Day08-python数据操作进阶(二)_函数等于方法吗
目录
- 前言
- 一、函数和方法的区别
- 二、浅拷贝和深拷贝
- 三、数值类数据常用函数和方法
- 四、字符串常用函数和方法
- 五、列表常用函数和方法
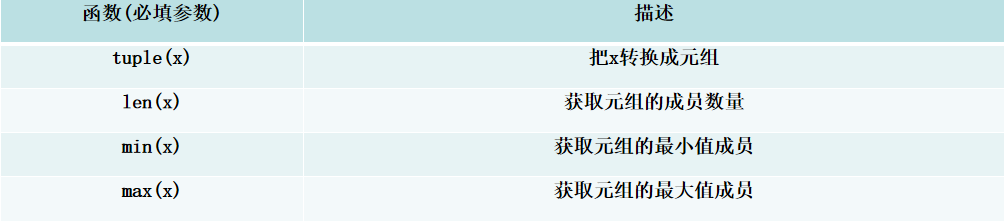
- 六、元组常用函数和方法
- 七、集合常用函数和方法
- 八、字典常用函数和方法
- 总结
前言
今天学习使用函数和方法对数据进行进阶操作。
一、函数和方法的区别
函数(Function)和方法(Method)是两个容易混淆的概念,它们的核心区别在于是否与特定对象关联。
- 函数(Function)是独立定义的代码块,不依附于任何类或对象,通过函数名直接调用。
\'\'\'函数使用时直接用函数名调用\'\'\'def sum_num(a, b): # 独立函数,不属于任何类 return a + b# 直接调用,无需关联对象print(sum_num(2, 3)) # 输出:5- 方法(Method)是定义在类内部的函数,必须依附于类或实例对象,调用时需要通过类或实例触发。 方法的第一个参数通常是
self(实例方法)或cls(类方法),用于关联调用者。
\'\'\'方法必须通过实例(对象.方法名())或类(类名.方法名())调用\'\'\'class MathTool: def multiply(self, a, b): # 实例方法,属于MathTool类 return a * b# 必须通过实例调用tool = MathTool()print(tool.multiply(2, 3)) # 输出:6
- 函数只能访问传入的参数或全局变量,无法直接操作对象的属性。
- 方法可以通过 self 访问所属实例的属性和其他方法,直接操作对象内部状态。
二、浅拷贝和深拷贝
python中为变量赋值使用的是引用赋值,与变量绑定的是内存地址空间,当两个变量同时指向一个内存地址空间时,如果空间内保存的是可变容器对象,对其中一个变量进行修改操作,会导致另一个变量的数据也随之发生变化。
list1 = [1, 2, 3] # 原始列表list2 = list1 # 引用赋值(list2指向list1的内存地址)list2.append(4) # 修改list2print(list1) # 输出 [1, 2, 3, 4](list1也被改变)print(list2) # 输出 [1, 2, 3, 4]为了控制对象复制的程度,以满足不同场景下对数据独立性的需求,需要使用浅拷贝和深拷贝。
- 浅拷贝: 只拷贝外层列表,内层列表跟随原列表进行改变。
copy.copy(变量)或者变量.copy()- 深拷贝: 拷贝整个列表,内外列表都不跟随原列表进行改变。
copy.deepcopy(listvar)
使用场景和价值主要体现在以下几个方面:
- 避免意外修改原对象
当你需要操作一个容器对象(如列表、字典),但又不想修改原始数据时,可以根据数据类型和嵌套情况选择拷贝方式。
例如,函数接收一个列表参数,如果直接修改该列表,会影响函数外部的原始数据。通过拷贝创建副本后再操作,就能避免这种副作用。
- 平衡性能与数据独立性
- 浅拷贝(copy.copy())只复制容器本身,不复制内部嵌套的对象(仅保留引用)。
优点:速度快、内存占用少,适合处理不含嵌套结构或嵌套对象无需独立修改的场景。
例如:复制一个包含基础类型(int、str等)的列表,浅拷贝足以满足需求。
- 深拷贝会递归复制容器及所有嵌套对象,形成完全独立的副本。
优点:确保副本与原对象彻底分离,适合处理包含多层嵌套结构(如列表中的列表、字典中的对象等)的场景。
例如:复制一个复杂的配置项字典(含嵌套字典),需要修改副本而不影响原配置时,必须用深拷贝。
- 处理可变与不可变对象的嵌套
- 若原对象包含可变子对象(如列表中的列表),浅拷贝后修改子对象会影响原对象,此时需要深拷贝来彻底隔离。
- 若仅包含不可变子对象(如列表中的字符串),浅拷贝即可满足需求(因为不可变对象无法被修改)。
- 浅拷贝:适用于简单结构或无需修改嵌套对象的场景,追求效率。
- 深拷贝:适用于复杂嵌套结构,需要完全独立副本的场景,牺牲性能换取数据隔离。
三、数值类数据常用函数和方法
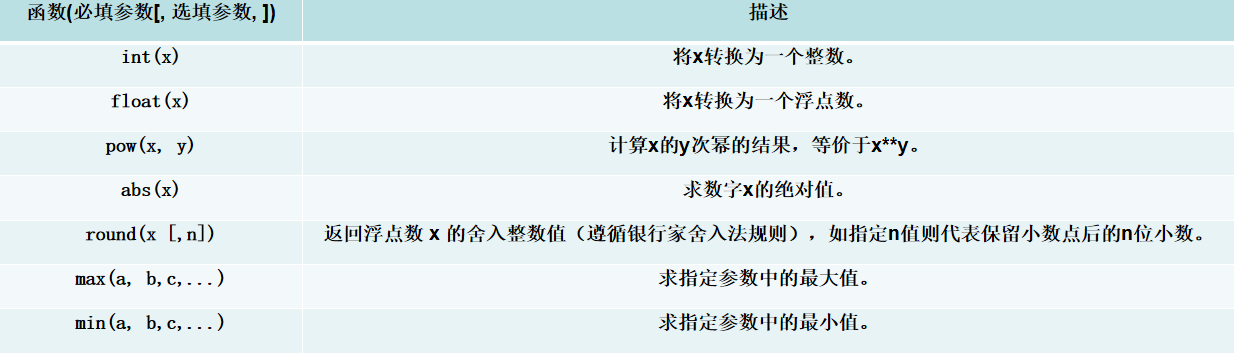
\'\'\'函数使用示例字符串获取最大和最小值规则与字符串比较一致,是比较每个元素的编码\'\'\'print(int(\"123\")) # 输出: 123print(float(42)) # 输出: 42.0print(pow(2, 3)) # 输出: 8print(abs(-5)) # 输出: 5print(round(3.1415, 2)) # 输出: 3.14print(max(1, 5, 3)) # 输出: 5print(max([\"apple\", \"banana\", \"cherry\"])) # 输出: cherryprint(min(1, 5, 3)) # 输出: 1print(min([\"apple\", \"banana\", \"cherry\"])) # 输出: apple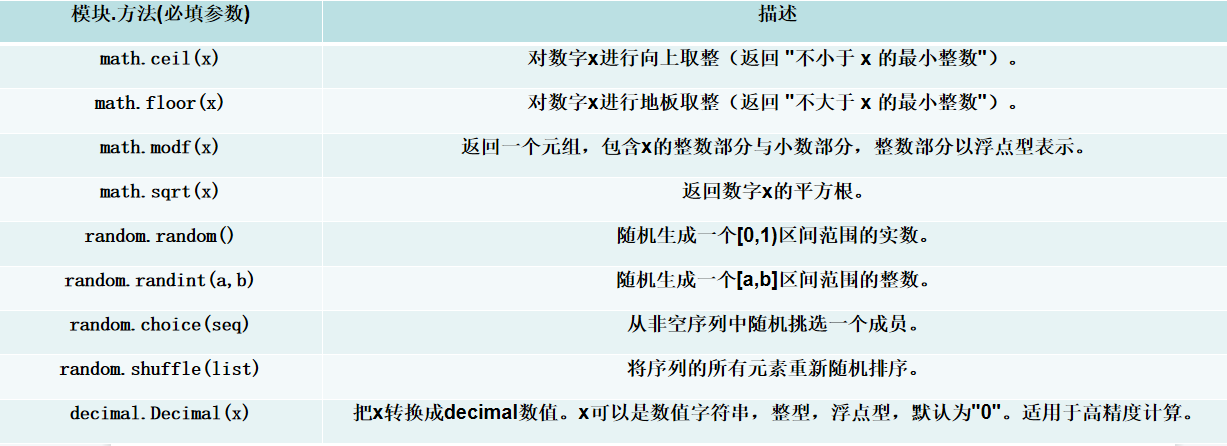
\'\'\'方法使用示例方法使用前需要先导入模块\'\'\'import mathimport randomprint(math.ceil(3.2)) # 输出: 4print(math.ceil(-2.8)) # 输出: -2print(math.floor(-2.2)) # 输出: -3print(math.modf(3.14)) # 输出: (0.14000000000000012, 3.0)print(math.sqrt(16)) # 输出: 4.0print(random.random()) # 输出: 0.5373579497240183 (每次运行结果不同)print(random.randint(1, 10)) # 输出: 5 (每次运行结果可能不同)print(random.choice([\"apple\", \"banana\", \"cherry\"])) # 输出: cherry (每次运行结果可能不同)list1 = [1, 2, 3, 4, 5, 9]random.shuffle(list1)print(list1) # 输出: [1, 4, 9, 2, 3, 5] (每次运行结果可能不同)from decimal import Decimalprint(Decimal(\'0.1\') + Decimal(\'0.2\')) # 输出: 0.3
用print(0.1+0.2)对比下结果
四、字符串常用函数和方法

\'\'\'函数使用示例字符串获取最大和最小值规则是比较每个元素的编码点\'\'\'num = 123456999str_num = str(num)print(type(str_num),str_num) # 输出 123456999print(len(str_num)) # 输出 9# 找出字符串最大和最小print(max([\"apple\", \"banana\", \"cherry\"])) # 输出: cherryprint(min([\"apple\", \"banana\", \"cherry\"])) # 输出: apple# ord()函数转换字符为编码点(字符串长度必须为1)char1 = \'A\'char2 = \'z\'char3 = \'5\'char4 = \' \' # 空格char5 = \'编\' # 中文字符print(f\"\'{char1}\' 的编码:{ord(char1)}\") # 输出:\'A\' 的编码:65print(f\"\'{char2}\' 的编码:{ord(char2)}\") # 输出:\'z\' 的编码:122print(f\"\'{char3}\' 的编码:{ord(char3)}\") # 输出:\'5\' 的编码:53print(f\"空格的编码:{ord(char4)}\") # 输出:空格的编码:32print(f\"\'{char5}\' 的编码:{ord(char5)}\") # 输出:\'编\' 的编码:32534# chr()根据编码点获取对应字符# 生成字母print(chr(65)) # 输出:A(对应大写字母A的编码)print(chr(97)) # 输出:a(对应小写字母a的编码)# 生成数字字符print(chr(48)) # 输出:0(对应数字0的编码)# 生成特殊符号print(chr(33)) # 输出:!(感叹号的编码)print(chr(64)) # 输出:@(@符号的编码)# 生成中文字符print(chr(20013)) # 输出:中(\"中\"字的编码)print(chr(32534)) # 输出:编(\"编\"字的编码)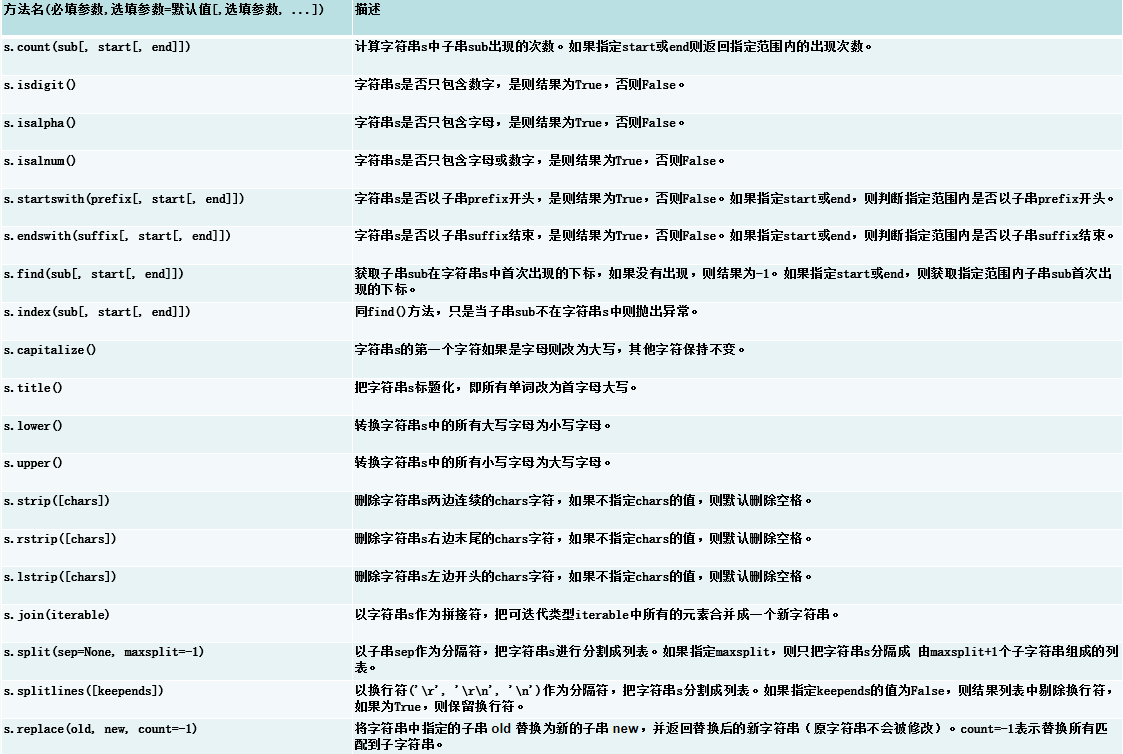
s = \" Hello World! 123 python \" # 原始字符串 , 左右留有数个空格print(s.count(\"o\")) # 统计子串\"o\"出现的次数 → 2print(s.isdigit()) # 判断是否全为数字 → Falseprint(s.isalpha()) # 判断是否全为字母 → Falseprint(s.isalnum()) # 判断是否只包含字母和数字 → Falseprint(s.startswith(\"He\", 2)) # 从索引2开始是否以\"He\"开头 → Trueprint(s.endswith(\"on \")) # 是否以\"on \"结尾 → Trueprint(s.find(\"World\")) # 查找\"World\"首次出现的索引 → 7print(s.index(\"python\")) # 查找\"Python\"首次出现的索引 → 17print(s.capitalize()) # 首字符大写,其余小写 → \" hello world! 123 python \"print(s.title()) # 每个单词首字母大写 → \" Hello World! 123 Python \"print(s.lower()) # 全部转为小写 → \" hello world! 123 python \"print(s.upper()) # 全部转为大写 → \" HELLO WORLD! 123 PYTHON \"print(s.strip()) # 去除首尾空白 → \"Hello World! 123 python\"print(s.rstrip()) # 去除右侧空白 → \" Hello World! 123 python\"print(s.lstrip()) # 去除左侧空白 → \"Hello World! 123 python \"print(s.split()) # 按空白拆分字符串 → [\'Hello\', \'World!\', \'123\', \'python\']print(\"-\".join(s.strip().split())) # 用\"-\"连接拆分后的单词 → \"Hello-World!-123-python\"print(s.splitlines()) # 按行拆分(原数据无换行) → [\' Hello World! 123 python \']print(s.replace(\"World\", \"python\")) # 将\"World\"替换为\"python\" → \" Hello python! 123 python \"五、列表常用函数和方法
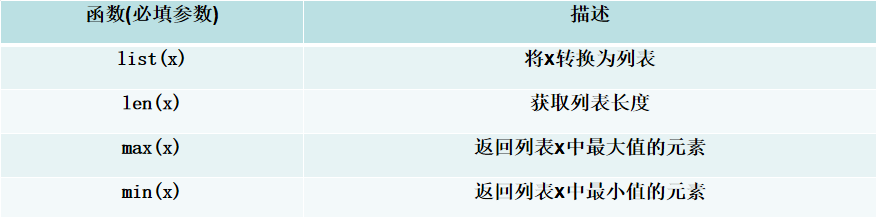
# 定义一个列表my_list = [3, 1, 5, 2, 4, 7, 6]# 1. list(x):将可迭代对象转换为列表# 将元组转换为列表tuple_data = (10, 20, 30)converted_list = list(tuple_data)print(f\"{converted_list}\") # 输出: [10, 20, 30]# 2. len(x):获取列表的长度(元素个数)print(len(my_list)) # 输出:7# 3. max(x):获取列表中的最大值print(max(my_list)) # 输出: 7# 4. min(x):获取列表中的最小值print(min(my_list)) # 输出:1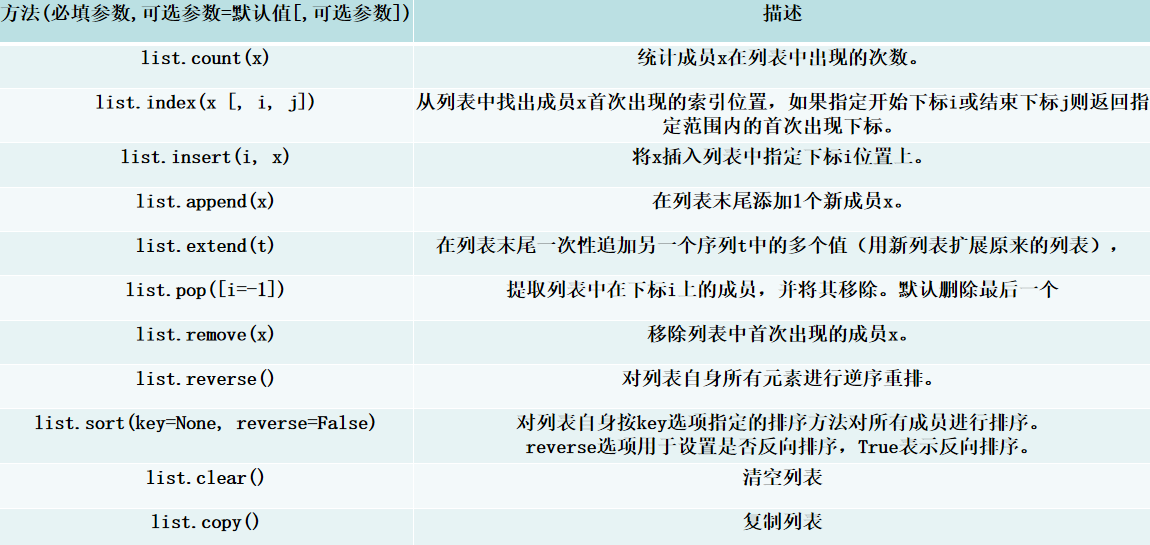
# 初始列表my_list = [3, 1, 5, 2, 3, 6]# count(x):统计元素x出现的次数print(my_list.count(3)) # 统计3出现的次数 2# index(x[, i, j]):返回x在[i,j)范围内首次出现的索引print(my_list.index(3, 2)) # 从索引2开始找3的索引号 4# insert(i, x):在索引i处插入元素xmy_list.insert(2, 10)print(my_list) # 在索引2插入10 → [3, 1, 10, 5, 2, 3, 6]# append(x):在列表末尾添加元素xmy_list.append(7)print(my_list) # 末尾添加7 → [3, 1, 5, 2, 3, 6, 7]# extend(t):用可迭代对象t的元素扩展列表my_list.extend([8, 9])print(my_list) # 扩展列表 → [3, 1, 5, 2, 3, 6, 8, 9]# pop([i=-1]):删除并返回索引i处的元素(默认最后一个)popped = my_list.pop(3)print(my_list) # 删除索引3的元素2 → [3, 1, 5, 3, 6]# remove(x):删除第一个出现的元素xmy_list.remove(3)print(my_list) # 删除第一个3 → [1, 5, 2, 3, 6]# reverse():反转列表元素my_list.reverse()print(my_list) # 反转列表 → [6, 3, 2, 5, 1, 3]# sort(key=None, reverse=False):排序(默认升序)my_list.sort()print(my_list) # 升序排序 → [1, 2, 3, 3, 5, 6]# sort(reverse=True):降序排序my_list.sort(reverse=True)print(my_list) # 降序排序 → [6, 5, 3, 3, 2, 1]# copy():复制列表(浅拷贝)new_list = my_list.copy()print(new_list) # 复制得到新列表 → [3, 1, 5, 2, 3, 6]# clear():清空列表my_list.clear()print(my_list) # 清空列表 → []六、元组常用函数和方法
# 定义一个元组my_tuple = (5, 2, 8, 1, 9, 3)list_data = [10, 20, 30]# 1. tuple(x):将可迭代对象转换为元组# 将列表转换为元组converted_tuple = tuple(list_data)print(converted_tuple) # 输出:(10, 20, 30)# 2. len(x):获取元组的长度(元素个数)print(len(my_tuple)) # 输出:6(元组包含6个元素)# 3. min(x):获取元组中的最小值print(min(my_tuple)) # 输出:1(元组中最小的元素)# 4. max(x):获取元组中的最大值print(max(my_tuple)) # 输出:9(元组中最大的元素)
# 定义一个元组my_tuple = (3, 1, 5, 3, 7, 3, 9)# tuple.count(x):统计元素x在元组中出现的次数count_3 = my_tuple.count(3)print(count_3) # 输出 3 # tuple.index(x):返回元素x在元组中首次出现的索引first_index_3 = my_tuple.index(3)print(first_index_3) # 输出 0 # tuple.index(x, i):从索引i开始查找x首次出现的位置index_from_2 = my_tuple.index(3, 2) # 从索引2开始查找3print(index_from_2) # 输出 3 # tuple.index(x, i, j):在[i, j)范围内查找x首次出现的位置index_between_4_6 = my_tuple.index(3, 4, 6) # 在索引4到6(不包含6)之间查找3print(index_between_4_6) # 输出 5 七、集合常用函数和方法
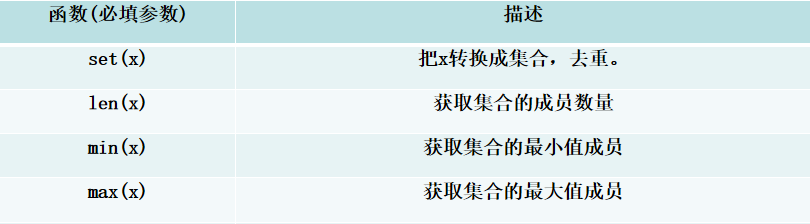
# 定义1个集合my_set = {5, 2, 8, 1, 9, 3}# 1. set(x):将可迭代对象转换为集合(会自动去重)list_data = [3, 5, 7, 3, 9] # 列表包含重复元素converted_set = set(list_data)print(converted_set) # 输出:{3, 5, 7, 9}(自动去重)# 2. len(x):获取集合的元素个数print(len(my_set)) # 输出:6(集合包含6个元素)# 3. min(x):获取集合中的最小值print(min(my_set)) # 输出:1(集合中最小的元素)# 4. max(x):获取集合中的最大值print(max(my_set)) # 输出:9(集合中最大的元素)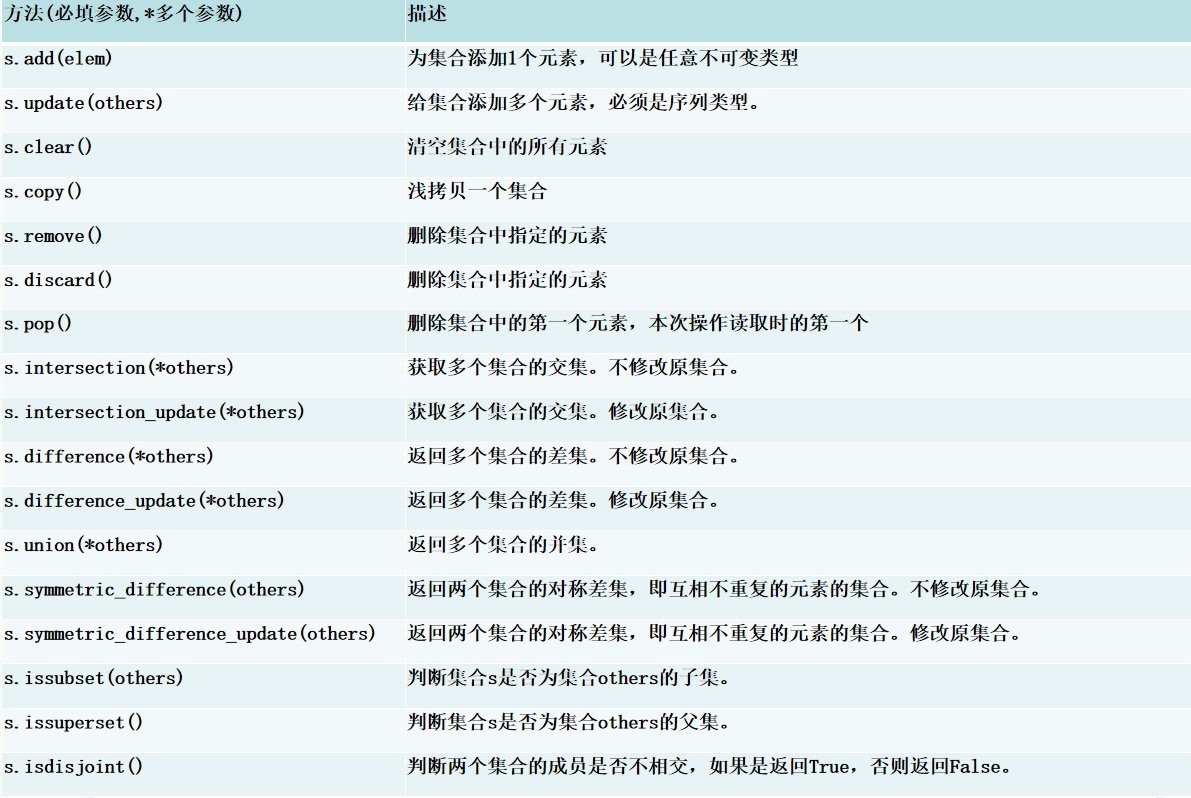
# 定义2个集合base_set = {1, 2, 3, 4, 5}other_set = {4, 5, 6, 7, 8} # 用于集合关系操作的对比集合# 1. add(elem):添加元素base_set.add(6)print(set1) # {1, 2, 3, 4, 5, 6}# 2. update(others):添加多个元素base_set.update([6, 7, 8])print(set2) # {1, 2, 3, 4, 5, 6, 7, 8}# 3. clear():清空集合base_set.clear()print(set3) # set()# 4. copy():复制集合copy_set = base_set.copy()print(copy_set) # {1, 2, 3, 4, 5}# 5. remove(elem):删除指定元素(元素存在)base_set.remove(3)print(base_set) # {1, 2, 4, 5}# 6. discard(elem):删除指定元素(元素不存在也不报错)base_set.discard(6) # 6不存在,无操作print(base_set) # {1, 2, 3, 4, 5}# 7. pop():随机删除并返回一个元素base_set.pop()print(base_set) # 如: {2, 3, 4, 5}# 8. intersection(*others):返回交集intersection_result = base_set.intersection(other_set)print(intersection_result) # {4, 5}# 9. intersection_update(*others):交集更新(原地)base_set.intersection_update(other_set)print(base_set) # {4, 5}# 10. difference(*others):返回差集difference_result = base_set.difference(other_set)print(difference_result) # {1, 2, 3}# 11. difference_update(*others):差集更新(原地)base_set.difference_update(other_set)print(base_set) # {1, 2, 3}# 12. union(*others):返回并集union_result = base_set.union(other_set)print(union_result) # {1, 2, 3, 4, 5, 6, 7, 8}# 13. symmetric_difference(others):返回对称差集sym_diff_result = base_set.symmetric_difference(other_set)print(sym_diff_result) # {1, 2, 3, 6, 7, 8}# 14. symmetric_difference_update(others):对称差集更新(原地)base_set.symmetric_difference_update(other_set)print(base_set) # {1, 2, 3, 6, 7, 8}# 15. issubset(others):判断是否为子集is_subset =base_set.issubset({1, 2, 3, 4, 5, 6})print(is_subset) # True# 16. issuperset(others):判断是否为超集is_superset = base_set.issuperset({1, 2, 3})print(is_superset) # True# 17. isdisjoint(others):判断是否无交集is_disjoint = base_set.isdisjoint({6, 7, 8, 9})print(is_disjoint) # True八、字典常用函数和方法
# 学生成绩字典scores = {\'小明\': 92, \'小红\': 88, \'小刚\': 95, \'小丽\': 85}print(\"学生成绩字典:\", scores)# 1. dict(x):将可迭代对象转换为字典# 从包含键值对的列表创建新的成绩记录new_scores = [(\'小芳\', 90), (\'小强\', 89)]added_scores = dict(new_scores)print(added_scores) # 输出:{\'小芳\': 90, \'小强\': 89}# 合并到原字典(示例)scores.update(added_scores)print(scores) # 包含6名学生成绩# 2. len(x):获取字典中键值对的数量(即学生人数)print(len(scores)) # 输出:4# 3. min(x):默认获取最小的键(学生姓名,按Unicode排序)print(min(scores)) # 输出:小丽# 4. max(x):默认获取最大的键(学生姓名,按Unicode排序)print(max(scores)) # 输出:小红# 扩展:获取最高分成绩max_score = max(scores.values())# 查找最高分对应的学生max_student = [name for name, score in scores.items() if score == max_score]print(f\"最高分: {max_score},获得者: {max_student}\") # 输出:最高分: 95,获得者: [\'小刚\']
# 基础学生成绩字典base_scores = {\'小明\': 92, \'小红\': 88, \'小刚\': 95, \'小丽\': 85}# 1. clear():清空字典base_scores.clear()print(base_scores) # 输出:{}# 2. copy():复制字典scores2 = base_scores.copy()print(scores2) # 输出:{\'小明\': 92, \'小红\': 88, \'小刚\': 95, \'小丽\': 85}print(\" 复制的字典与原字典是否相同:\", scores2 == base_scores) # 输出:Trueprint(\" 复制的字典与原字典是否为同一对象:\", scores2 is base_scores) # 输出:False# 3. fromkeys(iterable, value=None):创建新字典(类方法)new_students = [\'小芳\', \'小强\']scores3 = dict.fromkeys(new_students, 0) # 新学生初始分数为0print(scores3) # 输出:{\'小芳\': 0, \'小强\': 0}# 4. get(key, default=None):获取键对应的值,不存在则返回默认值print(base_scores.get(\'小刚\')) # 输出:95print(base_scores.get(\'小芳\', \'未找到\')) # 输出:未找到# 5. setdefault(key, default=None):获取值,不存在则添加键值对print(base_scores.setdefault(\'小丽\')) # 输出:85(已存在)print(base_scores.setdefault(\'小芳\', 90)) # 输出:90(新增)# 6. keys():返回所有键print(base_scores.keys()) # 输出:dict_keys([\'小明\', \'小红\', \'小刚\', \'小丽\'])# 7. values():返回所有值print(base_scores.values()) # 输出:dict_values([92, 88, 95, 85])# 8. items():返回所有键值对print(base_scores.items()) # 输出:dict_items([(\'小明\', 92), (\'小红\', 88), (\'小刚\', 95), (\'小丽\', 85)])# 9. update(dict2):更新字典(添加/覆盖键值对)base_scores.update({\'小明\': 93, \'小芳\': 90}) # 覆盖小明成绩,新增小芳print(base_scores) # 小明分数变为93,新增\'小芳\':90# 10. pop(key[, default]):删除并返回指定键的值pop_result = base_scores.pop(\'小红\')print(pop_result) # 输出:88print(base_scores) # 已移除\'小红\'# 11. popitem():返回并删除最后一组键值对popitem_result = base_scores.popitem()print(popitem_result) # 输出:(\'小丽\', 85)(最后一组键值对)print(base_scores) # 已移除\'小丽\'总结
今天内容中初学者容易弄错的点有以下几个:
- 方法使用前要先导入模块,不是内置模块需要单独下载安装,如果用不到模块包含的所有方法,可以指定导入模块中的某个方法,降低程序运行消耗。
round函数处理部分小数时由于精度问题,会与实际看到的不一样,导致结果与预期不同,如果需要特别精确,建议使用decimal方法。ord()处理对象必须是单个字符(长度为 1 的字符串),常用于字符编码转换、密码学、文本处理等场景,例如判断字符类型(字母 / 数字 / 符号)、字符加密等。- 字符串的查找、替换等操作都对大小写敏感,使用时注意数据大小写格式。
capitalize()处理的是字符串的第一个字符,且第一个字符要是字母才会起作用。- 除了
copy()方法会返回新列表,表格中其他对列表修改的方法都是在原列表直接修改 - 列表添加或者删除数据时,操作数据之后的元素索引都会发生变化,多次添加、删除操作建议从后往前操作。
演示代码块里的范例为了节省空间,定义了一个变量,每个函数或者方法对变量的操作都是独立搭配运行,不要直接全部拷贝到开发工具中运行查看,否则会出现上一个函数或方法执行完后变量发生变化,下一个函数或方法执行后得到的结果与注释不同。
感谢骆昊老师和墨落老师,本文中部分描述及图片引用自老师的公开课程中的资料


