不断发展的 Tripadvisor 搜索:构建用于旅行推荐的语义搜索引擎
Tripadvisor 如何超越关键字,提供更智能、更快速、更个性化的旅行推荐。
作者:ASK Sathvik、Jaskirat Singh Benipal、Jay DeStories、Luis Baía、Sabreena Rajan、Pedro Balage、Tripadvisor
挑战:超越旅行推荐中的关键字
在 Tripadvisor,旅行者寻求个性化推荐,帮助他们以他们最喜欢的方式体验世界。凭借 11M+ 的企业和 1B+ 的评论和贡献,用户常常被大量可用内容所淹没。快速、智能地提供最相关的信息对于创建无缝体验至关重要。
从历史上看,我们的搜索和推荐系统一直基于关键字匹配。虽然这种方法可以实现快速检索,但它严重依赖单词匹配和关键字识别,限制了其理解细微用户意图的能力,并且在提供上下文丰富的动态推荐方面存在不足。这意味着诸如“给我找一个安静的地方吃一顿浪漫晚餐,在那里我们可以看到日落”之类的查询无法得到完全处理或支持。
为了解决这个问题,我们正在过渡到语义匹配方法。这种范式转变的重点是理解用户查询背后的含义和意图,并将其与我们大量内容的潜在语义相匹配,包括列表数据,最重要的是,在数百万条用户评论和论坛帖子(目前只有英文内容)中找到的情绪、体验和描述性细节。所有这些都在短短几毫秒内完成,使我们能够根据旅行者体验提供实时推荐,从而提供更智能、更快速和更个性化的发现过程。
为下一代功能提供支持
我们的语义搜索服务已经增强了几项关键的 Tripadvisor AI 体验:
人工智能旅行生成器:该工具根据目的地、旅行日期、同伴和兴趣等用户输入生成旅行行程。
- 通过利用语义搜索,我们确保每个行程的推荐与用户的特定偏好高度相关。
- 例如,当用户表示他们对户外活动感兴趣时,语义搜索会全面解释他们的偏好,即使没有提及确切的搜索词,也会显示与这些兴趣相符的推荐。
人工智能旅行助手:我们的人工智能旅行助手使用户能够通过对话式聊天界面提出开放式问题,从而轻松访问量身定制的旅行建议。
- 当用户提出特定问题时,例如“在哪里可以找到圣托里尼岛最好的日落景观”或“巴黎有哪些浪漫酒店”,他们的请求将由我们的语义搜索引擎解析和处理。该引擎不依赖严格的关键字匹配,而是通过将查询与每个列表的丰富、多方面的表示形式(包括标题、描述、评论和其他元数据)进行比较来解释用户的意图并检索最相关的结果
- 这可确保用户收到与他们真正正在寻找的内容密切相关的推荐,而不仅仅是基于关键字匹配。
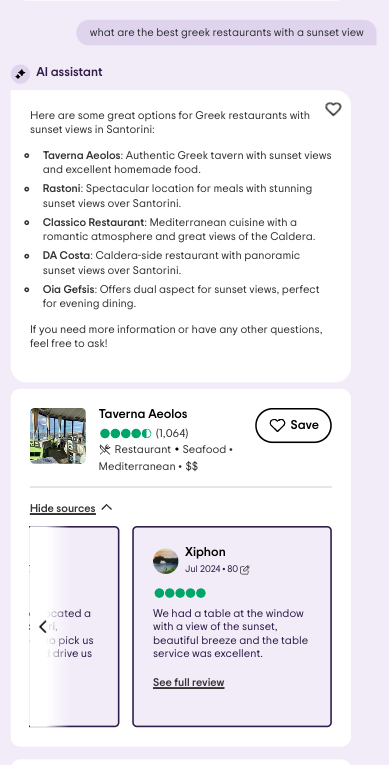
AI出行助手界面
在这两个功能中,我们的语义检索引擎为所谓的检索增强生成 (RAG) 策略提供支持,其中建议稍后由大型语言模型 (LLM) 细化,以便在用户响应中更好地进行上下文化。
一个重要的特征是,我们不直接从 LLM 提供兴趣点 (POI) 推荐(例如景点、餐厅和酒店)。尽管我们认识到这些模型非常有能力生成良好的推荐,但我们相信,通过利用 Tripadvisor 内容、我们的旅行者评论和论坛帖子,我们可以提供更好、更符合情境的建议。
设计可扩展的语义搜索架构
为了支持更细致入微和上下文感知的推荐,我们从传统的词汇搜索过渡到基于内容和查询的向量表示的语义检索系统。这种转变需要重新思考我们如何表示旅行者的意图和我们的列表——不是作为字符串,而是作为密集的、意义丰富的向量。在高层次上,我们的方法以三个原则为中心:
- 统一的语义表示:我们将用户查询和 Tripadvisor 内容(例如 POI、评论)嵌入到共享向量空间中,使我们能够根据含义而不仅仅是单词来计算相关性。
- 多源信号:我们将不同的数据类型(列出元数据、用户评论和行为上下文)合并到语义表示中,以最大限度地提高覆盖范围和精度。
- 高效的实时检索:我们构建了一个低延迟的矢量搜索管道,能够在几毫秒内提供相关结果,平衡相关性和生产使用的速度。
该框架为我们在以下部分中描述的嵌入策略、向量基础设施和混合检索技术奠定了基础。
语义理解的嵌入
语义搜索的核心在于以捕获含义的方式以数字方式表示文本的能力。为此,我们使用机器学习模型为我们的内容生成嵌入。
按 Enter 键或单击以查看大图
嵌入模型将 Tripadvisor 兴趣点 (POI) 和评论转换为捕获其语义含义的数字表示形式。这些表示形式支持基于相似性的搜索和个性化推荐。
按 Enter 键或单击以查看大图
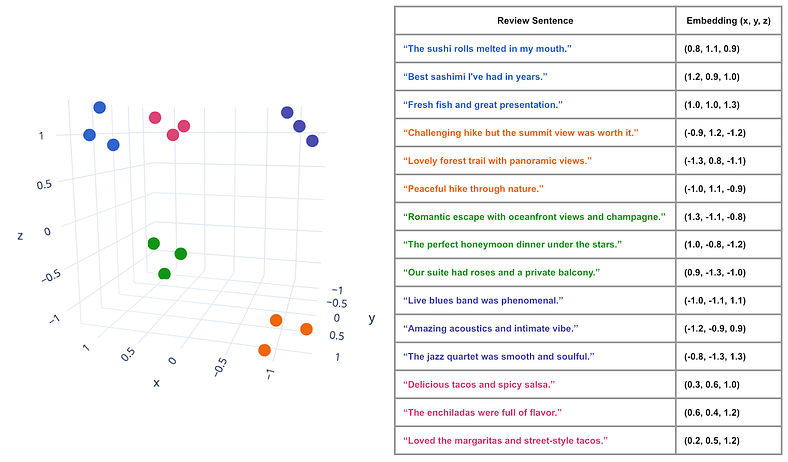
评论句子作为向量嵌入到 3D 空间中,其中语义相似性通过空间邻近性反映。具有相似含义的句子聚集在一起,说明嵌入如何捕捉不同类型体验之间的上下文关系。
嵌入模型: 我们利用了 gte-base 等嵌入模型,它在语义匹配方面表现出了良好的结果。此外,为了针对旅行领域内的独特语言和概念(例如,特定设施、体验类型、评论情绪)优化此模型,我们在 Tripadvisor 广泛的评论语料库、POI 描述和查询日志上微调了这些模型,以最大限度地提高相关性。这些模型将文本转换为高维向量(例如,gte-base 的 768 维),其中语义相似的概念在向量空间中的位置更近。
嵌入策略:我们为不同的内容类型生成单独的嵌入:
- POI 嵌入:派生自标题、描述、类别和关键属性等结构化数据。
- 评论嵌入:根据用户评论文本生成,捕捉旅行者体验和情绪的细微差别。这种分离允许灵活的检索策略。当用户查询(例如,“最佳蜜月目的地”)转换为自己的嵌入时,我们可以将其与 POI 和评论嵌入进行比较。
语义匹配:系统计算查询嵌入和内容嵌入之间的相似性分数(例如,余弦相似度)。这使我们能够找到相关的 POI,即使不存在确切的关键字。一篇提到“非常适合我们的周年纪念旅行”的评论有助于 POI 与 “浪漫之旅 ”的相关性,捕捉潜在的语义联系。
Retrieval Engine
任何语义搜索服务的核心都在于其检索引擎,该组件负责提供快速、相关且上下文准确的结果。虽然市场上有几种强大的解决方案,例如 ElasticSearch、Milvus、Weaviate 和 Pinecone,但我们选择与 Qdrant 合作来支持 Tripadvisor 的语义搜索功能。这一决定不仅受到 Qdrant 高性能矢量搜索功能的推动,还得益于其对地理空间矢量搜索的高级支持,这是像我们这样面向旅行的平台的关键要求,在该平台中,邻近性和位置相关性对于用户体验至关重要。
Qdrant 作为一个矢量数据库,支持尖端的检索技术,使我们能够将 POI 数据(例如酒店、餐厅、体验)和用户评论表示为密集嵌入。生成这些嵌入是为了反映语义含义(捕获文本的意图和上下文)和词汇相似性,确保重要的关键字和短语不会在转换中丢失。这种双层嵌入策略提高了召回率和精确度,特别是在处理复杂而细致的旅行查询时。
为了提供准确且符合用户意图的结果,我们实施了两步检索算法。这种多阶段方法使我们能够考虑更广泛的因素,这些因素会影响建议的相关性、有用性和专家驱动性。
第一步,我们通过结合词汇和语义相似性来检索一组相关的 POI。这确保了我们捕获的结果不仅与用户键入的术语匹配,而且与概念或上下文相关的结果也匹配。此步骤对于从可能以不同方式描述相同意图的旅行者那里捕获内容至关重要。
在第二步中,我们通过检索与第一阶段确定的 POI 相关的所有评论来进行更深入的检索。然后,根据与用户查询的语义相似性,检索到的 POI 及其各自的用户生成的评论会重新评分。这使我们能够优先考虑评论最能反映用户意图、情绪或期望的 POI。
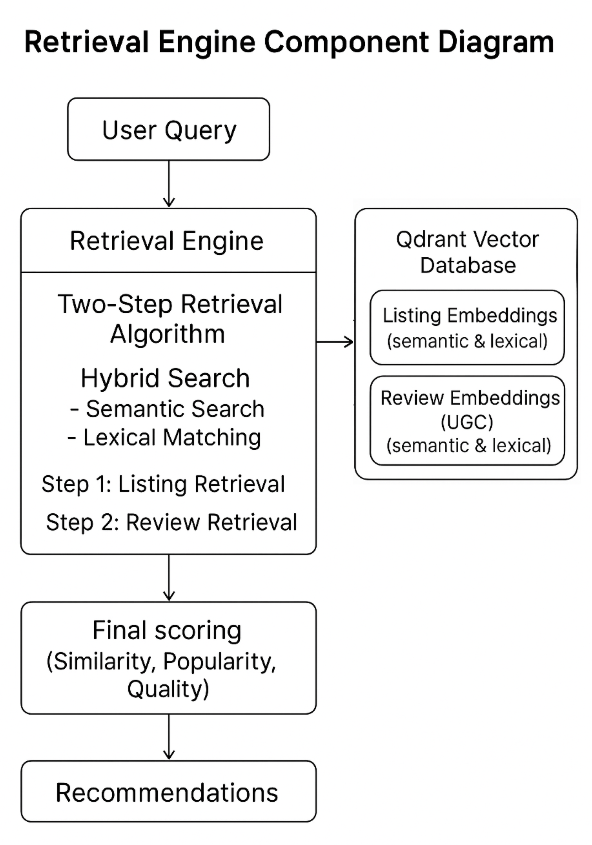
组件图显示了使用 POI 数据和用户评论对语义搜索 Tripadvisor 列表的两步检索算法
我们方法的一个关键区别在于我们强调用户生成内容 (UGC)。作为一个围绕数百万旅行者贡献而构建的平台,Tripadvisor 不仅将 UGC 视为补充信息,而且将其视为质量和相关性的主要信号。评论提供了丰富的第一手观点,帮助未来的用户做出明智的决定。这就是为什么根据评论的语义相似性重新排名的第二步可以说是最关键的。它确保我们的建议不仅在算法上合理,而且基于同行者的经验和声音。
检索最相似的结果后,考虑最后一步,以平衡建议的相关性与受欢迎程度(识别度)和质量(用户引用)。对于受欢迎程度,我们衡量评论数量以及与 POI 的参与度,而对于质量,我们使用我们著名的气泡分数(关于其他旅行者如何推荐特定 POI 的 5 级平均气泡评分)。
评估和质量标准
我们通过几种关键方法评估语义搜索引擎的质量,以确保其提供相关且准确的结果。通过结合内部测试、相关性评分、基于人工智能的评估和用户反馈,我们收集全面的见解,以优化所有用例的搜索性能。
质量保证 (QA) 测试:我们对每项 AI 体验进行 QA,以确保我们的语义搜索引擎运行一致且准确。
- 我们为每种体验使用一组精选的示例查询,测试不同上下文中的搜索响应,识别任何差距或不一致之处,并进行调整以优化结果。
LLM 作为法官相关性评估员t:我们使用 LLM-as-Judge 评估,利用 LLM 复杂模型根据用户查询信息以及匹配的位置信息和评论来分析和评级每个结果的相关性。
- 法学硕士细致入微的语言理解有助于识别传统指标可能无法捕获的细微相关因素,从而可以更彻底地评估搜索质量。
护栏指标:我们知道受欢迎程度和质量是重要因素。因此,我们密切监控这些指标,并确定特定查询的预期 POI 的存在。
最终用户反馈:用户反馈是评估搜索质量的关键指标。
- 明确反馈:我们直接从最终用户那里收集搜索结果上的“竖起大拇指”和“竖起大拇指”的回复,从而深入了解现实世界的相关性。
- 隐式反馈:我们进行了跟踪来捕获点击、保存和预订等互动,并提供建议以帮助确定结果的质量。
挑战和持续改进
构建和完善语义搜索系统面临着持续的挑战:
- 精度与召回率:平衡查找所有相关项目(召回率)而不包含太多不相关的项目(精确度)。例如,搜索“寿司”最初可能会出现相关概念,例如“拉面”;需要调整以提高精度。
- 数据稀疏性:处理评论中未明确包含相关信息的查询(例如,“提供免费 Wi-Fi 的酒店”需要改进列表数据集成)。
- 冷启动:有效地推荐评论很少的新房源。
- 多语言支持:确保 Tripadvisor 支持的多种语言的性能一致。
- 成本:有效管理大规模嵌入生成、索引和查询所需的计算资源。
- 正常运行时间和延迟: 在我们推广新功能时,保留我们的服务级别协议 (SLA),以了解正常运行时间和延迟响应时间。我们当前的延迟响应约为 200 毫秒。
我们不断迭代,探索新的建模技术,完善我们的检索和排名策略,并改进数据集成,以克服这些挑战。
结论
Tripadvisor 转向语义搜索代表着我们从根本上增强了将旅行者与真正符合他们的需求和偏好的体验联系起来的能力。通过利用深度学习模型进行语义理解,与 Qdrant 等先进的向量数据库技术合作,实施复杂的混合检索和重新排名策略,并采用严格的评估技术,我们正在构建一个更加智能和直观的发现引擎。这种持续的发展使我们能够更好地利用数百万条评论中的集体智慧,最终帮助旅行者计划和预订他们的完美旅行。

