一文吃透!Java与Elasticsearch的梦幻联动_java elasticsearch
一文吃透!Java与Elasticsearch的梦幻联动
一、从 “找东西” 说起:Elasticsearch 是什么

想象一下,你置身于一个巨大无比的图书馆,里面堆满了各种各样的书籍、文档和资料。这时候,你想要找到一本关于 Java 编程的书籍,你会怎么做呢?如果没有一个好的索引和检索系统,你可能需要一本一本地去翻找,这得找到猴年马月去。但要是有一套强大的搜索系统,你只需要输入 “Java 编程” 几个字,就能快速定位到你想要的那本书,是不是方便多啦?
在大数据的世界里,Elasticsearch 就扮演着这样一个超级强大的 “图书馆搜索系统” 角色。它是一个基于 Lucene 的分布式、RESTful 风格的搜索和分析引擎,能对海量数据进行快速检索和分析。它就像一把瑞士军刀,在各种需要搜索和数据分析的场景中都能大显身手,从电商网站的商品搜索,到日志文件的分析,再到企业内部的文档检索,都离不开它。
Elasticsearch 的特点
-
分布式:Elasticsearch 天生就是为分布式环境设计的。它可以把数据分布在多个节点上,就像把图书馆的书籍分散存放在不同的书架区域。这样一来,不仅提高了数据的存储容量,还能让搜索和分析的速度更快,因为多个节点可以同时工作,分担任务。而且,当某个节点出现故障时,其他节点可以继续提供服务,保证系统的高可用性。就好比图书馆里某个书架坏了,不影响你从其他书架找到想要的书。
-
实时性:在 Elasticsearch 里,数据一旦被索引,几乎可以立刻被搜索到。这对于那些需要实时反馈的应用场景来说非常重要,比如实时监控系统,一旦有异常情况发生,能马上通过 Elasticsearch 搜索到相关信息并发出警报。
-
强大的搜索功能:它支持全文搜索、结构化搜索以及各种复杂的查询语句。你可以进行模糊搜索,就像在图书馆里只记得书名大概有个 “Java” 字眼,也能找到相关书籍;也可以进行精确匹配搜索,指定搜索某本特定的书。还能进行组合条件搜索,比如搜索 “2020 年以后出版的 Java 编程书籍”。
-
可扩展性:随着数据量的增长,你可以很方便地向 Elasticsearch 集群中添加更多的节点,就像给图书馆增加更多的书架区域一样,轻松实现水平扩展,应对不断增长的业务需求。
Elasticsearch 在 Java 开发中的地位
在 Java 开发的世界里,Elasticsearch 可是相当受欢迎的。很多大型互联网公司都在使用它来解决搜索和数据分析的问题。它和 Java 的结合非常紧密,因为它本身就是用 Java 编写的,这使得 Java 开发者在使用它的时候更加得心应手。通过 Java 的客户端,我们可以方便地与 Elasticsearch 进行交互,实现数据的索引、搜索和管理等操作。
为了让大家更好地理解 Elasticsearch 的整体架构,下面我们来看一张图:
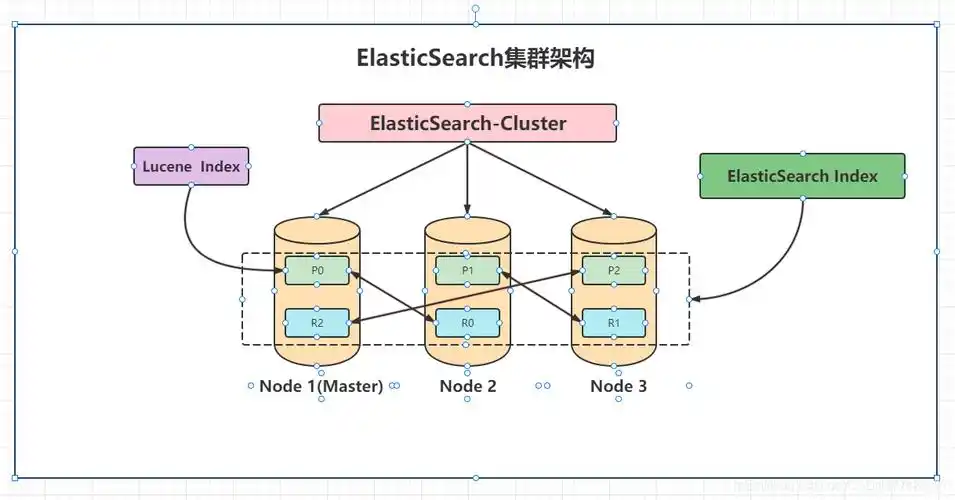
从图中可以看到,Elasticsearch 集群由多个节点组成,每个节点都可以存储数据和执行搜索任务。索引是一组相关文档的集合,就像图书馆里的一个书架类别,比如 “计算机类” 书架。文档则是具体的数据单元,就像书架上的每一本书。分片是将索引进一步划分成更小的部分,分布在不同节点上,提高搜索效率。副本则是分片的备份,用于保证数据的高可用性和容错性。当主分片所在节点出现故障时,副本分片可以顶上,继续提供服务。
二、Java 与 Elasticsearch 的初见:环境搭建与连接
2.1 安装 Elasticsearch
在正式开启 Elasticsearch 的探索之旅前,我们得先把它安装到我们的系统里。就好比你要开一家图书馆,得先把书架、桌椅这些基础设施准备好。Elasticsearch 的安装步骤因操作系统而异,下面我就来详细说说在 Windows、Linux 和 Mac 系统下的安装方法。
Windows 系统:
-
前往 Elasticsearch 的官方下载地址,在下载页面中,找到适合 Windows 系统的安装包,一般是一个 ZIP 文件。
-
下载完成后,解压这个 ZIP 文件到你想要安装的目录,比如
C:\\elasticsearch。解压完成后,你会看到一系列的文件夹和文件,其中bin目录下存放着可执行文件,config目录下是配置文件,这些文件就像是图书馆的管理规则和操作指南。 -
进入
bin目录,双击elasticsearch.bat文件启动 Elasticsearch。在启动过程中,你可能会看到一些命令行输出,这是 Elasticsearch 在初始化各种组件,就像图书馆工作人员在开馆前进行的准备工作一样。 -
启动成功后,打开浏览器,访问
http://localhost:9200,如果看到类似下面的 JSON 数据,那就说明 Elasticsearch 已经成功安装并启动啦!
{ \"name\" : \"your_computer_name\", \"cluster_name\" : \"elasticsearch\", \"cluster_uuid\" : \"xxxxxxxxxxxxxxxxxxxxxxxxxxxx\", \"version\" : { \"number\" : \"7.10.2\", \"build_flavor\" : \"default\", \"build_type\" : \"zip\", \"build_hash\" : \"xxxxxxxxxxxxxxxxxxxxxxxxxxxx\", \"build_date\" : \"2020-12-09T21:36:44.016220Z\", \"build_snapshot\" : false, \"lucene_version\" : \"8.7.0\", \"minimum_wire_compatibility_version\" : \"6.8.0\", \"minimum_index_compatibility_version\" : \"6.0.0-beta1\" }, \"tagline\" : \"You Know, for Search\"}注意事项:
-
Elasticsearch 依赖 Java 环境,所以在安装 Elasticsearch 之前,请确保你的系统已经安装了 Java,并且版本符合要求。一般来说,建议使用 Java 11 及以上版本。
-
如果在启动过程中遇到端口冲突的问题,比如提示
9200端口被占用,可以修改config/elasticsearch.yml文件中的http.port配置项,将其改为其他未被占用的端口。这就好比图书馆的大门被堵住了,我们换个门进出一样。
Linux 系统:
-
同样在官方下载地址下载适用于 Linux 的安装包,通常是一个
.tar.gz文件。 -
使用命令解压安装包,比如:
tar -zxvf elasticsearch-7.10.2-linux-x86_64.tar.gz解压后,你可以将文件夹移动到你希望的安装目录,比如/usr/local/elasticsearch 。
3. 进入解压后的config目录,编辑elasticsearch.yml文件,根据你的需求进行配置,比如设置集群名称、节点名称、网络绑定地址等。例如:
cluster.name: my-elasticsearch-clusternode.name: node-1network.host: 0.0.0.0http.port: 9200这里设置集群名称为my-elasticsearch-cluster ,节点名称为node-1 ,绑定所有网络地址,使用默认的9200端口。
4. 由于 Elasticsearch 不建议使用 root 用户启动,所以我们需要创建一个新的用户来运行它。使用以下命令创建用户并赋予权限:
sudo adduser elasticsearchsudo chown -R elasticsearch:elasticsearch /usr/local/elasticsearch- 切换到新创建的用户,启动 Elasticsearch:
sudo su - elasticsearchcd /usr/local/elasticsearch/bin./elasticsearch -d这里的-d参数表示以后台守护进程的方式运行 Elasticsearch,就像让图书馆在后台默默运行,不占用你的终端窗口。
6. 用浏览器访问http://your_server_ip:9200 (将your_server_ip替换为你的服务器 IP 地址),验证是否安装成功。
注意事项:
- 在 Linux 系统中,Elasticsearch 对文件描述符和内存等系统资源有一定要求。在启动之前,需要确保系统配置满足要求。可以通过修改
/etc/security/limits.conf文件,增加如下配置:
elasticsearch soft nofile 65536elasticsearch hard nofile 65536这是设置elasticsearch用户的文件描述符限制,防止因为文件描述符不足导致启动失败。
- 另外,还需要修改
/etc/sysctl.conf文件,增加vm.max_map_count=655360配置,并执行sudo sysctl -p使配置生效。这是因为 Elasticsearch 使用了大量的内存映射文件,需要足够的vm.max_map_count值来支持。
Mac 系统:
-
从官方下载地址下载 Mac 版本的安装包,同样是
.tar.gz文件。 -
解压安装包:
tar -zxvf elasticsearch-7.10.2-darwin-x86_64.tar.gz-
进入解压后的目录,编辑
config/elasticsearch.yml文件进行配置,和 Linux 系统类似,设置集群名称、节点名称等参数。 -
启动 Elasticsearch:
cd elasticsearch-7.10.2/bin./elasticsearch如果想以后台方式运行,可以使用./elasticsearch -d 。
5. 打开浏览器,访问http://localhost:9200 ,检查安装是否成功。
注意事项:
-
确保系统安装了 Java 环境,并且版本符合要求。
-
Mac 系统的安全性设置可能会阻止 Elasticsearch 的某些操作。如果遇到权限问题,可以在系统的安全性与隐私设置中,允许 Elasticsearch 的相关操作。这就好比图书馆的安保系统限制了某些人的进入,我们需要在安保设置中给 Elasticsearch 放行。
2.2 Java 项目引入 Elasticsearch 依赖
安装好 Elasticsearch 后,就该让我们的 Java 项目和它建立联系了。在 Java 项目中,我们通过引入 Elasticsearch 的客户端依赖来实现与 Elasticsearch 集群的交互。这里我们以 Maven 项目为例,来看看如何添加依赖。
打开项目的pom.xml文件,在标签内添加如下依赖:
<dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.10.2</version></dependency>这里引入的elasticsearch-rest-high-level-client是 Elasticsearch 官方提供的高级 REST 客户端,它基于 HTTP 协议与 Elasticsearch 集群进行通信,提供了丰富的 API 来执行各种操作,比如索引数据、搜索数据、管理索引等。就像我们去图书馆借书,这个客户端就像是图书馆的借书卡,凭借它我们可以进行各种与书相关的操作。
依赖版本选择的考量:
在选择依赖版本时,要特别注意与你安装的 Elasticsearch 服务端版本保持一致。不同版本的 Elasticsearch 可能在 API、功能和性能等方面存在差异,如果客户端和服务端版本不匹配,可能会导致一些奇怪的问题,比如连接失败、请求执行错误等。就好比你拿着一张旧的图书馆借书卡,可能无法使用图书馆新的借阅系统。
不同版本客户端的特性差异:
随着 Elasticsearch 的不断发展,客户端也在持续更新,每个版本都可能带来一些新特性和改进。例如,在较新的版本中,可能会优化搜索性能,提高连接的稳定性,或者增加对新的 Elasticsearch 功能的支持。以elasticsearch-rest-high-level-client为例,从早期版本到现在,它在请求处理、响应解析等方面都有了很大的改进,使得开发者在使用时更加方便和高效。所以,在选择版本时,可以查看官方文档,了解各个版本的特性,根据项目的实际需求来决定使用哪个版本。这就像选择图书馆的服务套餐,不同的套餐有不同的服务内容,我们要根据自己的需求来选择合适的套餐。
2.3 Java 连接 Elasticsearch 集群
有了依赖之后,我们就可以在 Java 代码中连接 Elasticsearch 集群了。下面是使用elasticsearch-rest-high-level-client创建连接的代码示例:
import org.apache.http.HttpHost;import org.elasticsearch.client.RestClient;import org.elasticsearch.client.RestHighLevelClient;public class ElasticsearchConnection { public static void main(String[] args) { // 创建RestHighLevelClient实例 RestHighLevelClient client = new RestHighLevelClient( RestClient.builder( new HttpHost(\"localhost\", 9200, \"http\"))); // 使用client进行各种操作,比如索引数据、搜索数据等 // 操作完成后关闭client try { client.close(); } catch (Exception e) { e.printStackTrace(); } }}在这段代码中:
-
RestHighLevelClient是 Elasticsearch 高级 REST 客户端的核心类,通过它我们可以执行各种 Elasticsearch 操作。 -
RestClient.builder用于构建RestClient实例,RestClient是底层的 HTTP 客户端,负责与 Elasticsearch 集群建立 HTTP 连接。 -
new HttpHost(\"``localhost``\", 9200, \"http\")指定了 Elasticsearch 集群的地址和端口,这里假设 Elasticsearch 运行在本地,端口为9200,协议为http。如果你的 Elasticsearch 集群部署在远程服务器,或者使用了不同的端口和协议,需要相应地修改这里的参数。这就好比你要去图书馆,得知道图书馆的具体地址和开门时间。
参数的配置含义:
-
HttpHost的第一个参数是 Elasticsearch 集群的主机地址,可以是 IP 地址或者域名。 -
第二个参数是端口号,Elasticsearch 默认的 HTTP 端口是
9200,如果你在安装时修改了端口,这里也要相应修改。 -
第三个参数是协议,通常使用
http,如果你的 Elasticsearch 配置了 HTTPS,这里要改为https。
连接失败时常见的排查方法:
-
检查网络连接:确保你的 Java 应用程序所在的服务器能够访问 Elasticsearch 集群的地址和端口。可以使用
ping命令检查主机是否可达,使用telnet命令检查端口是否开放。例如,telnet ``localhost`` 9200,如果连接成功,说明端口是开放的;如果连接失败,可能是网络问题或者 Elasticsearch 服务没有正常启动。这就像你去图书馆,发现图书馆的大门打不开,得先检查一下是不是路走错了或者图书馆还没开门。 -
检查 Elasticsearch 服务状态:确保 Elasticsearch 服务已经正常启动,并且没有报错。可以查看 Elasticsearch 的日志文件,通常位于
logs目录下,检查是否有异常信息。如果服务没有正常启动,需要根据日志中的错误信息进行排查和修复。 -
检查客户端配置:检查代码中的连接配置是否正确,比如主机地址、端口号、协议等参数是否与 Elasticsearch 集群的实际配置一致。同时,也要确保引入的客户端依赖版本与 Elasticsearch 服务端版本兼容。这就像你拿着图书馆的地图,要确保地图上的路线和图书馆的实际布局是一致的。
-
检查防火墙设置:如果 Java 应用程序和 Elasticsearch 集群之间存在防火墙,需要确保防火墙允许相关的网络流量通过。可以检查防火墙的规则,开放
9200端口(如果使用的是默认端口),或者根据实际情况开放其他端口。这就好比图书馆设置了门禁系统,我们得确保门禁系统允许我们进入。
三、深入 Elasticsearch 核心原理
3.1 倒排索引:快速检索的秘密武器
在 Elasticsearch 的神奇世界里,倒排索引可是当之无愧的 “秘密武器”,它就像图书馆里超级智能的书籍索引系统,能让我们以超快的速度找到想要的信息。那倒排索引到底是什么呢?别着急,听我慢慢道来。
想象一下,你有一堆文档,每个文档都包含很多内容。正向索引就像是我们常见的按文档顺序排列的目录,要查找某个关键词,得一个文档一个文档地去翻,效率那叫一个低。而倒排索引就完全不一样啦,它是把文档中的关键词和文档的对应关系给反过来记录。比如说,有三个文档:
-
文档 1:“Elasticsearch 是一个强大的搜索工具”
-
文档 2:“我喜欢使用 Elasticsearch 进行数据搜索”
-
文档 3:“搜索功能在很多应用中都非常重要”
对于正向索引,它记录的是每个文档包含哪些内容,就像这样:
-
文档 1:[“Elasticsearch”,“是”,“一个”,“强大的”,“搜索”,“工具”]
-
文档 2:[“我”,“喜欢”,“使用”,“Elasticsearch”,“进行”,“数据”,“搜索”]
-
文档 3:[“搜索”,“功能”,“在”,“很多”,“应用”,“中”,“都”,“非常”,“重要”]
如果我们要搜索 “搜索” 这个关键词,正向索引就得逐个检查每个文档,看看里面有没有 “搜索”,这得多费时间呀。
再看看倒排索引,它记录的是每个关键词出现在哪些文档里,就像下面这样:
-
“Elasticsearch”:[1, 2]
-
“搜索”:[1, 2, 3]
-
“工具”:[1]
-
“我”:[2]
-
“喜欢”:[2]
-
“使用”:[2]
-
“进行”:[2]
-
“数据”:[2]
-
“功能”:[3]
-
“在”:[3]
-
“很多”:[3]
-
“应用”:[3]
-
“中”:[3]
-
“都”:[3]
-
“非常”:[3]
-
“重要”:[3]
这样一来,当我们搜索 “搜索” 时,倒排索引能直接告诉我们它出现在文档 1、2、3 中,一下子就定位到了,是不是超级快!
倒排索引的构建过程:
-
文档分词:Elasticsearch 会把每个文档的内容进行拆分,变成一个个单独的词语,这些词语就叫做词条(Term)。比如上面文档 1 中的 “Elasticsearch 是一个强大的搜索工具”,就会被拆分成 “Elasticsearch”、“是”、“一个”、“强大的”、“搜索”、“工具” 这些词条。这一步就像是把一本本书里的内容拆成一个个小零件,方便后续处理。
-
去除停用词和标准化处理:像 “是”、“一个”、“在”、“中” 这些没有太多实际意义的词,我们叫它们停用词,Elasticsearch 会把它们去掉。同时,还会对词条进行标准化,比如把大写字母转成小写,把复数形式变成单数等。比如 “Search” 和 “search” 就会被统一成 “search”,“dogs” 会被变成 “dog”。这一步就像是把零件上一些无关紧要的小装饰去掉,把零件打磨得更规整,方便后续组装。
-
构建倒排列表:把每个词条和它出现的文档 ID 关联起来,形成一个列表,这个列表就叫做倒排列表。比如 “Elasticsearch” 这个词条,它出现在文档 1 和文档 2 中,那么它的倒排列表就是 [1, 2] 。这一步就像是给每个小零件贴上标签,标明它们来自哪些文档。
为了让大家更清楚地理解倒排索引的构建流程,下面给大家放一张倒排索引构建流程图:
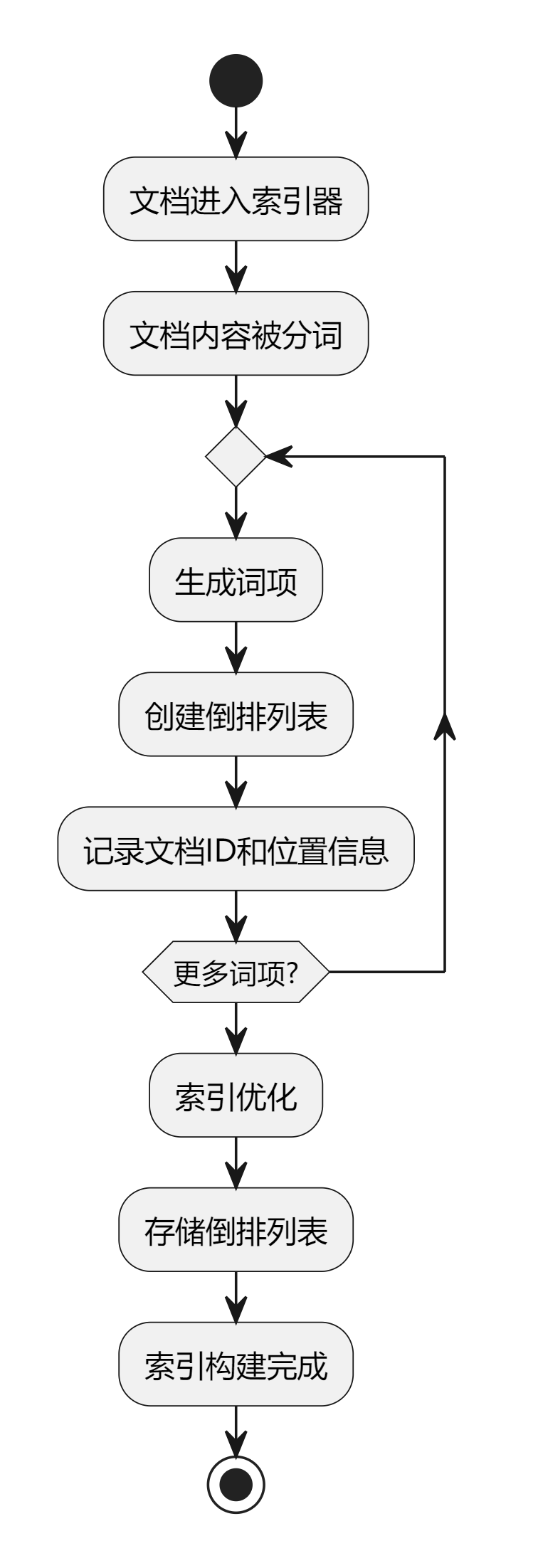
从图中可以清晰地看到,文档经过分词、去除停用词和标准化处理后,生成了词条,然后这些词条和文档 ID 一起构建成了倒排列表,最终形成了倒排索引。
正向索引与倒排索引在搜索场景中的优劣对比:
-
正向索引的优势:在根据文档 ID 精确查找某个文档时,速度非常快,就像在图书馆里根据书架编号和层数快速找到某本书一样。因为它是按照文档顺序排列的,直接定位就可以了。而且它可以给多个字段创建索引,比如在数据库表中,我们可以给 “姓名”、“年龄”、“地址” 等多个字段都创建索引。
-
正向索引的劣势:但要是遇到根据关键词进行模糊搜索的情况,正向索引就力不从心了。因为它得遍历每个文档,检查文档里是否包含关键词,效率极低。就好比在一个超大的图书馆里,不通过索引,直接在所有书架上找一本只知道部分关键词的书,那得费多大劲啊。
-
倒排索引的优势:倒排索引在关键词搜索和模糊搜索方面表现得非常出色。因为它是基于关键词来组织的,能快速定位到包含关键词的文档。比如我们在 Elasticsearch 中搜索 “大数据分析”,它能迅速从倒排索引中找到所有包含这几个关键词的文档,速度快得飞起。而且它还支持复杂查询,比如短语搜索(“大数据分析” 必须作为一个整体短语出现)、邻近查询(两个关键词在一定距离内出现)等。
-
倒排索引的劣势:倒排索引只能给词条创建索引,而不是像正向索引那样可以给字段创建索引。而且它在根据字段进行排序时不太方便,因为它主要关注的是关键词和文档的关系,而不是字段的顺序。
3.2 分布式架构:多节点协作的魔法
Elasticsearch 之所以能处理海量数据,还能保持高效稳定,分布式架构可是立下了汗马功劳。它就像一个超级大工厂,里面有很多工人(节点),大家分工合作,共同完成生产任务(数据处理)。
Elasticsearch 集群的组成部分:
-
主节点(Master Node):主节点就像是工厂的厂长,负责管理整个集群的 “大事”。比如创建或删除索引,就像是决定新建一个产品线或者淘汰一个旧产品线;管理节点的加入和离开,就像是招聘新员工或者辞退员工;分配分片,就像是把生产任务分配到不同的车间。一个集群中可以有多个候选主节点,但同一时间只有一个主节点在工作。为了保证选举的可靠性,通常建议集群中的主节点候选节点数量为奇数个,这样在出现网络分区等情况时,能更好地达成共识。比如有 3 个候选主节点,即使有一个节点因为网络问题和其他节点失联了,剩下的两个节点还能达成一致,选出新的主节点。
-
数据节点(Data Node):数据节点是真正干活的 “工人”,它们负责存储数据和执行与数据相关的操作,比如索引数据(把数据存到索引里)、搜索数据(从索引里查找数据)、聚合数据(对数据进行统计分析,比如计算平均值、求和等)。数据节点就像工厂里的生产车间,里面堆满了各种原材料(数据),工人们在这里对原材料进行加工处理。数据节点的数量可以根据数据量和查询需求来调整,如果数据量很大,查询也很频繁,就可以多增加一些数据节点,提高处理能力。
-
协调节点(Coordinating Node):协调节点可以看作是工厂的调度员,它的主要工作是接收客户端的请求,然后把请求分发到合适的数据节点去处理,等数据节点处理完后,再把结果聚合起来返回给客户端。比如客户端发送一个搜索请求,协调节点会根据请求的内容,把它拆分成多个小请求,分别发送到不同的数据节点上,每个数据节点处理自己负责的那部分数据,最后协调节点把这些数据节点返回的结果汇总起来,返回给客户端。在默认情况下,Elasticsearch 中的每个节点都可以充当协调节点,但在大规模集群中,为了提高性能,通常会专门配置一些节点作为协调节点。
-
客户端节点(Client Node):客户端节点主要是作为集群的接入点,它可以接收客户端的请求,然后把请求转发到其他节点上。它不存储数据,也不参与主节点选举,主要作用就是减轻其他节点的负载,就像工厂的门卫,负责把外来的业务请求传递给工厂内部的各个部门。
数据在集群中的分片和复制:
当我们往 Elasticsearch 集群中存储数据时,数据会被分成多个小块,这些小块就叫做分片(Shard)。每个分片都是一个独立的 Lucene 索引,它们可以分布在集群中的不同节点上。比如我们有一个很大的电商商品索引,里面包含了几百万个商品信息,为了提高存储和搜索效率,我们可以把这个索引分成 10 个分片,然后把这 10 个分片分别存储在不同的节点上。这样,在进行搜索时,多个节点可以同时工作,并行处理搜索请求,大大提高了搜索速度。这就好比把一个大工程分成多个小项目,分给不同的团队同时进行,能加快工程进度。
为了保证数据的可靠性和高可用性,Elasticsearch 还会为每个主分片创建一个或多个副本分片(Replica Shard)。副本分片和主分片的数据是一样的,它们会被存储在不同的节点上。当主分片所在的节点出现故障时,副本分片可以马上接替主分片的工作,保证数据的可用性。而且副本分片还可以提高搜索性能,因为搜索请求可以在主分片和副本分片上并行执行。比如我们有一个主分片和两个副本分片,搜索请求来了之后,三个分片可以同时进行搜索,然后把结果汇总起来,这样搜索速度就更快了。这就像我们准备了多份相同的资料,放在不同的地方,当一处资料找不到或者损坏时,其他地方的资料还能派上用场,而且在查找资料时,多个地方同时找,效率也更高。
分布式架构对系统扩展性和容错性的影响:
-
扩展性:Elasticsearch 的分布式架构使得系统具有很强的扩展性。当数据量不断增加,或者查询请求越来越多时,我们只需要往集群中添加更多的节点就可以了。新添加的节点会自动参与到集群的工作中,分担数据存储和处理的压力。就像工厂订单增多了,我们多招一些工人,增加一些生产设备,就能提高生产能力,满足订单需求。而且 Elasticsearch 会自动重新分配分片,让数据均匀地分布在新的节点上,保证系统的性能和稳定性。
-
容错性:由于数据在多个节点上进行了分片和复制,所以 Elasticsearch 集群具有很高的容错性。即使某个节点出现故障,其他节点上的数据副本还能继续提供服务,不会影响整个系统的正常运行。比如工厂里某个车间突然停电了,但其他车间还能正常生产,整个工厂的生产任务不会中断。而且 Elasticsearch 会自动检测到故障节点,并把故障节点上的分片重新分配到其他健康的节点上,保证数据的完整性和可用性。这就像我们有多个备份方案,当一个方案出现问题时,其他方案能马上启动,确保事情顺利进行。
为了更直观地展示 Elasticsearch 集群的节点间关系,下面给大家放一张集群架构图:
从图中可以看到,集群中有多个节点,包括主节点、数据节点和协调节点。主节点负责管理集群,数据节点存储和处理数据,协调节点负责请求的分发和结果的聚合。数据被分成多个分片,分布在不同的数据节点上,每个主分片都有对应的副本分片,以保证数据的可靠性和高可用性。
3.3 文档、索引与类型:数据的组织方式
在 Elasticsearch 中,文档、索引和类型是三个非常重要的概念,它们就像图书馆里的书籍、书架和书架分类一样,共同构成了数据的组织体系。
文档(Document):文档是 Elasticsearch 中存储和检索的最小数据单元,它就像是图书馆里的每一本书。每个文档都是一个独立的实体,以 JSON 格式来表示,包含了各种字段和对应的值。比如我们有一个用户文档,它可能包含以下字段:
{ \"user_id\": \"12345\", \"name\": \"张三\", \"age\": 25, \"email\": \"zhangsan@example.com\", \"address\": \"北京市朝阳区\"}这里的 “user_id”、“name”、“age”、“email” 和 “address” 就是文档的字段,每个字段都有对应的取值。每个文档在它所属的索引内都有一个唯一的 ID,这个 ID 可以是我们自己指定,比如使用业务相关的 ID,像上面的 “user_id”;也可以由 Elasticsearch 自动生成,是一个随机的 UUID。文档就像是我们生活中的一个个小包裹,每个包裹里装着不同的物品(字段和值),并且都有一个独一无二的编号(ID),方便我们查找和管理。
索引(Index):索引是文档的集合,是具有相似特征的文档的逻辑容器,它类似于图书馆里的书架。一个索引可以包含多个文档,就像一个书架上可以放很多本书。比如我们有一个电商项目,可能会有一个 “products” 索引,用来存储所有商品的文档;有一个 “orders” 索引,用来存储所有订单的文档。每个索引在 Elasticsearch 中都有一个唯一的名称,通过这个名称我们可以对索引进行操作,比如创建索引、删除索引、向索引中添加文档、从索引中搜索文档等。索引就像是一个大柜子,把相关的小包裹(文档)都放在一起,方便我们统一管理和查找。
类型(Type):在 Elasticsearch 6.x 及以下版本中,类型是索引的子集,用于定义数据的结构和映射,就像是书架上的书籍分类。一个索引可以包含多个类型,每个类型可以有自己的映射和设置。比如在 “products” 索引中,我们可以有 “electronics” 类型,用来存储电子产品的文档;有 “clothes” 类型,用来存储服装类商品的文档。不同类型的文档结构可能不同,比如 “electronics” 类型的文档可能包含 “brand”(品牌)、“model”(型号)、“specifications”(规格参数)等字段,而 “clothes” 类型的文档可能包含 “size”(尺码)、“color”(颜色)、“style”(款式)等字段。但是从 Elasticsearch 7.0 开始,类型的概念已经逐渐被废弃,取而代之的是使用单一的类型 “_doc”。这就好比以前书架上的书按照不同的类别分在不同的区域,现在把所有的书都放在一起,不再细分区域了,但每本书还是有自己独特的内容(文档结构)。
它们之间的层级关系:简单来说,索引包含类型(在旧版本中)或直接包含文档(在新版本中),类型包含文档。可以用下面这个类比来理解:
-
关系型数据库:数据库(Database) -> 表(Table) -> 行(Row) -> 列(Column)
-
Elasticsearch:索引(Index) -> 类型(Type,在旧版本中) -> 文档(Document) -> 字段(Field)
在实际应用中,我们要根据业务需求来设计索引和类型(如果使用旧版本)来存储数据。比如在一个博客系统中,我们可以创建一个 “blogs” 索引,里面包含 “articles” 类型,用来存储博客文章的文档。每个文章文档可能包含 “title”(标题)、“author”(作者)、“content”(内容)、“publish_date”(发布日期)等字段。这样,我们就可以通过 Elasticsearch 对博客文章进行高效的存储、搜索和管理了。再比如在一个日志分析系统中,我们可以创建一个 “logs” 索引,直接往里面存储各种日志文档,每个文档包含 “timestamp”(时间戳)、“level”(日志级别)、“message”(日志信息)等字段,方便我们对日志进行实时分析和查询。
四、Java 操作 Elasticsearch 实战
理论知识讲了这么多,是时候来真刀真枪地实战一番啦!接下来,我们就通过 Java 代码来实际操作 Elasticsearch,看看如何进行索引的创建、文档的插入、查询、更新和删除等操作。就像学会了开车理论知识后,得真正上路练练手一样,只有通过实战,才能对 Elasticsearch 有更深刻的理解。
4.1 创建索引
在 Elasticsearch 中,索引就像是一个容器,用来存放我们的文档数据。下面我们来看如何用 Java 代码创建一个索引,并指定相关的设置和映射。
import org.apache.http.HttpHost;import org.elasticsearch.action.admin.indices.create.CreateIndexRequest;import org.elasticsearch.action.admin.indices.create.CreateIndexResponse;import org.elasticsearch.client.RequestOptions;import org.elasticsearch.client.RestClient;import org.elasticsearch.client.RestHighLevelClient;import org.elasticsearch.common.settings.Settings;import org.elasticsearch.common.xcontent.XContentType;public class ElasticsearchIndexCreation { public static void main(String[] args) throws Exception { // 创建RestHighLevelClient实例 RestHighLevelClient client = new RestHighLevelClient( RestClient.builder( new HttpHost(\"localhost\", 9200, \"http\"))); // 创建创建索引的请求 CreateIndexRequest request = new CreateIndexRequest(\"my_index\"); // 设置索引的相关设置,比如分片数和副本数 request.settings(Settings.builder() .put(\"index.number_of_shards\", 3) .put(\"index.number_of_replicas\", 2)); // 设置索引的映射,这里以一个简单的文档结构为例 String mapping = \"{\\n\" + \" \\\"properties\\\": {\\n\" + \" \\\"title\\\": {\\n\" + \" \\\"type\\\": \\\"text\\\"\\n\" + \" },\\n\" + \" \\\"content\\\": {\\n\" + \" \\\"type\\\": \\\"text\\\"\\n\" + \" },\\n\" + \" \\\"date\\\": {\\n\" + \" \\\"type\\\": \\\"date\\\"\\n\" + \" }\\n\" + \" }\\n\" + \"}\"; request.mapping(mapping, XContentType.JSON); // 执行创建索引的请求 CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT); if (response.isAcknowledged()) { System.out.println(\"索引创建成功!\"); } else { System.out.println(\"索引创建失败!\"); } // 关闭客户端 client.close(); }}在这段代码中:
-
CreateIndexRequest类用于创建一个创建索引的请求,我们传入要创建的索引名称my_index。 -
request.settings方法用于设置索引的一些参数,这里设置了分片数为 3,副本数为 2。分片数决定了索引数据在集群中的分布情况,副本数则用于提高数据的可靠性和查询性能。就像把一个大仓库分成 3 个小仓库来存放货物(分片),并且每个小仓库都有 2 份备份(副本),这样既方便管理,又能保证货物的安全。 -
request.mapping方法用于设置索引的映射,映射定义了文档中字段的数据类型和索引方式等。这里我们定义了三个字段:title和content为文本类型,date为日期类型。文本类型的字段会被分词处理,以便进行全文搜索;日期类型的字段则用于存储日期和时间数据。这就好比给仓库里的货物贴上标签,标明它们的类型和存放规则。
创建成功和失败时的返回结果及处理方式:
-
成功时:如果索引创建成功,
CreateIndexResponse的isAcknowledged方法会返回true,此时我们可以在控制台打印 “索引创建成功!”,并可以根据业务需求进行后续操作,比如向索引中插入数据。这就像你成功租到了一个仓库,接下来就可以往里面存放货物了。 -
失败时:如果索引创建失败,
isAcknowledged方法会返回false,我们可以在控制台打印 “索引创建失败!”,并查看CreateIndexResponse中的错误信息,根据错误提示来排查问题。可能的原因有很多,比如索引名称已经存在、设置参数不正确、集群连接问题等。这就好比你租仓库失败了,得看看是因为仓库名字重复了,还是租金没付够,或者是和房东联系不上等原因,然后针对性地解决问题。
4.2 插入文档
索引创建好之后,就该往里面插入文档数据啦。下面是使用 Java 代码将文档插入到 Elasticsearch 索引中的示例。
import com.fasterxml.jackson.databind.ObjectMapper;import org.apache.http.HttpHost;import org.elasticsearch.action.index.IndexRequest;import org.elasticsearch.action.index.IndexResponse;import org.elasticsearch.client.RequestOptions;import org.elasticsearch.client.RestClient;import org.elasticsearch.client.RestHighLevelClient;import org.elasticsearch.common.xcontent.XContentType;import java.util.HashMap;import java.util.Map;public class ElasticsearchDocumentInsertion { public static void main(String[] args) throws Exception { RestHighLevelClient client = new RestHighLevelClient( RestClient.builder( new HttpHost(\"localhost\", 9200, \"http\"))); // 创建要插入的文档数据,这里使用Map来表示 Map<String, Object> document = new HashMap<>(); document.put(\"title\", \"Elasticsearch入门教程\"); document.put(\"content\", \"这是一篇关于Elasticsearch的入门教程,介绍了Elasticsearch的基本概念和使用方法。\"); document.put(\"date\", \"2023-10-15\"); // 创建索引请求,指定索引名称和文档ID(这里文档ID可以自动生成,也可以手动指定) IndexRequest request = new IndexRequest(\"my_index\") .id(\"1\") .source(document, XContentType.JSON); // 执行插入操作 IndexResponse response = client.index(request, RequestOptions.DEFAULT); if (response.getResult().name().equals(\"CREATED\") || response.getResult().name().equals(\"UPDATED\")) { System.out.println(\"文档插入成功!\"); } else { System.out.println(\"文档插入失败!\"); } client.close(); }}在这段代码中:
-
首先创建了一个
Map对象document,用来存储文档的字段和值。就像把要存放进仓库的货物整理好,贴上标签,标明它们的名称和内容。 -
IndexRequest类用于创建一个插入文档的请求,我们指定了要插入的索引名称my_index和文档 ID1(这里的 ID 可以根据业务需求自行指定,也可以让 Elasticsearch 自动生成)。然后通过source方法将文档数据传入请求,数据格式为 JSON,这里使用XContentType.JSON来指定。这就好比把整理好的货物放进一个特定的箱子里(IndexRequest),并贴上箱子的标签(索引名称和文档 ID),准备放进仓库(索引)。 -
执行插入操作后,根据
IndexResponse的getResult方法返回的结果来判断插入是否成功。如果结果是CREATED,表示文档是新创建并插入成功;如果是UPDATED,表示文档原本已存在,进行了更新操作。这就像你把货物放进仓库后,看看仓库管理员给你的反馈,是成功新建了一个存放位置(CREATED),还是更新了已有的存放位置(UPDATED)。
将 Java 对象转换为 JSON 格式插入的方法:
除了使用Map来构建文档数据,我们还可以将 Java 对象转换为 JSON 格式后插入。这里需要借助一些 JSON 处理库,比如 Jackson。下面是一个将 Java 对象转换为 JSON 并插入的示例:
import com.fasterxml.jackson.databind.ObjectMapper;import org.apache.http.HttpHost;import org.elasticsearch.action.index.IndexRequest;import org.elasticsearch.action.index.IndexResponse;import org.elasticsearch.client.RequestOptions;import org.elasticsearch.client.RestClient;import org.elasticsearch.client.RestHighLevelClient;import org.elasticsearch.common.xcontent.XContentType;public class ElasticsearchObjectInsertion { public static void main(String[] args) throws Exception { RestHighLevelClient client = new RestHighLevelClient( RestClient.builder( new HttpHost(\"localhost\", 9200, \"http\"))); // 创建Java对象 Article article = new Article(); article.setTitle(\"Elasticsearch进阶教程\"); article.setContent(\"这是一篇关于Elasticsearch的进阶教程,深入介绍了Elasticsearch的原理和高级用法。\"); article.setDate(\"2023-10-16\"); // 使用Jackson将Java对象转换为JSON字符串 ObjectMapper objectMapper = new ObjectMapper(); String json = objectMapper.writeValueAsString(article); // 创建索引请求,指定索引名称和文档ID IndexRequest request = new IndexRequest(\"my_index\") .id(\"2\") .source(json, XContentType.JSON); // 执行插入操作 IndexResponse response = client.index(request, RequestOptions.DEFAULT); if (response.getResult().name().equals(\"CREATED\") || response.getResult().name().equals(\"UPDATED\")) { System.out.println(\"文档插入成功!\"); } else { System.out.println(\"文档插入失败!\"); } client.close(); }}class Article { private String title; private String content; private String date; // 省略getter和setter方法}在这个示例中,我们先创建了一个Article类的对象,然后使用 Jackson 的ObjectMapper将其转换为 JSON 字符串,再将 JSON 字符串作为文档数据插入到 Elasticsearch 中。这就好比把货物(Java 对象)装进一个特殊的包装(JSON 字符串)里,再放进仓库(索引)。
插入时的并发处理策略和可能遇到的冲突问题及解决方法:
-
并发处理策略:在高并发场景下,多个线程可能同时向 Elasticsearch 插入文档。为了保证数据的一致性和完整性,可以使用 Elasticsearch 提供的乐观锁机制。在插入文档时,可以指定文档的版本号(version),Elasticsearch 会根据版本号来判断文档是否被修改过。如果版本号不一致,说明文档在插入过程中被其他线程修改过,此时可以根据业务需求进行重试或者其他处理。这就像多个工人同时往仓库里放货物,为了避免货物放错位置或者被覆盖,每个工人在放货物前都要检查一下这个位置的货物版本号(相当于一个标记),如果版本号不对,就重新确认一下再放。
-
冲突问题及解决方法:可能遇到的冲突问题主要是版本冲突(version conflict),即多个线程同时尝试更新同一个文档,导致版本不一致。解决方法除了上述的乐观锁机制外,还可以采用悲观锁机制,即在操作文档前先锁定文档,防止其他线程同时修改。不过悲观锁会降低系统的并发性能,所以要根据实际业务场景来选择合适的方法。另外,还可以在应用层进行重试处理,当遇到版本冲突时,等待一段时间后重新尝试插入操作,直到成功为止。这就好比仓库里的货物被多个工人同时操作出现了冲突,我们可以让工人先停下来,等一会儿再重新操作,或者给货物上一把锁,一次只允许一个工人操作。
4.3 查询文档
Elasticsearch 的强大之处就在于它提供了丰富的查询功能。下面我们来看一些常见的查询方式,以及它们在 Java 代码中的实现。
精确查询(Term Query):
精确查询用于查找与指定值完全匹配的文档,通常用于对不分词的字段进行查询,比如 ID 字段、状态字段等。
import org.apache.http.HttpHost;import org.elasticsearch.action.search.SearchRequest;import org.elasticsearch.action.search.SearchResponse;import org.elasticsearch.client.RequestOptions;import org.elasticsearch.client.RestClient;import org.elasticsearch.client.RestHighLevelClient;import org.elasticsearch.index.query.QueryBuilders;import org.elasticsearch.search.builder.SearchSourceBuilder;import org.elasticsearch.search.fetch.subphase.FetchSourceContext;public class ElasticsearchExactQuery { public static void main(String[] args) throws Exception { RestHighLevelClient client = new RestHighLevelClient( RestClient.builder( new HttpHost(\"localhost\", 9200, \"http\"))); // 创建搜索请求,指定索引名称 SearchRequest searchRequest = new SearchRequest(\"my_index\"); // 构建查询条件,这里使用精确查询,查找title为\"Elasticsearch入门教程\"的文档 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); sourceBuilder.query(QueryBuilders.termQuery(\"title\", \"Elasticsearch入门教程\")); // 设置只返回指定字段,这里只返回title和content字段 sourceBuilder.fetchSource(new String[]{\"title\", \"content\"}, null); searchRequest.source(sourceBuilder); // 执行搜索请求 SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT); // 处理搜索结果 if (searchResponse.getHits().getTotalHits().value > 0) { for (SearchHit hit : searchResponse.getHits().getHits()) { System.out.println(hit.getSourceAsString()); } } else { System.out.println(\"没有找到匹配的文档。\"); } client.close(); }}在这段代码中:
-
SearchRequest类用于创建一个搜索请求,指定要搜索的索引名称my_index。 -
SearchSourceBuilder类用于构建搜索条件,这里使用QueryBuilders.termQuery方法创建了一个精确查询条件,查找title字段值为 “Elasticsearch 入门教程” 的文档。就像在仓库里找一个特定标签(字段)上写着特定内容(值)的货物。 -
sourceBuilder.fetchSource方法用于设置只返回指定的字段,这里只返回title和content字段,提高查询效率,减少不必要的数据传输。这就好比你去仓库取货,只取你需要的货物,而不是把整个仓库的货物都搬回来。
模糊查询(Match Query):
模糊查询用于查找与指定文本相似的文档,会对查询文本进行分词处理,然后在索引中查找包含这些分词的文档,适用于全文搜索场景。
import org.apache.http.HttpHost;import org.elasticsearch.action.search.SearchRequest;import org.elasticsearch.action.search.SearchResponse;import org.elasticsearch.client.RequestOptions;import org.elasticsearch.client.RestClient;import org.elasticsearch.client.RestHighLevelClient;import org.elasticsearch.index.query.QueryBuilders;import org.elasticsearch.search.builder.SearchSourceBuilder;public class ElasticsearchFuzzyQuery { public static void main(String[] args) throws Exception { RestHighLevelClient client = new RestHighLevelClient( RestClient.builder( new HttpHost(\"localhost\", 9200, \"http\"))); SearchRequest searchRequest = new SearchRequest(\"my_index\"); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); // 使用模糊查询,查找content中包含\"Elasticsearch\"的文档 sourceBuilder.query(QueryBuilders.matchQuery(\"content\", \"Elasticsearch\")); searchRequest.source(sourceBuilder); SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT); if (searchResponse.getHits().getTotalHits().value > 0) { for (SearchHit hit : searchResponse.getHits().getHits()) { System.out.println(hit.getSourceAsString()); } } else { System.out.println(\"没有找到匹配的文档。\"); } client.close(); }}在这段代码中,使用QueryBuilders.matchQuery方法创建了一个模糊查询条件,查找content字段中包含 “Elasticsearch” 的文档。由于是模糊查询,只要文档的content字段中包含 “Elasticsearch” 这个词的分词,就会被匹配到。这就像在仓库里找所有和 “Elasticsearch” 有点关系的货物,只要货物的描述里有相关的词,就可能被找到。
范围查询(Range Query):
范围查询用于查找在指定范围内的文档,比如查找某个日期范围内的文档,或者某个数值范围内的文档。
import org.apache.http.HttpHost;import org.elasticsearch.action.search.SearchRequest;import org.elasticsearch.action.search.SearchResponse;import org.elasticsearch.client.RequestOptions;import org.elasticsearch.client.RestClient;import org.elasticsearch.client.RestHighLevelClient;import org.elasticsearch.index.query.QueryBuilders;import org.elasticsearch.search.builder.SearchSourceBuilder;import java.io.IOException;public class ElasticsearchRangeQuery { public static void main(String[] args) throws IOException { // 创建高级客户端 try (RestHighLevelClient client = new RestHighLevelClient( RestClient.builder( new HttpHost(\"localhost\", 9200, \"http\")))) { // 创建搜索请求 SearchRequest searchRequest = new SearchRequest(\"my_index\"); // 创建搜索源构建器 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); // 使用范围查询,查找date在\"2023-10-01\"到\"2023-10-31\"之间的文档 sourceBuilder.query(QueryBuilders.rangeQuery(\"date\") .gte(\"2023-10-01\") // 大于等于 .lte(\"2023-10-31\")); // 小于等于 // 将搜索源构建器设置到搜索请求 searchRequest.source(sourceBuilder); // 执行搜索请求 SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT); // 打印搜索结果 System.out.println(searchResponse.toString()); } }}五、Elasticsearch中的定时任务
5.1 定时任务的应用场景
在Elasticsearch的实际应用中,定时任务就像一个默默工作的小助手,在很多场景下发挥着重要作用。下面我们来看看它在日志分析和数据同步这两个常见场景中的应用,以及对系统性能和数据一致性的影响。
日志分析场景:
在大型系统中,日志就像一个忠实的记录员,记录着系统运行过程中的点点滴滴。但随着时间的推移,日志数据会越来越多,如果不及时清理,不仅会占用大量的磁盘空间,还会影响Elasticsearch的查询性能。这时候,定时任务就派上用场啦。我们可以设置一个定时任务,定期清理过期的日志。比如每天凌晨2点,自动删除30天前的日志数据。这样既能保证系统有足够的磁盘空间,又能让Elasticsearch专注于处理近期的日志数据,提高查询效率。这就好比定期清理仓库里过期的货物,让仓库保持整洁,提高货物管理效率。
但是,定时清理日志也可能会对系统性能产生一定的影响。在清理过程中,Elasticsearch需要读取和删除大量的文档,这会占用一定的CPU、内存和磁盘I/O资源。如果系统在这个时间段内还有其他重要的任务在运行,可能会导致系统性能下降。所以,在设置定时任务时,要尽量选择系统负载较低的时间段执行,比如凌晨等业务低谷期。同时,为了保证数据的一致性,在清理日志之前,最好先对相关的日志索引进行备份,以防误删重要数据。这就像在清理仓库货物前,先把重要的货物拍照留存,万一误删了还能找回。
数据同步场景:
在很多业务系统中,我们需要将数据从其他数据源(如MySQL、Oracle等关系型数据库)同步到Elasticsearch中,以便利用Elasticsearch强大的搜索和分析功能。定时任务可以帮助我们实现定时从其他数据源同步数据到Elasticsearch。比如,我们可以设置一个定时任务,每小时从MySQL数据库中读取新增和修改的数据,同步到Elasticsearch的相应索引中。这样,Elasticsearch中的数据就能与数据源保持一定程度的一致性,用户在搜索时能获取到最新的数据。这就好比定期从一个仓库(数据源)把新到的货物搬运到另一个仓库(Elasticsearch),让两个仓库的货物信息保持一致。
然而,定时数据同步也存在一些挑战。首先,由于是定时同步,数据会存在一定的时间差,无法做到实时同步。如果业务对数据的实时性要求很高,这种方式可能就不太适用。其次,在同步过程中,如果数据源的数据频繁变化,可能会出现数据不一致的情况。比如,在同步过程中,数据源中的数据又被修改了,这就需要我们在同步逻辑中考虑如何处理这种情况,以保证数据的一致性。另外,频繁的定时同步也会对数据源和Elasticsearch造成一定的负载压力,需要合理设置同步的时间间隔和数据量,以平衡系统性能和数据一致性的需求。这就像在搬运货物时,要考虑搬运的频率和每次搬运的数量,既要保证两个仓库货物一致,又不能让搬运工作影响到仓库的正常运作。
5.2 使用Java实现Elasticsearch定时任务
在Java中,我们可以借助Quartz框架来实现Elasticsearch的定时任务。Quartz是一个功能强大的开源任务调度框架,就像一个精准的时钟,能按照我们设定的时间规则来执行任务。下面我们就来看看如何使用Quartz实现定时操作Elasticsearch。
引入依赖:
首先,在我们的Java项目中,需要引入Quartz的依赖。如果使用Maven项目,在pom.xml文件中添加以下依赖:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-quartz</artifactId></dependency>这个依赖就像是给我们的项目装上了 Quartz 这个强大的 “外挂”,让我们可以使用 Quartz 提供的各种功能来实现定时任务。
定义定时任务 Job 类:
接下来,我们要定义一个定时任务的 Job 类,这个类就是我们定时任务的具体执行者,它知道要做什么。比如,我们要定时从 Elasticsearch 中查询数据,就可以这样定义 Job 类:
import org.quartz.Job;import org.quartz.JobExecutionContext;import org.quartz.JobExecutionException;import org.elasticsearch.action.search.SearchRequest;import org.elasticsearch.action.search.SearchResponse;import org.elasticsearch.client.RequestOptions;import org.elasticsearch.client.RestHighLevelClient;import org.elasticsearch.index.query.QueryBuilders;import org.elasticsearch.search.builder.SearchSourceBuilder;import org.elasticsearch.search.fetch.subphase.FetchSourceContext;public class ElasticsearchJob implements Job { private RestHighLevelClient client; public ElasticsearchJob(RestHighLevelClient client) { this.client = client; } @Override public void execute(JobExecutionContext context) throws JobExecutionException { try { // 创建搜索请求,指定索引名称 SearchRequest searchRequest = new SearchRequest(\"my_index\"); // 构建查询条件,这里使用模糊查询,查找content中包含\"Elasticsearch\"的文档 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); sourceBuilder.query(QueryBuilders.matchQuery(\"content\", \"Elasticsearch\")); // 设置只返回指定字段,这里只返回title和content字段 sourceBuilder.fetchSource(new String[]{\"title\", \"content\"}, null); searchRequest.source(sourceBuilder); // 执行搜索请求 SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT); // 处理搜索结果 if (searchResponse.getHits().getTotalHits().value > 0) { for (SearchHit hit : searchResponse.getHits().getHits()) { System.out.println(hit.getSourceAsString()); } } else { System.out.println(\"没有找到匹配的文档。\"); } } catch (Exception e) { e.printStackTrace(); } }}在这个 Job 类中:
-
首先通过构造函数接收一个
RestHighLevelClient实例,这个实例就像是我们和 Elasticsearch 交流的 “翻译官”,通过它我们可以向 Elasticsearch 发送各种请求。 -
在
execute方法中,我们编写了具体的操作 Elasticsearch 的逻辑。这里是创建一个搜索请求,指定要搜索的索引为my_index,然后构建查询条件,使用模糊查询查找content字段中包含 “Elasticsearch” 的文档,并设置只返回title和content字段。最后执行搜索请求,并处理搜索结果。这就好比我们给 “翻译官” 下达指令,让它去 Elasticsearch 这个 “大仓库” 里找符合条件的 “货物”(文档),并把找到的 “货物” 展示出来。
配置和启动定时任务:
配置定时任务时,我们可以通过 Spring 的配置类来完成。下面是一个配置和启动定时任务的示例:
import org.quartz.*;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;@Configurationpublic class QuartzConfig { @Bean public JobDetail jobDetail() { return JobBuilder.newJob(ElasticsearchJob.class) .withIdentity(\"elasticsearchJob\", \"elasticsearchGroup\") .storeDurably() .build(); } @Bean public Trigger trigger(JobDetail jobDetail, RestHighLevelClient client) { // 使用Cron表达式设置触发时间,这里设置为每分钟执行一次 CronScheduleBuilder scheduleBuilder = CronScheduleBuilder.cronSchedule(\"0 * * * * ?\"); return TriggerBuilder.newTrigger() .withIdentity(\"elasticsearchTrigger\", \"elasticsearchGroup\") .forJob(jobDetail) .withSchedule(scheduleBuilder) .usingJobData(\"client\", client) .build(); }}在这个配置类中:
-
jobDetail方法创建了一个JobDetail实例,它描述了定时任务的详细信息。JobBuilder.newJob(ElasticsearchJob.class)指定了任务的执行类为ElasticsearchJob,withIdentity(\"elasticsearchJob\", \"elasticsearchGroup\")给任务设置了唯一的标识,storeDurably()表示任务即使没有触发器关联也会持久化保存。这就好比给我们的定时任务贴上了一个独一无二的标签,并且保证它不会轻易丢失。 -
trigger方法创建了一个触发器Trigger,它决定了任务什么时候执行。CronScheduleBuilder.cronSchedule(\"0 * * * * ?\")使用 Cron 表达式设置了触发时间,这里表示每分钟的 0 秒执行一次,就像一个闹钟,每分钟准时响一次。forJob(jobDetail)将触发器和任务关联起来,usingJobData(\"client\", client)将RestHighLevelClient实例作为参数传递给任务,这样在任务执行时就能使用这个客户端与 Elasticsearch 进行交互。这就好比把闹钟和要执行的任务绑在一起,并且给任务提供了它需要的工具(RestHighLevelClient)。
定时任务执行流程时序图:
为了让大家更清楚地了解定时任务的执行流程,下面给大家展示一个时序图:
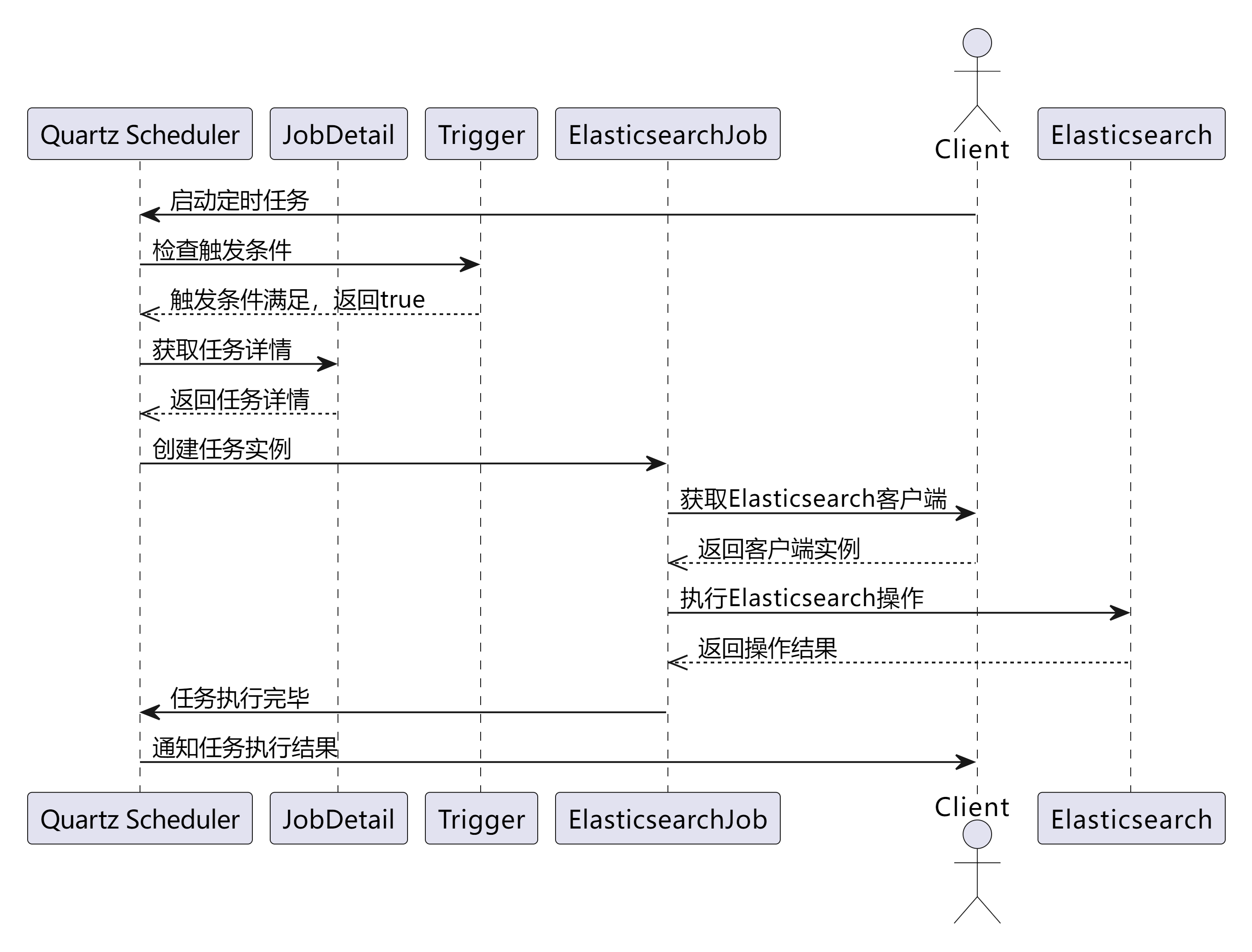
从时序图中可以清晰地看到:
-
客户端启动定时任务,向 Quartz Scheduler 发送启动请求。
-
Scheduler 定期检查 Trigger 的触发条件,当触发条件满足时(比如到达了设定的执行时间),Trigger 返回
true,通知 Scheduler 可以执行任务了。 -
Scheduler 根据 JobDetail 获取任务的详细信息,然后创建任务实例(这里是
ElasticsearchJob)。 -
ElasticsearchJob从传入的参数中获取RestHighLevelClient实例,通过这个客户端与 Elasticsearch 进行交互,执行具体的操作(比如搜索数据)。 -
Elasticsearch 返回操作结果,
ElasticsearchJob处理完结果后,通知 Scheduler 任务执行完毕。 -
最后,Scheduler 将任务执行结果通知给客户端。
通过以上步骤,我们就使用 Quartz 框架在 Java 中实现了一个定时操作 Elasticsearch 的任务,并且清楚地了解了它的执行流程。
六、性能优化与常见问题解决
6.1 性能优化技巧
在 Elasticsearch 的使用过程中,性能优化是一个至关重要的环节。就好比开车,性能优化就像是给汽车做保养、升级零件,让它跑得又快又稳。下面我们从索引设计、查询优化、硬件配置这几个方面来看看具体的优化建议。
索引设计优化
-
合理设置分片数:分片数的设置直接影响着数据的分布和查询性能。如果分片数过多,每个分片的数据量就会很少,查询时需要在多个分片之间切换,增加了查询开销;如果分片数过少,单个分片的数据量过大,可能会导致查询性能下降,而且不利于水平扩展。一般来说,可以根据数据量和节点数来估算分片数,公式为节点数 × 1.5~3 倍。例如,有 5 个节点的集群,数据量较大且增长较快,那么分片数可以设置在 7.5(5×1.5)到 15(5×3)之间。同时,要考虑数据的增长趋势,预留一定的扩展空间,避免后期频繁调整分片数。这就像规划仓库的分区,如果分区太多,货物存放分散,找货麻烦;分区太少,货物堆积,也不好管理。
-
选择合适的字段类型:不同的字段类型对性能和存储空间有不同的影响。比如,对于需要进行聚合操作的字段,应避免使用
text类型,因为text类型默认会进行分词处理,聚合结果可能不准确,而改用keyword类型更合适,它不会分词,适合精确匹配和聚合。在存储数值类型时,如果数值范围不大,比如年龄字段,使用integer类型比long类型更节省内存,因为integer占用 4 个字节,而long占用 8 个字节。这就像选择合适的容器来装货物,大材小用或者小材大用都不合适。
查询优化技巧
-
避免全表扫描:全表扫描就像是在一个超大仓库里不按任何规则地找东西,效率极低。为了避免全表扫描,我们可以合理设置索引和查询条件。比如,使用
term查询代替match查询,term查询是精确匹配,不需要分词,效率更高;使用range查询时,合理设置范围条件,减少需要扫描的文档数量。另外,在查询中使用过滤条件,如bool查询中的filter子句,它不计算相关性分数,结果可以缓存,适合频繁使用的查询条件,能有效减少需要扫描的文档数量。这就像在仓库里找东西时,先确定大致的区域(过滤条件),再在这个区域内精确查找(term查询),比盲目地在整个仓库里找要快得多。 -
使用缓存:Elasticsearch 提供了查询缓存和分片请求缓存机制。对于频繁使用的查询,可以启用查询缓存,缓存查询结果,减少重复查询的开销。在
elasticsearch.yml文件中,可以配置indices.query.cache.enable: true来启用查询缓存。对于一些小索引且查询频繁的场景,还可以设置request_cache: true启用节点本地缓存。此外,也可以结合分布式缓存,如 Redis,缓存热门查询结果,进一步提高查询性能。这就像把常用的工具放在手边(缓存),下次再用的时候就不用到处去找了,节省时间。
硬件配置优化
-
内存:Elasticsearch 对内存的需求较高,因为它需要缓存索引数据和查询结果。建议每个节点至少配备 32GB RAM,如果是大型索引或高查询负载,可能需要更多。同时,要合理分配 JVM 堆内存,一般不超过物理内存的 50%,且不超过 32GB,因为超过 32GB 会导致指针压缩失效,降低内存使用效率。在
elasticsearch.yml文件中,可以通过-Xms和-Xmx参数来设置 JVM 堆内存的初始值和最大值,比如-Xms16g -Xmx16g。这就像给汽车加足够的油,并且合理分配油箱空间,让汽车能跑得更远更稳。 -
CPU:Elasticsearch 是一个多线程应用,可以充分利用多核 CPU 的优势。建议每个节点至少有 4 个核心,如果是高并发查询或者复杂的聚合操作,更多的核心会更有帮助。在选择 CPU 时,要平衡核心数量与频率,以适应工作负载。比如,对于实时性要求较高的搜索场景,较高频率的 CPU 可能更合适;对于大量数据的聚合分析任务,多核 CPU 能并行处理,提高效率。这就像汽车的发动机,核心数多就像发动机的气缸多,能提供更强大的动力;频率高就像发动机的转速快,能让汽车跑得更快。
为了更直观地展示优化前后的效果,我们来看一组性能测试数据对比。假设有一个包含 100 万条文档的索引,进行以下测试:
从数据可以明显看出,经过性能优化后,查询耗时大幅减少,系统性能得到了显著提升。这就像把一辆旧车经过改装和保养后,它的速度和性能都有了质的飞跃。
6.2 常见问题及解决方法
在使用 Elasticsearch 的过程中,难免会遇到一些问题。下面我们来列举一些常见问题,并分析问题产生的原因,给出详细的解决方案和排查步骤。
连接超时问题
问题描述:在 Java 应用程序与 Elasticsearch 集群通信时,经常会遇到连接超时的问题,导致请求无法正常发送或响应超时。这就像打电话时一直无法接通或者通话中途突然中断,非常影响使用体验。
原因分析:
-
网络问题:网络不稳定或者高延迟是导致连接超时的常见原因。可能是客户端与 Elasticsearch 服务器之间的网络线路存在故障,或者网络带宽不足,数据传输缓慢。这就像道路堵塞,车辆(数据)无法顺畅通行。
-
节点不可达:某些节点崩溃或未启动,会导致客户端无法连接到这些节点,从而出现连接超时。比如 Elasticsearch 集群中的某个数据节点突然死机了,客户端就无法与它建立连接。
-
过高的负载:节点负载过高,处理请求变慢,也会导致连接超时。当 Elasticsearch 集群中的节点同时处理大量的请求时,就像一个人要同时做很多事情,会忙不过来,处理速度就会变慢。
-
错误的配置:客户端连接配置错误,如设置的连接超时时间过短、主机地址或端口号错误等,也会导致连接超时。这就像你要去一个地方,但是地址写错了,肯定就去不了。
解决方案和排查步骤:
-
检查网络稳定性:使用
ping命令检查客户端与 Elasticsearch 服务器之间的网络是否连通,例如ping your_elasticsearch_server_ip。如果网络不通,需要检查网络线路、路由器等网络设备是否正常工作。 -
优化 Elasticsearch 集群性能:通过监控工具(如 Kibana)查看集群的负载情况,检查是否有节点负载过高。如果有,可以考虑增加节点、调整分片数量或减少大查询的频率,以降低节点的负载。
-
合理设置连接超时参数:在 Java 代码中,设置适当的连接超时时间和响应超时时间。例如,使用
RestClientBuilder设置连接超时时间为 5 秒,响应超时时间为 60 秒:
import org.apache.http.impl.nio.client.HttpAsyncClientBuilder;RestClientBuilder builder = RestClient.builder(new HttpHost(hostname, port, scheme));builder.setRequestConfigCallback(requestConfigBuilder -> requestConfigBuilder.setConnectTimeout(5000) .setSocketTimeout(60000));client = new RestHighLevelClient(builder);- 检查节点状态:使用
_cluster/healthAPI 查看集群的健康状态,检查是否有节点出现故障。例如,发送 HTTP 请求GET ``http://localhost:9200/_cluster/health,如果返回的status不是green或yellow,说明集群可能存在问题,需要进一步排查故障节点。
数据丢失问题
问题描述:有时候会发现 Elasticsearch 中的数据丢失,这可是个大问题,就像仓库里的货物莫名其妙不见了,让人头疼不已。
原因分析:
-
硬件故障:硬盘故障、电源故障或网络故障等硬件问题可能导致数据丢失。比如硬盘突然损坏,存储在上面的数据就可能无法读取。
-
节点故障:Elasticsearch 是一个分布式系统,由多个节点组成。如果某个节点发生故障,可能会导致该节点上的数据丢失。虽然 Elasticsearch 有副本机制,但如果副本分片还未完全同步数据,也可能会出现数据丢失的情况。这就像一个团队里有人突然离开,他负责的工作如果没有交接好,就可能出现问题。
-
索引操作错误:在进行索引操作时,如果操作不当或者发生错误,可能会导致数据丢失。比如在删除索引时,不小心删除了不该删除的索引;在更新文档时,由于并发操作等原因,导致数据更新错误。
-
配置错误:错误的配置可能导致数据丢失。例如,如果没有正确配置备份策略或者快照策略,可能会导致数据无法恢复。这就像按照错误的地图导航,很容易迷路。
解决方案和排查步骤:
- 使用冗余存储和备份策略:采用冗余存储,如 RAID 技术,防止硬盘故障导致的数据丢失。同时,定期进行数据备份,可以使用 Elasticsearch 的快照和恢复功能,将数据备份到外部存储设备。例如,创建一个快照仓库,并定期创建快照:
PUT _snapshot/my_backup_repo{ \"type\": \"fs\", \"settings\": { \"location\": \"/path/to/backup\" }}PUT _snapshot/my_backup_repo/snapshot_1?wait_for_completion=true- 配置合适的复制机制:确保每个主分片都有足够的副本分片,并且副本分片分布在不同的节点上,以防止单点故障。在创建索引时,可以设置副本数,例如:
CreateIndexRequest request = new CreateIndexRequest(\"my_index\");request.settings(Settings.builder() .put(\"index.number_of_shards\", 3) .put(\"index.number_of_replicas\", 2));- 仔细配置索引操作:在进行索引操作时,要仔细检查操作的正确性。可以使用事务或者确认机制来确保操作的完成。例如,在删除索引时,先进行确认操作,避免误删:
DeleteIndexRequest request = new DeleteIndexRequest(\"my_index\");request.setMasterTimeout(TimeValue.timeValueSeconds(10));request.setTimeout(TimeValue.timeValueSeconds(10));AckResponse response = client.indices().delete(request, RequestOptions.DEFAULT);if (response.isAcknowledged()) { System.out.println(\"索引删除成功\");} else { System.out.println(\"索引删除失败\");}- 检查配置文件:仔细检查 Elasticsearch 的配置文件,确保备份策略、快照策略等配置正确。可以参考官方文档,对比自己的配置是否有误。这就像检查地图上的路线是否正确,确保能顺利到达目的地。
查询结果不准确问题
问题描述:在进行查询时,有时候会发现查询结果不准确,返回的文档与预期不符,这就像在图书馆里按照书名找书,却拿到了一本不相关的书,让人很困惑。
原因分析:
-
字段映射错误:如果字段映射设置错误,比如将应该是
keyword类型的字段设置成了text类型,会导致查询结果不准确。因为text类型会进行分词处理,而keyword类型不会,这会影响查询的匹配逻辑。这就像给货物贴错了标签,按照错误的标签去找货物,肯定找不到正确的。 -
分词器选择不当:对于文本字段,分词器的选择非常重要。如果选择的分词器不能正确地将文本切分成合适的词项,就会影响查询结果。比如对于中文文本,如果使用默认的标准分词器,可能无法准确地分词,导致查询结果不准确。
-
查询语句错误:查询语句的编写错误也会导致查询结果不准确。比如在使用布尔查询时,逻辑关系设置错误,
must、should、mustNot等子句使用不当,会导致查询条件不符合预期。这就像给搜索引擎下达了错误的指令,它当然无法返回正确的结果。
解决方案和排查步骤:
- 检查字段映射:使用
_mappingAPI 查看索引的字段映射,确保字段类型设置正确。例如,查看my_index的字段映射:
GET my_index/_mapping如果发现字段映射错误,可以通过PUT请求修改字段映射,但要注意,对于已经存在数据的字段,修改映射可能会导致数据丢失或查询错误,需要谨慎操作。
2. 选择合适的分词器:根据文本的语言和特点,选择合适的分词器。对于中文文本,可以使用ik分词器等中文分词器,它能更准确地对中文进行分词。在创建索引时,设置分词器:
String mapping = \"{\\n\" + \" \\\"properties\\\": {\\n\" + \" \\\"content\\\": {\\n\" + \" \\\"type\\\": \\\"text\\\",\\n\" + \" \\\"analyzer\\\": \\\"ik_max_word\\\"\\n\" + \" }\\n\" + \" }\\n\" + \"}\";request.mapping(mapping, XContentType.JSON);- 检查查询语句:仔细检查查询语句的逻辑,确保查询条件正确。可以使用
_explainAPI 来分析查询语句的执行过程,查看匹配的文档和得分情况,找出查询结果不准确的原因。例如,分析查询语句:
GET my_index/_explain/1{ \"query\": { \"match\": { \"content\": \"查询关键词\" } }}通过分析返回的结果,可以了解查询是如何匹配文档的,从而调整查询语句。
在实际项目中,遇到这些问题时,要冷静分析,按照上述的排查步骤逐步找出问题的根源,并采取相应的解决方案。同时,要多参考官方文档和社区经验,不断积累解决问题的技巧,让 Elasticsearch 更好地为我们的项目服务。
七、总结与展望
在本次探索 Java 与 Elasticsearch 的奇妙之旅中,我们一起揭开了 Elasticsearch 的神秘面纱,深入了解了它的核心原理、在 Java 中的操作实战以及性能优化和定时任务的相关知识。
Elasticsearch 作为一款强大的分布式搜索和分析引擎,其基于倒排索引的数据检索方式,就像是在知识的海洋中为我们配备了一张无比精准的航海图,让我们能够快速定位到所需的信息。分布式架构则赋予了它处理海量数据的能力,通过多节点协作,如同一个高效运转的超级工厂,实现了数据的高效存储、检索和分析。文档、索引与类型构成了它独特的数据组织体系,让数据的管理变得井井有条,就像一个分类清晰的大型图书馆,每本书(文档)都能在对应的书架(索引)和书架分类(类型)中找到。
在 Java 开发中,我们通过一步步的实战,学会了如何搭建环境并连接 Elasticsearch 集群,就像搭建了一座通往数据宝藏的桥梁。从创建索引、插入文档,到进行各种复杂的查询操作,我们仿佛掌握了打开数据宝箱的钥匙,能够自由地对数据进行增删改查。而使用 Java 实现 Elasticsearch 定时任务,就像是为我们的数据处理流程安装了一个智能定时器,能够在特定的时间自动执行任务,大大提高了工作效率。
在性能优化方面,我们从索引设计、查询优化和硬件配置等多个角度入手,为 Elasticsearch 这台强大的机器进行了全方位的优化,让它能够在高负载的情况下依然保持高效运行。同时,我们也学会了如何应对常见问题,当遇到连接超时、数据丢失、查询结果不准确等问题时,能够冷静分析,找到问题的根源并解决它,确保系统的稳定运行。
随着大数据和人工智能技术的飞速发展,Elasticsearch 的应用前景将更加广阔。在大数据领域,它将继续发挥其强大的数据处理能力,帮助企业更好地分析和利用海量数据,挖掘数据背后的价值。在人工智能领域,它可能会与机器学习、深度学习算法相结合,实现更智能的搜索和数据分析功能。例如,通过机器学习算法对搜索结果进行智能排序,根据用户的行为和偏好提供个性化的搜索推荐;利用深度学习算法进行文本分类、情感分析等,进一步拓展其应用场景。
希望读者们能够在实际项目中积极应用 Elasticsearch,不断探索它的更多功能和潜力。相信在 Elasticsearch 的助力下,大家能够更加高效地处理和分析数据,为项目的成功贡献更多的力量。让我们一起期待 Elasticsearch 在未来带给我们更多的惊喜和可能!

