博查AI Web Search API 使用指南:全网搜索网页与图片信息_博查api
博查AI Web Search API 使用指南:全网搜索网页与图片信息
- 一、博查搜索 API 简介
- 二、快速开始
-
- 1. 获取API密钥
- 2. 基础搜索示例(Python)
- 三、API 使用详解
-
- 1. API接口
- 2. Request
-
- 请求方式
- 请求头 HEADER
- 请求体 BODY
- 2. Responses
-
- 2.1 整体响应结构
- 2.2 QueryContext 结构
- 2.3 WebPages 结构
-
- 2.3.1 WebPageValue 结构
- 2.4 Images 结构
-
- 2.4.1 ImageValue 结构
- 2.5 Videos 结构(当前版本暂未开放)
- 2.6 调用示例
- 3. 高级搜索场景
-
- 1. 带摘要的近期新闻
- 2. 特定网站搜索
- 3. 排除特定网站
- 四、错误处理
-
- 1. 常见错误码及解决方案
- 五、最佳实践
-
- 1. 结果分页处理
- 2. 时间敏感内容处理
- 3. 多网站联合搜索
- 六、常见问题
-
- Q1:为什么返回的结果数量少于请求的count值?
- Q2:dateLastCrawled字段的时间格式如何处理?
- Q3:如何提升搜索结果相关性?
一、博查搜索 API 简介
博查AI Web Search API 是一个强大的全网搜索引擎接口,专为开发者和AI系统设计。

它能从近百亿网页中精准检索信息,提供网页、图片等丰富搜索结果,具有以下核心优势:
- 结果准确:智能算法过滤低质量内容;
- 摘要完整:提供AI友好的结构化摘要;
- 参数灵活:支持时间范围、网站过滤等高级搜索;
- 响应快速:平均响应时间<1秒;
二、快速开始
1. 获取API密钥
-
访问 博查AI开放平台,点击「使用搜索API」。
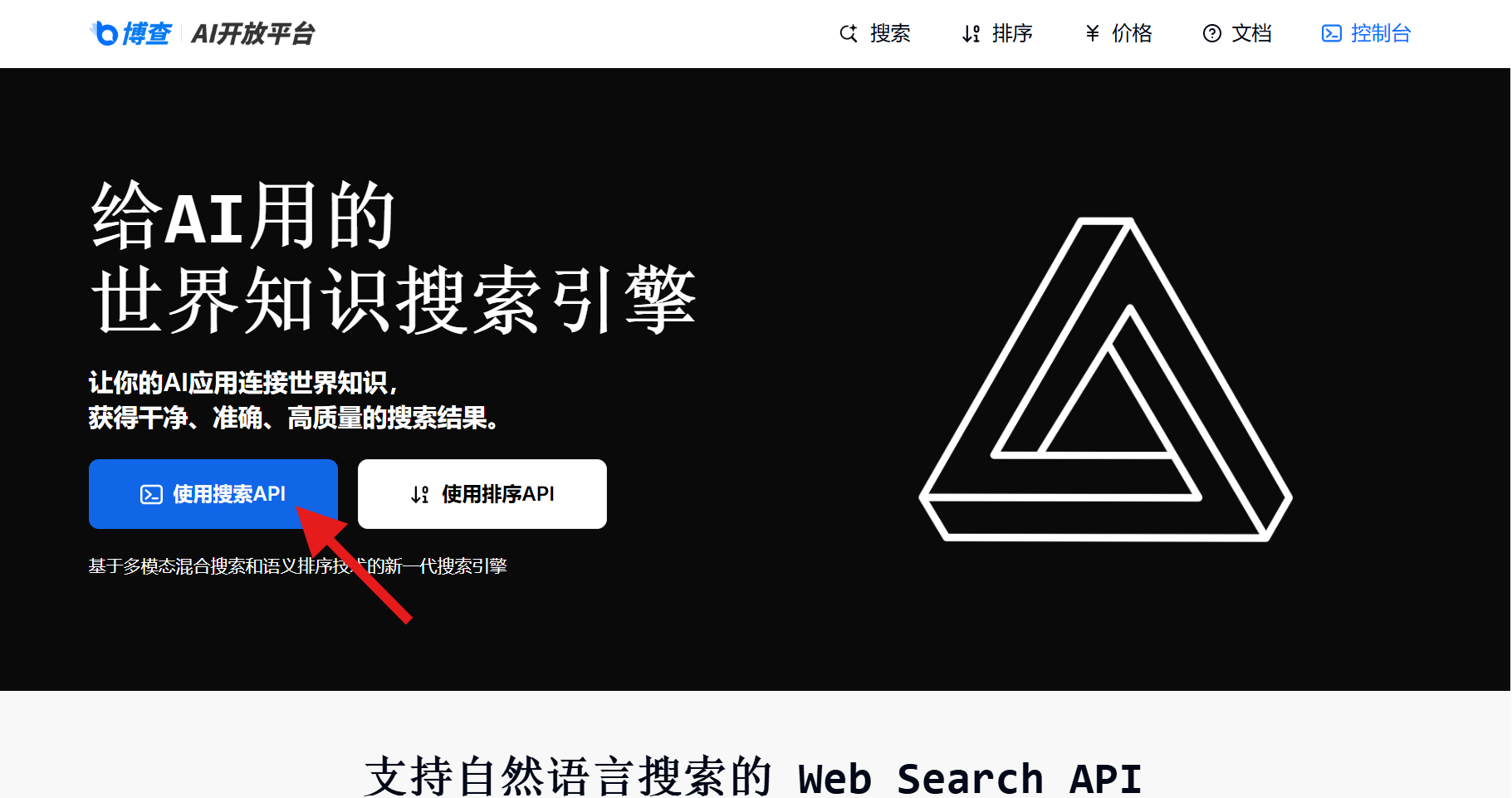
-
注册/登录账号。
-
进入「API KEY管理」页面,点击「创建 API KEY」快速创建密钥。
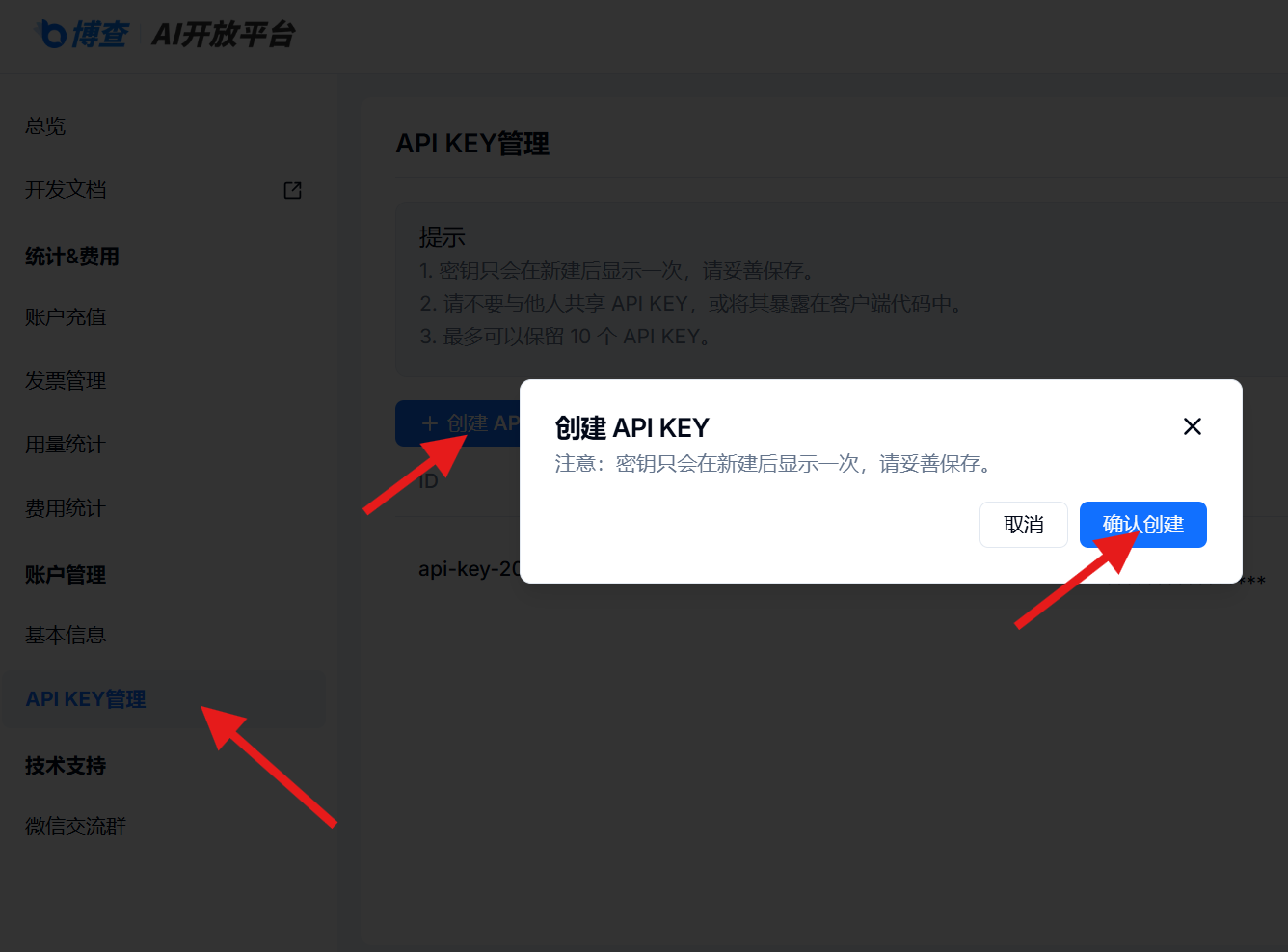
2. 基础搜索示例(Python)
点击即可快速使用Bocha Web Search API
import requestsimport jsonurl = \"https://api.bochaai.com/v1/web-search\"api_key = \"sk-********\" # 替换为您的实际API密钥payload = json.dumps({ \"query\": \"人工智能最新进展\", \"summary\": True, # 启用详细摘要 \"count\": 5 # 返回5条结果})headers = { \'Authorization\': f\'Bearer {api_key}\', \'Content-Type\': \'application/json\'}response = requests.post(url, headers=headers, data=payload)results = response.json()# 打印第一条结果first_result = results[\'data\'][\'webPages\'][\'value\'][0]print(f\"标题: {first_result[\'name\']}\")print(f\"链接: {first_result[\'url\']}\")print(f\"摘要: {first_result[\'summary\']}\")三、API 使用详解
1. API接口
接口域名:https://api.bochaai.com
EndPoint:https://api.bochaai.com/v1/web-search
2. Request
请求方式
POST
请求头 HEADER
AuthorizationContent-Type请求体 BODY
querycountsummarytrue,显示false,不显示falsefreshnessnoLimit:不限(默认)oneDay:一天内 oneWeek:一周内 oneMonth:一个月内 oneYear:一年内 YYYY-MM-DD..YYYY-MM-DD:日期范围 YYYY-MM-DD:指定日期noLimitinclude|或,分隔,最多不能超过20个。可填值:根域名、子域名
例:qq.com|m.163.com
exclude|或,分隔,最多不能超过20个。可填值:根域名、子域名
例:qq.com|m.163.com
2. Responses
2.1 整体响应结构
_typequeryContextwebPagesimagesvideos2.2 QueryContext 结构
originalQuery2.3 WebPages 结构
webSearchUrltotalEstimatedMatchesvaluesomeResultsRemoved2.3.1 WebPageValue 结构
idnameurldisplayUrlsnippetsummarysiteNamesiteIcondatePublisheddateLastCrawledcachedPageUrllanguageisFamilyFriendlyisNavigational时间字段说明:
请优先使用datePublished字段获取正确的 UTC+8 时间。
如需使用dateLastCrawled,请将其中的 “Z” 替换为 “+08:00” 获得正确时间
2.4 Images 结构
idreadLinkwebSearchUrlisFamilyFriendlyvalue2.4.1 ImageValue 结构
webSearchUrlnamethumbnailUrldatePublishedcontentUrlhostPageUrlcontentSizeencodingFormathostPageDisplayUrlwidthheightthumbnail2.5 Videos 结构(当前版本暂未开放)
idreadLinkwebSearchUrlisFamilyFriendlyscenariovalue2.6 调用示例
- Request BODY
{ \"query\": \"阿里巴巴2024年的esg报告\", \"freshness\": \"noLimit\", \"summary\": true, \"count\": 50}- 成功响应(HTTP 200):
{ \"code\": 200, \"log_id\": \"d71841ad20095f61\", \"msg\": null, \"data\": { \"_type\": \"SearchResponse\", \"queryContext\": { \"originalQuery\": \"阿里巴巴2024年的esg报告\" }, \"webPages\": { \"webSearchUrl\": \"\", \"totalEstimatedMatches\": 8912791, \"value\": [ { \"id\": null, \"name\": \"阿里巴巴发布2024年ESG报告 持续推进减碳与数字化普惠\", \"url\": \"https://www.alibabagroup.com/document-1752073403914780672\", \"displayUrl\": \"https://www.alibabagroup.com/document-1752073403914780672\", \"snippet\": \"阿里巴巴集团发布《2024财年环境、社会和治理(ESG)报告》(下称“报告”),详细分享过去一年在ESG各方面取得的进展。报告显示,阿里巴巴扎实推进减碳举措,全集团自身运营净碳排放和价值链碳...\", \"siteName\": \"www.alibabagroup.com\", \"siteIcon\": \"https://th.bochaai.com/favicon?domain_url=https://www.alibabagroup.com/document-1752073403914780672\", \"dateLastCrawled\": \"2024-07-22T00:00:00Z\", \"cachedPageUrl\": null, \"language\": null, \"isFamilyFriendly\": null, \"isNavigational\": null }, ... ], \"someResultsRemoved\": true }, \"images\": { \"id\": null, \"readLink\": null, \"webSearchUrl\": null, \"value\": [ { \"webSearchUrl\": null, \"name\": null, \"thumbnailUrl\": \"http://dayu-img.uc.cn/columbus/img/oc/1002/45628755e2db09ccf7e6ea3bf22ad2b0.jpg\", \"datePublished\": null, \"contentUrl\": \"http://dayu-img.uc.cn/columbus/img/oc/1002/45628755e2db09ccf7e6ea3bf22ad2b0.jpg\", \"hostPageUrl\": \"https://mparticle.uc.cn/article_org.html?uc_param_str=frdnsnpfvecpntnwprdssskt#!wm_cid=632457937121448960!!wm_id=b3f0578cbbd8434da8e437702e399f91\", \"contentSize\": null, \"encodingFormat\": null, \"hostPageDisplayUrl\": \"https://mparticle.uc.cn/article_org.html?uc_param_str=frdnsnpfvecpntnwprdssskt#!wm_cid=632457937121448960!!wm_id=b3f0578cbbd8434da8e437702e399f91\", \"width\": 553, \"height\": 311, \"thumbnail\": null }, ... ], \"isFamilyFriendly\": null }, \"videos\": null }}3. 高级搜索场景
1. 带摘要的近期新闻
results = client.web_search( query=\"人工智能突破\", summary=True, freshness=\"oneDay\", # 24小时内 count=3)2. 特定网站搜索
results = client.web_search( query=\"深度学习\", include=\"csdn.net|zhihu.com\", # 包含CSDN和知乎搜索 count=5)3. 排除特定网站
results = client.web_search( query=\"Python教程\", exclude=\"baidu.com\", # 排除百度内容 count=8)四、错误处理
1. 常见错误码及解决方案
Missing parameter query,The API KEY is missingInvalid API KEYYou do not have enough moneyYou have reached the request limit错误响应示例:
{ \"code\": 401, \"message\": \"Invalid API KEY\", \"log_id\": \"c66aac17eab1bb7e\"}五、最佳实践
1. 结果分页处理
import requestsimport jsonurl = \"https://api.bochaai.com/v1/web-search\"def get_search_results(query, page=1, per_page=10): offset = (page - 1) * per_page payload = json.dumps({ \"query\": query, \"summary\": True, \"count\": per_page # 实际分页需结合totalEstimatedMatches }) headers = { \'Authorization\': \'Bearer sk-********\', \'Content-Type\': \'application/json\' } return requests.request(\"POST\", url, headers=headers, data=payload)2. 时间敏感内容处理
from datetime import datetime, timedeltaimport json# 自动计算最近两周end_date = datetime.now().strftime(\"%Y-%m-%d\")start_date = (datetime.now() - timedelta(days=14)).strftime(\"%Y-%m-%d\")payload = json.dumps({ \"query\": \"科技新闻\", \"freshness\": f\"{start_date}..{end_date}\"})3. 多网站联合搜索
import jsontech_sites = \"csdn.net|jianshu.com|zhihu.com|segmentfault.com\"payload = json.dumps({ \"query\":\"机器学习实践\", \"include\": tech_sites, \"summary\": True, \"count\": 15})六、常见问题
Q1:为什么返回的结果数量少于请求的count值?
A:当搜索结果不足或内容质量不符合要求时,系统会自动过滤低质量结果。
Q2:dateLastCrawled字段的时间格式如何处理?
接口中返回的dateLastCrawled值(例如:2025-02-23T08:18:30Z)实际上要表达的是 UTC+8 北京时间2025-02-23 08:18:30,并非UTC时间。
实际应用中请使用 datePublished 字段,或将\"2025-02-23T08:18:30Z\"替换成\"2025-02-23T08:18:30+08:00\",即得到正确的UTC+8时间,可以使用 datetime 函数正确解析。
这个问题将在v2版本中修复。
from datetime import datetime, timezone# 示例接口返回值date_str = \"2025-02-23T08:18:30Z\"# 1. 转换时区标识corrected_str = date_str.replace(\"Z\", \"+08:00\")# 2. 解析为datetime对象 (Python 3.7+ 支持)dt = datetime.fromisoformat(corrected_str)print(\"解析结果:\", dt) # 2025-02-23 08:18:30+08:00print(\"时区:\", dt.tzinfo) # UTC+08:00# 3. 可选:转换为UTC时间utc_time = dt.astimezone(timezone.utc)print(\"UTC时间:\", utc_time) # 2025-02-23 00:18:30+00:00Q3:如何提升搜索结果相关性?
建议:
- 使用更具体的关键词
- 添加时间范围限制
- 使用网站过滤功能
- 开启摘要生成(summary=true)
更多技术问题请访问博查官方或联系support@bochaai.com

立即体验强大搜索能力:前往博查AI开放平台
本文档更新于2025年7月,适用于Web Search API v1版本

