Text2Sql实战指南|Vanna本地化部署并结合Dify_vanna dify
Text2Sql实战指南|Vanna本地化部署并结合Dify
目录
- 前言
- 一、环境准备
- 二、向量数据库准备
- 三、模型框架选择
- 四、Vanna 安装与配置
- 五、Web 界面启动
- 六、模型训练
- 七、Vanna 结合 Dify
前言:探索 Vanna + Dify 的强大组合
Vanna 是一个基于 AI 的智能 SQL 生成工具,能够通过自然语言理解(NLU)和机器学习模型,将自然语言问题转换为 SQL 查询语句。它通过与数据库的无缝连接,帮助用户快速生成和执行 SQL 查询,大大提高了数据处理的效率和准确性。
Dify 是一个低代码/无代码平台,专注于将复杂的业务逻辑和数据处理流程自动化。它通过可视化界面和强大的工作流引擎,使用户能够轻松构建和部署复杂的业务应用,而无需深入编写代码。
将 Vanna 和 Dify 结合使用,可以实现从自然语言问题到数据查询结果的端到端自动化处理。这种组合不仅提高了开发效率,还降低了技术门槛,使非技术背景的用户也能够快速获取数据洞察
一、环境准备
准备好pyhton环境,我是用的Python 3.10.16,建议使用anaconda 创建独立的Python虚拟环境,避免依赖冲突
二、准备一个向量数据库
参考vanna官方文档

可以看到官方文档支持以上几种数据库,这里我是使用docker部署了Qdrant
三、模型框架选择
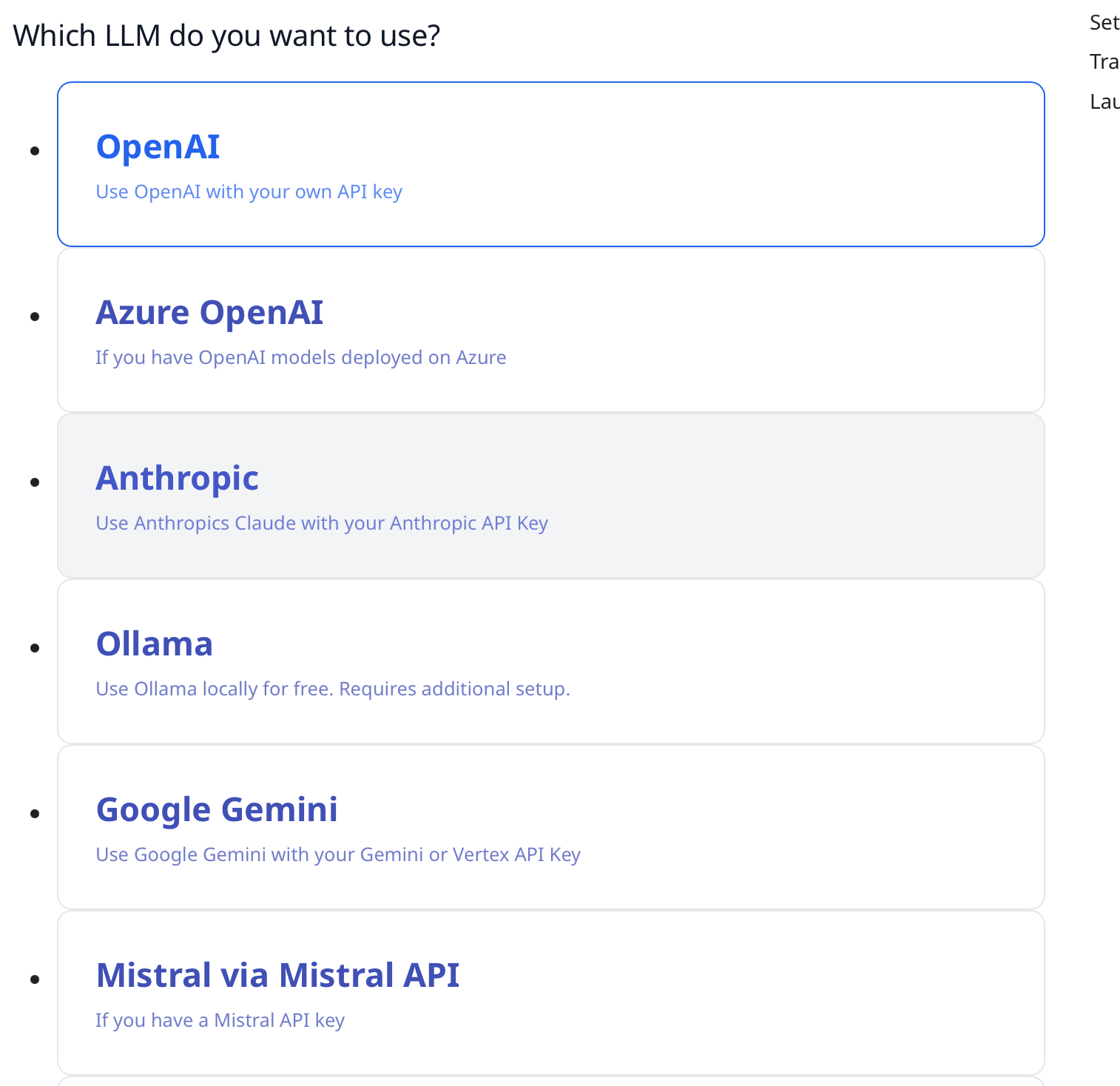
这里我用的是本机使用xinference部署的qwen2.5,采用openAI接口,所以选择OpenAI
四、Vanna安装与配置
安装 Vanna 及其相关依赖(最好在虚拟环境下):
pip install \'vanna[qdrant,openai,mysql]\'创建一个start.py启动脚本
from vanna.openai import OpenAI_Chatfrom vanna.chromadb import ChromaDB_VectorStorefrom openai import OpenAIfrom vanna.base import VannaBasefrom vanna.qdrant import Qdrant_VectorStorefrom qdrant_client import QdrantClientimport osos.environ[\'HF_ENDPOINT\'] = \'https://hf-mirror.com\'#因为公司服务器无法连接huggingface所以我在这里配置了镜像QDRANT_URL=\'http://127.0.0.1:6333\'#填你qdrant部署的地址,如果是服务器部署填服务器地址#创建 Qdrant 客户端实例qdrant_client = QdrantClient(url=QDRANT_URL)client =OpenAI( api_key = \"EMPTY\", base_url=\"http://127.0.0.1:9997/v1/\" )#填你部署的大模型地址,api_key未设置就填EMPTY class MyVanna(Qdrant_VectorStore, OpenAI_Chat): def __init__(self, config=None,client=None): Qdrant_VectorStore.__init__(self, config={\'client\':qdrant_client}) OpenAI_Chat.__init__(self,client=client, config=config)#创建 MyVanna 类的实例,模型名与本机模型对应vn = MyVanna(client=client,config={\'model\': \'qwen2.5-coder-instruct\'})#填你自己的数据库配置vn.connect_to_mysql(host=\'localhost\', dbname=\'testdb\', user=\'test\', password=\'123456\', port=6033)五、Web界面启动
在 start.py 中添加以下代码,启动 Web 界面:
from vanna.flask import VannaFlaskAppapp=VannaFlaskApp(vn, title=\"Vanna\",#web界面主标题 subtitle=\"test\"#副标题 )app.run(host=\'127.0.0.1\',port = 6060)六、模型训练
以下步骤也可启动vanna后在可视化页面手动添加
在启动脚本中添加以下代码
输入表结构
vn.train(ddl=\"\"\" CREATE TABLE IF NOT EXISTS Employee( `MANDT` COMMENT \'集团\', `PERNR` COMMENT \'人员编号\', `ENAME` COMMENT \'职员/申请人名\', ... ) ENGINE=InnoDB COMMENT=\'员工信息表\'; \"\"\" )这一步主要是告诉vanna各字段的含义
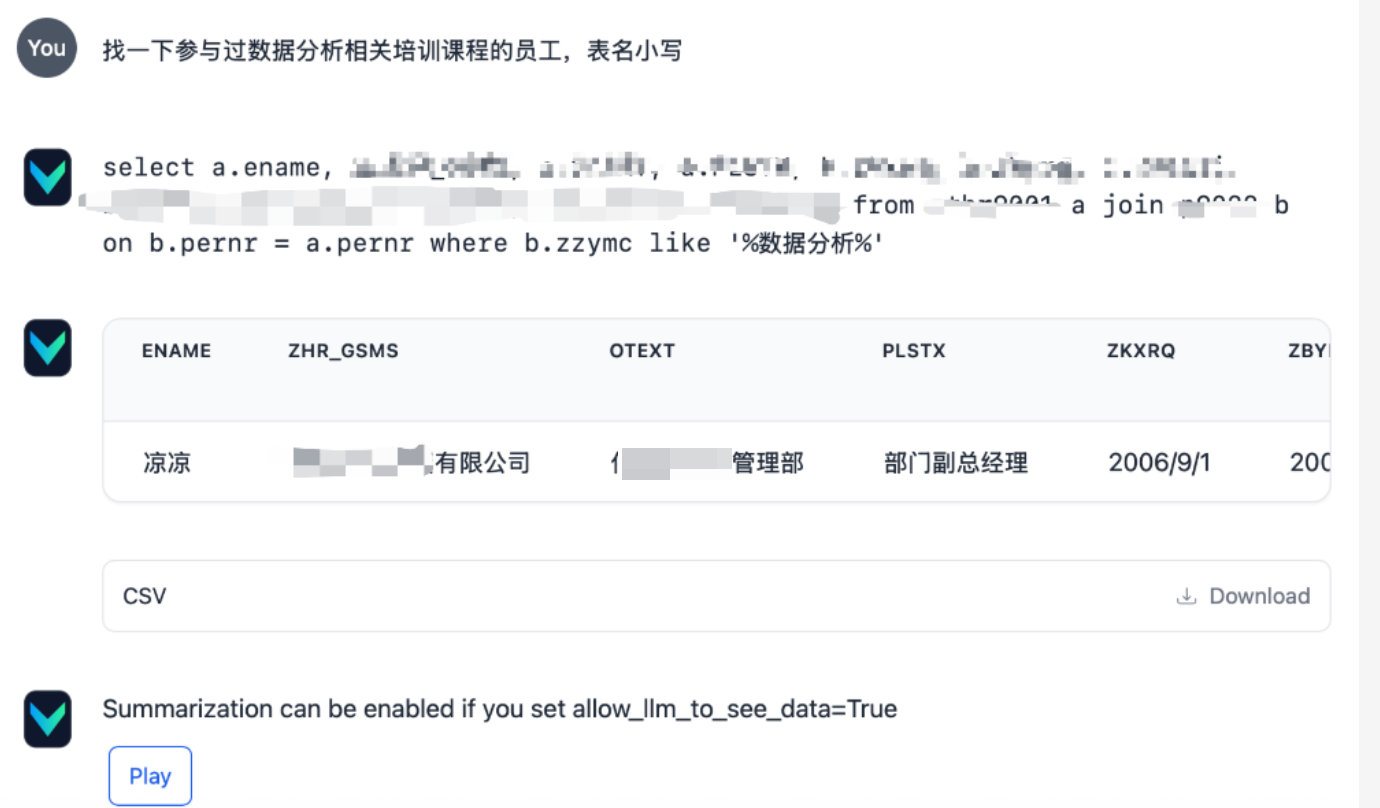
输入准备好的sql问题进行训练
vn.train(question=\"找一下名为上官婉儿的人员编号\", sql=\"SELECT ename FROM Employee WHERE name LIKE \'%上官婉儿%\';\" )添加说明
vn.train(documentation=\"尽量使用模糊查询\")到这里基本上训练就结束了
训练完后可以查看训练数据:
train_data = vn.get_training_data()print(\'===查看训练数据===\\n\',train_data)值得一提的是,vanna官方文档中提到每张表只需要训练一次,不需要重复训练
如果想清空训练数据可在脚本中添以下代码
train_data = vn.get_training_data()id_list = train_data[\'id\'].valuesfor i in range(len(id_list)):vn.remove_training_data(id=id_list[i])不想结合dify的话到这一步就可以运行脚本了
python3 start.py启动后可在浏览器输入http://127.0.0.1:6060查看前端页面
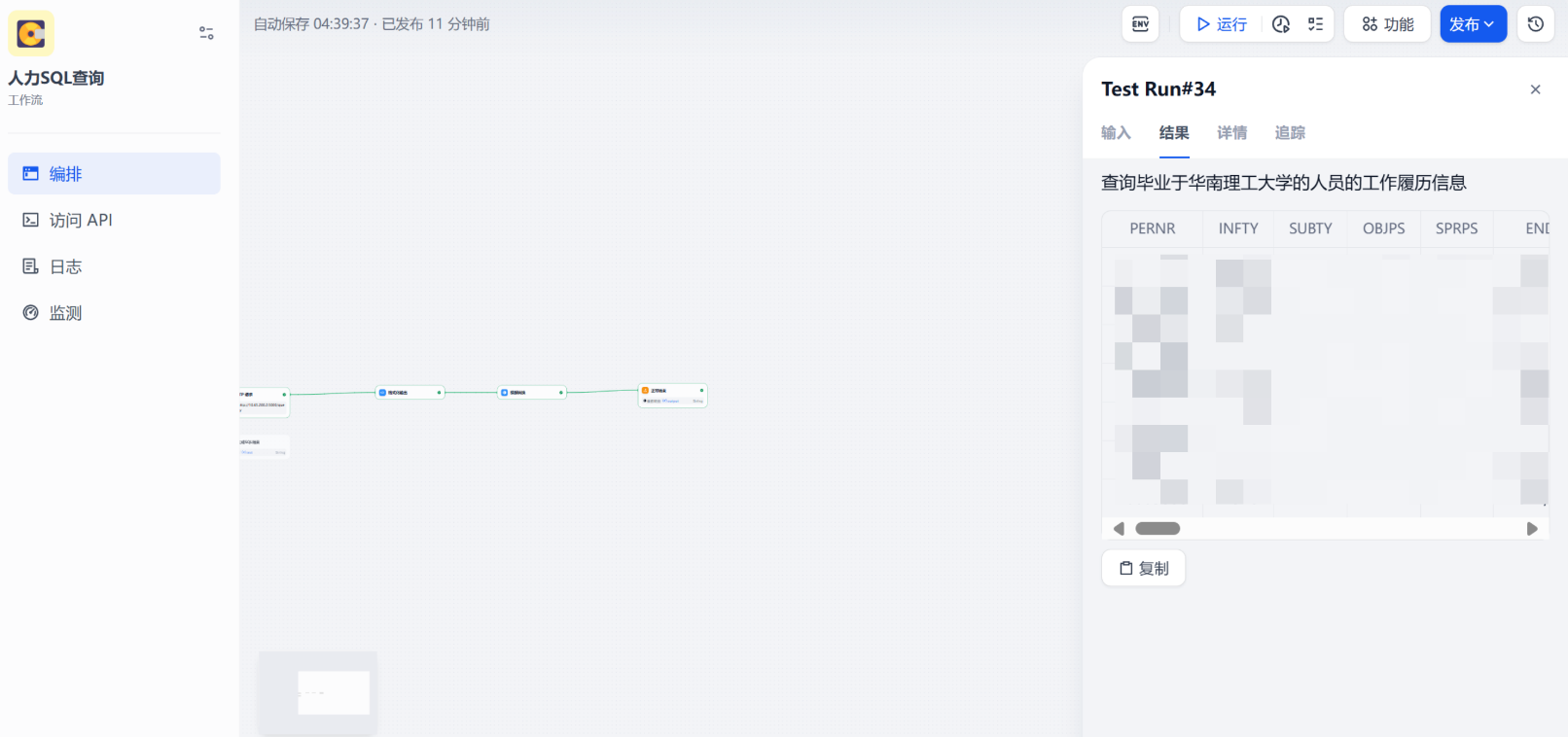
七、vanna结合dify
利用 FastAPI 将 Vanna 封装成 OpenAPI 形式,以工具的形式嵌入 Dify。
在启动脚本中添加以下代码
app = FastAPI()@app.post(\'/sql\')async def get_weather(request: Request): auth_header = request.headers.get(\'Authorization\') if auth_header != \'Bearer sql\': raise HTTPException(status_code=403, detail=\"Invalid Authorization header\") request_data = await request.json() data = request_data.get(\'sql\', None) if data is None: return { \'status\': \'error\', \'errorInfo\': \'No city provided\', \'data\': None } sql=vn.generate_sql(data) return f\"{vn.run_sql(sql)}\"import uvicornif __name__ == \'__main__\': uvicorn.run(app, host=\'0.0.0.0\', port=8081)运行脚本
python3 start.py执行后如果配置了web界面会先启动web,需要ctrl+c启动FastAPI。建议再开个命令行启动web前端,这样两边都能同时用
dify配置
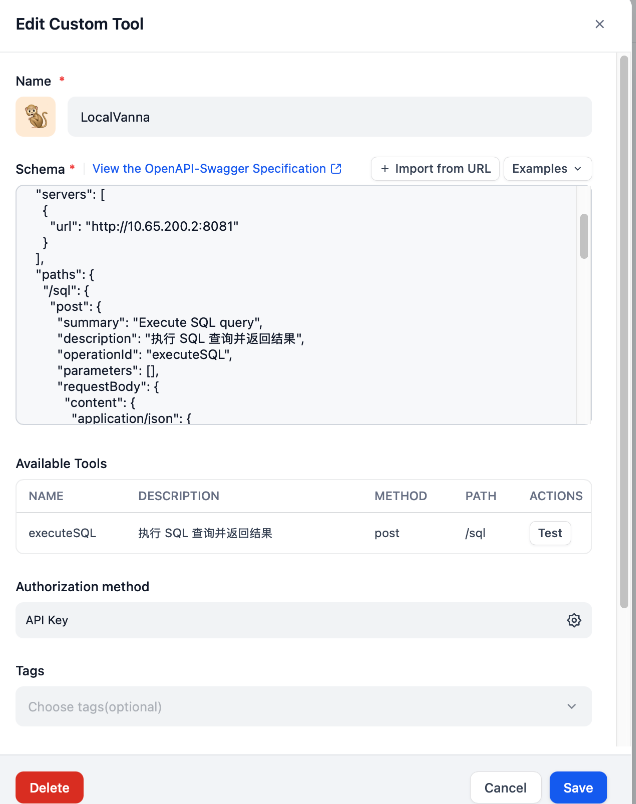
Schema
{ \"openapi\": \"3.1.0\", \"info\": { \"title\": \"SQL Query Execution API\", \"description\": \"Executes SQL queries and returns the results.\", \"version\": \"v1.0.0\" }, \"servers\": [ { \"url\": \"http://127.0.0.1:8081\" #这里填之前vanna封装成openApi的接口 } ], \"paths\": { \"/sql\": { \"post\": { \"summary\": \"Execute SQL query\", \"description\": \"执行 SQL 查询并返回结果\", \"operationId\": \"executeSQL\", \"parameters\": [], \"requestBody\": { \"content\": { \"application/json\": { \"schema\": { \"type\": \"object\", \"properties\": { \"sql\": { \"type\": \"string\", \"description\": \"The SQL query to execute.\" } }, \"required\": [\"sql\"] } } } }, \"responses\": { \"200\": { \"description\": \"Successful response\", \"content\": { \"application/json\": { \"schema\": { \"type\": \"string\", \"description\": \"The result of the SQL query.\" } } } }, \"403\": { \"description\": \"Invalid Authorization header\" }, \"400\": { \"description\": \"No SQL query provided\" } }, \"security\": [ { \"bearerAuth\": [] } ] } } }, \"components\": { \"securitySchemes\": { \"bearerAuth\": { \"type\": \"http\", \"scheme\": \"bearer\", \"bearerFormat\": \"JWT\" } } }}授权方法配置
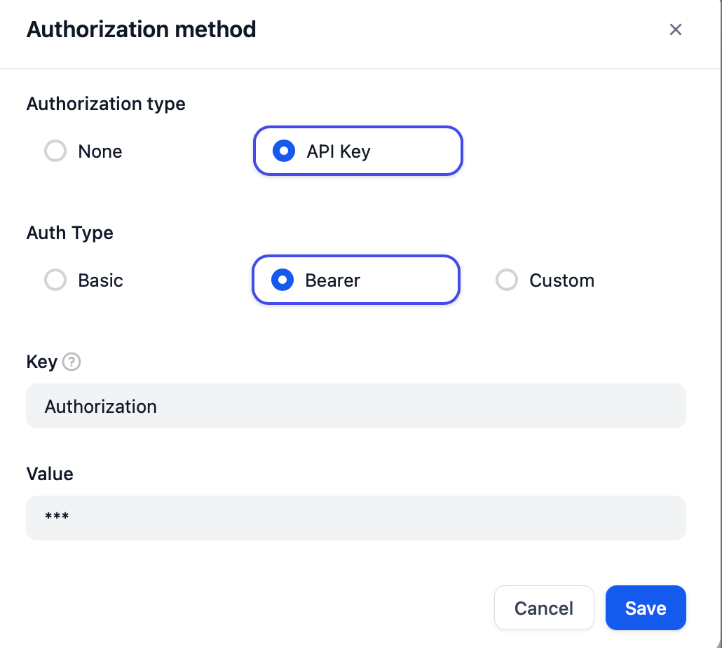
这里Value值填sql
保存后就可以在工作流中使用了

效果展示