MQTT教训(二)MQTT物联网中Keep Alive值的那些坑_mqtt keep alive
在MQTT协议的世界里,Keep Alive(心跳周期)是一个看似简单却影响深远的参数。它定义了客户端与Broker之间的\"沉默容忍期\",一旦超过这个时间没有通信,连接就会被判定为失效。然而,这个参数的设置如同走钢丝——过小会导致设备功耗飙升,过大则可能让离线设备\"假在线\",引发业务故障。本文通过两个真实工程案例,解析Keep Alive值设置的深层影响,并给出一套经实战验证的配置方案。
一、从两个崩溃案例说起:Keep Alive值的\"生死线\"
案例1:Keep Alive=60s,2万台传感器48小时耗尽电池
场景:某智慧农业项目部署了2万台土壤湿度传感器,采用NB-IoT网络,电池供电,设计续航目标为1年。
问题:设备部署后仅48小时,就有30%的传感器因电量耗尽离线。
排查过程:
- 查看设备日志发现,传感器每60秒发送一次
PINGREQ心跳包,即使没有业务数据也会发送; - 测算能耗:每次心跳(含NB-IoT唤醒、发送、等待响应)消耗5mA电流,每小时10次心跳,单日耗电量相当于传输100条业务数据的总能耗;
- 根因定位:
Keep Alive值设置为60s,远小于NB-IoT网络的实际需求(该场景下网络延迟通常<300s),导致无效心跳消耗了90%的电量。
案例2:Keep Alive=3600s,车联网平台8小时未检测离线设备
场景:某新能源车企的远程控制平台,通过MQTT实现车辆指令下发(如远程开空调),Keep Alive值设置为3600s(1小时)。
问题:一批车辆因网络模块故障离线,但平台显示\"在线\",导致用户下发指令失败,投诉量激增。
排查过程:
- 车辆离线后,Broker需等待
1.5×3600=5400s(1.5小时)才判定连接失效; - 加上业务层轮询检测(每小时一次),整个离线发现周期长达8小时;
- 根因定位:
Keep Alive值设置过大,超过了业务对实时性的要求(远程控制需在5分钟内发现离线),导致故障感知严重滞后。
二、Keep Alive的工作原理:不止是\"心跳包\"那么简单
要理解Keep Alive的影响,首先需要明确其核心机制:
- 客户端承诺:在
Keep Alive周期(如120s)内,必须至少发送1个报文(可以是业务数据或PINGREQ心跳包); - Broker判定:如果超过
1.5×Keep Alive时间(如180s)未收到任何报文,就会主动断开连接,并触发遗嘱消息(Will Message); - 心跳形式:业务数据报文可替代
PINGREQ,无需额外发送心跳(这是很多工程师忽略的优化点)。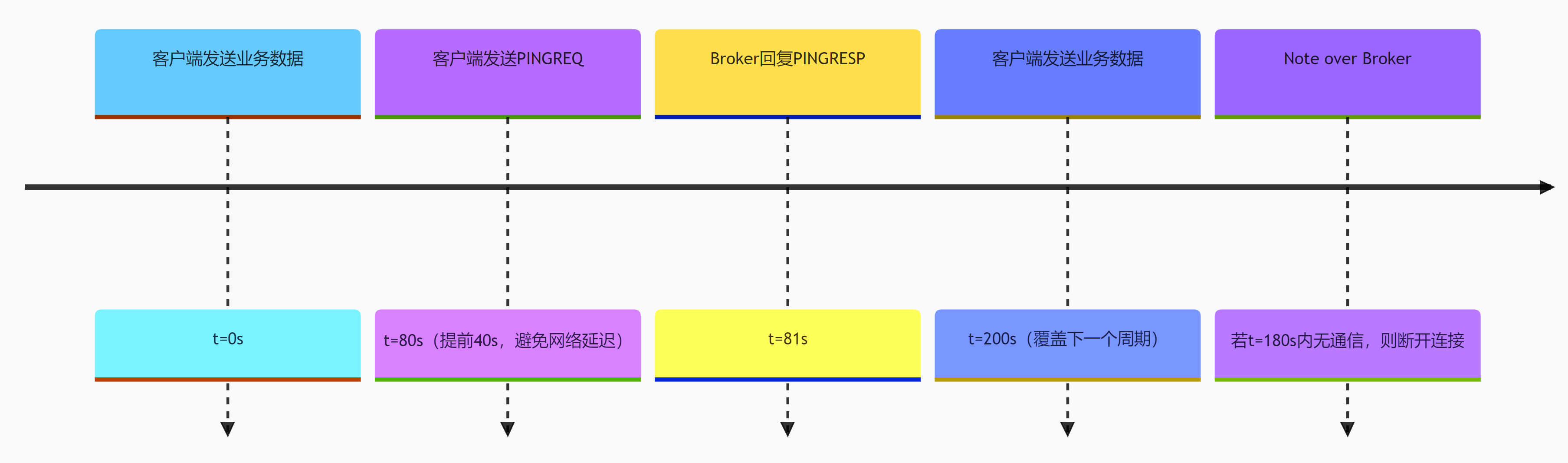
这个机制的设计初衷是平衡\"连接可靠性\"与\"资源消耗\",但在实际工程中,很多团队往往简单照搬默认值(如60s),忽视了不同场景的差异性。
三、Keep Alive值设置的深层影响:功耗与实时性的博弈
Keep Alive值的设置本质上是一场\"功耗\"与\"实时性\"的博弈,不同场景的平衡点差异极大:
四、实战配置方案:一套\"动态+分层\"的设置策略
经过10+物联网项目验证,我们总结出一套\"动态+分层\"的Keep Alive配置方案,核心原则是\"按需调整,场景适配\"。
1. 按网络类型分层配置(基础值)
不同网络的延迟和稳定性差异巨大,Keep Alive值需与网络特性匹配:
2. 按设备类型动态调整(修正值)
同一网络下,设备的供电方式和业务角色不同,Keep Alive值需进一步修正:
- 电池供电设备:在网络推荐值基础上×1.5(如NB-IoT设备从1800s→2700s),优先降低功耗;
- 市电供电设备:可采用网络推荐值下限(如WiFi设备用180s),优先保证实时性;
- 核心业务设备(如工业控制器):在网络推荐值基础上×0.5(如4G设备从120s→60s),缩短离线检测时间。
3. 代码层优化:用业务数据替代心跳
很多工程师忽视了MQTT的一个关键特性:业务数据报文可替代PINGREQ。通过代码优化,可减少70%以上的无效心跳:
// 优化前:固定60s发送PINGREQvoid loop() { if (millis() - last_ping_time > 60000) { client.ping(); // 无论是否有业务数据,强制发心跳 last_ping_time = millis(); } // 业务逻辑...}// 优化后:业务数据触发心跳重置void loop() { if (has_business_data()) { client.publish(topic, data); // 业务数据替代心跳 last_active_time = millis(); // 重置活跃时间 } else if (millis() - last_active_time > 0.7 * keep_alive) { client.ping(); // 仅在无业务数据时发心跳(提前30%时间) last_active_time = millis(); }}五、经验教训:从踩坑中提炼的5条铁律
经过多个项目的\"血泪教训\",我们总结出关于Keep Alive值的5条实战原则,避免重复踩坑:
- 没有\"万能值\":切勿所有设备共用一个
Keep Alive值(如统一设为60s),需按\"网络类型+设备角色\"分层配置; - 1.5倍超时原则:Broker的超时时间是客户端
Keep Alive值的1.5倍,配置时需同步计算(如客户端设120s,Broker实际超时180s); - 心跳≠PINGREQ:优先用业务数据报文替代
PINGREQ,尤其对低功耗设备,可大幅降低功耗; - 测试验证是关键:新设备部署前,必须通过\"断网测试\"验证离线检测时间(用
tc netem模拟网络中断); - 监控告警不可少:通过Broker的
$SYS主题监控keepalive_timeout指标,异常时及时告警(如某类设备心跳失败率突增)。
六、总结:在\"活着\"与\"省能\"之间找平衡
Keep Alive值的设置,本质上是物联网系统\"可用性\"与\"经济性\"的平衡艺术。过小的取值会让设备\"累死\"(功耗过高),过大的取值会让系统\"变瞎\"(离线检测滞后)。
记住:没有放之四海而皆准的配置,只有贴合业务场景的权衡。在实际工程中,建议从\"网络特性\"和\"设备角色\"两个维度出发,结合本文的配置方案进行测试调优,必要时甚至可以实现动态调整(如设备根据信号强度实时修改Keep Alive值)。
最后,用一位资深物联网工程师的话收尾:“调试Keep Alive值的过程,就是理解物联网设备’生存状态’的过程——既要让它们活着,也要让它们活得高效。”


