【python】selenium + python自动化测试环境搭建(如何获取数据)_自动化测试环境配置python
更多的程序员文章收录在
【JAVA方向学习文章视频汇总】
文章目录
- 啥?selenium 你不会?
- 大数据时代真的来了。
-
- 富哥请随意
- 低微的技术哥的方案
-
- Python爬虫技术在当今信息化时代具有重要意义
- 不能直接爬的怎么办?Selenium
- 第二部分:Selenium的安装与配置
-
- 2.1 python 安装
- 下载与导入
- 2.2下载webDriver
- 第三部分:利用Selenium进行数据抓取的代码
- 总结及资源下载
啥?selenium 你不会?
现在真的是大数据时代了,有人想挖点自己的数据。
老师,我想挖某影评下面 的所有的个人的信息,省份,来形成一个图表。
这想法有点意思呀!!
难不成看电影按省份来统计出来个人的爱好? 是因为电影 里有四川辣子,广东汤粉,还是有东北的铁锅炖大鹅呀?
大数据时代真的来了。
用python构建用户画像.实时表单系统开发如何做到最精准? 把某的客户搞过来? 无不良引导,纯技术!
一起维护好CSDN环境,拒绝广告,拒绝黄赌毒!坚决不发表,敏感信息、不当言论、恶意链接等。
运营商大数据精准抓取实时一手用户数
运营商大数据,顾名思义,是基于我国三大运营商的用户数据进行建模分析和数据挖掘的一种技术手段。通过实时截流访客数据,我们可以获取到精准的、实时的用户信息,包括他们的行为足迹、消费记录等。这些数据可以帮助企业更好地理解用户,进行精准营销,提升转化率。
原理和机制
运营商大数据的原理和机制主要基于API接口的开放权限。通过这些接口,我们可以实时抓取到垂直于你行业的手机APP的使用情况,包括访问、下载、注册、登录等行为。我们也可以获取到竞争对手和同行的推广竞价网站留下的400电话、固话的实时通话记录,包括主叫被叫、实时来电者数据等。
实例和案例
例如,我们可以通过运营商大数据实时获取到指定APP的实名用户访问情况,或者指定网址的实时访问情况(比如关键词搜索)。我们还可以获取到行业网站对外咨询热线(400或区号开头)的外呼和被呼用户数据。这些数据都可以帮助我们更好地理解用户行为,进行精准营销。
应用和意义
运营商大数据的应用和意义主要体现在客户画像的精准建立、精准营销、实时监测、数据分析和个性化推荐等方面。通过标签筛选,我们可以识别用户,并根据企业的需求来获取精准客户。例如,意向客户的保底达到8%-10%。运营商大数据也是一种高效、低成本、高转化的获客方式,可以帮助金融机构扩大市场份额和提升业绩。
通过实时跟踪移动用户的行为足迹,包括搜索行为、访问行为、应用下载、注册、登录行为、短信交互行为、拨号行为、消费记录等综合信息,我们可以根据客户的兴趣和偏好进行个性化推荐,从而提升用户体验,提高转化率。
富哥请随意
要啥技术,买就是了。而且买的是又快又好。
简直就是100米开外的距离,冲锋枪与砍马的对决。
深度数据包检测 (DPI) 技术 精准数据获取
深度数据包检测 (DPI) 技术是一种能够深入分析和控制网络流量的技术,其检测粒度达到应用层,可以识别和控制各种应用协议,如HTTP、FTP、DNS等。DPI技术广泛应用于网络安全、网络优化、业务运营等地方,能够帮助企业提高网络性能、保障网络安全、提升用户体验。
DPI技术的应用对于企业和个人都有着重要的意义。对于企业来说,DPI技术可以帮助他们提高网络性能、保障网络安全、提升用户体验,从而提高企业的运营效率和竞争力。对于个人来说,DPI技术可以保护他们的网络安全,避免网络攻击和网络钓鱼等安全威胁,提高他们的网络使用体验。
DPI技术还可以用于构建用户画像。在当今这个信息爆炸的时代,品牌了解自己的用户变得越来越重要。用户画像中包含了用户的年龄、性别、地域、社交关系、兴趣偏好、触媒习惯、行为特征、消费习惯等信息,可以帮助品牌深入了解目标用户群体,洞察用户真正的动机和行为。这对于品牌来说,具有重要的营销和产品设计意义。
低微的技术哥的方案
能爬的肯定就直接爬了呀
Python爬虫技术在当今信息化时代具有重要意义
使用python的requests模块还是存在很大的局限性,例如:只发一次请求;针对ajax动态加载的网页则无法获取数据等等问题。
不过就是限制太多了。
因为爬虫太简单了。
Python爬虫学习需要系统掌握基础知识、常用工具库和反爬应对策略,并通过案例实践提升技能。以下是2025年最新的爬虫技术体系详解:
爬核心技术基础
HTTP协议与请求机制。
请求类型:GET/POST/HEAD等方法的适用场景。
请求头设置:User-Agent、Cookie、Referer等参数的实战配置技巧。
状态码解析:200/403/404等常见响应状态的处理逻辑。
数据解析方法论。
HTML解析:XPath与CSS选择器的效率对比与实战应用。
JSON数据处理:嵌套结构解析与API接口调用规范。
二进制处理:图片/视频等非结构化数据的下载与管理。
主流工具库实战
基础工具栈。
Requests库:会话保持(Session)、超时重试、SSL验证等高级用法。
BeautifulSoup:多解析器(lxml/html5lib)性能对比与异常处理机制。
进阶框架应用。
Scrapy架构:Spider中间件、Item Pipeline、分布式爬虫构建。
Selenium自动化:Headless模式、元素等待策略、反检测指纹修改。
数据存储方案。
结构化存储:Pandas与CSV/Excel的交互处理。
数据库集成:MongoDB批量写入优化与MySQL事务控制。
反爬破解与性能优化
身份验证突破。
验证码识别:Tesseract OCR与深度学习方案集成。
IP代理策略:隧道代理与住宅IP池的选型建议。
请求特征伪装。
TLS指纹修改:JA3/JA4指纹的生成与伪装技术。
浏览器特征模拟:WebDriver协议深度定制方案。
分布式爬虫架构。
Scrapy-Redis集群:任务调度与去重机制优化。
异步加速方案:aiohttp与asyncio的协程并发实践。
社交媒体采集。
登录态维持:OAuth2.0协议与Cookie持久化存储。
瀑布流处理:增量抓取与历史数据去重策略
网络数据抓取在当今信息时代具有重要意义,而Python作为一种强大的编程语言,拥有丰富的库和工具来实现网络数据的抓取和处理。本教程将重点介绍如何使用Selenium这一强大的工具来进行网络数据抓取,帮助读者更好地理解和掌握Python爬虫技术。
不能直接爬的怎么办?Selenium
第一部分:Selenium简介
Selenium是一个自动化测试工具,最初是为Web应用程序测试而开发的,但它同样适用于网络数据抓取。Selenium可以模拟用户在浏览器中的操作,包括点击、填写表单、提交等,因此非常适合用于抓取那些需要交互操作的网页数据。
Selenium是一个用于自动化Web应用程序测试的开源工具集。
它提供了一组API和工具,可以与多种编程语言一起使用,如Java、Python、C#等,用于模拟用户在浏览器中的行为,如点击、填写表单、提交数据等。 Selenium可以运行在各种浏览器上,包括Chrome、Firefox、Safari等,它还可以与多个测试框架和开发工具集成,如JUnit、TestNG、Maven等。总之,Selenium是一个功能强大的自动化测试工具,可用于模拟用户在浏览器中的行为,以及验证和测试Web应用程序的功能和性能。
开源、免费
多浏览器支持:FireFox、Chrome、IE、Opera、Edge;
多平台支持:Linux、Windows、MAC;
多语言支持:Java、Python、Ruby、C#、JavaScript、C++;
对Web页面有良好的支持;
简单(API 简单)、灵活(用开发语言驱动);
支持分布式测试用例执行。
第二部分:Selenium的安装与配置
在使用Selenium进行网络数据抓取之前,首先需要安装Selenium库,并配置相应的浏览器驱动。Selenium支持多种浏览器,包括Chrome、Firefox、Edge等,读者可以根据自己的需求选择合适的浏览器驱动。
2.1 python 安装
【python】pycharm2018安装与python3.7
也可以参考这篇,里面安的是python3.8
【python】python库Matplotlib安装与在pycharm如何安装==附python的版本
下载与导入
点击 File -> Settings -> 选择项目:project untitled ,这里列出来了这个python 项目的虚拟环境所需要的python 导。
selenium的项目其实不需要这么多的包。我的这个项目也同时画图表。
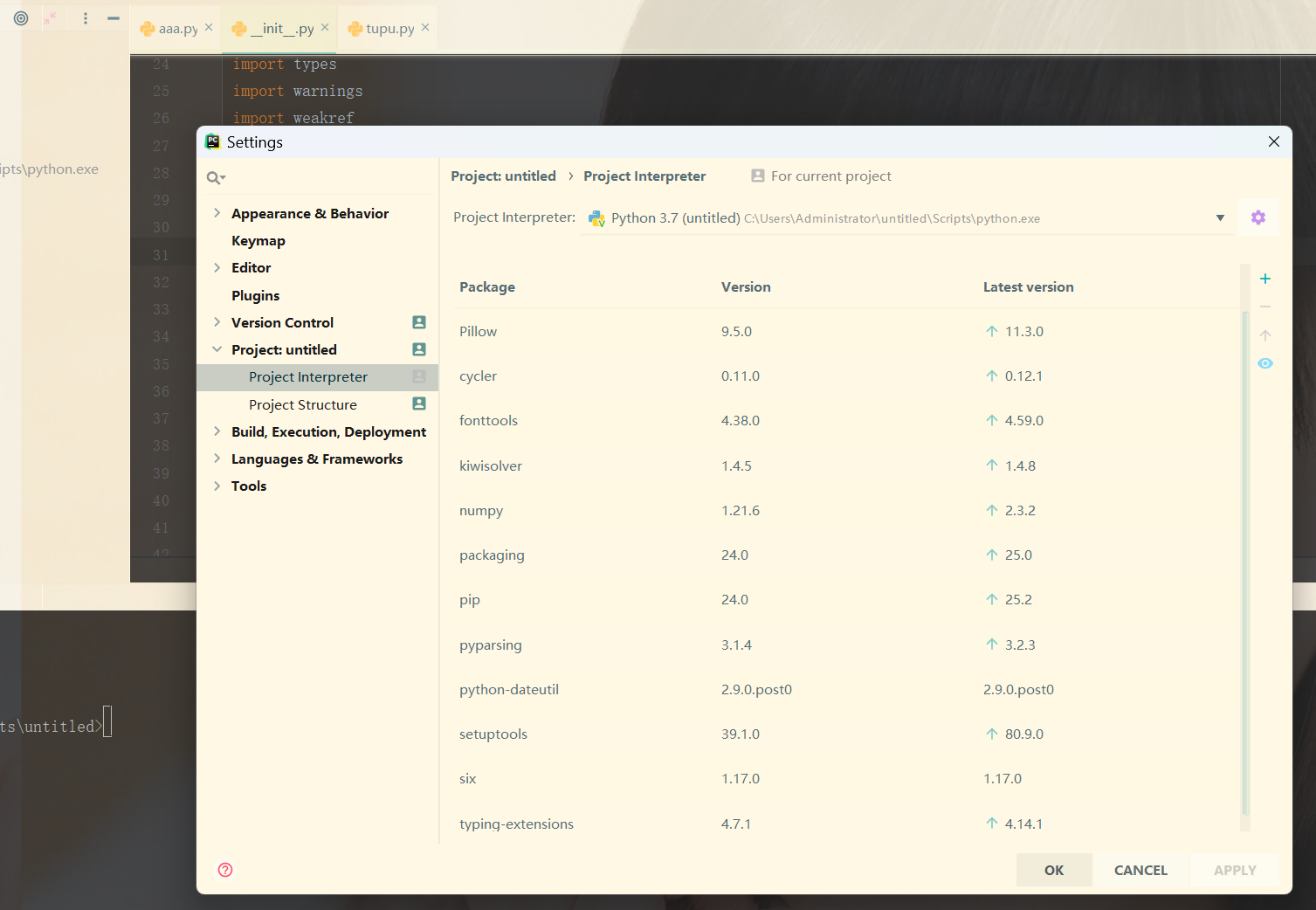
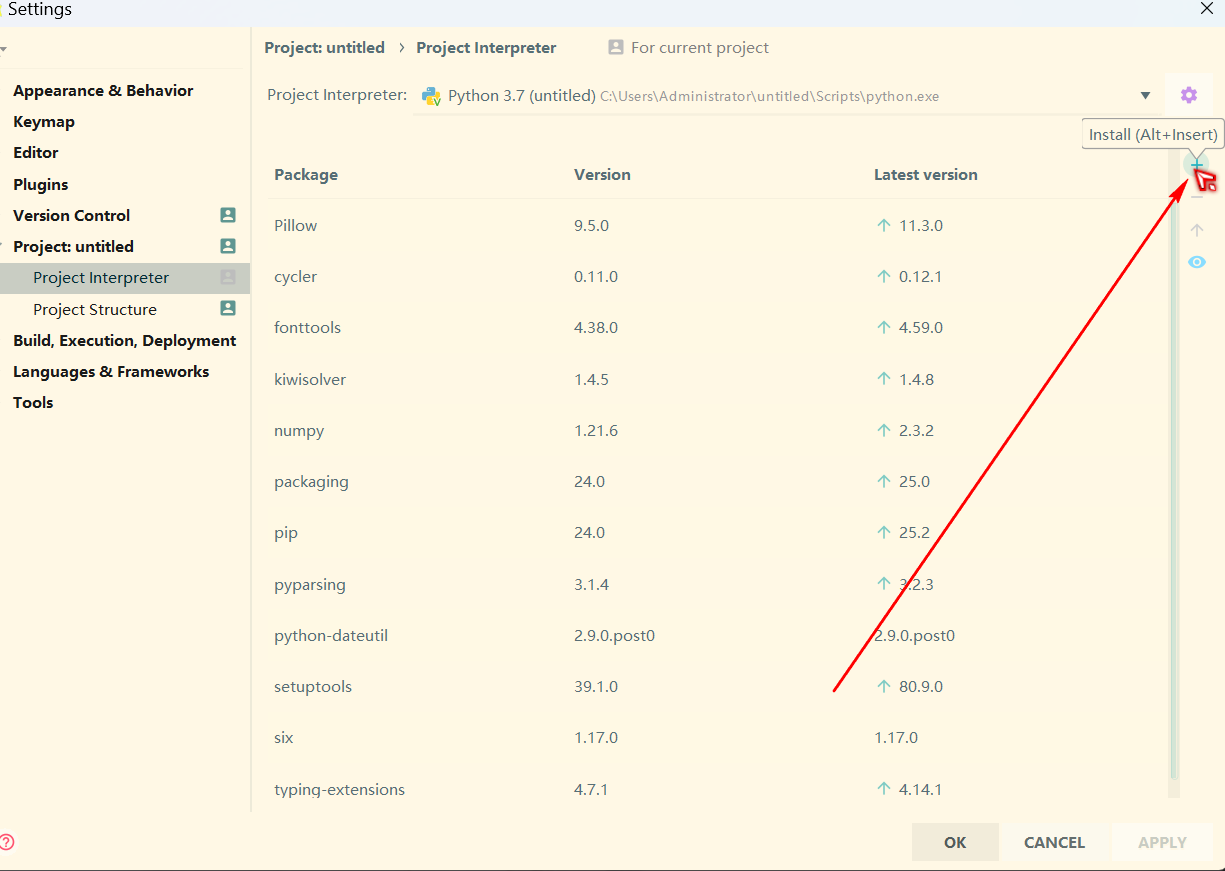
再点击 + 按钮,输入selenium,选择指定的版本,最后点击安装包即可。
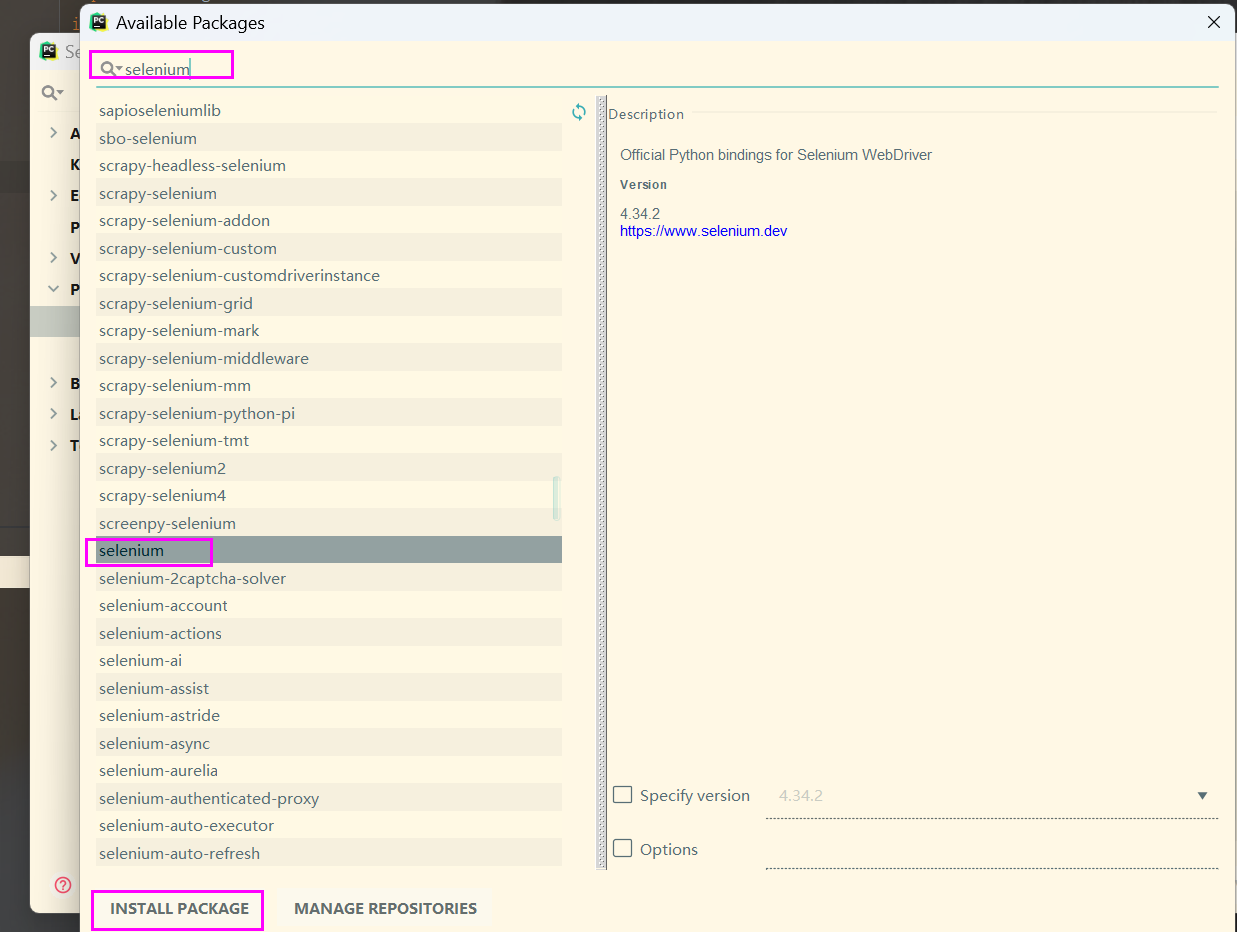
2.2下载webDriver
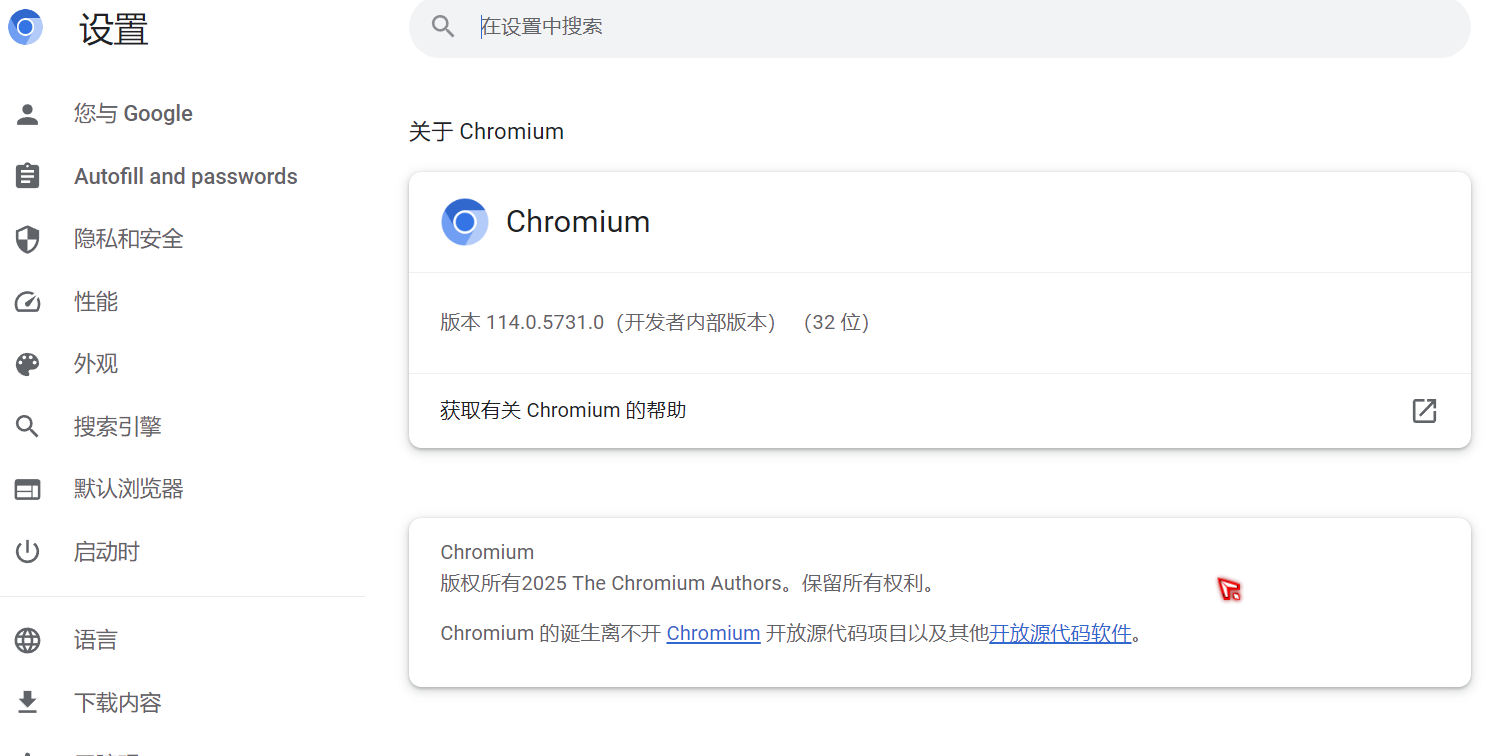
chrome浏览器 一定要与webDriver版本对应,否则浏览器是不会启动的。
也可以通过本文的资源下载的链接里下载
要注意的是,一般人如果用chrome浏览器就一定要用官方版本。
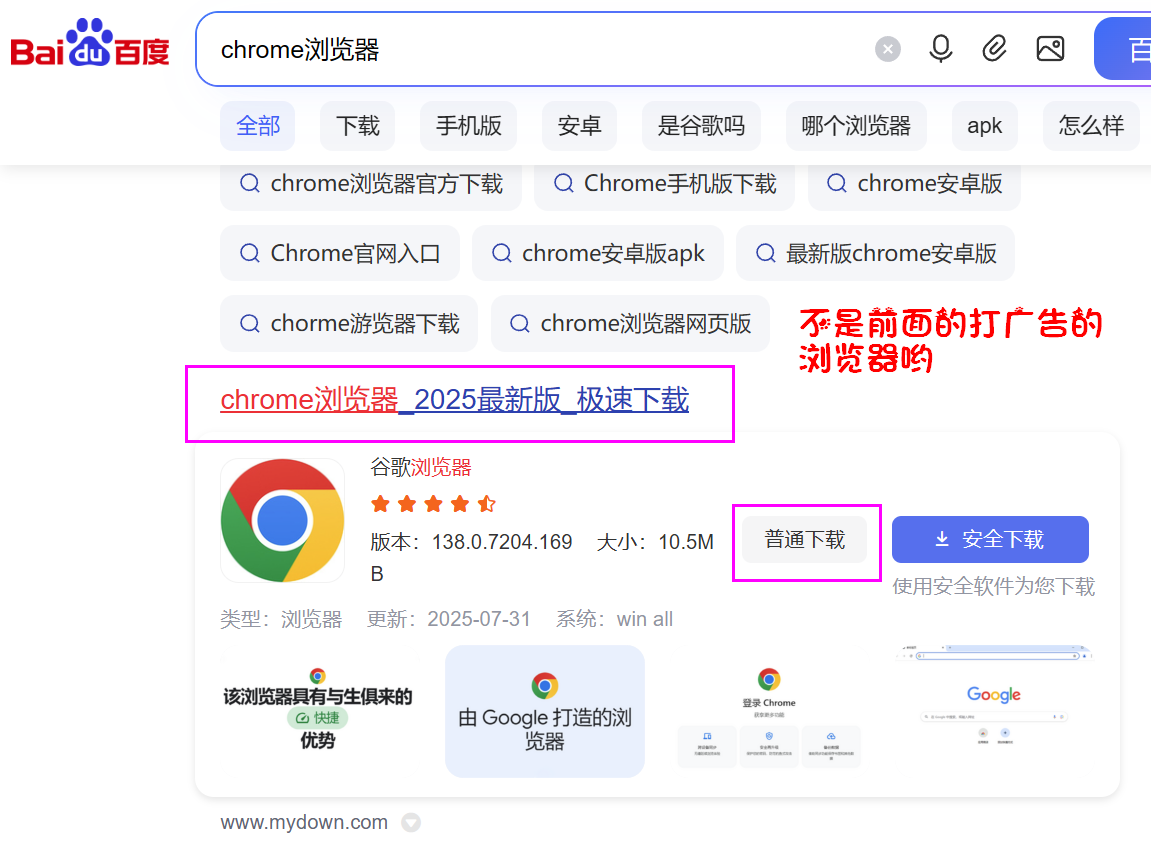
或者需要指定哪一个版本。比如114版本
下载对应浏览器的webDriver,例如:Chrome浏览器对应的webDriver
大多数人都是来这里下载(官网)
http://chromedriver.storage.googleapis.com/index.html
镜像:速度快
https://registry.npmmirror.com/binary.html?path=chromedriver/
找到自己的chrome 的版本号(很关键)
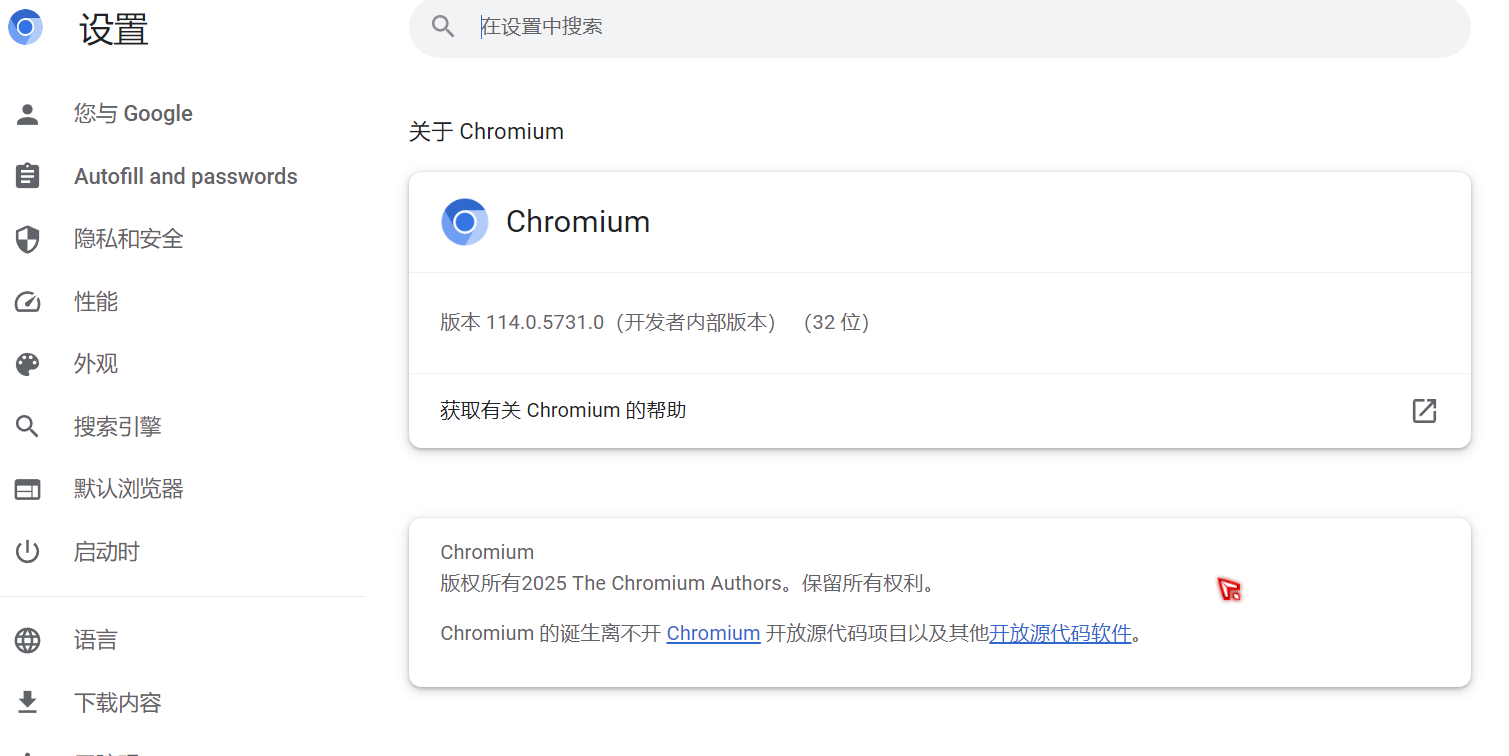
将下载chromedriver_win32.zip解压,并将其内的chromedriver.exe复制到Python安装目录下的Scripts目录中。
第三部分:利用Selenium进行数据抓取的代码
在这一部分,我们将介绍如何使用Selenium来抓取网页数据。首先,我们需要启动浏览器,并打开目标网页;然后,通过Selenium提供的方法来定位和提取我们需要的数据,比如通过XPath或CSS选择器定位元素,并获取其中的文本或属性值;最后,我们可以将抓取到的数据保存到本地文件或数据库中,以便后续分析和处理。
接下来,你需要下载相应的浏览器驱动,比如Chrome浏览器对应的ChromeDriver。将下载好的驱动文件放在系统路径中,或者在代码中指定驱动文件的路径。
使用Selenium抓取知乎数据的示例代码: 下面是一个简单的示例代码,演示如何使用Selenium来抓取知乎数据:
from selenium import webdriver# 启动浏览器driver = webdriver.Chrome() # 这里选择Chrome浏览器,你也可以选择其他浏览器# 打开知乎页面driver.get(\'https://www.zhihu.com/)# 定位并提取需要的数据# 这里可以通过查看网页源代码,使用XPath或CSS选择器定位元素,并获取其中的文本或属性值# 举例:假设要获取某对象title_element = driver.find_element_by_xpath(\'//*[@id=\"TopstoryContent\"]/div/div/div/div[2]/div/div/div/div/div[1]/div[2]/button[3]\') # 通过XPath定位商品标题元素title = title_element.text # 获取对象文本内容print(title)# 正常情况下是将抓取到的数据保存到本地文件或数据库中# 略...# 关闭浏览器driver.quit()总结及资源下载
提示:这里对文章进行总结:
关于python 安装的我没有录制视频。
先发一个JAVA版本的吧。其实一般人主要是需要那个延长试用期(破戒),
但是CSDN上面这些又不能发。
【JAVA环境】介绍IDEA 2020的下载以及安装
因为chrome 浏览器 与webdriver 要有版本对应,所以,这里的资源把这两个打包到一起了。
pythonselenium + python自动化测试环境搭建资源 114版本的chrome 浏览器+WEBDriver


