【生成式AI導論 2024】第6講:大型語言模型修練史 — 第3个 階段 学习记录
第一階段: 自我學習,累積實力
学习(SFT)
- 数据清洗
- 过滤有害信息
- 清除项目符号
- 采用GPT-3/PaLM质量分类器进行数据筛选
- 高质量内容在训练集中会被多次复用
- 剔除低质量数据
- 去除重复内容(如广告)
语言模型根据网络资料学了很多东西,却不知道使用方法
就好像有上乘内功,却不知道使用的方法
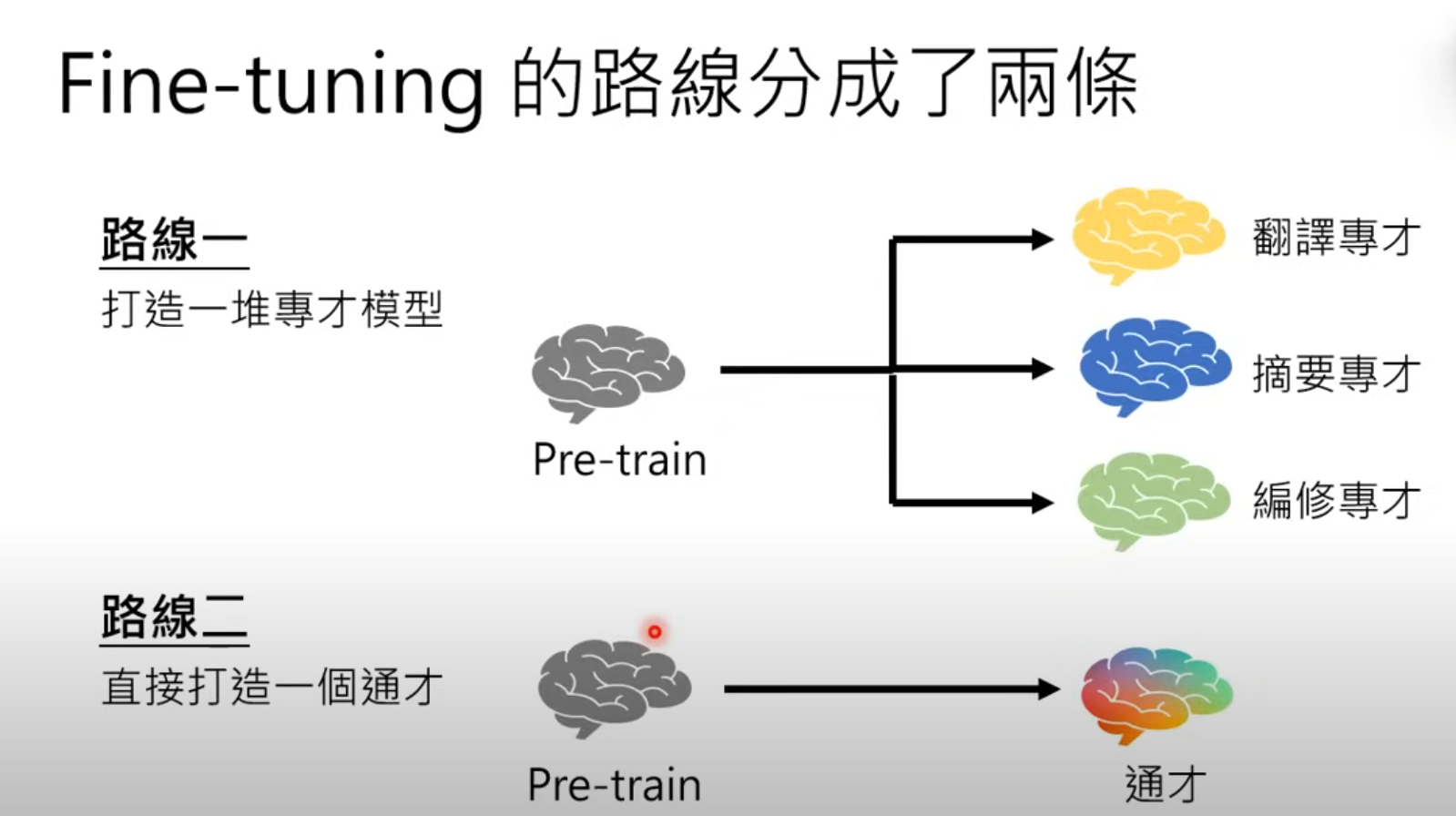
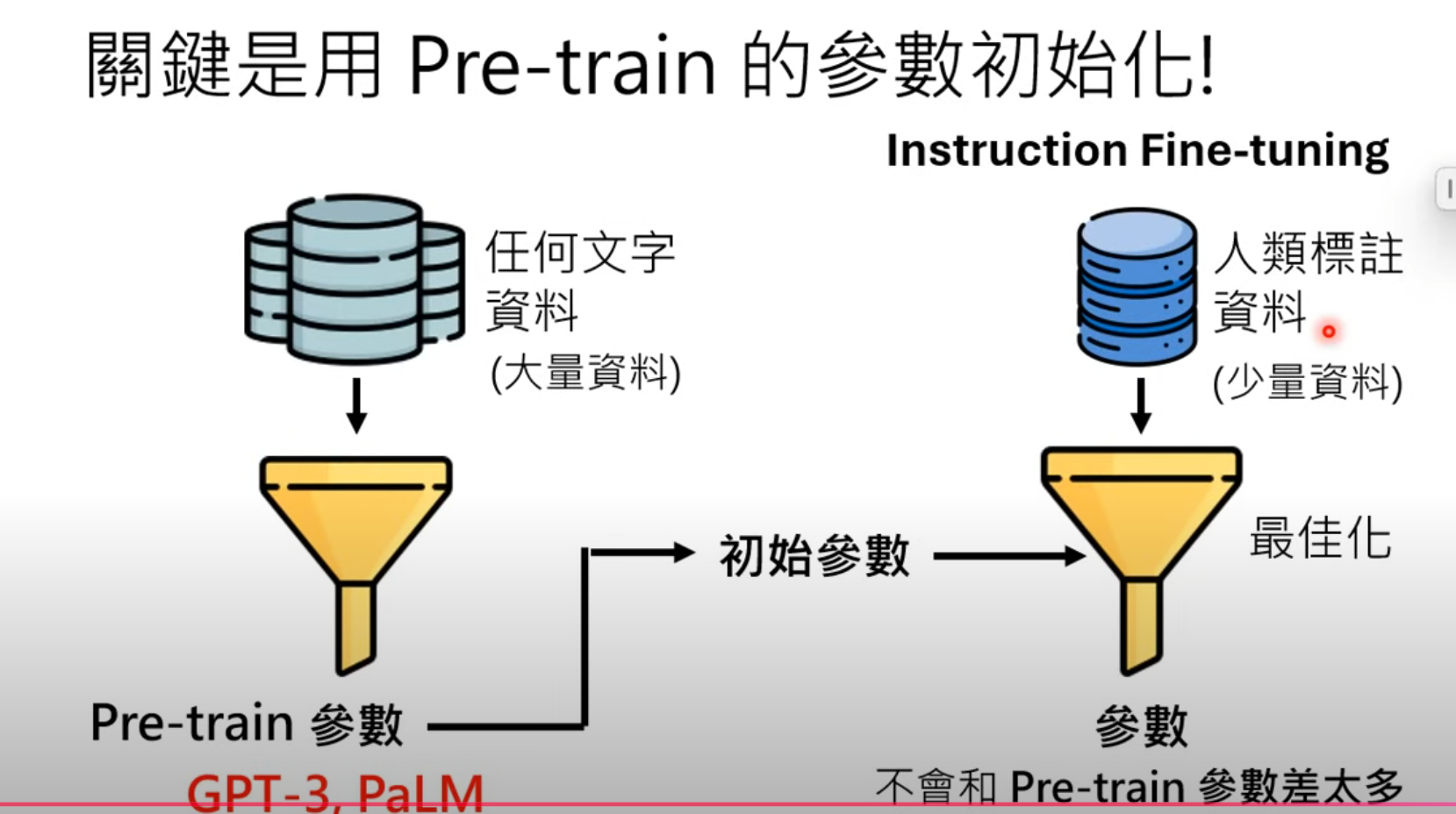
第二階段: 名師指點,發揮潛力
关键:初始参数
Adapter 和 LoRA
可以举一反三的能力
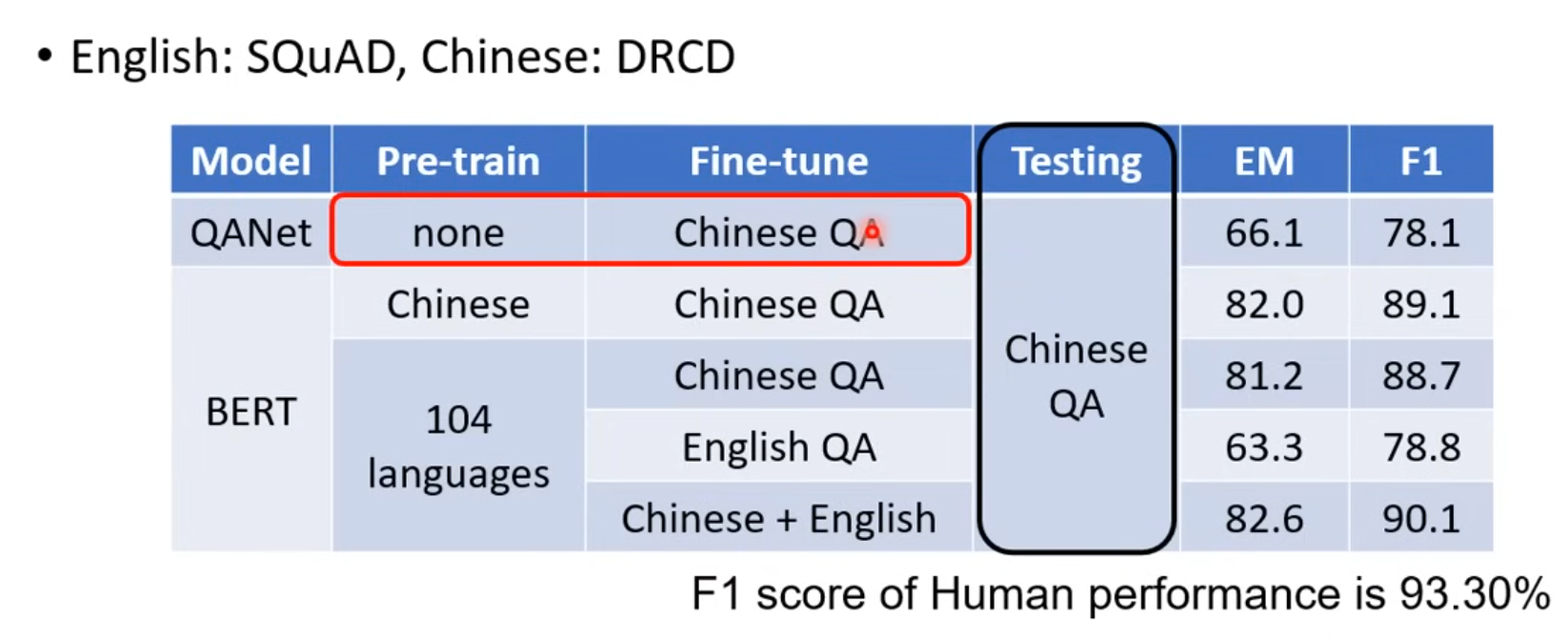

instruct GPT
LLaMA2
fine-tuning 是画龙点睛
对chatgpt做逆向工程
self-instruct
Self-Instruct: Aligning Language Models with Self-Generated Instructions
The False Promise of Imitating Proprietary LLMs
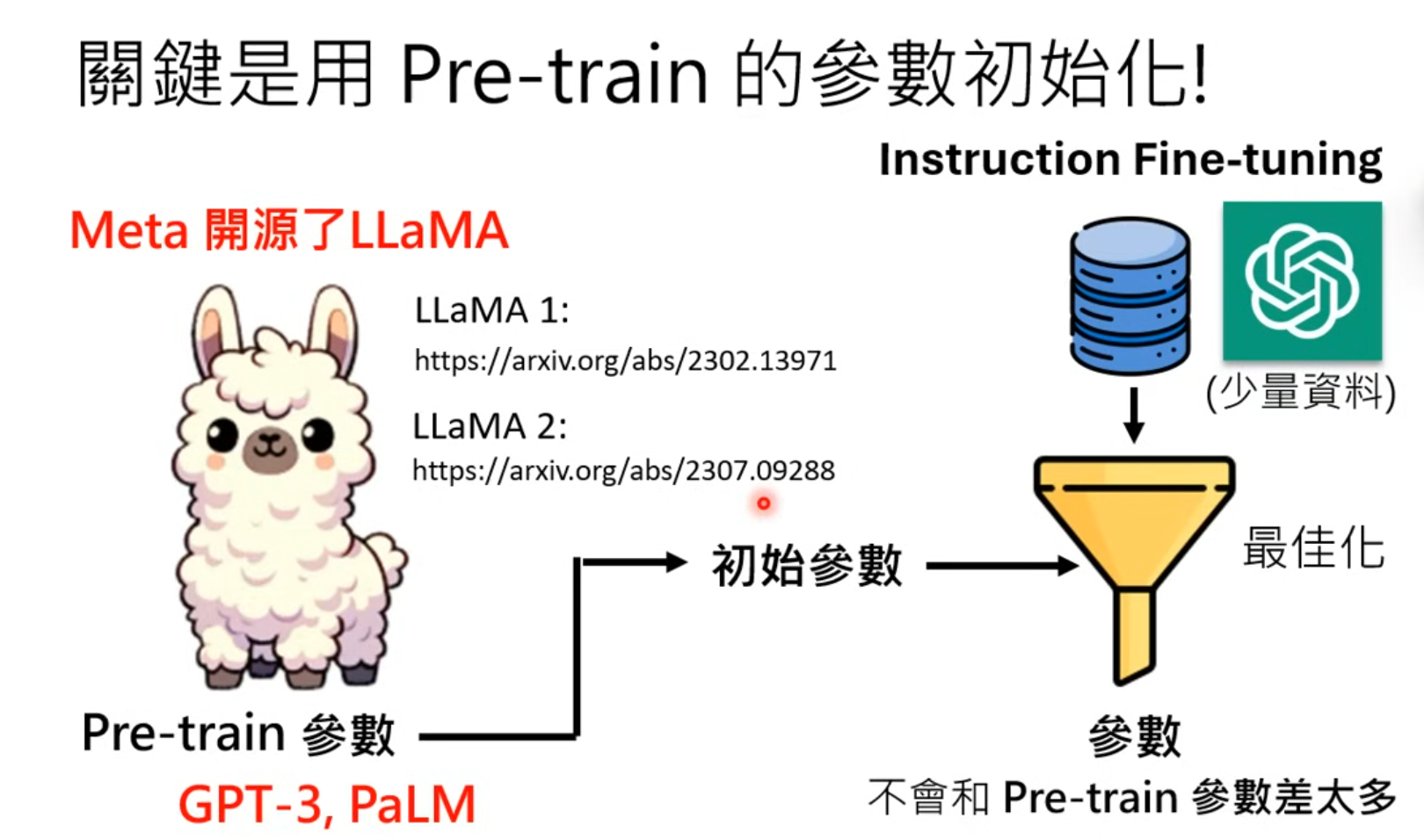

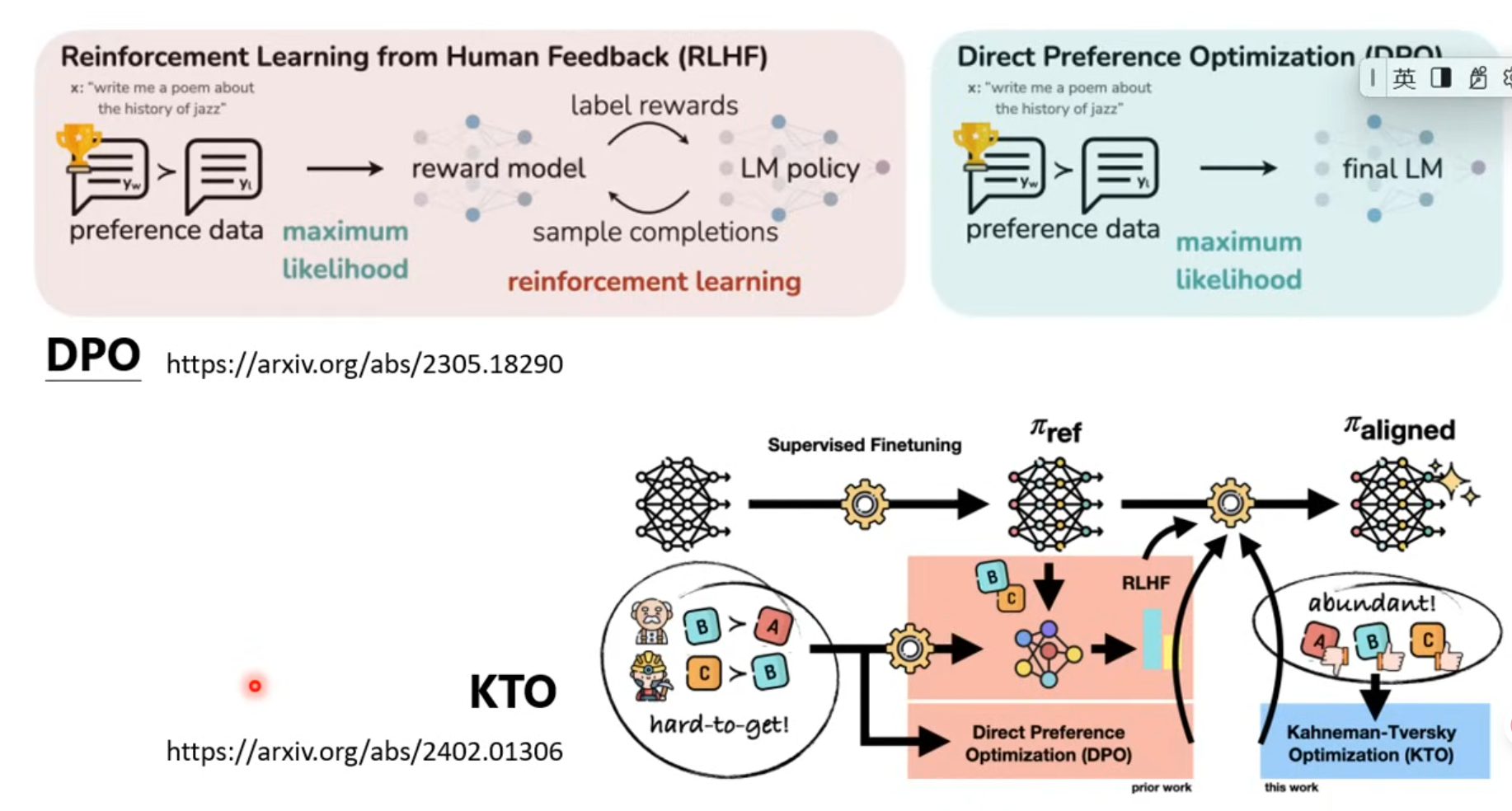
第三階段: 參與實戰,打磨技巧
Reinforcement Learning from Human Feedback, (RLHF)
强化学习
-ppo
-GPO
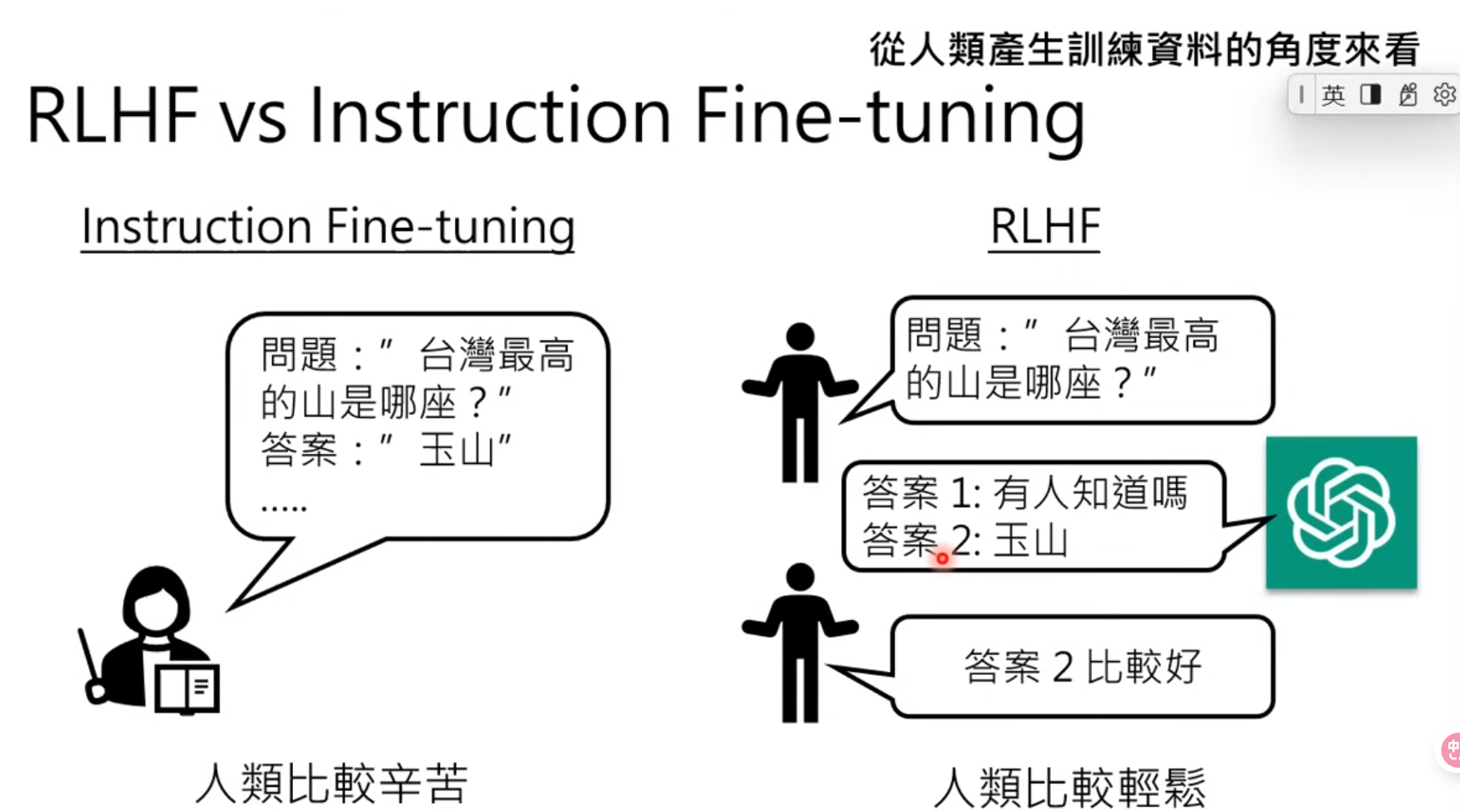
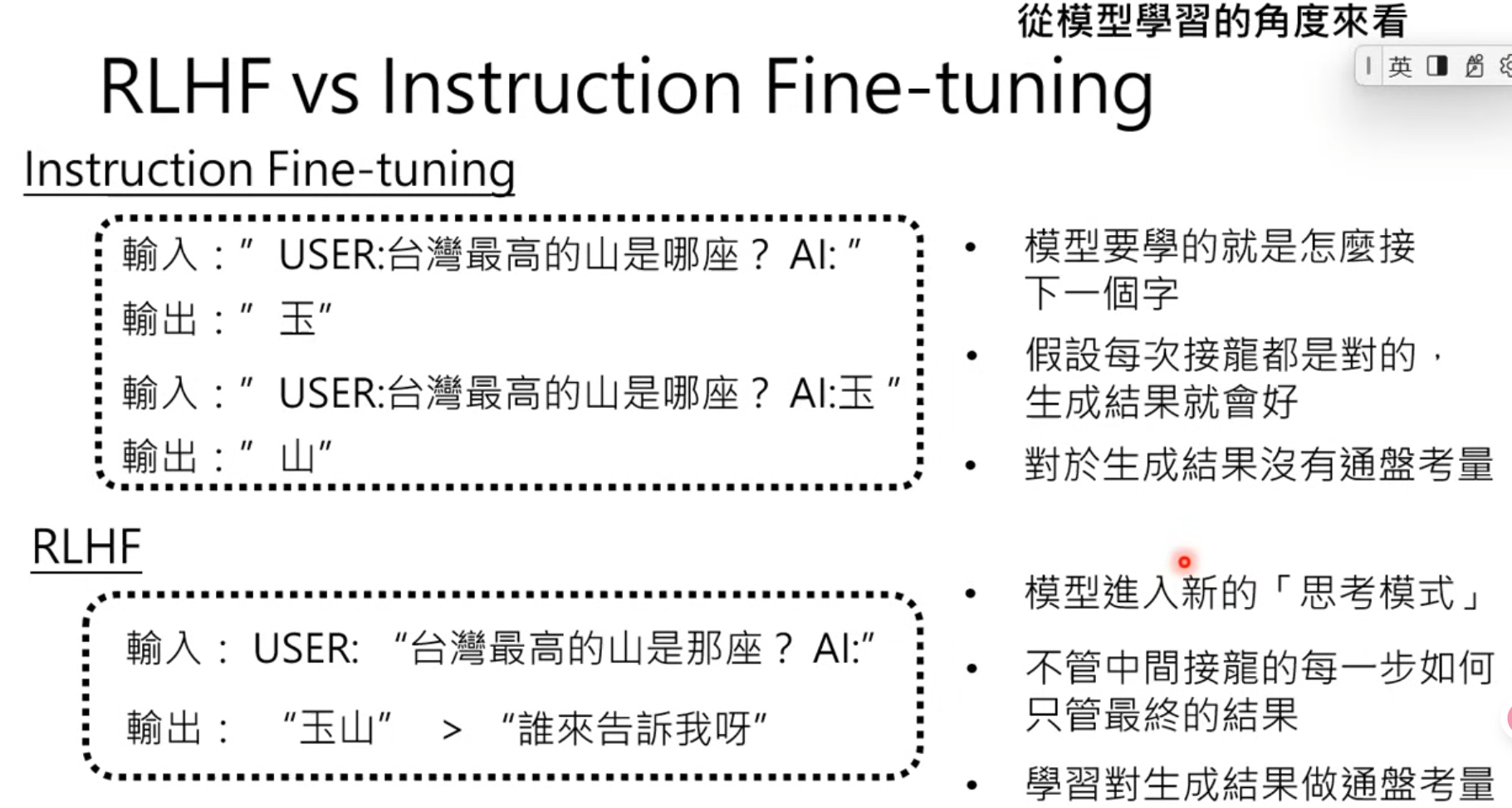
instruction Fine-tuning:只问过程,不问结果
RLHF: 只问结果,不问过程
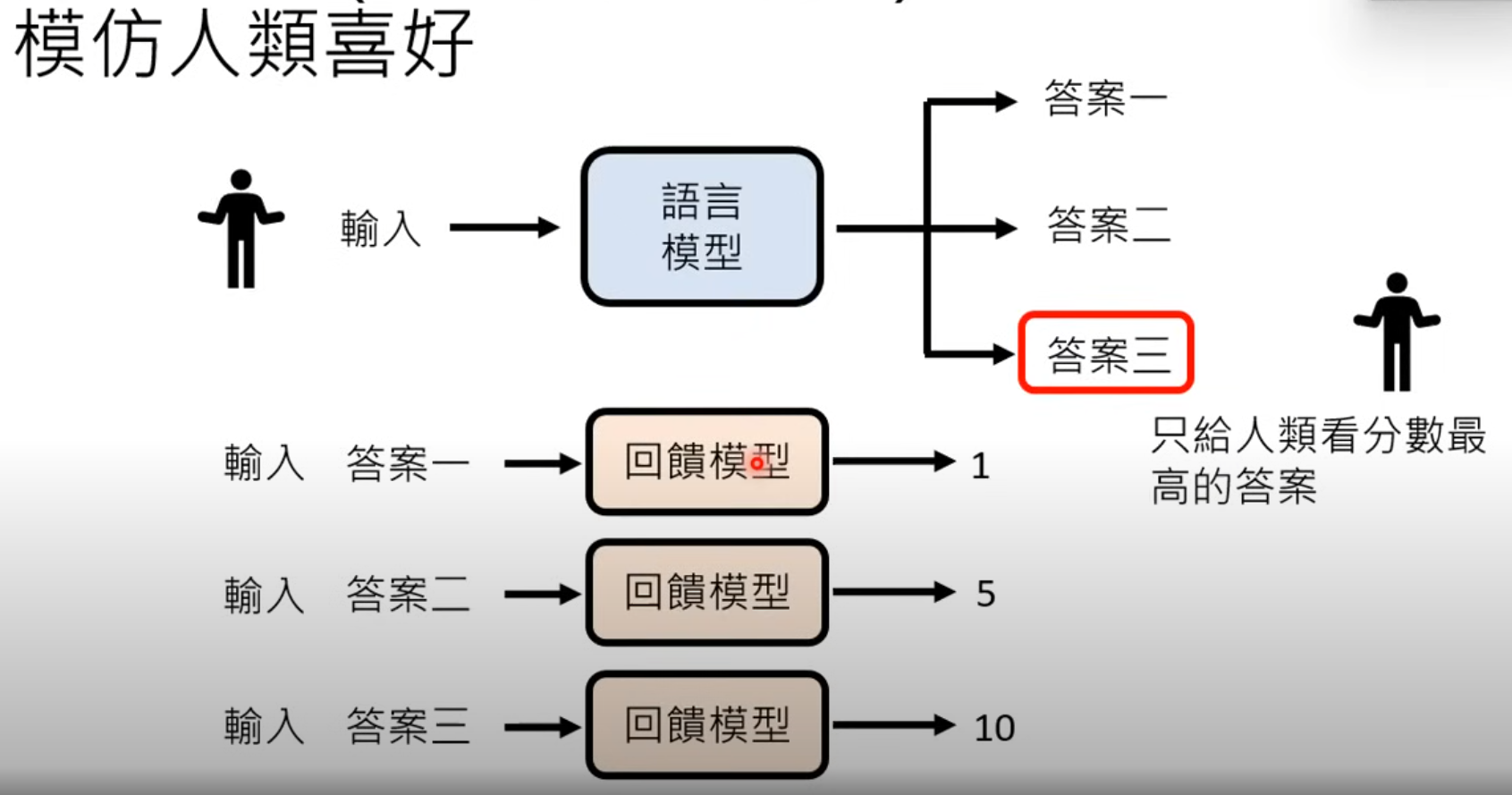
如何更有效利用人类的回馈??
回馈模型(reward model)
通过分数来评价
40f293946345afa4bec365e2090a78.png)
其他的方法