个目录将成为新发行版的家,里面会生成一个ext4.vhdx文件。- 最后的
--version 2指定使用WSL2。
步骤 4:设置默认用户
导入的系统默认是 root 用户。你需要设置回你之前的普通用户。
-
首先启动这个新系统(它会以root身份登录):
wsl -d Ubuntu
-
在WSL内部,执行以下命令,将
[你的用户名]替换为你之前常用的用户名(如果忘了,可以看看/home/目录下哪个名字眼熟):echo -e \"[user]\\ndefault=$(你的用户名)\" >> /etc/wsl.conf
例如:
echo -e \"[user]\\ndefault=alex\" >> /etc/wsl.conf -
退出WSL并完全关闭它:
exit
wsl --shutdown
-
再次启动WSL,现在它就会自动以你的默认用户登录了:
wsl ~
完成后,你的WSL2就已经完全运行在D盘了。你可以删除 D:\\WSL\\ubuntu-backup.tar 备份文件以节省空间。
2.5.4 WSL2下安装的Ubuntu与Windows高效互通
你可以在 Windows 的文件资源管理器里直接访问 WSL2 的文件(\\\\wsl$\\Ubuntu\\home\\\\...),也可以在 WSL2 里访问 Windows 的磁盘(/mnt/c/, /mnt/d/)。
2.6 进阶功能
完成上面操作,你已经有了一个本地大模型,可以通过命令行或openwebui的界面进行简单的拉取模型或会话。如果只想简单体验,看到这里就足够了。
但这时你可能会想,我怎么样让这个本地对话助手具有高度拟人化、具备记忆和联网获取实时信息等能力呢?实现这个目标,需要一个综合系统,而不仅仅是单个模型。
实现见章节四
三 ※性能问题※
3.1 一个坑: WSL2跨文件系统交互性能差
建议改完3.2视效果再来看需不需要看3.1。
基于上述步骤,你已经可以开始使用openwebui访问ollama并管理你的模型了,但是使用中会发现网页速度很慢,很多命令你从wsl2下的ubuntu用curl等请求容器中程序的接口很快,但是通过页面用起来就很慢了。这是因为2.5.4里面提到了高效互通,却并不高速,这就很搞笑了。我们把ollama访问的大模型文件和openwebui使用的用户数据文件放在windows下并用volume映射,期间包含了文件系统转换,这种性能差异在需要顺序读取大文件(如模型加载) 或 频繁读取大量小文件(如包含成千上万个文件的LoRA模型) 时十分明显。
强烈推荐将大模型文件放在 WSL2 的 Ubuntu 文件系统内部(例如 /home/username/models),而不是放在 Windows 下通过 Volume 映射到容器。
这不仅仅是“好一点”,而是好一个数量级的差异。对于模型加载和推理这种需要高速、低延迟读取大量数据的场景,这种选择至关重要。
问题分析如下:
见WSL1和WSL2比较-Microsoft learn
解决Docker使用WSL2项目运行慢的问题
解决PHP项目在Docker(WSL2)中运行缓慢的问题
⚠️ WSL 2 跨文件系统性能慢的主要原因
WSL 2 虽然提供了完整的 Linux 内核和更好的系统调用兼容性2,但其架构决定了它在跨操作系统文件访问时,性能上的一些取舍:
- 不同的架构机制:WSL 2 基于轻量级虚拟机(VM) 和完整的 Linux 内核2。当 Linux 系统需要访问 Windows 文件系统(比如
/mnt/c)时,这个请求需要通过 网络协议 转发到宿主机 Windows3。这个过程会带来额外的开销,导致 I/O 操作(尤其是大量小文件读写)比 WSL 1 慢。 - 与 WSL 1 的对比:WSL 1 由于直接将 Linux 系统调用转换为 Windows NT 系统调用,没有虚拟机这一层2,所以在跨系统文件操作时,性能反而更好1。
为了更直观地对比 WSL 1 和 WSL 2 的主要特性,请看下表:
💡 使用高效的开发工具和插件
-
如果你使用 VS Code,强烈推荐使用 Remote - WSL 扩展。它允许你将项目文件存储在 WSL 文件系统中,但在 Windows 上使用 VS Code 进行编辑和调试,从而避免性能损失
用图片帮助理解
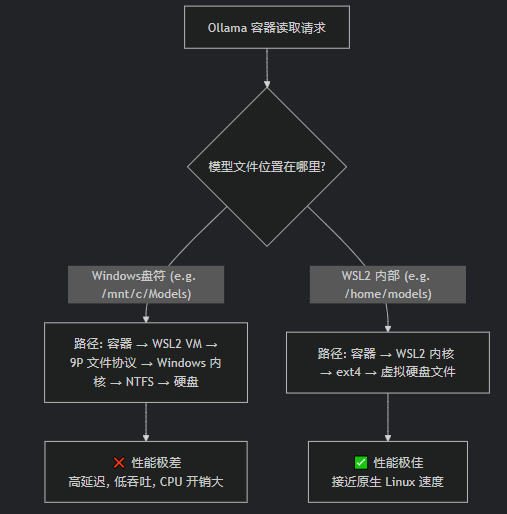
从上图可以看出,方式B(WSL2内部)的路径更短、更高效。它完全在Linux内核内完成,使用的是高效的ext4文件系统,避免了所有在Windows和WSL2之间转换的开销。
除了模型放到WSL2下的ubuntu中以外,还建议从WSL2 的 Ubuntu 终端内部运行 Docker 命令来启动和管理你的容器(比如 Ollama),而不是在windows的命令行或docker desktop软件启动.。这也是获得最好性能和最少问题的途径。
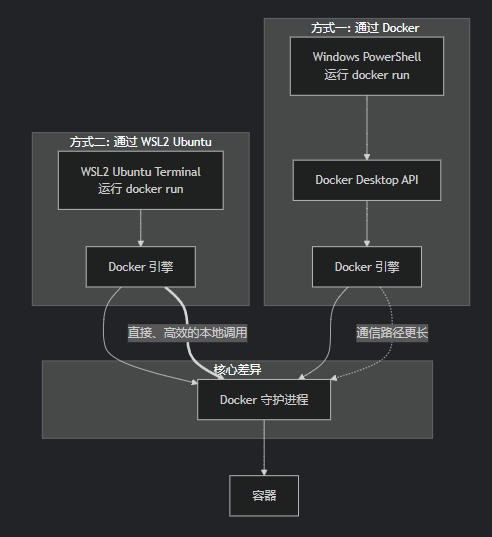
为此需要启用WSL集成功能,以在ubuntu中可用docker命令。
- 打开Docker Desktop,点击右上角的 Settings(设置)。
- 在设置菜单中,选择 Resources > WSL Integration。
- 勾选要启用集成的WSL发行版(如Ubuntu)。
- 点击 Apply & Restart 以应用更改并重启Docker Desktop。
启动用的yml中volume映射路径也要相应修改,直接改到ubuntu文件系统下,如/home/username/model。
3.2 ※页面影响巨大,openwebui一些配置修改※
如果只布了ollama,管理员配置中把openai api关闭,不然后台经常报错找不到相应主机,等待请求耗时很长,非常影响页面响应速度


3.3 上下文长度参数
知识库上传文件包含文本量较大时,注意调高模型的num_ctx(上下文长度),以免截断
站内文章普遍流传说法ollama默认使用上下文长度是2048,远小于模型最大能力。
但是通过AI获取的信息:
早期版本或某些模型可能有默认限制,但现代 Ollama 通常按模型最大支持值运行
我暂时没有进行进一步的探索,去看信息来源如何,以及了解目前的运行模式,留待进一步确认
但是上下文长度提高时的系统资源占用也会大幅提高,需平衡参数设置。
有多种配置方式,作用在不同阶段,有优先级。建议用modelfile对模型参数进行约定,方法很容易搜到,不展开说明。另外在openwebui页面右上角打开的用户高级设置里,可在高级参数设置里修改num_ctx,优先级最高(作用于API 请求参数),比如改成-1,你会发现完全驴唇不对马嘴。
下面是一个汇总表格,帮你快速了解 Ollama 中与上下文长度相关的配置方式:
OLLAMA_CONTEXT_SIZEPARAMETER num_ctx {\"options\": {\"num_ctx\": }}ollama run ... 中使用 /set parameter num_ctx /set, API options)PARAMETER num_ctx)OLLAMA_CONTEXT_SIZE)🚨 需要注意的点:
-
优先级:通常,通过 API 请求或命令行运行时直接指定的参数优先级高于环境变量的设置3。
-
资源消耗:增大上下文窗口会显著增加内存(尤其是显存)的消耗,可能导致内存不足(OOM)错误或推理速度下降12。请务必根据你的硬件资源量力而行。
-
模型限制:上下文长度最终不能超过模型本身所能支持的最大技术上限(例如,某些模型可能最大只支持 32K)
如何设置环境变量:
1.docker从单个镜像启动容器
docker run -d -e OLLAMA_CONTEXT_SIZE=32768 -p 11434:11434 --name ollama ollama/ollama
2.docker compose用docker-compose.yml为配置启动多个容器时
修改yml:
services: ollama: # image: ollama/ollama:${OLLAMA_DOCKER_TAG-latest} image: ollama/ollama:0.11.6 container_name: ollama # pull_policy: always tty: true restart: unless-stopped ports: - \"11434:11434\" volumes: - /home/username/LLM-study/models:/root/.ollama # 从ubuntu启动docker,Ollama 模型存放在ubuntu文件系统下 - /home/username/LLM-study/modelfile:/modelfile:ro # <--- 新增这行挂载,存放用户编写的modelfile文件 environment: # <--- 新增环境变量配置 - OLLAMA_NUM_CTX=8192 # 将上下文长度设置为8192--备用,不知道这个参数有没有效,多写点也没影响 - OLLAMA_CONTEXT_SIZE=8192 # 将上下文长度设置为8192--搜到的比较多的写法 deploy: resources: limits: cpus: \'10\' # <--- 限制CPU核心数,根据你的主机修改 memory: 12G # <--- 限制内存,根据你的主机和模型大小修改 # reservations: # devices: #显卡穿透,使ollama可以检测到并启用显卡来运行模型 # - driver: nvidia # count: all # capabilities: [gpu] # ………………3.4 openwebui发送会话请求时调用的接口
openwebui为什么在会话中调用/api/v1/chats而不是/api/generate?
Open WebUI 在会话中调用 /api/1/chat 而不是 /api/generate,主要是为了更好地适配其前端界面功能、优化交互体验以及遵循更通用的 API 设计规范。虽然搜索结果中没有直接解释这一设计选择的原因,但我们可以根据相关知识进行分析。
下面是一个简单的对比表格,帮助你快速了解这两个接口的一些关键区别:
/api/generate/api/1/chat (或类似聊天端点)prompt53.5 你用的模型是什么
入门者通常听着deepseek的大名,想要入门地体验一下它的使用,于是拉取deepseek-r1:1.5b
比如在openwebui左上角选择模型处输出这个名称调用ollama来下载模型,或是到启动的ollama容器里docker exec -it ollama /bin/bash 然后ollama run deepseek-r1:1.5b拉取ollama服务器上的镜像。不过要注意本地部署的DeepSeek-R1,它其实不是R1,运行ollama show deepseek-R1:1.5b,看到下面信息
Model
architecture qwen2
parameters 1.8B
context length 131072
embedding length 1536
quantization Q4_K_M
模型的全称其实是DeepSeek-R1-Distill-Qwen-1.5B,实际上是使用 DeepSeek-R1 生成的样本基于Qwen2.5-Math-1.5B模型进行微调的,本质仍然源自Qwen2的结构。不过简单用用是无所谓的。
你用的R1是什么?
3.6 把docker容器和WSL2时间调整一致
从ubuntu启动docker时,可以让docker内容器使用的时间文件映射绑定到Ubuntu的时间文件,这样可以让时间一致;WSL2默认又和宿主机时间一致。
wsl date查看时间,一般是对的。
然后yml内在
volumes:
添加
- /etc/localtime:/etc/localtime:ro
ollama和openwebui镜像一般加这行就可以了,如果你还有tika镜像,还需要加一行调整时区
- /etc/timezone:/etc/timezone:ro
四 进阶功能
你可以在deepseek、混元等直接提问“如何让本地模型有性格有记忆像人一样和自己对话还能获取网上实时信息”,它会给你一套代码方案。
4.1 联网能力(基础版,Open WebUI提供,国内环境可能不太好用)
你的架构现在是这样的:
用户 → Open WebUI → Ollama (DeepSeek-R1) → 返回答案
我们要把它升级成这样:
用户 → Open WebUI → Ollama (DeepSeek-R1) → (需要搜索时) → 搜索工具 → 获取结果 → Ollama (总结) → 返回答案
实现这个目标,主要有两种清晰的路径,第一种简单快捷。
方法一:在 Open WebUI 中启用其内置的联网搜索功能(最简单、最原生)
你只需要配置一下即可。不涉及网络问题的情况下能让你的体验(仅从操作上说,不指效果)和官方客户端几乎一模一样。
配置步骤:
-
找到你的 Open WebUI 的 Docker Compose 文件
首先,你需要知道你当初是如何用 Docker Compose 启动 Open WebUI 的。通常会在docker-compose.yml文件中。 -
修改 Open WebUI 的配置环境变量
你需要为 Open WebUI 的容器添加两个关键的环境变量来启用搜索:OLLAMA_BASE_URL: 你已经有这个了,指向你的 Ollama。WEBUI_SEARCH_ENABLED: 设置为true来开启功能。WEBUI_SEARCH_PROVIDER: 设置搜索提供商,例如duckduckgo或google、Bing等(没有Baidu)。SERPAPI_API_KEY(如果使用 Google): 如果你不用 DuckDuckGo 而想用 Google,需要去 SerpAPI 申请一个 Key。Bing也要key。DuckDuckGo 是免费且无需 Key的。 -
编辑你的
docker-compose.yml文件
找到open-webui服务的部分,在environment部分添加新的变量。示例配置(使用 DuckDuckGo):
services: open-webui: image: ghcr.io/open-webui/open-webui:main container_name: open-webui # ... 其他配置(端口、卷等) environment: - OLLAMA_BASE_URL=http://ollama:11434 # 这是原有的,确保存在 - WEBUI_SEARCH_ENABLED=true # 新增:启用搜索 - WEBUI_SEARCH_PROVIDER=duckduckgo # 新增:使用DuckDuckGo # ... 其他配置示例配置(使用 Google via SerpAPI):
services: open-webui: image: ghcr.io/open-webui/open-webui:main container_name: open-webui # ... 其他配置(端口、卷等) environment: - OLLAMA_BASE_URL=http://ollama:11434 - WEBUI_SEARCH_ENABLED=true - WEBUI_SEARCH_PROVIDER=google # 使用Google - SERPAPI_API_KEY=your_serpapi_key_here # 你的SerpAPI密钥 # ... 其他配置 -
重启服务
保存docker-compose.yml文件后,在终端运行命令重启服务:docker-compose downdocker-compose up -d -
在界面中使用
重启后,打开 Open WebUI 界面。你应该能在输入框的右下角或者附近看到一个全新的“地球”图标。点击它,当它变成彩色或有一个勾选状态时,就表示“联网搜索”已启用。接下来你问的任何问题,模型都会自动先去网上搜索再回答。
优点:无缝集成,一键开关,无需修改代码,用户体验最佳。
缺点:要考虑网络因素
方法二:在 Ollama 层面为 DeepSeek 模型添加搜索工具(更底层,更复杂)
如果 Open WebUI 的搜索功能因网络问题无法使用,或者你想有更强的控制权,可以采用这种方法。这需要你创建一个自定义的 Ollama Modelfile。使用 Ollama 的 Modelfile 中的 TEMPLATE 指令,重写模型的提示词模板,当检测到用户需要实时信息时,在后台调用一个你写的 Python 脚本(作为工具)去搜索。不易实现,自行搜索做法。我觉得如果要通过编程拓展功能,不如把增强逻辑都写到python程序中,调用ollama进行对话。
其他方案(待研究):
LangChain + Search API
Mem0
自托管 SearXNG
4.2 记忆系统实现(本节重点)
这个章节和openwebui无关,但是openwebui里也是可以做相关配置的。
4.2.1 建议架构
-
向量数据库存储:使用ChromaDB、Weaviate或Pinecone存储对话历史,将每次对话转换为向量嵌入
-
分层记忆结构:
-
短期记忆:最近对话的缓存(最近10-15轮对话)
-
长期记忆:重要事实、用户偏好和关键信息的向量化存储
-
核心身份记忆:模型的性格设定、背景故事和价值观
-
4.2.2 向量数据库
向量数据库是当前AI领域的一个热门技术,与传统数据库不同,不是精确匹配,而是通过相似度匹配。
向量数据库是一种专门设计用于存储、管理和检索高维向量的数据库。它的核心不是存储原始数据(如文本、图片、音频),而是存储这些数据的向量嵌入。
-
向量嵌入:是由AI模型(如各种深度学习模型)将非结构化数据(文本、图像、音频、视频)转换成一长串数字(即向量)。这个向量在高维空间中代表数据的“含义”或“特征”。例如,单词“国王”通过模型转换后,可能得到一个300维的向量,这个向量在空间中的位置与“男人”、“女王”、“王冠”等词的向量有数学上的关联。
-
核心操作:向量数据库的核心操作是相似性搜索。给定一个查询向量,数据库会快速找到库中与它最相似的向量(即距离最近的向量)。常用的距离度量方式包括余弦相似度、欧几里得距离等。
实现上,向量数据库使用近似最近邻算法和专门索引(如 HNSW, IVF-PQ 等),牺牲百分百的精确度,换来巨大的速度提升。
向量数据库的一个重要作用就是大模型的“长期记忆”。LLM(如 ChatGPT)本身有知识 cutoff date,并且无法记住每次对话。向量数据库可以作为其外部知识库。将公司内部文档、知识库转化为向量存起来。当用户提问时,先从向量库中找到最相关的文档片段,再连同问题一起送给LLM生成答案。这就是 RAG 的核心架构。(RAG的实现是我后面要讨论的)
同时解锁非结构化数据价值:世界上80%的数据都是非结构化的(图片、视频、邮件、报告等)。
它与关系数据库、文件/文档数据库的关系:
- 关系数据库是处理结构化交易数据的王者,追求精确和一致。
- 文件/文档数据库是处理灵活、半结构化数据的好手,追求灵活和扩展。
- 向量数据库是处理非结构化数据语义的专家,追求相似和关联。
它们不是取代关系,而是互补关系。一个现代AI应用很可能同时使用这三种数据库:
- 用关系数据库存用户订单和账户信息。
- 用文档数据库存用户生成的JSON格式的配置文件和日志。
- 用向量数据库存产品图片的特征向量和用户聊天记录的嵌入,以实现相似产品推荐和智能客服。
4.2.3 组建RAG
组建本地的 RAG(检索增强生成)系统是一个非常实用且强大的项目,它能让你利用自己的数据与大型语言模型(LLM)进行智能交互。
本地 RAG 的核心组件
一个典型的 RAG 系统包含以下三个核心部分:
-
加载器:从各种来源(PDF, Word, TXT, 网页等)加载你的文档。
-
向量数据库:存储和处理文档的向量嵌入,负责高效检索。
-
大语言模型:根据检索到的上下文信息生成最终答案。
技术选型推荐(全本地、开源方案)
以下是一套非常流行且易于上手的全开源技术栈:
一步步组建你的本地 RAG(看完本文再操作)
※※※我们以使用 LlamaIndex + Chroma + Ollama 这套组合为例。※※※
第 1 步:环境准备
-
安装 Python:确保你的电脑(windows)已安装 Python (建议 3.10 或以上版本)。
-
创建虚拟环境(推荐):
python -m venv my_rag_envsource my_rag_env/bin/activate # Linux/macOS# 或my_rag_env\\Scripts\\activate # Windows
-
安装核心库:
pip install llama-index chromadb sentence-transformers
-
安装 Ollama 并拉取模型
第 2 步:准备你的数据
将你想要问答的文档(如 PDF、TXT 等)放在一个文件夹中,例如 ./data。
第 3 步:编写代码
创建一个名为 my_rag.py 的 Python 文件,然后开始编写代码。
1. 导入必要的库
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settingsfrom llama_index.embeddings.huggingface import HuggingFaceEmbeddingfrom llama_index.llms.ollama import Ollamaimport chromadb2. 配置全局设置(LLM 和嵌入模型)
# 设置本地 LLM (通过 Ollama)Settings.llm = Ollama(model=\"llama3\", request_timeout=60.0)# 设置本地嵌入模型Settings.embed_model = HuggingFaceEmbedding( model_name=\"sentence-transformers/all-MiniLM-L6-v2\")# (可选) 设置块大小Settings.chunk_size = 5123. 加载文档并处理
# 从 data 目录加载文档documents = SimpleDirectoryReader(\"./data\").load_data()print(f\"已加载 {len(documents)} 篇文档\")4. 创建索引并存入向量数据库
# 创建向量存储客户端,持久化到本地目录vector_store = chromadb.PersistentClient(path=\"./chroma_db\")# 创建索引# 这将自动进行文本分块、生成向量并存储到 ChromaDBindex = VectorStoreIndex.from_documents( documents, embed_model=Settings.embed_model)# 将索引持久化到磁盘(可选,这样下次就不用重新处理文档了)index.storage_context.persist(persist_dir=\"./storage\")5. 创建查询引擎进行问答
# 基于索引创建一个查询引擎query_engine = index.as_query_engine()# 提出你的问题query = \"你的问题是什么?\"response = query_engine.query(query)# 打印结果print(f\"\\n问: {query}\")print(f\"\\n答: {response}\")第 4 步:运行和查询
保存文件后,在终端运行:
python my_rag.py
第一次运行会花费一些时间,因为它需要下载嵌入模型并将你的所有文档进行分块和向量化处理。之后运行就会非常快。
第 5 步:进阶优化和改进
上面的代码是一个最简示例。一个成熟的 RAG 系统还需要考虑以下几点:
-
更好的文本分割:调整
chunk_size和chunk_overlap参数,让文本块更合理,避免信息被切断。 -
前端界面:使用 Gradio 或 Streamlit 快速构建一个 Web 界面,让交互更直观。
pip install gradio
-
元数据过滤:在检索时,除了语义,还可以过滤来源、作者、日期等元信息,使检索更精确。
-
重新排序:初步检索出多个块后,使用一个更小的模型对结果进行重新排序,将最相关的结果排在前面,提升最终答案的质量。
-
评估:准备一些测试问题,评估你的 RAG 系统回答的质量,从而迭代优化分块策略、提示词等。
完整代码示例(整合版)
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settingsfrom llama_index.embeddings.huggingface import HuggingFaceEmbeddingfrom llama_index.llms.ollama import Ollamaimport chromadb# 配置模型Settings.llm = Ollama(model=\"llama3\", request_timeout=60.0)Settings.embed_model = HuggingFaceEmbedding( model_name=\"sentence-transformers/all-MiniLM-L6-v2\")Settings.chunk_size = 512# 加载文档documents = SimpleDirectoryReader(\"./data\").load_data()print(f\"已加载 {len(documents)} 篇文档\")# 创建索引index = VectorStoreIndex.from_documents( documents)# 持久化存储(可选)index.storage_context.persist(persist_dir=\"./storage\")# 问答循环query_engine = index.as_query_engine()while True: user_input = input(\"\\n请输入你的问题 (输入 \'quit\' 退出): \") if user_input.lower() == \'quit\': break response = query_engine.query(user_input) print(f\"\\n答: {response}\")通过以上步骤,你就可以成功搭建一个运行在自己电脑上的本地 RAG 系统了!整个过程无需网络,你的数据也完全保持私有。
4.2.4 进阶管理
装了这么多东西,怎么组织管理项目?
4.2.4.1 docker容器+宿主机
按照上面的方法,你的Ollama和OpenWebUI是运行在docker容器中,他们变化很少,主要是提供常态化的服务。在宿主机(你的 Windows 系统)上运行 Python RAG 代码,直接通过网络连接 Docker 中的 Ollama。
这是最简单、最清晰的方式,因为向量数据库(Chroma)在本地运行也更简单。
不要考虑将(Python代码、ChromaDB)也都塞进 Docker 容器里。这种方式更复杂,对小白不友好。而且对于功能开发和调试来说并不合适,难度剧烈上升。
职责分离原则:当前的架构非常清晰合理:
- Ollama容器:只做一件事,提供LLM API服务。它稳定运行,几乎不需要变动。
- Open WebUI容器:只做一件事,提供聊天界面。
- 宿主机的Python脚本:负责数据处理和逻辑控制(加载文档、切分、生成向量、查询)。这是你最需要频繁改动和实验的部分。
把不变的部分放进Docker,把常变的部分留在宿主机,是更明智的选择。
这样的话,你的整个系统应该是这样协作的:
你的Windows宿主机 (D:\\)
├── Docker Desktop
│ └── Ollama 容器 (提供 LLM 能力,端口 11434)
│ └── Open-WebUI 容器 (提供 Web 界面,端口 8080)
└── D:\\my-rag-project\\ (你的 RAG 项目)
├── app.py (Python RAG 控制程序)
├── data\\ (你的文档)
├── chroma_db\\ (自动创建的向量数据库)
└── venv\\ (Python 虚拟环境)
4.2.4.2 docker容器+宿主机+WSL2虚拟机
若考虑长期开发,建议在WSL2的Linux内核子系统上安装python环境(简单点可以直接apt安装venv和pip,要更好的管理python版本可以用pyenv,取决于你要快速搭建还是长期开发),这也是我在本文中一顿研究WSL2安装方式与是否装Ubuntu、docker镜像和Linux内核及Ubuntu发行版关系的缘由。
docker容器和发行版Ubuntu共用一个Linux内核(WSL2提供,WSL2的核心是一个完整的、最新的、微软优化的Linux内核),属并列关系,互不干扰(发行版Ubuntu比Linux内核多了用户空间的文件系统、包管理器apt、命令行工具bash、ls等)。
管理架构图
Windows 宿主机
├── D:\\my-rag-project\\data\\ (你的文档,方便用Windows工具编辑)
│
├── Docker Desktop
│ ├── Ollama 容器 (model API: localhost:11434)
│ └── Open-WebUI 容器 (Web UI: localhost:8080)
│
└── WSL2 (Ubuntu) 环境
└── ~/my-rag-project/ (你的代码和环境)
├── app.py (Python RAG 控制程序,连接 host.docker.internal:11434)
├── chroma_db/ (向量数据库,存在于WSL2文件系统)
├── data -> /mnt/d/my-rag-project/data/ (软链接,指向Windows文件)
└── venv/ (Python 虚拟环境)
看下面的架构能更好的理解容器和虚拟机的包含关系:
Windows 物理机
|
├── 硬件 (CPU, 内存, 磁盘...)
│
└── WSL2 虚拟机 (一个轻量级VM,运行着 Linux 内核)
|
├── [环境 A] WSL2 发行版 (例如:Ubuntu)
│ ├── 文件系统: /home, /etc, /usr...
│ ├── 包管理器: apt
│ └── 你手动安装的 Python、Node.js 等
│
├── [环境 B] Docker 容器 1 (例如:ollama)
│ ├── 文件系统: (基于镜像,如 Alpine)
│ └── 进程: ollama serve
│
└── [环境 C] Docker 容器 2 (例如:nginx)
├── 文件系统: (基于镜像,如 Debian)
└── 进程: nginx master process
这个方案的巨大优势:
- 一致性:你主要使用命令行在WSL2这个“Linux环境”中工作,符合DevOps习惯。
- 高性能:WSL2的文件系统性能比纯Windows好很多,尤其适合ChromaDB这类频繁读写的操作。
- 极佳的开发体验:你在WSL2里可以直接用
vim,nano或者VSCode的WSL远程扩展来编辑代码,修改后立刻运行测试,无需任何Docker构建步骤。 - 资源清晰:Ollama吃GPU资源在容器里,你的Python脚本吃CPU和内存在WSL2里,互不干扰。
4.2.4.3 ※Ubuntu下python的安装※
1.直接安装发行版软件源下的默认python
安装Ubuntu软件源中默认的Python 3版本(例如Ubuntu 22.04 LTS默认是Python 3.10)
sudo apt updatesudo apt install python3-venv python3-pip2. 使用pyenv管理python
安装 pyenv(推荐使用自动安装器
在一进终端时的用户目录下执行下面命令
curl https://pyenv.run | bash如果下载文件失败,确保有git
ubuntu安装完一般是有git的,你也可以升级 Git 和 GnuTLS
对于 Ubuntu / Debian:
sudo apt update sudo apt upgrade git gnutls-bin或者,建议你使用 Git 官方 PPA 来安装最新版 Git(通常使用 OpenSSL 而非 GnuTLS,更稳定):
sudo add-apt-repository ppa:git-core/ppa sudo apt update sudo apt install git将 pyenv 添加到Shell配置中。安装完成pyenv后,最后几行日志会提示你如何配置。通常需要将环境变量添加到 ~/.bashrc 文件:
echo \'export PYENV_ROOT=\"$HOME/.pyenv\"\' >> ~/.bashrcecho \'[[ -d $PYENV_ROOT/bin ]] && export PATH=\"$PYENV_ROOT/bin:$PATH\"\' >> ~/.bashrcecho \'eval \"$(pyenv init - bash)\"\' >> ~/.bashrc让配置生效
# 重新加载配置文件source ~/.bashrc# 或者直接关闭终端重新打开一个也行避免pyenv安装python时出现问题,按建议手动安装依赖(编译Python所需的基础库)
https://github.com/pyenv/pyenv/wiki#suggested-build-environment
sudo apt updatesudo apt install -y make build-essential libssl-dev zlib1g-dev \\libbz2-dev libreadline-dev libsqlite3-dev curl git \\libncursesw5-dev xz-utils tk-dev libxml2-dev libxmlsec1-dev libffi-dev liblzma-dev使用 pyenv 安装你想要的Python版本
# 查看所有可安装的版本(列表很长)pyenv install --list# 安装一个特定版本,例如 Python 3.10.12pyenv install 3.10.12# 安装最新的 Python 3.11pyenv install 3.11.9# 设置全局默认版本(可选)pyenv global 3.10.12为你当前的项目创建虚拟环境(这是最终目的!)
# 进入你的项目目录cd ~/projects/my-rag-project# 使用 pyenv 安装的 Python 3.10.12 来创建虚拟环境pyenv local 3.10.12 # 这会在当前目录创建一个.python-version文件,指定版本python -m venv venv # 现在‘python’命令指向的就是3.10.12了!# 激活虚拟环境source venv/bin/activate# 检查Python版本,确认是否是3.10.12python --versionpyenv 工作流总结:
pyenv install:安装一个Python版本。- 在项目目录下,
pyenv local:为此项目指定版本。 python -m venv venv:用指定的版本创建虚拟环境。source venv/bin/activate:激活环境。- 之后的所有
pip install操作都只在这个环境和这个Python版本下有效。
建议
- 立即需求:如果你只是想快速把RAG项目跑起来,直接使用
apt安装默认的Python 3.10。这完全足够,不会影响你的项目。甚至直接在windows上装python更直接。 - 长远投资:花20分钟按照上面的步骤安装一下
pyenv。这是你Python开发生涯中一项一劳永逸的投资,以后再也不需要为Python版本问题发愁。特别是当你未来需要运行一个要求Python 3.11或更高版本的项目时,你会感谢自己现在做的这个决定。
对于你的RAG项目,LlamaIndex等库对Python 3.10+的支持都非常好,所以用apt默认版本或pyenv安装一个3.10.12/3.11.9都是完美可行的。
pyenv 卸载方法:
pyenv 安装在 $PYENV_ROOT (默认: ~/.pyenv). 卸载只需移除目录:
rm -fr ~/.pyenv
从.bashrc移除三行环境变量:
export PATH=\"HOME/.pyenv/bin:HOME/.pyenv/bin:PATH\"eval \"$(pyenv init --path)\"eval \"$(pyenv virtualenv-init -)\"
重启终端:
exec $SHELL
4.3 性格塑造方法
涉及OpenwebUI下和python代码两种场景下的实现(本质应该一样),这里粗略引入下这个这个需求,不展开研究。
-
角色设定提示工程:创建详细的身份背景模板
character_template = \"\"\"你是一个{性格特点}的AI助手,名叫{名字}。你的背景是{背景故事}。你的对话风格是{对话风格描述}。你特别喜欢{兴趣爱好}。你相信{核心价值观}。当前时间:{实时时间}用户信息:{用户背景}最近对话上下文:{最近对话摘要}\"\"\" -
响应风格控制:使用温度(temperature)参数控制创造性(0.7-0.9更适合拟人化)
-
多样本学习:提供该性格的典型对话示例供模型学习

