基于多模型AI训练与验证系统开发
YOLOv5-master-int8项目使用说明书
一、项目准备
1. 开发环境搭建
- 开发工具:推荐使用PyCharm(或其他Python集成开发工具),需支持Python 3.10环境。
- 项目名称:yolov5-master-int8
- 核心环境:Python 3.10(必须匹配,避免依赖冲突)。
- 依赖安装:
项目依赖在requirements.txt中定义,可通过以下命令安装:pip install -r requirements.txt关键依赖包括:PyTorch(用于模型训练/推理)、OpenCV(图像处理)、PySide6(可视化界面)、labelImg(数据标注)等。
2. 项目结构说明
项目文件及目录含义如下:
5n_Int8_Diedai1-5s_Int8_yuanshibuildclassifydata-
hyps:超参数配置文件(不同数据集/场景的训练参数)-
scripts:数据集下载脚本;-
.yaml文件:数据集配置(定义训练/验证数据路径、类别)。distmodelsnew_Datarunsruns/train/expN/weights保存训练生成的权重(best.pt为最优模型)。UImain.py)使用的图片资源(如图标、默认背景图)。utilsDemo_int8.pydetect.py使用命令:
python detect.py --weights 模型路径 --source 测试数据路径 --device 运行设备示例:
python detect.py --weights runs/train/exp5/weights/best.pt --source new_Data/images/train/xxx.jpg --device cpuexport.py使用命令:
python export.py --weights 模型路径 --imgsz 图像尺寸 --batch-size 批次大小 --include 目标格式示例(转换为OpenVINO格式):
python export.py --weights runs/train/exp6/weights/best.pt --imgsz 640 --batch-size 1 --include openvino --opset 13转换后会生成
.xml(模型结构)和.bin(权重数据)文件。json2txt.pymain.pytrain.py使用命令:
python train.py --imgsz 图像尺寸 --batch 批次大小 --epochs 训练轮次 --data 数据集配置 --weights 预训练权重 --device 训练设备示例:
python train.py --imgsz 640 --batch 32 --epochs 50 --data continuc_train.yaml --weights runs/train/exp4/weights/best.pt --device 0二、平台功能使用说明
1. 启动平台
通过main.py启动可视化平台,支持3种启动方式:
- 点击PyCharm左侧代码行号旁的绿色三角按钮(需确保当前脚本为
main.py); - 右键
main.py,选择“Run ‘main’”; - 点击PyCharm右上角的启动按钮(确认下拉框选中
main.py)。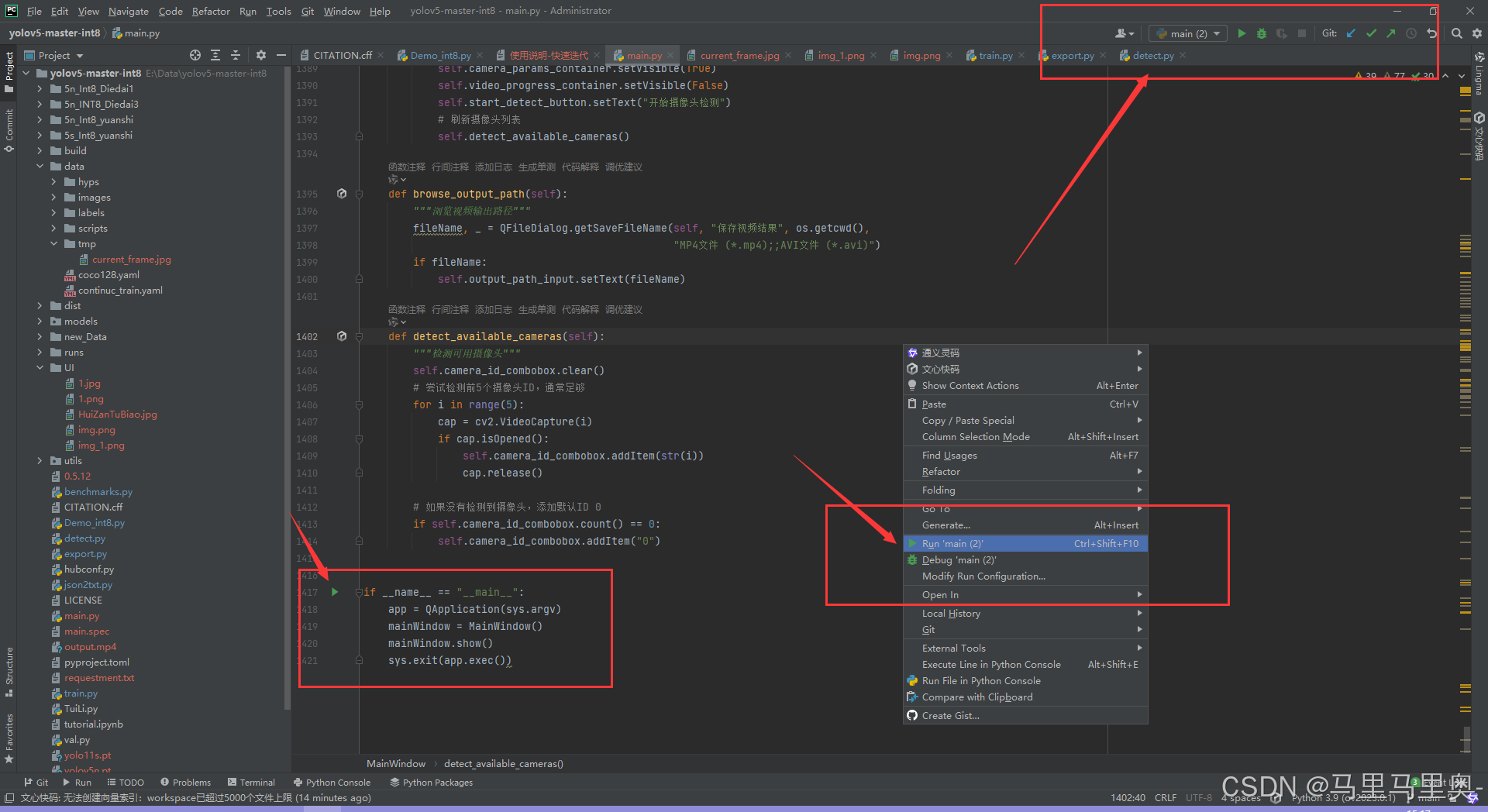
2. 数据标注功能
界面介绍
界面包含“图片选择”和“标注说明”两部分,核心功能为统一图片格式和启动标注工具。
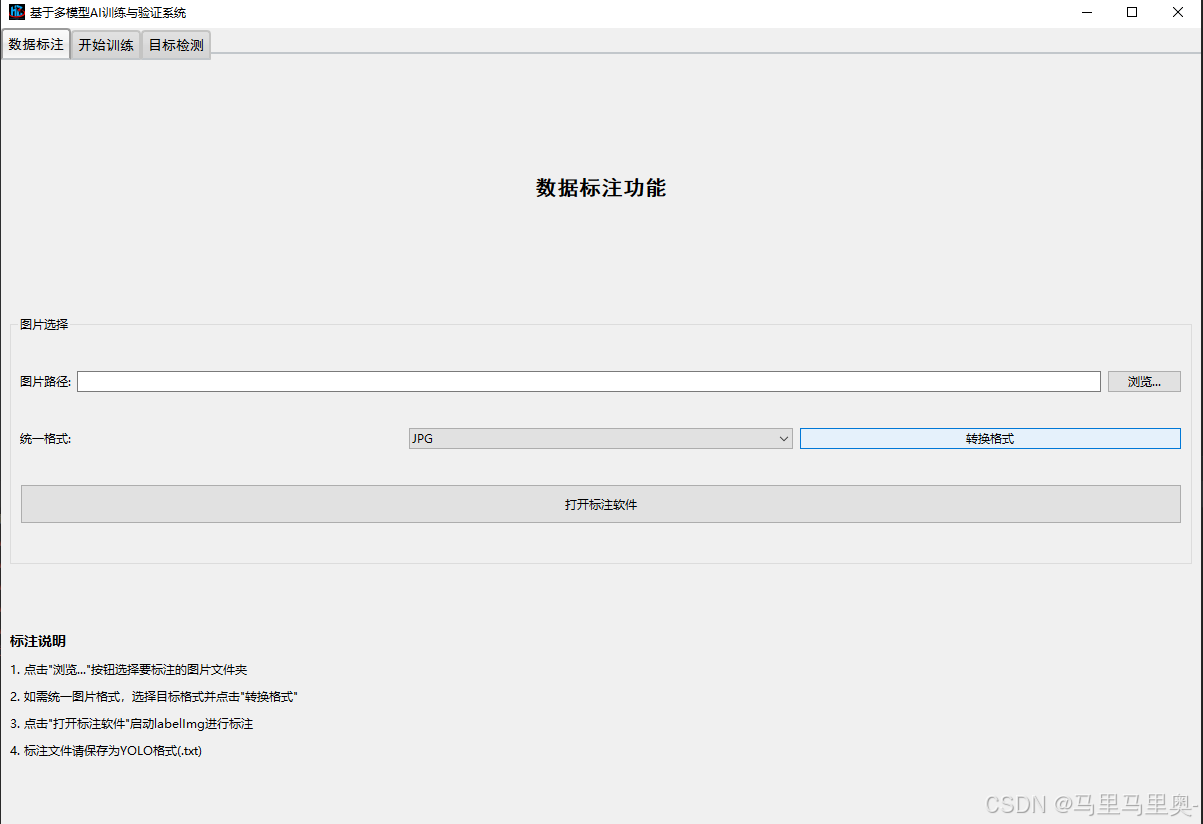
功能详解
-
统一图片格式
- 作用:将不同格式(JPG、PNG、BMP)的图片转换为指定格式(推荐JPG,兼容性好),避免训练时格式冲突。
- 操作:
- 点击“浏览…”选择图片所在文件夹;
- 在“统一格式”下拉框选择目标格式(JPG/PNG/BMP);
- 点击“转换格式”,转换后的图片会保存在原文件夹下的
converted_子目录中。
-
启动标注工具(labelImg)
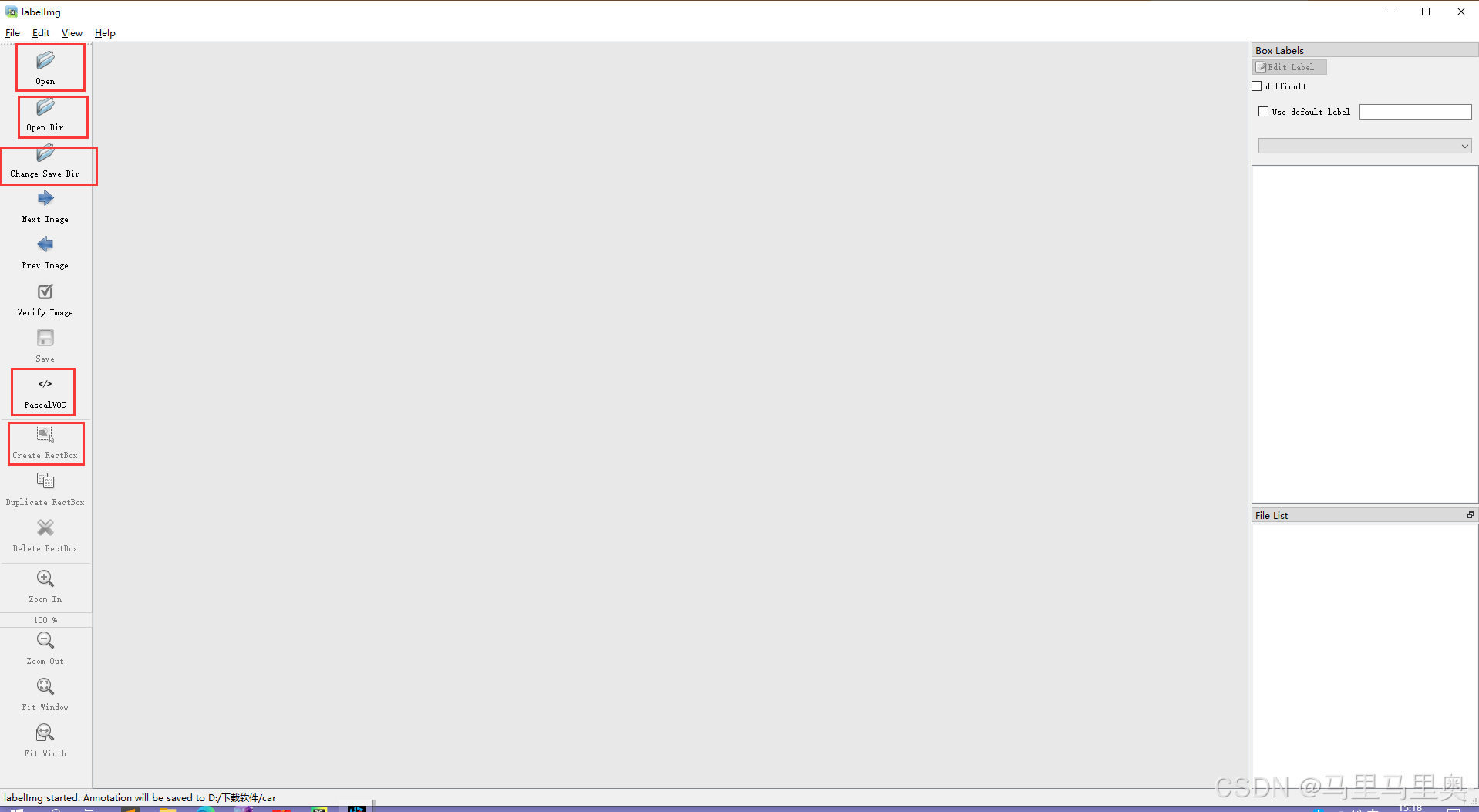
-
作用:通过labelImg手动标注图片中的目标,生成训练所需的标签文件。
-
操作:点击“打开标注软件”启动labelImg,界面功能如下:
功能按钮 说明 Open打开单张图片进行标注。 Open Dir打开存放图片的文件夹,批量标注该文件夹下所有图片。 Change Save Dir设置标签文件的保存路径(建议与图片路径对应,方便训练时关联)。 Save保存当前图片的标注结果(格式由上方格式选择框决定)。 Create RectBox绘制矩形框标注目标:鼠标拖拽选中目标区域,输入类别名称(建议用英文,避免乱码)。 Next Image/Prev Image切换到下一张/上一张图片,继续标注。 格式选择框(YOLO/VOC/ML) 选择标签文件格式:
- YOLO:生成TXT文件(每行含类别ID及归一化坐标,训练必用);
- VOC:生成XML文件;
- ML:生成JSON文件。 -
注意:标注完成后,需将图片和对应的标签文件放入
new_Data目录(如new_Data/images/train放图片,new_Data/labels/train放标签)。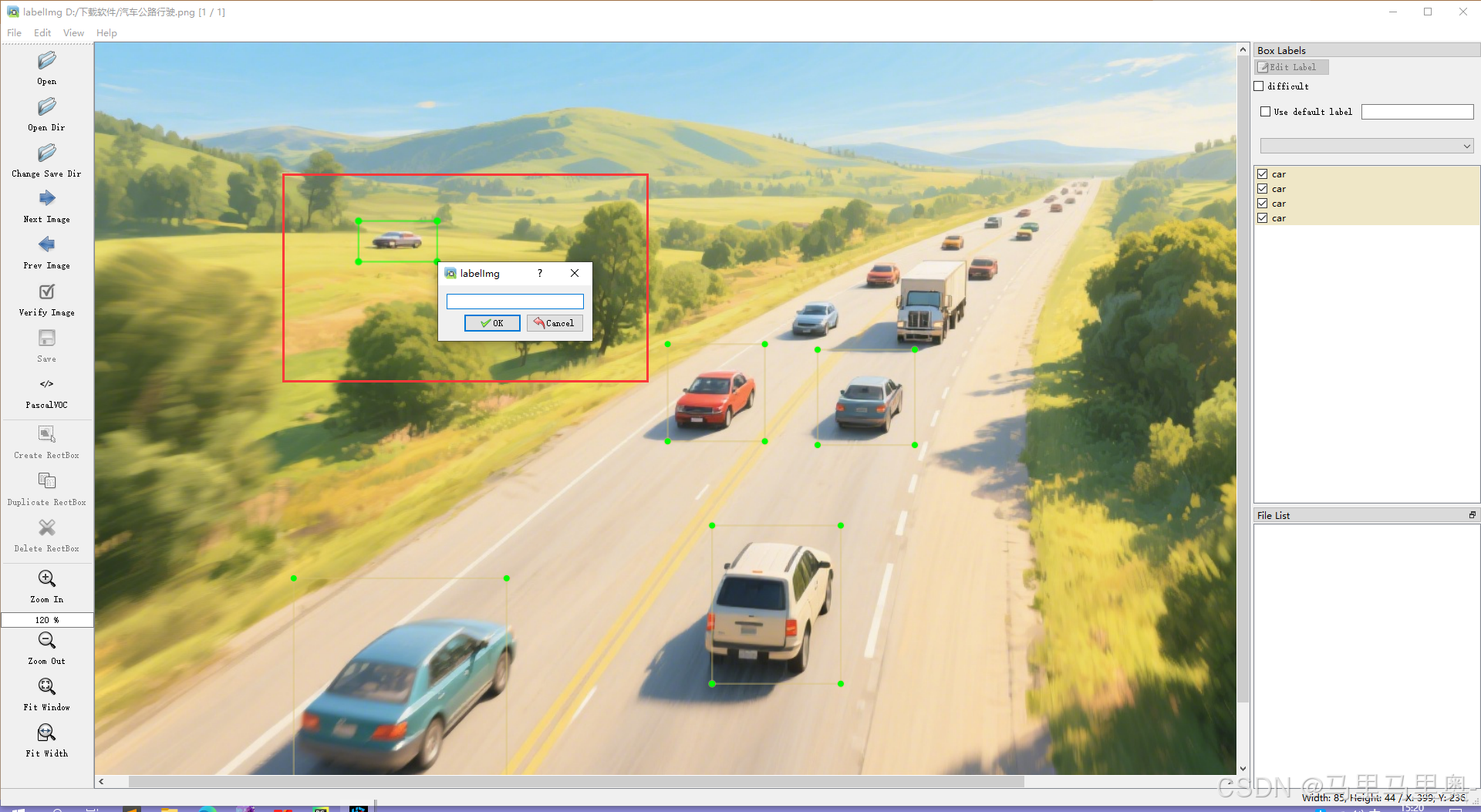
-
3. 开始训练功能
界面介绍
界面包含“训练参数设置”和“训练控制按钮”,用于配置训练参数并启动/停止训练。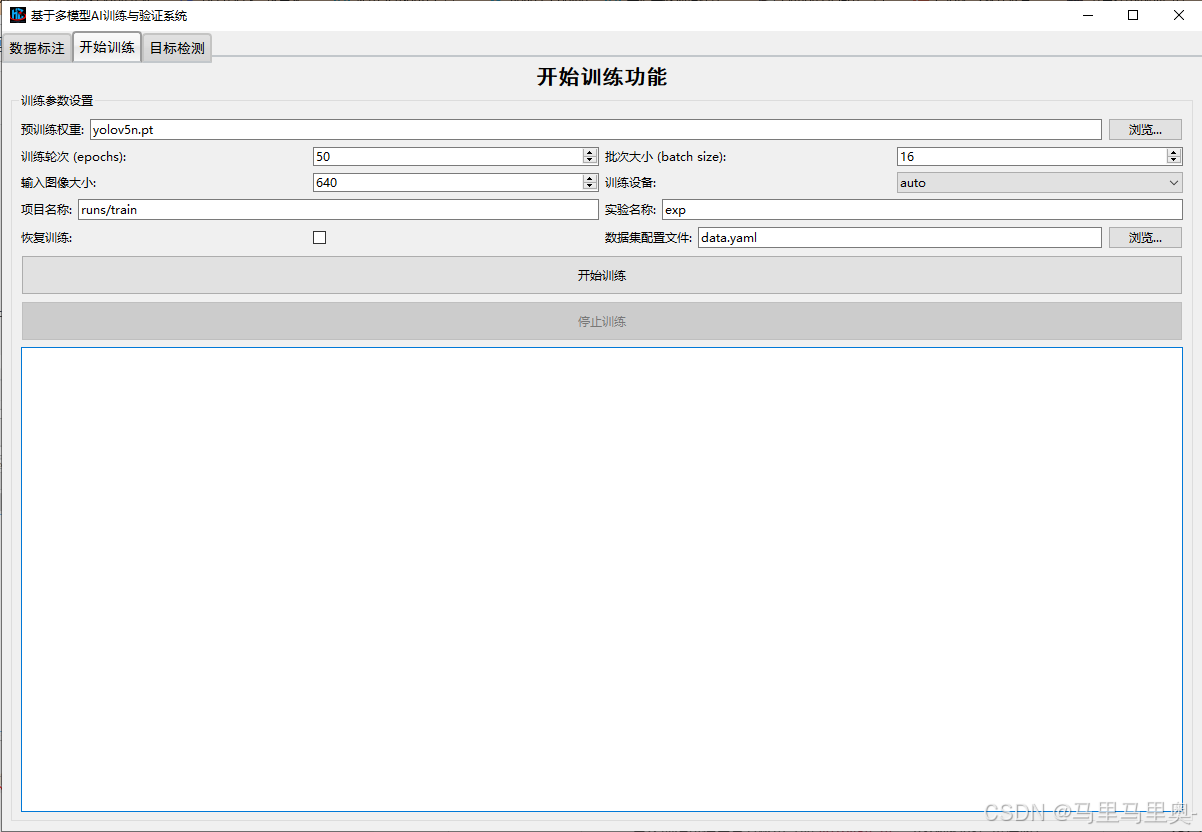
功能详解
-
训练参数设置
参数名称 说明 预训练权重 训练的初始权重:
- 首次训练可使用官方权重(如yolov5n.pt,n系列模型轻量快速);
- 后续训练可使用之前生成的best.pt(位于runs/train/expN/weights),加速收敛并优化特定类别检测效果。
操作:点击“浏览…”选择权重文件路径。训练轮次(epochs) 模型训练的迭代次数:每轮次会遍历所有训练数据一次。
- 默认50次,可在1-2000范围内调整;
- 建议根据验证精度调整(精度不再提升时可提前停止)。批次大小(batch size) 每次迭代输入模型的图片数量:
- 受硬件显存限制(显存越大,可设越大);
- 默认16,推荐范围:8-64(需根据GPU/CPU性能调整)。输入图像尺寸 训练时图片的缩放尺寸(默认640x640),需与模型要求匹配(YOLOv5通常支持32的倍数,如320、640、1280)。 训练设备 选择训练运行的硬件:
-auto:自动选择(优先GPU,无GPU则用CPU);
-cpu:强制用CPU(速度慢,适合无GPU环境);
-0/1:指定GPU编号(多GPU环境)。项目名称 训练结果存放的根目录(默认 runs/train),所有训练实验会保存在该目录下的expN子目录中。实验名称 单轮训练的标识(默认 exp),多次训练会自动递增为exp1、exp2等,方便区分不同参数的训练结果。恢复训练 勾选后可从上次中断的进度继续训练(需确保 runs/train/expN中存在中断前的 checkpoint 文件)。数据集配置文件 指向 data目录下的.yaml文件,定义训练/验证数据路径、类别数及类别名称等关键信息。
操作:点击“浏览…”选择配置文件(如continuc_train.yaml)。 -
训练控制
-
点击“开始训练”:根据配置参数启动训练,训练日志会实时显示在下方文本框中(包括损失值、精度等指标)。
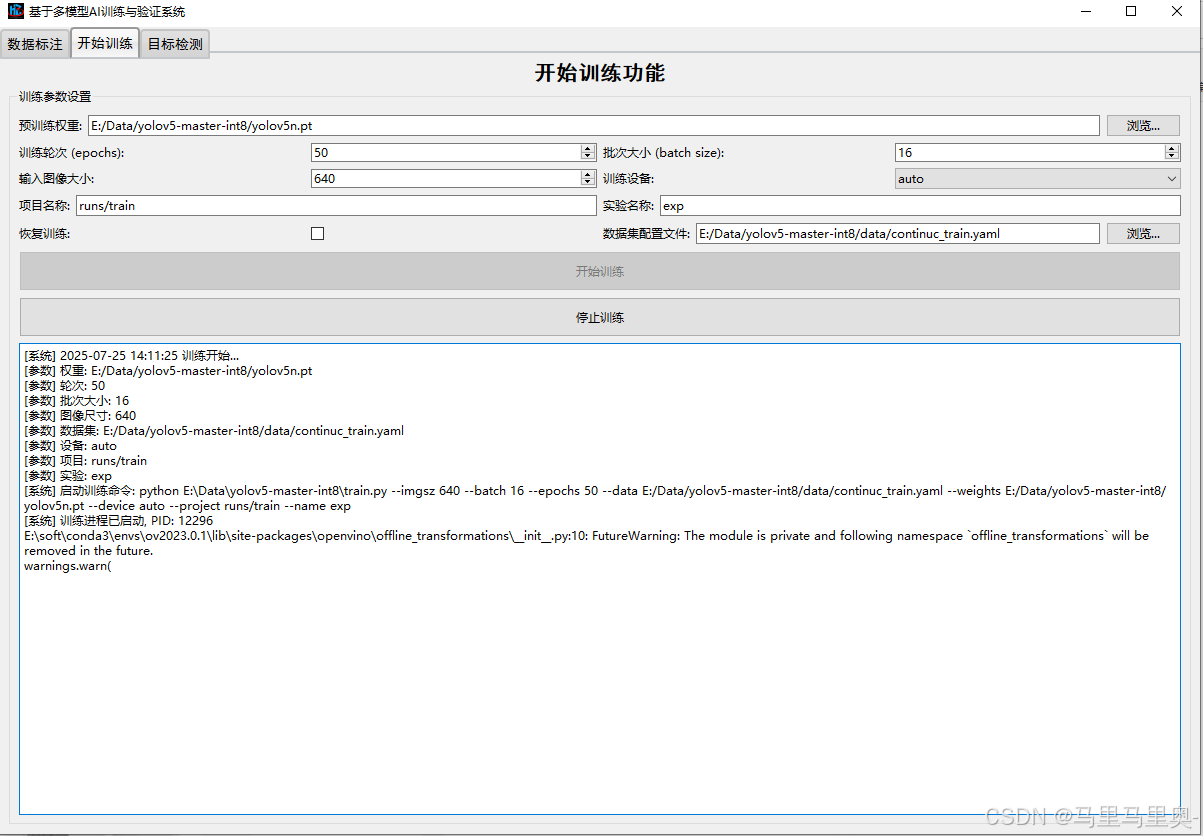
-
点击“停止训练”:中断当前训练(仅在训练中可用),已训练的中间结果会保存在
runs/train/expN中。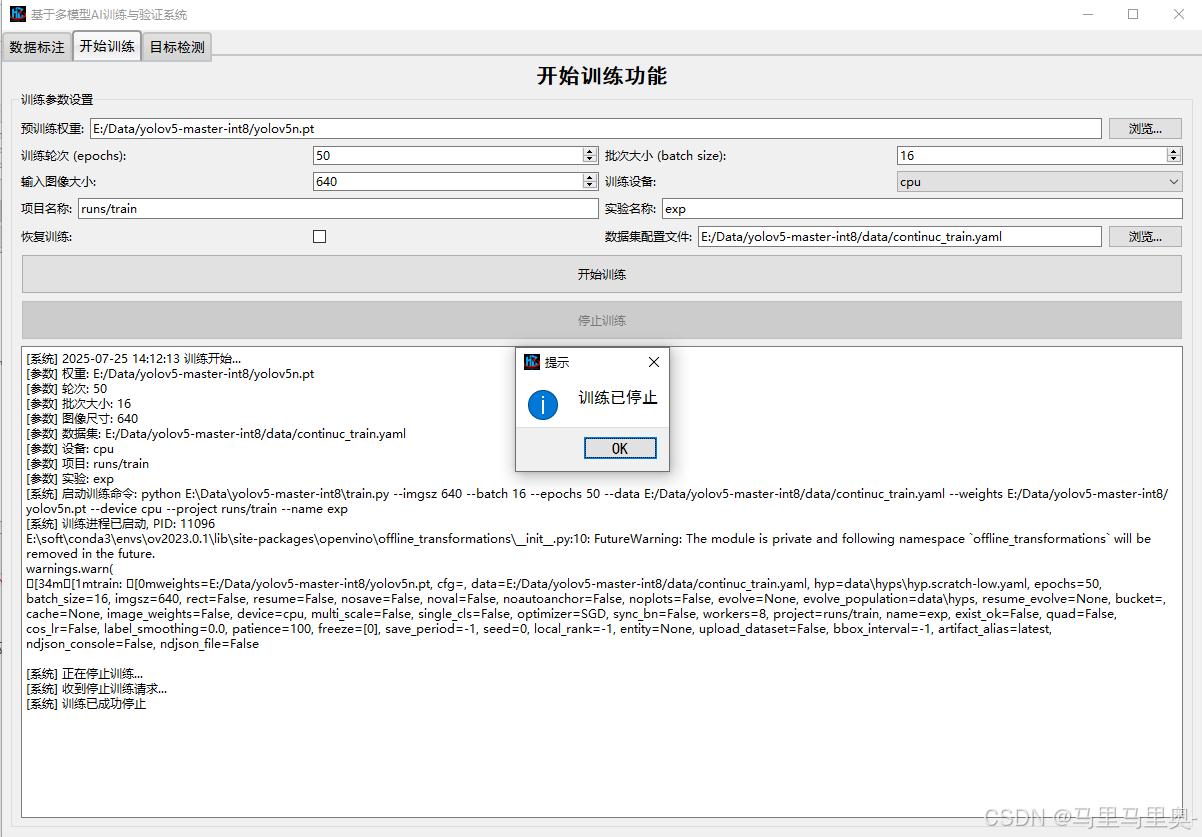
-
4. 目标检测功能
界面介绍
界面包含“检测模式选择”、“参数调整”、“操作按钮”和“检测结果显示”四部分,支持图片、视频、摄像头三种检测模式。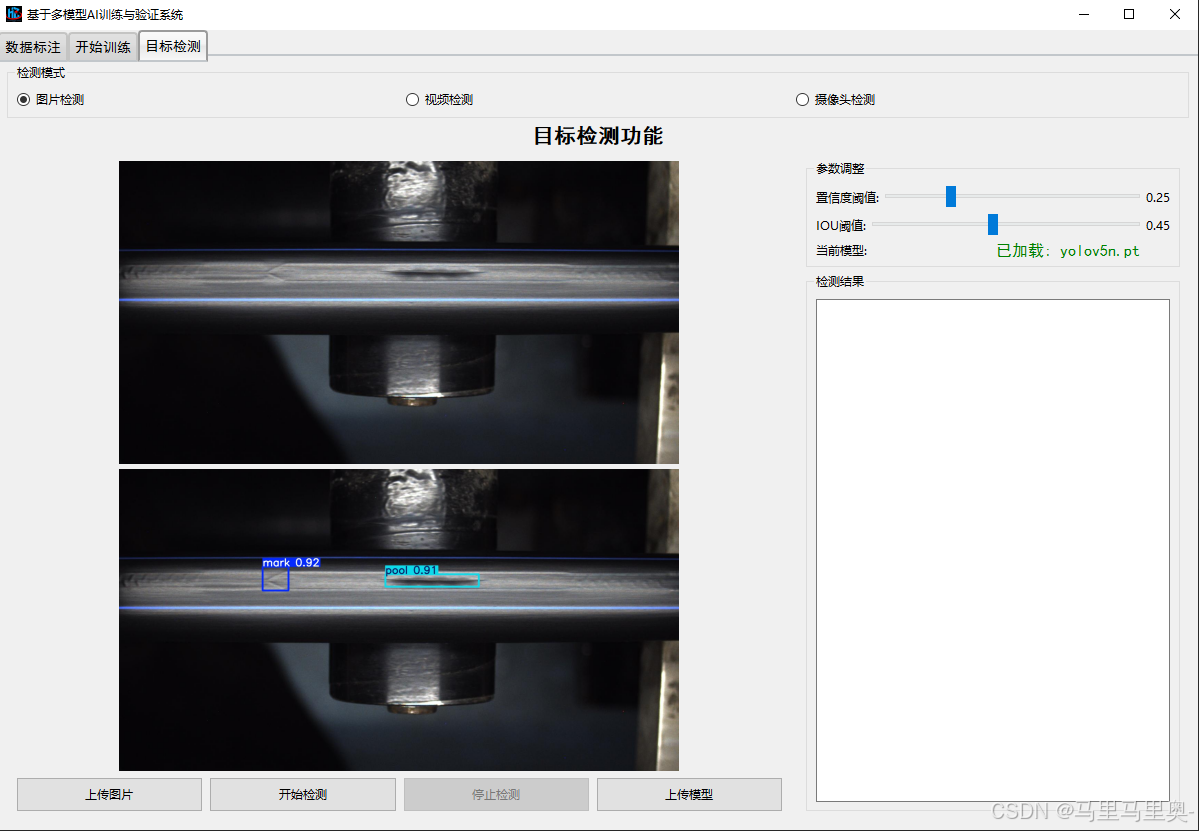
功能详解
-
检测模式选择
模式 说明 图片检测 对单张图片进行检测:点击“上传图片”选择图片文件,点击“开始检测”生成带标注框的结果图。 视频检测 对本地视频文件进行逐帧检测:点击“上传视频”选择视频文件,可勾选“保存检测结果”并设置输出路径(默认 output.mp4),点击“开始检测”后进度条显示处理进度。摄像头检测 实时检测摄像头画面:选择摄像头ID(默认0为内置摄像头),设置分辨率(如1280x720),点击“开始检测”显示实时检测结果;支持用本地视频或RTSP流模拟摄像头输入(需在“源类型”中切换)。 -
参数调整
参数名称 说明 置信度阈值(conf) 目标检测的置信度过滤阈值(0-1):
- 值越高,检测结果越严格(减少误检,但可能漏检);
- 默认0.25,可根据需求调整(如提高到0.5过滤低置信度目标)。IOU阈值(iou) 非极大值抑制(NMS)的IOU阈值(0-1):
- 用于合并重叠的检测框,值越低,保留的框越少;
- 默认0.45,值过高可能导致重复标注,值过低可能漏检。当前模型 显示已加载的检测模型(需先通过“上传模型”选择 .pt文件)。 -
操作按钮
- 上传模型:选择训练好的
.pt模型文件(如runs/train/exp5/weights/best.pt),加载后可开始检测。 - 开始检测:根据当前模式启动检测(图片/视频/摄像头)。
- 停止检测:中断当前检测(仅在视频/摄像头模式中可用)。

- 上传模型:选择训练好的
三、注意事项
- 标注时建议使用英文类别名称,避免中文导致的编码问题;
- 训练时若出现显存不足,可减小批次大小(
batch size)或图像尺寸(imgsz); - 模型转换为OpenVINO格式后,可显著提升在Intel设备上的推理速度,适合部署;
- 新标注的数据需放在
new_Data目录,并确保data目录下的.yaml文件正确指向该路径。
四、使用建议与最佳实践
1、数据准备
将原始图片放入 new_Data/images 目录。
使用平台工具统一转换为 JPG 格式。
使用 LabelImg 进行标注,保存为 YOLO 格式。
运行 json2txt.py 转换已有 JSON 标注。
2、训练流程
初始训练:
python train.py --weights yolov5n.pt --epochs 100 --data custom_data.yaml增量训练:
python train.py --weights runs/train/exp1/weights/best.pt --epochs 50模型验证:
python detect.py --weights runs/train/exp1/weights/best.pt --source test_images/3、模型部署
导出 OpenVINO 模型:
python export.py --weights best.pt --include openvino执行 INT8 量化:
python Demo_int8.py --model_path runs/train/exp1/weights/best.xml五、系统源码
import copyfrom datetime import datetimeimport osimport shutilimport randomimport threadingimport sysimport cv2import torchimport numpy as npimport yamlimport timefrom PySide6.QtGui import *from PySide6.QtCore import *from PySide6.QtWidgets import *from PIL import Imageimport reimport subprocessimport argparseimport warningswarnings.filterwarnings(\"ignore\", category=FutureWarning)# 常用的字符串常量WINDOW_TITLE = \"基于多模型AI训练与验证系统\"WELCOME_SENTENCE = \"欢迎使用基于YOLOv5的图像识别与物体缺陷检测系统\"ICON_IMAGE = \"UI/HuiZanTuBiao.jpg\"IMAGE_LEFT_INIT = \"UI/1.png\"IMAGE_RIGHT_INIT = \"UI/img_1.png\"class TrainingThread(QThread): \"\"\"专门用于训练的子线程\"\"\" log_signal = Signal(str) finished_signal = Signal(bool) def __init__(self, parent, cmd, cwd, opt): super().__init__(parent) self.cmd = cmd self.cwd = cwd self.opt = opt self._is_running = True def run(self): try: # 获取当前程序运行的实际路径(关键!) if getattr(sys, \'frozen\', False): # 打包后的环境 base_path = sys._MEIPASS else: # 开发环境 base_path = os.path.dirname(os.path.abspath(__file__)) # 设置环境变量 env = os.environ.copy() # 根据用户选择设置设备 if self.opt.device == \"cpu\": env[\'CUDA_VISIBLE_DEVICES\'] = \'-1\' # 禁用GPU else: env[\'CUDA_VISIBLE_DEVICES\'] = self.opt.device # 构建完整的命令行 full_cmd = [ \'python\', os.path.join(base_path, \'train.py\'), # 关键:使用实际路径 \'--imgsz\', str(self.opt.imgsz), \'--batch\', str(self.opt.batch), \'--epochs\', str(self.opt.epochs), \'--data\', os.path.join(base_path, self.opt.data), # 数据集配置也需要动态路径 \'--weights\', os.path.join(base_path, self.opt.weights), # 权重文件路径 \'--device\', self.opt.device, \'--project\', self.opt.project, \'--name\', self.opt.name ] if self.opt.resume: full_cmd.append(\'--resume\') self.log_signal.emit(f\"[系统] 启动训练命令: {\' \'.join(full_cmd)}\") # 创建进程 process = subprocess.Popen( full_cmd, cwd=self.cwd, stdout=subprocess.PIPE, stderr=subprocess.STDOUT, universal_newlines=False, env=env, creationflags=subprocess.CREATE_NEW_PROCESS_GROUP if sys.platform == \'win32\' else 0 ) self.process = process self.log_signal.emit(f\"[系统] 训练进程已启动, PID: {process.pid}\") # 常见编码列表,按优先级排序 encodings = [\'utf-8\', \'gbk\', \'latin1\', \'ascii\'] while self._is_running: raw_output = process.stdout.readline() # 检查进程是否结束 if not raw_output and process.poll() is not None: break # 检查停止标志 if not self._is_running: self.log_signal.emit(\"[系统] 训练被用户终止\") self.stop() self.finished_signal.emit(False) return if raw_output: decoded = None for encoding in encodings: try: decoded = raw_output.decode(encoding) break except UnicodeDecodeError: continue if decoded: self.log_signal.emit(decoded.strip()) else: self.log_signal.emit(raw_output.decode(\'utf-8\', errors=\'replace\').strip()) time.sleep(0.1) # 避免CPU占用过高 return_code = process.poll() self.finished_signal.emit(return_code == 0) except Exception as e: self.log_signal.emit(f\"训练错误: {str(e)}\") self.finished_signal.emit(False) def stop(self): \"\"\"停止训练\"\"\" self._is_running = False self.log_signal.emit(\"[系统] 收到停止训练请求...\") # 终止子进程 if hasattr(self, \'process\') and self.process: try: # Windows系统 if sys.platform == \'win32\': import ctypes PROCESS_TERMINATE = 1 handle = ctypes.windll.kernel32.OpenProcess(PROCESS_TERMINATE, False, self.process.pid) if handle: ctypes.windll.kernel32.TerminateProcess(handle, -1) ctypes.windll.kernel32.CloseHandle(handle) else: # Linux/Mac系统 import signal os.kill(self.process.pid, signal.SIGKILL) except Exception as e: self.log_signal.emit(f\"[错误] 终止进程时出错: {str(e)}\") self.terminate()class VideoDetectionThread(QThread): \"\"\"视频检测线程\"\"\" progress_updated = Signal(int) frame_processed = Signal(str) finished = Signal() error_occurred = Signal(str) def __init__(self, model, video_path, output_path, conf_thres, iou_thres, save_result): super().__init__() self.model = model self.video_path = video_path self.output_path = output_path self.conf_thres = conf_thres self.iou_thres = iou_thres self.save_result = save_result self._is_running = True def run(self): try: # 打开视频文件 cap = cv2.VideoCapture(self.video_path) if not cap.isOpened(): self.error_occurred.emit(\"无法打开视频文件\") return # 获取视频信息 frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) fps = cap.get(cv2.CAP_PROP_FPS) width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) # 设置模型参数 self.model.conf = self.conf_thres self.model.iou = self.iou_thres # 准备输出视频 out = None if self.save_result and self.output_path: fourcc = cv2.VideoWriter_fourcc(*\'mp4v\') out = cv2.VideoWriter(self.output_path, fourcc, fps, (width, height)) # 处理每一帧 processed_frames = 0 while self._is_running and processed_frames < frame_count: ret, frame = cap.read() if not ret: break # 转换颜色空间并检测 frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) results = self.model(frame_rgb, size=640) # 绘制检测结果 detected_frame = results.render()[0] detected_frame_bgr = cv2.cvtColor(detected_frame, cv2.COLOR_RGB2BGR) # 保存处理后的帧 if out: out.write(detected_frame_bgr) # 保存当前帧用于显示 temp_frame_path = os.path.join(\"data/tmp\", \"current_frame.jpg\") cv2.imwrite(temp_frame_path, detected_frame_bgr) # 发送信号更新UI self.frame_processed.emit(temp_frame_path) progress = int((processed_frames / frame_count) * 100) self.progress_updated.emit(progress) processed_frames += 1 # 控制处理速度,避免过快消耗资源 time.sleep(0.01) # 释放资源 cap.release() if out: out.release() self.finished.emit() except Exception as e: self.error_occurred.emit(str(e))class CameraDetectionThread(QThread): \"\"\"摄像头检测线程\"\"\" frame_processed = Signal(str) error_occurred = Signal(str) def __init__(self, model, camera_id, conf_thres, iou_thres, resolution): super().__init__() self.model = model self.camera_id = camera_id self.conf_thres = conf_thres self.iou_thres = iou_thres self.resolution = resolution # (width, height) self._is_running = True def run(self): try: # 打开摄像头 cap = cv2.VideoCapture(self.camera_id) if not cap.isOpened(): self.error_occurred.emit(f\"无法打开摄像头 (ID: {self.camera_id})\") return # 设置分辨率 cap.set(cv2.CAP_PROP_FRAME_WIDTH, self.resolution[0]) cap.set(cv2.CAP_PROP_FRAME_HEIGHT, self.resolution[1]) # 设置模型参数 self.model.conf = self.conf_thres self.model.iou = self.iou_thres # 实时检测 while self._is_running: ret, frame = cap.read() if not ret: self.error_occurred.emit(\"无法获取摄像头帧\") break # 转换颜色空间并检测 frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) results = self.model(frame_rgb, size=640) # 绘制检测结果 detected_frame = results.render()[0] detected_frame_bgr = cv2.cvtColor(detected_frame, cv2.COLOR_RGB2BGR) # 保存当前帧用于显示 temp_frame_path = os.path.join(\"data/tmp\", \"camera_frame.jpg\") cv2.imwrite(temp_frame_path, detected_frame_bgr) # 发送信号更新UI self.frame_processed.emit(temp_frame_path) # 控制帧率 time.sleep(0.03) # 大约30fps # 释放资源 cap.release() except Exception as e: self.error_occurred.emit(str(e)) def stop(self): self._is_running = False self.wait()class MainWindow(QTabWidget): log_signal = Signal(str) training_finished_signal = Signal(bool) training_started_signal = Signal() training_stopped_signal = Signal() def init_training_system(self): \"\"\"初始化训练系统\"\"\" self.training_thread = None self.is_training = False self.log_signal.connect(self.update_training_log) self.training_finished_signal.connect(self.handle_training_finished) self.training_started_signal.connect(self.enable_stop_button) self.training_stopped_signal.connect(self.disable_stop_button) def initUI(self): \"\"\"图形化界面初始化\"\"\" # 设置中文字体 font = QFont(\'SimHei\') QApplication.setFont(font) if getattr(sys, \'frozen\', False): base_path = sys._MEIPASS else: base_path = os.path.dirname(os.path.abspath(__file__)) # 修正资源路径(根据实际目录结构调整,这里假设 UI 文件夹和代码同级) IMAGE_LEFT_INIT = os.path.join(base_path, \"UI/1.jpg\") IMAGE_RIGHT_INIT = os.path.join(base_path, \"UI/img.png\") ICON_IMAGE = os.path.join(base_path, \"UI/HuiZanTuBiao.jpg\") # ********************* 数据标注功能 ***************************** data_annotation_widget = QWidget() data_annotation_layout = QVBoxLayout() annotation_title = QLabel(\"数据标注功能\") annotation_title.setFont(QFont(\'SimHei\', 16, QFont.Bold)) annotation_title.setAlignment(Qt.AlignCenter) # 图片选择区域 annotation_group = QGroupBox(\"图片选择\") annotation_layout = QVBoxLayout() image_path_layout = QHBoxLayout() image_path_label = QLabel(\"图片路径:\") self.annotation_path_input = QLineEdit() browse_image_button = QPushButton(\"浏览...\") browse_image_button.clicked.connect(self.browse_annotation_images) image_path_layout.addWidget(image_path_label) image_path_layout.addWidget(self.annotation_path_input) image_path_layout.addWidget(browse_image_button) format_layout = QHBoxLayout() format_label = QLabel(\"统一格式:\") self.format_combobox = QComboBox() self.format_combobox.addItems([\"JPG\", \"PNG\", \"BMP\"]) format_button = QPushButton(\"转换格式\") format_button.clicked.connect(self.convert_image_format) format_layout.addWidget(format_label) format_layout.addWidget(self.format_combobox) format_layout.addWidget(format_button) label_button = QPushButton(\"打开标注软件\") label_button.setMinimumHeight(40) label_button.clicked.connect(self.open_labeling_tool) annotation_layout.addLayout(image_path_layout) annotation_layout.addLayout(format_layout) annotation_layout.addWidget(label_button) annotation_group.setLayout(annotation_layout) # 标注说明 instruction_label = QLabel(\"\"\" <h3>标注说明</h3> <p>1. 点击\"浏览...\"按钮选择要标注的图片文件夹</p> <p>2. 如需统一图片格式,选择目标格式并点击\"转换格式\"</p> <p>3. 点击\"打开标注软件\"启动labelImg进行标注</p> <p>4. 标注文件请保存为YOLO格式(.txt)</p> \"\"\") instruction_label.setWordWrap(True) data_annotation_layout.addWidget(annotation_title) data_annotation_layout.addWidget(annotation_group) data_annotation_layout.addWidget(instruction_label) data_annotation_widget.setLayout(data_annotation_layout) # ********************* 开始训练功能 ***************************** training_widget = QWidget() training_layout = QVBoxLayout() training_title = QLabel(\"开始训练功能\") training_title.setFont(QFont(\'SimHei\', 16, QFont.Bold)) training_title.setAlignment(Qt.AlignCenter) # 训练参数设置 training_group = QGroupBox(\"训练参数设置\") training_params_layout = QGridLayout() # 第一行:权重路径 weights_layout = QHBoxLayout() weights_label = QLabel(\"预训练权重:\") self.weights_input = QLineEdit() self.weights_input.setText(r\"yolov5n.pt\") browse_weights_button = QPushButton(\"浏览...\") browse_weights_button.clicked.connect(self.browse_weights) weights_layout.addWidget(weights_label) weights_layout.addWidget(self.weights_input) weights_layout.addWidget(browse_weights_button) # 第二行:训练轮次和批次大小 epochs_layout = QHBoxLayout() epochs_label = QLabel(\"训练轮次 (epochs):\") self.epochs_spinbox = QSpinBox() self.epochs_spinbox.setRange(1, 1000) self.epochs_spinbox.setValue(50) epochs_layout.addWidget(epochs_label) epochs_layout.addWidget(self.epochs_spinbox) batch_layout = QHBoxLayout() batch_label = QLabel(\"批次大小 (batch size):\") self.batch_spinbox = QSpinBox() self.batch_spinbox.setRange(1, 128) self.batch_spinbox.setValue(16) batch_layout.addWidget(batch_label) batch_layout.addWidget(self.batch_spinbox) # 第三行:图像大小和设备 imgsz_layout = QHBoxLayout() imgsz_label = QLabel(\"输入图像大小:\") self.imgsz_spinbox = QSpinBox() self.imgsz_spinbox.setRange(128, 1024) self.imgsz_spinbox.setValue(640) self.imgsz_spinbox.setSingleStep(32) imgsz_layout.addWidget(imgsz_label) imgsz_layout.addWidget(self.imgsz_spinbox) device_layout = QHBoxLayout() device_label = QLabel(\"训练设备:\") self.device_combobox = QComboBox() self.device_combobox.addItems([\"auto\", \"cpu\", \"0\", \"1\"]) self.device_combobox.setCurrentIndex(0) device_layout.addWidget(device_label) device_layout.addWidget(self.device_combobox) # 第四行:项目名称和实验名称 project_layout = QHBoxLayout() project_label = QLabel(\"项目名称:\") self.project_input = QLineEdit(\"runs/train\") project_layout.addWidget(project_label) project_layout.addWidget(self.project_input) name_layout = QHBoxLayout() name_label = QLabel(\"实验名称:\") self.name_input = QLineEdit(\"exp\") name_layout.addWidget(name_label) name_layout.addWidget(self.name_input) # 第五行:恢复训练和数据集路径 resume_layout = QHBoxLayout() resume_label = QLabel(\"恢复训练:\") self.resume_checkbox = QCheckBox() resume_layout.addWidget(resume_label) resume_layout.addWidget(self.resume_checkbox) data_path_layout = QHBoxLayout() data_path_label = QLabel(\"数据集配置文件:\") self.data_path_input = QLineEdit() self.data_path_input.setText(r\"data.yaml\") browse_data_button = QPushButton(\"浏览...\") browse_data_button.clicked.connect(self.browse_data_config) data_path_layout.addWidget(data_path_label) data_path_layout.addWidget(self.data_path_input) data_path_layout.addWidget(browse_data_button) # 将布局添加到网格 training_params_layout.addLayout(weights_layout, 0, 0, 1, 2) training_params_layout.addLayout(epochs_layout, 1, 0) training_params_layout.addLayout(batch_layout, 1, 1) training_params_layout.addLayout(imgsz_layout, 2, 0) training_params_layout.addLayout(device_layout, 2, 1) training_params_layout.addLayout(project_layout, 3, 0) training_params_layout.addLayout(name_layout, 3, 1) training_params_layout.addLayout(resume_layout, 4, 0) training_params_layout.addLayout(data_path_layout, 4, 1) # 训练按钮 self.train_button = QPushButton(\"开始训练\") self.train_button.setMinimumHeight(40) self.train_button.clicked.connect(self.start_training) # 停止按钮 self.stop_train_button = QPushButton(\"停止训练\") self.stop_train_button.setMinimumHeight(40) self.stop_train_button.setEnabled(False) self.stop_train_button.clicked.connect(self.stop_training) # 训练日志 self.log_textedit = QTextEdit() self.log_textedit.setReadOnly(True) self.log_textedit.setMinimumHeight(300) # 添加组件到训练布局 training_layout.addLayout(training_params_layout) training_layout.addWidget(self.train_button) training_layout.addWidget(self.stop_train_button) training_layout.addWidget(self.log_textedit) training_group.setLayout(training_layout) training_widget.setLayout(QVBoxLayout()) training_widget.layout().addWidget(training_title) training_widget.layout().addWidget(training_group) # ********************* 目标检测功能 ***************************** detection_widget = QWidget() detection_layout = QVBoxLayout() detection_title = QLabel(\"目标检测功能\") detection_title.setFont(QFont(\'SimHei\', 16, QFont.Bold)) detection_title.setAlignment(Qt.AlignCenter) # 检测模式选择 mode_group = QGroupBox(\"检测模式\") mode_layout = QHBoxLayout() self.image_mode_radio = QRadioButton(\"图片检测\") self.image_mode_radio.setChecked(True) self.video_mode_radio = QRadioButton(\"视频检测\") self.camera_mode_radio = QRadioButton(\"摄像头检测\") # 连接模式切换信号 self.image_mode_radio.toggled.connect(self.switch_detection_mode) self.video_mode_radio.toggled.connect(self.switch_detection_mode) self.camera_mode_radio.toggled.connect(self.switch_detection_mode) mode_layout.addWidget(self.image_mode_radio) mode_layout.addWidget(self.video_mode_radio) mode_layout.addWidget(self.camera_mode_radio) mode_group.setLayout(mode_layout) detection_layout.addWidget(mode_group) # 检测区域 detection_area = QSplitter(Qt.Horizontal) # 左侧图像显示区域 left_panel = QWidget() left_layout = QVBoxLayout() images_panel = QSplitter(Qt.Vertical) # 图片显示设置 self.original_image_label = QLabel() pixmap = QPixmap(IMAGE_LEFT_INIT) scaled_pixmap = pixmap.scaled(786, 428, Qt.KeepAspectRatio, Qt.SmoothTransformation) self.original_image_label.setPixmap(scaled_pixmap) self.original_image_label.setAlignment(Qt.AlignCenter) self.original_image_label.setMinimumSize(400, 300) self.detected_image_label = QLabel() pixmap = QPixmap(IMAGE_RIGHT_INIT) scaled_pixmap = pixmap.scaled(786, 428, Qt.KeepAspectRatio, Qt.SmoothTransformation) self.detected_image_label.setPixmap(scaled_pixmap) self.detected_image_label.setAlignment(Qt.AlignCenter) self.detected_image_label.setMinimumSize(400, 300) # 设置窗口图标 self.setWindowIcon(QIcon(ICON_IMAGE)) # 用动态路径 images_panel.addWidget(self.original_image_label) images_panel.addWidget(self.detected_image_label) images_panel.setSizes([300, 300]) left_layout.addWidget(images_panel) # 操作按钮 button_layout = QHBoxLayout() # 图片/视频上传按钮 self.upload_media_button = QPushButton(\"上传图片\") self.upload_media_button.setMinimumHeight(35) self.upload_media_button.clicked.connect(self.upload_media) # 开始检测按钮 self.start_detect_button = QPushButton(\"开始检测\") self.start_detect_button.setMinimumHeight(35) self.start_detect_button.clicked.connect(self.start_detection) # 停止检测按钮(用于视频和摄像头) self.stop_detect_button = QPushButton(\"停止检测\") self.stop_detect_button.setMinimumHeight(35) self.stop_detect_button.setEnabled(False) self.stop_detect_button.clicked.connect(self.stop_detection) # 添加模型上传按钮 upload_model_button = QPushButton(\"上传模型\") upload_model_button.setMinimumHeight(35) upload_model_button.clicked.connect(self.upload_model) button_layout.addWidget(self.upload_media_button) button_layout.addWidget(self.start_detect_button) button_layout.addWidget(self.stop_detect_button) button_layout.addWidget(upload_model_button) left_layout.addLayout(button_layout) # 视频进度条容器 self.video_progress_container = QWidget() self.video_progress_layout = QHBoxLayout(self.video_progress_container) self.video_progress_label = QLabel(\"处理进度:\") self.video_progress_bar = QProgressBar() self.video_progress_bar.setValue(0) self.video_progress_layout.addWidget(self.video_progress_label) self.video_progress_layout.addWidget(self.video_progress_bar) self.video_progress_container.setVisible(False) # 默认隐藏 left_layout.addWidget(self.video_progress_container) left_panel.setLayout(left_layout) # 右侧参数调整和结果显示区域 right_panel = QWidget() right_layout = QVBoxLayout() # 参数调整 params_group = QGroupBox(\"参数调整\") params_layout = QGridLayout() conf_layout = QHBoxLayout() conf_label = QLabel(\"置信度阈值:\") self.conf_slider = QSlider(Qt.Horizontal) self.conf_slider.setRange(0, 100) self.conf_slider.setValue(25) # 默认0.25 self.conf_value_label = QLabel(\"0.25\") # 连接滑块值改变信号到更新函数 self.conf_slider.valueChanged.connect(self.update_conf_thres) conf_layout.addWidget(conf_label) conf_layout.addWidget(self.conf_slider) conf_layout.addWidget(self.conf_value_label) iou_layout = QHBoxLayout() iou_label = QLabel(\"IOU阈值:\") self.iou_slider = QSlider(Qt.Horizontal) self.iou_slider.setRange(0, 100) self.iou_slider.setValue(45) # 默认0.45 self.iou_value_label = QLabel(\"0.45\") # 连接滑块值改变信号到更新函数 self.iou_slider.valueChanged.connect(self.update_iou_thres) iou_layout.addWidget(iou_label) iou_layout.addWidget(self.iou_slider) iou_layout.addWidget(self.iou_value_label) # 视频保存选项容器 self.video_save_container = QWidget() self.video_save_layout = QHBoxLayout(self.video_save_container) self.save_result_checkbox = QCheckBox(\"保存检测结果\") self.save_result_checkbox.setChecked(True) self.output_path_input = QLineEdit(\"output.mp4\") browse_output_button = QPushButton(\"浏览...\") browse_output_button.clicked.connect(self.browse_output_path) self.video_save_layout.addWidget(self.save_result_checkbox) self.video_save_layout.addWidget(self.output_path_input) self.video_save_layout.addWidget(browse_output_button) self.video_save_container.setVisible(False) # 默认隐藏 # 摄像头参数容器 self.camera_params_container = QWidget() self.camera_params_layout = QVBoxLayout(self.camera_params_container) camera_id_layout = QHBoxLayout() camera_id_label = QLabel(\"摄像头ID:\") self.camera_id_combobox = QComboBox() # 尝试检测可用摄像头 self.detect_available_cameras() camera_id_layout.addWidget(camera_id_label) camera_id_layout.addWidget(self.camera_id_combobox) resolution_layout = QHBoxLayout() resolution_label = QLabel(\"分辨率:\") self.resolution_combobox = QComboBox() self.resolution_combobox.addItems([\"640x480\", \"1280x720\", \"1920x1080\"]) self.resolution_combobox.setCurrentIndex(1) # 默认720p resolution_layout.addWidget(resolution_label) resolution_layout.addWidget(self.resolution_combobox) self.camera_params_layout.addLayout(camera_id_layout) self.camera_params_layout.addLayout(resolution_layout) self.camera_params_container.setVisible(False) # 默认隐藏 # 添加模型状态显示 model_status_layout = QHBoxLayout() model_label = QLabel(\"当前模型:\") self.model_status_label = QLabel(\"未加载\") self.model_status_label.setStyleSheet(\"color: gray;\") model_status_layout.addWidget(model_label) model_status_layout.addWidget(self.model_status_label) # 添加各布局到参数网格 params_layout.addLayout(conf_layout, 0, 0) params_layout.addLayout(iou_layout, 1, 0) params_layout.addWidget(self.video_save_container, 2, 0) # 视频保存选项 params_layout.addWidget(self.camera_params_container, 3, 0) # 摄像头参数 params_layout.addLayout(model_status_layout, 4, 0) params_group.setLayout(params_layout) # 结果显示 results_group = QGroupBox(\"检测结果\") results_layout = QVBoxLayout() self.results_textedit = QTextEdit() self.results_textedit.setReadOnly(True) self.results_textedit.setMinimumHeight(200) results_layout.addWidget(self.results_textedit) results_group.setLayout(results_layout) right_layout.addWidget(params_group) right_layout.addWidget(results_group) right_panel.setLayout(right_layout) detection_area.addWidget(left_panel) detection_area.addWidget(right_panel) detection_area.setSizes([800, 400]) detection_layout.addWidget(detection_title) detection_layout.addWidget(detection_area) detection_widget.setLayout(detection_layout) # 添加所有选项卡到主窗口 self.addTab(data_annotation_widget, \"数据标注\") self.addTab(training_widget, \"开始训练\") self.addTab(detection_widget, \"目标检测\") # 设置选项卡样式 self.setStyleSheet(\"\"\" QTabWidget::pane { border-top: 2px solid #C2C7CB; position: absolute; top: -0.5em; } QTabWidget::tab-bar { alignment: left; } QTabBar::tab { background: qlineargradient(x1: 0, y1: 0, x2: 0, y2: 1,stop: 0 #E1E1E1, stop: 0.4 #DDDDDD,stop: 0.5 #D8D8D8, stop: 1.0 #D3D3D3); border: 2px solid #C4C4C3; border-bottom-color: #C2C7CB; border-top-left-radius: 4px; border-top-right-radius: 4px; min-width: 8ex; padding: 5px; font-size: 14px; font-family: SimHei; } QTabBar::tab:selected, QTabBar::tab:hover { background: qlineargradient(x1: 0, y1: 0, x2: 0, y2: 1,stop: 0 #fafafa, stop: 0.4 #f4f4f4,stop: 0.5 #e7e7e7, stop: 1.0 #fafafa); } QTabBar::tab:selected { border-color: #9B9B9B; border-bottom-color: #C2C7CB; } QTabBar::tab:!selected { margin-top: 2px; } \"\"\") def browse_annotation_images(self): \"\"\"浏览并选择要标注的图片文件夹\"\"\" directory = QFileDialog.getExistingDirectory(self, \"选择图片文件夹\", os.getcwd()) if directory: self.annotation_path_input.setText(directory) def browse_weights(self): \"\"\"浏览并选择预训练权重文件\"\"\" fileName, _ = QFileDialog.getOpenFileName(self, \"选择预训练权重\", os.getcwd(), \"PT Files (*.pt)\") if fileName: self.weights_input.setText(fileName) def browse_data_config(self): \"\"\"浏览并选择数据集配置文件\"\"\" fileName, _ = QFileDialog.getOpenFileName(self, \"选择数据集配置文件\", os.getcwd(), \"YAML Files (*.yaml)\") if fileName: self.data_path_input.setText(fileName) def convert_image_format(self): \"\"\"转换图片格式\"\"\" image_path = self.annotation_path_input.text() target_format = self.format_combobox.currentText().lower() if not image_path or not os.path.exists(image_path): QMessageBox.warning(self, \"警告\", \"请选择有效的图片路径\") return # 获取所有图片文件 image_extensions = [\'.jpg\', \'.jpeg\', \'.png\', \'.bmp\', \'.tif\', \'.tiff\'] image_files = [f for f in os.listdir(image_path) if os.path.isfile(os.path.join(image_path, f)) and os.path.splitext(f)[1].lower() in image_extensions] if not image_files: QMessageBox.warning(self, \"警告\", \"未找到图片文件\") return # 创建转换后的文件夹 converted_path = os.path.join(image_path, f\"converted_{target_format}\") os.makedirs(converted_path, exist_ok=True) # 转换图片格式 for i, img_file in enumerate(image_files): try: img_path = os.path.join(image_path, img_file) img = Image.open(img_path) # 生成新文件名 base_name = os.path.splitext(img_file)[0] new_file = f\"{base_name}.{target_format}\" new_path = os.path.join(converted_path, new_file) # 保存为新格式 img.save(new_path) except Exception as e: print(f\"转换失败: {img_file}, 错误: {str(e)}\") QMessageBox.information(self, \"完成\", f\"图片格式转换完成\\n转换后的图片保存在: {converted_path}\") def open_labeling_tool(self): \"\"\"打开标注软件\"\"\" try: # 尝试启动labelImg import subprocess subprocess.Popen([\'labelImg\']) except Exception as e: QMessageBox.critical(self, \"错误\", f\"无法启动labelImg: {str(e)}\\n请确保labelImg已安装\") def start_training(self): \"\"\"开始训练\"\"\" if self.is_training: QMessageBox.warning(self, \"警告\", \"已有训练任务正在进行\") return # 获取参数 weights = self.weights_input.text() epochs = self.epochs_spinbox.value() batch_size = self.batch_spinbox.value() imgsz = self.imgsz_spinbox.value() data = self.data_path_input.text() device = self.device_combobox.currentText() resume = self.resume_checkbox.isChecked() project = self.project_input.text() name = self.name_input.text() # 验证参数 if not all([weights, data]): QMessageBox.warning(self, \"警告\", \"请填写所有必要参数\") return if not os.path.exists(weights): QMessageBox.warning(self, \"警告\", \"权重文件不存在\") return if not os.path.exists(data): QMessageBox.warning(self, \"警告\", \"数据集配置文件不存在\") return # 构建 opt 对象 opt = argparse.Namespace( weights=weights, epochs=epochs, batch=batch_size, imgsz=imgsz, data=data, device=device, resume=resume, project=project, name=name ) # 启动训练 self.is_training = True self.training_thread = TrainingThread(self, [\'python\', \'train.py\'], os.getcwd(), opt) self.training_thread.log_signal.connect(self.update_training_log) self.training_thread.finished_signal.connect(self.handle_training_finished) self.training_thread.start() # 更新 UI 状态 self.update_ui_for_training(True) @Slot(str) def update_training_log(self, message): \"\"\"更新训练日志\"\"\" self.log_textedit.append(message) # 自动滚动到底部 self.log_textedit.verticalScrollBar().setValue( self.log_textedit.verticalScrollBar().maximum() ) @Slot(bool) def handle_training_finished(self, success): \"\"\"处理训练完成\"\"\" self.is_training = False self.update_ui_for_training(False) # 记录训练完成状态 timestamp = datetime.now().strftime(\"%Y-%m-%d %H:%M:%S\") if success: self.log_textedit.append(f\"\\n[系统] {timestamp} 训练成功完成\") QMessageBox.information(self, \"完成\", \"训练成功完成\") else: self.log_textedit.append(f\"\\n[系统] {timestamp} 训练过程中出现错误\") QMessageBox.warning(self, \"警告\", \"训练过程中出现错误\") def enable_stop_button(self): \"\"\"启用停止按钮(线程安全)\"\"\" self.stop_train_button.setEnabled(True) def disable_stop_button(self): \"\"\"禁用停止按钮(线程安全)\"\"\" self.stop_train_button.setEnabled(False) def update_ui_for_training(self, is_training): \"\"\"更新UI状态\"\"\" self.train_button.setEnabled(not is_training) if is_training: # 记录训练开始 timestamp = datetime.now().strftime(\"%Y-%m-%d %H:%M:%S\") self.training_started_signal.emit() self.log_textedit.clear() self.log_textedit.append(f\"[系统] {timestamp} 训练开始...\") self.log_textedit.append(f\"[参数] 权重: {self.weights_input.text()}\") self.log_textedit.append(f\"[参数] 轮次: {self.epochs_spinbox.value()}\") self.log_textedit.append(f\"[参数] 批次大小: {self.batch_spinbox.value()}\") self.log_textedit.append(f\"[参数] 图像尺寸: {self.imgsz_spinbox.value()}\") self.log_textedit.append(f\"[参数] 数据集: {self.data_path_input.text()}\") self.log_textedit.append(f\"[参数] 设备: {self.device_combobox.currentText()}\") self.log_textedit.append(f\"[参数] 项目: {self.project_input.text()}\") self.log_textedit.append(f\"[参数] 实验: {self.name_input.text()}\") else: self.training_stopped_signal.emit() def stop_training(self): \"\"\"停止训练\"\"\" if self.training_thread and self.is_training: self.log_textedit.append(\"\\n[系统] 正在停止训练...\") try: # 停止训练线程 self.training_thread.stop() self.is_training = False self.update_ui_for_training(False) self.log_textedit.append(\"[系统] 训练已成功停止\") QMessageBox.information(self, \"提示\", \"训练已停止\") except Exception as e: self.log_textedit.append(f\"[错误] 停止训练时发生异常: {str(e)}\") QMessageBox.critical(self, \"错误\", f\"停止训练时发生错误: {str(e)}\") def update_conf_thres(self, value): \"\"\"更新置信度阈值\"\"\" self.conf_thres = value / 100.0 self.conf_value_label.setText(f\"{self.conf_thres:.2f}\") def update_iou_thres(self, value): \"\"\"更新IOU阈值\"\"\" self.iou_thres = value / 100.0 self.iou_value_label.setText(f\"{self.iou_thres:.2f}\") def upload_model(self): \"\"\"上传模型文件\"\"\" fileName, _ = QFileDialog.getOpenFileName(self, \"选择模型文件\", os.getcwd(), \"PyTorch模型文件 (*.pt)\") if fileName: # 验证模型文件 if not os.path.exists(fileName): QMessageBox.warning(self, \"警告\", \"模型文件不存在\") return # 获取文件扩展名 _, ext = os.path.splitext(fileName) ext = ext.lower() # 验证模型格式 if ext != \'.pt\': QMessageBox.warning(self, \"警告\", \"本系统目前只支持PyTorch模型(.pt),请使用.pt格式的模型\") return try: # 验证模型文件大小 file_size = os.path.getsize(fileName) / (1024 * 1024) # MB if file_size < 1: QMessageBox.warning(self, \"警告\", \"模型文件过小,可能无效\") return # 尝试加载模型进行验证 model = torch.hub.load(\'ultralytics/yolov5\', \'custom\', path=fileName) model.to(self.device) model.eval() # 验证模型结构 if not hasattr(model, \'model\'): QMessageBox.warning(self, \"警告\", \"无效的PyTorch模型结构\") return # 验证通过,设置当前模型 self.model_path = fileName self.model_loaded = False # 启动异步加载模型 threading.Thread(target=self.load_model_async, daemon=True).start() # 更新UI状态 self.model_status_label.setText(f\"加载中... ({os.path.basename(fileName)})\") self.model_status_label.setStyleSheet(\"color: orange;\") except Exception as e: QMessageBox.critical(self, \"模型验证失败\", f\"无法加载模型: {str(e)}\") self.model_status_label.setText(\"加载失败\") self.model_status_label.setStyleSheet(\"color: red;\") return def __init__(self): # 初始化界面 super().__init__() self.setWindowTitle(WINDOW_TITLE) self.resize(1200, 800) self.setWindowIcon(QIcon(ICON_IMAGE)) self.output_size = 480 self.img2predict = \"\" self.video2predict = \"\" self.video_detection_thread = None self.camera_detection_thread = None # 创建临时目录 os.makedirs(os.path.join(\"data\", \"tmp\"), exist_ok=True) # 初始化训练系统 self.init_training_system() # 初始化检测参数 self.conf_thres = 0.25 self.iou_thres = 0.45 self.model = None self.model_loaded = False self.initUI() # 启动异步加载模型 threading.Thread(target=self.load_model_async, daemon=True).start() def load_model_async(self): try: self.device = torch.device(\'cuda\' if torch.cuda.is_available() else \'cpu\') # ↓↓↓ 新增动态路径获取逻辑 ↓↓↓ # 获取当前程序运行的实际路径(关键!) if getattr(sys, \'frozen\', False): # 打包后的环境 base_path = sys._MEIPASS else: # 开发环境 base_path = os.path.dirname(os.path.abspath(__file__)) # 优先用上传的模型路径,没有则用默认 self.model_path = getattr(self, \'model_path\', os.path.join(base_path, \"yolov5n.pt\")) # 验证模型文件是否存在 if not os.path.exists(self.model_path): self.model_status_label.setText(\"模型文件不存在\") self.model_status_label.setStyleSheet(\"color: red;\") return # 加载PyTorch模型 self.model = torch.hub.load(\'ultralytics/yolov5\', \'custom\', path=self.model_path) self.model.to(self.device) self.model.eval() # 模型加载成功 self.model_loaded = True self.model_status_label.setText(f\"已加载: {os.path.basename(self.model_path)}\") self.model_status_label.setStyleSheet(\"color: green;\") except Exception as e: print(f\"模型加载失败: {str(e)}\") self.model_status_label.setText( f\"加载失败: {os.path.basename(self.model_path) if hasattr(self, \'model_path\') else \'无\'}\") self.model_status_label.setStyleSheet(\"color: red;\") def upload_media(self): \"\"\"上传图像或视频\"\"\" if self.image_mode_radio.isChecked(): # 图片模式 fileName, _ = QFileDialog.getOpenFileName(self, \"选择图像\", os.getcwd(), \"图像文件 (*.jpg *.jpeg *.png *.bmp)\") if fileName: # 保存图像路径 self.img2predict = fileName self.video2predict = \"\" # 显示原始图像 pixmap = QPixmap(fileName) if not pixmap.isNull(): scaled_pixmap = pixmap.scaled(self.original_image_label.size(), Qt.KeepAspectRatio, Qt.SmoothTransformation) self.original_image_label.setPixmap(scaled_pixmap) self.detected_image_label.setPixmap(QPixmap(IMAGE_RIGHT_INIT)) self.results_textedit.clear() elif self.video_mode_radio.isChecked(): # 视频模式 fileName, _ = QFileDialog.getOpenFileName(self, \"选择视频\", os.getcwd(), \"视频文件 (*.mp4 *.avi *.mov *.mkv)\") if fileName: # 保存视频路径 self.video2predict = fileName self.img2predict = \"\" # 显示视频第一帧作为预览 cap = cv2.VideoCapture(fileName) ret, frame = cap.read() if ret: frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) h, w, c = frame.shape qimg = QImage(frame_rgb.data, w, h, w * c, QImage.Format_RGB888) pixmap = QPixmap.fromImage(qimg) scaled_pixmap = pixmap.scaled(self.original_image_label.size(), Qt.KeepAspectRatio, Qt.SmoothTransformation) self.original_image_label.setPixmap(scaled_pixmap) self.detected_image_label.setPixmap(QPixmap(IMAGE_RIGHT_INIT)) self.results_textedit.clear() cap.release() def start_detection(self): \"\"\"开始检测(根据当前模式)\"\"\" if self.model is None or not self.model_loaded: QMessageBox.warning(self, \"警告\", \"模型未加载,请先加载模型\") return if self.image_mode_radio.isChecked(): # 图片检测 self.start_image_detection() elif self.video_mode_radio.isChecked(): # 视频检测 self.start_video_detection() elif self.camera_mode_radio.isChecked(): # 摄像头检测 self.start_camera_detection() def start_image_detection(self): \"\"\"开始图片检测\"\"\" if not self.img2predict or not os.path.exists(self.img2predict): QMessageBox.warning(self, \"警告\", \"请先上传图像\") return # 显示处理中 self.results_textedit.setText(\"正在检测...\") # 在单独的线程中执行检测 self.detection_thread = threading.Thread( target=self.run_detection ) self.detection_thread.daemon = True self.detection_thread.start() def start_video_detection(self): \"\"\"开始视频检测\"\"\" if not self.video2predict or not os.path.exists(self.video2predict): QMessageBox.warning(self, \"警告\", \"请先上传视频\") return # 获取保存路径 output_path = self.output_path_input.text() if self.save_result_checkbox.isChecked() else None # 显示处理中 self.results_textedit.setText(\"正在准备视频检测...\") self.video_progress_bar.setValue(0) # 禁用相关按钮 self.start_detect_button.setEnabled(False) self.upload_media_button.setEnabled(False) self.stop_detect_button.setEnabled(True) # 创建并启动视频检测线程 self.video_detection_thread = VideoDetectionThread( self.model, self.video2predict, output_path, self.conf_thres, self.iou_thres, self.save_result_checkbox.isChecked() ) # 连接信号 self.video_detection_thread.progress_updated.connect(self.update_video_progress) self.video_detection_thread.frame_processed.connect(self.update_video_frame) self.video_detection_thread.finished.connect(self.video_detection_finished) self.video_detection_thread.error_occurred.connect(self.show_detection_error) self.video_detection_thread.start() def start_camera_detection(self): \"\"\"开始摄像头检测\"\"\" # 获取摄像头ID try: camera_id = int(self.camera_id_combobox.currentText()) except ValueError: QMessageBox.warning(self, \"警告\", \"请选择有效的摄像头ID\") return # 获取分辨率 resolution_str = self.resolution_combobox.currentText() width, height = map(int, resolution_str.split(\'x\')) # 显示处理中 self.results_textedit.setText(\"正在启动摄像头检测...\") # 禁用相关按钮 self.start_detect_button.setEnabled(False) self.upload_media_button.setEnabled(False) self.stop_detect_button.setEnabled(True) self.camera_id_combobox.setEnabled(False) self.resolution_combobox.setEnabled(False) # 创建并启动摄像头检测线程 self.camera_detection_thread = CameraDetectionThread( self.model, camera_id, self.conf_thres, self.iou_thres, (width, height) ) # 连接信号 self.camera_detection_thread.frame_processed.connect(self.update_camera_frame) self.camera_detection_thread.error_occurred.connect(self.show_detection_error) self.camera_detection_thread.start() def stop_detection(self): \"\"\"停止检测(视频或摄像头)\"\"\" if self.video_detection_thread and self.video_detection_thread.isRunning(): self.video_detection_thread._is_running = False self.video_detection_thread.wait() self.video_detection_finished() elif self.camera_detection_thread and self.camera_detection_thread.isRunning(): self.camera_detection_thread.stop() self.camera_detection_finished() def run_detection(self): \"\"\"执行图像检测\"\"\" try: # 读取图像 img = cv2.imread(self.img2predict) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 设置置信度和IOU阈值 self.model.conf = self.conf_thres # 置信度阈值 self.model.iou = self.iou_thres # IOU阈值 # 执行检测 results = self.model(img, size=640) detected_img = results.render()[0] # 提取检测结果信息 result_info = [] for box in results.xyxy[0]: class_id = int(box[5]) conf = float(box[4]) label = self.model.names[class_id] x1, y1, x2, y2 = map(int, box[:4]) result_info.append(f\"- {label}: 置信度 {conf:.2f}, 位置: ({x1}, {y1}), ({x2}, {y2})\") # 保存检测结果 result_path = os.path.join(\"data/tmp\", \"detection_result.jpg\") detected_img = cv2.cvtColor(detected_img, cv2.COLOR_RGB2BGR) cv2.imwrite(result_path, detected_img) # 显示检测结果 QMetaObject.invokeMethod(self, \"show_detection_result\", Qt.QueuedConnection, Q_ARG(str, result_path), Q_ARG(str, \"\\n\".join(result_info) if result_info else \"未检测到目标\")) except Exception as e: QMetaObject.invokeMethod(self, \"show_detection_error\", Qt.QueuedConnection, Q_ARG(str, str(e))) @Slot(str, str) def show_detection_result(self, result_path, result_info): \"\"\"显示检测结果\"\"\" # 显示检测后的图像 pixmap = QPixmap(result_path) scaled_pixmap = pixmap.scaled(self.detected_image_label.size(), Qt.KeepAspectRatio, Qt.SmoothTransformation) self.detected_image_label.setPixmap(scaled_pixmap) # 显示检测结果信息 self.results_textedit.setText(result_info) @Slot(str) def show_detection_error(self, error_message): \"\"\"显示检测错误\"\"\" self.results_textedit.setText(f\"检测出错: {error_message}\") QMessageBox.critical(self, \"检测错误\", f\"检测过程中出错: {error_message}\") # 恢复UI状态 self.start_detect_button.setEnabled(True) self.upload_media_button.setEnabled(True) self.stop_detect_button.setEnabled(False) self.camera_id_combobox.setEnabled(True) self.resolution_combobox.setEnabled(True) @Slot(int) def update_video_progress(self, progress): \"\"\"更新视频处理进度\"\"\" self.video_progress_bar.setValue(progress) self.results_textedit.setText(f\"视频处理中... {progress}%\") @Slot(str) def update_video_frame(self, frame_path): \"\"\"更新视频帧显示\"\"\" pixmap = QPixmap(frame_path) scaled_pixmap = pixmap.scaled(self.detected_image_label.size(), Qt.KeepAspectRatio, Qt.SmoothTransformation) self.detected_image_label.setPixmap(scaled_pixmap) @Slot(str) def update_camera_frame(self, frame_path): \"\"\"更新摄像头帧显示\"\"\" pixmap = QPixmap(frame_path) scaled_pixmap = pixmap.scaled(self.detected_image_label.size(), Qt.KeepAspectRatio, Qt.SmoothTransformation) self.detected_image_label.setPixmap(scaled_pixmap) def video_detection_finished(self): \"\"\"视频检测完成处理\"\"\" self.results_textedit.setText(\"视频检测完成!\") self.video_progress_bar.setValue(100) # 恢复UI状态 self.start_detect_button.setEnabled(True) self.upload_media_button.setEnabled(True) self.stop_detect_button.setEnabled(False) if self.save_result_checkbox.isChecked() and self.output_path_input.text(): QMessageBox.information(self, \"完成\", f\"视频检测已完成,结果已保存至:\\n{self.output_path_input.text()}\") def camera_detection_finished(self): \"\"\"摄像头检测完成处理\"\"\" self.results_textedit.setText(\"摄像头检测已停止\") # 恢复UI状态 self.start_detect_button.setEnabled(True) self.upload_media_button.setEnabled(True) self.stop_detect_button.setEnabled(False) self.camera_id_combobox.setEnabled(True) self.resolution_combobox.setEnabled(True) def switch_detection_mode(self): \"\"\"切换检测模式\"\"\" # 停止当前可能正在进行的检测 self.stop_detection() if self.image_mode_radio.isChecked(): # 图片模式 self.upload_media_button.setText(\"上传图片\") self.video_save_container.setVisible(False) self.camera_params_container.setVisible(False) self.video_progress_container.setVisible(False) self.start_detect_button.setText(\"开始检测\") elif self.video_mode_radio.isChecked(): # 视频模式 self.upload_media_button.setText(\"上传视频\") self.video_save_container.setVisible(True) self.camera_params_container.setVisible(False) self.video_progress_container.setVisible(True) self.start_detect_button.setText(\"开始视频检测\") elif self.camera_mode_radio.isChecked(): # 摄像头模式 self.upload_media_button.setText(\"选择摄像头\") self.video_save_container.setVisible(False) self.camera_params_container.setVisible(True) self.video_progress_container.setVisible(False) self.start_detect_button.setText(\"开始摄像头检测\") # 刷新摄像头列表 self.detect_available_cameras() def browse_output_path(self): \"\"\"浏览视频输出路径\"\"\" fileName, _ = QFileDialog.getSaveFileName(self, \"保存视频结果\", os.getcwd(), \"MP4文件 (*.mp4);;AVI文件 (*.avi)\") if fileName: self.output_path_input.setText(fileName) def detect_available_cameras(self): \"\"\"检测可用摄像头\"\"\" self.camera_id_combobox.clear() # 尝试检测前5个摄像头ID,通常足够 for i in range(5): cap = cv2.VideoCapture(i) if cap.isOpened(): self.camera_id_combobox.addItem(str(i)) cap.release() # 如果没有检测到摄像头,添加默认ID 0 if self.camera_id_combobox.count() == 0: self.camera_id_combobox.addItem(\"0\")if __name__ == \"__main__\": app = QApplication(sys.argv) mainWindow = MainWindow() mainWindow.show() sys.exit(app.exec())

